【图像处理】使用自动编码器进行图像降噪(改进版)
阿里雷扎·凯沙瓦尔兹
一、说明
自动编码器是一种学习压缩和重建输入数据的神经网络。它由一个将数据压缩为低维表示的编码器和一个从压缩表示中重建原始数据的解码器组成。该模型使用无监督学习进行训练,旨在最小化输入和重建输出之间的差异。自动编码器可用于降维、数据去噪和异常检测等任务。它们在处理未标记数据时非常有效,并且可以从大型数据集中学习有意义的表示。
二、自动编码器的工作原理
网络提供原始图像x,以及它们的噪声版本x~。网络尝试重建其输出 x',使其尽可能接近原始图像 x。通过这样做,它学会了如何对图像进行去噪。

源
如图所示,编码器模型将输入转换为小型密集表示形式。解码器模型可以看作是能够生成特定特征的生成模型。
编码器和解码器网络通常都是作为一个整体进行训练的。损失函数惩罚网络创建与原始输入 x 不同的输出 x'。
通过这样做,编码器学会了保留潜在空间限制所需的尽可能多的相关信息,并巧妙地丢弃不相关的部分,例如噪声。解码器学习获取压缩的潜在信息并将其重建为完整的无错误输入。
三、如何实现自动编码器
让我们实现一个自动编码器来对手写数字进行降噪。输入是一个 28x28 灰度缩放的图像,构建一个 128 个元素的矢量。
编码器层负责将输入图像转换为潜在空间中的压缩表示。它由一系列卷积层和全连接层组成。这种压缩表示包含捕获其底层模式和结构的输入图像的基本特征。ReLU用作编码器层中的激活函数。它应用逐元素激活函数,将负输入的输出设置为零,并保持正输入不变。在编码器层中使用ReLU的目标是引入非线性,允许网络学习复杂的表示并从输入数据中提取重要特征。
代码中的解码器层负责从潜在空间中的压缩表示重建图像。它反映了编码器层的结构,由一系列完全连接和转置卷积层组成。解码器层从潜在空间获取压缩表示,并通过反转编码器层执行的操作来重建图像。它使用转置卷积层逐渐对压缩表示进行上采样,并最终生成与输入图像具有相同尺寸的输出图像。Sigmoid 和 ReLU 激活用于解码器层。Sigmoid 激活将输入值压缩在 0 到 1 之间,将每个神经元的输出映射到类似概率的值。在解码器层中使用 sigmoid 的目标是生成 [0, 1] 范围内的重建输出值。由于此代码中的输入数据表示二进制图像,因此 sigmoid 是重建像素值的合适激活函数。
通过在编码器层和解码器层使用适当的激活函数,自动编码器模型可以有效地学习将输入数据压缩到低维潜在空间中,然后从潜在空间重建原始输入数据。激活函数的选择取决于所解决问题的具体要求和特征。
二进制交叉熵用作损失函数,Adam 用作最小化损失函数的优化器。“binary_crossentropy”损失函数通常用于二元分类任务,适用于在这种情况下重建二元图像。它衡量预测输出与真实目标输出之间的相似性。“adam”优化器用于在训练期间更新模型的权重和偏差。Adam(自适应矩估计的缩写)是一种优化算法,它结合了 RMSprop 优化器和基于动量的优化器的优点。它单独调整每个权重参数的学习率,并使用梯度的第一和第二时刻来有效地更新参数。
通过使用二进制交叉熵作为损失函数和Adam优化器,自动编码器模型旨在最小化重建误差并优化模型的参数,以生成输入数据的准确重建。
第 1 部分:导入库和模块
import numpy as npimport matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnistfrom tensorflow.keras.layers import input, dense, reshape, flatten, Conv2D, Conv2DTransposefrom tensorflow.keras.models import model from tensorflow.keras.optimizers import Adamfrom tensorflow.keras.callbacks import EarlyStop在这一部分中,导入了必要的库和模块。
numpy(导入为 )是用于数值运算的库。npmatplotlib.pyplot(导入为 )是用于打印的库。pltmnist从 导入以加载 MNIST 数据集。tensorflow.keras.datasets- 从 和 导入各种层和模型。
tensorflow.keras.layerstensorflow.keras.models - 优化程序是从 导入的。
Adamtensorflow.keras.optimizers - 回调是从 导入的。
EarlyStoppingtensorflow.keras.callbacks
第 2 部分:加载和预处理数据集
(x_train, _), (x_test, _) = mnist.load_data()在这一部分中,加载 MNIST 数据集并将其拆分为训练集和测试集。相应的标签将被忽略,并且不会分配给任何变量。
第 3 部分:预处理数据集
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
x_train = np.expand_dims(x_train, axis=-1)
x_test = np.expand_dims(x_test, axis=-1)在这一部分中,数据集被预处理:
- 和 中图像的像素值通过除以 0.1 归一化为 255 到 0 的范围。
x_trainx_test - 输入数据的维度使用 展开以包括通道维度。这对于卷积运算是必需的。
np.expand_dims
第 4 部分:向训练集添加随机噪声
noise_factor = 0.5
x_train_noisy = x_train + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_train.shape)
x_test_noisy = x_test + noise_factor * np.random.normal(loc=0.0, scale=1.0, size=x_test.shape)
x_train_noisy = np.clip(x_train_noisy, 0., 1.)
x_test_noisy = np.clip(x_test_noisy, 0., 1.)在这一部分中,随机噪声被添加到训练集中:
- 选择0.5的噪声系数来控制噪声量。
- 使用平均值为 0、标准差为 1 的随机噪声样本生成,然后按噪声因子进行缩放。
np.random.normal - 噪声训练集和测试集是通过将噪声添加到原始数据中获得的。
- 对像素值进行裁剪,以确保它们保持在 0 到 1 的有效范围内。
第 5 部分:创建自动编码器模型
input_shape = (28, 28, 1)
latent_dim = 128# Encoder
inputs = Input(shape=input_shape)
x = Conv2D(32, kernel_size=3, strides=2, activation='relu', padding='same')(inputs)
x = Conv2D(64, kernel_size=3, strides=2, activation='relu', padding='same')(x)
x = Flatten()(x)
latent_repr = Dense(latent_dim)(x)# Decoder
x = Dense(7 * 7 * 64)(latent_repr)
x = Reshape((7, 7, 64))(x)
x = Conv2DTranspose(32, kernel_size=3, strides=2, activation='relu', padding='same')(x)
decoded = Conv2DTranspose(1, kernel_size=3, strides=2, activation='sigmoid', padding='same')(x)# Autoencoder model
autoencoder = Model(inputs, decoded)在这一部分中,自动编码器模型是使用编码器-解码器架构创建的:
input_shape定义为 ,表示输入图像的形状。(28, 28, 1)latent_dim设置为 128,这决定了潜在空间的维数。- 编码器层定义:
- 将使用指定的 .
input_shape - 添加了两个分别具有 32 和 64 个过滤器的卷积层,内核大小为 3x3,步幅为 2,激活和填充设置为 。
'relu''same' - 卷积层的输出使用 .
Flatten() - 通过将扁平输出传递到带有神经元的完全连接层来获得潜在表示。
Denselatent_dim - 解码器层定义:
- 添加带有神经元的层以匹配编码器中最后一个特征图的形状。
Dense7 * 7 * 64 - 输出将调整为 使用 .
(7, 7, 64)Reshape - 添加了两个转置卷积层:
- 第一层有 32 个过滤器,内核大小为 3x3,步幅为 2,激活和填充设置为 。
'relu''same' - 第二层有 1 个筛选器,内核大小为 3x3,步幅为 2,激活和填充设置为 。
'sigmoid''same' - 通过指定输入和输出层来创建模型。
autoencoder
第 6 部分:编译自动编码器模型
autoencoder.compile(optimizer=Adam(lr=0.0002), loss='binary_crossentropy')在这一部分中,编译了自动编码器模型:
- 优化器的学习率为 0.0002。
Adam - 损失函数设置为 。
'binary_crossentropy'
第 7 部分:添加提前停止
early_stopping = EarlyStopping(monitor='val_loss', patience=5, restore_best_weights=True)在这一部分中,创建了一个提前停止回调:
- 它监视验证丢失 ()。
'val_loss' - 如果验证损失连续 5 个 epoch 没有改善,则停止训练。
- 恢复训练期间模型的最佳权重。
第 8 部分:训练自动编码器
epochs = 20
batch_size = 128history = autoencoder.fit(x_train_noisy, x_train, validation_data=(x_test_noisy, x_test),epochs=epochs, batch_size=batch_size, callbacks=[early_stopping])在这一部分中,对自动编码器模型进行了训练:
- 纪元数设置为 100,批大小设置为 128。
- 训练数据以 提供,验证数据以 提供。
(x_train_noisy, x_train)(x_test_noisy, x_test) - 训练过程以指定的周期数、批大小和提前停止回调执行。
- 训练历史记录存储在变量中。
history
第 9 部分:去噪测试图像并显示结果
denoised_test_images = autoencoder.predict(x_test_noisy)# Display original, noisy, and denoised images
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):# Original imagesax = plt.subplot(3, n, i + 1)plt.imshow(x_test[i].reshape(28, 28), cmap='gray')plt.title("Original")ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)# Noisy imagesax = plt.subplot(3, n, i + 1 + n)plt.imshow(x_test_noisy[i].reshape(28, 28), cmap='gray')plt.title("Noisy")ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)# Denoised imagesax = plt.subplot(3, n, i + 1 + n + n)plt.imshow(denoised_test_images[i].reshape(28, 28), cmap='gray')plt.title("Denoised")ax.get_xaxis().set_visible(False)ax.get_yaxis().set_visible(False)
plt.show()在这一部分中:
- 通过使用该方法将噪声测试图像通过训练的自动编码器来获得去噪测试图像。
predict - 原始、噪点和去噪图像使用 .
matplotlib.pyplot - 将创建一个包含三行的图形来显示图像。
- 对于每一行,为每个图像创建一个子图。
- 原始图像、噪点图像和去噪图像显示在单独的子图中。
- 为每个子图设置轴标签和标题。
- 结果图使用 表示。
plt.show()
四、结果

相关文章:
【图像处理】使用自动编码器进行图像降噪(改进版)
阿里雷扎凯沙瓦尔兹 一、说明 自动编码器是一种学习压缩和重建输入数据的神经网络。它由一个将数据压缩为低维表示的编码器和一个从压缩表示中重建原始数据的解码器组成。该模型使用无监督学习进行训练,旨在最小化输入和重建输出之间的差异。自动编码器可用于降维、…...

MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句 ---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N ---适应场景: 适用于数据量较少的情况(元组百/千级) ---原因/缺点: 全表扫描,速度会很慢 且 有的数据库结果集返回不稳定(如某次返回1,2,3,另外的一次返回2,1,3). L…...

dataTable转成对象、json、list
datatable转换成list集合 public static T TableToEntity<T>(DataTable dt, int rowindex 0, bool isStoreDB true){Type type typeof(T);T entity Activator.CreateInstance<T>();if (dt null){return entity;}DataRow row dt.Rows[rowindex];PropertyInfo…...

ubuntu环境安装centos7虚拟机网络主机不可达,ping不通
【NAT模式下解决】1.首先vi /etc/sysconfig/network-scripts/ifcfg-ens33检查ONBOOTyes,保存 2.输入systemctl restart network命令重启网关...

STN:Spatial Transformer Networks
1.Abstract 卷积神经网络缺乏对输入数据保持空间不变的能力,导致模型性能下降。作者提出了一种新的可学习模块,STN。这个可微模块可以插入现有的卷积结构中,使神经网络能够根据特征图像本身,主动地对特征图像进行空间变换&#x…...

C语言学习笔记 VScode设置C环境-06
目录 一、下载vscode软件 二、安装minGW软件 三、VS Code安装C/C插件 3.1 搜索并安装C/C插件 3.2 配置C/C环境 总结 一、下载vscode软件 在官网上下载最新的版本 Download Visual Studio Code - Mac, Linux, Windowshttps://code.visualstudio.com/download 二、安装minGW…...

alias取别名后,另一个shell中和shell脚本中不生效的问题以及crontab执行docker失败问题
目录 问题一:用alias取别名后,另一个shell中不生效描述原因解决 问题二:用alias取别名后,别名在脚本中不生效描述原因解决 问题三:crontab计划任务不能运行docker命令描述原因解决 问题一:用alias取别名后&…...
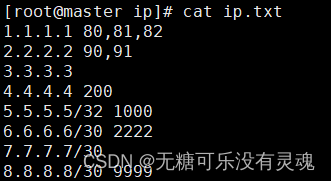
Shell ❀ 一键配置Iptables规则脚本 (HW推荐)
文章目录 注意事项1. 地址列表填写规范2. 代码块3. 执行结果4. 地址与端口获取方法4.1 tcpdump抓包分析(推荐使用)4.2 TCP连接分析(仅能识别TCP连接) 注意事项 请务必按照格式填写具体参数,否则会影响到匹配规则的创建…...

linux服务器查找大文件及删除文件后磁盘空间没有得到释放
1、查询服务器中大于1G的文件 find / -type f -size 1G这条命令是查询自”/”根目录下所有大小超过1G的文件,查询的大小可以根据需要改变,如下: 相关查询:查询服务器中大于100M的文件 find / -type f -size 100M2、查询服务器中…...
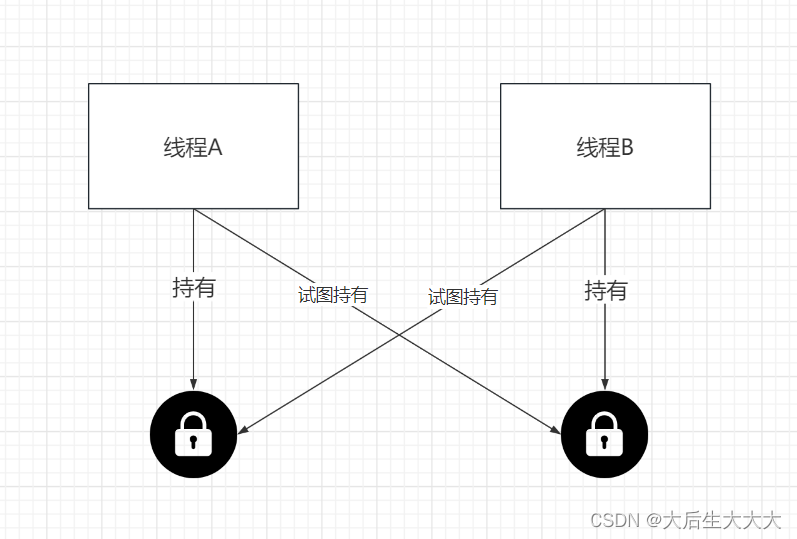
Java那些“锁”事 - 死锁及排查
死锁是两个或者两个以上的线程在执行过程中,因争夺资源而造成的一种互斥等待现象,若没有外界干涉那么它们将无法推进下去。如果系统资源不足,进程的资源请求都得到满足,死锁出现的可能性就很低,否则就会因为争夺有限的…...

LLM系列 | 18 : 如何用LangChain进行网页问答
简介 一夕轻雷落万丝,霁光浮瓦碧参差。 紧接之前LangChain专题文章: 15:如何用LangChain做长文档问答?16:如何基于LangChain打造联网版ChatGPT?17:ChatGPT应用框架LangChain速成大法 今天这篇小作文是LangChain实践专题的第4…...
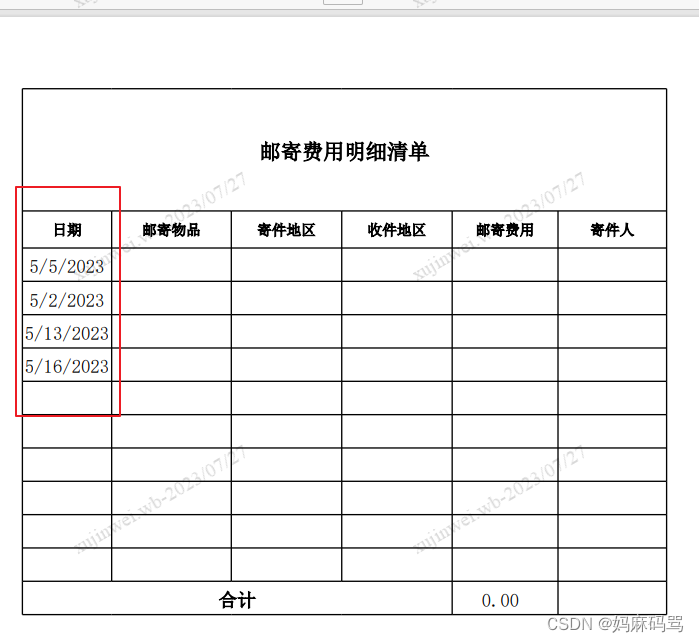
Aspose.cell excel转pdf日期格式不正确yyyy/MM/dd变成MM/dd/yyyy
最近使用Aspose.cell将excel转pdf过程中excel中时间格式列的显示和excel表里的值显示不一样。 excel里日期格式 yyyy/MM/dd pdf里日期格式MM/dd/yyyy 主要原因:linux和windows里内置的时间格式不一致,当代码部署到linux服务器的时候转换格式就会发生不一…...

搭建golang开发环境
这里参考一篇文章: golang环境变量链接,还不错...
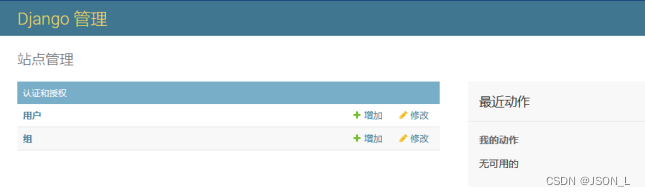
Django实现音乐网站 ⑴
使用Python Django框架制作一个音乐网站。 目录 网站功能模块 安装django 创建项目 创建应用 注册应用 配置数据库 设置数据库配置 设置pymysql库引用 创建数据库 创建数据表 生成表迁移文件 执行表迁移 后台管理 创建管理员账户 启动服务器 登录网站 配置时区…...

基于粒子群优化算法的分布式电源选址与定容【多目标优化】【IEEE33节点】(Matlab代码实现)
目录 💥1 概述 1.1 目标函数 2.2 约束条件 📚2 运行结果 🎉3 参考文献 🌈4 Matlab代码实现 💥1 概述 分布式电源接入配电网,实现就地消纳,可以提高新能源的利用率、提高电能质量和降低系统网损…...

打卡一个力扣题目
目录 一、问题 二、解题办法一 三、解题方法二 四、对比分析 关于 ARTS 的释义 —— 每周完成一个 ARTS: ● Algorithm: 每周至少做一个 LeetCode 的算法题 ● Review: 阅读并点评至少一篇英文技术文章 ● Tips: 学习至少一个技术技巧 ● Share: 分享一篇有观点…...
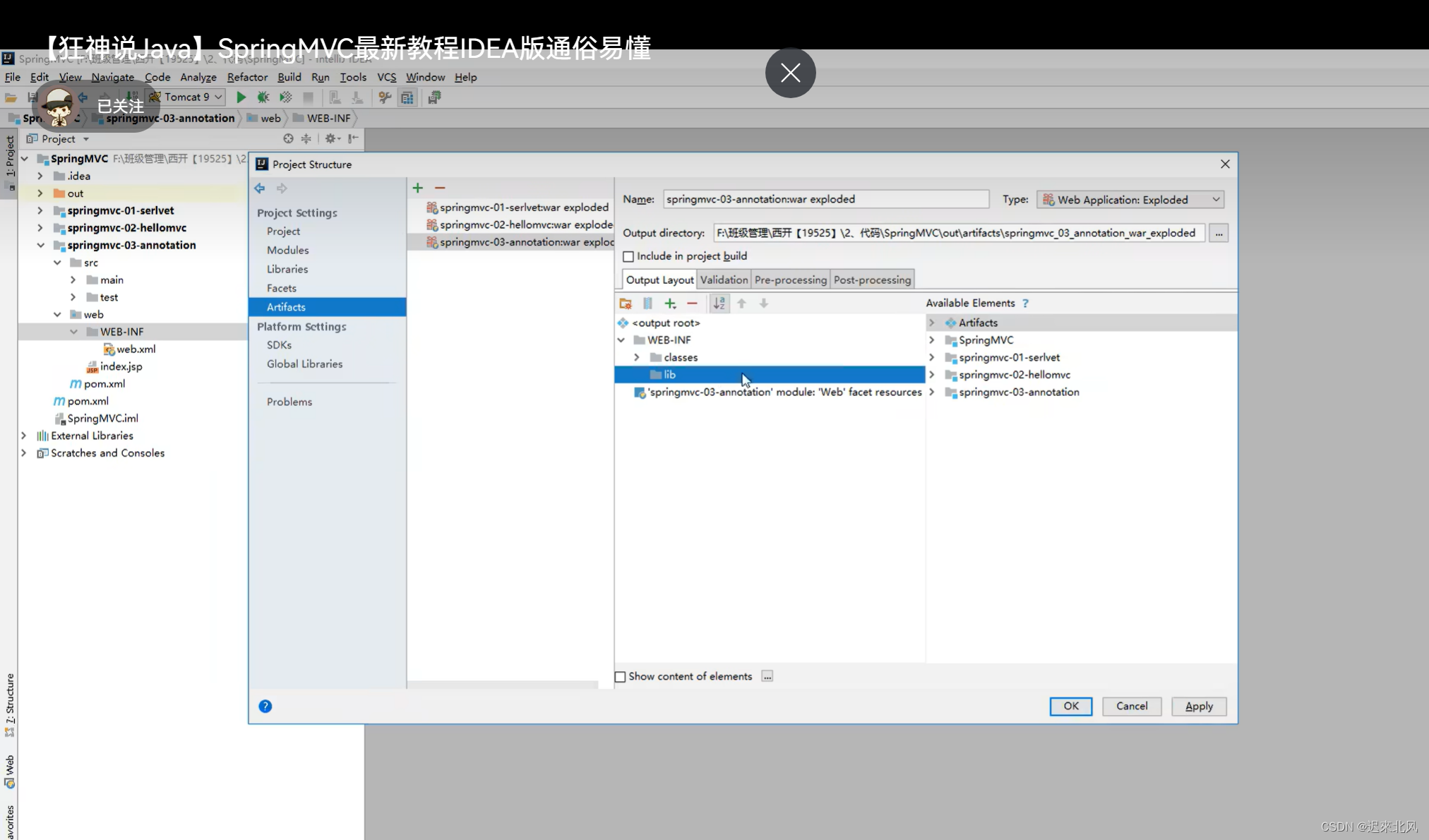
【SSM—SpringMVC】 问题集锦(持续更新)
目录 1.Tomcat启动,部署工件失败 1.Tomcat启动,部署工件失败 解决:使用SpringMVC,添加Web支持,要将项目结构进行添加WEB-INF下添加lib目录,将依赖添进去...
“软件测试”赛项接口测试任务书)
2022年全国职业院校技能大赛(高职组)“软件测试”赛项接口测试任务书
任务七 接口测试 执行接口测试 本部分按照要求,执行接口测试;使用接口测试工具PostMan,编写脚本、配置参数、执行接口测试并且截图,截图需粘贴在接口测试总结报告中。 接口测试具体要求如下: 题目1:资产…...
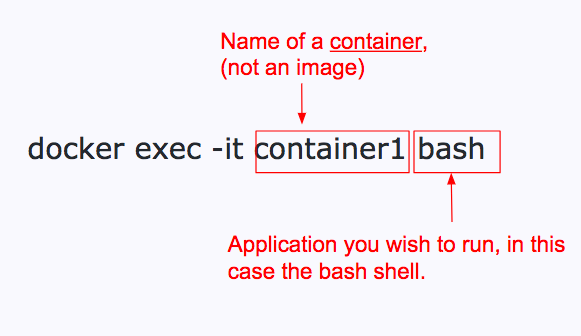
Docker 如何助您成为数据科学家
一、说明 在过去的 5 年里,我听到了很多关于 docker 容器的嗡嗡声。似乎我所有的软件工程朋友都在使用它们来开发应用程序。我想弄清楚这项技术如何使我更有效率,但我发现网上的教程要么太详细:阐明我作为数据科学家永远不会使用的功能&#…...

机器学习01 -Hello World(对鸢尾花(Iris Flower)进行训练及测试)
什么是机器学习? 机器学习是一种人工智能(AI)的子领域,它探索和开发计算机系统,使其能够从数据中学习和改进,并在没有明确编程指令的情况下做出决策或完成任务。 传统的程序需要程序员明确编写指令来告诉…...

【手把手实战!fMRI数据预处理全流程解析】SPM12操作指南
1. fMRI数据预处理入门:为什么需要SPM12? 第一次接触fMRI数据分析的朋友,往往会被各种专业术语吓到——DICOM、NIFTI、头动校正、空间标准化...这些名词听起来就让人头大。但别担心,就像我第一次在实验室处理数据时导师说的&…...

双轴光伏智能跟踪系统,怎么让光伏发电效率提上来的?
做光伏相关开发和落地的朋友,应该都绕不开一个核心痛点:传统固定式光伏的光能利用率,一直有明显的天花板。今天就用通俗的方式,拆解WZ HELIO这套双轴智能跟踪系统,看看它是怎么解决这个行业老问题的。先搞懂核心逻辑&a…...

从黑客攻防角度看网络命令:如何用ping/tracert/nslookup发现网络安全隐患
网络命令的攻防实战:用基础工具发现隐藏的安全威胁 当大多数人还在把ping、tracert这些基础网络命令当作简单的连通性测试工具时,安全工程师已经将它们变成了发现网络威胁的"显微镜"。这些看似简单的命令行工具,在专业的安全分析场…...

CTF逆向实战:从RC4到Base64,手把手拆解CTFshow赛题
1. RC4加密实战:从文件分析到密钥破解 第一次接触CTF逆向题时,看到RC4加密可能会觉得无从下手。但实际拆解后你会发现,这类题目往往藏着明显的突破口。就拿CTFshow这道re2赛题来说,整个解题过程就像在玩解谜游戏。 用IDA打开题目…...

3步突破显卡限制:如何让AMD/Intel显卡实现DLSS级画质?
3步突破显卡限制:如何让AMD/Intel显卡实现DLSS级画质? 【免费下载链接】OptiScaler OptiScaler bridges upscaling/frame gen across GPUs. Supports DLSS2/XeSS/FSR2 inputs, replaces native upscalers, enables FSR3 FG on non-FG titles. Supports N…...
)
告别付费IP!手把手教你用ZCU102 PS端DP接口点亮显示器(附参数调试心得)
解锁ZCU102 PS端DisplayPort潜力:零成本实现高效显示输出的实战指南 在嵌入式视觉系统开发中,显示输出往往是项目落地的最后一道关卡。当我在多个Zynq UltraScale MPSoC项目中反复遭遇HDMI IP核的授权困扰和PL端实现的复杂性后,意外发现PS端集…...

Kodi PVR IPTV Simple全方位应用指南:从入门到精通的多场景解决方案
Kodi PVR IPTV Simple全方位应用指南:从入门到精通的多场景解决方案 【免费下载链接】pvr.iptvsimple IPTV Simple client for Kodi PVR 项目地址: https://gitcode.com/gh_mirrors/pv/pvr.iptvsimple 一、场景痛点分析:当IPTV体验不如预期时&…...

在MATLAB中调用与可视化Lingbot-Depth-Pretrain-ViTL-14的深度估计结果
在MATLAB中调用与可视化Lingbot-Depth-Pretrain-ViTL-14的深度估计结果 对于很多从事计算机视觉、机器人或者测绘相关研究的工程师和学者来说,深度估计是一个基础又关键的任务。它能从一张普通的二维图片中,推测出每个像素点距离相机的远近,…...

告别手动!用Python+GDAL批量处理GlobeLand30影像:下载、去黑边、镶嵌裁剪全自动
用PythonGDAL打造GlobeLand30全自动处理流水线 遥感影像处理一直是地理信息科学领域的核心工作之一。对于需要处理大范围GlobeLand30数据的科研人员和开发者来说,传统的手动操作不仅效率低下,还容易引入人为错误。想象一下,当你需要处理覆盖整…...

USB251xB集线器I²C控制库:嵌入式USB设备扩展实战指南
1. 项目概述SparkFun USB Hub Qwiic USB251x 是一款面向嵌入式原型开发与量产过渡阶段的轻量级 USB 2.0 集线器控制库,专为 SparkFun 自研的 Qwiic 兼容 USB251xB 系列 Hub 模块(SPX-18014)设计。该库并非通用 USB 协议栈,而是聚焦…...