python中的.nc文件处理 | 05 NetCDF数据的进一步分析
NetCDF数据的进一步分析
比较不同数据集、不同季节的气候数据
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
import cartopy.feature as cfeature
import seaborn as sns
import geopandas as gpd
import earthpy as et
import xarray as xr
import regionmask
绘制设置
sns.set(font_scale=1.3) # 字号
sns.set_style(“white”,{‘font.family’: ‘Times New Roman’}) # 主题
读取数据集
2006-2099年月最高气温
data_path_monthly = ‘http://thredds.northwestknowledge.net:8080/thredds/dodsC/agg_macav2metdata_tasmax_BNU-ESM_r1i1p1_rcp45_2006_2099_CONUS_monthly.nc’
with xr.open_dataset(data_path_monthly) as file_nc:
monthly_forecast_temp_xr=file_nc
monthly_forecast_temp_xr
读取矢量数据
states_path = “ne_50m_admin_1_states_provinces_lakes”
states_path = os.path.join(
states_path, “ne_50m_admin_1_states_provinces_lakes.shp”)
states_gdf=gpd.read_file(states_path)
cali_aoi=states_gdf[states_gdf.name==“California”]
获取aoi的左下-右上经纬度坐标
def get_aoi(shp, world=True):
“”“Takes a geopandas object and converts it to a lat/ lon
extent “””
lon_lat = {}
# Get lat min, max
aoi_lat = [float(shp.total_bounds[1]), float(shp.total_bounds[3])]
aoi_lon = [float(shp.total_bounds[0]), float(shp.total_bounds[2])]# Handle the 0-360 lon values
if world:aoi_lon[0] = aoi_lon[0] + 360aoi_lon[1] = aoi_lon[1] + 360
lon_lat["lon"] = aoi_lon
lon_lat["lat"] = aoi_lat
return lon_lat
cali_bounds=get_aoi(cali_aoi)
数据切片
start_date=“2059-12-15”
end_date=“2099-12-15”
cali_temp=monthly_forecast_temp_xr[“air_temperature”].sel(
time=slice(start_date,end_date),
lon=slice(cali_bounds[“lon”][0],cali_bounds[“lon”][1]),
lat=slice(cali_bounds[“lat”][0],cali_bounds[“lat”][1]))
cali_temp
print("Time Period start: ", cali_temp.time.min().values)
print("Time Period end: ", cali_temp.time.max().values)
Time Period start: 2059-12-15 00:00:00
Time Period end: 2099-12-15 00:00:00
掩膜
cali_mask=regionmask.mask_3D_geopandas(cali_aoi,
monthly_forecast_temp_xr.lon,
monthly_forecast_temp_xr.lat)
cali_temp_masked=cali_temp.where(cali_mask)
cali_temp_masked.dims
(‘time’, ‘lat’, ‘lon’, ‘region’)
cali_temp_masked.shape
(481, 227, 246, 1)
计算每个季节的平均最高温
groupby()参数:time.season time.month time.year
cali_season_summary=cali_temp_masked.groupby(
“time.season”).mean(“time”,skipna=True)
cali_season_summary.shape # 汇总成四个季节
(4, 227, 246, 1)
(DJF=Dec-Feb, MAM=Mar-May,. JJA=Jun-Aug, SON=Sep-Nov)
cali_season_summary.plot(col=“season”,col_wrap=2,figsize=(10,10))
plt.suptitle(“Mean Temperature Across All Selected Years By Season \n California, USA”,
y=1.05)
plt.show()
计算每年的每个季节的均值变化
String in the ‘#offset’ to specify the step-size along the resampled dimension
‘AS’: year start
‘QS-DEC’: quarterly, starting on December 1
‘MS’: month start
‘D’: day
‘H’: hour
‘Min’: minute
Resample the data by season across all years
cali_season_mean_all_years = cali_temp_masked.resample(
time=‘QS-DEC’, keep_attrs=True).mean()
cali_season_mean_all_years.shape
(161, 227, 246, 1)
Summarize each array into one single (mean) value
cali_seasonal_mean = cali_season_mean_all_years.groupby(‘time’).mean([
“lat”, “lon”])
cali_seasonal_mean.shape
(161, 1)
f, ax = plt.subplots(figsize=(10, 4))
cali_seasonal_mean.plot(marker=“o”,
color=“grey”,
markerfacecolor=“purple”,
markeredgecolor=“purple”)
ax.set(title=“Seasonal Mean Temperature”)
plt.show()
转换成pd格式
cali_seasonal_mean_df = cali_seasonal_mean.to_dataframe()
cali_seasonal_mean_df.head()
导出为csv
cali_seasonal_mean_df.to_csv(“cali-seasonal-temp.csv”)
分季节绘制均值变化
colors={3:“grey”,6:“lightgreen”,9:“green”,12:“purple”}
seasons={3:“spring”,6:“summer”,9:“fall”,12:“winter”}
f,ax=plt.subplots(figsize=(10,7))
for month,arr in cali_seasonal_mean.groupby(“time.month”):
arr.plot(ax=ax,
color=“grey”,
marker=“o”,
markerfacecolor=colors[month],
markeredgecolor=colors[month],
label=seasons[month])
ax.legend(bbox_to_anchor=(1.05,1),loc=“upper left”)
ax.set(title=“Seasonal Change in Mean Temperature Over Time”)
plt.show()
参考链接:
https://www.earthdatascience.org/courses/use-data-open-source-python/hierarchical-data-formats-hdf/summarize-climate-data-by-season/
https://xarray.pydata.org/en/v0.8.2/generated/xarray.Dataset.resample.html
https://gitee.com/jiangroubao/learning/tree/master/NetCDF4
相关文章:

python中的.nc文件处理 | 05 NetCDF数据的进一步分析
NetCDF数据的进一步分析 比较不同数据集、不同季节的气候数据 import os import numpy as np import pandas as pd import matplotlib.pyplot as plt import cartopy.crs as ccrs import cartopy.feature as cfeature import seaborn as sns import geopandas as gpd import…...

GGX发布全新路线图,揭示具备 Layer0 特性且可编程的跨链基建生态
据彭博社报道,具备跨链通信且可编程的 Layer0 基础设施协议 Golden Gate (GGX) 已进行了 两年的线下开发,于近日公开发布了最新的路线图,该路线图不仅显示了该生态在过去两年的发展历程,也披露了 2023 年即将实现的重要里程碑。 G…...

taro+vue3 搭建一套框架,适用于微信小程序和H5
这里写tarovue3 搭建一套框架,适用于微信小程序和H5TaroVue3 搭建适用于微信小程序和 H5 的框架的大致步骤:TaroVue3 搭建适用于微信小程序和 H5 的框架的大致步骤: 安装 Taro。可以在终端输入以下命令进行安装: npm install -g…...

C++:模板初阶(泛型编程、函数模板、类模板)
文章目录1 泛型编程2 函数模板2.1 函数模板概念2.2 函数模板格式2.3 函数模板的原理2.4 函数模板的实例化2.5 模板参数的匹配原则3 类模板3.1 类模板的定义格式3.2 类模板的实例化1 泛型编程 所谓泛型,也就是通用型的意思。 在以往编写代码时,我们常常…...
)
把数组排成最小的数 AcWing(JAVA)
输入一个正整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。 例如输入数组 [3,32,321][3,32,321],则打印出这 33 个数字能排成的最小数字 321323321323。 数据范围 数组长度 [0,500][0,500]。 样例&#x…...
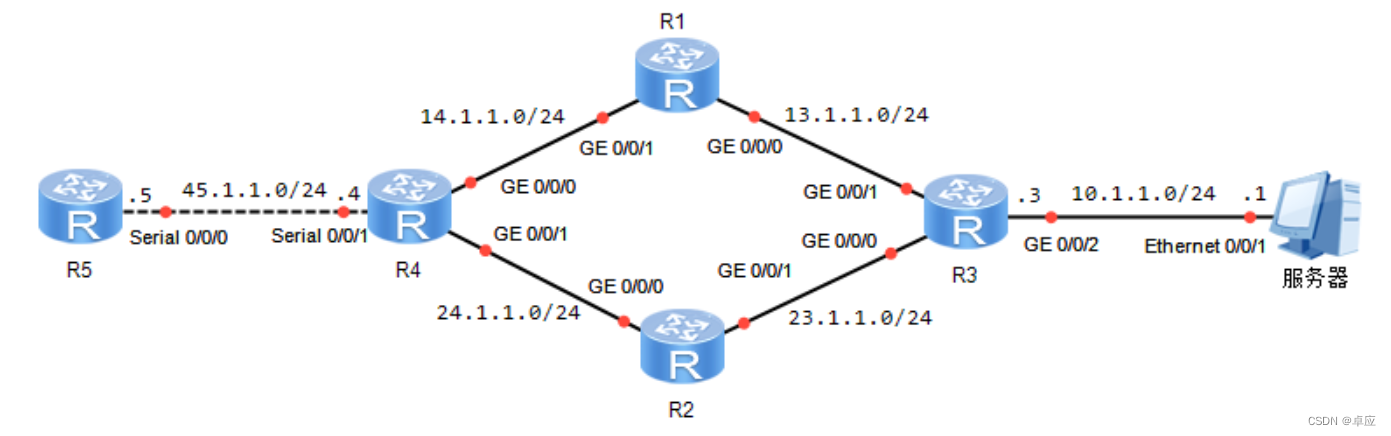
4.3 PBR
1. 实验目的 熟悉PBR的应用场景掌握PBR的配置方法2. 实验拓扑 PBR实验拓扑如图4-8所示: 图4-8:PBR 3. 实验步骤 (1) IP地址的配置 R1的配置 <Huawei>system-view...

hmac — 加密消息签名和验证
hmac — 加密消息签名和验证 1.概述 它的全称叫做Hash-based Message Authentication Code: 哈希消息认证码,从名字中就可以看出来这个hmac基于哈希函数的,并且还得提供一个秘钥key,它的作用就是用来保证消息的完整性,不可篡改。…...
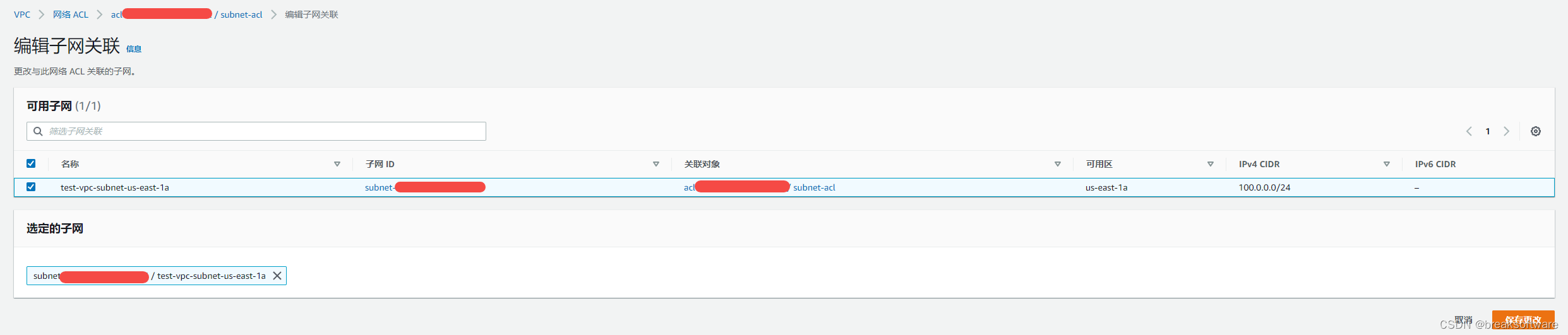
AWS攻略——使用ACL限制访问
文章目录确定出口IP修改ACL修改主网络ACL修改入站规则修改子网ACL创建子网ACL新增入站规则新增出站规则关联子网假如我们希望限制只有公司内部的IP可以SSH登录到EC2,则可以考虑使用ACL来实现。 我们延续使用《AWS攻略——创建VPC》的案例,在它的基础上做…...
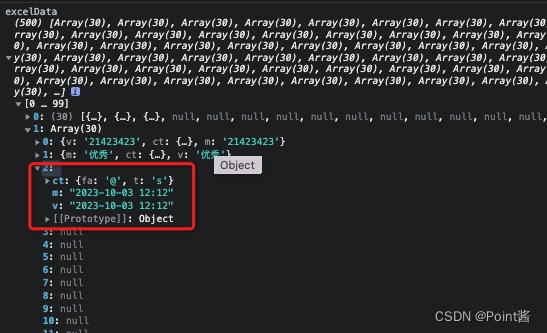
【已解决】关于 luckysheet 设置纯文本,解决日期格式回显错误的办法
目录 一、现象 二、分析 三、思考过程 五、解决 六、参考链接 一、现象 在excel里面输入内容,如 2023-2-17 12:00 保存后,传回后端的数据被转化成了 数值类型,这显然是一种困扰。 如图所示 二、分析 查阅了文档和一些博客发现 Lucky…...

Jackson
first you need to add dependence: gradle: implementation com.fasterxml.jackson.core:jackson-databind:2.13.1 implementation com.fasterxml.jackson.datatype:jackson-datatype-jsr310:2.13.1原生Jackson的使用示例: /*** 原生Jackson的使用示例*/ public class Jacks…...
字节软件测试岗:惨不忍睹的三面,幸好做足了准备,月薪19k,已拿offer
我今年25岁,专业是电子信息工程本科,19年年末的时候去面试,统一投了测试的岗位,软件硬件都有,那时候面试的两家公司都是做培训的,当初没啥钱,他们以面试为谎言再推荐去培训这点让我特别难受。后…...
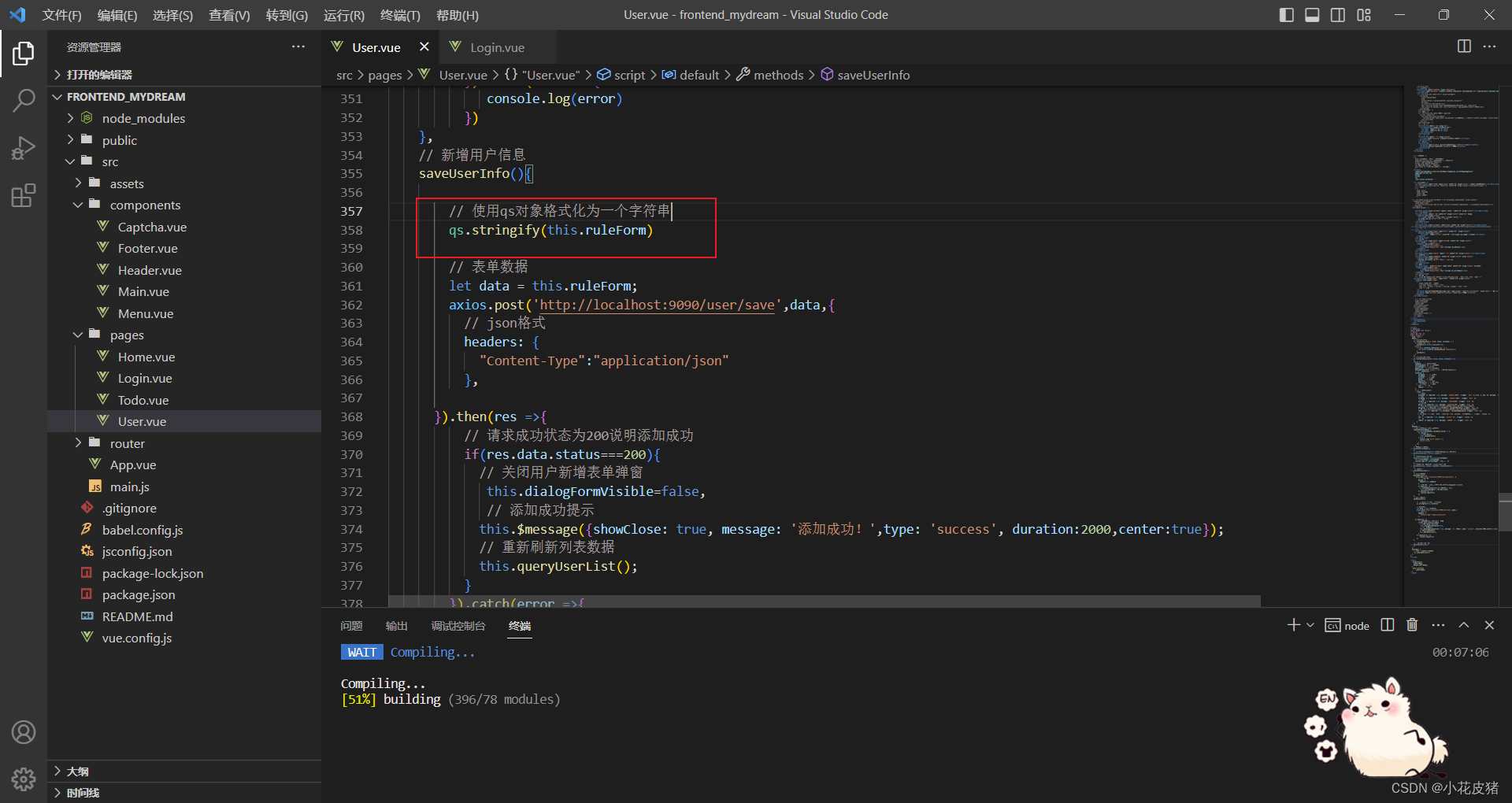
vue使用axios发送post请求携带json body参数,后端使用@RequestBody进行接收
前言 最近在做自己项目中,做一个非常简单的新增用户场景,但是使用原生axios发送post请求的时候,还是踩了不少坑的。 唉,说多了都是泪,小小一个新增业务,在自己前后端一起开发的时候,硬是搞了好…...

【python百炼成魔】python之列表详解
文章目录一. 列表的概念1.1 列表是什么?1.2 为什么要使用列表?1.3 列表的定义二. 列表的增删改查操作2.1 列表的读取2.2 列表的切片2.3 列表的查询操作2.3.1 not in ,in 表达式2.3.2 列表元素遍历2.4 列表元素的增加操作2.4.1 append()的相关用法2.4.2 e…...

如何学习 Web3
在本文中,我将总结您可以采取的步骤来学习 Web3。从哪儿开始?当我们想要开始新事物时,我们需要一些指导,以免在一开始就卡住。但我们都是不同的,我们有不同的学习方式。这篇文章基于我学习 Web3 的非常个人的经验。路线…...
大数据框架之Hadoop:MapReduce(一)MapReduce概述
1.1MapReduce定义 MapReduce是一个分布式计算框架,用于编写批处理应用程序,是用户开发“基于Hadoop的数据分析应用”的核心框架。 MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一…...

一文搞定python语法进阶
前言前面我们已经学习了Python的基础语法,了解了Python的分支结构,也就是选择结构、循环结构以及函数这些具体的框架,还学习了列表、元组、字典、字符串这些Python中特有的数据结构,还用这些语法完成了一个简单的名片管理系统。下…...

2019蓝桥杯真题数列求值(填空题) C语言/C++
题目描述 本题为填空题,只需要算出结果后,在代码中使用输出语句将所填结果输出即可。 给定数列 1,1,1,3,5,9,17,⋯,从第 4 项开始,每项都是前 3 项的和。 求第 20190324 项的最后 4 位数字。 运行限制 最大运行时间:…...
spring中@Autowire和@Resource的区别在哪里?
介绍今天使用Idea写代码的时候,看到之前的项目中显示有warning的提示,去看了下,是如下代码?Autowire private JdbcTemplate jdbcTemplate;提示的警告信息Field injection is not recommended Inspection info: Spring Team recommends: &quo…...
算法训练营DAY54|583. 两个字符串的删除操作、72. 编辑距离
583. 两个字符串的删除操作 - 力扣(LeetCode)https://leetcode.cn/problems/delete-operation-for-two-strings/这道题也是对于编辑距离的铺垫题目,是可以操作两个字符串的删除,使得两个字符串的字符完全相同,这道题可…...

【Ctfshow_Web】信息收集和爆破
0x00 信息收集 web1 直接查看源码 web2 查看不了源码,抓包即可看到(JS拦截了F12) web3 抓包,发送repeater,在响应包中有Flag字段 web4 题目提示后台地址在robots,访问/robots.txt看到Disallow: /fl…...

AI专著生成神器登场!快速输出20万字专著,写作不用愁!
学术专著写作困境与AI工具的崛起 对于许多学术研究者来说,撰写学术专著时面临的最大挑战,无疑是“有限的精力”和“无穷的需求”之间的矛盾。撰写专著通常需要三到五年,甚至更长时间,而研究者还需平衡教学、科研项目和学术交流等…...

从用户态到内核态:Linux Hook技术的全景实践与攻防解析
1. Linux Hook技术入门:从概念到实践 第一次接触Hook技术是在十年前的一个安全分析项目中,当时需要监控某个可疑进程的行为。那时候我才明白,原来Linux系统里藏着这么多可以"截胡"程序执行的秘密通道。简单来说,Hook技术…...

如何用Figma-to-JSON解决设计开发协作难题:4个实用场景详解
如何用Figma-to-JSON解决设计开发协作难题:4个实用场景详解 【免费下载链接】figma-to-json 💾 Read/Write Figma Files as JSON 项目地址: https://gitcode.com/gh_mirrors/fi/figma-to-json 在当今快速迭代的产品开发环境中,设计师与…...
)
MATLAB roots函数实战:5分钟搞定高阶系统稳定性判断(附完整代码)
MATLAB roots函数实战:高阶系统稳定性分析的黄金法则 在控制工程和自动化领域,系统稳定性分析是每个工程师的必修课。面对复杂的高阶系统特征方程,传统的手工计算方法不仅耗时耗力,还容易出错。而MATLAB的roots函数配合简单的可视…...
,让开源检索进入“所想即所得”时代)
别再Ctrl+F GitHub了!Perplexity高级提示词工程(含18个已验证模板),让开源检索进入“所想即所得”时代
更多请点击: https://intelliparadigm.com 第一章:Perplexity GitHub资源检索的范式革命 从关键词匹配到语义理解的跃迁 传统 GitHub 搜索依赖精确的仓库名、文件路径或正则表达式,而 Perplexity 引入的 LLM 驱动检索将自然语言查询&#x…...

为AI编程助手构建持久化项目记忆库:告别上下文遗忘,提升团队协作效率
1. 项目概述:为AI编程助手构建持久化项目记忆库如果你和我一样,每天都要和Claude Code、Cursor这些AI编程助手打交道,肯定遇到过这个烦人的问题:每次新开一个对话,AI就像得了失忆症,完全不记得你刚才在做什…...

终极罗技PUBG压枪宏配置指南:从新手到高手的完整教程
终极罗技PUBG压枪宏配置指南:从新手到高手的完整教程 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 你是否在《绝地求生》中经历过这…...

如何在Windows上轻松安装ViGEmBus虚拟手柄驱动解决游戏兼容性问题
如何在Windows上轻松安装ViGEmBus虚拟手柄驱动解决游戏兼容性问题 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的困扰:手…...

Linux下Cursor AI编辑器自动化安装脚本设计与实现
1. 项目概述:为什么我们需要一个Cursor的Linux安装脚本如果你是一个在Linux环境下工作的开发者,并且对AI辅助编程工具感兴趣,那么Cursor这个名字你一定不陌生。作为一款集成了强大AI能力的代码编辑器,它正迅速成为许多程序员的新宠…...

3分钟搞定TrollStore:iOS 14-16.6.1一键安装终极指南
3分钟搞定TrollStore:iOS 14-16.6.1一键安装终极指南 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 你是否曾为在iOS设备上安装TrollStore而烦恼࿱…...