LightGlue论文翻译
LightGlue:光速下的局部特征匹配
摘要 - 我们介绍 LightGlue,一个深度神经网络,学习匹配图像中的局部特征。我们重新审视 SuperGlue 的多重设计决策,稀疏匹配的最新技术,并得出简单而有效的改进。累积起来,它们使 LightGlue 更加高效——在内存和计算方面,更加精确,更容易训练。一个关键特性是 LightGlue 能够适应问题的难度: 对于直观上容易匹配的图像对,比如由于较大的视觉重叠或有限的外观变化,推断速度要快得多。这为在3D 重建等对延迟敏感的应用程序中部署深度匹配器开辟了令人兴奋的前景。代码和经过培训的模型可在 github.com/cvg/lightglue 公开查阅。
1.引言
寻找两幅图像之间的对应关系是许多计算机视觉应用程序(如相机跟踪和3D建图)的基本组成部分。最常见的图像匹配方法依赖于稀疏的兴趣点,这些兴趣点使用高维表示对其局部视觉外观进行编码进行匹配。可靠地描述每个点在表现出对称性,弱纹理,或外观变化,由于不同的视点和照明是挑战性的。为了拒绝由遮挡和缺失点产生的异常值,这种表示也应该是判别的。这就产生了难以满足的两个相互冲突的目标:鲁棒性和唯一性。
为了解决这些限制,SuperGlue[56]引入了一种新的范例——一种深度网络,它同时考虑两个图像,共同匹配稀疏点并拒绝异常值。它利用强大的Transformer模型[74]来学习匹配来自大型数据集的具有挑战性的图像对。这在室内和室外环境中都产生了鲁棒的图像匹配。SuperGlue对于具有挑战性条件下的视觉定位非常有效[59,55,58,57],并且可以很好地推广到其他任务,如空中匹配[83],目标姿态估计[69],甚至是鱼类再识别[47]。
然而这些改进的计算昂贵,而图像匹配的效率对于需要低延迟的任务(如跟踪)或需要高处理量的任务(如大规模建图)至关重要。此外,SuperGlue 与其他基于 Transformer 的模型一样,非常难以训练,需要许多从业者无法访问的计算资源。后续工作[8,65]因此未能达到原来的 Su-perGlue 模型的性能。然而,自从它最初的出版,Transformer 已经被广泛的研究,改进,并应用于许多语言[17,51,13]和视觉[18,6,29]任务。
在本文中,我们借鉴这些见解来设计Light- Glue,这是一个比SuperGlue更准确、更高效、更容易训练的深度网络。我们重新审视了它的设计决策,并结合了许多简单而有效的结构修改。我们用有限的资源提炼出训练高性能深度匹配器的配方,在短短几个gpu时间内达到最先进的精度。如图1所示,与现有的稀疏和密集匹配器相比,LightGlue在效率和精度权衡方面是帕累托最优的。
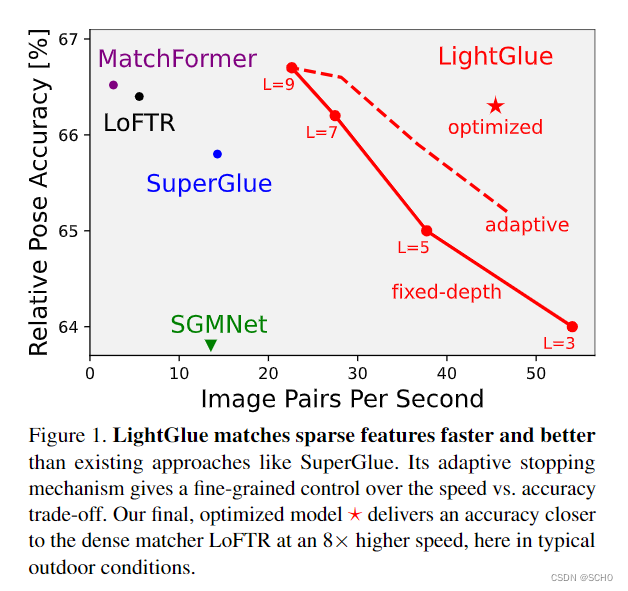
与之前的方法不同,LightGlue可以自适应每个图像对的难度,这取决视觉重叠、外观变化或区别性信息的数量。图2显示,在直观上容易匹配的配对上,推理速度要比在具有挑战性的配对上快得多,这种行为让人想起人类处理视觉信息的方式。这是通过1)在每个计算块之后预测一组对应来实现的,2)使模型能够自省并预测是否需要进一步的计算。lightglue还在早期阶段丢弃不匹配的点,从而将其注意力集中在共同可见区域。

我们的实验表明,LightGlue是SuperGlue的即插即用替代品:它在一小部分运行时间内预测两组局部特征的强匹配。这为在延迟敏感的应用中部署深度匹配器(如SLAM[45,5])或从众包数据中重构更大的场景[25,60,39,57]开辟了令人兴奋的前景。LightGlue模型及其训练代码将在许可许可下公开发布。
2.相关工作
匹配描绘相同场景或物体的图像通常依赖于局部特征,这些局部特征是稀疏的关键点,每个关键点都与其局部外观的描述符相关联。虽然经典算法依赖于手工制作的标准和梯度统计[41,23,4,53],但最近的许多研究都集中在为检测[81,16,19,52,73]和描述[42,72]设计卷积神经网络(cnn)。经过挑战性数据的训练,cnn在很大程度上提高了匹配的准确性和鲁棒性。局部特征现在有多种形式:一些是更好的本地化[41],高度可重复[16],便宜的存储和匹配[54],不受特定变化的影响[46],或者忽略不可靠的对象[73]。
然后在描述符空间中用最近邻搜索匹配局部特征。由于关键点不匹配和描述符不完善,导致一些对应不正确。这些都是通过启发式过滤出来的,如 Lowe 的比率检验[41]或相互检验,内点分类器[44,82] ,以及强大的拟合几何模型[22,7]。这个过程需要广泛的领域专业知识和调优,并且当条件太具挑战性时很容易失败。这些限制在很大程度上被深度匹配解决了。
深度匹配器是经过训练的深度网络,用于联合匹配局部特征并拒绝给定输入图像对的异常值。SuperGlue[56]将Transformers[74]的表达性表示与最优传输[48]相结合,解决了部分分配问题。它学习了关于场景几何和相机运动的强大先验,因此对极端变化具有鲁棒性,并且可以很好地跨数据域进行推广。继承了早期Transformers的局限性,超级胶水很难训练,其复杂性随着关键点的数量呈二次增长。
随后的工作通过减少注意机制的大小使其更加有效。他们将其限制在一小组种子匹配[8]或类似关键点的集群内[65]。这在很大程度上减少了大量关键点的运行时间,但是对于较小的标准输入大小没有任何好处。这也削弱了在最具挑战性的条件下的稳健性,无法达到原始SuperGlue模型的性能。相反,LightGlue为典型的操作条件(如SLAM)带来了巨大的改进,而不会影响任何难度级别上的性能。这是通过动态调整网络大小而不是减少其总容量来实现的。
相反,像LoFTR[68]和后续[9,78]这样的密集匹配器匹配点分布在密集网格上,而不是稀疏的位置。这将鲁棒性提升到令人印象深刻的水平,但通常要慢得多,因为它处理更多的元素。这限制了输入图像的分辨率,进而限制了对应的空间精度。虽然LightGlue在稀疏输入上运行,但我们表明,公平的调优和评估使其在一小部分运行时间内与密集匹配器竞争。
随着Transformers在语言处理方面的成功,提高它们的效率受到了极大的关注。由于注意力的内存占用是处理长序列的主要限制,许多工作使用线性公式[79,32,33]或瓶颈潜在标记[35,30]来减少它。这样可以实现远程上下文,但对于小的输入大小可能会损害性能。选择性检查点[49]减少了注意力的内存占用,优化了内存访问也大大加快了它的速度。
另外,正交工作通过预测给定层上令牌的预测是最终的还是需要进一步的计算来自适应地调节网络深度[15,20,62]。这主要是受视觉社区为cnn开发的自适应方案的启发 [71, 80, 40, 21, 36, 76]. 在Transformers中位置编码的类型对精度有很大的影响。虽然绝对正弦[74]或学习编码[17,51]最初很流行,但最近的研究工作已经研究了相对编码[63,67],以稳定训练并更好地捕获远程依赖关系。
LightGlue将其中一些创新应用于2D特征匹配,并在效率和准确性方面都有所提高。
3.快速特征匹配
问题公式化:继SuperGlue之后,LightGlue预测了从图像A和图像B中提取的两组局部特征之间的部分分配。每个局部特征 i i i由2D点位置 p i : = ( x , y ) i ∈ [ 0 , 1 ] 2 p_i:=(x,y)_i\in[0,1]^2 pi:=(x,y)i∈[0,1]2,由图像尺寸归一化,一个视觉描述子 d i ∈ R d d_i \in \mathbb R^d di∈Rd组成,图像A和B分别有M和N个局部特征,它们的分别索引为A:={1,…,M}和B:={1,…,N}。
我们设计LightGlue来输出一组通信 M = { ( i , j ) } ⊆ A × B \mathcal M = \{(i,j)\}\subseteq A×B M={(i,j)}⊆A×B。每个点至少匹配一次,因为它源于一个独特的3D点,并且由于遮挡或不可重复性,一些关键点是不可匹配的。因此,与之前的工作一样,我们在A和B的局部特征之间寻求一个软部分分配矩阵 P ∈ [ 0 , 1 ] M × N P∈[0,1]^{M×N} P∈[0,1]M×N,从中提取对应关系。
概述-图3:LightGlue由L个相同的层堆叠而成,可以共同处理两个集合。每一层都由自注意单元和交叉注意单元组成,它们更新每个点的表示。然后,分类器在每一层决定是否停止推理,从而避免不必要的计算。一个轻量级的头最终从表示集合中计算出部分赋值。
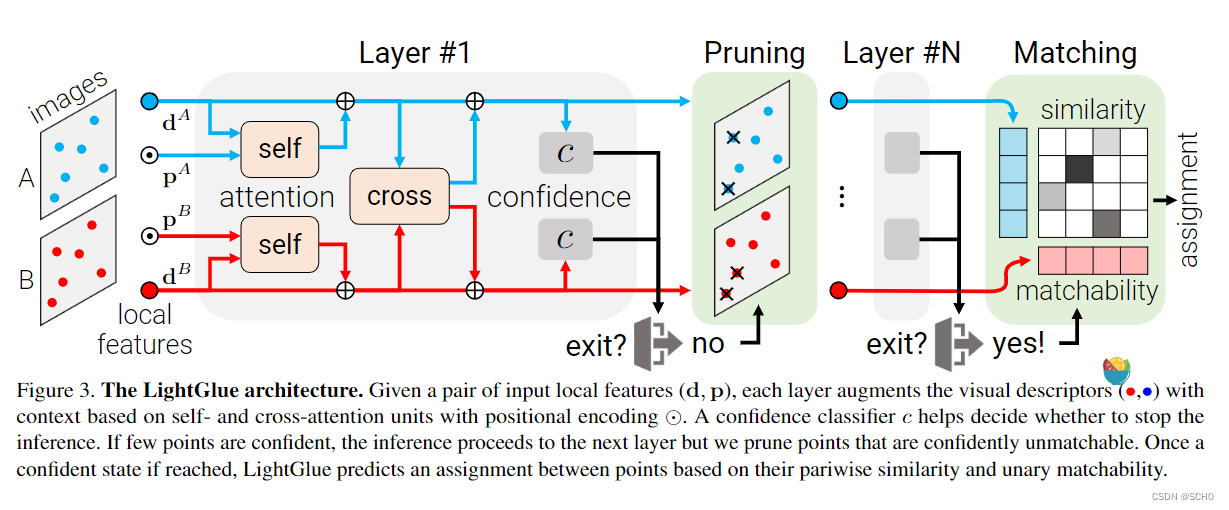
3.1 Transform 骨架
我们将图像 I ∈ { A , B } I∈\{A,B\} I∈{A,B}中的每个局部特征i与状态 x i I ∈ R d x^I_i∈R^d xiI∈Rd相关联。状态由相应的视觉描述子 x i I ← d i I x^I_i←d^I_i xiI←diI初始化,随后由每层更新。我们将一个层定义为连续的一个自注意力单元和一个交叉注意力单元。
注意力单元:在每个单元中,多层感知器(MLP)根据源图像 S ∈ { A , B } S∈\{A,B\} S∈{A,B}聚合的给定消息 m i I ← S m^{I←S}_i miI←S更新状态:
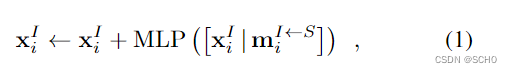
其中[·|·]叠加两个向量。这是对两个图像中的所有点并行计算的。在自注意单元中,每个图像I从同一图像的点提取信息,因此S = I。在交叉注意单元中,每个图像从另一个图像中提取信息,S = {A,B}\I。
消息通过注意机制计算为图像S的所有状态j的加权平均值:

其中W是一个投影矩阵, a i j I S a^{IS}_{ij} aijIS是图像I和S的点i和点j之间的注意力分数。这个分数在自注意单元和交叉注意单元中计算有何不同。
自注意力:每个点关注同一图像的所有点。我们对每个图像I执行相同的以下步骤,因此为了清晰起见,去掉上标I。对于每个点i,首先将当前状态xi通过不同的线性变换分解为键和查询向量ki和qi。然后我们定义点i和点j之间的注意力得分:
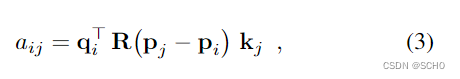
其中 R ( ⋅ ) ∈ R d × d R(·)∈R^{d×d} R(⋅)∈Rd×d是点之间的相对位置的旋转编码[67]。我们将空间划分为d/2个二维子空间,并根据傅立叶特征[37]将每个子空间旋转一个角度,以对应于投影到学习的基础 b k ∈ R 2 b_k∈R^2 bk∈R2上:
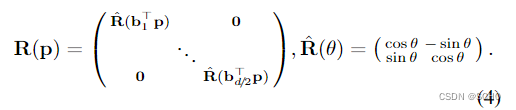
位置编码是注意的关键部分,因为它允许根据不同的位置来处理不同的元素。我们注意到,在投影相机几何中,视觉观测的位置等价于相机在图像平面内的平移:源自同一正面平行平面上的3D点的2D点以相同的方式平移,并且它们的相对距离保持不变。这就要求编码只捕获点的相对位置,而不捕获点的绝对位置。
旋转编码[67]使模型能够从i检索位于学习的相对位置的点j。位置编码不应用于值Vj,因此不会溢出到状态Xi。编码对于所有层都是相同的,因此只计算一次并缓存。
交叉注意力:每个点都注意到另一个图像S的所有点。我们为每个元素计算一个键Ki,但没有查询。这允许将分数表示为
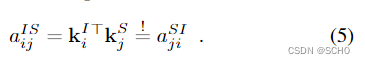
因此,对于 I ← S I←S I←S和 S ← I S←I S←I消息,我们只需要计算一次相似度。这一技巧以前被称为双向注意[77]。由于这一步骤代价高昂,复杂度为O(NMD),因此它节省了2的显著因子。我们不添加任何位置信息,因为相对位置在图像中没有意义。
3.2 匹配预测
我们设计了一个轻量级头部,它可以预测任意层的更新状态。
分配分数:我们首先计算两个图像点之间的两两得分矩阵 S ∈ R m × n S∈R^{m×n} S∈Rm×n
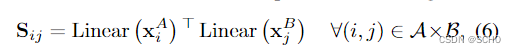
其中,线性(·)是带偏差的学习线性变换。该分数编码对应的每对点的亲和力,即相同3D点的2D投影。我们还计算每个点的匹配度分数为
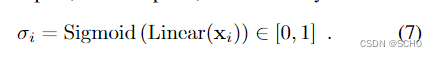
这个分数编码了i有一个相应点的可能性。在另一个图像中没有检测到的点,例如当被遮挡时,是不匹配的,因此具有σi→0。对应关系:我们将相似度和匹配度得分合并到软部分分配矩阵P中:
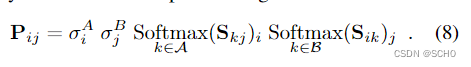
当两个点被预测为可匹配并且当它们的相似性高于两个图像中的任何其他点时,一对点(i,j)产生对应。我们选择Pij大于阈值τ并且大于沿着其行和列的任何其他元素的对。
3.3自适应深度和宽度
我们增加了两种机制,避免了不必要的计算,节省了推理时间:i)根据输入图像对的难度减少了层数;ii)我们剔除了早期确信被拒绝的点。
置信度分类器:LightGlue的主干输入带有上下文的可视描述符。如果图像对很容易,即具有高度的视觉重叠和很少的外观变化,则这些通常是可靠的。在这种情况下,早期层的预测是可信的,并且与后期层的预测相同。
在每个层的末尾,LightGlue推断每个点的预测分配的置信度:
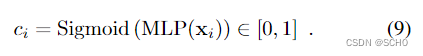
较高的值表明i的表示是可靠的和最终的-它肯定是匹配的或不匹配的。这是受到成功地将这一策略应用于语言和视觉任务的多部作品的启发[62,20,71,80,40]。在最坏的情况下,紧凑型MLP仅增加2%的推理时间,但大多数情况下节省的时间要多得多。
退出标准:对于给定的层ℓ,如果Ci>ℓλ,则点被认为是确定的。如果所有点的足够比率α是有把握的,则我们停止推断:
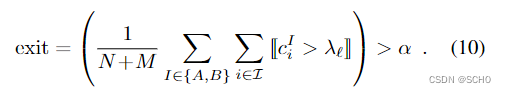
我们观察到,正如在[62]中一样,分类器本身在早期层中不那么容易确定。因此,我们基于每个分类器的验证精度在整个层中衰减ℓλ。退出4阈值α直接控制精度和推断时间之间的权衡。
点修剪:当不满足退出标准时,预测为自信和不匹配的点不太可能有助于后续层中其他点的匹配。例如,这样的点位于图像上明显不可见的区域。因此,我们在每一层都丢弃它们,只将剩余的点提供给下一层。考虑到注意力的二次方复杂性,这显著减少了计算量,并且不影响准确性。

3.4 监督
我们分两个阶段训练LightGlue:首先训练它以预测对应关系,然后才训练置信度分类器。因此,后者不影响最后一层的准确性或训练的收敛。
通信:我们监督分配矩阵P与地面真实标签估计从两个视点变换。给定一个单应或像素深度和一个相对姿势,我们将点从A换到B,反之亦然。地面真实匹配的M,在两幅图像中具有低的重新投影误差和一致的深度。当重投影或深度误差与所有其他点足够大时,A⊆A和B⊆B的一些点被标记为不匹配。然后,我们最小化在每一层ℓ预测的赋值的对数似然,推动LightGlue及早预测正确的对应:
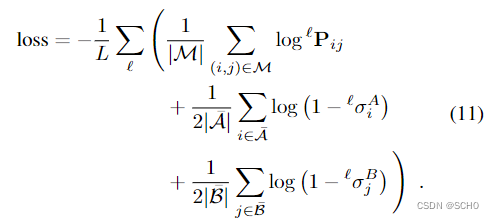
损失在正面标签和负面标签之间平衡。
置信度分类器:然后我们训练等式(9)的MLP预测每一层的预测是否与最终的预测相同。设 ℓ m i A ∈ B ∪ ⋅ {}^ℓm^A_i∈B∪{·} ℓmiA∈B∪⋅是B中与ℓ层匹配的点i的索引,如果i不匹配, ℓ m i A = ⋅ {}^ℓm^A_i=· ℓmiA=⋅。每个点的真实二进制标签为 ℓ m i A = L m i A {}^ℓm^A_i={}^Lm^A_i ℓmiA=LmiA,且对B恒定。然后,我们最小化了Layersℓ∈{1,…,L−1}的分类器的二进制交叉熵。
3.5 与SuperGlue的比较
LightGlue的灵感来自强力胶,但在对其准确性、效率和易用性至关重要的方面有所不同。
位置编码:Superglue使用MLP对绝对点位置进行编码,并及早将它们与描述符融合。我们观察到,模型往往会忘记各层的位置信息。取而代之的是LightGlue依赖于一种相对编码,这种编码在图像之间具有更好的可比性,并被添加到每个自我注意单元中。这使得利用位置更容易,并提高了更深层次的精度。
预测头:Superglue通过使用Sinkhorn算法解决可微的最优运输问题来预测分配[66,48]。它包括按行和按列的归一化的多次迭代,这在计算和存储方面都是昂贵的。我们发现,垃圾桶纠缠了所有点的相似度得分,从而产生了次优的训练动力学。LightGlue解开了相似性和匹配性,这两项预测要高效得多。这也会产生更清晰的渐变。
深度监督:由于Sinkhorn非常昂贵,Superglue不能在每一层之后进行预测,只在最后一层进行监督。LightGlue的头部较轻,因此可以预测每一层的任务并进行监督。这加快了收敛速度,并允许在任何层之后退出推理,这是LightGlue效率提高的关键。
4.重要的细节
食谱:LightGlue遵循SuperGlue的监督培训设置。我们首先用从1M幅图像中采样的合成同形图像来预先训练模型[50]。这样的扩容提供了全面和无噪音的监督,但需要仔细调整。然后,使用MegaDepth数据集[38]对LightGlue进行微调,其中包括1M张众包图像,从中挑选出196个旅游地标,通过SfM恢复相机校准和姿势,并通过多视角双目恢复密集深度。
训练技巧:虽然LightGlue架构提高了训练的速度、稳定性和准确性,但我们发现一些细节也有很大的影响。图5展示了与Superglue相比,这减少了训练模型所需的资源。这降低了训练成本,使深度匹配器更容易为更广泛的社区所接受。
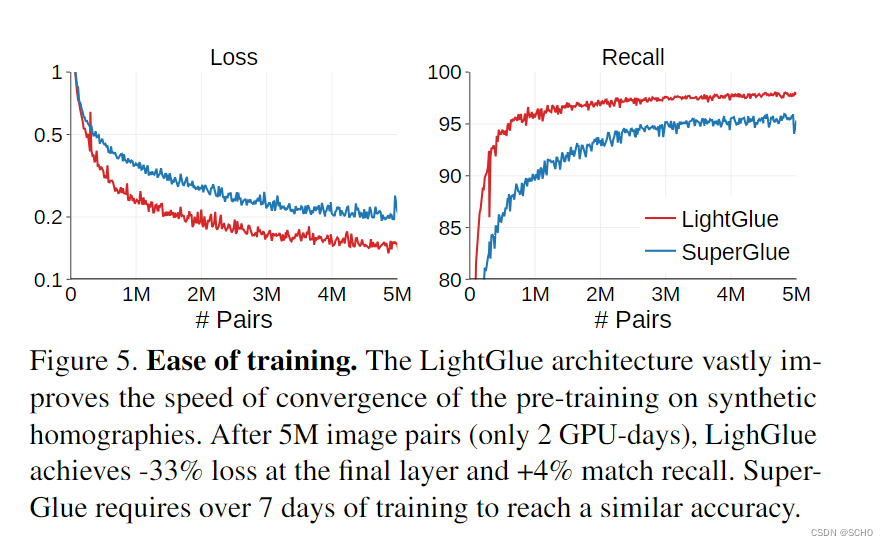
由于MegaDepth的深度图通常是不完整的,我们也将具有较大极线误差的点标记为不匹配。仔细调整和退火法的学习速度提高了精度。点数更多的训练也起到了作用:我们使用2k而不是1k。批次大小很重要:我们使用渐变检查点[10]和混合精度在具有24 GB VRAM的单个GPU上容纳32个图像对。
实现细节:LighGue有L=9层。每个注意单元有4个头。所有的表示都有维度d=256。在整篇文章中,被称为优化的运行时数字使用了自我注意的有效实现[14]。附录中提供了更多详细信息。
我们使用SuperPoint[16]和SIFT[41]局部特征训练LightGlue,但它与任何其他类型兼容。在MegaDepth[38]上微调模型时,我们使用了Sun等人的数据拆分。[68]避免在图像匹配挑战赛中的场景中进行训练。
5.实验
我们评估了LightGlue在单应性估计、相对姿势估计和视觉定位方面的任务。我们还分析了我们的设计决策的影响。
5.1 单应估计
我们评估了LightGlue在HPatches[2]数据集的平面场景上估计的对应关系的质量。该数据集由5个图像对的序列组成,每个图像对在光照或视点变化的情况下。
设置:按照Superglue[56],我们报告了与GT Matches相比的精确度和召回率,重新投影误差为3px。我们还使用稳健和非稳健求解器:RANSAC[22]和加权DLT[24]来评估从对应关系估计的单应性的准确性。对于每个图像对,我们计算四个图像角点的平均重投影误差,并报告累积误差曲线(AUC)下的面积,直到1px和5px。遵循基准测试的最佳实践[31],与过去的工作[56,68]不同,我们使用了最先进的稳健估计器[3],并分别广泛地调整了每种方法的Inlier阈值。然后我们报告得分最高的结果。
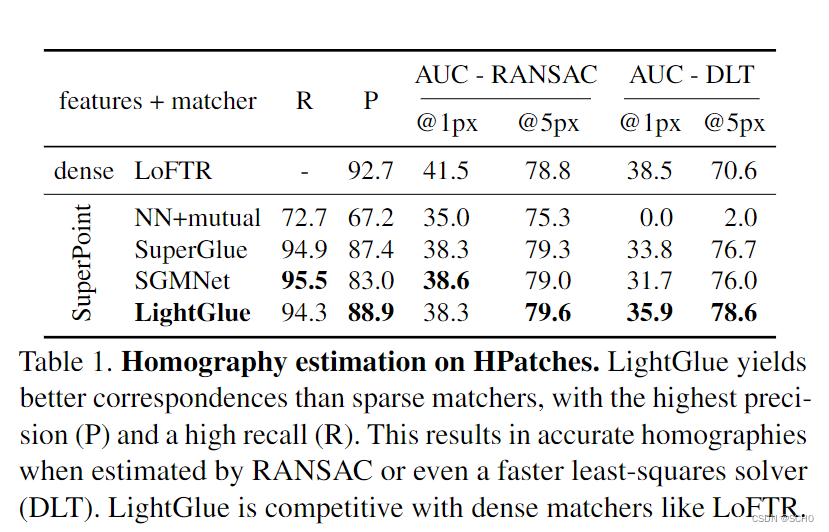
基线:我们遵循[68]的设置,调整所有图像的大小,使其较小的尺寸等于480像素。我们用SuperPoint[16]提取的1024个局部特征对稀疏匹配器进行了评估。我们将LightGlue与最近邻匹配、相互检查以及深度匹配器Superglue[56]和SGMNet[8]进行了比较。我们使用在户外数据集上训练的官方模型[38,64]。作为参考,我们还评估了密集匹配器LoFTR[68],为了公平起见,只选择了预测的前1024个匹配。
结果:表1显示LightGlue的准确率高于SU-perGlue和SGMNet,召回率与SU-perGlue和SGMNet相似。当用DLT估计同形异义词时,这比用其他匹配器得到的估计要准确得多。因此,LightGlue使DLT,一个简单的求解器,与昂贵且速度较慢的MAGSAC竞争[3]。在5px的粗略阈值下,尽管受到稀疏关键点的约束,LightGlue也比LoFTR更准确。
5.2 相对位姿估计
我们评估LightGlue用于户外场景中的姿势估计,这些场景表现出强烈的遮挡和具有挑战性的照明和结构变化。
设置:根据[68]的评估,我们使用MegaDepth-1500测试集中的图像对。测试集包含来自两个热门摄影旅游目的地的1500对图像:圣彼得斯广场和国会大厦。收集数据的方式是基于视觉重叠来平衡难度。我们在下游的相对位姿估计任务中对我们的方法进行了评估。
我们分别用Vanilla RANSAC和LO-RANSAC[34]估计了一个本质矩阵,并将它们分解成旋转和平移。Inlier阈值针对测试数据上的每种方法进行了调整-我们认为这使得比较更公平,因为我们不评估RANSAC本身。我们计算了位姿误差作为旋转和平移的最大角度误差,并报告了它在5°、10°和20°时的AUC。
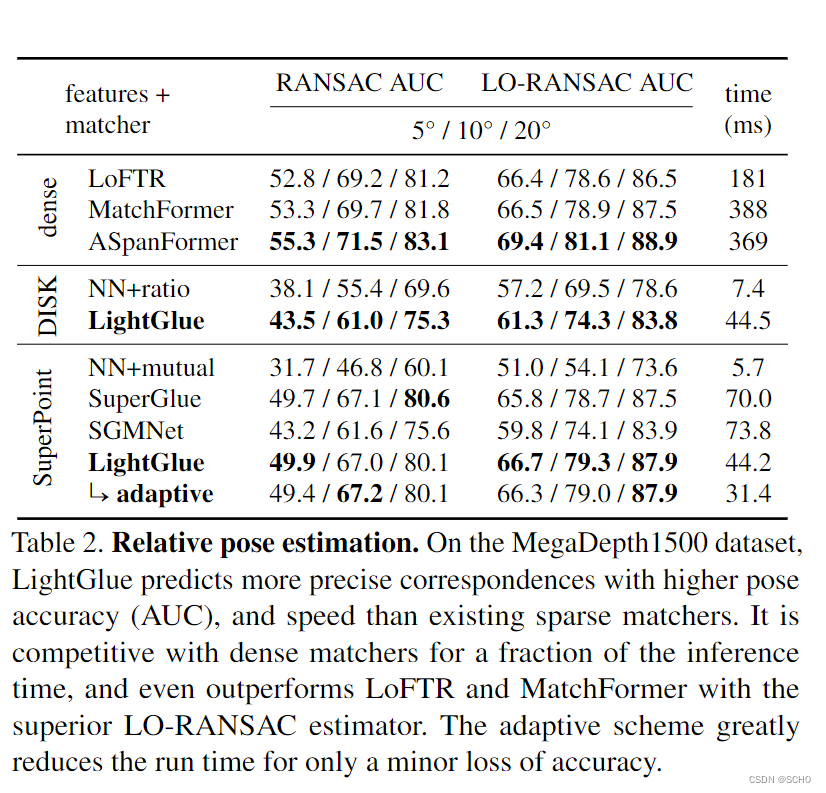
基线:我们提取每个图像的2048个局部特征,每个特征都调整了大小,使其更大的维度为1600像素。利用SuperPoint[16]的功能,我们将LightGlue与相互检查的最近邻匹配以及SuperGlue[56]和SGMNet[8]的官方实现进行了比较。对于Disk[73],我们只根据其强大的基准进行评估,因为没有其他受过训练的Disk匹配者是公开可用的。
我们还评估了最近密集的深度匹配器LoFTR[68]、MatchFormer[78]和ASpanFormer[9]。我们仔细遵循他们各自的评估设置,并调整输入图像的大小,使其最大尺寸达到840像素(LoFTR,MatchFormer)或1152像素(ASpanFormer)。较大的图像将提高其准确性,就像稀疏的特征一样,但会招致令人望而却步和不切实际的运行时间和内存要求。
结果:表2显示,LightGlue在超点特征上的性能大大优于SuperGlue和SGMNet等现有方法,并能大大提高对磁盘局部特征的匹配精度。它产生了更好的对应和更准确的相对姿势,并减少了30%的推理时间。LightGlue通常预测的匹配率略低于Superglue,但它们的预测准确率更高。通过在模型的早期检测到有把握的预测,自适应变量比Superglue和SGMNet快2倍以上,而且精度更高。通过精心调整的Lo-RANSAC[34],LightGlue可以实现比一些流行的密集匹配器更高的精度,后者的速度要慢5到11倍。在所评价的稠密匹配器中,ASAN-FORFER是最准确的。考虑到精度和速度之间的权衡,LightGlue的表现比所有方法都要好得多。
5.3 室外视觉定位
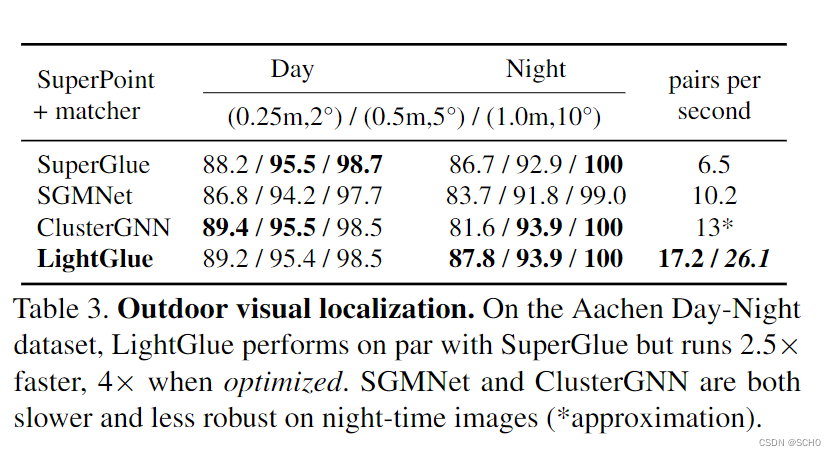
设置:我们使用大规模亚琛昼夜基准[59]来评估在Chal延长条件下的长期视觉定位[59]。我们遵循分层本地化框架和hloc工具箱[55]。我们首先使用COLMAP[60]从4328张日间参考图像中三角化一个稀疏的三维点云,其中包含已知的姿态和定标。对于824个日间和98个夜间查询中的每一个,我们使用NetVLAD[1]检索50幅图像,对每一幅图像进行匹配,并使用RANSAC和透视n点解算器估计相机姿势。我们报告了在多个阈值下的姿势回忆以及在映射和定位过程中匹配步骤的平均吞吐量.
基线:我们使用Super-Point提取多达4096个特征,并将它们与SuperGlue、SGMNet[8]、clus-terGNN[65]和具有自适应深度和宽度的LightGlue进行匹配。由于ClusterGNN的实现并不是公开可用的,我们报告了原始论文中发现的准确性和作者友好地提供的时间估计。
结果:表3显示,LightGlue达到了与Superglue类似的精度,但吞吐量增加了2.5倍。优化的变种利用了有效的自我关注[14],将吞吐量提高了4倍。因此,LightGlue可以实时匹配多达4096个关键点。
5.4 洞察
消融研究:我们通过评估LightGlue来验证我们的设计决策,LightGlue在具有极端光度增强的具有挑战性的合成单应数据集上进行了预培训。我们用SuperPoint功能和500万个样本训练了不同的变种,所有这些都是在4个GPU天内完成的。我们从应用于训练期间看不到的图像的相同增强创建一个测试集。我们从每个关键点中提取512个关键点。我们还与Superglue进行比较,后者是我们用相同的设置进行训练的。附录中提供了更多详细信息。
我们在表4中报告了烧蚀结果。与Superglue相比,LightGlue的收敛速度显著加快,召回率和准确率分别达到+4%和+12%。请注意,通过足够长的训练,Super-Glue可以达到与LightGlue类似的精度,但改进的收敛使其在新数据上进行训练更加实用。
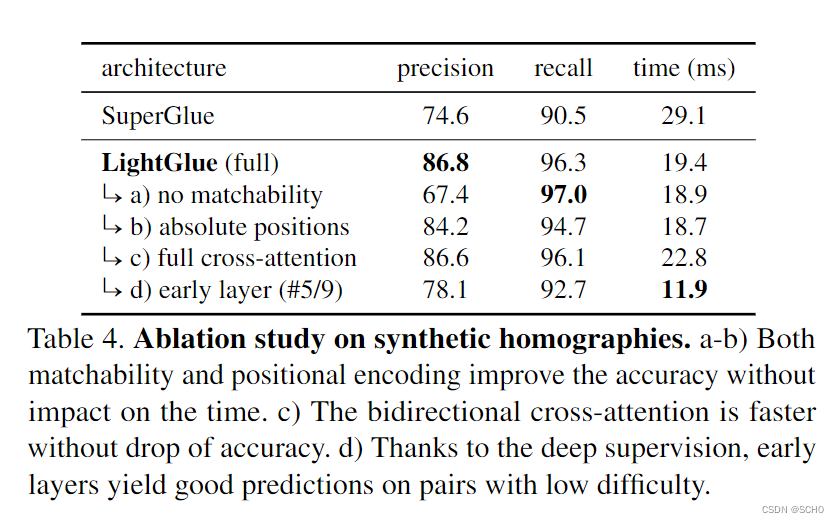
如果没有匹配性分类器,网络将失去区分好的和不好的匹配的能力,如图6所示。直观地说,相似性矩阵建议许多可能的匹配,而匹配性过滤不正确的建议。因此,我们的部分赋值可以被视为相互最近邻搜索和学习的Inlier分类器的完美融合[44,82]。这比解决 SuperGlue的最优运输问题要快得多。

用随机嵌入替换学习的绝对位置编码提高了准确率,同时在每个自我关注层轮换查询和关键字对运行时间的影响很小。通过使用相对位置,LightGlue可以学习匹配图像中的几何图案。提醒网络关于每一层的位置提高了网络的精确度为+2%健壮性。
双向交叉注意与标准交叉注意具有同样的精确度,但由于只计算一次相似性矩阵,因此节省了20%的运行时间。目前的瓶颈是沿两个维度计算Softmax。使用专用的双向Softmax内核,可以避免大量冗余计算。
使用深度监督,中间层也会产生有意义的输出。在5层之后,该网络可以预测稳健的匹配,实现了90%以上的召回率。在第一层,网络专注于剔除离群点,从而提高了匹配精度。
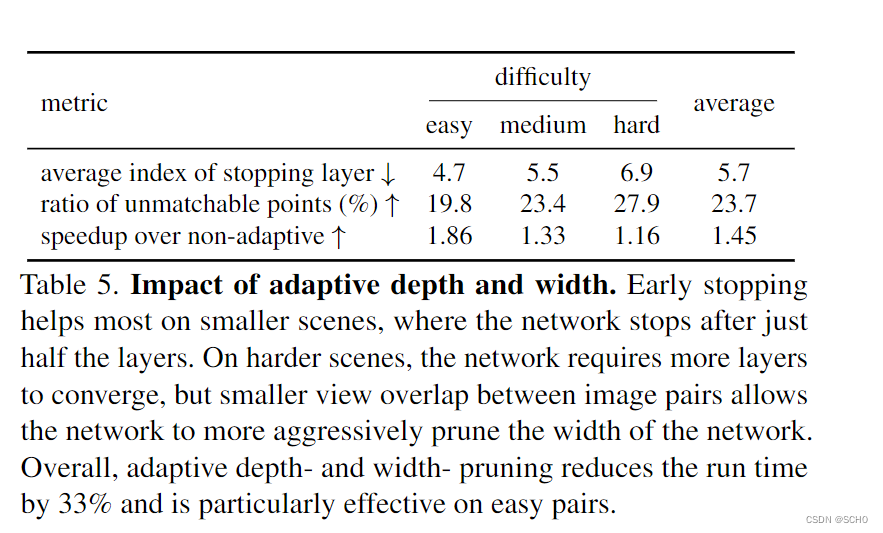
适应性:通过预测匹配分数和一致性,我们可以在逐个案例的基础上自适应地减少前向传递过程中的计算量。表5研究了两种剪枝机制-自适应深度和宽度-对不同视觉重叠范围的MegaDepth图像对的有效性。对于简单的采样,例如视频的连续帧,网络在几层后快速收敛并退出,加速比为1.86倍。在视觉重叠较低的情况下,例如环路闭合,网络需要更多的层来收敛。然而,它拒绝置信和早期不匹配的点,并将它们排除在后续层的输入之外,从而避免了不必要的计算。
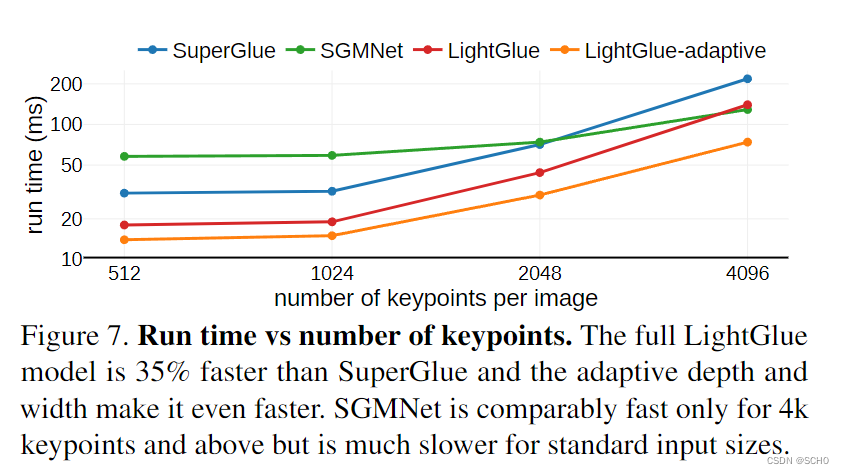
效率:图7显示了不同数量的输入关键点的运行时间。对于每个图像高达2K的关键点,这是视觉本地化的常见设置,LightGlue比Superglue[56]和SGMNet[8]都要快。自适应修剪进一步减少了任何输入大小的运行时间。
6.结论
本文介绍了LightGlue,这是一种深度神经网络,用于匹配图像中稀疏的局部特征。在强力胶成功的基础上,我们将注意力机制的力量与对匹配问题的洞察力和Transformer的最新创新结合在一起。我们赋予该模型反思其自身预测的信心的能力。这产生了一种优雅的方案,使计算量适应每个图像对的难度。它的深度和宽度都是自适应的:1)如果所有预测都准备好了,推理可以在早期停止,2)被认为不匹配的点在进一步步骤的早期被丢弃。由此产生的模型LightGlue最终比长期无与伦比的SuperGlue更快、更准确、更容易训练。总而言之,LightGlue是一个仅有好处的即兴替代品。代码将公开发布,以造福于社区。
相关文章:
LightGlue论文翻译
LightGlue:光速下的局部特征匹配 摘要 - 我们介绍 LightGlue,一个深度神经网络,学习匹配图像中的局部特征。我们重新审视 SuperGlue 的多重设计决策,稀疏匹配的最新技术,并得出简单而有效的改进。累积起来,它们使 Lig…...

iOS开发-CAShapeLayer与UIBezierPath实现微信首页的下拉菜单效果
iOS开发-CAShapeLayer与UIBezierPath实现微信首页的下拉菜单效果 之前开发中遇到需要使用实现微信首页的下拉菜单效果。用到了CAShapeLayer与UIBezierPath绘制菜单外框。 一、效果图 二、CAShapeLayer与UIBezierPath 2.1、CAShapeLayer是什么? CAShapeLayer继承自…...

《Elasticsearch 源码解析与优化实战》第5章:选主流程
《Elasticsearch 源码解析与优化实战》第5章:选主流程 - 墨天轮 一、简介 Discovery 模块负责发现集群中的节点,以及选择主节点。ES 支持多种不同 Discovery 类型选择,内置的实现称为Zen Discovery ,其他的包括公有云平台亚马逊的EC2、谷歌…...

Spring Cloud Alibaba - Nacos源码分析(三)
目录 一、Nacos客户端服务订阅的事件机制 1、监听事件的注册 2、ServiceInfo处理 serviceInfoHolder.processServiceInfo 一、Nacos客户端服务订阅的事件机制 Nacos客户端订阅的核心流程:Nacos客户端通过一个定时任务,每6秒从注册中心获取实例列表&…...

DOCKER镜像和容器
1.前言 初见DOCKER,感觉和我们常用的虚拟机(VMware,viurebox)类似,是一个独立于宿主机的模块,可以解决程序在各个系统间的移植,但它真的仅仅是这样嘛? 2.容器的优缺点 1.1.容器…...
探索网页原型设计:构建出色的用户体验
在当今数字化时代,用户对网页体验的要求日益提高。在网页设计过程中,扮演着至关重要的角色。通过网页原型设计,产品经理能够更好地展示和传达网页的整体布局、导航结构、元素位置和交互效果,从而使团队成员更清晰地了解设计意图&a…...

48,排序算法merge
功能描述: 两个容器元素合并,并储存到另一容器中 函数原型: merge(iterator beg1,iterator end1,iterator beg2,iterator end2,iterator dest); //容器元素合并,并存储到另一个容器中 //注意:两个容器必须是有序的…...

【MySQL】复合查询
复合查询目录 一、基本查询二、多表查询三、自连接四、子查询4.1 单行子查询4.2 多行子查询4.3 多列子查询4.4 在from子句中使用子查询4.5 合并查询4.5.1 union4.5.2 union all 五、实战OJ 一、基本查询 --查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的…...

JavaScript中的this指向及绑定规则
在JavaScript中,this是一个特殊的关键字,用于表示函数执行的上下文对象,也就是当前函数被调用时所在的对象。由于JavaScript的函数调用方式多种多样,this的指向也因此而变化。本文将介绍JavaScript中this的指向及绑定规则…...

css中预编译理解,它们之间区别
css预编译? css预编译器用一种专门的编程语言,它可以对web页面样式然后再编译成正常css文件,可以更加方便和高效的编写css代表。主要作用就是为css提供了变量,函数,嵌套,继承,混合等功能&#…...

如何使用Java处理JSON数据?
在Java中,您可以使用许多库来处理JSON数据。以下是使用一种常见的库 Gson 的示例: 首先,确保您已经将 Gson 库添加到您的项目中。您可以在 Maven 中添加以下依赖项: <dependency><groupId>com.google.code.gson<…...
java设计模式-观察者模式
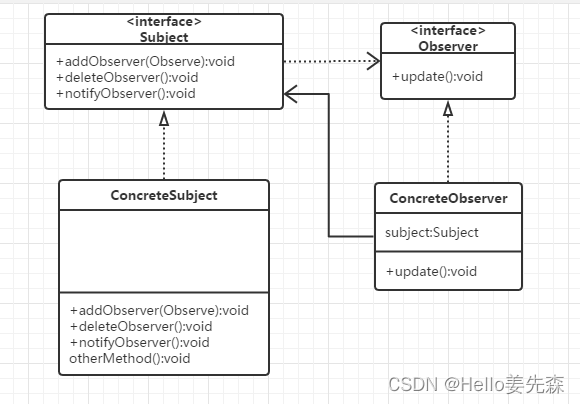
什么是观察者模式 观察者模式(Observer)是软件设计中的一种行为模式。 它定义了对象之间的一对多关系,其中如果一个对象改变了状态,所有依赖它的对象都会自动被通知并更新。 这种模式包含了两种主要的角色,即被观察…...

HiveSQL SparkSQL中常用知识点记录
目录 0. 相关文章链接 1. hive中多表full join主键重复问题 2. Hive中选出最新一个分区中新增和变化的数据 3. Hive中使用sort_array函数解决collet_list列表排序混乱问题 4. SQL中对小数位数很多的数值转换成文本的时候不使用科学计数法 5. HiveSQL & SparkSQL中炸裂…...

mac不识别移动硬盘导致无法拷贝资源
背景 硬盘插入到Mac电脑上之后,mac不识别移动硬盘导致无法拷贝资源。 移动硬盘在Mac上无法被识别的原因可能有很多,多数情况下,是硬盘的格式与Mac电脑不兼容。 文件系统格式不兼容 macOS使用的文件系统是HFS或APFS,如果移动硬盘是…...

Opencv的Mat内容学习
来源:Opencv的Mat内容小记 - 知乎 (zhihu.com) 1.Mat是一种图像容器,是二维向量。 灰度图的Mat一般存放<uchar>类型 RGB彩色图像一般存放<Vec3b>类型。 (1)单通道灰度图数据存放样式: (2)RGB三通道彩色图存放形式不同&#x…...

MySQL~数据库的设计
二、数据库的设计 1、多表之间的关系 1.1 三种分类 一对一: 分析:一个人只有一个身份证,一个身份证只能对应一个人 如:人和身份证 一对多: 如:部门和员工 分析:一个部门有多个员工ÿ…...
开源了!最强原创图解八股文面试网来袭
强烈推荐 Github上业内新晋的一匹黑马—Java图解八股文面试网—Java2Top.cn,图解 Java 大厂面试题,深入全面,真的强烈推荐~ 这是一个二本逆袭阿里的大佬根据自己秋招上岸所看过的相关专栏,面经,课程,结合自…...

微信小程序开发6
一、分包-基础概念 1.1、什么是分包 分包指的是把一个完整的小程序项目,按照需求划分为不同的子包,在构建时打包成不同的分包,用户在使用时按需进行加载。 1.2、分包的好处 对小程序进行分包的好处主要有以下两点: 可以优化小程序…...

JS 根据身份证号获取年龄、性别、出生日期
先说一代身份证和二代身份证的区别: 1.编号位数不同,第一代身份证为15位号码,第二代证是18位号码 2.编码规则不同,第一代身份证在前6位号码后没有完整出生年份,而二代的有完整的出生年份,一代身份证将年份前二位省略…...
)
Python+Mongo+LSTM(GTP生成)
下面是一个简单的示例来展示如何使用Python和MongoDB来生成LSTM预测算法。 首先,我们需要安装pymongo和tensorflow库,可以使用以下命令进行安装: pip install pymongo tensorflow接下来,我们连接到MongoDB数据库并获取需要进行预…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

GEMM内核与MHA中的寄存器分配优化策略
1. GEMM内核与寄存器分配基础解析通用矩阵乘法(GEMM)作为深度学习计算的核心算子,其性能表现直接决定了神经网络训练和推理的效率。在硬件层面,寄存器分配的优劣往往能带来数倍的性能差异。我们以典型的GEMM运算C αAB βC为例&…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了
AI开始替人办事后,最危险的不是模型不够强,而是它把旧资料当真了2026年真正值得重视的AI底层能力,是让模型知道该信谁 你有没有发现一个很扎心的变化。 以前我们用AI,最怕它不会。 现在我们用AI,最怕它太会了。 它能写…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

3分钟掌握抖音视频批量下载:解放双手的素材收集革命
3分钟掌握抖音视频批量下载:解放双手的素材收集革命 【免费下载链接】douyinhelper 抖音批量下载助手 项目地址: https://gitcode.com/gh_mirrors/do/douyinhelper 还在为一个个手动保存抖音视频而烦恼吗?想要高效收集创作者素材却苦于没有合适的…...

ESP32屏幕项目救星:用TFT_eSPI库的Touch_calibrate例程,5分钟搞定LittleVGL触摸校准
ESP32屏幕开发实战:5分钟完成LittleVGL触摸校准的高效方法论 当一块全新的ILI9341XPT2046电阻屏摆在你面前时,大多数开发者会迫不及待地跳进LittleVGL的配置深渊。但真正高效的硬件开发者知道,在编写任何图形界面代码之前,有一个关…...

<数据集>yolo高粱叶片病害识别<目标检测>
数据集下载链接https://download.csdn.net/download/qq_53332949/92902223数据集格式:VOCYOLO格式 图片数量:3242张 标注数量(xml文件个数):3242 标注数量(txt文件个数):3242 标注类别数:1 使用标注工具ÿ…...

H.Test.DefaultApplicationBase-默认应用组合
H.Test.DefaultApplicationBase 示例项目学习教程 一、概述 H.Test.DefaultApplicationBase 展示了如何使用 WPF-Control 框架的默认应用组合(Default ApplicationBase)。这是一个"开箱即用"的应用模板,一键注册所有常用服务和模块…...

Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台
Windows安卓应用安装终极指南:APK Installer让你的电脑变身安卓平台 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为无法在Windows电脑上直接安装安卓…...