自然语言处理从入门到应用——LangChain:模型(Models)-[文本嵌入模型Ⅰ]
分类目录:《自然语言处理从入门到应用》总目录
本文将介绍如何在LangChain中使用Embedding类。Embedding类是一种与嵌入交互的类。有很多嵌入提供商,如:OpenAI、Cohere、Hugging Face等,这个类旨在为所有这些提供一个标准接口。
嵌入创建文本的向量表示会很有用,因为这意味着我们可以在向量空间中表示文本,并执行类似语义搜索这样的操作。LangChain中的基本Embedding类公开两种方法:
embed_documents:适用于多个文档embed_query:适用于单个文档
将这两种方法作为两种不同的方法的另一个原因是一些嵌入提供商对于需要搜索的文档和查询(搜索查询本身)具有不同的嵌入方法,下面是文本嵌入的集成示例:
Aleph Alpha
使用Aleph Alpha的语义嵌入有两种可能的方法。如果我们有不同结构的文本(例如文档和查询),则我们使用非对称嵌入。相反,对于具有可比结构的文本,则建议使用对称嵌入的方法:
非对称
from langchain.embeddings import AlephAlphaAsymmetricSemanticEmbedding
document = "This is a content of the document"
query = "What is the content of the document?"
embeddings = AlephAlphaAsymmetricSemanticEmbedding()
doc_result = embeddings.embed_documents([document])
query_result = embeddings.embed_query(query)
对称
from langchain.embeddings import AlephAlphaSymmetricSemanticEmbedding
text = "This is a test text"
embeddings = AlephAlphaSymmetricSemanticEmbedding()
doc_result = embeddings.embed_documents([text])
query_result = embeddings.embed_query(text)
Amazon Bedrock
Amazon Bedrock是一个完全托管的服务,通过API提供了来自领先AI初创公司和亚马逊的FMs,因此您可以从广泛的FMs中选择最适合您的用例的模型。
%pip install boto3
from langchain.embeddings import BedrockEmbeddingsembeddings = BedrockEmbeddings(credentials_profile_name="bedrock-admin")
embeddings.embed_query("This is a content of the document")
embeddings.embed_documents(["This is a content of the document"])
Azure OpenAI
我们加载OpenAI Embedding类,并设置环境变量以指示使用Azure端点。
# 设置用于 OpenAI 包的环境变量,以指示使用 Azure 端点
import osos.environ["OPENAI_API_TYPE"] = "azure"
os.environ["OPENAI_API_BASE"] = "https://<your-endpoint.openai.azure.com/"
os.environ["OPENAI_API_KEY"] = "your AzureOpenAI key"
os.environ["OPENAI_API_VERSION"] = "2023-03-15-preview"
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(deployment="your-embeddings-deployment-name")
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
Cohere
我们加载Cohere Embedding类:
from langchain.embeddings import CohereEmbeddings
embeddings = CohereEmbeddings(cohere_api_key=cohere_api_key)
text = "This is a test document."
query_result = embeddings.embed_query(text)
doc_result = embeddings.embed_documents([text])
DashScope
我们加载DashScope嵌入类:
from langchain.embeddings import DashScopeEmbeddings
embeddings = DashScopeEmbeddings(model='text-embedding-v1', dashscope_api_key='your-dashscope-api-key')
text = "This is a test document."
query_result = embeddings.embed_query(text)
print(query_result)
doc_results = embeddings.embed_documents(["foo"])
print(doc_results)
DashScope
我们加载DashScope嵌入类:
from langchain.embeddings import DashScopeEmbeddings
embeddings = DashScopeEmbeddings(model='text-embedding-v1', dashscope_api_key='your-dashscope-api-key')
text = "This is a test document."
query_result = embeddings.embed_query(text)
print(query_result)
doc_results = embeddings.embed_documents(["foo"])
print(doc_results)
Elasticsearch
使用Elasticsearch中托管的嵌入模型生成嵌入的操作步骤。通过下面的方式,可以很容易地实例化ElasticsearchEmbeddings类。如果我们使用的是Elastic Cloud,则可以使用from_credentials构造函数,如果我们使用的是Elasticsearch集群,则可以使用from_es_connection构造函数:
!pip -q install elasticsearch langchain
import elasticsearch
from langchain.embeddings.elasticsearch import ElasticsearchEmbeddings
# 定义模型 ID
model_id = 'your_model_id'
如果我们希望使用from_credentials进行测试,那么我们需要Elastic Cloud的cloud_id:
# 使用凭据实例化 ElasticsearchEmbeddings
embeddings = ElasticsearchEmbeddings.from_credentials(model_id,es_cloud_id='your_cloud_id', es_user='your_user', es_password='your_password'
)# 为多个文档创建嵌入
documents = ['This is an example document.', 'Another example document to generate embeddings for.'
]
document_embeddings = embeddings.embed_documents(documents)# 打印文档嵌入
for i, embedding in enumerate(document_embeddings):print(f"文档 {i+1} 的嵌入:{embedding}")# 为单个查询创建嵌入
query = 'This is a single query.'
query_embedding = embeddings.embed_query(query)# 打印查询嵌入
print(f"查询的嵌入:{query_embedding}")
同时,我们可以使用现有的Elasticsearch客户端连接进行测试,这可用于任何Elasticsearch部署:
# 创建 Elasticsearch 连接
es_connection = Elasticsearch(hosts=['https://es_cluster_url:port'], basic_auth=('user', 'password')
)
# 使用 es_connection 实例化 ElasticsearchEmbeddings
embeddings = ElasticsearchEmbeddings.from_es_connection(model_id,es_connection,
)
# 为多个文档创建嵌入
documents = ['This is an example document.', 'Another example document to generate embeddings for.'
]
document_embeddings = embeddings.embed_documents(documents)# 打印文档嵌入
for i, embedding in enumerate(document_embeddings):print(f"文档 {i+1} 的嵌入:{embedding}")# 为单个查询创建嵌入
query = 'This is a single query.'
query_embedding = embeddings.embed_query(query)# 打印查询嵌入
print(f"查询的嵌入:{query_embedding}")
参考文献:
[1] LangChain 🦜️🔗 中文网,跟着LangChain一起学LLM/GPT开发:https://www.langchain.com.cn/
[2] LangChain中文网 - LangChain 是一个用于开发由语言模型驱动的应用程序的框架:http://www.cnlangchain.com/
相关文章:
-[文本嵌入模型Ⅰ])
自然语言处理从入门到应用——LangChain:模型(Models)-[文本嵌入模型Ⅰ]
分类目录:《自然语言处理从入门到应用》总目录 本文将介绍如何在LangChain中使用Embedding类。Embedding类是一种与嵌入交互的类。有很多嵌入提供商,如:OpenAI、Cohere、Hugging Face等,这个类旨在为所有这些提供一个标准接口。 …...

使用Gradio构建生成式AI应用程序; Stability AI推出Stable Diffusion XL 1.0
🦉 AI新闻 🚀 Stability AI推出最先进的AI工具Stable Diffusion XL 1.0 摘要:Stability AI宣布推出Stable Diffusion XL 1.0,该版本是其迄今为止最先进的AI工具。Stable Diffusion XL 1.0提供更鲜艳、更准确的图片生成ÿ…...

Java 递归计算斐波那契数列指定位置上的数字
Java 递归计算斐波那契数列指定位置上的数字 一、原理二、代码实现三、运行结果 一、原理 斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为…...

ai数字人透明屏的应用场景有哪些?
AI数字人透明屏的应用场景: 银行、保险、售楼处等接待场景:AI数字人透明屏可以作为接待员,提供详细的信息和导航,提高客户体验和服务效率。 商业街、购物中心等场所:AI数字人透明屏可以作为导购员,提供商品…...

一、1、Hadoop的安装与环境配置
安装JDK: 首先检查Java是否已经安装: java -version 如果没有安装,点击链接https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 并选择相应系统以及位数下载(本文选择jdk-8u381-linux-x64…...
:论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失)
剑指YOLOv7改进最新MPDIoU损失函数(23年7月首发论文):论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失
💡本篇内容:剑指YOLOv7改进最新MPDIoU损失函数(23年7月首发论文):论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失 💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可 💡:重点:该专栏《剑指YOLOv7原…...
)
前端JavaScript面试100问(上)
1、解释一下什么是闭包 ? 闭包:就是能够读取外层函数内部变量的函数。闭包需要满足三个条件: 访问所在作用域;函数嵌套;在所在作用域外被调用 。 优点: 可以重复使用变量,并且不会造成变量污染 。缺点&am…...

C语言第九课------------------数组----------------C中之将
作者前言 作者介绍: 作者id:老秦包你会, 简单介绍: 喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 个人主页::小小页面 gitee页面:秦大大 一个爱分享的小博主 欢迎小可爱…...
MySQL的安装
掌握在Windows系统中安装MySQL数据库 MySQL的介绍 MySQL数据库管理系统由瑞典的DataKonsultAB公司研发,该公司被Sun公司收购,现在Sun公司又被Oracle公司收购,因此MySQL目前属于 Oracle 旗下产品。MySQL 软件采用了双授权政策,分…...
在Chrome(谷歌浏览器)中安装Vue.js devtools开发者工具及解决Vue.js not detected报错
文章目录 一、Vue.js devtools开发者工具安装1.打开谷歌浏览器——点击扩展程序——选择管理扩展程序2.先下载添加一个谷歌助手到扩展程序中(根据提示进行永久激活)3.点击谷歌浏览器的应用商店4.输入Vue.js devtools——搜索——选择下载 二、解决Vue.js…...
算法在MovieLens ml-100k数据集上构建精确的推荐系统:深入理解GroupLens数据的操作)
用Python实现概率矩阵分解(PMF)算法在MovieLens ml-100k数据集上构建精确的推荐系统:深入理解GroupLens数据的操作
第一部分:推荐系统的重要性以及概率矩阵分解的介绍 在如今的数字化时代,推荐系统在我们的日常生活中起着重要的作用。无论我们在哪个电商网站上购物,哪个音乐平台听歌,或者在哪个电影网站看电影,都会看到推荐系统的身影。它们根据我们的喜好和行为,向我们推荐可能喜欢的…...

WPF icon的设置
想给控件设置个圆形图片,代码如下: <Setter Property"Icon"><Setter.Value><Image Source"/WpfApp1;component/Resource/1.ico" Width"16" Height"16"/></Setter.Value></Setter&…...

使用frp中的xtcp映射穿透指定服务实现不依赖公网ip网速的内网穿透p2p
使用frp中的xtcp映射穿透指定服务实现不依赖公网ip网速的内网穿透p2p 管理员Ubuntu配置公网服务端frps配置service自启(可选) 配置内网服务端frpc配置service自启(可选) 使用者配置service自启(可选) 效果 通过frp实现内网client访问另外一个内网服务器 管理员 1)…...
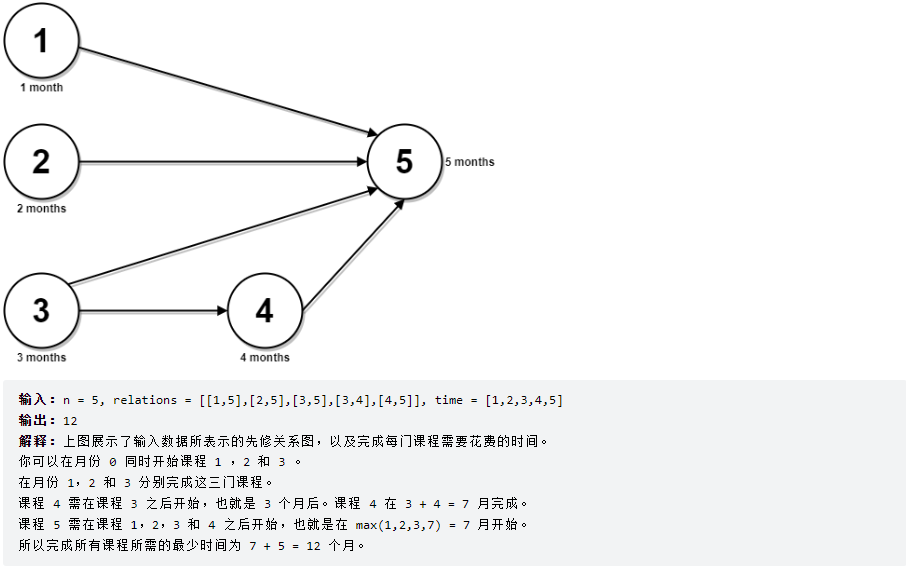
2023-07-28 LeetCode每日一题(并行课程 III)
2023-07-28每日一题 一、题目编号 2050. 并行课程 III二、题目链接 点击跳转到题目位置 三、题目描述 给你一个整数 n ,表示有 n 节课,课程编号从 1 到 n 。同时给你一个二维整数数组 relations ,其中 relations[j] [prevCoursej, next…...
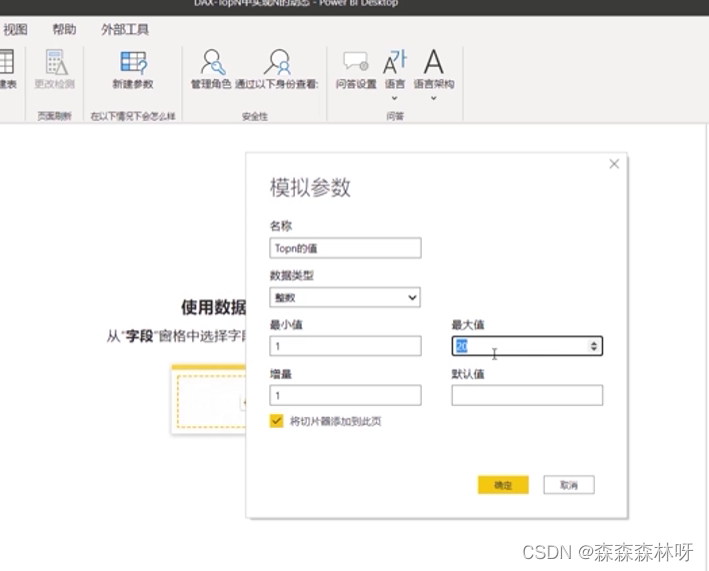
8.11 PowerBI系列之DAX函数专题-TopN中实现N的动态
需求 实现 1 ranking by amount rankx(allselected(order_2[产品名称]),[total amount]) 2 rowshowing_boolean var v_ranking [ranking by amount] var v_topN-no [topN参数 值] var v_result int( v_ranking < v_topN_no) return v_result 3 将度量值2放入视觉对象筛…...

后端性能测试的类型
目录 性能测试的类型 负载测试(load testing) 压力测试(Stress Testing) 可扩展性测试( 尖峰测试(Spike Testing) 耐久性测试(Endurance Testing) 并发测试(Concurrency Testing) 容量测试(Capacity Testing) 资料获取方法 性能测试的类型 性能测试:确定软…...

关闭Tomcat的日志输出
要关闭Tomcat的日志输出,您可以在Tomcat的配置文件中进行相应的调整。具体地说,您可以通过修改logging.properties文件来关闭Tomcat的日志输出。这个文件通常位于Tomcat的conf目录下。请按照以下步骤进行: 打开Tomcat安装目录,找…...

express 路由匹配和数据获取
express配置路由只需要通过app.method(url,func)来配置,其中url配置和其中的参数获取方法不同 直接写全路径 路由中允许存在. get请求传入的参数 router.get("/home", (req, res) > {res.status(200).send(req.query); });通过/home?a1会收到对象…...

62 | Python 操作 PDF
文章目录 Python 操作 PDF 教程1. 安装 PyPDF22. 读取 PDF 文件3. 创建 PDF 文件4. 修改 PDF 文件练习题1. 创建一个新的 PDF 文件,其中包含两个页面。第一个页面包含一段文本和一张图片,第二个页面包含一个表格。2. 打开练习题中创建的 PDF 文件,并将第一个页面中的文本修改…...

[SQL挖掘机] - 左连接: left join
介绍: 左连接是一种多表连接方式,它以左侧的表为基础,并返回满足连接条件的匹配行以及左侧表中的所有行,即使右侧的表中没有匹配的行。左连接将左表的每一行与右表进行比较,并根据连接条件返回结果集。 左连接的工作原理如下&am…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

适合地产人用的中介房源管理系统
在房产经纪行业,房源管理与客源管理是经纪人日常工作的核心,直接影响业务效率与成交转化。选择一套适配行业需求的中介房源管理系统,能帮助中介团队规范流程、降低运营成本、大幅提升业绩。今天我们以客观视角,详细解析全房源系统…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

电子商务设计师软考备战:特别篇 - 综合模拟与备考策略
1. 考试形式与内容结构1.1 考试基本信息考试科目与时间基础知识考试:上午9:00-11:30(150分钟)应用技术考试:下午2:00-4:30(150分钟)题型与分值分布上午考试(基础知识): -…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

通过用量看板分析团队大模型API消耗发现优化调用策略的机会
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过用量看板分析团队大模型API消耗发现优化调用策略的机会 作为团队的技术负责人,确保大模型API调用在满足业务需求的…...

TVA注意力层INT8量化配置技巧
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...