比memcpy还要快的内存拷贝,了解一下
前言
朋友们有想过居然还有比memcpy更快的内存拷贝吗?
讲道理,在这之前我没想到过,我也一直觉得memcpy就是最快的内存拷贝方法了。
也不知道老板最近是咋了,天天开会都强调:“我们最近的目标就一个字,性能优化!”
一顿操作猛如虎,也没提高5%。感觉自己实在是黔驴技穷,江郎才尽,想到又要被老板骂立马滚蛋,心里就很不是滋味。
所谓车到山前必有路,船到桥头自然直。嘿,有一天我刚好注意到我们的业务代码里有大量的memcpy,正一筹莫展之时,突然灵光一现,脑海里闪过一个想法:memcpy还可以优化吗?
我想说,正是这个想法又让我可以在老板面前暂时苟且偷生一段时间,实在是不得不佩服自己!
一、SIMD技术简介
这一小节介绍的内容跟小节标题很契合,就是介绍一下SIMD(Single Instruction Multiple Data,单指令多数据)。啥意思呢,就是一条指令并发处理多条数据。形象一点讲就是老板在桌上放了很多钱让你拿,有同学喜欢一张一张的拿,还说我喜欢这种慢慢富有的感觉;SIMD就是,老子一把拿,我踏马喜欢暴富!没错,它就是可以提升memcpy性能的关键核心技术。引用大佬画的一张图:
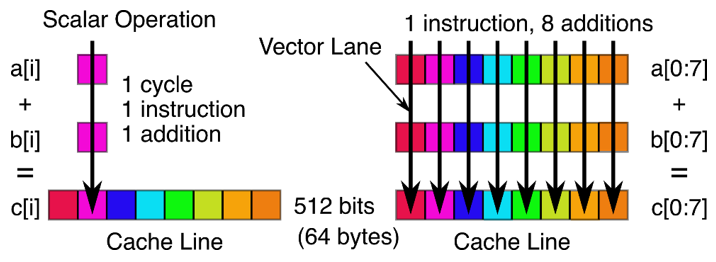
图1
Scalar Operation就是指的SISD(Single Instruction Single Data,单指令单数据),这种方式完成上图所有C[i]的计算需要串行执行八次,因为每个时间点,CPU的一条指令只能执行一份数据。
SIMD,就是一次运算就可以得到上述SISD的多次运算结果,即一条指令可以并发执行多份数据,因此SIMD也称为向量化计算。
到底是什么奇技淫巧使得SIMD具有并发执行多份数据的能力呢?
其实就是CPU增加了专门用于向量化计算的向量寄存器,这些寄存器跟普通的寄存器不太一样,它们的位宽都比较大,比如有128bit,256bit,甚至512bit,也就是说这些寄存器可以分别一次存储16byte,32byte,64byte的数据。比如上图的加法运算,SISD一条指令只能完成一次两个8byte数据的加法运算。但是SIMD,一条指令就可以完成a[0:7] + b[0:7] = c[0:7],两组数据的加法运算。
CPU除了增加向量寄存器,还为向量寄存器配套了专门的指令集,比如Intel的MMX,SSE(MMX的升级版),AVX(SSE的升级版)指令集。CPU运算时,识别到指令集命令,就会采用指令集对应的SIMD计算方法完成并发运算。Intel指令集查询链接:个人学习和技术验证
二、memcpy_fast方法
带着memcpy是否还可以继续优化的疑问,一通搜索,真找到了采用SIMD技术的memcpy方法:memcpy_fast,链接:GitHub - skywind3000/FastMemcpy: Speed-up over 50% in average vs traditional memcpy in gcc 4.9 or vc2012
分析了一下源码实现。
(1)SSE指令集实现的fast拷贝
1、使用_mm_loadu_si128指令,从src + 0的位置取走128bit,即16字节,然后依次类推,src + 1,...,直至src + 7,一共取走16byte * 8=128byte,取出的内容分别储存到向量寄存器c0,c1,...,c7;
2、使用_mm_prefetch实现数据预取,提前把数据从内存加载到cache,保证CPU对数据的快速读取;
3、使用_mm_store_si128指令,将c0,c1,...,c7寄存器的内容分别存储至目的地址dst + 0, dst + 1,..., dst + 7的八个位置。
利用指令集、向量寄存器、数据预取技术实现了每次16byte的并发,128byte的批次拷贝。

图2
(2)AVX指令集实现的fast拷贝
与SSE指令集实现内存拷贝逻辑一致。
1、由AVX指令集的_mm256_loadu_si256,实现每次256byte的数据加载;
2、由AVX指令集的_mm256_storeu_si256,实现每次256byte数据的存储。
可以预料,当然是寄存器位宽越大,性能会越好,也就是从理论上说使用AVX指令集会比SSE指令集更快。
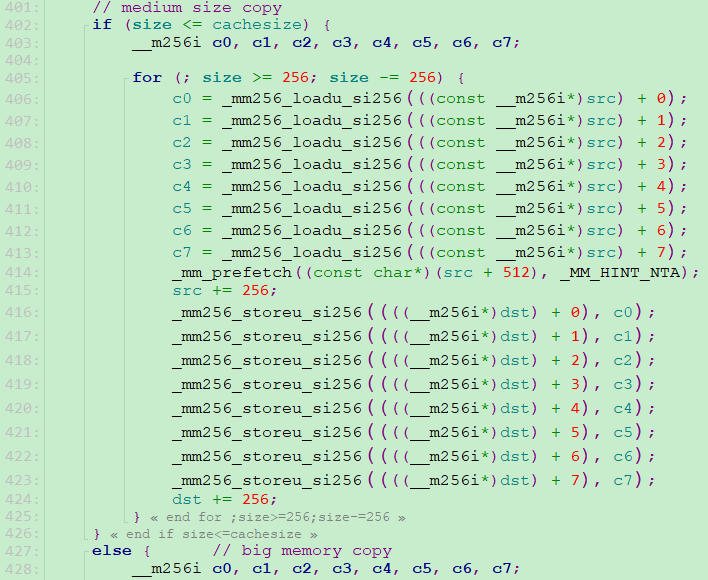
图3
三、memcpy VS memcpy_fast
我们一起来看看memcpy与使用了SIMD技术的memcpy_fast的性能对比吧。
直接将memcpy_fast源码下载后编译即可,链接:GitHub - skywind3000/FastMemcpy: Speed-up over 50% in average vs traditional memcpy in gcc 4.9 or vc2012
SSE指令集编译命令:gcc -O3 -msse2 FastMemcpy.c -o FastMemcpy
AVX指令集编译命令:gcc -O3 -mavx FastMemcpy_Avx.c -o FastMemcpy_Avx
(1)SSE指令集下性能结果对比
绿色框里,即内存拷贝在1MB以下时,特别是拷贝长度在(1024 ~ 1048576)bytes时,拷贝性能有显著提升。但是靠拷贝长度超过1MB时,memcpy_fast居然比memcpy更慢了,发生了什么?
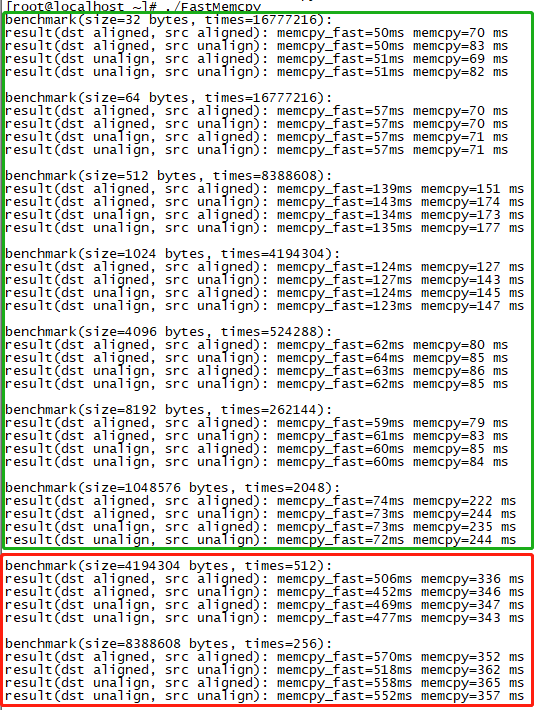
图4
继续查阅源码,发现在大于2MB时,与2MB长度以下的拷贝相比,采用了不同的SIMD拷贝指令。即在拷贝长度小于等于 cachesize = 0x200000 时,使用 _mm_store_si128进行数据存储;在大于0x200000 时,使用_mm_stream_si128进行数据存储。
![]()

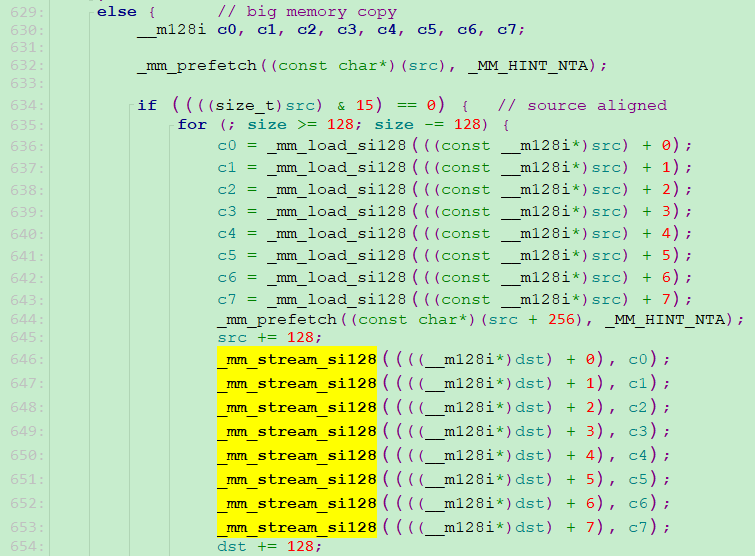
图5
我把大长度数据拷贝由_mm_stream_si128替换为中等长度数据拷贝指令_mm_store_si128后,memcpy_fast无论是中等长度,还是大长度的数据拷贝性能都比memcpy要好。
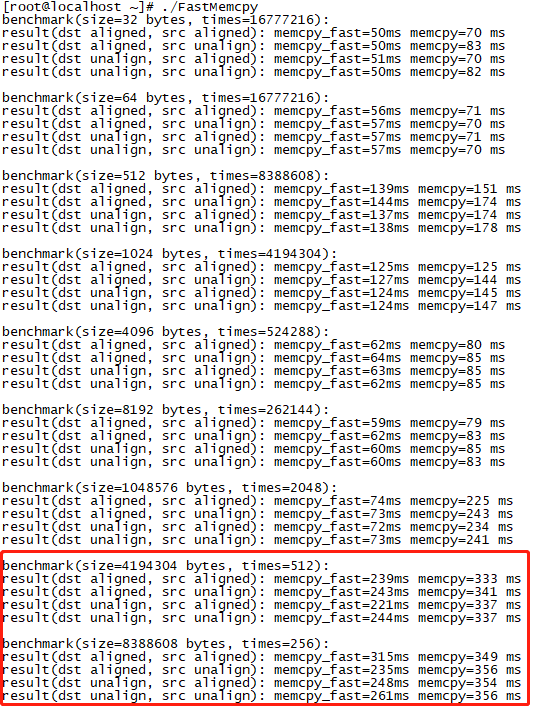
图6
(2)AVX指令集下性能结果对比
同样,将AVX大长度数据拷贝也进行优化,将指令_mm256_stream_si256替换为_mm256_storeu_si256,AVX指令集的性能测试结果如下图7所示。
简单总结为两点:
1、图6和图7进行了充分说明,相同长度的数据拷贝,AVX确实比SSE性能更高;
2、拷贝长度在(512 ~ 8388608)bytes,memcpy_fast都比memcpy要提升一倍不止,有的长度,内存拷贝性能甚至提升了4倍!

图7
四、结语
这种内存拷贝的性能提升,有什么好处呢?
想到一个场景,比如生产环境的网关设备(FW,VPN等等),内存拷贝的性能提升可以降低网关设备的流量处理时延,提升网络质量,从而进一步提高用户使用体验。
相关文章:
比memcpy还要快的内存拷贝,了解一下
前言 朋友们有想过居然还有比memcpy更快的内存拷贝吗? 讲道理,在这之前我没想到过,我也一直觉得memcpy就是最快的内存拷贝方法了。 也不知道老板最近是咋了,天天开会都强调:“我们最近的目标就一个字,性能优…...

正则表达式常用字符及案例
引言 正则表达式是一种强大而灵活的工具,它在文本搜索和处理中起到了至关重要的作用。熟练掌握正则表达式的常用字符和使用方法,将能帮助开发者更加高效地进行模式匹配和字符串操作。本文将介绍一些常见的正则表达式字符,并给出一些实际案例…...
周训龙老兵参观广西森林安全紧急救援装备演练
7月21日上午,周训龙老兵参观广西紧急救援促进中心在南宁市青秀山举行森林安全紧急救援装备演练,多功能水罐消防车、无人救援机等先进设备轮番上阵,展示了广西应对突发事件的紧急救援速度和水平。广西壮族自治区应急厅不情愿参此次演练活动。 …...

[开发|java] java 将json转化java对象
使用Jackson库将JSON转换为Java对象: 安装依赖 <!-- Jackson Core --> <dependency><groupId>com.fasterxml.jackson.core</groupId><artifactId>jackson-core</artifactId><version>2.12.5</version> </depen…...
平台化的测试工具推荐|一站式测试平台RunnerGo
互联网行业的发展到今天越来越多的公司更加注重工作效率和团队协作,越来越多的产品也趋于平台化,平台化也更有利于提高团队效率,代码管理、持续构建、持续部署这些工具的发展都是非常超前的,它们对于团队协作的支持和工作效率的提…...
PCB封装设计指导(十五)验证封装的正确性
PCB封装设计指导(十五)验证封装的正确性 封装建立好之后,我们需要验证封装是否能够正常的放入PCB文件中,最好最直接的办法就是直接放入PCB中来验证。 具体操作如下 任意新建一个空白的PCB文件点击File 选择NEW...

Godot 4 插件 - Utility AI 研究
今天看到一个视频教学 Godot4 | 实现简单AI | Utility AI 插件_哔哩哔哩_bilibili 就看了一下。吸引我的不是插件,是AI这两个字母。这AI与Godot怎么结合?感觉还是离线使用,值得一看。 视频时间不长,15分钟左右,看得…...

第八章:将自下而上、自上而下和平滑性线索结合起来进行弱监督图像分割
0.摘要 本文解决了弱监督语义图像分割的问题。我们的目标是在仅给出与训练图像关联的图像级别对象标签的情况下,为新图像中的每个像素标记类别。我们的问题陈述与常见的语义分割有所不同,常规的语义分割假设在训练中可用像素级注释。我们提出了一种新颖的…...
MySql忘记密码如何修改
前言 好久没用数据库的软件了,要用的时候突然发现密码已经忘记了,怎么试都不对,心态直接爆炸,上一次用还是22年6月份,也记不得当时用数据库干什么了,这份爆炸浮躁的心态值得这样记录一下,警示自…...

【NetCore】04-作用域与对象释放行为
文章目录 作用域 作用域由IServiceScope接口承载 对象释放 实现IDisposable接口类型释放 1.DI只负责释放由其创建的对象实例 2.DI在容器或子容器释放时,释放由其创建的对象实例 建议 1.避免在根容器获取实现IDisposable接口的瞬时服务 2.避免手动创建实现了IDispo…...

新材料技术的优势
目录 1.什么是新材料技术 2.新材料技术给人类带来了哪些便利 3.新材料技术未来的发展趋势 1.什么是新材料技术 新材料技术指的是通过科学和工程技术的手段开发和应用全新的材料,以满足特定的需求和应用。新材料技术是材料科学和工程领域的重要研究方向࿰…...

HTTPS、DNS、正则表达式
HTTPS原理 HTTPS(Hypertext Transfer Protocol Secure)是一种安全的通信协议,它基于HTTP协议,在数据传输过程中使用了加密技术来保护通信的安全性和完整性。HTTPS的工作原理主要包括以下几个步骤: 客户端发起HTTPS请求…...

MAC电脑设置charles,连接手机的步骤说明(个人实际操作)
目录 一、charles web端设置 1. 安装charles之后,先安装证书 2. 设置 Proxy-Proxy Settings 3. 设置 SSL Proxying 二、手机的设置 1. 安卓 2. ios 资料获取方法 一、charles web端设置 1. 安装charles之后,先安装证书 Help-SSL Proxying-Inst…...
百度文心一言接入教程-Java版
原文链接 前言 前段时间由于种种原因我的AI BOT网站停运了数天,后来申请了百度的文心一言和阿里的通义千问开放接口,文心一言的接口很快就通过了,但是文心一言至今杳无音讯。文心一言通过审之后,很快将AI BOT的AI能力接入了文心…...
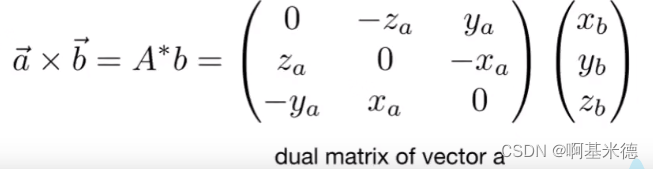
Games101学习笔记 - 基础数学
向量 向量:方向和长度,没有起始位置 向量长度:各个方向平方相加开方 单位向量:向量除向量的长度 点乘 在笛卡尔坐标系中的点乘计算: 几何意思: 表示一个向量在另一个向量上的投影点乘在图形学中应用&a…...

Linux进程的认识
查看进程指令proc/ps 注意哦, 我们经常使用的指令, 像ls, touch…这些指令在启动之后本质上也是进程 proc 是内存文件系统, 存放着当前系统的实时进程信息. 每一个进程在系统中, 都会存在一个唯一的标识符(pid -> process id), 就如同学生在学校里有一个专门的学号一样. 大…...
向量vector与sort()
运行代码: //向量与sort() #include"std_lib_facilities.h" //声明Item类 struct Item {string name;int iid;double value;friend istream& operator>>(istream& is, Item& ii);friend ostream& operator<<(ostream& o…...

Netty学习(三)
文章目录 三. Netty 进阶1. 粘包与半包1.1 粘包现象服务端代码客户端代码 1.2 半包现象服务端代码客户端代码 1.3 现象分析粘包半包缘由滑动窗口MSS 限制Nagle 算法 1.4 解决方案方法1,短链接方法2,固定长度方法3,固定分隔符方法4,…...

c++学习(布隆过滤器)[23]
布隆 布隆过滤器(Bloom Filter)是一种概率型数据结构,用于判断一个元素是否可能存在于一个集合中。它使用多个哈希函数和位图来表示集合中的元素。 布隆过滤器的基本原理如下: 初始化:创建一个长度为m的位图…...
React的UmiJS搭建的项目集成海康威视h5player播放插件H5视频播放器开发包 V2.1.2
最近前端的一个项目,大屏需要摄像头播放,摄像头厂家是海康威视的,网上找了一圈都没有React集成的,特别是没有使用UmiJS搭脚手架搭建的,所以记录一下。 海康威视的开放平台的API地址,相关插件和文档都可以下…...

Stitches API完全指南:从基础配置到自定义扩展
Stitches API完全指南:从基础配置到自定义扩展 【免费下载链接】stitches HTML5 Sprite Sheet Generator 项目地址: https://gitcode.com/gh_mirrors/sti/stitches Stitches是一款强大的HTML5 Sprite Sheet Generator,它提供了直观的API接口&…...

机器学习赋能6G近场通信:从信道估计到波束赋形的智能革命
1. 项目概述:当6G遇见近场,为何机器学习成为破局关键?如果你关注过5G到6G的技术演进路线,会发现一个核心趋势:天线阵列的规模正在从“大规模”走向“极大规模”。这不仅仅是数量的堆砌,更是通信物理原理的一…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...
—东方仙盟)
酒店门锁V10SDK接口说明-幽冥大陆(一百23)—东方仙盟
相关文件系统环境C# :NET.20,NET3.5,NET4,NET4.5,NET 5.0C:VS2005,VS2012,VS2015操作系统:未来之窗VOSWEB:CHROME43核心代码完整代码using System; using System.Collections.Generic; using System.Text; using System.Collections.Specialized;using System.Windo…...

C语言双端队列完整实现:一行代码吃透头尾操作,算法效率拉满
一、为什么C语言实现双端队列,是数据结构的必学天花板?在C语言数据结构里,队列、栈都是基础中的基础,但真正能把灵活度、效率、内存管理三者揉到一起的,还得是双端队列(deque)。普通队列只能一头…...

【CP-05】RTE运行时环境 - SWC的操作系统接口
CP-05_RTE运行时环境【CP-05】RTE运行时环境 - SWC的“操作系统接口”前言在AUTOSAR架构中,RTE(Runtime Environment,运行时环境)是一个常被提及却难以理解的概念。它像是应用层软件组件(SW-C)与底层基础软…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

别再死记硬背了!用UE材质里的点积、叉积,5分钟搞定模型表面动态光效
用UE材质玩转动态光效:点积、叉积实战指南第一次接触UE材质编辑器时,看到那些密密麻麻的数学节点总让人头皮发麻。特别是"点积"、"叉积"这些听起来就很高深的术语,很容易让美术背景的创作者望而却步。但你知道吗…...

别再只会用--nogpgcheck了!手把手教你安全修复PostgreSQL yum源的GPG密钥问题
企业级PostgreSQL部署:安全解决GPG密钥验证的完整方案 当你在生产环境中部署PostgreSQL时,遇到GPG签名验证错误直接使用--nogpgcheck绕过检查,就像因为门锁打不开就直接把门拆掉一样危险。本文将带你深入理解GPG验证机制,并提供一…...

如何快速解锁加密音乐文件:3个简单步骤让音乐自由播放
如何快速解锁加密音乐文件:3个简单步骤让音乐自由播放 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https…...