论文浅尝 | 预训练Transformer用于跨领域知识图谱补全

笔记整理:汪俊杰,浙江大学硕士,研究方向为知识图谱
链接:https://arxiv.org/pdf/2303.15682.pdf
动机
传统的直推式(tranductive)或者归纳式(inductive)的知识图谱补全(KGC)模型都关注于域内(in-domain)数据,而比较少关注模型在不同领域KG之间的迁移能力。随着NLP领域中迁移学习的成功,目前有不少研究使用预训练的语言模型来提高KGC模型的表现,或者同时训练语言模型和KGC模型提升下游NLP任务的表现。尽管这种在结构化的KG和非结构化的文本之间的迁移已经取得了进展,但是关于将模型从一个KG迁移到其他KG的研究还比较少。因此,这项工作的目标是预训练一个Transformer-based可以同时用于transductive和inductive任务的知识图谱补全模型,并且从非结构化文本和结构化KG中同时学习可迁移的知识表示。
贡献
本论文的主要贡献如下:
(1). 提出了一个新的知识图谱补全模型iHT,使用实体的文本信息和实体的邻居进行实体的表示,可以同时用于transductive和inductive KGC;
(2). 在百科全书式大型知识图谱Wikidata5M上进行预训练,预训练的链接预测取得了比传统方法更好的效果;
(3). 将预训练的模型iHT迁移到小型知识图谱上进行微调,取得了比传统模型以及预训练语言模型更好的效果;
方法
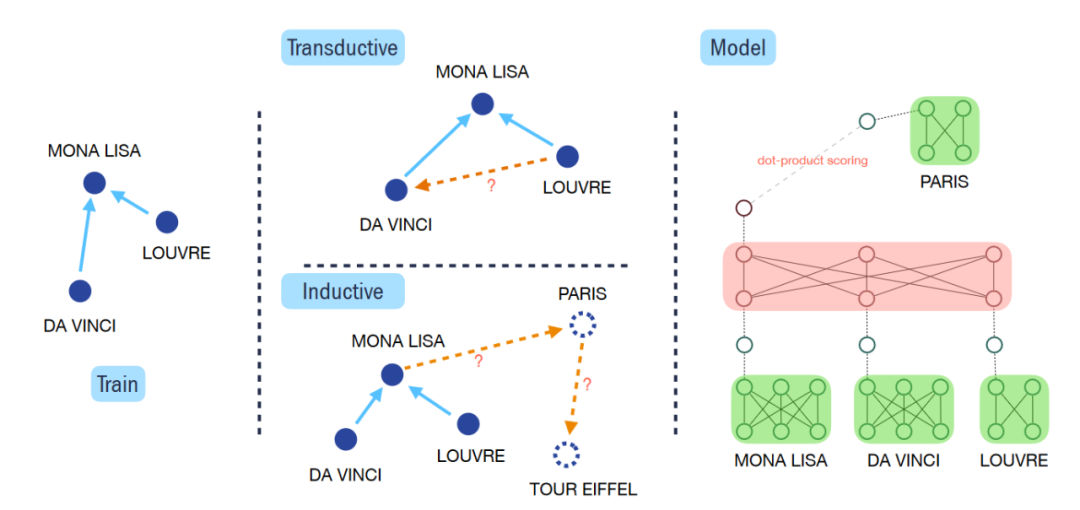
1. 预训练
预训练阶段使用的数据集为Wikidata5M,数据集里面的每个实体都有一段文本描述,作者首先构造了Entity Transformer输入每个实体的文本描述从而得到每个实体的表示。因为有实体文本的存在,所以在inductive KGC任务下,测试中没有见过的实体可以通过文本的内容进行表示。此处Entity Transformer的初始化参数来自于预训练的语言模型BERT,从而更好获取实体文本中蕴含的知识。
在E ntity Transformer之后,作者又设置了Context Transformer。对于一个训练样本(h,r,t)来说,会随机采样K个头实体(h)的邻居以及相连的关系(r)作为这个训练样本的环境信息(Context),Context Transformer的输入为CLS token、h、r,以及h的Context组成的序列。在Context Transformer最后一层GCLS token的embedding将用于之后的链接预测(link predication)。
在link prediction这一步,如果是在训练阶段,每个batch内将会随机采样N个实体作为负样本,将这N个错误的实体与正确的尾实体都和GCLS的embedding计算点乘相似度作为分数,得到N+1维的预测向量,再将此预测向量和one-hot标签计算交叉熵损失。而在预测阶段,这一步将会使用所有的候选实体计算预测分数。
2. 模型迁移
在Wikidata5M上完成iHT的预训练之后,作者将其迁移到小型知识图谱FB15K-237和WN18RR上进行微调。这两个小型KG与预训练的KG存在区别,故可以视为是跨领域的知识图谱补全,虽然FB15K-237中的实体大多数都在Wikidata5M中出现过,但是关系的分布存在区别,作者统计得出在FB15K-237中有80%的头尾实体对是没有在Wikidata5M中出现过的,故也能在一定程度上说明模型的迁移能力;而WN18RR和Wikidata5M的区别会更大,他们的数据源和内容都不一样,因此更能说明模型在不同领域KG之间的迁移能力。
实验
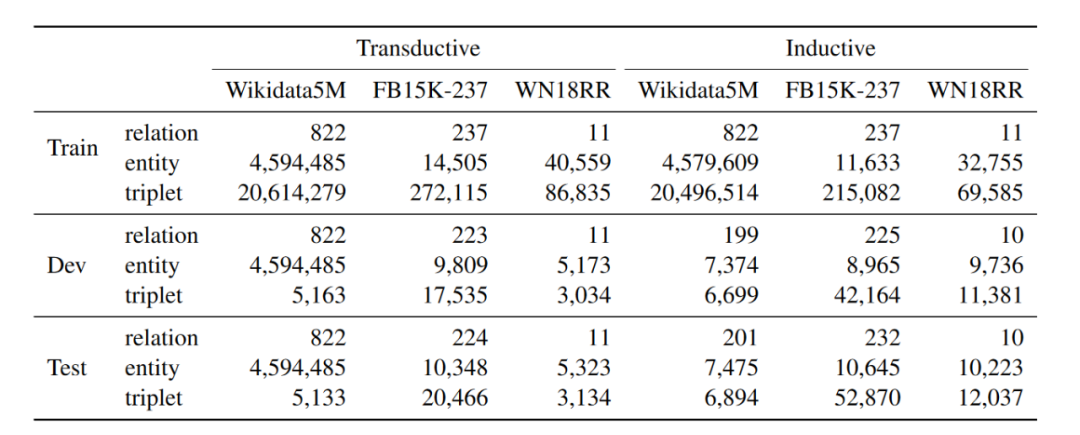
本文在预训练和迁移实验中分别用到了Wikidata5M、FB15K-237和WN18RR三个数据集,并且每个数据集都有transductive和inductive两个版本,数据集的统计信息如下:
实验的部分参数设置如下:

1. 预训练实验
在预训练阶段,作者测试了模型的表现能力,在transductive设定下的实验结果为:
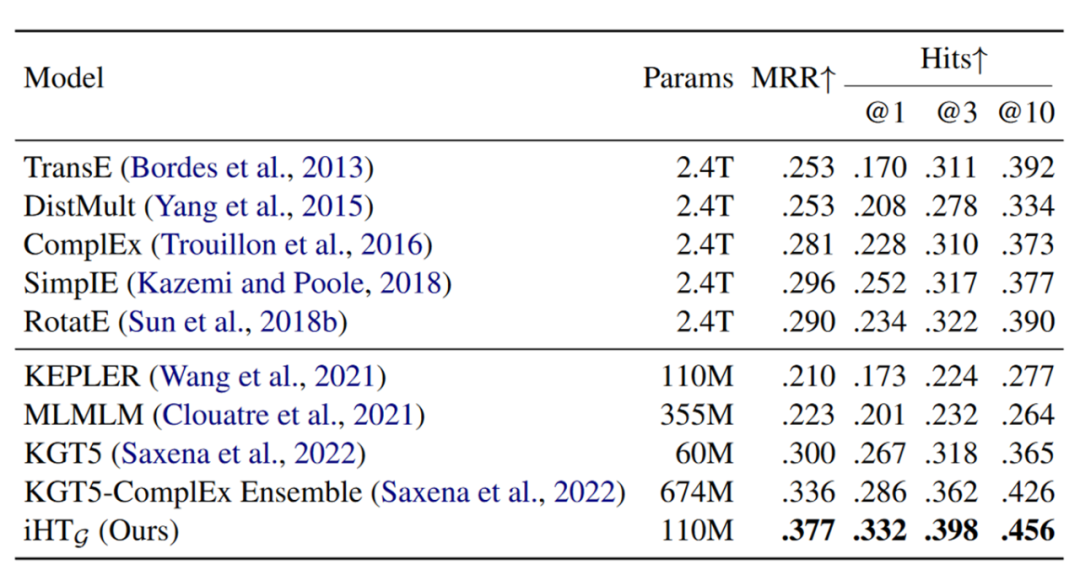
表格的上半部分为传统的KGE模型,下半部分为Transformer-based并且使用了数据集中文本信息的模型,这些Transformer-based模型与本文所提出的模型的主要区别在于Decoder部分,例如MLMLM和KGT5都利用语言建模目标的分布来估计目标实体的可能性,而KEPLER使用类似TransE的评分函数。可以看出不管与哪种模型比较,本文的新模型iHT都取得了最优的效果。在inductive设定下,本文的模型iHT也依然取得了最优效果,具体表现如下所示:
随后作者做了预训练阶段的消融实验,结果如下表所示:
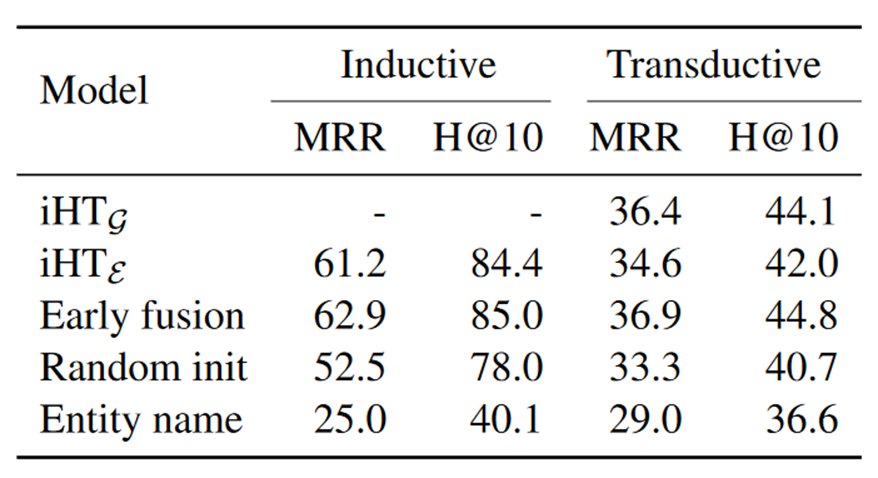
为了节约时间,作者在消融实验阶段只设置了5个epoch,所以完整实验结果会与主实验存在微小差异,但并不影响对于模型效果影响因素的探究。第一行是在Context Transformer中使用了头实体邻居信息的结果;第二行是没有使用头实体邻居信息的结果,可以看出在Transductive情境下实体的邻居信息对于实验效果起到了一定程度的贡献;第三行Early Fusion代表着在Entity Transformer中融入关系信息(具体实现方法论文中未详细阐述),可以看出提前给模型关于关系的信息可以提高模型在KGC任务上的表现,但这也会带来效率的下降,因此是否使用提前使用关系信息可以视为在模型表现和模型效率之间的权衡;第四行Random init代表不使用预训练的语言模型BERT进行参数初始化,而是使用参数随机初始化的Transformer模型,在给定的训练epoch下,模型的表现出现了较大程度的下降,因此可以证明预训练的语言模型在训练资源有限的情况下可以帮助理解实体的文本信息从而提高KGC模型的表现;最后一行Entity name代表的是实体的文本类型对于模型性能的影响,在消融实验中作者将实体的文本替换为长度更短、信息更少的实体名称,结果实验效果出现了最大幅度的下降。从上可以看出,在作者设计的模型中,预训练语言模型以及语料信息起到非常大的作用。
2. 迁移实验
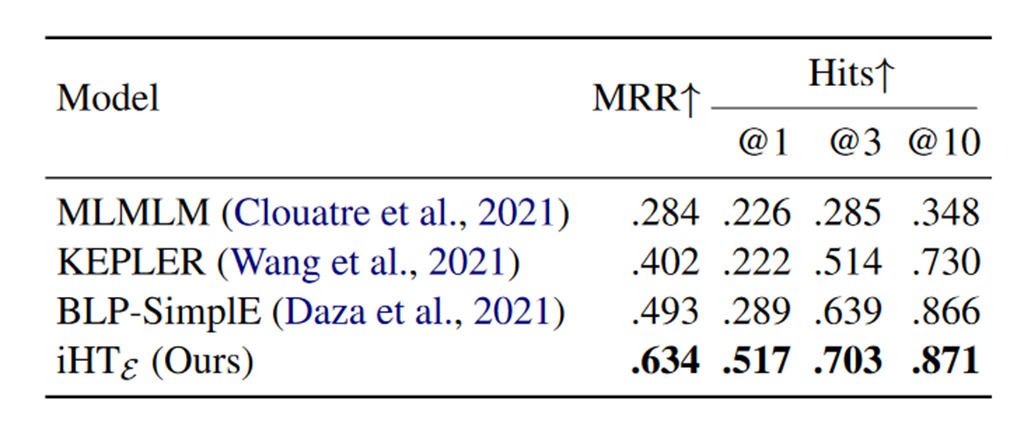
作者将预训练之后的模型iHT在两个小型知识图谱上进行了微调,并测试了链接预测的实验结果,如下表所示:
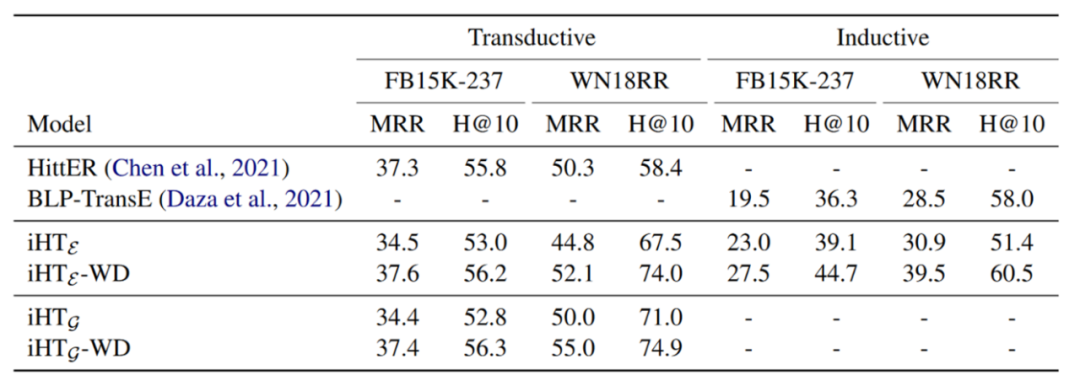
作者对比了两个从头训练的baseline模型,并对比了有无Wikidata5M预训练的模型,表格中WD代表使用在Wikidata5M上预训练过的模型进行微调的测试结果,未带WD的实验结果为直接使用预训练的语言模型BERT进行微调的结果,可以看出使用大型知识图谱预训练过的模型会比原始的BERT效果更好一点,说明了在一个KG上预训练然后迁移到另外一个KG上会比直接使用预训练的语言模型迁移到KG上效果更好。
论文还进一步探究在迁移实验下不同的训练数据量对于模型表现的影响,实验结果对下表所示:
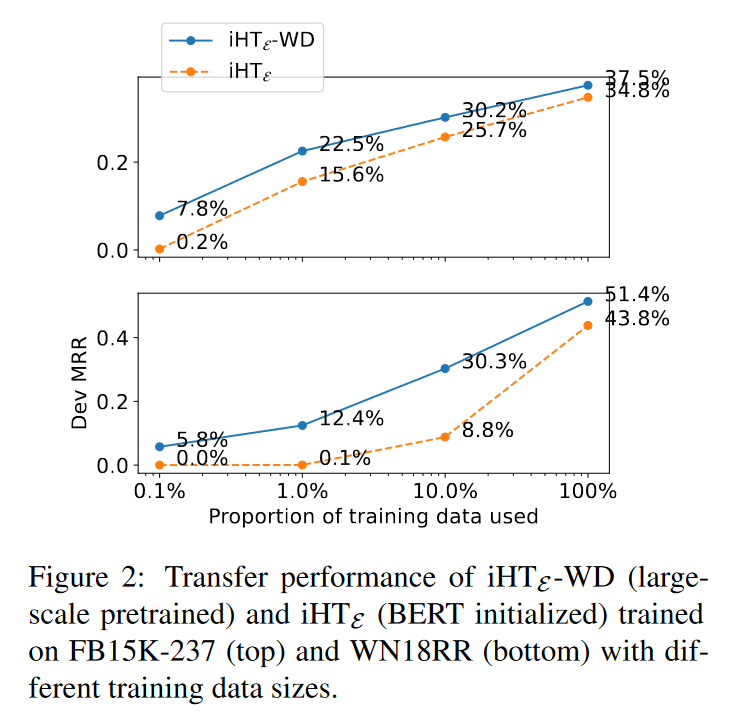
在任何体量的训练数据下,使用Wikidata5M大型知识图谱预训练的模型的链接预测效果都比不进行预训练的效果更好,值得注意的是,在WN18RR数据集中使用10%的训练数据原模型就可以达到0.3以上的MRR,对比使用全量训练数据且未经KG预训练的语言模型的MRR(0.438),已经可以达到其70%以上的效果。可见在大型知识图谱上进行预训练有望减少下游迁移任务的训练数据量要求。
总结
这篇论文提出了一个Transformer-based可以用于inductive KGC和transductive KGC的模型,模型适用于有实体文本信息的数据。在这样的设定下,Wikidata5M上的预训练结果不管在transuctive还是inductive情境下都取得了SOTA效果。最后将Wikidata5M上预训练过的模型迁移到了FB15K-237和WN18RR上进行微调,证明了使用语言模型在大型KG上进行预训练之后,可以提升它在其他领域KG上的表现。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
相关文章:
论文浅尝 | 预训练Transformer用于跨领域知识图谱补全
笔记整理:汪俊杰,浙江大学硕士,研究方向为知识图谱 链接:https://arxiv.org/pdf/2303.15682.pdf 动机 传统的直推式(tranductive)或者归纳式(inductive)的知识图谱补全(KGC)模型都关注于域内(in-domain)数据,而比较少关…...
)
算法工程师-机器学习面试题总结(2)
线性回归 线性回归的基本思想是? 线性回归是一种用于建立和预测变量之间线性关系的统计模型。其基本思想是假设自变量(输入)和因变量(输出)之间存在线性关系,通过建立一个线性方程来拟合观测数据ÿ…...

低成本32位单片机空调内风机方案
空调内风机方案主控芯片采用低成本32位单片机MM32SPIN0230,内部集成了具有灵动特色的电机控制功能:高阶4路互补PWM、注入功能的高精度ADC、轨到轨运放、轮询比较器、32位针对霍尔传感器的捕获时钟、以及硬件除法器和DMA等电机算法加速引擎。 该方案具有…...
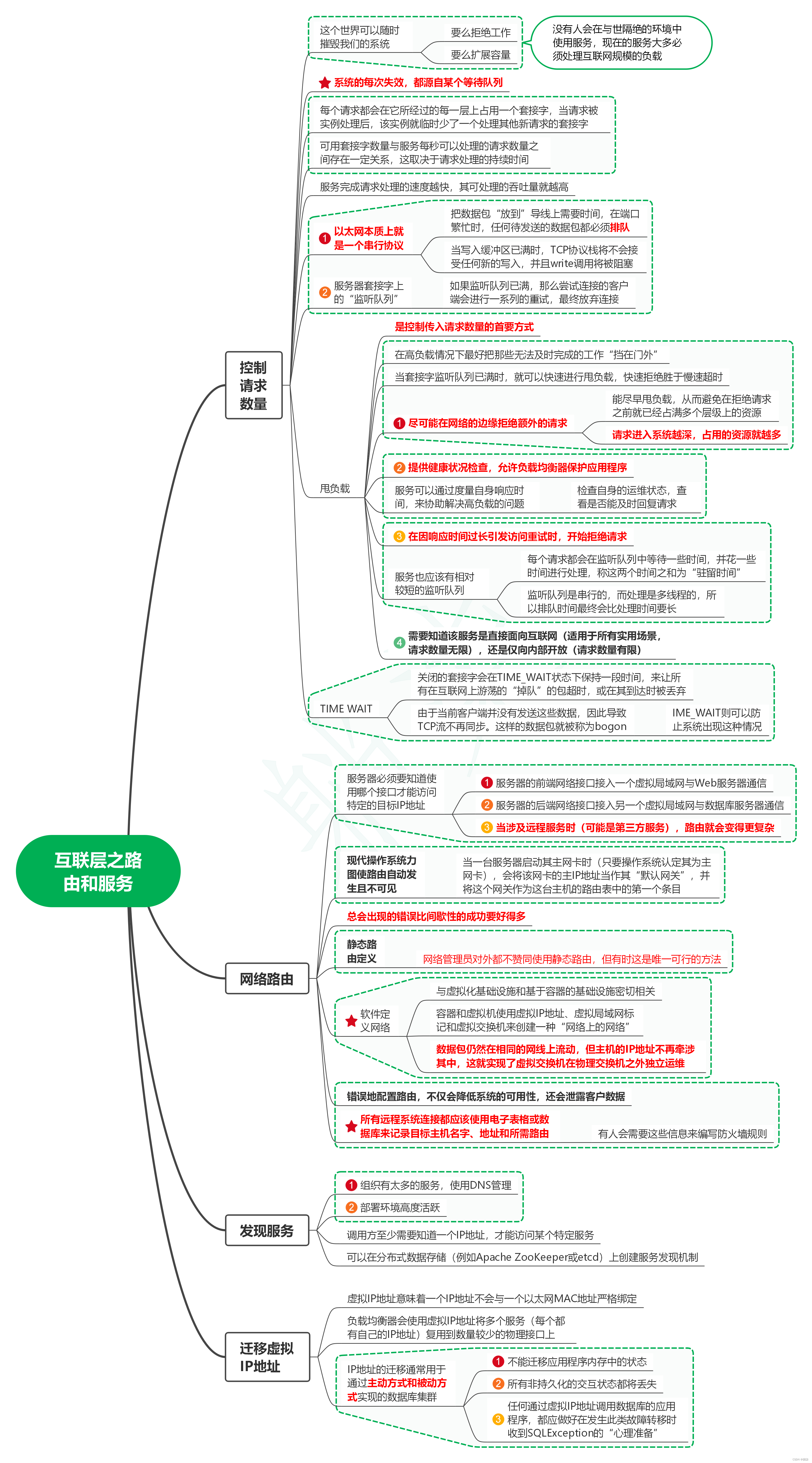
读发布!设计与部署稳定的分布式系统(第2版)笔记25_互联层之路由和服务
1. 控制请求数量 1.1. 这个世界可以随时摧毁我们的系统 1.1.1. 要么拒绝工作 1.1.2. 要么扩展容量 1.1.3. 没有人会在与世隔绝的环境中使用服务,现在的服务大多必须处理互联网规模的负载 1.2. 系统的每次失效,都源自某个等待队列 1.3. 每个请求都会…...
)
AI面试官:LINQ和Lambda表达式(二)
AI面试官:LINQ和Lambda表达式(二) 当面试官面对C#中关于LINQ和Lambda表达式的面试题时,通常会涉及这两个主题的基本概念、用法、实际应用以及与其他相关技术的对比等。以下是一些可能的面试题目,附带简要解答和相关案…...

Mysql原理篇--第二章 索引
文章目录 前言一、mysql的索引是什么?1.1 索引的结构:1.2 b树特性:1.3 b树每个节点的结构:1.4 b树 键值的大小排序:1.4 b树 存储(InnoDB): 二、索引类型2.1 主要的索引类型ÿ…...
保姆级系列教程-玩转Fiddler抓包教程(1)-HTTP和HTTPS基础知识
1.简介 有的小伙伴或者童鞋们可能会好奇地问,不是讲解和分享抓包工具了怎么这里开始讲解HTTP和HTTPS协议了。这是因为你对HTTP协议越了解,你就能越掌握Fiddler的使用方法,反过来你越使用Fiddler,就越能帮助你了解HTTP协议。 Fid…...

【iOS】单例、通知、代理
1 单例模式 1.1 什么是单例 单例模式在整个工程中,相当于一个全局变量,就是不论在哪里需要用到这个类的实例变量,都可以通过单例方法来取得,而且一旦你创建了一个单例类,不论你在多少个界面中初始化调用了这个单例方…...

从Vue2到Vue3【五】——新的组件(Fragment、Teleport、Suspense)
系列文章目录 内容链接从Vue2到Vue3【零】Vue3简介从Vue2到Vue3【一】Composition API(第一章)从Vue2到Vue3【二】Composition API(第二章)从Vue2到Vue3【三】Composition API(第三章)从Vue2到Vue3【四】C…...
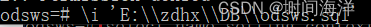
PostgreSQL——sql文件导入
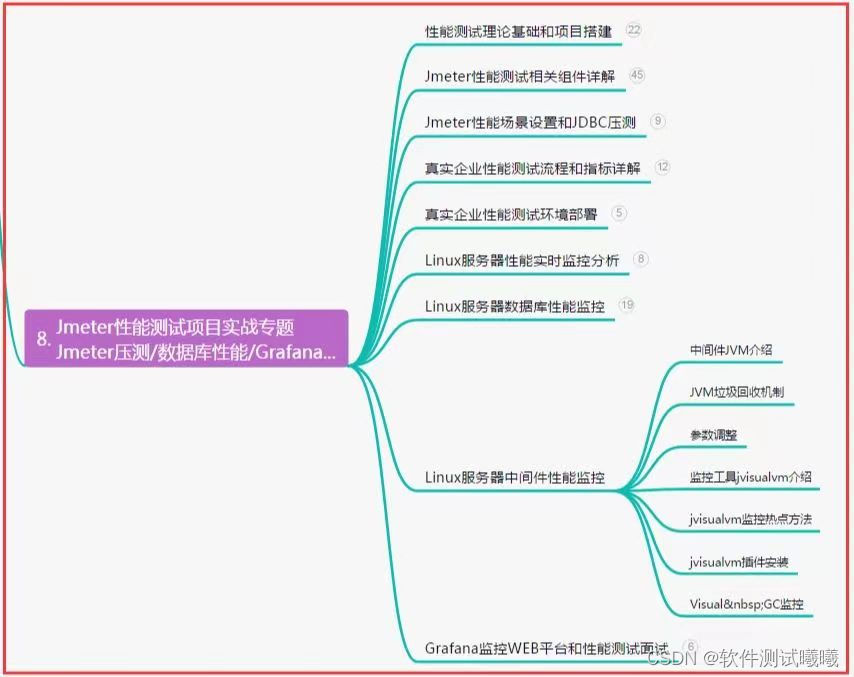
Windows方式: 进入PostgreSQL安装目录的bin,进入cmd 执行命令: psql -d 数据库名 -h localhost -p 5432 -U 用户名 -f 文件目录 SQL Shell: 执行命令: \i 文件目录(Windows下要加引号和双斜线)...

[SQL挖掘机] - 全连接: full join
介绍: 在sql中,join是将多个表中的数据按照一定条件进行关联的操作。全连接(full join)是一种连接类型,它会返回所有满足连接条件的行,同时还包括那些在左表和右表中没有匹配行的数据。 在进行全连接时,会…...

SpringDataJpa 实体类—主键生成策略
主键配置 IdGeneratedValue(strategy GenerationType.IDENTITY)Column(name "cust_id")private Long custId;//主键 Id:表示这个注解表示此属性对应数据表中的主键GeneratedValue(strategy GenerationType.IDENTITY) 此注解表示配置主键的生成策…...

【LeetCode 算法】Parallel Courses III 并行课程 III-拓扑
文章目录 Parallel Courses III 并行课程 III问题描述:分析代码拓扑 Tag Parallel Courses III 并行课程 III 问题描述: 给你一个整数 n ,表示有 n 节课,课程编号从 1 到 n 。同时给你一个二维整数数组 relations ,其…...

进行消息撤回功能的测试时,需要考虑哪些?
进行消息撤回功能的测试时,可以考虑以下测试点: 1. 功能可用性测试:确认消息撤回功能是否能够正常使用,并且在不同的场景下(例如单聊、群聊)是否表现一致。 2. 撤回时限测试:检查消息撤回的时…...
C语言动态内存管理(三)
目录 五、C/C程序的内存开辟1.图解2.关键点 六、柔性数组1.什么是柔性数组2.两种语法形式3.柔性数组的特点4.柔性数组的创建及使用在这个方案中柔性数组的柔性怎么体现出来的? 5.不用柔性数组,实现数组可大可小的思路6.对比 总结 五、C/C程序的内存开辟 1.图解 &a…...
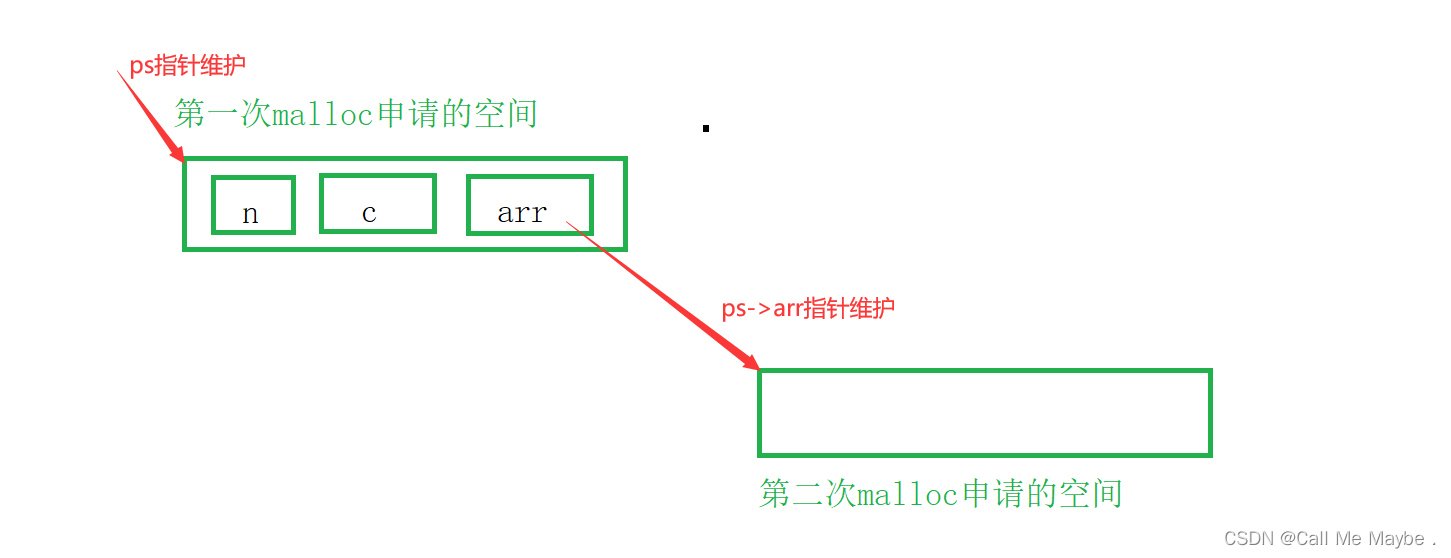
通过cmake工程生成visual studio解决方案
1、前言 visual studio是一个很强大的开发工具,这个工具主要是通过解决方案对我们的源码进行编译等操作。但是我们很多时候拿到的可能并不是一个直接的解决方案,可能是是一个cmake工程,那么这个时候我们就需要通过cmake工程生成解决方案&…...
STM32CubeMX配置STM32G031多通道ADC + DMA采集(HAL库开发)
时钟配置HSI主频配置64M 勾选打开8个通道的ADC 使能连续转换模式 添加DMA DMA模式选择循环模式 使能DMA连续请求 采样时间配置160.5 转换次数为8 配置好8次转换的顺序 配置好串口,选择异步模式配置好需要的开发环境并获取代码 修改main.c 串口重定向 #include &…...
Vue入门项目——WebApi
Vue入门——WebApi vue3项目搭建组合式API响应式APIreactive()ref() 生命周期钩子computed计算属性函数watch监听函数父子通信模板引用组合选项 vue3项目搭建 简单看下Vue3的优势吧 下载安装npm及node.js16.0以上版本(确保安装成功可用如下代码检查版本࿰…...

【电源专题】电量计参数RSOC/RM/FCC定义
在文章【电源芯片】电量计(Gauge)介绍中我们讲到电量计的功能就是监测电池、计量电量。 那么电量计其实也是有很多算法的,比如【电源专题】电量计估计电池荷电状态方法(开路电压法及库仑计法)的差别文章所说的开路电压法和库仑计法。当然还有如阻抗跟踪法、CEDV算法等。 …...

实际开发中,React应用常见问题【持续更新中】
实际开发中,React应用常见问题【持续更新中】 实际开发中,React应用常见问题【持续更新中】 一、路由相关 “react-router-dom”: “^6.14.2”, “react”: “^18.2.0”, 1、监听路由 import { useLocation } from react-router-domexport default func…...

Visual Studio 项目属性页开发完全教程:从基础到高级
Visual Studio 项目属性页开发完全教程:从基础到高级 【免费下载链接】project-system The .NET Project System for Visual Studio 项目地址: https://gitcode.com/gh_mirrors/pr/project-system Visual Studio 项目属性页是开发者管理项目配置的核心界面&a…...

小说下载器终极指南:一站式解决100+网站小说保存难题
小说下载器终极指南:一站式解决100网站小说保存难题 【免费下载链接】novel-downloader 一个可扩展的通用型小说下载器。 项目地址: https://gitcode.com/gh_mirrors/no/novel-downloader 在数字阅读时代,你是否曾因小说突然下架、网站404或网络中…...

网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程
网易云音乐NCM转MP3终极指南:ncmdump工具完整使用教程 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经从网易云音乐下载了心爱的歌曲,却发现只能在特定播放器上收听?NCM格式的限制让音乐…...

MAX78000移植Zephyr RTOS实战:从BSP创建到AI边缘设备开发
1. 项目概述与动机作为一名长期在嵌入式边缘AI和机器人领域摸爬滚打的开发者,我最近把目光投向了一块相当有潜力的板子:Maxim Integrated(现为ADI一部分)的MAX78000FTHR开发套件。这块板子的核心——MAX78000微控制器,…...

ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库
ComfyUI-Manager完整指南:如何轻松管理你的AI工作流扩展库 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and enable various c…...

2026上海GEO生成式引擎优化服务商综合实力测评:谁在真正帮品牌进入AI答案
当企业在讨论“上海生成式引擎优化公司哪家好”时,这个问题本身就反映了市场一个关键的转折。两三年前,企业营销的主战场还是搜索引擎排名和官网访问量。现在,决策者开始频繁向DeepSeek、豆包、通义千问等AI工具提问,而这些生成式…...

安卓用户如何免费获取大模型API密钥并开始调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 安卓用户如何免费获取大模型API密钥并开始调用 对于安卓开发者或移动端技术爱好者而言,直接体验和调用多种大模型的能力…...

修复 PowerShell 7 下 conda activate 报错的指南
修复 PowerShell 7 下 conda activate 报错的指南 适用场景:升级到 PowerShell 7.x 后,conda activate 突然报错,但 Windows PowerShell 5.1 正常。 发布日期:2026-05-24 适用版本:conda 23.x PowerShell 7.x 一、问题…...
)
DeepSeek注释质量跃迁路径(附12个真实项目对比数据+可复用Prompt模板)
更多请点击: https://codechina.net 第一章:DeepSeek注释质量跃迁路径(附12个真实项目对比数据可复用Prompt模板) 高质量代码注释不再是“锦上添花”,而是模型理解意图、团队高效协同与长期可维护性的核心基础设施。…...

RedisDesktopManager Windows版:3分钟掌握免费Redis可视化工具,告别命令行操作!
RedisDesktopManager Windows版:3分钟掌握免费Redis可视化工具,告别命令行操作! 【免费下载链接】RedisDesktopManager-Windows RedisDesktopManager Windows版本 项目地址: https://gitcode.com/gh_mirrors/re/RedisDesktopManager-Window…...