第八章:将自下而上、自上而下和平滑性线索结合起来进行弱监督图像分割
0.摘要
本文解决了弱监督语义图像分割的问题。我们的目标是在仅给出与训练图像关联的图像级别对象标签的情况下,为新图像中的每个像素标记类别。我们的问题陈述与常见的语义分割有所不同,常规的语义分割假设在训练中可用像素级注释。我们提出了一种新颖的深度架构,它融合了三个不同的计算过程,用于语义分割,即:(i)在CNN中进行自下而上的神经激活计算,用于对对象类别进行图像级别预测;(ii)在给定预测对象的情况下,估计CNN激活的条件概率,从而产生每个对象类别的概率注意力图;(iii)在同一层的相邻神经元之间进行横向注意力消息传递。通过条件随机场作为循环网络,将(i)-(iii)的融合实现为生成平滑且保持边界的分割。与现有工作不同的是,我们统一了我们深度架构的所有组件的端到端学习。在基准的PASCAL VOC 2012数据集上的评估表明,我们优于合理的弱监督基线和最先进的方法。
1.引言
本文解决了在弱监督条件下的语义图像分割问题。给定一张图像,我们的目标是为每个像素分配一个对象类别标签。我们通过仅使用图像级别的类别标签(即图像标签)从训练图像中学习对象的信息。我们的问题与之前的工作中常见的全监督语义分割问题不同,全监督语义分割问题通常在训练中提供了像素级别的真实对象类别注释。
语义图像分割具有挑战性,因为图像中的对象可能以各种姿势出现,在部分遮挡下,并且背景混乱。这是一个长期存在的问题,在训练中使用真实的像素级标签,已经有很多成功的方法来解决这个问题[22,14,27,11,3,7,12]。由于这种假设,很难将之前的工作扩展到其他广泛的领域,这些领域没有提供像素级别的注释,或者提供的监督信息不足以进行强大的学习。
为了减少训练中所需的监督级别,最近提出了用于语义图像分割的弱监督卷积神经网络(CNN)[24,25,28,26,45,29,18,41,4,30,36]。这些方法仅在训练中使用图像标签。其中大部分方法在多实例学习(MIL)框架内进行分割,这可以确保像素标签与预测图像标签一致,因为后者的预测可以用于根据可用的图像级别真实标签指定损失,并以此方式训练CNN模型。
受到这些方法的成功启发,我们也从一个CNN开始,旨在完成两个任务:像素标注和预测图像类别-其中在训练数据上的图像分类结果用于进行端到端的基于MIL的学习。具体而言,我们使用DeepLab网络[7]进行像素标注,并使用另一个全连接层进行图像类别预测。然后,我们扩展了这个框架,以融合自顶向下、自下而上和平滑性的视觉线索,以实现更准确的语义分割,如图1所示。我们的扩展旨在解决我们在相关工作的分割结果中观察到的以下两个问题:(1)对象的定位不准确;(2)对象边界的保留和平滑性在真实空间范围内受到限制。
为了生成保持边界的分割结果,我们将CNN预测的像素标签和图像的原始像素传递给一个全连接的条件随机场(CRF)。具体来说,我们将CRF实现为一个循环神经网络(RNN),并将其称为CRF-RNN。我们的CRF-RNN对初始CNN的预测进行了细化,使得像素标签更好地适应输入图像中的图像边缘。重要的是,我们的基于CRF的分割细化不是像相关工作[24,25,29,18]中的独立后处理步骤,而是我们端到端训练的深度架构的一个组成部分。由于CRF-RNN试图尊重图像边缘,它的输出可能容易出现过分分割的情况。
为了避免过度分割,并且改善对象的空间范围内的平滑性,我们将我们的CNN用于第三个任务,即预测识别图像类别的自顶向下的视觉注意力图。我们将对象类别的视觉注意力图指定为CNN对该类别的神经激活的空间矫正高斯分布[34,16]。这扩展了最近的方法[44],该方法使用马尔可夫链来建模神经激活的父子依赖关系以估计注意力图,因为我们通过考虑CNN中三种类型的神经依赖关系(i)从父到子;(ii)从子到父;(iii)在同一CNN层中相邻神经元的激活之间)来估计矫正的高斯分布。重要的是,我们使用相同的CNN来计算注意力图,这与相关工作不同,相关工作使用外部网络来估计对象种子。
如图1所示,我们的方法迭代地进行以下操作:(i)将CNN和CRF-RNN产生的自下而上的过分割图与CNN估计的自顶向下的注意力图进行融合,然后(ii)使用CRF-RNN对融合的像素标签预测进行细化,生成最终的分割图。注意力图表示对分类至关重要的具有鉴别性的对象部分,而分割图则捕捉到对象的空间范围。我们采用了相关文献中使用的自顶向下和自下而上处理的相同定义[5,20,16],其中自下而上的过程从像素预测对象类别,而自顶向下的过程在自下而上的过程预测的对象类别的条件下,预测图像中的注意力图。我们的深度架构的所有组件都通过估计图像分类损失和分割“损失”进行端到端的训练。在训练中,使用一个全连接层(FCL)从像素标签预测中预测图像类别。这进一步生成图像分类损失,该损失通过FCL、CRF-RNN和CNN进行反向传播,学习所有网络参数。关于分割“损失”,我们在这里稍微滥用了常见的损失定义,因为我们没有给出地面真值分割。我们将分割“损失”估计为注意力图和自下而上分割中像素标签的两个概率分布之间的距离。分割“损失”通过CRF-RNN和CNN进行反向传播,并用于规范化图像分类损失。
在基准PASCAL VOC 2012数据集上的评估表明,我们的方法胜过了合理的弱监督基线和最先进的方法。我们的贡献包括:•新的深度架构,融合自顶向下的注意力和自下而上的分割,并通过细化分割来保持边界。该架构是统一的,不使用外部网络,也不进行后处理。•使用矫正的高斯分布对视觉注意力图进行新的建模,该分布考虑了CNN中父节点、子节点和相邻神经元之间的激活之间的统计依赖关系。
接下来,第2节回顾了相关工作,第3节详细说明了我们的自下而上像素标签和对象识别聚合方法,第4节阐述了我们的自顶向下注意力估计方法,第5节描述了我们保持边界的分割细化方法,第6节解释了两个损失函数和我们的学习方法,第7节呈现了我们的结果。

图1:概述:给定一张图像,我们使用CNN计算每个对象类别的自下而上分割图(蓝色链接表示自下而上计算)。这些像素级的预测通过一个全连接层(FCL)进行对象识别的聚合。同样的CNN用于每个识别的对象类别的自顶向下注意力图的估计(红色链接表示自顶向下计算)。最后,自下而上和自顶向下的线索在CRF-RNN中进行融合和迭代细化,以改善对象边界的定位和最终分割的空间平滑度(黑色链接表示融合和细化计算)。在学习过程中,我们通过反向传播图像分类损失来对训练图像中的FCL输出进行学习。这个学习过程通过弱监督的分割“损失”进行规范化,该损失估计了注意力图和自下而上分割中像素标签的两个概率分布之间的距离(灰色链接表示所有组件的端到端训练)。
2.先前的研究工作
弱监督语义图像分割已经通过图形模型和参数化结构化预测模型进行了研究[39,40,9,45,21]。这些方法通常利用关于空间平滑性的启发式信息(例如基于相邻像素之间的相似性[39]),需要预处理提取超像素[40],或使用弱分割先验[9]。最近,基于CNN的方法[28,25,24,4,41]通过通常考虑多实例学习(MIL)来迭代地增强其输出分割与地面真实图像标签一致,已经显示出更好的性能。MIL框架可以通过广义期望或后验规则化来扩展,以在域约束下最大化模型参数的期望[25]。
为了提高性能,一些最近的方法[28,24,4,41]试图通过运行对象提议的检测器[1,10]来初始化对象定位。然而,这增加了监督的程度,因为对象提议检测器需要边界框注释或对象边界注释进行训练。此外,使用基于注意力的对象定位已经被证明可以改善弱监督分割[29,18,15,30]。然而,这些方法通常依赖外部网络来计算注意力线索[18],或者从自下而上的神经激活中估计前景掩码(类别非特定)[29]。最近的工作[44]通过估计自上而下的马尔可夫链来计算注意力图,但这项工作没有考虑弱监督分割。我们通过使用矫正的高斯分布来扩展[44]的马尔可夫链公式,用于对视觉注意力图的建模,从而改善了每个对象类别的注意力图的空间平滑性。
将自上而下和自下而上的线索结合起来用于图像分割和其他视觉问题是一个经常出现的研究课题;然而,这两个线索通常在不同的阶段计算[5,6,20,42]。最近的方法[16]使用矫正的高斯分布将这两个计算过程结合在一个单一的CNN中,用于人体姿势估计。但是他们的CNN是在全监督下训练的。虽然我们解决了一个不同的视觉问题,但关键的区别在于我们矫正的高斯的协方差矩阵不是二值的,而是根据视觉外观进行估计,并且我们的自顶向下的注意力线索在预测的对象类别的条件下具有语义上的意义。
3.自下而上的计算过程
像素标注。给定一张图像x,我们使用具有大场景视野的DeepLab网络[7]生成像素标签y={yi},其中yi∈Y是来自对象类别集合Y的第i个像素的对象类别标签。具体而言,我们通过计算每个像素i的每个对象类别y∈Y的输出得分fi(y),生成K=|Y|个分割图。像素级的得分通过标准的softmax操作进行归一化,以估计相应的后验概率,如下所示:
因此,我们将使用简写符号pSi(y)来表示pSi(y|x),即自下而上的分割预测。
聚合。上述像素级的对象预测得分然后被聚合用于对象识别,即预测图像x中出现的对象类别集合Yx。文献中提出了许多启发式方法来进行这种聚合,包括全局最大池化(GMP)[23]、全局平均池化(GAP)[47]、对GMP和GAP进行平滑组合的对数和指数测量(LSE)[28],以及全局加权排序池化(GWRP)在聚合中偏好于地面真实对象的高分数并抑制其他对象[18]。我们不使用这些启发式方法,而是使用全连接层(FCL)从像素级得分中估计图像级得分,然后与我们方法的其他组件一起训练FCL。给定K个像素级得分的图{fi(y):i,y∈Y},FCL输出K个归一化的对象得分{p(y|x):y∈Y}。为此,每个分割热图{fi(y):i}都与表示对象类别y的相应输出单元进行全连接。
4.自下而上的计算过程
本节解释了如何为每个对象类别估计自上而下的视觉注意力图,然后将其用作改善对象定位和减少自下而上像素标注中的过分分割的上下文线索。在估计概率视觉注意力图方面,我们遵循了众多研究工作[38,17,35]以及最近对神经激活进行可视化的方法[43,32,2,44]。我们使用自上而下的计算过程来估计我们CNN每一层的神经激活的概率视觉注意力图。我们的自上而下估计是逐层进行的,从用于对象识别的FCL的输出层开始,如第3节所述。为了提高效率,与[44]类似,我们将自上而下的计算停止在pool-4层,并将该结果放大到图像大小,以获得与K个对象类别对应的所有像素上的K个概率视觉注意力图。
我们将第l层第i个神经元对于对象类别y的视觉注意力定义为该神经元激活al i在图像中预测y的相关性,表示为p(al i|y)≥0。第l层所有神经元的视觉注意力图被定义为一个随机变量向量:pl(y)=[...p(al i|y)...]⊤,由修正的高斯分布[34,16]控制:
我们使用简写符号 p = pl(y) 表示矩阵 D = Dl = [δii l ′] 捕捉同一层 l 中相邻神经元激活之间的依赖关系的强度,而 b = bl(y) 表示层 l 和下一层 l - 1 中神经元激活的父子依赖关系。根据设计,我们保证 δii l ′ < 0,因此负的 -D 是一个共正矩阵,即 -p⊤Dp ≥ 0,对于 p 0。δl ii δl ii' 的计算如下所述。根据 (2),pl(y) 的计算等同于修正高斯分布的最大后验估计,而这又可以被表述为具有非负约束的二次规划问题。

负矩阵 -D 的共正性质保证了二次优化在 (3) 中的收敛性[16,34]。给定我们的卷积神经网络,我们按照自顶向下、逐层地计算 (3) 中的二次规划问题,直到 pool-4 层为止。前一层 l-1 的结果被用来定义参数 bl(y),因为它们捕捉了神经元激活的父子依赖关系。最后,对于 pool-4 层,估计的 pl(y) 被放大到图像尺寸,然后在对象类别上进行归一化,以便在每个像素上生成一个合适的概率分布。

与最近的工作[44]相比,该工作仅考虑神经元激活的父子依赖关系,即 p(al i|y)=Pj p(al i|al j−1)p(al j−1|y),我们在一定程度上增加了计算时间,但显著改善了注意力图,使其能够很好地覆盖对象的真实空间范围。在本节的剩余部分,我们定义了修正高斯的参数 bl(y) 和 D。如图2所示,每个 p(al i|y) 都依赖于神经元的激活情况: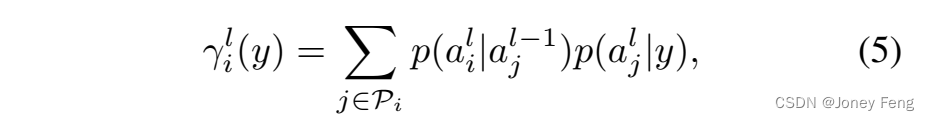

其中 zi = (xi, yi) 是像素的位置,ri 是HSV颜色直方图,σz = 10 和 σr = 30 控制敏感度。然后,我们对双边相似性进行归一化,并定义:
请注意,δl ii δl ii' 只取决于图像,而不取决于对象类别的预测,因此可以预先计算以提高效率。请注意,在 (8) 中,wii = 1,wii' > 0: i 6= i',这意味着在 (9) 中 δii' < 0。因此,矩阵 -D 是共正的,这保证了二次优化在 (3) 中的收敛性。回想一下,注意力图用于计算分割损失,该损失在学习过程中通过网络进行反向传播(图1)。

图2:(左)之前的工作[44]使用自顶向下的马尔可夫链来估计注意力图。(右)我们还考虑了同一层的邻近神经元激活,以改善基于对象的平滑度估计注意力图。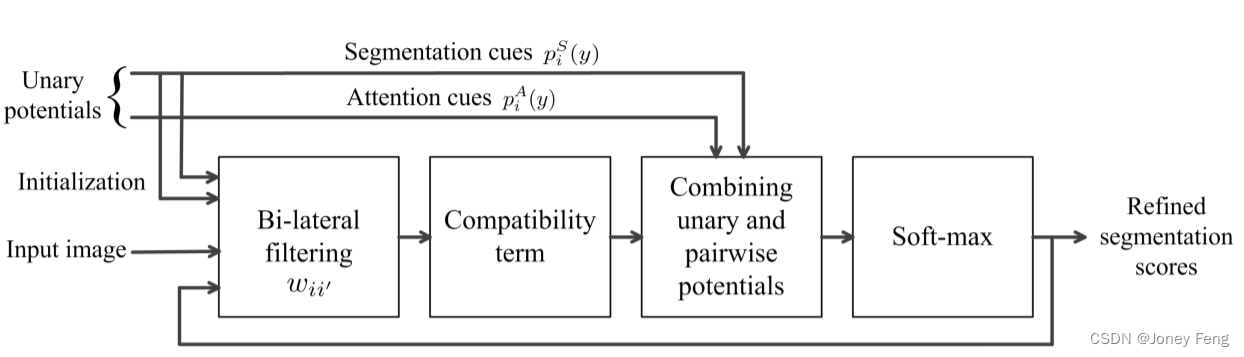
图3:CRF均场推理的单步骤实现,实现为一堆叠卷积层。均场迭代代表了一个循环神经网络。
5.细化计算过程
由于CNN中的连续池化,由(1)给出的初始像素标签pS i (y|x)很可能会产生粗糙的分割图,对象边界的检测效果较差。为了解决这个问题,我们将初始的粗糙分割图与估计的视觉注意力图和输入图像一起传递给CRF-RNN [19, 46],以进一步细化分割。我们考虑一个全连接的CRF,其像素级类别分配y = {yi}的能量定义为:
一元势能。为了初始化我们的分割优化,在每个像素i处,我们结合上行的视觉注意力pA i (yi)(由(4)给出)和下行的分割pS i (y|x)(由(1)给出),计算相应的一元势能φ(yi),即:
在(11)中,我们使用视觉注意力pA i (yi)作为像素级先验(PLP)来进行分割。我们的动机来自于现有的弱监督分割工作,这些工作考虑了图像级先验(ILP),例如图像级对象预测得分,用于优化他们的分割[28,31,39]。ILP已被证明通过减少假阳性来改善弱监督分割。我们在(11)中的公式扩展了这项工作,因为我们在每个像素上驱动的注意力先验似乎比图像级先验更适合分割。与ILP不同,我们的PLP融合了有关对象位置的线索。
成对势能。我们根据双边权重wii'(由(8)给出)定义成对势能,以确保我们的分割优化遵守对象边界:
其中µ(yi, yi′)是标签兼容性,旨在估计类别yi和yi′在像素i和i′处共存的可能性。注意,µ(yi, yi′)在不同的像素位置上变化。它被实现为一个卷积层,并且通过在第6节中指定的分割“损失”进行学习。
CRF推理。根据[19,46]的方法,我们将CRF推理作为一系列的平均场迭代进行。如图3所示,每个平均场估计对应于沿着一系列卷积层的前馈神经处理,其结果被反馈用于另一次迭代。因此,平均场迭代表示一个递归神经网络。注意,我们的CRF推理以pS和pA作为输入,根据公式(11)计算每个像素i和所有K个对象类别的φ(yi)。在第一次迭代中,将一元势能的软最大得分视为边际概率以初始化解决方案。在随后的迭代中,边际概率被估计为CRF-RNN输出的软最大得分。给定前一层输出,双边滤波器响应从输入图像中计算出来。与[46]不同的是,我们考虑固定的双边核,因为它们不能在没有像素级监督的情况下可靠地学习。标签兼容性µ(yi, yi′)是通过应用1×1卷积滤波器来估计的,其具有K个输入通道和K个输出通道,用于K个对象类别,给定双边响应。最后,给定估计的φ(yi)和ψ(yi, yi′),将组合的CRF势通过软最大操作传递,以生成下一个CRF-RNN迭代的归一化分割得分。
6.端到端学习和损失函数
我们的方法的所有组件都是以端到端的方式进行学习的,只使用了地面真实图像标签。为了在学习中使用这种图像级监督,我们的方法将训练图像上预测的像素标签聚合到对象识别中,这反过来可以用于估计分类损失∆C。为了训练CRF-RNN和我们的初始分割器DeepLab网络[7],我们另外使用了一个对象分割“损失”∆S,该损失相对于在训练图像上估计的视觉注意力图进行定义,因为我们无法访问像素级注释。因此,在我们的学习中,我们反向传播以下损失:
分类损失是根据Sec.3中指定的用于图像级对象识别的FCL输出聚合函数p(y|x)来定义的。

其中,Yx表示训练图像x中存在的地面真实对象类别的集合,Y¯x = Y \ Yx表示已知不存在的类别的集合。∆C惩罚FCL对于在训练图像中被注释为存在的对象的低预测得分,并对于其他对象给出高得分。
对象分割损失定义为惩罚估计的分割与视觉注意力图之间的任何差异。∆S被定义为在训练图像中被注释为存在的对象y ∈Yx的两个预测分布pS和pA之间的距离:
其中N表示像素的数量。值得注意的是,在我们的方法中,视觉注意力以两种不同的方式使用,即用于计算单个图像上CRF-RNN推理的一元势能,以及用于在训练图像的小批量学习中估计∆S。因此,我们方法中的这两种对视觉注意力的使用并不多余,正如我们的实验证明的那样。
7.实验
在本节中,我们首先描述了我们的实验设置,然后呈现了结果。
数据集。我们在PASCAL VOC 2012数据集上评估我们的方法,这个数据集通常被认为是弱监督分割基准[25,28,29,18]。该数据集包含21个对象类别,包括背景。我们遵循标准的实验设置,将图像分为三组:1464个训练图像,1456个测试图像和1449个验证图像。按照通常的做法,我们在训练时考虑额外的trainaug集合[18,36],并在验证和测试集合的图像上评估我们的方法。我们考虑使用标准的PASCAL VOC分割指标,即平均交并比(mIoU)比率,也称为Jaccard指数。
实现细节。我们考虑使用具有大视野的DeepLab网络[7]进行图像分割。DeepLab采用VGG-16网络[33]进行分割,通过用卷积层替换全连接层。给定输入图像,DeepLab生成与每个对象类别相对应的粗糙热图。网络使用带动量的次梯度下降进行训练。我们考虑批大小为20个图像,动量设置为0.9。学习率初始设为0.001,并在每2000次迭代中缩小10倍。我们训练网络进行10000次迭代。整个训练过程在Nvidia Tesla k80 GPU上大约需要10小时,与[25,24]相当。在推理过程中,我们首先计算特定对象的注意力图,然后将其视为基于注意力的PLP。基于注意力的PLP用作CRF-RNN层中的一元势能。虽然在推理过程中无法获得图像级别的标签,但可以基于完全监督的图像分类对可靠的对象预测进行估计注意力图。对于学习和推理,我们将CRF-RNN应用于三次迭代,因为额外的迭代对最终性能没有显著影响。
基线。为了证明我们方法的各个组成部分的重要性,我们定义了以下基线。与基线的比较结果如表1所示。
B1:没有自上而下的注意力(无att)。在这个基线中,我们忽略了我们方法中的自上而下的注意力线索。由于没有注意力线索,无法计算分割损失,因此只使用分类损失来学习分割网络。请注意,没有注意力线索,很难在图像中定位对象。表1中的结果表明,忽略自上而下的注意力线索对性能有显著影响,这证明了在弱监督分割中注意力线索的重要性。
B2:没有分割损失(无seg损失)。在这个基线中,我们忽略了基于注意力图计算的分割损失。没有分割损失,注意力线索仅在CRF-RNN层的一元势能中考虑,如(11)中定义的那样。如表1所示,分割损失对于弱监督分割很重要,因为它在学习分割网络和CRF-RNN时是必需的。
B3:没有基于注意力的一元势能(无att一元)。在这个基线中,我们不在CRF-RNN层的一元势能中考虑注意力线索。因此,注意力线索仅通过损失函数(15)在分割框架中进行考虑。表1中的结果表明,在CRF一元势能中考虑注意力线索可以提高整体性能。
B4:没有考虑注意力中的邻居依赖(无neighbor)。在这个基线中,我们在计算注意力图时忽略了邻居神经元之间的依赖关系(即(9)中的δii l')。因此,我们只考虑父子依赖关系来计算注意力图,就像[44]中所示。如表1所示,如果不考虑注意力估计中的邻居依赖关系,性能会较差,因为这些依赖关系提供了关于对象的平滑性和边界的线索。
B5:没有CRF-RNN层(无CRF-RNN)。在这个基线中,不是将CRF-RNN层应用于细化分割图,而是执行基于密集CRF的后处理[7]。没有CRF-RNN层,标签的兼容性或对象类之间的共现关系(即(12)中的µ(yi,yi′))无法学习。从表1中我们可以看出,考虑CRF-RNN层比基于CRF的后处理能够获得更好的性能。
B6:在推理中没有注意力线索(无att推理)。在这个基线中,我们忽略了注意力线索,在推理过程中计算CRF一元势能。回想一下,注意力线索可以被视为像素级先验,对于在图像中定位对象非常重要。因此,在推理过程中忽略注意力会导致更差的整体性能(表1)。
使用图像级别注释与最先进方法的比较。我们在PASCAL 2012验证集和测试图像上与最先进的方法进行比较。我们的方法仅使用图像级别标签进行学习。因此,为了公平比较,我们将与仅考虑图像级别注释作为弱监督的方法进行比较。由于基于注意力的定位线索,我们不需要依赖额外的监督,如目标提议[28],图像裁剪[24]或对象尺寸[25]。在PASCAL验证集和测试集上的结果分别显示在表2和表3中,我们在mIoU指标方面超过了最先进的方法。
与具有额外注释的最先进方法的比较。一些方法考虑额外的低成本监督来促进弱监督分割。例如,MIL+ILP+SP-bb[28],MIL+ILP+SP-seg[28],SN-B[41]使用对象定位线索,使用MCG对象提议[1]或BING边界框[10]。EM-Adapt的变体[24]和CCCN[25]考虑多个图像裁剪以增加监督数量。[4]使用了额外的“点击每个对象”的注释,CCCN+size[25]考虑了额外的1位监督,即对象的大小(大或小)。直接与这些方法进行比较是不公平的,但为了完整性起见,我们在表4中总结了上述方法的结果。
聚合方法的评估。请注意,我们考虑了一个全连接层(FCL),它被学习用于将逐像素的预测聚合成图像级别的对象预测分数。我们将FCL与其他聚合方法进行了比较,如GMP [23],GAP [47]和LSE [28],LSE是GMP和GAP的平滑组合。尽管考虑FCL层会增加学习中的参数数量,如表5所示,我们提出的FCL明显优于其他基于启发式的聚合方法。
定性结果。在图4中,我们展示了在PASCAL 2012验证集上的定性结果。我们的方法在大部分情况下能够正确地定位图像中的对象,并且保持对象的边界。图5中展示了一对失败案例,我们的方法未能检测到图像中的“飞机”,这是由于它与训练数据中其他“飞机”实例的外观不同。在第二个案例中,我们的方法未能检测到图像中的一些“人”实例和“瓶子”。我们认为这是由于图像中小物体(例如瓶子)缺乏注意力线索所导致的。请注意,即使在完全监督的情况下,分割小物体也是具有挑战性的[8]。
表1:根据mIoU指标(%)与PASCAL 2012验证集和测试集上的基准方法进行比较
表2:根据mIOU指标(%)与PASCAL 2012验证集上的最先进方法进行比较
表3:根据mIOU指标(%)与PASCAL 2012测试集上的最先进方法进行比较
表4:根据mIoU指标(%)对使用额外监督的方法在PASCAL 2012验证集和测试集上进行比较
表5:根据平均IoU指标(%),在PASCAL 2012验证集和测试集上对FCL与其他聚合方法进行比较
8.结果
我们提出了一种用于弱监督图像分割的新型深度架构。我们的关键思想是使用同一网络估计和融合自底向上、自顶向下和平滑性线索,以更好地适应物体边界并覆盖物体的空间范围。我们的统一框架由CNN、CRF-RNN和全连接层组成,可以仅使用地面真实图像标签进行端到端训练。在对基准PASCAL VOC 2012数据集的评估中,我们观察到我们的方法可以在不依赖额外监督(如物体提议和图像裁剪)的情况下定位物体。基于外观的相邻依赖关系估计有助于更好地定位物体的完整范围,而不仅仅是部分范围。我们的方法与基线方法的比较证明了注意力线索、CRF RNN平滑和FCL层作为弱监督分割中的聚合方法的重要性。

图4:PASCAL 2012验证集上的定性结果。

图5:PASCAL 2012验证集上的失败案例。
相关文章:
第八章:将自下而上、自上而下和平滑性线索结合起来进行弱监督图像分割
0.摘要 本文解决了弱监督语义图像分割的问题。我们的目标是在仅给出与训练图像关联的图像级别对象标签的情况下,为新图像中的每个像素标记类别。我们的问题陈述与常见的语义分割有所不同,常规的语义分割假设在训练中可用像素级注释。我们提出了一种新颖的…...
MySql忘记密码如何修改
前言 好久没用数据库的软件了,要用的时候突然发现密码已经忘记了,怎么试都不对,心态直接爆炸,上一次用还是22年6月份,也记不得当时用数据库干什么了,这份爆炸浮躁的心态值得这样记录一下,警示自…...

【NetCore】04-作用域与对象释放行为
文章目录 作用域 作用域由IServiceScope接口承载 对象释放 实现IDisposable接口类型释放 1.DI只负责释放由其创建的对象实例 2.DI在容器或子容器释放时,释放由其创建的对象实例 建议 1.避免在根容器获取实现IDisposable接口的瞬时服务 2.避免手动创建实现了IDispo…...

新材料技术的优势
目录 1.什么是新材料技术 2.新材料技术给人类带来了哪些便利 3.新材料技术未来的发展趋势 1.什么是新材料技术 新材料技术指的是通过科学和工程技术的手段开发和应用全新的材料,以满足特定的需求和应用。新材料技术是材料科学和工程领域的重要研究方向࿰…...

HTTPS、DNS、正则表达式
HTTPS原理 HTTPS(Hypertext Transfer Protocol Secure)是一种安全的通信协议,它基于HTTP协议,在数据传输过程中使用了加密技术来保护通信的安全性和完整性。HTTPS的工作原理主要包括以下几个步骤: 客户端发起HTTPS请求…...

MAC电脑设置charles,连接手机的步骤说明(个人实际操作)
目录 一、charles web端设置 1. 安装charles之后,先安装证书 2. 设置 Proxy-Proxy Settings 3. 设置 SSL Proxying 二、手机的设置 1. 安卓 2. ios 资料获取方法 一、charles web端设置 1. 安装charles之后,先安装证书 Help-SSL Proxying-Inst…...
百度文心一言接入教程-Java版
原文链接 前言 前段时间由于种种原因我的AI BOT网站停运了数天,后来申请了百度的文心一言和阿里的通义千问开放接口,文心一言的接口很快就通过了,但是文心一言至今杳无音讯。文心一言通过审之后,很快将AI BOT的AI能力接入了文心…...
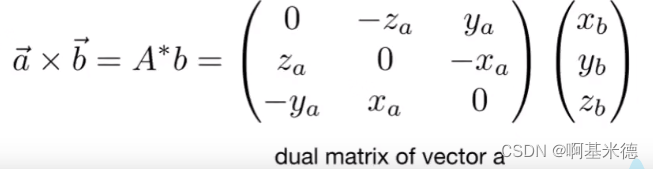
Games101学习笔记 - 基础数学
向量 向量:方向和长度,没有起始位置 向量长度:各个方向平方相加开方 单位向量:向量除向量的长度 点乘 在笛卡尔坐标系中的点乘计算: 几何意思: 表示一个向量在另一个向量上的投影点乘在图形学中应用&a…...

Linux进程的认识
查看进程指令proc/ps 注意哦, 我们经常使用的指令, 像ls, touch…这些指令在启动之后本质上也是进程 proc 是内存文件系统, 存放着当前系统的实时进程信息. 每一个进程在系统中, 都会存在一个唯一的标识符(pid -> process id), 就如同学生在学校里有一个专门的学号一样. 大…...
向量vector与sort()
运行代码: //向量与sort() #include"std_lib_facilities.h" //声明Item类 struct Item {string name;int iid;double value;friend istream& operator>>(istream& is, Item& ii);friend ostream& operator<<(ostream& o…...

Netty学习(三)
文章目录 三. Netty 进阶1. 粘包与半包1.1 粘包现象服务端代码客户端代码 1.2 半包现象服务端代码客户端代码 1.3 现象分析粘包半包缘由滑动窗口MSS 限制Nagle 算法 1.4 解决方案方法1,短链接方法2,固定长度方法3,固定分隔符方法4,…...

c++学习(布隆过滤器)[23]
布隆 布隆过滤器(Bloom Filter)是一种概率型数据结构,用于判断一个元素是否可能存在于一个集合中。它使用多个哈希函数和位图来表示集合中的元素。 布隆过滤器的基本原理如下: 初始化:创建一个长度为m的位图…...
React的UmiJS搭建的项目集成海康威视h5player播放插件H5视频播放器开发包 V2.1.2
最近前端的一个项目,大屏需要摄像头播放,摄像头厂家是海康威视的,网上找了一圈都没有React集成的,特别是没有使用UmiJS搭脚手架搭建的,所以记录一下。 海康威视的开放平台的API地址,相关插件和文档都可以下…...
细讲TCP三次握手四次挥手(二)
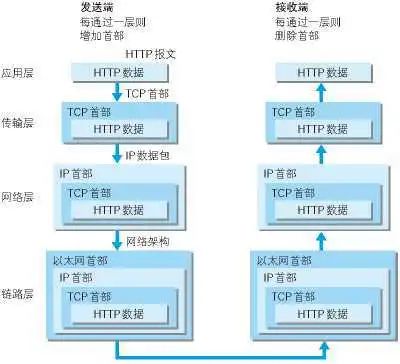
TCP/IP 协议族 应用层 应用层( application-layer )的任务是通过应用进程间的交互来完成特定网络应用。应用层协议定义的是应用进程(进程:主机中正在运行的程序)间的通信和交互的规则。 对于不同的网络应用需要不同的应用层协议…...
)
LeetCode Top100 Liked 题单(序号19~)
19. Remove Nth Node From End of List 题意:给一个链表,删除从尾数起的第n个结点,返回头节点。 我的思路 指针到最后,数出来有多少个,之从前向后数,再删掉节点 代码 10ms Beats 16.06% class Solution…...
qssh使用
到官网下载qssh的源码QSsh-botan-1,使用qtcreator打开后,直接编译,即可得到qssh的库 头文件将QSsh-botan-1\src\libs\ssh目录下的.h文件拷到include文件夹下,即为库头文件。 qssh有个问题,如果你将qssh的类放在子线程…...

持续部署CICD
目录 (1)CICD的开展场景 (2)项目实际应用 CICD 是持续集成(Continuous Integration)和持续部署(Continuous Deployment)简称。指在研发过程中自动执行一系列脚本来降低开发引入 bug…...

ARM 循环阻塞延迟函数
串行驱动的关键是双方能够按照既定的时序进行检测、设置相关引脚上的电平,比如单总线、I2c这样基本的可以用GPIO模拟的时序协议,需要主从双方,必须在链路接口内严格按照微妙级的延迟单位进行时序同步。 所以,在这种对时间要求很敏…...

Spark的DataFrame和Schema详解和实战案例Demo
1、概念介绍 Spark是一个分布式计算框架,用于处理大规模数据处理任务。在Spark中,DataFrame是一种分布式的数据集合,类似于关系型数据库中的表格。DataFrame提供了一种更高级别的抽象,允许用户以声明式的方式处理数据,…...

WPF线程使用详解:提升应用性能和响应能力
在WPF应用程序开发中,线程的合理使用是保证应用性能和响应能力的关键。WPF提供了多种线程处理方式,包括UI线程、后台线程、Task/Async Await和BackgroundWorker。这些方式与传统的Thread类相比,更加适用于WPF框架,并能够简化线程操…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...
)
用Python+OpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图)
用PythonOpenCV手把手实现Prewitt边缘检测(附完整代码与效果对比图) 边缘检测是计算机视觉中最基础也最关键的预处理步骤之一。想象一下,当你需要让计算机"看清"一张照片中的物体轮廓时,边缘检测算法就是它的"视觉…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南
开启Python GUI开发新纪元:Tkinter Designer可视化界面自动化生成终极指南 【免费下载链接】Tkinter-Designer An easy and fast way to create a Python GUI 🐍 项目地址: https://gitcode.com/gh_mirrors/tk/Tkinter-Designer 在Python GUI开发…...

使用TaotokenCLI工具一键配置开发环境中的API密钥
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken CLI工具一键配置开发环境中的API密钥 在团队协作或个人开发中,为每个项目或成员手动配置大模型API密钥和…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...
)
在线文档协作工具选型必看:14款产品对比(2026版)
一、在线文档协作工具的概念解析及其核心功能 在线文档协作工具是基于云端的文档创建、编辑、共享与协同沟通平台,核心目标是让团队在同一份资料上“实时共同工作”,减少反复传文件、版本混乱与沟通成本。 企业常见的核心能力包括: 多人实…...
)
Sora 2 GIF导出速度提升300%?20年多媒体架构师亲授GPU加速转码链路(CUDA 12.4 + cuVID硬编实测)
更多请点击: https://kaifayun.com 第一章:Sora 2 GIF导出方法概览 Sora 2 并非 OpenAI 官方发布的模型,当前(截至2024年)并无名为“Sora 2”的公开产品。因此,所谓“Sora 2 GIF导出”实为社区对视频生成工…...

Godot 4.2 + C# 避坑指南:手把手教你打包发布你的第一个2D游戏到Steam
Godot 4.2 C# 避坑指南:从开发到Steam发布的完整实战手册当你终于完成心爱的2D游戏开发,准备向全世界展示你的作品时,打包发布这个看似简单的环节往往会成为独立开发者最大的噩梦。特别是使用Godot 4.2搭配C#的项目,从导出设置到…...