【项目】轻量级HTTP服务器
文章目录
- 一、项目介绍
- 二、前置知识
- 2.1 URI、URL、URN
- 2.2 CGI
- 2.2.1 CGI的概念
- 2.2.2 CGI模式的实现
- 2.2.3 CGI的意义
- 三、项目设计
- 3.1 日志的编写
- 3.2 套接字编写
- 3.3 HTTP服务器实现
- 3.4 HTTP请求与响应结构
- 3.5 EndPoint类的实现
- 3.5.1 EndPoint的基本逻辑
- 3.5.2 读取请求
- 3.5.3 构建响应
- 3.5.3.1 CGI处理
- 3.5.3.2 非CGI处理
- 3.5.4 发送响应
- 3.6 错误处理
- 3.6.1 处理逻辑错误
- 3.6.2 处理读取错误
- 3.6.3 处理写入错误
- 3.7 引入线程池
- 四、项目测试
- 4.1 GET方法上传数据测试
- 4.2 POST方法上传数据测试
- 五、项目源码
一、项目介绍
本项目实现的是一个HTTP服务器,项目主要功能是通过基本的网络套接字读取客户端发来的HTTP请求并进行分析,最终构建HTTP响应并返回给客户端。
该项目采用CS模型实现一个轻量级的HTTP服务器,目的在于理解HTTP协议的处理过程。
涉及技术:
C/C++、HTTP协议、Socket编程、CGI、单例模式、互斥锁、条件变量、多线程、线程池等方面的技术。
二、前置知识
关于HTTP协议在博主之前的文章有过详细介绍:【网络编程】应用层协议——HTTP协议
2.1 URI、URL、URN
这里补充一些知识点:
- URI、URL、URN的定义
URI统一资源标识符:用来标识唯一资源。
URL统一资源定位符:用来定位唯一的资源。
URN统一资源名称:通过名字来标识资源。
URI就是保证资源的唯一性即可,而URL不仅要保证唯一性还要让我们能找到这个资源。
2.2 CGI
当我们进行网络请求的时候,也就两种情况
1️⃣ 从服务器获得资源
2️⃣ 提交数据给服务器
通常从服务器上获取资源对应的请求方法就是GET(通过URL传参)方法,而将数据上传至服务器对应的请求方法就是POST(通过正文传参)方法。
拿到数据只是第一步,还要对数据进行处理。如何处理数据呢?
用CGI模式处理数据。
CGI(通用网关接口)是一种重要的互联网技术,可以让一个客户端,从网页浏览器向执行在网络服务器上的程序请求数据。CGI描述了服务器和请求处理程序之间传输数据的一种标准。
2.2.1 CGI的概念
实际对数据的处理与HTTP的关系并不大,而是取决于上层具体的业务场景的,因此HTTP不对这些数据做处理。但HTTP提供了CGI机制,上层可以在服务器中部署若干个CGI程序,这些CGI程序可以用任何程语言编写,当HTTP获取到数据后会将其提交给对应CGI程序进行处理,然后再用CGI程序的处理结果构建HTTP响应返回给浏览器。
CGI也是一个运行程序,逻辑图如下:
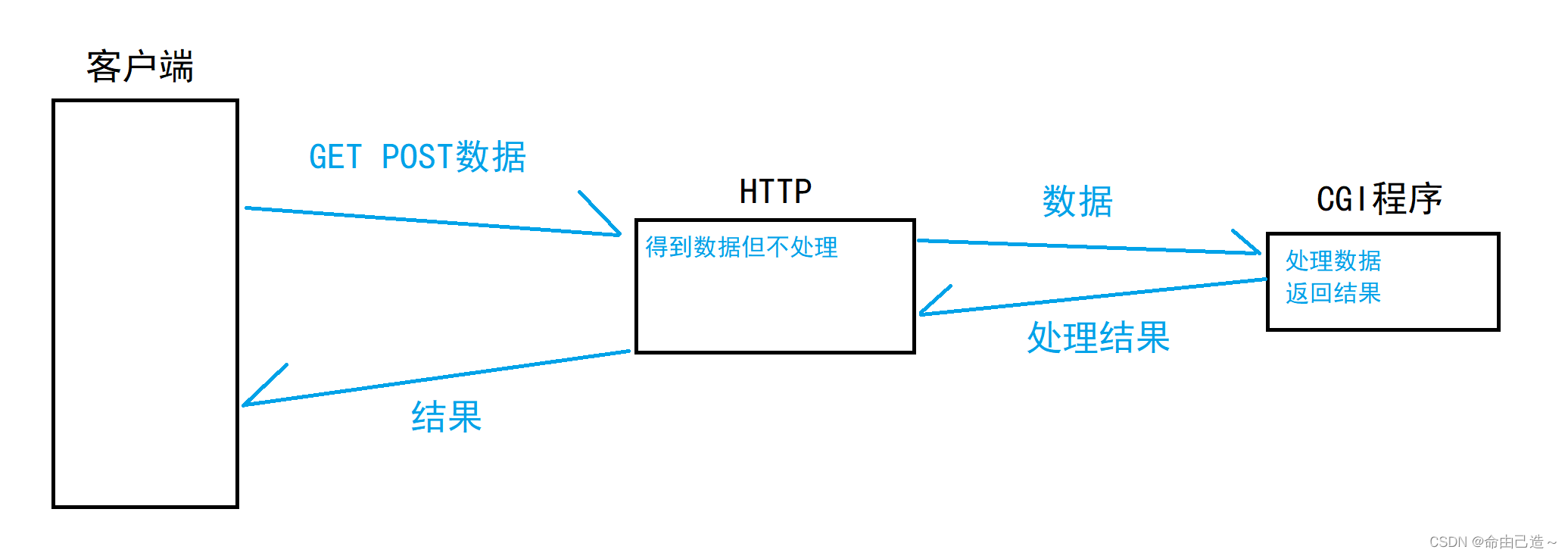
细节问题:
如何调用目标CGI程序、如何传递数据给CGI程序、如何拿到CGI程序的处理结果
- 什么时候需要使用CGI模式?
只要用户请求服务器时上传了数据,那么服务器就需要使用CGI模式对用户上传的数据进行处理。
而如果用户只是单纯的想请求服务器上的某个资源文件则不需要使用CGI模式,此时直接将用户请求的资源文件返回给用户即可。
此外,如果用户请求的是服务器上的一个可执行程序,说明用户想让服务器运行这个可执行程序,此时也需要使用CGI模式。
2.2.2 CGI模式的实现
想让一个程序执行另一个程序,显而易见要用到程序替换,但是如果直接进行程序替换的话,那么服务器的代码和数据就会被替换掉,所以第一步:
1️⃣ 创建子进程进行程序替换
接下来要思考的问题是CGI程序是为了帮我们处理数据的,那么CGI程序如何拿到数据呢?因为这里的服务器进程和CGI进程是父子进程,因此优先选择使用匿名管道。
但匿名管道只能单向通信,这里是要相互传输数据,所以我们可以用两个匿名管道。
2️⃣ 创建两个匿名管道完成数据传输
父子进程都是各自用两个变量来记录管道对应读写端的文件描述符的,但是对于子进程来说,当子进程执行exec程序替换后,记录的文件描述符就会丢失(程序替换会替换代码和数据)。
子进程进行进程程序替换后,底层创建的两个匿名管道仍然存在,只不过被替换后的CGI程序不知道这两个管道对应的文件描述符罢了。
解决办法:
被替换后的CGI程序,从标准输入读取数据等价于从管道读取数据,向标准输出写入数据等价于向管道写入数据。
要实现这种操作就要在子进程被替换之前进行重定向。
3️⃣ 重定向操作
现在把通信信道建立好后,就要进行数据交付了。
首先要知道父进程的数据在哪?
因为有两种请求方法,GET和POST,所以参数可能会在url中,也可能会在正文部分。所以要分两种情况讨论。
如果请求方法为GET方法,那么用户是通过URL传递参数的,一般参数长度比较短,通过管道读取效率较低,此时可以在子进程进行进程程序替换之前,通过putenv函数将参数导入环境变量,由于环境变量也不受进程程序替换的影响,因此被替换后的CGI程序就可以通过getenv函数来获取对应的参数。
如果请求方法为POST方法,那么用户是通过请求正文传参的,此时父进程直接将请求正文中的数据写入管道传递给CGI程序即可,但是为了让CGI程序知道应该从管道读取多少个参数,父进程还需要通过putenv函数将请求正文的长度导入环境变量。
但是子进程如何知道自己是从管道读取数据还是从环境变量中读取呢?
子进程也得知道请求方法。方法就是通过环境变量。
总结以下:
使用CGI模式时如果请求方法为POST方法,那么CGI程序需要从管道读取父进程传递过来的数据,如果请求方法为GET方法,那么CGI程序需要从环境变量中获取父进程传递过来的数据。
在子进程在进行进程程序替换之前,还需要通过putenv函数将本次HTTP请求所对应的请求方法也导入环境变量
这整个流程就是第四步:
4️⃣ 父子进程交付数据
2.2.3 CGI的意义
CGI机制就是让服务器将获取到的数据交给对应的CGI程序进行处理,然后将CGI程序的处理结果返回给客户端。
CGI机制使得浏览器输入的数据最终交给了CGI程序,而CGI程序输出的结果最终交给了浏览器。这也就意味着CGI程序的开发者,可以完全忽略中间服务器的处理逻辑。
相当于CGI程序从标准输入就能读取到浏览器输入的内容,CGI程序写入标准输出的数据最终就能输出到浏览器。中间的通信细节全部是由HTTP完成的,CGI并不关注。
三、项目设计
3.1 日志的编写
在服务器的运行过程中我们想要看到服务器产生的一些事件,就可以使用日志。
期望看到的结果如下:
[日志等级][时间][信息][错误文件][行数]
说明:
日志等级分成四个:
#define NORMAL 0// 正常
#define WARNING 1// 警告
#define ERROR 2// 错误
#define FATAL 3// 致命错误
时间:打印当前时间。
信息: 事件产生的日志信息。
错误文件:事件在哪一个文件产生。
行数: 事件在对应文件的哪一行产生。
源码:
#define NORMAL 0// 正常
#define WARNING 1// 警告
#define ERROR 2// 错误
#define FATAL 3// 致命错误#define LOG_NOR "log.txt"
#define LOG_ERR "log.error"const char* to_string_level(int level)
{switch(level){case NORMAL: return "NORMAL";case WARNING: return "WARNING";case ERROR: return "ERROR";case FATAL: return "FATAL";default : return nullptr;}
}#define LOG(level, format) logMessage(level, __FILE__, __LINE__, format)void logMessage(int level, std::string file_name, int line, std::string format)
{// [日志等级][时间][信息][错误文件][行数]char logprefix[1024];time_t now;time(&now);struct tm *ptm = localtime(&now);char timebuf[1024];snprintf(timebuf, sizeof timebuf, "%d年%d月%d日 %d:%d:%d", ptm->tm_year + 1900, ptm->tm_mon + 1, ptm->tm_mday, ptm->tm_hour, ptm->tm_min, ptm->tm_sec);snprintf(logprefix, sizeof logprefix, "[%s][%s]", to_string_level(level), timebuf);std::cout << logprefix << "[" << format << "]" << "[" << file_name << "]" << "[" << line << "]" << std::endl;
}
3.2 套接字编写
服务器绑定端口就够了,不需要显示绑定IP,直接将IP地址设置为INADDR_ANY即可,它的意思就是随机绑定本主机的ip地址,这里不能绑定公网IP和私网IP,如果在云服务器上绑定了公网IP,因为这是云服务器厂商虚拟出来的IP,无法通信。
因为服务器全局唯一,所以可以设置为单例模式。
#define BACKLOG 5 // 等待队列的最大长度class TCPServer
{
public:// 获取单例对象static TCPServer* GetSingle(int port){// 静态锁,不用调用init初始化和销毁锁static pthread_mutex_t Lock = PTHREAD_MUTEX_INITIALIZER;if(_TCPSingle == nullptr){pthread_mutex_lock(&Lock);if(_TCPSingle == nullptr){_TCPSingle = new TCPServer(port);_TCPSingle->InitServer();// 初始化服务器}pthread_mutex_unlock(&Lock);}return _TCPSingle;}void InitServer(){// 1.创建套接字// 2.绑定// 3.设置监听状态Socket();Bind();Listen();LOG(NORMAL, "Init Server Success");}// 创建套接字void Socket(){_listensock = socket(AF_INET/*网络通信*/, SOCK_STREAM/*流式套接字*/, 0/*协议*/);if(_listensock < 0){ LOG(FATAL, "Socket Error!");exit(1);}// 设置端口复用int opt = 1;setsockopt(_listensock, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof opt);LOG(NORMAL, "Creat Socket Success");}// 方便上层获得监听套接字int sock(){return _listensock;}// 绑定void Bind(){struct sockaddr_in local;// 初始化结构体bzero(&local, sizeof local);local.sin_family = AF_INET;local.sin_port = htons(_port);local.sin_addr.s_addr = INADDR_ANY;// 随机绑定IPif(bind(_listensock, (struct sockaddr*)&local, sizeof local) < 0){// 绑定失败LOG(FATAL, "Bind Socket Error!");exit(2);}LOG(NORMAL, "Bind Socket Success");}// 监听void Listen(){if(listen(_listensock, BACKLOG) < 0){// 监听失败LOG(FATAL, "Listen Socket Error!");exit(3); }LOG(NORMAL, "Listen Socket Success");}~TCPServer(){if(_listensock >= 0)close(_listensock);}
private:// 私有构造+防拷贝TCPServer(int port): _port(port), _listensock(-1){}TCPServer(const TCPServer&)=delete;TCPServer* operator=(const TCPServer&)=delete;
private:int _port;// 端口号int _listensock;// 监听套接字static TCPServer* _TCPSingle;// 单例对象
};TCPServer* TCPServer::_TCPSingle = nullptr;
3.3 HTTP服务器实现
在套接字编写中,完成了创建套接字、绑定端口、设置监听状态的工作,接下来就是要获取新连接。
#define PORT 8080class HTTPServer
{
public:HTTPServer(int port = PORT): _port(port){}void InitServer(){tcp_server = TCPServer::GetSingle(_port);}// 启动服务器void Start(){LOG(NORMAL, "HTTP Start");// 监听套接字int listen_sock = tcp_server->sock();while(true){struct sockaddr_in peer;socklen_t len = sizeof(peer);// 获取新连接 int sock = accept(listen_sock, (struct sockaddr*)&peer, &len);if(sock < 0){continue; //获取失败,继续获取}LOG(NORMAL, "Accept Link Success");int* _sock = new int(sock);pthread_t tid;pthread_create(&tid, nullptr,Enter::Handler, _sock);pthread_detach(tid);// 线程分离}}~HTTPServer(){}
private:int _port;TCPServer* tcp_server = nullptr;
};
说一下为什么要int* _sock = new int(sock);
因为传递给了线程后可能会发生修改。
- 线程函数
class Enter
{
public:static void *Handler(void* sock){LOG(NORMAL, "Handler Request Begin");int _sock = *(int*)sock;delete (int*)sock; EndPoint *ep = new EndPoint(_sock);ep->RecvHTTPRequest();ep->BuildHTTPResponse();ep->SendHTTPResponse();delete ep;LOG(NORMAL, "Handler Request End");return nullptr;}
};
这里的EndPoint类下面讲解。
3.4 HTTP请求与响应结构
- HTTP请求类
//HTTP请求
class Request
{
public://HTTP请求内容std::string req_line;// 请求行std::vector<std::string> req_header;// 请求报头std::string req_blank;// 空行std::string req_body;// 请求正文// 请求行解析完之后的数据std::string method;// 请求方法std::string uri;// 请求资源std::string version;// 版本号std::unordered_map<std::string, std::string> header_kv;int content_length = 0;// uri: path?argsstd::string path;// 路径std::string args;// 参数std::string suffix;// 文件后缀int fd_size = 0;// 资源文件的大小bool cgi = false;// 是否使用CGI模式
};
收到了请求后把数据放入成员变量中(请求行、请求报头、空行、请求正文),因为请求行包含了三个字段,所以还要添加三个成员变量来存请求方法和请求资源和版本号。为了后边分析请求报头中的数据,所以用了
header_kv结构存储。下面几个成员变量主要是为了获取请求资源的相关信息以及是否使用cgi模式。
- HTTP响应类
//HTTP响应
class Response
{
public://HTTP响应内容std::string status_line;// 状态行std::vector<std::string> resp_header;// 响应报头std::string resp_blank = LINE_SEP;// 空行std::string resp_body;// 响应正文int status_code = OK;// 状态码int fd = -1;// 响应文件的fd
};
这里讲一下fd:非CGI正文在fd中保存、CGI在_resp.body中保存。
3.5 EndPoint类的实现
3.5.1 EndPoint的基本逻辑
EndPoint这个词经常用来描述进程间通信,比如在客户端和服务器通信时,客户端是一个EndPoint,服务器则是另一个EndPoint,因此这里将处理请求的类取名为EndPoint,主要作用:读取分析请求、构建响应、IO通信。
基本结构:
//读取分析请求、构建响应、IO通信
class EndPoint
{
public:EndPoint(int sock): _sock(sock){}// 读取请求void RecvHTTPRequest(){}// 构建响应void BuildHTTPResponse(){}// 发送响应void SendHTTPResponse(){}~EndPoint(){close(_sock);}
private:int _sock;Request _req;Response _resp;
};
可以看到处理的流程是:
1️⃣ 读取请求
2️⃣ 构建响应
3️⃣ 发送响应
3.5.2 读取请求
读取HTTP请求的同时可以对HTTP请求进行解析,这里分为五个步骤,分别是读取请求行、读取请求报头和空行、解析请求行、解析请求报头、读取请求正文。
// 读取请求
void RecvHTTPRequest()
{// 读取请求行 + 请求报头RecvHTTpRequestLine();RecvHTTpRequestHeader();// 解析请求行 + 请求报头PraseHTTPRequestLine();PraseHTTPRequestHeader();// 读取请求正文RecvHTTPRequsetBody();
}
- 读取请求行
这里首先要知道请求行的结尾方式有三种:
\r、\n、\r\n。
由此得知不能直接按行读,需要自定义方法读取:
我们可以写一个Util工具类进行方法ReadLine的编写
这个函数采取的方法:
按照一个字符一个字符的读取。
如果读取到的字符是\n,则说明行分隔符是\n,此时将\npush到自定义的缓冲区后停止读取。
如果读取到的字符是\r,则需要继续窥探下一个字符是否是\n,不管后边是不是\n,都将\npush到自定义的缓冲区后停止读取。
// 按行读取
static int ReadLine(int sock, std::string& out)
{char ch;do{// 一次读一个字符ssize_t n = recv(sock, &ch, 1, 0);if(n > 0){// 读取成功if(ch == '\r'){// '\r' || "\r\n"// 窥探,只看不取recv(sock, &ch, 1, MSG_PEEK);if(ch == '\n'){// 把"\r\n"中的'\r'覆盖掉recv(sock, &ch, 1, 0);}else {// '\r' -> '\n'ch = '\n';}}out.push_back(ch);}else if(n == 0){// 对端关闭return 0;}else {// 读取错误return -1;}}while(ch != '\n');return out.size();
}
说明一下: recv函数的最后一个参数MSG_PEEK:recv函数将返回TCP接收缓冲区头部指定字节个数的数据,但是并不把这些数据从TCP接收缓冲区中取走,这个叫做数据的窥探功能。
- 读取请求报头和空行
这里也是按照一行行的读取,刚好使用ReadLine函数:
//读取请求报头和空行
bool RecvHTTpRequestHeader()
{std::string line;// 读取报头while(true){line.clear();Util::ReadLine(_sock, line);if(line == "\n"){// 读取空行_req.req_blank= line;break;}line.resize(line.size() - 1);_req.req_header.push_back(line);LOG(NORMAL, line);}
}
- 解析请求行
这个步骤要做的是将请求行中的请求方法、URI和HTTP版本号拆分出来,并且为了兼容大小写,我们把请求方法全部转换成大写:
// 解析请求行
void PraseHTTPRequestLine()
{std::string& line = _req.req_line;std::stringstream ss(line);ss >> _req.method >> _req.uri >> _req.version;// 请求方法全部转大写字母std::transform(_req.method.begin(), _req.method.end(), _req.method.begin(), ::toupper);
}
- 解析请求报头
因为请求报头是name: val的结构,所以要把每一行的kv键值对放入header_kv中,以便后续通过属性名获取到对应的值。
至于这里的切分也可以在Util工具类中封装切割的方法:
// 分割字符串
static bool CutString(const std::string& body, std::string& sub1, std::string& sub2, const std::string& sep)
{size_t pos = body.find(sep);if(pos == std::string::npos){return false;}sub1 = body.substr(0, pos);sub2 = body.substr(pos + sep.size());return true;
}
// 解析请求报头
void PraseHTTPRequestHeader()
{std::string key;std::string val;for(auto& e : _req.req_header){if(Util::CutString(e, key, val, ": ")){_req.header_kv.insert({key, val});}}
}
- 读取请求正文
这里要分析是否有正文,因为只有POST方法可能会有请求正文。
如果请求方法为POST,我们还需要通过请求报头中的Content-Length属性来得知请求正文的长度。 以便读取正文。
// 是否需要读取正文
bool IsNeedRecvHTTPRequsetBody()
{// 通过method判断是否有正文if(_req.method == "POST"){// 有正文auto it = _req.header_kv.find("Content-Length");if(it != _req.header_kv.end()){LOG(NORMAL, "POST Method, Content-Length: " + it->second);_req.content_length = atoi(it->second.c_str());return true;}}return false;
}// 读取正文
void RecvHTTPRequsetBody()
{if(IsNeedRecvHTTPRequsetBody()){int len = _req.content_length;char ch;while(len--){ssize_t n = recv(_sock, &ch, 1, 0);if(n > 0){_req.req_body += ch;}else break;}}LOG(NORMAL, _req.req_body);
}
3.5.3 构建响应
上面把请求全部收到后,首先要处理请求,但是处理请求的过程可能会出错,不管是什么类型的错误客户端都希望能够收到反馈,根据不同的状态码构建响应,所以定义了如下的状态码:
// 状态码
#define OK 200
#define BAD_REQUEST 400// 请求方法不正确
#define NOT_FOUND 404// 请求资源不存在
#define SERVER_ERROR 500// 服务器错误
首先要做的就是解析收到的请求:
1️⃣ 先判断方法,方法出错就把状态码置为
BAD_REQUEST然后直接构建响应。
如果是GET方法,有两种情况,一种是URI携带参数,一种是不携带参数,用非CGI处理请求。携带了参数就要把请求路径和参数都提取出来,并用CGI模式处理参数。没有携带参数就只用把请求路径提取出来即可。
如果是POST方法,先要看是否有正文,如果没有正文,说明没有参数,用非CGI处理请求。如果有正文说明有参数就使用CGI模式处理。
2️⃣ 接下来分析客户端的请求路径,首先要在请求的路径前拼接WEB根目录,也就是我们自己定义的根目录,判断路径的结尾是不是/,如果是/说明是个目录,不可能把整个目录都返回,所以每个目录离都要添加一个默认资源index.html。
而客户端请求的资源有可能是一个可执行程序,怎么判断呢?
通过stat函数获取客户端请求资源文件的属性信息,如果资源类型是一个可执行程序,则说明后续处理需要使用CGI模式。
当然我们也需要知道请求的资源是什么类型,以便构建响应返回。
我们可以通过请求资源的后缀来判断是什么类型。
然后再写一个通过后缀获得资源类型的函数,后边填写Content-Type的时候会用到。
// 根据后缀提取资源类型
static std::string SuffixToDesc(const std::string& suffix)
{static std::unordered_map<std::string, std::string> suffix_to_desc = {{".html", "text/html"},{".css", "text/css"},{".js", "application/x-javascript"},{".jpg", "application/x-jpg"},{".xml", "text/xml"}};auto it = suffix_to_desc.find(suffix);if(it != suffix_to_desc.end()){return it->second;}return "text/html"; //所给后缀未找到则默认该资源为html文件
}
构建响应流程:
// 构建响应
void BuildHTTPResponse()
{// 验证合法性struct stat st;int size = 0;// 资源大小size_t suf_pos = 0;// 找后缀if(_req.method != "GET" && _req.method != "POST"){LOG(WARNING, "Method Error!");_resp.status_code = BAD_REQUEST;goto END;}if(_req.method == "GET"){auto pos = _req.uri.find("?");if(pos != std::string::npos){// uri携带了参数Util::CutString(_req.uri, _req.path, _req.args, "?"); _req.cgi = true;}else{// uri没有携带参数_req.path = _req.uri;}}else if(_req.method == "POST"){// CGI处理数据_req.cgi = true;_req.path = _req.uri;// 无参数就不走CGIif(_req.content_length == 0){_req.cgi = false;}}else{// do nothing}// 添加根目录_req.path = WEB_ROOT + _req.path;if(_req.path[_req.path.size() - 1] == '/'){// 添加首页信息_req.path += HOME_PAGE;}// 判断路径是否存在if(stat(_req.path.c_str(), &st) == 0){// 资源存在if(S_ISDIR(st.st_mode)){// 请求的是一个目录_req.path += "/";_req.path += HOME_PAGE;// 重新获取属性stat(_req.path.c_str(), &st);}// 拥有者、所属组、其他 是否有可执行权限if( (st.st_mode & S_IXUSR) || (st.st_mode & S_IXGRP) || (st.st_mode & S_IXOTH) ){// 可执行程序_req.cgi = true;}_req.fd_size = st.st_size;}else{std::string msg = _req.path;msg += " Not Find";LOG(WARNING, msg);_resp.status_code = NOT_FOUND;goto END;}// 提取后缀以便确认资源类型suf_pos = _req.path.rfind(".");if(suf_pos == std::string::npos){// 没找到到,设置默认_req.suffix = ".html";}else{_req.suffix = _req.path.substr(suf_pos);}if(_req.cgi == true){// 要用CGI处理请求_resp.status_code = ProcessCGI();}else{// 非CGI方式处理请求// 返回静态网页 + HTTP响应_resp.status_code = ProcessNoCGI();}
END:// 根据状态码构建响应BuildHTTPResponseHelper();
}
说明:
stat是一个系统调用函数,它可以获取指定文件的属性信息,包括文件的inode编号、文件的权限、文件的大小等。如果调用stat函数获取文件的属性信息失败,则可以认为客户端请求的这个资源文件不存在,此时直接设置状态码为NOT_FOUND后停止处理即可。
判断是否是可执行文件:只要一个文件的拥有者、所属组、other其中一个具有可执行权限,则说明这是一个可执行文件。
3.5.3.1 CGI处理
在上面讲过CGI处理的流程,这里讲一下细节问题。
因为用CGI模式就说明有参数,参数就需要传递,结果就需要返回,这样就需要两个管道。
站在父进程角度对这两个管道进行命名,父进程用于读取数据的管道叫做input,父进程用于写入数据的管道叫做output。

但是后边要执行程序替换,我们保存的指向input和output文件描述符会丢失,因为程序替换会替换所有的代码和数据,当时管道还是存在的,为了让子进程也获得这两个文件描述符,我们可以把这两个文件描述符重定向到标准输入和标准输出。
那么子进程往标准输出写就是相当于写给了input管道。
此外,在子进程进行程序替换之前,还需要进行各种参数的传递:
首先需要将请求方法通过putenv函数导入环境变量,以供CGI程序判断应该以哪种方式读取父进程传递过来的参数。
如果请求方法为GET方法,则需要将URL中携带的参数通过导入环境变量的方式传递给CGI程序。
如果请求方法为POST方法,则需要将请求正文的长度通过导入环境变量的方式传递给CGI程序,以供CGI程序判断应该从管道读取多少个参数。
至此,如果是GET方法时参数就已经传递过去了,POST方法只知道了要传递参数的字节数。
1️⃣ 所以父进程就负责往管道中写入POST方法传递的参数。
2️⃣ 接下来就是获得子进程程序替换成CGI处理的结果:不断调用read函数,从管道中读取CGI程序写入的处理结果。
int ProcessCGI()
{LOG(NORMAL, "Process cgi method");int code = OK;// 可执行程序在path中auto& bin = _req.path;// 把方法导入环境变量std::string method_env;// 创建两个管道int input[2];int output[2];if(pipe(input) < 0){LOG(ERROR, "Pipe Input Error!");code = SERVER_ERROR;return code;}if(pipe(output) < 0){LOG(ERROR, "Pipe Output Error!");code = SERVER_ERROR;return code;}pid_t id = fork();if(id == 0){// 子进程close(input[0]);close(output[1]);// 通过环境变量传递请求方法method_env = "METHOD=";method_env += _req.method;std::cout << "Method_env: " << method_env << std::endl;putenv((char*)method_env.c_str());if(_req.method == "GET"){// kv模型// 把参数导入环境变量std::string query_string_env = "QUERY_STRING=";query_string_env += _req.args;// 导入环境变量putenv((char*)query_string_env.c_str());LOG(NORMAL, "Get Method, Add QUERY_STRING");}else if(_req.method == "POST"){// 把数据大小导入环境变量std::string content_length_env = "CONTENT_LENGTH="; content_length_env += std::to_string(_req.content_length);putenv((char*)content_length_env.c_str());LOG(NORMAL, "POST Method, Add CONTENT_LENGTH");}else{// Do Nothing}std::cout << "bin: " << bin << std::endl;// 重定向dup2(output[0], 0);dup2(input[1], 1);// 进行程序替换execl(bin.c_str(), bin.c_str(), nullptr);exit(1);}else if(id < 0){LOG(ERROR, "Fork Error!");return NOT_FOUND;}else{// 父进程close(input[1]);close(output[0]);if(_req.method == "POST"){// 可能管道不够大,多次写入const char* start = _req.req_body.c_str();int total = 0;int size = 0;while(total < _req.content_length && (size = write(output[1], start + total, _req.req_body.size() - total)) > 0){total += size;}}char ch;while(read(input[0], &ch, 1) > 0){_resp.resp_body.push_back(ch);}int status;// 获取退出码pid_t ret = waitpid(id, &status, 0);if(ret == id){if(WIFEXITED(status))// 进程退出是正常的{if(WEXITSTATUS(status) == 0){code = OK;}else{code = BAD_REQUEST;}}else{// 进程不正常退出code = SERVER_ERROR;}}// 结束后关闭文件描述符close(input[0]);close(output[1]);}return code;
}
说明一下:
WIFEXITED可以获取子进程是否是正常退出,根据status的值填写不同的退出码,以便后续构建响应。
3.5.3.2 非CGI处理
其实非CGI处理的过程非常简单,因为没有参数,所以请求的一定是一个静态网页,所以我们只需要返回资源+构建响应即可。构建响应是最后通过状态码来构建,这里只需要考虑如何返回我们的静态网页。
如果按照正常的方法,就是打开我们的文件,然后读取内容拷贝到_resp.body中,然后构建响应发送出去,但是有一个方法可以不用将数据拷贝到_resp.body(不用进入用户级缓冲区),而是直接在内核区完成拷贝,由内核直接发送到对端。
使用
sendfile函数该函数的功能就是将数据从一个文件描述符拷贝到另一个文件描述符,并且这个拷贝操作是在内核中完成的。
但是一旦sendfile之后文件就发出去了,所以我们应该在构建响应之后再调用sendfile。那么我们现在的工作就只用将要发送的目标文件打开即可,将打开文件对应的文件描述符保存到HTTP响应的fd当中。
// 返回静态网页 + 响应
int ProcessNoCGI()
{_resp.fd = open(_req.path.c_str(), O_RDONLY);// 只读if(_resp.fd >= 0){return OK;} return NOT_FOUND;
}
上面已经把数据处理好并且得到了结果,接下来就是根据状态码来构建响应。
不管状态码是正确都要先填写状态行,至于响应报头要分情况:
1️⃣ 如果状态码出错,那么一定返回的是一个静态网页,那么所有的错误状态码都可以用一个函数封装来填写报头。
2️⃣ 对于正确的情况则还需要分析正文的类型,因为可能是CGI处理的或者非CGI,而非CGI正文在fd中保存、CGI在_resp.body中保存、所以要分情况填写报头。
// 对于错误直接返回的是页面
void HandlerError(const std::string& page)
{_req.cgi = false;// 保证最后发送的是网页_resp.fd = open(page.c_str(), O_RDONLY);if(_resp.fd > 0){// 填写报头// 获取属性struct stat st;stat(page.c_str(), &st);_req.fd_size = st.st_size;std::string line = "Content-Type: text/html";line += LINE_SEP;_resp.resp_header.push_back(line);line = "Content-Length: ";line += std::to_string(st.st_size);line += LINE_SEP;_resp.resp_header.push_back(line);}
}// 构建OK的响应
void BuildOkResponse()
{std::string line = "Content-Type: ";line += SuffixToDesc(_req.suffix);line += LINE_SEP;_resp.resp_header.push_back(line);// 正文大小line = "Content-Length: ";if(_req.cgi){line += std::to_string(_resp.resp_body.size());}else{line += std::to_string(_req.fd_size);}line += LINE_SEP;_resp.resp_header.push_back(line);}// 根据状态码构建响应
void BuildHTTPResponseHelper()
{// 状态行_resp.status_line += HTTP_VERSION;_resp.status_line += " ";_resp.status_line += std::to_string(_resp.status_code);_resp.status_line += " ";_resp.status_line += CodeToDesc(_resp.status_code);_resp.status_line += LINE_SEP;// 响应报头std::string path = WEB_ROOT;// 路径path += "/";switch(_resp.status_code){case OK:BuildOkResponse();break;case NOT_FOUND:path += PAGE_400;HandlerError(path);// 返回400页面break;case BAD_REQUEST:path += PAGE_404;HandlerError(path);// 返回404页面break;case SERVER_ERROR:path += PAGE_500;HandlerError(path);// 返回500页面break;default:break;}
}
至于正文就在发送响应的时候进行发送,因为对于非CGI要用sendfile函数。
3.5.4 发送响应
发送流程:
1️⃣ 发送状态行、响应报头和空行。
2️⃣ 关于正文部分就需要看是什么处理方式了。因为非CGI正文在fd中保存、CGI在_resp.body中保存。
如果是CGI方式,直接把数据发送给对端即可。
如果是非CGI方式处理或在处理过程中出错的,它们返回的都是静态网页+响应,那么待发送的资源文件或错误页面文件对应的文件描述符是保存在HTTP响应类的fd中的,此时调用sendfile进行发送即可。
// 发送响应
void SendHTTPResponse()
{// 发送状态行send(_sock, _resp.status_line.c_str(), _resp.status_line.size(), 0);// 发送响应报头for(auto& it : _resp.resp_header){send(_sock, it.c_str(), it.size(), 0);}// 发送空行send(_sock, _resp.resp_blank.c_str(), _resp.resp_blank.size(), 0);// 非CGI正文在fd中保存、CGI在_resp.body中保存// 发送正文if(_req.cgi){size_t size = 0;size_t total = 0;const char* start = _resp.resp_body.c_str();// 起始while( total < _resp.resp_body.size() && (size = send(_sock, start + total, _resp.resp_body.size() - total, 0)) > 0 ){total += size;}}else{sendfile(_sock, _resp.fd, nullptr, _req.fd_size);close(_resp.fd);}
}
3.6 错误处理
3.6.1 处理逻辑错误
逻辑错误指的是请求已经被读完成了,但是发现有一些逻辑错误比如说请求的方法不对。对于这种类型的错误我们是要返回给客户端响应的。
3.6.2 处理读取错误
在读取请求的过程中出现的错误就叫做读取错误,比如调用recv读取请求时出错或读取请求时对方连接关闭等。
这就意味这服务器根本就没有读取一个完整的请求,那么就不需要返回响应了,更不需要对数据进行分析,直接停止处理即可。
处理方式:
在EndPoint类中新增
_stop成员变量,表示是否停止本次处理。
在所有读取请求的地方判断是否读取成功:
//本次处理是否停止
bool Stop()
{return _stop;
}// 读取请求
void RecvHTTPRequest()
{// 读取请求行 + 请求报头if(!RecvHTTpRequestLine() && !RecvHTTpRequestHeader())// 都没出错{// 解析请求行 + 请求报头PraseHTTPRequestLine();PraseHTTPRequestHeader();// 读取请求正文RecvHTTPRequsetBody();}
}//读取请求行
bool RecvHTTpRequestLine()
{if(Util::ReadLine(_sock, _req.req_line) > 0){_req.req_line.resize(_req.req_line.size() - 1);LOG(NORMAL, _req.req_line);}else{_stop = true;}return _stop;
}// 读取请求报头和空行
bool RecvHTTpRequestHeader()
{std::string line;// 读取报头while(true){line.clear();if(Util::ReadLine(_sock, line) <= 0){_stop = true;break;}if(line == "\n"){// 读取空行_req.req_blank= line;break;}line.resize(line.size() - 1);_req.req_header.push_back(line);LOG(NORMAL, line);}return _stop;
}
3.6.3 处理写入错误
当构建好响应要返回给客户端的时候,当数据正在发送的时候客户端把连接断开了,就出现了写入错误。
当对方把读文件描述符关闭时,我们还在写入的话就会收到一个信号SIGNALPIPE,那么服务端就会直接退出。
我们就可以在初始化服务器的时候忽略掉这个信号。
//HTTP服务器
class HTTPServer
{
public://初始化服务器void InitServer(){signal(SIGPIPE, SIG_IGN); // 忽略掉SIGNAL信号}
private:int _port; //端口号
};
3.7 引入线程池
目前我们的服务器是当获取一个新连接就创建一个套接字,然后把套接字传递给线程让线程来处理,处理完后就把连接断开,把线程销毁,总的来说就是短连接的方式。
为了提高效率。可以引入线程池:
关于线程池在博主之前的文章就有过介绍:【linux】基于单例模式实现线程池
在服务器端预先创建一批线程和一个任务队列,每当获取到一个新连接时就将其封装成一个任务对象放到任务队列当中。
线程池中的若干线程就不断从任务队列中获取任务进行处理,如果任务队列当中没有任务则线程进入休眠状态,当有新任务时再唤醒线程进行任务处理。
那么首先第一步就是封装任务类:
当服务器获取到一个新连接后,需要将其封装成一个任务对象放到任务队列当中。任务类中首先需要有一个套接字,此外还需要有一个回调函数,当线程池中的线程获取到任务后就可以调用这个回调函数进行任务处理。
// 任务类
class Task
{
public:Task(){}Task(int sock):_sock(sock){}//处理任务void ProcessOn(){_handler(_sock); //调用回调}~Task(){}private:int _sock;// 套接字CallBack _handler;// 回调函数
};
接下来就是处理这里的回调函数,其实回调函数我们之前就写好了,就是之前的线程执行的函数,我们提供一个仿函数来调用即可。
class CallBack
{
public:CallBack(){}~CallBack(){}void operator()(int sock){Handler(sock);}void Handler(int sock){LOG(NORMAL, "Handler Request Begin"); EndPoint *ep = new EndPoint(sock);ep->RecvHTTPRequest();if(!ep->Stop()){LOG(NORMAL, "Recv Success");ep->BuildHTTPResponse();ep->SendHTTPResponse();}else{LOG(WARNING, "Recv Error");}delete ep;}
};
- 线程池编写
#define NUM 6class ThreadPool
{
public:// 获取单例static ThreadPool* GetSingle(){static pthread_mutex_t _mtx = PTHREAD_MUTEX_INITIALIZER;if(_single == nullptr){pthread_mutex_lock(&_mtx);if(_single == nullptr){_single = new ThreadPool();_single->InitThreadPool();}pthread_mutex_unlock(&_mtx);}return _single;}~ThreadPool(){pthread_mutex_destroy(&_lock);pthread_cond_destroy(&_cond);}// 让线程在条件变量下进行等待void ThreadWait(){pthread_cond_wait(&_cond, &_lock);}// 让线程在条件变量下进行唤醒void ThreadWakeUp(){pthread_cond_signal(&_cond);}// 加锁void Lock(){pthread_mutex_lock(&_lock);}// 解锁void unLock(){pthread_mutex_unlock(&_lock);}bool TaskQueueIsEmpty(){return _task_q.empty();}// 线程执行函数static void* ThreadRoutine(void* args){ThreadPool* tp = (ThreadPool*)args;while(true){Task t;tp->Lock();while(tp->TaskQueueIsEmpty()){// 任务队列为空,线程休眠tp->ThreadWait();}tp->PopTask(t);// 获取任务tp->unLock();t.ProcessOn();// 处理任务}}// 初始化线程池bool InitThreadPool(){// 创建一批线程for(int i = 0; i < _num; i++){pthread_t id;if(0 != pthread_create(&id, nullptr, ThreadRoutine, this)){// 创建失败LOG(FATAL, "Create ThreadPool Error!");return false;} }LOG(NORMAL, "Create ThreadPool Success");return true;}// 推送任务void PushTask(const Task& task){Lock();_task_q.push(task);unLock();// 一旦有了任务就可以唤醒线程进行处理了ThreadWakeUp();}// 获取任务void PopTask(Task& task){task = _task_q.front();_task_q.pop();}
private:// 构造私有+防拷贝ThreadPool(int num = NUM): _num(num){// 初始化锁和条件变量pthread_mutex_init(&_lock, nullptr);pthread_cond_init(&_cond, nullptr);}ThreadPool(const ThreadPool&)=delete;ThreadPool& operator=(const ThreadPool&)=delete;
private:std::queue<Task> _task_q;// 任务队列int _num;// 线程数pthread_mutex_t _lock;// 锁pthread_cond_t _cond;// 条件变量static ThreadPool* _single;// 单例
};ThreadPool* ThreadPool::_single = nullptr;
当第一次获得单例对象时,线程池会创建出一批线程,但此时任务队列为空,所以会在条件变量下等待,一但服务器推送任务进入任务队列,就会随机唤醒一个线程。
四、项目测试
首先CGI要获得我们请求的参数:
// 获得参数
bool GetQueryString(std::string& query_string)
{std::string method = getenv("METHOD");if(method == "GET"){query_string = getenv("QUERY_STRING");return true;}else if(method == "POST"){// 通过环境变量得知该从标准输入读取多少字节std::cerr << "Content-Length: " << getenv("CONTENT_LENGTH") << std::endl;int content_length = atoi(getenv("CONTENT_LENGTH"));char ch;while(content_length--){read(0, &ch, 1);query_string.push_back(ch);}return true;}else{return false;}
}
先通过环境变量获取请求方法。
如果请求方法为GET方法,则继续通过环境变量获取父进程传递过来的数据。
如果请求方法为POST方法,则先通过环境变量获取父进程传递过来的数据的长度,然后再标准输入中读取指定长度的数据即可。
CGI获取到了数据后就可以对数据进行处理,这里我们可以进行加减乘除操作:
// 分割字符串
static void CutString(const std::string& body, std::string& sub1, std::string& sub2, const std::string& sep)
{size_t pos = body.find(sep);if(pos != std::string::npos){sub1 = body.substr(0, pos);sub2 = body.substr(pos + sep.size());}
}int main()
{std::string query_string;GetQueryString(query_string);std::cerr << "query_string: " << query_string << std::endl;// x=10&y=20//切分std::string left;std::string right;CutString(query_string, left, right, "&");std::cerr << "left: " << left << std::endl;std::cerr << "right: " << right << std::endl;std::string name1, val1;std::string name2, val2;CutString(left, name1, val1, "=");CutString(right, name2, val2, "=");//处理数据int x = atoi(val1.c_str());int y = atoi(val2.c_str());std::cout << "<html>";std::cout << "<head><meta charset=\"UTF-8\"></head>";std::cout << "<body>";std::cout << "<h3>" << x << "+" << y << "=" << x+y << "</h3>";std::cout << "<h3>" << x << "-" << y << "=" << x-y << "</h3>";std::cout << "<h3>" << x << "*" << y << "=" << x*y << "</h3>";std::cout << "<h3>" << x << "/" << y << "=" << x/y << "</h3>"; //除0后子进程返回错误状态码std::cout << "</body>";std::cout << "</html>";return 0;
}
4.1 GET方法上传数据测试
我们可以在w3School网站复制一个表单:
HTML中的表单用于搜集用户的输入,我们可以通过设置表单的method属性来指定表单提交的方法,通过设置表单的action属性来指定表单需要提交给服务器上的哪一个CGI程序。
<html>
<body><head><meta charset="UTF-8" /></head><form action="/test_cgi" method="GET">
x: <input type="text" name="data_x" value="0">
<br>
y: <input type="text" name="data_y" value="0">
<br><br>
<input type="submit" value="提交">
</form> <p>点击提交,表单数据发送给CGI</p></body>
</html>
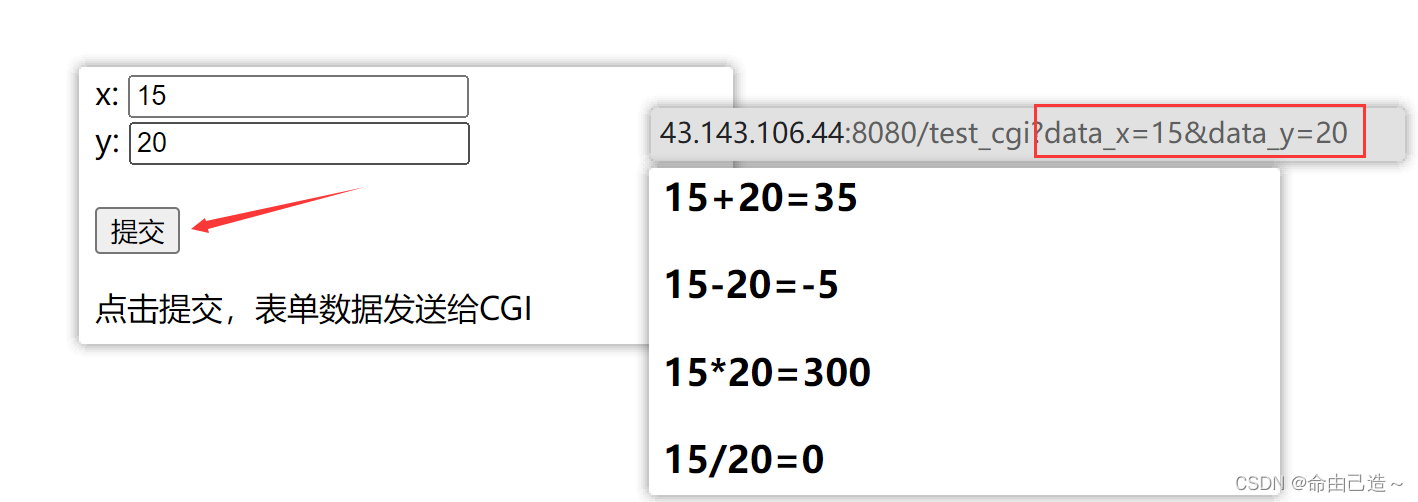
这样我们在请求的时候点击提交就可以把参数提交给我们自己写的CGI程序中。
- 为什么GET方法提交参数会有大小限制?
因为GET方法传递参数给子进程是通过环境变量传递的,所以注定了参数不能过长。
4.2 POST方法上传数据测试
测试表单通过POST方法上传数据时,只需要将表单中的method属性改为“post”即可。
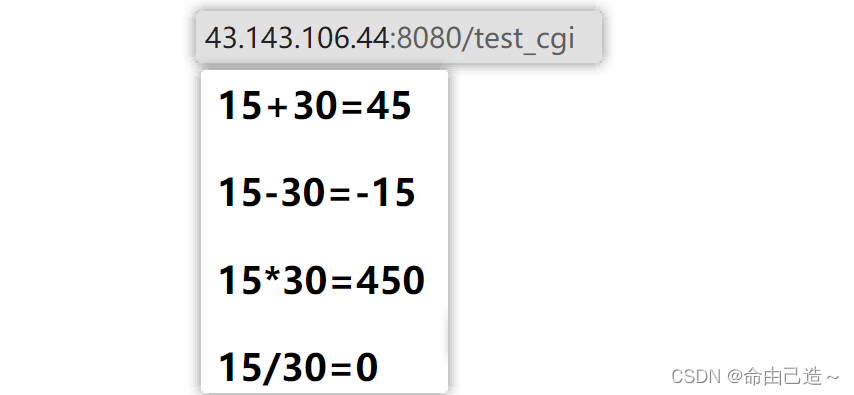

可以看到参数被放到了正文中。
当然如果出现了除0错误:

子进程会异常退出,退出码被设置,父进程分析退出码得出服务器处理出错,返回500.html的静态网页。
五、项目源码
gitee:https://gitee.com/yyh1161/http-server
相关文章:
【项目】轻量级HTTP服务器
文章目录 一、项目介绍二、前置知识2.1 URI、URL、URN2.2 CGI2.2.1 CGI的概念2.2.2 CGI模式的实现2.2.3 CGI的意义 三、项目设计3.1 日志的编写3.2 套接字编写3.3 HTTP服务器实现3.4 HTTP请求与响应结构3.5 EndPoint类的实现3.5.1 EndPoint的基本逻辑3.5.2 读取请求3.5.3 构建响…...

sketch如何在线打开?有没有什么软件可以辅助
Sketch 在线打开的方法有哪些?这个问题和我之前回答过的「Sketch 可以在线编辑吗?」是一样的答案,没有。很遗憾,Sketch 没有在线打开的方法,Sketch 也做不到可以在线编辑。那么,那些广告里出现的设计软件工…...

CSS Flex 笔记
1. Flexbox 术语 Flex 容器可以是<div> 等,对其设置属性:display: flex, justify-content 是沿主轴方向调整元素,align-items 是沿交叉轴对齐元素。 2. Cheatsheet 2.1 设置 Flex 容器,加粗的属性为默认值 2.1.1 align-it…...

Markdown常用标签及其用途-有示例
Markdown常用标签及其用途 Markdown是一种轻量级标记语言,具有简洁易读的特点。下面是一些常用的Markdown标签以及它们的用途,并附带一些示例: 标题 用于创建不同级别的标题,可通过添加一到六个#符号来表示不同级别的标题。 #…...

25.1 Knife4j-Swagger的增强插件
1.Knife4j概述 Knife4j是一款基于Swagger UI的增强插件,它可以为Spring Boot项目生成美观且易于使用的API文档界面。它是Swagger UI的增强版,提供了更多的功能和定制选项,使API文档更加易读和易于理解。 2.Knife4j使用 Knife4j 集Swagger2…...

用flask run代替flask run --debug
安装python-dotenv依赖。 在项目根目录下新建.flaskenv文件,并作如下配置: FLASK_ENVdevelopment FLASK_DEBUG1...
python_day14_综合案例
文件内容 导包配置 import jsonfrom pyspark import SparkContext, SparkConf import osos.environ["PYSPARK_PYTHON"] "D:/dev/python/python3.10.4/python.exe" os.environ["HADOOP_HOME"] "D:/dev/hadoop-3.0.0" conf SparkC…...

【算法题】2779. 数组的最大美丽值
题目: 给你一个下标从 0 开始的整数数组 nums 和一个 非负 整数 k 。 在一步操作中,你可以执行下述指令: 在范围 [0, nums.length - 1] 中选择一个 此前没有选过 的下标 i 。 将 nums[i] 替换为范围 [nums[i] - k, nums[i] k] 内的任一整…...

文件上传之PHP
别怕,我会一直陪着你 一.知识二.实例1.phtml, <?简单过滤2.前端验证, phtml3 \.htaccess 一.知识 绕过后缀的有文件格式有php,php3,php4,php5,phtml.pht 二.实例 1.phtml, <?简单过滤 (1)一句话木马 故意使用了post和get用来迷惑人 https://127.0.0.1/shy.php?POS…...

人脸检测实战-insightface
目录 简介 一、InsightFace介绍 二、安装 三、快速体验 四、代码实战 1、人脸检测 2、人脸识别 五、代码及示例图片链接 简介 目前github有非常多的人脸识别开源项目,下面列出几个常用的开源项目: 1、deepface 2、CompreFace 3、face_recogn…...

Linux工具【1】(编辑器vim、编译器gcc与g++)
vim详解 引言vimVim的三种模式及模式切换普通模式下操作底行模式下操作 gcc与ggcc的使用(g类似)预编译编译汇编链接静态库与动态库 总结 引言 vim(vi improved)编辑器是从 vi 发展出来的一个文本编辑器。 代码补全、编译及错误跳…...
基于Java+SpringBoot+vue前后端分离古典舞在线交流平台设计实现
博主介绍:✌全网粉丝30W,csdn特邀作者、博客专家、CSDN新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取源码联系🍅 👇🏻 精彩专…...

MQ - 闲聊MQ一二事儿 (Kafka、RocketMQ 、Pulsar )
文章目录 MQ的发展史阶段一:追求解耦阶段二:追求吞吐量与一致性阶段三:追求平台化 MQ的通用架构主题topic、生产者producer、消费者consumer分区partition MQ 存储KafkaGood Design ---> 磁盘顺序写盘Poor Impact---> topic 数量不能过…...
)
Qt中的 QIODevice类(包含:随机访问、顺序访问设备)
QIODevice类 一、简介 QIODevice用于对输入输出设备进行管理,是Qt中所有I/O设备的基接口类。为支持读写数据块的设备(如QFile、QBuffer和QTcpSocket)提供了通用实现和抽象接口。 输入设备有2种类型: 一种是随机访问设备,QFile(文件)和QBuff…...
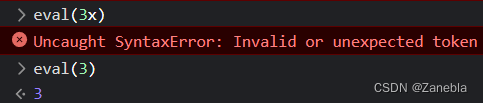
【JavaScript 07】函数声明 地位平等 函数提升 属性方法 作用域 参数 arguments对象 闭包 IIFE立即调用函数表达式 eval命令
函数 1 概述1.1 声明1.2 重复声明 1.3 圆括号/return/recursion1.4 一等公民1.5 函数提升 2 函数属性与方法2.1 name属性2.2 length属性2.3 toString() 3 函数作用域3.1 概念3.2 函数内部变量提升3.3 函数本身作用域 4 参数4.1 概念4.2 省略4.3 传递4.4 同名4.5 arguments 对象…...
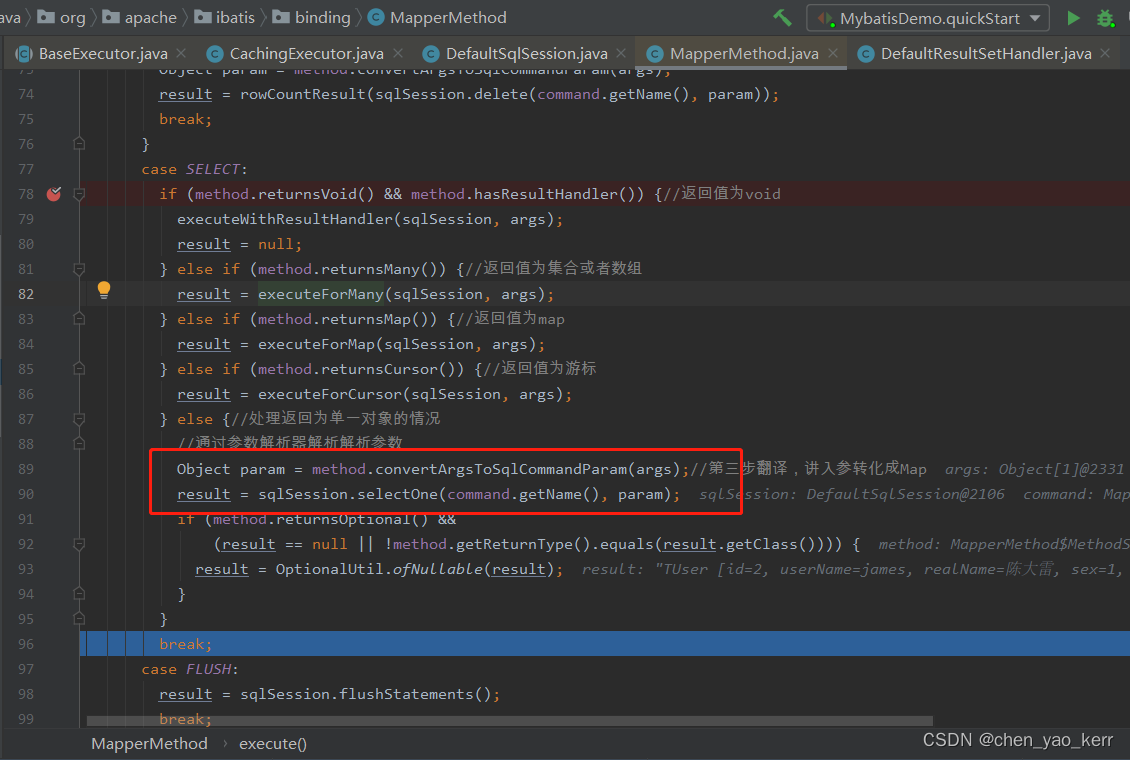
MyBatis源码分析_ResultSetHandler(7)
目录 1. 传统JDBC 2. Mybatis访问数据库 2.1 Statement访问数据库 2.2 火枪手 ResultSetHandler 出现 3. ResultSetHandler处理结果集 3.1 首先就是进入 handleResultSets 方法 3.2 handleResultSet 方法根据映射规则(resultMap)对结果集进行转化…...
Unittest加载执行用例的方法总结
前言 说到测试框架,unittest是我最先接触的自动化测试框架之一了, 而且也是用的时间最长的, unittest框架有很多方法加载用例,让我们针对不同的项目,不同项目的大小及用例的多少自己选择加载方式。今天我们就简单的说说…...

使用预训练的2D扩散模型改进3D成像
扩散模型已经成为一种新的生成高质量样本的生成模型,也被作为有效的逆问题求解器。然而,由于生成过程仍然处于相同的高维(即与数据维相同)空间中,极高的内存和计算成本导致模型尚未扩展到3D逆问题。在本文中࿰…...
微服务测试是什么?
微服务测试是一种特殊的测试类型,因为它涉及到多个独立的服务。以下是进行微服务测试的一般性步骤: 【B站最通俗易懂】Python接口自动化测试从入门到精通,超详细的进阶教程,看完这套视频就够了 1. 确定系统架构 了解微服务架构对…...
)
《现代C++教程》笔记(5-7)
文章目录 5 智能指针与内存管理5.1 RAII与引用计数5.2 std::shared_ptr5.3 std::unique_ptr5.4 std::weak_ptr 6 正则表达式7 并行与并发7.1 并行基础7.2 互斥量与临界区7.3 期物7.4 条件变量7.5 原子操作与内存模型 5 智能指针与内存管理 5.1 RAII与引用计数 在传统 C 中&am…...
)
从“Hello World”到区域赛银牌:我的ACM算法打怪升级全记录(附各阶段工具包)
从“Hello World”到区域赛银牌:我的ACM算法打怪升级全记录 记得大一刚接触编程时,连最简单的冒泡排序都要调试半天。三年后站在领奖台上,回想这段旅程,最珍贵的不是奖牌,而是那些深夜debug的坚持和突破自我的瞬间。这…...

Java后端如何优雅地封装第三方API调用逻辑以对接美团外卖霸王餐接口
Java后端如何优雅地封装第三方API调用逻辑以对接美团外卖霸王餐接口 在Java后端开发中,对接第三方API(如美团外卖霸王餐接口)是常见的需求。直接在业务代码中拼接URL、处理JSON、写HTTP请求不仅导致代码臃肿,还难以维护和测试。 本…...
TrackingNet评估实战:从注册到结果解析
1. TrackingNet评估平台入门指南 第一次接触TrackingNet这个目标跟踪领域的权威评估平台时,我和大多数研究者一样有点懵。这个平台不像GitHub那样有直观的界面,操作流程也相对复杂。不过别担心,跟着我的实战经验走,保证你能少踩8…...

Graphormer部署教程:/etc/supervisor/conf.d/graphormer.conf配置解析
Graphormer部署教程:/etc/supervisor/conf.d/graphormer.conf配置解析 1. 项目介绍 Graphormer是一种基于纯Transformer架构的图神经网络模型,专门为分子图(原子-键结构)的全局结构建模与属性预测而设计。该模型在OGB、PCQM4M等…...

利用快马平台快速构建arm7流水灯原型,十分钟验证硬件控制逻辑
最近在带学生入门嵌入式开发时,发现ARM7这类经典架构虽然功能强大,但初学者往往会被复杂的环境搭建劝退。为了让大家能快速上手硬件控制逻辑,我尝试用InsCode(快马)平台构建了一个LED流水灯原型,整个过程比想象中顺畅很多。 项目设…...

深入解析Nordic NRF52832的NFC天线与GPIO复用设计
1. NFC天线硬件设计基础 NRF52832芯片的NFC功能通过P0.09和P0.10两个专用引脚实现,这两个引脚在设计时需要特别注意硬件连接规范。实际项目中,我遇到过不少开发者直接将这两个引脚当作普通GPIO使用导致通信异常的情况——因为默认状态下它们被硬件映射为…...

什么是焦糖布丁理论?用 JTBD 做软件产品设计的四步法
“焦糖布丁理论”其实是对 Jobs to Be Done(JTBD,待办任务理论) 的一种本土化、形象化的称呼,源自哈佛商学院教授 克莱顿克里斯坦森(Clay Christensen) 在其著作《与运气竞争》(Competing Again…...

noice.nvim终极性能优化指南:让你的Neovim编辑器运行如飞
noice.nvim终极性能优化指南:让你的Neovim编辑器运行如飞 【免费下载链接】noice.nvim 💥 Highly experimental plugin that completely replaces the UI for messages, cmdline and the popupmenu. 项目地址: https://gitcode.com/gh_mirrors/no/noic…...

Unity资源提取技术解密:AssetRipper效能革命与实战指南
Unity资源提取技术解密:AssetRipper效能革命与实战指南 【免费下载链接】AssetRipper GUI Application to work with engine assets, asset bundles, and serialized files 项目地址: https://gitcode.com/GitHub_Trending/as/AssetRipper 在游戏开发迭代加速…...
Gemma-3 Pixel Studio一文详解:Flash Attention 2对图文响应速度提升实测
Gemma-3 Pixel Studio一文详解:Flash Attention 2对图文响应速度提升实测 1. 引言 在当今多模态AI应用快速发展的背景下,Gemma-3 Pixel Studio作为一款基于Google最新开源Gemma-3-12b-it模型构建的高性能对话终端,凭借其卓越的视觉理解能力…...