Elasticsearch:使用 ELSER 释放语义搜索的力量:Elastic Learned Sparse EncoderR

问题陈述
在信息过载的时代,根据上下文含义和用户意图而不是精确的关键字匹配来查找相关搜索结果已成为一项重大挑战。 传统的搜索引擎通常无法理解用户查询的语义上下文,从而导致相关性较低的结果。
解决方案:ELSER
Elastic 通过其检索模型 Elastic Learned Sparse EncodeR (ELSER) 引入了该问题的解决方案。 ELSER 是由 Elastic 训练的检索模型,使你能够执行语义搜索以检索更相关的搜索结果。 此搜索类型为你提供基于上下文含义和用户意图的搜索结果,而不是精确的关键字匹配。
ELSER 是一种域外(out-of-domain)模型,这意味着它不需要对你自己的数据进行微调,使其能够开箱即用地适应各种用例。 它将索引和搜索的段落扩展为术语集合,这些术语在不同的训练数据集中经常同时出现。 这些扩展术语不是搜索术语的同义词; 他们是 learned association。
架构
ELSER 使用 Elasticsearch 排名 rank-feature 类型在索引时存储术语和权重,并在以后进行搜索。 要使用 ELSER,你必须具有适当的语义搜索订阅级别或激活试用期。更多关于订阅的信息,请参阅网站 订阅 | Elastic Stack 产品和支持 | Elastic。
如果关闭部署自动扩展,则 Elasticsearch Service 中用于部署和使用 ELSER 模型的最小专用 ML 节点大小为 4 GB。 建议打开自动缩放,因为它允许你的部署根据需求动态调整资源。
KNN 与 ELSER:
Elasticsearch 的 k 最近邻 (KNN) 搜索和 ELSER (Elastic Learned Sparse EncodeR) 都提供强大的搜索功能,但它们是针对不同类型的搜索任务而设计的,并且以根本不同的方式工作。
Elasticsearch 中的 KNN 搜索
Elasticsearch 中的 KNN 搜索功能使你能够在高维空间中查找给定向量的 “最近邻居(nearest neigbors)”。 这对于图像搜索、产品推荐和异常检测等用例特别有用,在这些用例中,你可以将项目表示为矢量,并且希望查找矢量空间中相似的其他项目。
KNN 搜索的工作原理是对每个矢量进行索引,然后使用距离函数(例如 Euclidean 距离或余弦相似度)来查找最接近给定向量的向量。 这是相似性搜索的一种形式,其目标是查找与给定项目相似的项目。
Elasticsearch 中的 ELSER
另一方面,ELSER 是由 Elastic 训练的检索模型,使你能够执行语义搜索以检索更相关的搜索结果。 此搜索类型为您提供基于上下文含义和用户意图的搜索结果,而不是精确的关键字匹配。
ELSER 是一种域外(out-of-domain)模型,这意味着它不需要对你自己的数据进行微调,使其能够开箱即用地适应各种用例。 它将索引和搜索的段落扩展为术语集合,这些术语在不同的训练数据集中经常同时出现。 这些扩展术语不是搜索术语的同义词; 他们是 learned association。
比较
虽然 KNN 和 ELSER 都可用于提高搜索结果的相关性,但它们是针对不同类型的数据和用例而设计的。 KNN 最适合以下用例:你可以将条目表示为矢量,并且你希望根据其矢量表示找到相似的条目。 另一方面,ELSER 专为你想要查找与给定查询语义相关的搜索结果的用例而设计,即使它们不共享精确的关键字匹配。
在性能方面,KNN 搜索可能是计算密集型的,尤其是在高维空间中,并且可能需要大量资源来提供快速搜索结果。 另一方面,ELSER 使用学习模型来扩展搜索词,这可以更有效,但可能需要合适的订阅级别或试用期激活。
总之,KNN 和 ELSER 之间的选择取决于您的用例的具体要求和数据的性质。
代码示例
在 Kibana 中,你可以从 Machine Learning > Trained Models、Enterprise Search > Indices 或使用开发控制台下载和部署 ELSER。你可以参考文章 “Elasticsearch:部署 ELSER - Elastic Learned Sparse EncoderR” 来在自己的电脑上部署 ELSER 模型。
使用开发控制台
在 Kibana 中,导航到开发控制台并通过运行以下 API 调用来创建 ELSER 模型配置:
PUT _ml/trained_models/.elser_model_1
{"input": {"field_names": ["text_field"]}
}上述命令返回:
{"model_id": ".elser_model_1","model_type": "pytorch","model_package": {"packaged_model_id": "elser_model_1","model_repository": "https://ml-models.elastic.co","minimum_version": "8.8.0","size": 438123276,"sha256": "95f645a3ab8dc66a33de7892391a41ef4fc609a74d21d7b3f7fdd973d58dfe06","metadata": {},"tags": [],"vocabulary_file": "elser_model_1.vocab.json"},"created_by": "api_user","version": "8.8.2","create_time": 1690432777746,"model_size_bytes": 0,"estimated_operations": 0,"license_level": "platinum","description": "Elastic Learned Sparse EncodeR v1 (Tech Preview)","tags": ["elastic"],"metadata": {},"input": {"field_names": ["text_field"]},"inference_config": {"text_expansion": {"vocabulary": {"index": ".ml-inference-native-000001"},"tokenization": {"bert": {"do_lower_case": true,"with_special_tokens": true,"max_sequence_length": 512,"truncate": "first","span": -1}}}},"location": {"index": {"name": ".ml-inference-native-000001"}}
}使用带有部署 ID 的启动训练模型 deployment API 来部署模型:
POST _ml/trained_models/.elser_model_1/deployment/_start?deployment_id=for_search上述命令返回:
{"assignment": {"task_parameters": {"model_id": ".elser_model_1","deployment_id": "for_search","model_bytes": 438123276,"threads_per_allocation": 1,"number_of_allocations": 1,"queue_capacity": 1024,"cache_size": "438123276b","priority": "normal"},"routing_table": {"Gbl69vadQgK1nOqxUT8LaQ": {"current_allocations": 1,"target_allocations": 1,"routing_state": "started","reason": ""}},"assignment_state": "started","start_time": "2023-07-27T04:40:19.531125Z","max_assigned_allocations": 1}
}部署完成后,我们可以通过 Kibana 来查看部署的结果:
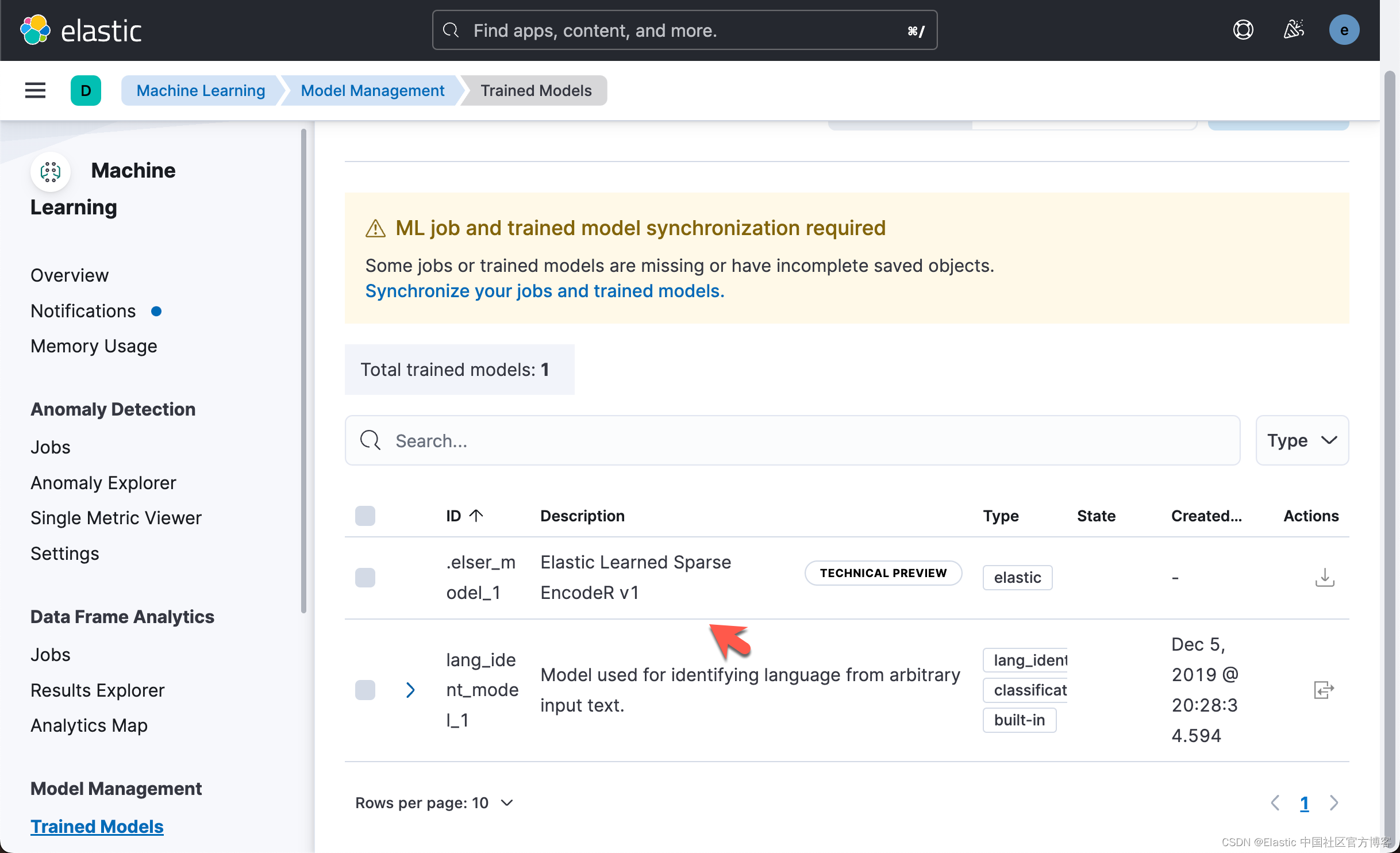
ELSER 就可以在摄取管道或 text_expansion 查询中使用来执行语义搜索。
在摄取管道中使用 ELSER:
PUT _ingest/pipeline/my_pipeline
{"description": "ELSER pipeline","processors": [{"inference": {"model_id": ".elser_model_1","target_field": "ml","field_map": {},"inference_config": {"text_expansion": {"results_field": "tokens"}}}}]
}使用管道索引文档。设置管道后,你可以使用它索引文档:
PUT my_index
{"mappings": {"properties": {"ml.tokens": {"type": "rank_features" },"text_field": {"type": "text" }}}
}PUT my_index/_doc/1?pipeline=my_pipeline
{"text_field": "This is a sample document for ELSER."
}PUT my_index/_doc/2?pipeline=my_pipeline
{"text_field": "Elastic is a great company"
}最后,你可以使用匹配查询来查询索引文档:
GET my_index/_search
{"_source":false,"fields": ["text_field"], "query": {"text_expansion": {"ml.tokens": {"model_id": ".elser_model_1","model_text": "Sample"}}}
}上面的搜索结果为:
{"took": 5,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 5.2040906,"hits": [{"_index": "my_index","_id": "1","_score": 5.2040906,"fields": {"text_field": ["This is a sample document for ELSER."]}},{"_index": "my_index","_id": "2","_score": 0.028514616,"fields": {"text_field": ["Elastic is a great company"]}}]}
}我们再做一次搜索:
GET my_index/_search
{"_source":false,"fields": ["text_field"], "query": {"text_expansion": {"ml.tokens": {"model_id": ".elser_model_1","model_text": "Elastic Stack"}}}
}上面显示的结果为:
{"took": 73,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 13.001609,"hits": [{"_index": "my_index","_id": "2","_score": 13.001609,"fields": {"text_field": ["Elastic is a great company"]}}]}
}我们再做一次搜索:
GET my_index/_search
{"_source":false,"fields": ["text_field"], "query": {"text_expansion": {"ml.tokens": {"model_id": ".elser_model_1","model_text": "ELK"}}}
}上面的搜索结果为:
{"took": 48,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 1,"relation": "eq"},"max_score": 0.054624833,"hits": [{"_index": "my_index","_id": "2","_score": 0.054624833,"fields": {"text_field": ["Elastic is a great company"]}}]}
}最后一个搜索:
GET my_index/_search
{"_source":false,"fields": ["text_field"], "query": {"text_expansion": {"ml.tokens": {"model_id": ".elser_model_1","model_text": "demo doc"}}}
}结果为:
{"took": 56,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 4.6410522,"hits": [{"_index": "my_index","_id": "1","_score": 4.6410522,"fields": {"text_field": ["This is a sample document for ELSER."]}},{"_index": "my_index","_id": "2","_score": 0.09583376,"fields": {"text_field": ["Elastic is a great company"]}}]}
}商业用例
ELSER(Elastic 的学习稀疏编码器)可以有效地用于以语义理解和上下文相关性为关键的各种用例。 这里有一些例子:
- 信息检索:在大型数据库或文档存储库中,ELSER 可用于检索与给定查询在语义上相关的文档,即使它们不共享精确的关键字匹配。 这在精确的信息检索至关重要的法律、学术或企业环境中特别有用。
- 电子商务搜索:电子商务平台可以使用 ELSER 来改进其搜索功能。 当客户搜索产品时,ELSER 可以根据搜索查询的语义上下文提供更相关的结果,从而改善购物体验并有可能增加销售额。
- 客户支持:ELSER 可用于客户支持系统,以更好地了解客户查询并提供更相关的解决方案。 例如,客户描述问题的方式可能与支持数据库中的措辞不完全匹配。 ELSER 可以帮助弥合这一差距并找到最相关的支持文档。
- 内容推荐:媒体平台可以使用 ELSER 来推荐与用户正在查看或已经查看的内容在语义上相关的内容。 这可以通过提供更多符合用户兴趣的内容来帮助保持用户的参与度。
- 社交媒体监控:公司可以使用 ELSER 监控社交媒体并了解有关其品牌的讨论背景。 这可以提供有关客户情绪和新兴趋势的宝贵见解。
- 语义 SEO(Search Engine Optimization):ELSER 可用于理解 Web 内容的语义上下文并针对搜索引擎进行优化。 这可以通过将网站内容与相关搜索查询的语义上下文更紧密地结合起来,帮助提高网站的搜索引擎排名。
相关文章:
Elasticsearch:使用 ELSER 释放语义搜索的力量:Elastic Learned Sparse EncoderR
问题陈述 在信息过载的时代,根据上下文含义和用户意图而不是精确的关键字匹配来查找相关搜索结果已成为一项重大挑战。 传统的搜索引擎通常无法理解用户查询的语义上下文,从而导致相关性较低的结果。 解决方案:ELSER Elastic 通过其检索模型…...
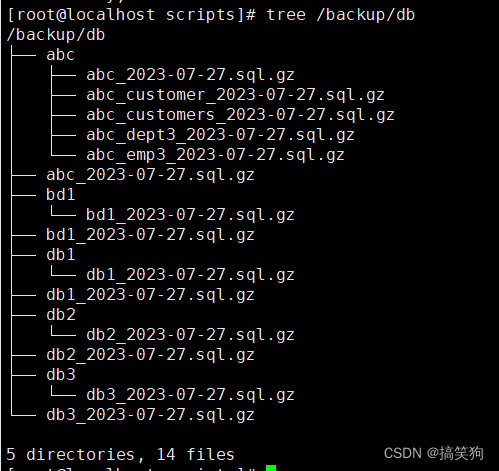
MySQL数据库分库分表备份(shell脚本)
创建目录 mkdir /server/scripts 一、使用脚本实现分库备份 1、创建脚本并编写 [rootlocalhost scripts]# vim bak_db_v1.sh #!/bin/bash ######################################### # File Name:bak_db_v1.sh # Version: V1.0 # Author:Shen QL # Email:17702390000163.co…...

建造者设计模式go实现尝试
文章目录 前言代码结果总结 前言 本文章尝试使用go实现“建造者”。 代码 package mainimport ("fmt" )// 产品1。可以有不同的毫无相关的产品,这里只举一个 type Product1 struct {parts []string }// 产品1逻辑。打印组成产品的部分 func (p *Product…...

创建交互式用户体验:探索JavaScript中的Prompt功能
使用JavaScript中的Prompt功能:创建交互式用户体验 在前端开发中,JavaScript的prompt()函数是一个强大而有用的工具,它可以创建交互式的用户体验。无论是接收用户输入、进行简单的验证还是实现高级的交互功能,prompt()函数都能胜…...
-[提示模板:基础知识])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[提示模板:基础知识]
分类目录:《自然语言处理从入门到应用》总目录 语言模型以文本作为输入,这段文本通常被称为提示(Prompt)。通常情况下,这不仅仅是一个硬编码的字符串,而是模板、示例和用户输入的组合。LangChain提供了多个…...

OpenPCDet调试出现的问题
Open3d遇到的问题,解决方案 1.ModuleNotFoundError: No module named ‘pcdet’ 原因:没有编译安装pcdet。 解决:进入openpcdet项目根目录,修改setup.py权限,并编译: sudo chmod 777 setup.py python set…...
【业务功能篇58】Springboot + Spring Security 权限管理 【下篇】
4.2.2.3 SpringSecurity工作流程分析 SpringSecurity的原理其实就是一个过滤器链,内部包含了提供各种功能的过滤器。这里我们可以看看入门案例中的过滤器。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KjoRRost-1690534711077)(http…...

VBA技术资料MF34:检查Excel自动筛选是否打开
【分享成果,随喜正能量】聪明人,抬人不抬杠;傻子,抬杠不抬人。聪明人,把别人抬得很高,别人高兴、舒服了,看你顺眼了,自然就愿意帮你!而傻人呢?不分青红皂白&a…...

spring扩展点
在Spring框架中,有多个扩展点(Extension Point)可用于自定义和扩展应用程序的行为。这些扩展点允许开发人员介入Spring的生命周期和行为,并提供了灵活性和可定制性。以下是一些常见的Spring扩展点: BeanPostProcessor&…...

Skin Shader 使用自动生成的Thickness
Unity2023.2的版本,Thickness 自动化生成,今天测试了一把,确实不错。 1.Render 设置 在Project Settings->Graphics->HDRP Global Settings中 Frame Setting->Rendering->Compute Thickness 打开 2.Layer设置 2.1添加Layer&…...
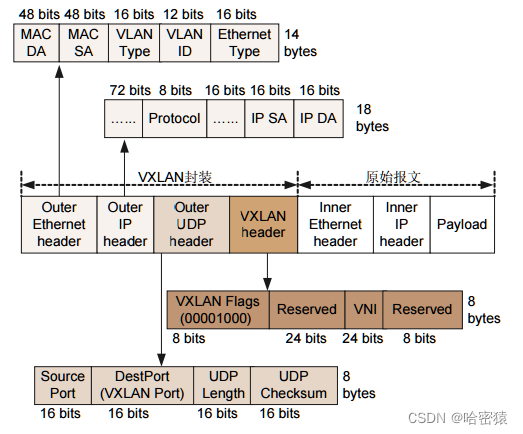
Docker中的网络
文章目录 网络网桥(bridge)创建网桥接口hostnonecontaineroverlayoverlay底层原理 网络 网桥(bridge) 在Docker中,网桥(Bridge)是一种网络驱动,用于实现Docker容器之间和容器与宿主…...

SRS开源代码框架,协程库state-threads的使用
本章内容解读SRS开源代码框架,无二次开发,以学习交流为目的。 SRS是国人开发的流媒体服务器,C语言开发,本章使用版本:https://github.com/ossrs/srs/tree/5.0release。 目录 SRS协程库ST的使用源码ST协程库测试SrsAut…...
【QT 网络云盘客户端】——登录界面功能的实现
目录 1.注册账号 2.服务器ip地址和端口号设置 3. 登录功能 4.读取配置文件 5.显示主界面 1.注册账号 1.点击注册页面,将数据 输入 到 用户名,昵称,密码,确认密码,手机,邮箱 的输入框中, 点…...

【复盘与分享】第十一届泰迪杯B题:产品订单的数据分析与需求预测
文章目录 题目第一问第二问2.1 数据预处理2.2 数据集分析2.2.1 训练集2.2.2 预测集 2.3 特征工程2.4 模型建立2.4.1 模型框架和评价指标2.4.2 模型建立2.4.3 误差分析和特征筛选2.4.4 新品模型 2.5 模型融合2.6 预测方法2.7 总结 结尾 距离比赛结束已经过去两个多月了。 整个过…...
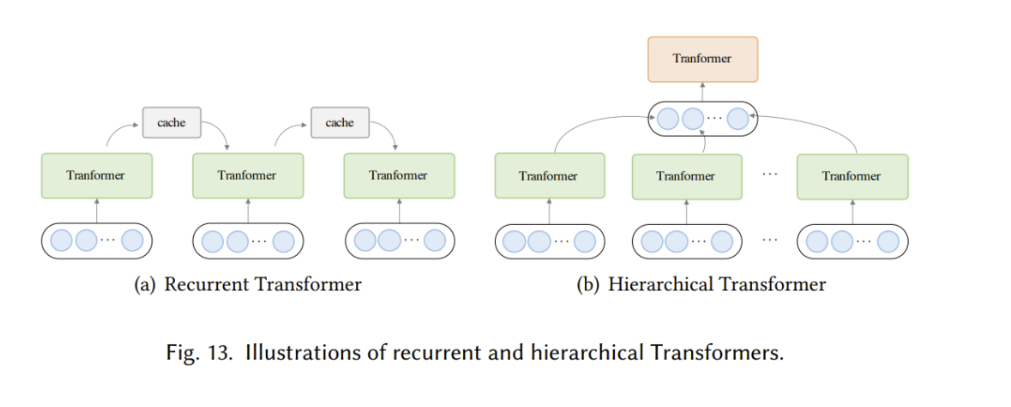
X - Transformer
回顾 Transformer 的发展 Transformer 最初是作为机器翻译的序列到序列模型提出的,而后来的研究表明,基于 Transformer 的预训练模型(PTM) 在各项任务中都有最优的表现。因此,Transformer 已成为 NLP 领域的首选架构&…...
ubuntu下畅玩Seer(via wine)
第一步:安装wine 部分exe文件的运行需要32位的指令集架构,需要向Ubuntu系统中添加一个新的架构(i386),以支持32位的软件包。因为在64位的Ubuntu系统中,默认情况下只能安装和运行64位的软件。 通过添加i386…...

第五章:Spring下
第五章:Spring下 5.1:AOP 场景模拟 创建一个新的模块,spring_proxy_10,并引入下面的jar包。 <packaging>jar</packaging><dependencies><dependency><groupId>junit</groupId><artifactI…...
)
在CSDN学Golang云原生(Kubernetes基础)
一,k8s集群安装和升级 安装 Golang K8s 集群可以参照以下步骤: 准备环境:需要一组 Linux 服务器,并在每台服务器上安装 Docker 和 Kubernetes 工具。初始化集群:使用 kubeadm 工具初始化一个 Kubernetes 集群。例如&…...
给APK签名—两种方式(flutter android 安装包)
前提:给未签名的apk签名,可以先检查下apk有没有签名 通过命令行查看:打开终端或命令行界面,导入包含APK文件的目录,并执行以下命令: keytool -printcert -jarfile your_app.apk 将 your_app.apk替换为要检查…...
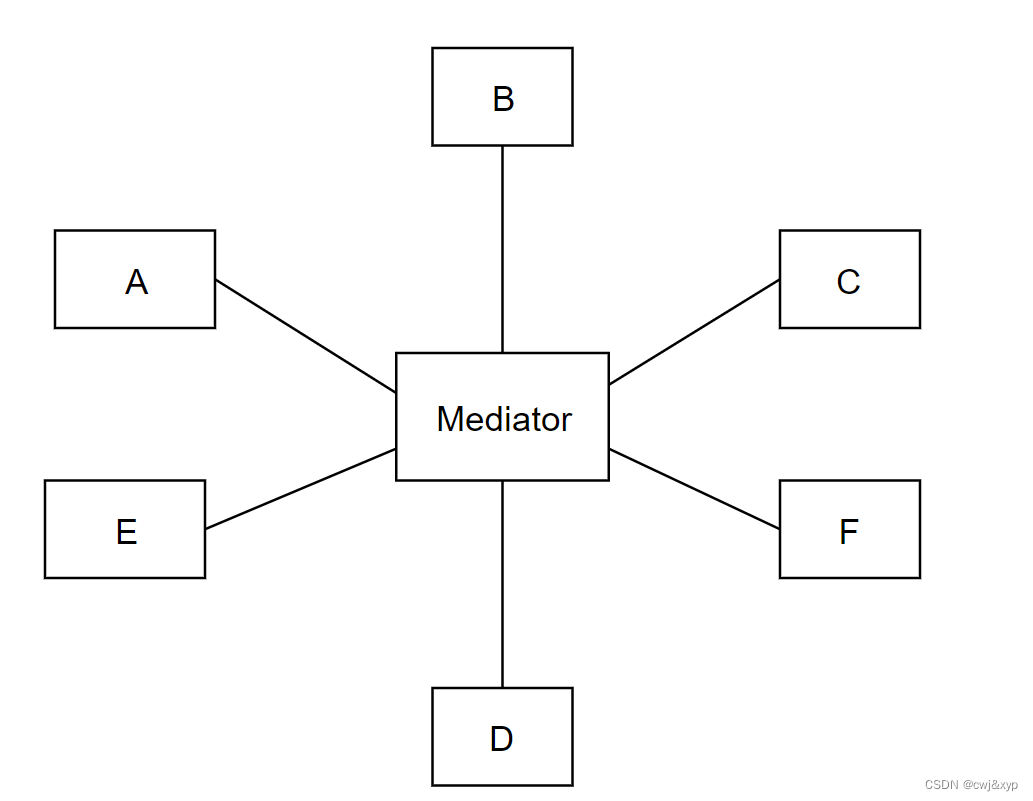
观察者模式、中介者模式和发布订阅模式
观察者模式 定义 观察者模式定义了对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知,并自动更新 观察者模式属于行为型模式,行为型模式关注的是对象之间的通讯,观察者模式…...

Kerberos身份认证原理与企业级排错实战指南
1. 这不是“另一个登录框”,而是一套精密运转的身份验证齿轮系统很多人第一次听说 Kerberos,是在公司内网登录邮箱或访问内部系统时,看到那个带小盾牌图标的弹窗——“正在使用 Kerberos 协议进行身份验证”。于是下意识觉得:“哦…...
)
保姆级教程:在ROS2 Humble/Foxy的Gazebo中配置RGB-D相机(附解决点云颜色/坐标问题)
ROS2 Humble/Foxy中Gazebo深度相机仿真全攻略:从配置到点云问题解决在机器人仿真开发中,深度相机(RGB-D)是不可或缺的传感器之一。它能够同时提供彩色图像和深度信息,为SLAM、物体识别、避障等任务提供关键数据支持。本…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南
SMUDebugTool:AMD Ryzen处理器深度调试与性能调优完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https:…...

如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南
如何在原神中解放双手:自动钓鱼、拾取与对话跳过的终极指南 【免费下载链接】genshin-impact-script 原神脚本,包含自动钓鱼、自动拾取、自动跳过对话等多项实用功能。A Genshin Impact script includes many useful features such as automatic fishing…...

条件Shapley值:用shapr包实现更公平的模型可解释性
1. 项目概述与核心价值 如果你在数据科学或机器学习领域工作过一段时间,尤其是在需要向业务方或非技术团队解释模型决策的场景里,你肯定遇到过这样的困境:模型预测准确率很高,但当别人问“为什么这个客户的贷款申请被拒绝了&#…...
)
【仅限首批200家认证用户】DeepSeek v3.2.1重复检测私有化部署补丁包(含GPU内存泄漏热修复+增量扫描加速模块)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek代码重复检测 DeepSeek-R1 模型在训练过程中引入了严格的代码去重机制,其核心目标是消除训练语料中语义等价或高度相似的代码片段,从而提升模型对真实编程模式的学习能力…...

如何用YOLOv5实现FPS游戏智能瞄准:完整实战指南
如何用YOLOv5实现FPS游戏智能瞄准:完整实战指南 【免费下载链接】FPSAutomaticAiming 基于yolov5的FPS游戏AI。 项目地址: https://gitcode.com/gh_mirrors/fp/FPSAutomaticAiming 在竞技射击游戏中,精准瞄准是决定胜负的关键因素,而F…...