机器学习分布式框架ray运行xgboost实例
Ray是一个开源的分布式计算框架,专门用于构建高性能的机器学习和深度学习应用程序。它的目标是简化分布式计算的复杂性,使得用户能够轻松地将任务并行化并在多台机器上运行,以加速训练和推理的速度。Ray的主要特点包括支持分布式任务执行、Actor模型、异步任务执行、分布式数据集、超参数优化以及多框架支持。首先,Ray允许用户将计算任务拆分成多个小任务,并在分布式环境下并行执行。通过充分利用多台机器的计算资源,Ray显著提高了任务的执行效率。其次,Ray采用了Actor模型,这是一种并发编程模型,可以简化分布式应用程序的设计和编程。Actors是独立的、状态可变的对象,可以并行运行,从而提高了分布式计算的效率。Ray还支持异步任务执行,用户可以提交任务并继续进行其他操作,而无需等待任务完成。这种机制提高了计算资源的利用率,同时增加了灵活性。此外,Ray提供了分布式数据集的支持,自动将数据分布在多台机器上,从而支持数据并行训练和处理大规模数据集。Ray整合了Tune库,可以用于超参数优化和自动调参。通过优化模型的超参数配置,用户可以更快地找到最佳模型性能。最后,Ray与常见的机器学习和深度学习框架(如TensorFlow和PyTorch)无缝集成,为用户提供了灵活的选择,使得开发者可以更加便捷地构建复杂的分布式应用程序。总之,Ray是一个强大且易用的分布式框架,特别适用于需要处理大规模数据和资源密集型机器学习任务的场景。它为用户提供了高性能的分布式计算能力,帮助加速机器学习模型的训练和推理过程,为构建分布式机器学习应用程序提供了便利和效率。
以下是使用 Ray 来并行训练 XGBoost 模型的示例代码,可以作为使用 Ray 并行训练模型的一般指南。
以下是逐步指南:
-
**初始化Ray:**启动Ray以启用分布式计算。
-
**加载数据:**加载您的数据集。
-
**划分数据:**将数据集划分为训练集和测试集。
-
**定义XGBoost训练函数:**创建一个函数,用于在给定数据集上训练XGBoost模型。
-
**使用Ray进行并行训练:**使用Ray启动多个并行训练任务,每个任务使用不同的数据集。
-
**收集模型:**从不同的任务中收集训练好的XGBoost模型。
-
**模型集成:**使用集成方法(例如平均预测)来合并所有模型的预测结果。
-
**评估集成模型:**在测试集上评估集成模型的性能。
-
**关闭Ray:**关闭Ray会话以释放资源。
首先,你需要安装必要的包:
pip install ray[xgboost] xgboost以下是一个简单的示例,演示了如何使用 Ray 来并行训练 XGBoost 模型:
import ray
import xgboost as xgb
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error# 在给定数据分割上训练 XGBoost 模型的函数
def train_xgboost(data, labels):dtrain = xgb.DMatrix(data, label=labels)params = {'objective': 'reg:squarederror','eval_metric': 'rmse','max_depth': 3,'eta': 0.1,'num_boost_round': 100}model = xgb.train(params, dtrain)return modelif __name__ == "__main__":# 初始化 Ray(确保有足够的资源可用)ray.init(ignore_reinit_error=True)# 加载数据集data, labels = load_boston(return_X_y=True)# 将数据划分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)# 使用 Ray 进行并行训练train_results = ray.get([ray.remote(train_xgboost).remote(X_train, y_train) for _ in range(4)])# 使用训练好的模型在测试集上进行预测predictions = [model.predict(xgb.DMatrix(X_test)) for model in train_results]# 对所有模型的预测结果求平均avg_predictions = sum(predictions) / len(predictions)# 计算均方根误差(RMSE)rmse = mean_squared_error(y_test, avg_predictions, squared=False)print(f"Ensemble RMSE: {rmse}")# 关闭 Rayray.shutdown()
代码实现了使用Ray进行XGBoost模型的并行训练,并通过模型集成(ensemble)来提高预测性能。让我们逐行解释代码的功能:
import ray
import xgboost as xgb
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
首先,导入所需的库:ray用于并行计算,xgboost用于构建和训练XGBoost模型,load_diabetes用于加载糖尿病数据集,train_test_split用于将数据集分为训练集和测试集,mean_squared_error用于计算均方根误差。
def train_xgboost(data, labels):dtrain = xgb.DMatrix(data, label=labels)params = {'objective': 'reg:squarederror','eval_metric': 'rmse','max_depth': 3,'eta': 0.1,'num_boost_round': 100}model = xgb.train(params, dtrain)return model
定义了一个名为train_xgboost的函数,该函数用于训练XGBoost模型。函数中的data是特征数据,labels是对应的标签数据。函数首先将特征数据和标签数据转换为xgb.DMatrix对象,然后定义了一些XGBoost模型的训练参数,并使用这些参数训练了一个XGBoost模型。最后,函数返回训练好的模型。
if __name__ == "__main__":ray.init(ignore_reinit_error=True)
在主程序中,初始化Ray并忽略重新初始化的错误。这个if __name__ == "__main__":部分确保只有当该文件作为主程序运行时才会执行以下代码。
data, labels = load_diabetes(return_X_y=True)X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.2, random_state=42)
加载糖尿病数据集,并将数据集划分为训练集和测试集,其中测试集占总数据集的20%。
train_results = ray.get([ray.remote(train_xgboost).remote(X_train, y_train) for _ in range(4)])
使用Ray进行并行训练,启动4个并行任务来训练4个XGBoost模型。每个任务都会调用train_xgboost函数进行训练,其中训练集数据作为参数传递给函数。ray.remote修饰器将函数调用封装为Ray任务,ray.get用于收集并返回任务的结果。
predictions = [model.predict(xgb.DMatrix(X_test)) for model in train_results]
使用训练好的模型对测试集X_test进行预测,并将预测结果存储在predictions列表中。
avg_predictions = sum(predictions) / len(predictions)
对所有模型的预测结果进行平均,这是模型集成的一种方式。通过将多个模型的预测结果平均化,可以获得更稳定和准确的预测。
rmse = mean_squared_error(y_test, avg_predictions, squared=False)print(f"Ensemble RMSE: {rmse}")
计算模型集成后的均方根误差(RMSE),mean_squared_error函数用于计算均方根误差。最后,打印模型集成的均方根误差。
ray.shutdown()
关闭Ray会话,释放资源。
这段代码的目标是使用并行计算和模型集成的方法来改进XGBoost模型的性能,特别是在大规模数据集上,通过并行训练多个模型可以加快训练速度,而模型集成则有望提高预测的准确性和稳定性。
相关文章:

机器学习分布式框架ray运行xgboost实例
Ray是一个开源的分布式计算框架,专门用于构建高性能的机器学习和深度学习应用程序。它的目标是简化分布式计算的复杂性,使得用户能够轻松地将任务并行化并在多台机器上运行,以加速训练和推理的速度。Ray的主要特点包括支持分布式任务执行、Ac…...

C++设计模式笔记
设计模式 如何解决复杂性? 分解 核心思想:分而治之,将大问题分解为多个小问题,将复杂问题分解为多个简单的问题。 抽象 核心思想:从高层次角度讲,人们处理复杂性有一个通用的技术,及抽象。…...
简单聊聊创新与创造力
文章目录 前言一、大脑运行的两种方式1、聚焦模式2、发散模式3、影响想法的因素a、背景知识b、兴趣c、天赋 4、思维固化 二、想法的不可靠1、对想法进行验证2、颠覆性创新,挤牙膏式创新3、为什么模仿这么多 三、更多更多的idea1、个人的方面a、积累不同的背景知识b、…...

使用TensorFlow训练深度学习模型实战(上)
大家好,尽管大多数关于神经网络的文章都强调数学,而TensorFlow文档则强调使用现成数据集进行快速实现,但将这些资源应用于真实世界数据集是很有挑战性的,很难将数学概念和现成数据集与我的具体用例联系起来。本文旨在提供一个实用…...
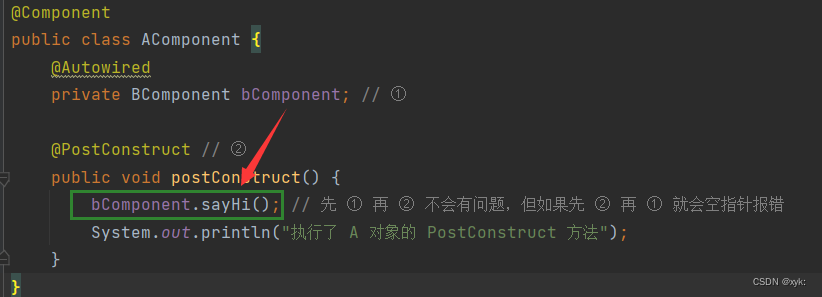
【Spring】什么是Bean的生命周期及作用域,什么是Spring的执行流程?
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: JavaEE进阶 在前面的播客中讲解了如何从Spring中存取Bean对象,那么本篇我们来讲解Bean对象的生命周期是什么,Bean对象的6种作用域分别是什么,都有哪些区别ÿ…...
立创EDA学习
学习树莓派3B的板子发现有个扩展板比较好,自己最好画一个,反正免费。 学习视频:立创EDA(专业版)电路设计与制作快速入门。 下载专业版,并激活。【分专业版和标准版,专业版也是免费的】 手机…...

清风学习笔记—层次分析法—matlab对判断矩阵的一致性检验
在判断矩阵是否为正互反矩阵这块,我写了两种代码,改进前很麻烦且有错误,改进后简洁多了,改进前的代码还有错误,忽略了对角线的值必须都是1,只考虑了除开对角线的元素相乘为1。 %% 改进前代码 A[3 2 4;1/2 …...

大众安徽内推
大众汽车(安徽)有限公司是大众汽车集团在中国第一家专注于新能源汽车的合资企业,是集团在中国首家拥有全面运营管理权的合资企业,担负着产品研发及数字化研发的重任,将成为集团全球电动出行中心之一。 VW Anhui Offic…...

Meta “地平线世界”移动端应用即将上线,手机快乐元宇宙?
根据海外记者 Janko Roettgers 的报道,Meta 预计很快推出移动版的 VR 元宇宙服务 "地平线世界",这是Meta 长期开发的产品。 根据最新报道,Meta宣布正在研发“地平线世界”的移动版,并表示这一服务已经可以在Quest VR设…...

更省更快更安全的云服务器,一站式集中管理,随时随地远程——站斧云桌面
随着全球化和数字化经济的发展,越来越多的企业开始海外扩张和拓展国际市场。而云服务器作为一种高效、灵活且可靠的IT基础设施方案,已成为出海企业不可或缺的重要工具。这里就为大家介绍云服务器在出海企业中的几个使用场景。 1.全球范围内协同办公 对…...
 的解决方法)
出现 Try run Maven import with -U flag (force update snapshots) 的解决方法
目录 1. 问题所示2. 原理分析3. 解决方法1. 问题所示 在配置Maven依赖信息的时候,出现如下问题: com.alibaba.nacos:nacos‐client:pom:1.1.3 failed to transfer from http://nexus.hepengju.cn:8081/nexus/content/groups/public/ during a previous attempt. This failu…...

python多线程
目录 一.多线程的定义 A.什么是多线程? B.多线程如今遇到的挑战 C.总结 二.python中的多线程 A.python中的多线程底层原理: B.全局解释器锁导致python多线程不能实现真正的并行执行! C.总结应用场景 三.java多线程,以及…...

Spring Framework 提供缓存管理器Caffeine
说明 Spring Framework 提供了一个名为 Caffeine 的缓存管理器。Caffeine 是一个基于 Java 的高性能缓存库,被广泛用于处理大规模缓存数据。 使用 Caffeine 缓存管理器,可以轻松地在 Spring 应用程序中添加缓存功能。它提供了以下主要特性:…...

ZQC的游戏 题解
前言 这题题意描述不是很清楚啊,所以我找了个有权限的人把题面改了改,应该还是比较清楚了。 感觉这道题挺妙的,就来写一篇题解。 思路 首先,根据贪心思想,我们会将 1 1 1 号点半径以内能吃的都吃了,假…...
24考研数据结构-第一章 绪论
数据结构 引用文章第一章:绪论1.0 数据结构在学什么1.1 数据结构的基本概念1.2 数据结构的三要素1.3 算法的基本概念1.4 算法的时间复杂度1.4.1 渐近时间复杂度1.4.2 常对幂指阶1.4.3 时间复杂度的计算1.4.4 最好与最坏时间复杂度 1.5 算法的空间复杂度1.5.1 空间复…...
Gitlab 备份与恢复
备份 1、备份数据(手动备份) gitlab-rake gitlab:backup:create2、备份数据(定时任务备份) [rootlocalhost ]# crontab -l 00 1 * * * /opt/gitlab/bin/gitlab-rake gitlab:backup:create 说明:每天凌晨1点备份数据…...
数据库—用户权限管理(三十三)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 二、用户权限类型 三、用户赋权 四、权限删除 五、用户删除 前言 数据库用户权限管理是指对数据库用户的权限进行控制和管理,确保用户只能执…...

C语言【怎么定义变量?】
变量定义的目的是向编译器说明在哪里创建变量的存储,并指明如何创建变量的存储方式。变量定义会明确指定一个数据类型,并包含一个或多个变量的列表。例如: type variable_list; 在这里,"type"必须是一个合法的C数据类…...

vue中使用vab-magnifier实现放大镜效果
效果图如下: 1. 首先,使用npm或yarn安装vab-magnifier插件: npm install vab-magnifier或 yarn add vab-magnifier2. 在Vue组件中引入vab-magnifier插件: import VabMagnifier from vab-magnifier; import vab-magnifier/lib…...

无涯教程-jQuery - Highlight方法函数
Highlight 效果可以与effect()方法一起使用。这将以特定的颜色突出显示元素的背景,默认为黄色(yellow)。 Highlight - 语法 selector.effect( "highlight", {arguments}, speed ); 这是所有参数的描述- color - 高亮显示颜色。默认值为"#fff…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

ARM PMU外部接口与性能监控寄存器详解
1. ARM性能监控寄存器外部接口深度解析性能监控单元(PMU)是现代处理器架构中用于硬件性能分析的核心模块,它通过一组可编程计数器实时捕获处理器微架构层面的各类事件。在ARMv8/v9架构中,PMU不仅可以通过系统寄存器访问,还提供了标准化的外部…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...

如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南
如何快速掌握开源UE资产编辑器:UAssetGUI完整配置与实战指南 【免费下载链接】UAssetGUI A tool designed for low-level examination and modification of Unreal Engine game assets by hand. 项目地址: https://gitcode.com/gh_mirrors/ua/UAssetGUI UAss…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

告别元素变动导致的报错:探索自动化测试脚本的 AI“自愈”能力
前言:一个所有测试人都经历过的噩梦 周三晚上十一点,CI/CD流水线再次亮起红灯。 你打开日志,满屏的NoSuchElementException扑面而来。仔细一看——前端团队在昨天的版本中重构了登录页面的DOM结构,原本的#login-btn变成了#signin-button-v2,30个测试用例因此全军覆没。 …...

【与我学 ClaudeCode】协作篇 之 Worktree + Task Isolation :目录隔离的并行执行通道
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!! 大家吼 ! 我是 逆境不可逃 今天给大家带来文章《【与我学 ClaudeCode】协作篇 之 Worktree Task Isolation :目录隔离的并行执行通道》. Le…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...