解决分类任务中数据倾斜问题
大家好,在处理文本分类任务时,基准测试流行的自然语言处理架构的性能是建立对可用选项的理解的重要步骤。在这里,本文将深入探讨与分类相关的最常见的挑战之一——数据倾斜。如果你曾经将机器学习(ML)应用于真实世界的分类数据集,那么你可能已经很熟悉这个问题了。
了解数据分类中的不平衡问题
在数据分类中,我们经常关注数据点在不同类别中的分布情况。平衡的数据集在所有类别中的数据点数大致相同,因此更易于处理,然而现实世界中的数据集往往是不平衡的。
不平衡数据可能会导致问题,因为模型可能会学习用最常见的类来标注所有内容,而忽略实际输入。如果主要类别非常普遍,以至于模型不会因为将少数类别错误分类而受到太多惩罚这种情况。此外,代表性不足的类别可能没有足够的数据供模型学习有意义的模式。
不平衡是数据的一个特征,一个很好的问题是,我们是否要对其采取任何措施。有一些技巧可以让模型的训练过程变得更容易,可以选择对训练过程或数据本身进行操作,让模型知道哪些类对我们来说特别重要,但这应该以业务需求或领域知识为依据。接下来,我们将详细讨论这些技巧和操作。
为了说明解决数据不平衡的不同技术的效果,我们将使用包含747条垃圾短信和4827条正常短信的sms-spam数据集。虽然只有两类,但为了更好地泛化,我们将把该任务视为多类分类问题,将使用roberta-base模型。
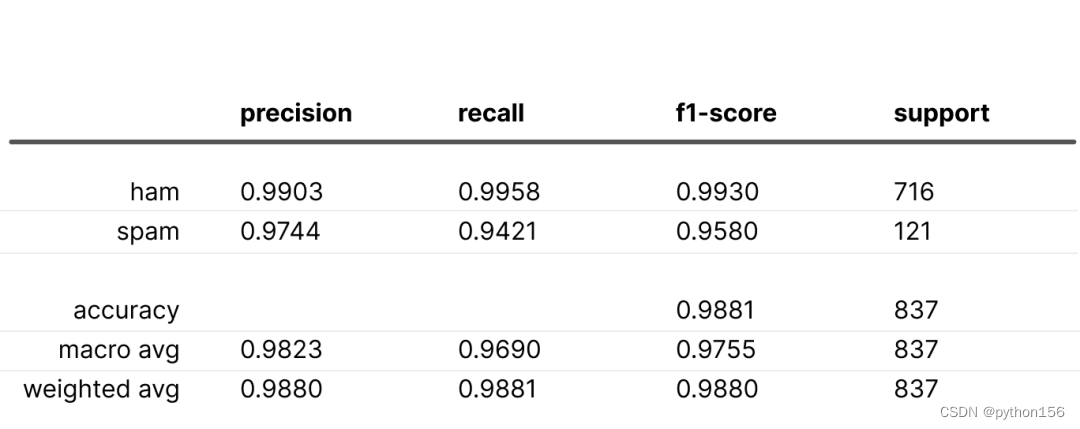
“Safe” 技巧
偏置初始化
本文的第一项技术是从一开始就让模型了解数据分布。我们可以通过相应地初始化最终分类层的偏置来传播这一知识。Andrej Karpathy在他的《训练神经网络的秘诀》(A Recipe for Training Neural Networks)中分享了这一技巧,它有助于模型从知情的角度出发。在我们的多分类案例中,我们使用softmax作为最终激活函数,我们希望模型在初始化时的输出能够反映数据分布。为了实现这一目标,我们需要解决以下问题:
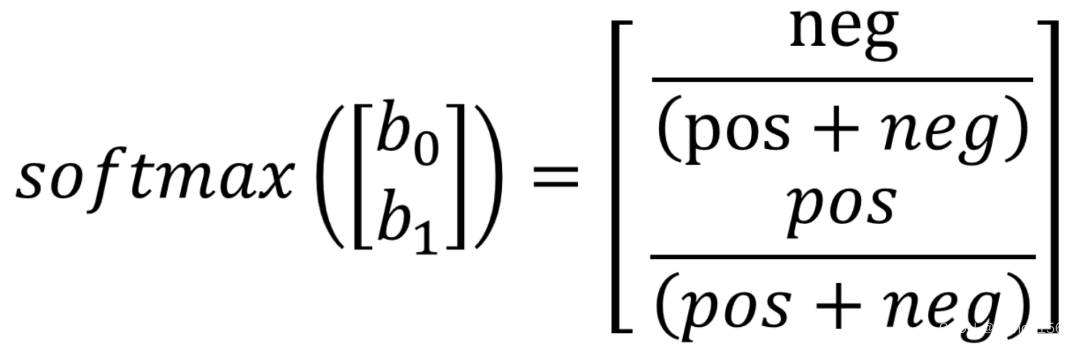
![]()
然后有 :
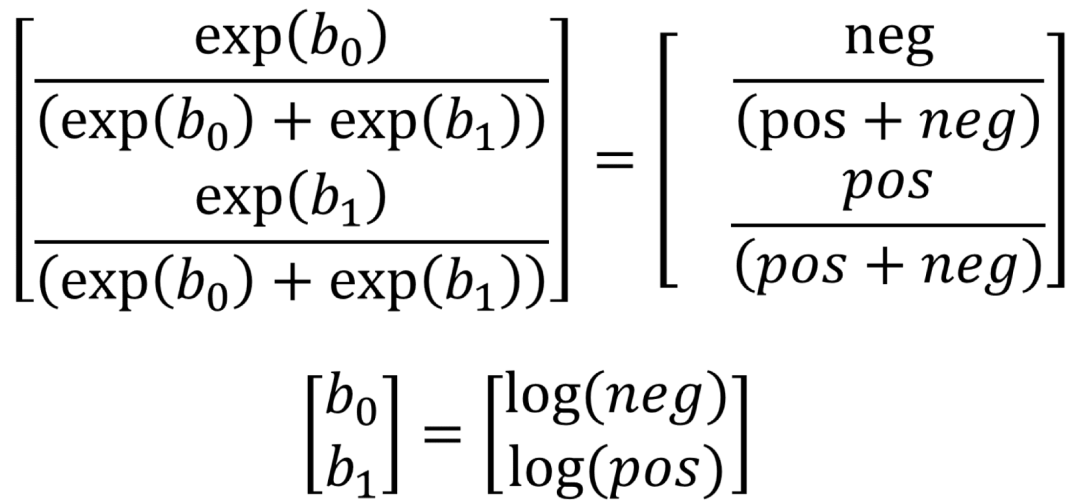
其中,b0和b1分别为负类和正类的偏置,neg和pos分别为负类和正类中元素的数量。通过这种初始化,所有指标都得到了简单的改善。
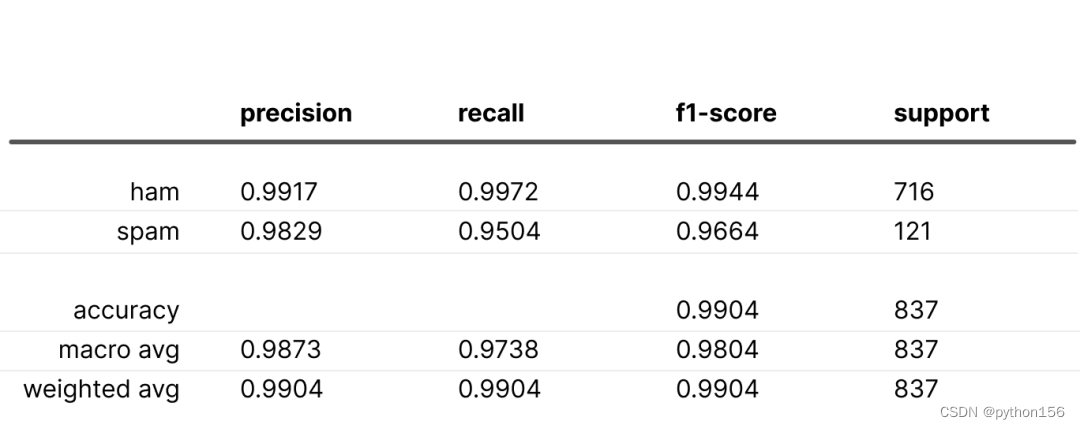
下采样和上加权/上采样和下加权
这些技术也能有效解决类不平衡问题。二者的概念相似,但执行方式不同。下采样和上加权涉及减少主要类的规模以平衡分布,同时在训练过程中为该类的示例分配更大的权重。上加权可确保输出概率仍然代表观察到的数据分布。相反,上采样和下加权则需要增加代表性不足的类别的规模,并按比例降低其权重。
下采样和上加权的结果:
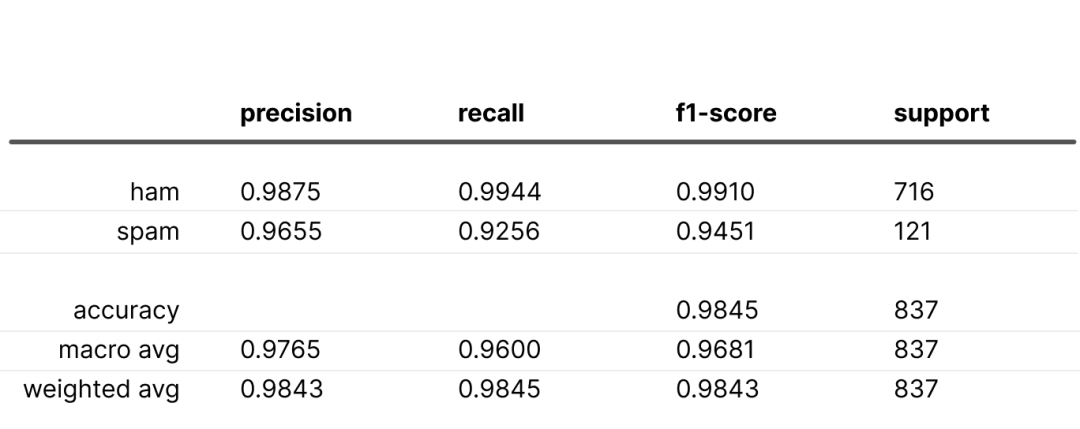
上采样和下加权的结果: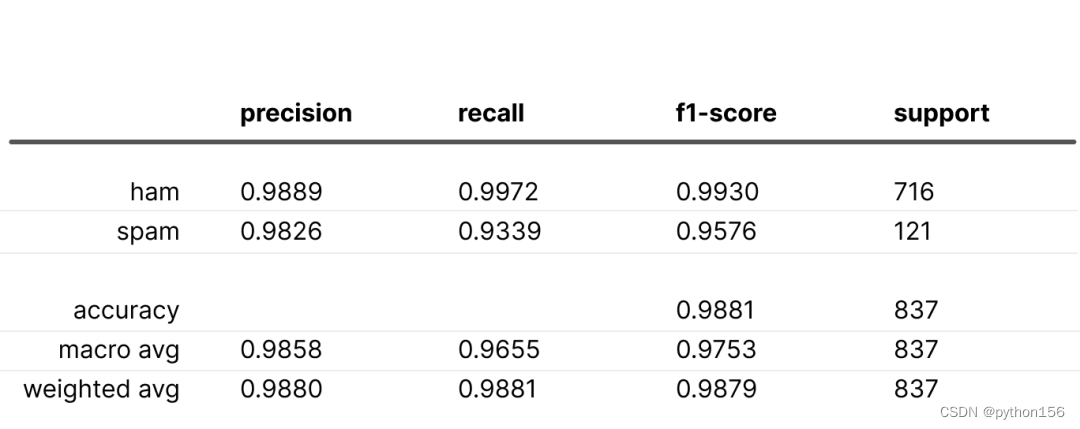
在这两种情况下,“垃圾邮件”的召回率都有所下降,这可能是因为“正常邮件”的权重是“垃圾邮件”权重的两倍。
“Not-so-safe”的技巧
众所周知,存在着方法可以故意改变输出概率分布,从而给代表性不足的类别带来优势。通过使用这些技术,我们明确地向模型发出信号,表明某些类别至关重要,不应被忽视。这通常是由业务需求驱动的,比如检测金融欺诈或攻击性评论,这比意外地错误标记好的示例更重要。当目标是提高特定类别的召回率时,即使牺牲其他指标也要应用这些技术。
加权法是为不同类别的样本损失值分配不同的权重。这是一种有效且适应性强的方法,因为它可以让你指出每个类别对模型的重要性。以下是单个训练样本的多类别加权交叉熵损失公式:
![]()
其中,pytrue表示真实类别的概率,wytrue是该类别的权重。
确定权重的一个很好的默认方法是使用类别频率倒数:
![]()
其中,N是数据集的总条目数,c是类别计数,ni是第i个类别的元素计数
权重计算如下:{'ham': 0.576, 'spam': 3.784}
以下是使用这些权重得出的指标:
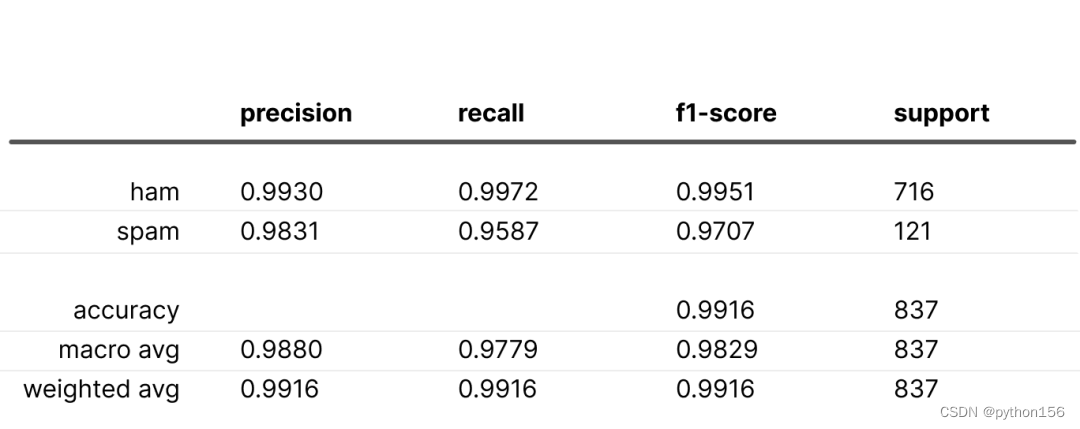
指标超过基线方案。虽然这种情况可能会发生,但并非总是如此。
不过,如果避免特定类的漏检至关重要,可以考虑增加类别的权重,这样可能会提高类别的召回率。让我们尝试使用权重{"ham": 0.576, "spam": 10.0}来查看结果。
结果如下:

正如预期的那样,“垃圾邮件”的召回率提高了,但精确度却下降了。与使用类别频率倒数权重相比,F1分数有所下降。这证明了基本损失加权的潜力。即使对于平衡数据,加权也可能有利于召回关键类别。
上采样和下采样虽然与前面讨论的方法类似,但它们不包括加权步骤。下采样可能会导致数据丢失,而上采样可能会导致过度拟合上采样类别。虽然这两种方法都有帮助,但加权通常是更有效、更透明的选择。
必要时可以解决数据不平衡问题,有些技术会有意改变数据分布,只有在必要时才可使用。虽然本文讨论了概率问题,但最终的性能指标才是对业务最重要的指标。如果离线测试表明某个模型能增加价值,那么就在生产中进行测试。在实验中,本文使用了Toloka ML平台,它提供了一系列随时可用的模型,可以为ML项目提供一个良好的开端。
总的来说,考虑到训练ML模型的数据分布至关重要。训练数据必须代表真实世界的分布,模型才能有效工作。如果数据本身不平衡,模型应考虑到这一点,以便在实际场景中表现良好。
相关文章:
解决分类任务中数据倾斜问题
大家好,在处理文本分类任务时,基准测试流行的自然语言处理架构的性能是建立对可用选项的理解的重要步骤。在这里,本文将深入探讨与分类相关的最常见的挑战之一——数据倾斜。如果你曾经将机器学习(ML)应用于真实世界的…...

Vue3 word如何转成pdf代码实现
🙂博主:锅盖哒 🙂文章核心:word如何转换pdf 目录 1.前端部分 2.后端部分 在Vue 3中,前端无法直接将Word文档转换为PDF,因为Word文档的解析和PDF的生成通常需要在后端进行。但是,你可以通过Vu…...

fpga--流水灯
fpga流水灯的设计 思路:外部时钟频率50mhz,若要实现每隔0.5s闪烁一次,则使用内部计数器计数到24999999拉高一个周期电平,当电平被拉高的时候,进行LED灯电平的设置,每次检测到高电平,就进行一位…...
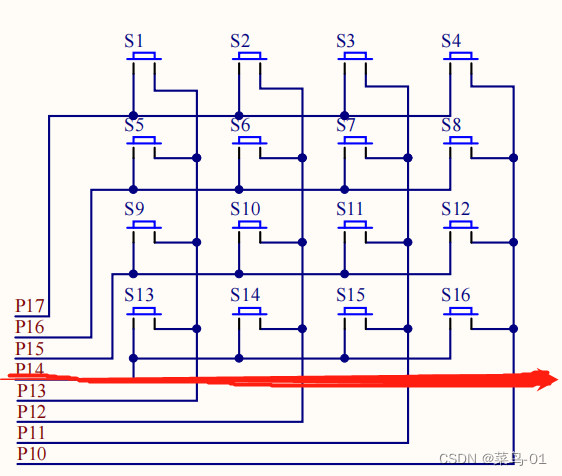
51单片机:数码管和矩阵按键
目录 一:动态数码管模块 1:介绍 2:共阴极和共阳极 A:共阴极 B:共阳极 C:转化表 3:74HC138译码器 4:74HC138译码器控制动态数码管 5:数码管显示完整代码 二:矩阵按键模块 1:介绍 2:原理图 3:矩阵按键代码 一:动态数码管模块 1:介绍 LED数码管:数码管是一种…...
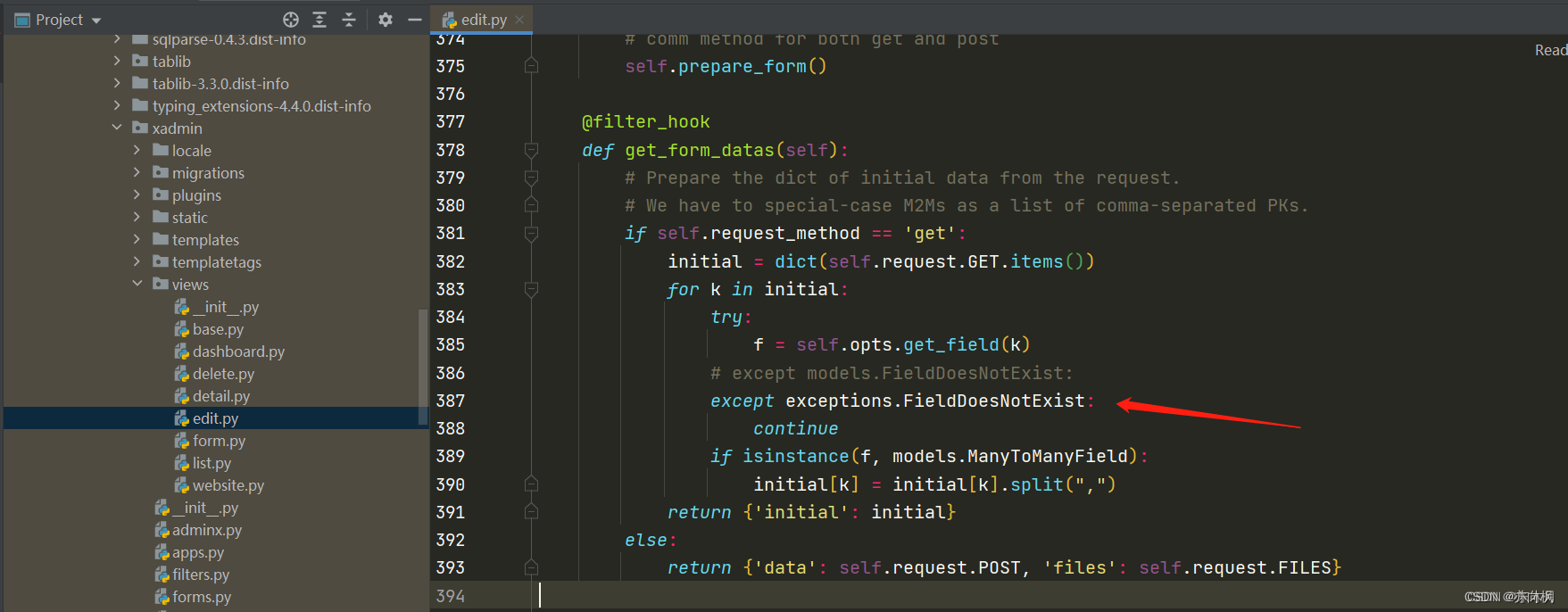
Django + Xadmin 数据列表复选框显示为空,怎么修复这个问题?
问题描述: 解决方法: 后续发现的报错: 解决方案: 先根据报错信息定位到源代码: 在该文件顶部写入: from django.core import exceptions然后把: except models.FieldDoesNotExist修改为&…...

《向量数据库指南》——Milvus Cloud2.2.12 易用性,可视化,自动化大幅提升
Milvus Cloud又迎版本升级,三大新特性全力加持,易用性再上新台阶! 近期,Milvus Cloud上线了 2.2.12 版本,此次更新不仅一次性增加了支持 Restful API、召回原始向量、json_contains 函数这三大特性,还优化了 standalone 模式下的 CPU 使用、查询链路等性能,用一句话总…...

Python web实战 | 用 Flask 框架快速构建 Web 应用【实战】
概要 Python web 开发已经有了相当长的历史,从最早的 CGI 脚本到现在的全栈 Web 框架,现在已经成为了一种非常流行的方式。 Python 最早被用于 Web 开发是在 1995 年(90年代早期),当时使用 CGI 脚本编写动态 Web 页面…...
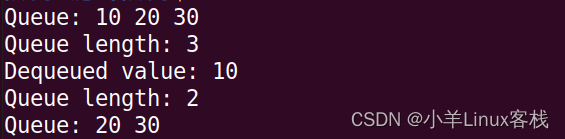
十、数据结构——链式队列
数据结构中的链式队列 目录 一、链式队列的定义 二、链式队列的实现 三、链式队列的基本操作 ①初始化 ②判空 ③入队 ④出队 ⑤获取长度 ⑥打印 四、循环队列的应用 五、总结 六、全部代码 七、结果 在数据结构中,队列(Queue)是一种常见…...
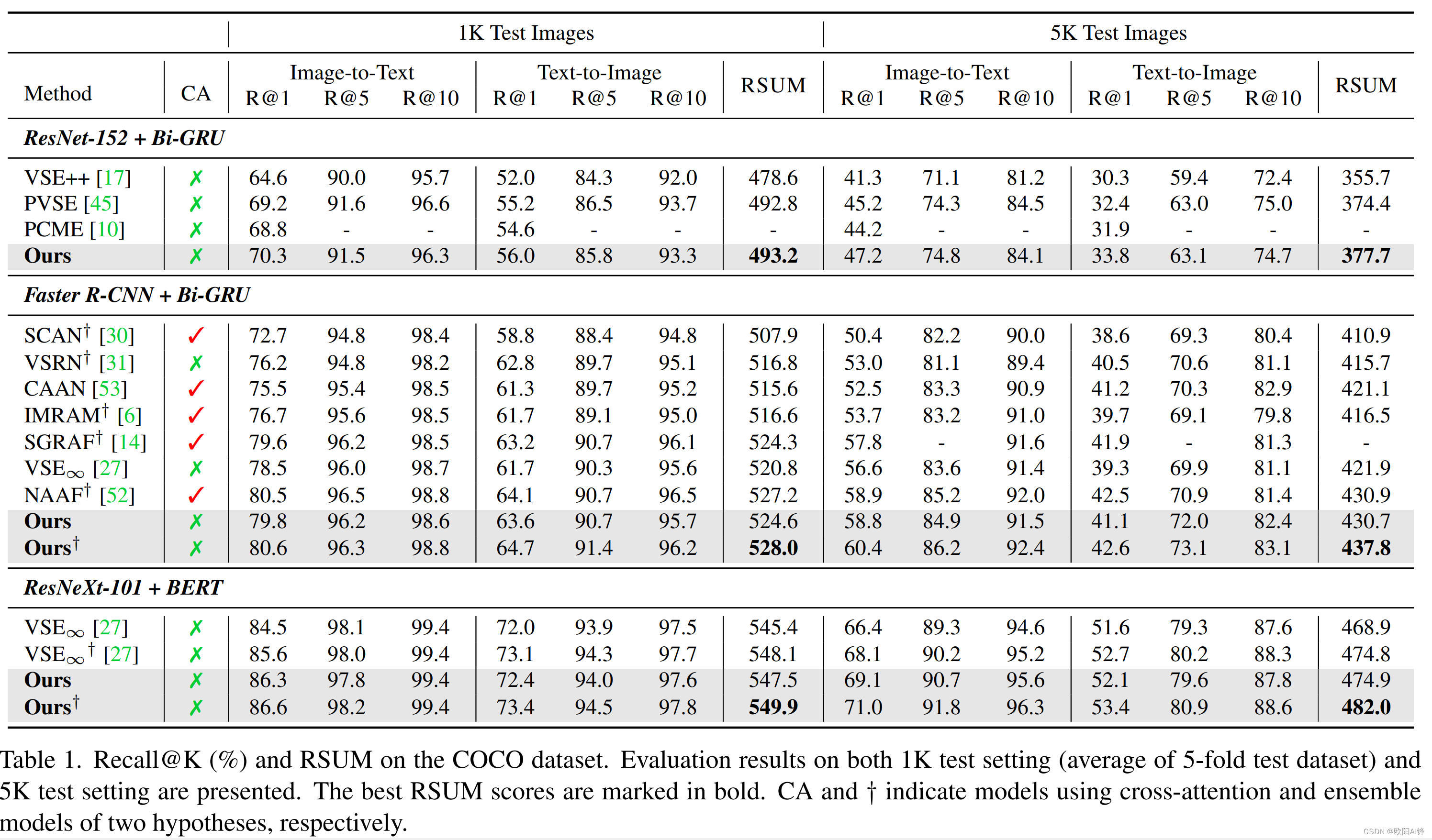
Improving Cross-Modal Retrieval with Set of Diverse Embeddings
框架图: Using Triplet Loss: Smooth-Chamfer similarity Using Log-Sum-Exp,...

物联网阀控水表计量准确度如何?
物联网阀控水表是一种新型的智能水表,它采用了先进的物联网技术,可以通过远程控制和监测水表的运行情况,实现更加精准的水量计量和费用结算。那么,物联网阀控水表的计量准确度如何呢?下面我们将从以下几个方面进行详细…...
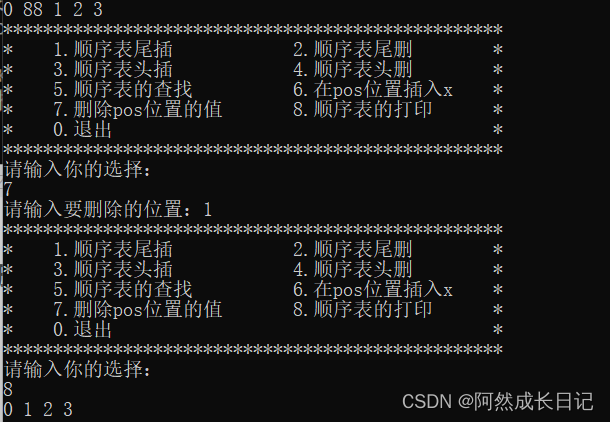
【C语言数据结构】模拟·顺序表·总项目实现
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...
-[文本嵌入模型Ⅰ])
自然语言处理从入门到应用——LangChain:模型(Models)-[文本嵌入模型Ⅰ]
分类目录:《自然语言处理从入门到应用》总目录 本文将介绍如何在LangChain中使用Embedding类。Embedding类是一种与嵌入交互的类。有很多嵌入提供商,如:OpenAI、Cohere、Hugging Face等,这个类旨在为所有这些提供一个标准接口。 …...

使用Gradio构建生成式AI应用程序; Stability AI推出Stable Diffusion XL 1.0
🦉 AI新闻 🚀 Stability AI推出最先进的AI工具Stable Diffusion XL 1.0 摘要:Stability AI宣布推出Stable Diffusion XL 1.0,该版本是其迄今为止最先进的AI工具。Stable Diffusion XL 1.0提供更鲜艳、更准确的图片生成ÿ…...

Java 递归计算斐波那契数列指定位置上的数字
Java 递归计算斐波那契数列指定位置上的数字 一、原理二、代码实现三、运行结果 一、原理 斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为…...

ai数字人透明屏的应用场景有哪些?
AI数字人透明屏的应用场景: 银行、保险、售楼处等接待场景:AI数字人透明屏可以作为接待员,提供详细的信息和导航,提高客户体验和服务效率。 商业街、购物中心等场所:AI数字人透明屏可以作为导购员,提供商品…...

一、1、Hadoop的安装与环境配置
安装JDK: 首先检查Java是否已经安装: java -version 如果没有安装,点击链接https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 并选择相应系统以及位数下载(本文选择jdk-8u381-linux-x64…...
:论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失)
剑指YOLOv7改进最新MPDIoU损失函数(23年7月首发论文):论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失
💡本篇内容:剑指YOLOv7改进最新MPDIoU损失函数(23年7月首发论文):论文实测YOLOv7模型涨点,超越现有多种G/D/C/EIoU,高效准确的边界框回归的损失 💡🚀🚀🚀本博客 改进源代码改进 适用于 YOLOv7 按步骤操作运行改进后的代码即可 💡:重点:该专栏《剑指YOLOv7原…...
)
前端JavaScript面试100问(上)
1、解释一下什么是闭包 ? 闭包:就是能够读取外层函数内部变量的函数。闭包需要满足三个条件: 访问所在作用域;函数嵌套;在所在作用域外被调用 。 优点: 可以重复使用变量,并且不会造成变量污染 。缺点&am…...

C语言第九课------------------数组----------------C中之将
作者前言 作者介绍: 作者id:老秦包你会, 简单介绍: 喜欢学习C语言和python等编程语言,是一位爱分享的博主,有兴趣的小可爱可以来互讨 个人主页::小小页面 gitee页面:秦大大 一个爱分享的小博主 欢迎小可爱…...
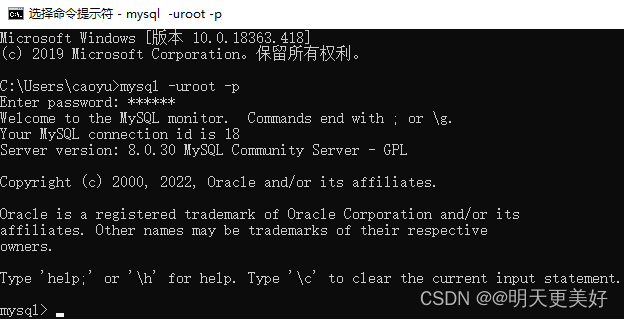
MySQL的安装
掌握在Windows系统中安装MySQL数据库 MySQL的介绍 MySQL数据库管理系统由瑞典的DataKonsultAB公司研发,该公司被Sun公司收购,现在Sun公司又被Oracle公司收购,因此MySQL目前属于 Oracle 旗下产品。MySQL 软件采用了双授权政策,分…...

LLM API安全攻防实战:从提示词注入到自动化测试方案
1. 项目概述:被忽视的LLM API安全前线最近在帮几个团队做上线前的安全审计,发现一个挺有意思的现象:大家对于传统API的鉴权、限流、SQL注入这些常规检查已经形成了肌肉记忆,但一旦涉及到LLM(大语言模型)的A…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

2026在线测评系统十大量表对比:信效度与场景全解析
【30s 核心摘要】2026 年在线测评成人才管理刚需,信效度与场景适配成选型核心。本文聚焦十大量表,从信度、效度、适配场景等维度深度对比,重点解析问卷星、北森、金数据等主流平台的量表能力与落地效果,为企业、高校及机构提供科学…...
)
ThinkPad开机报错0183/0253?别慌,手把手教你搞定EFI变量错误(附BIOS重置教程)
ThinkPad开机报错0183/0253?EFI变量错误全面解决方案当你按下ThinkPad的电源键,期待熟悉的开机画面时,屏幕上却突然跳出一串神秘代码——"0183: Bad CRC of Security Settings in EFI Variable"或"0253: EFI Variable Block D…...

Veo 2胶片质感生成器失效?——深度解析Color Science v2.3内核中被屏蔽的Cinematic Grain Injection层
更多请点击: https://kaifayun.com 第一章:Veo 2胶片质感生成器失效现象全景透视 近期大量用户反馈,Veo 2 胶片质感生成器在调用 generate_film_effect() 接口后返回空纹理、纯灰帧或 HTTP 503 Service Unavailable 错误,且该问题…...

荣耀出征官方网站下载正版手游 翅膀养成细节玩法全方位讲解
玩荣耀出征的玩家都清楚,翅膀不仅是角色的颜值象征,更是提升整体战力的核心途径。很多新手玩家只顾着升级、刷装备,完全忽略翅膀养成,导致等级很高但战力始终上不去。还有不少玩家胡乱合成、盲目进阶,浪费了大量稀有翅…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

高精度光照检测
光线检测仪,kotlin开发,调用手机感光模块检测室内外光照强度,用途多多,我主要用途孩子写作业检测光照保护视力。 食用方法∶打开即测,速度快,无广告,手机平视即可,无须直视光线。 买…...

php有什么版本,php语言有几个版本
php有什么版本,php语言有几个版本PHP的大版本主要分四支:PHP4/PHP5/PHP6/PHP7 其中,PHP4由于太古老、对OO支持不力已基本被淘汰,请无视PHP4。 PHP6由于基本没有生产线上的应用,还基本只是一款概念产品,很多功能已在PHP…...