【MySQL】MySQL索引、事务、用户管理
20岁的男生穷困潦倒,20岁的女生风华正茂,没有人会一直风华正茂,也没有人会一直穷困潦倒…

文章目录
- 一、MySQL索引特性(重点)
- 1.磁盘、OS、MySQL,在进行数据IO时三者的关系
- 2.索引的理解
- 3.聚簇索引(索引和数据放在一起)和非聚簇索引(索引和数据分离存储)
- 4.索引的操作
- 二、MySQL事务管理(重点)
- 1.什么是事务?
- 2.事务常见操作方式
- 3.事务隔离级别
- 4.MVCC(提高读写并发时数据库的性能)
- 5.RR与RC的本质区别
- 三、MySQL视图特性
- 四、MySQL用户管理
- 五、API和图形化界面的客户端
一、MySQL索引特性(重点)
1.磁盘、OS、MySQL,在进行数据IO时三者的关系
1.
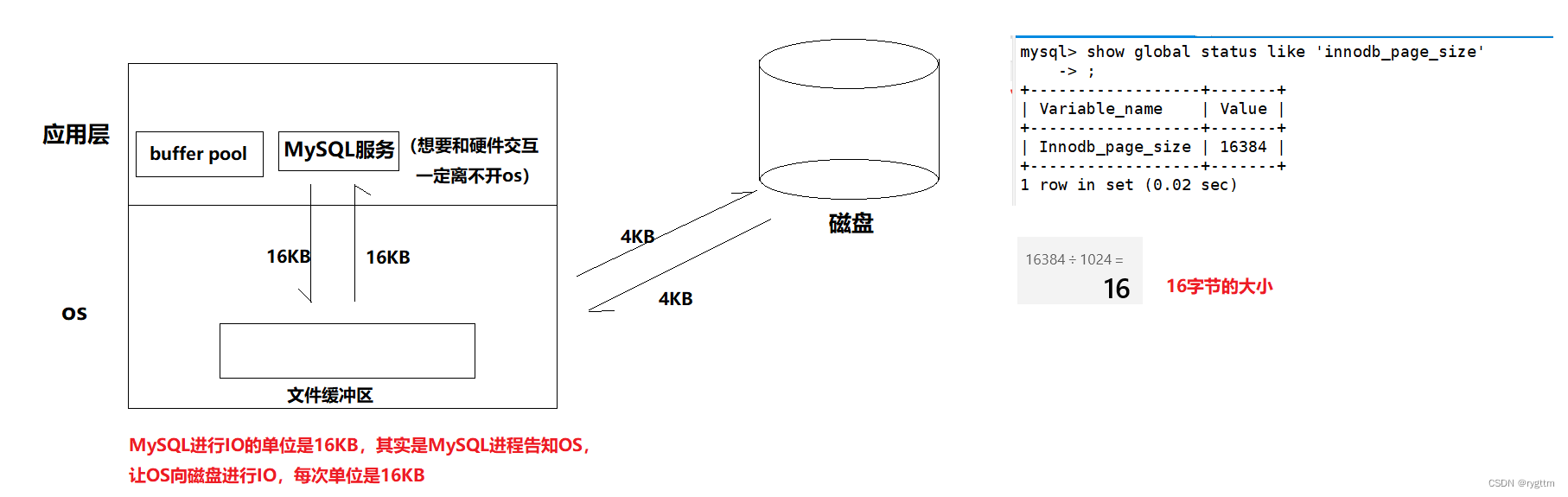
MySQL给用户提供存取数据的服务,但数据在linux机器的磁盘外设上进行存储,而磁盘的读取效率是比较低的,MySQL如何进行数据存取以提高效率呢?这是一个重要的话题。
在硬件层面上,数据块的基本单位是一个512字节的扇区,但OS在和磁盘进行IO时,难道就直接以扇区为基本单位进行数据IO了吗?当然不是!如果系统直接以硬件提供的扇区大小进行交互,则OS的IO代码就会和硬件强相关,但我们并不希望耦合度的提升,因为一旦耦合度较高,硬件改变软件代码也得随之改变。同时单次IO大小为512字节还是太小了,这会增加IO的次数,从而导致效率降低,而实际OS的文件系统的基本IO单位并不是扇区,而是以块为单位,基本大小是4KB,也就是每次读写8个扇区的大小。
而MySQL在和磁盘进行交互时,基本数据单元的大小为16KB,在MySQL这里叫做page(注意和系统的page作区分,系统的page页是4KB),虽然我们说的是MySQL和磁盘进行交互,但能和磁盘进行交互的软件层肯定只有操作系统,所以MySQL和磁盘每次进行16KB大小的page交互,MySQL中的数据文件都是以page为单位保存在磁盘当中的。
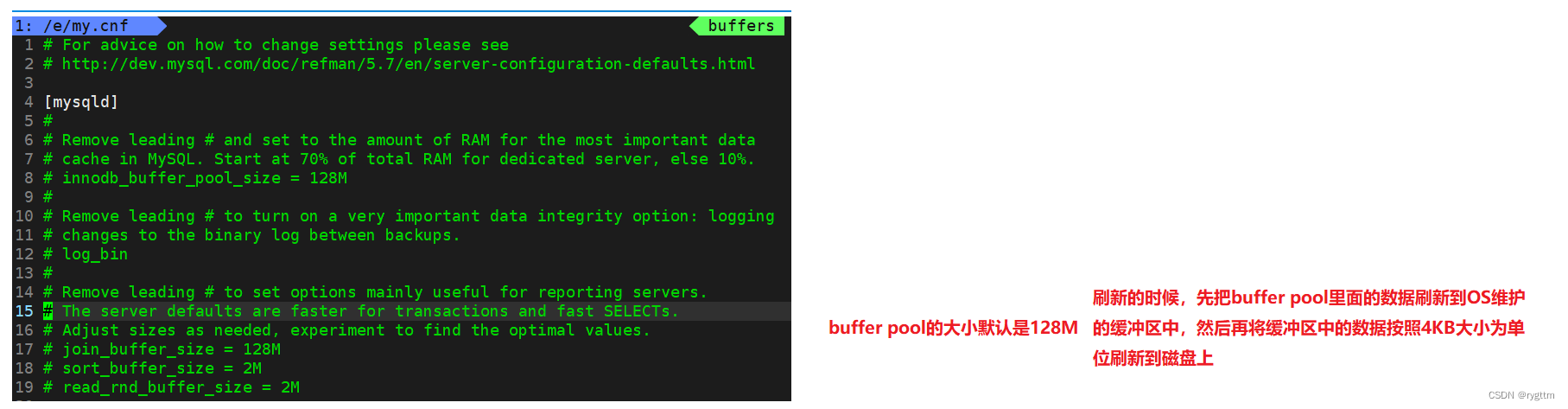
MySQL服务器在内存中运行时,服务器内部会申请一大块buffer pool的内存空间,来进行各种数据文件page的缓存,也就是通过OS来和磁盘进行IO交互,而OS实际在和磁盘进行IO时的单位是4KB,但MySQL不管这些事情,MySQL只认为自己和磁盘进行交互时,就是以16KB大小为单位进行交互的。

2.索引的理解
1.
下面是我创建的具有主键索引的一张表user,在插入数据时,实际我是对id进行乱序插入的,但在查询时,所有记录却变成有序的了。这个工作是谁做的呢?这么做的原因又是什么呢?

2.
为何MySQL与磁盘IO交互的基本单位是page呢?用多少加载多少不行吗?这样当然是不行的,如果你要查询id为1的记录,那就需要一次IO,而查询整表的数据就需要进行5次IO,这样的效率会非常低。如果将表中的多条记录保存在一个page里面,实际IO时直接将一个page加载到buffer pool里面,这样在后面查询的时候,就不用再进行IO了,直接在内存中的buffer pool进行读取就可以,而且根据局部性原理,下一次访问的数据大概率同样也在该page里面,那下一次进行读取时,大概率不用在进行IO了,直接在当前buffer pool中的page内读取数据就可以了,这样的效率就会高了,因为我们知道,导致IO效率低下的主要原因不是单次IO数据的大小,而是IO的次数多少,因为硬件与软件相比,时间上要差别很多。
3.
我们在理解page时,同样不能简单的的将page理解为一个存储数据的内存块,page可以理解为一个结构体对象,保存着表中的一部分数据,每个page之间用"数据结构"连接起来,统一进行管理。
单个page内部的数据存储是按照有序的方式来进行排序的,其实就是用链表的方式将有序的数据一个个连接起来。


4.
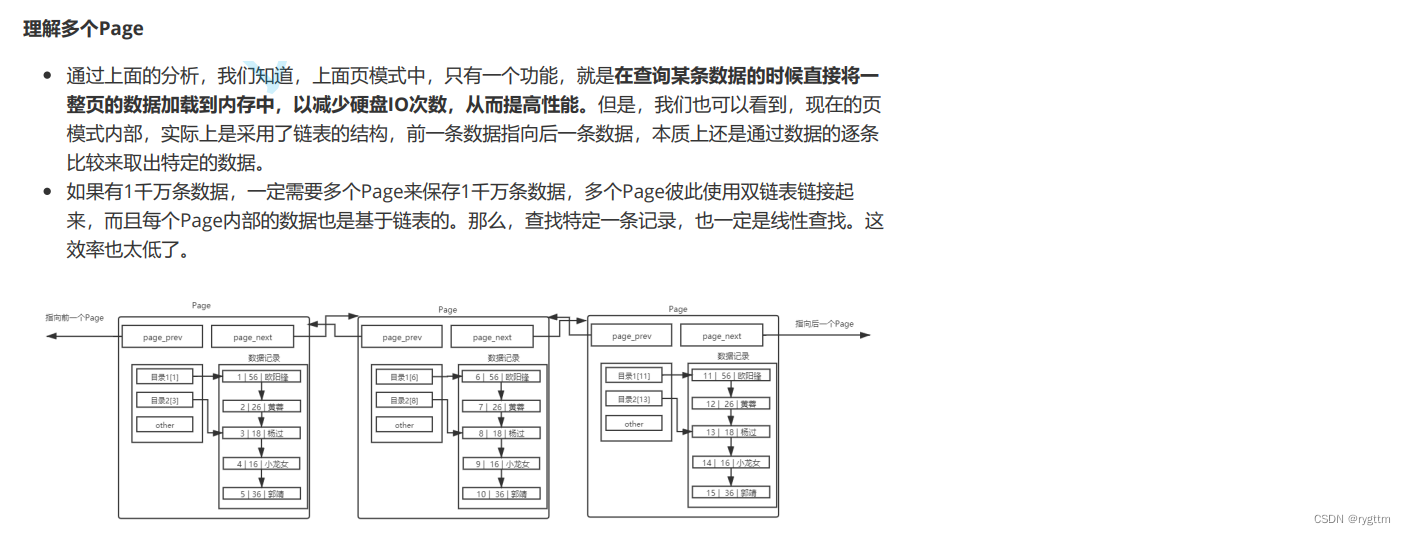
我们知道了单个page内部的记录之间是按照链表进行连接的,此时在查找某条记录的时候,就需要逐条遍历进行查找,比如先一个一个的遍历page,在每个page的内部在逐个记录的进行遍历,与每个记录进行比较,直到比较查找出要搜索的记录,这样的效率一定是非常低的。因为无论是page间,还是page内部,我们都需要线性遍历,直到通过比较找到要查找的记录。
5.
所以,为了提升查找的速度,需要引入页目录的概念,通过目录来快速定位记录的位置本身,比如一本书有500页,其中有50条目录,每个目录分别管理10页的内容,则50条目录就可以管理整本书,以前查找某一页的内容,最坏需要查找500次,现在你最多需要查找60次,先遍历目录,然后再遍历目录所管理的10个页,所以最坏也就是查找60次,这样不就提升了查找的效率吗?

6.
所以为了提升查找的效率,我们可以在单个page内部引入页目录,以提高在page内部查找记录时的效率。所以这也就可以解释为什么当我们创建具有主键索引的表的时候,插入数据记录是默认有序的呢?其实就是为了提高搜索效率,因为只有当记录是有序的时候,目录才有意义。
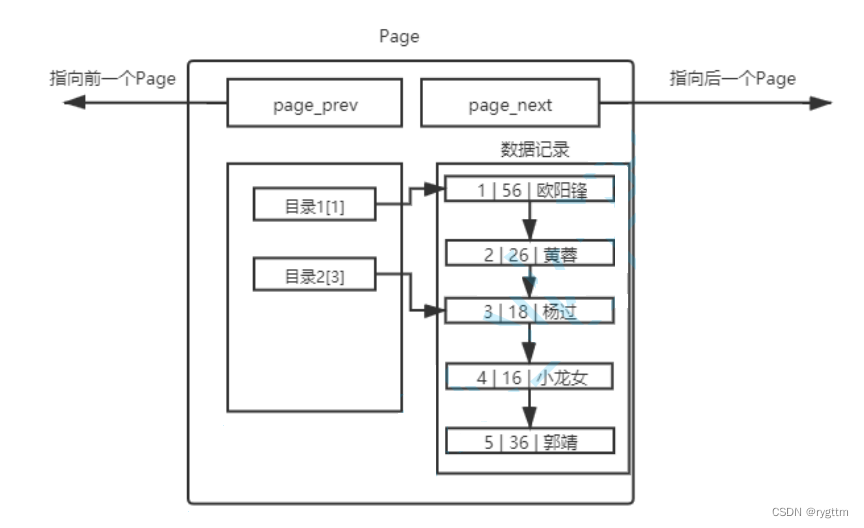
而当表存储的数据过多时,单个page的大小固定是16KB,则一定需要多个page来存储对应的数据,多个page之间我们也用链表管理起来,但page之间进行线性遍历的时候,也会造成效率低下的问题,因为page在线性遍历的时候,是需要进行磁盘IO的,磁盘IO更费时间,那如何解决这个问题呢?还是之前的思路,引入页目录!
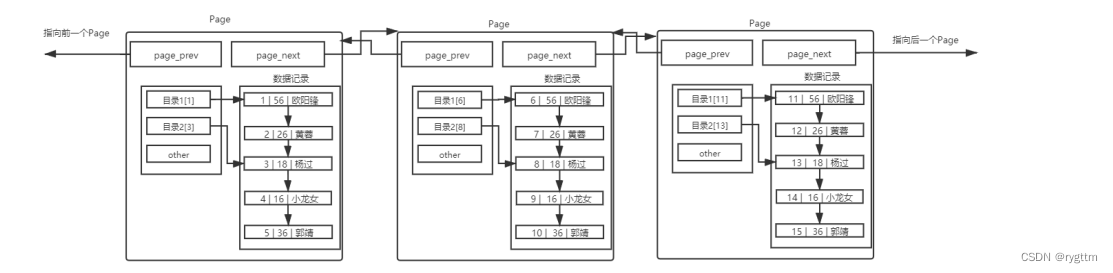
我们可以在多个page的基础上,再加入存储页目录的page,而此时每个page内部不再存储数据,而是只存储目录项,每个目录项存储每个普通page的最小键值和目录页的地址,所以原来普通页中存储的数据是用户数据,而目录页中存储的数据是普通页中的最小键值和普通页的地址,每个普通page之间的键值也必须是有序的,因为目录页要对多个page进行管理。
如果顶层的目录页过多还需要进行遍历的话,则我们还可以在目录页的基础上再次增加目录页,对第二层的目录页进行管理。

一个page能够保存的数据大小是16KB,一个page所占字节数其实也就是16字节,也就是四个指针,prev和next指向前后的page,一个指针指向存储用户数据的链表的头结点,另一个指针指向页目录的头结点,所以一个目录页能够管理的page个数就是16×1024÷16,也就是1024个page,转换成数据的计量单位就是1024个16KB,也就是16MB的数据,最上层的目录页能够管理的第二层的目录页的个数是1024个页目录,所以像上面的这样一棵B+树最多管理的数据就是1024×16MB的数据,也就是16GB的数据。
7.
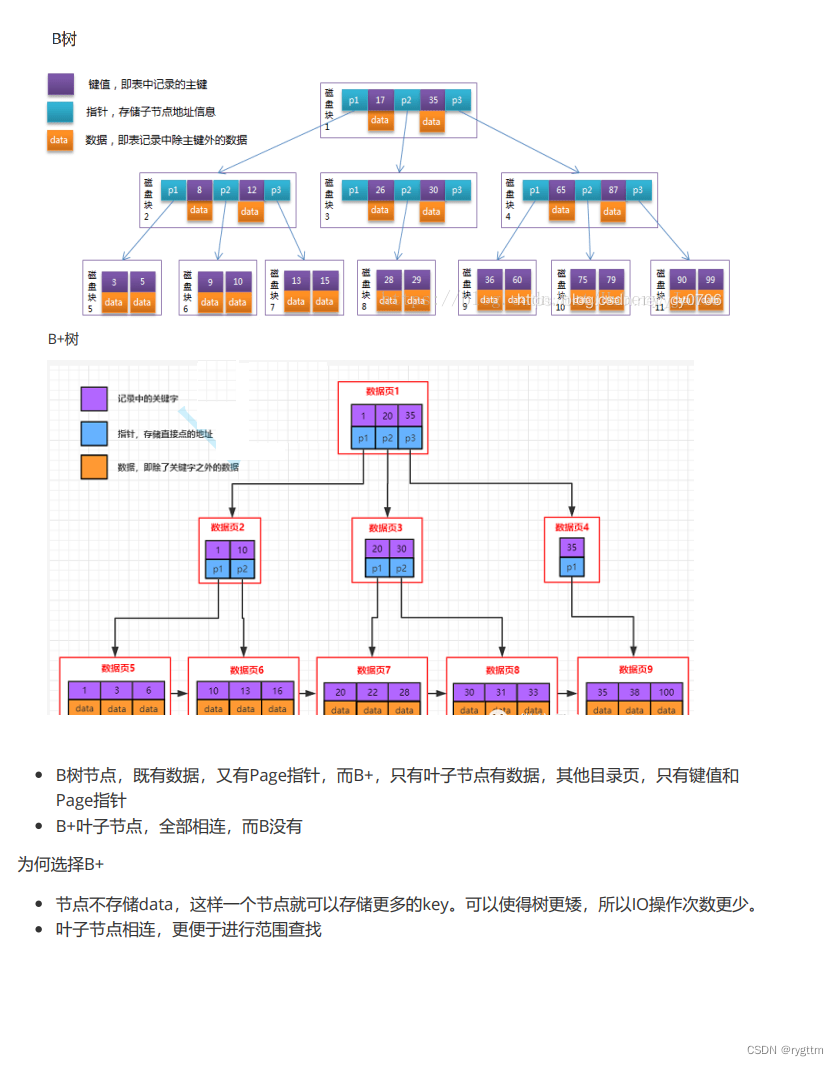
真实的B+树,只有叶子结点之间用链表连接起来,非叶子结点之间并无连接关系,通常在查找时,我们都会进行范围查找,叶子节点之间连接起来的话,是比较方便进行范围查找的,如果不连接起来,则如果当前查找的叶子结点不是目标叶子节点的话,则还需要重新自顶向下进行查找,直到找到正确的叶子结点,这样的效率很低。
叶子结点负责保存用户数据,非叶子结点只保存目录项,每个目录项负责管理一个叶子结点。所以B+树是一棵矮胖的树,因为一层非叶子结点就可以管理很多的叶子结点,矮胖对于B+树来说是很大的优势,因为查找目标叶子结点路上经过的结点数量越少,就代表从磁盘进行IO的page就越少,查找的效率就越高。同时我们还有页目录的设计,这在遍历数据的层面上来看也可以大大提高查找的效率

8.
即使创建出来的表没有索引,但对表的增删查改依旧是在表所对应的B+树结构下进行的,因为如果你没有指定表的索引值,表也会有自己的默认主键,只不过你在查询的时候,是线性遍历叶子结点进行查询的,并没有利用B+树的结构进行查询,因为你没有创建某一列字段为索引值,这也就是为什么没有创建索引的表在查询时速度慢的原因,因为时间复杂度是O(N)
同时每一个表,都会有对应的B+树数据结构。
9.

B树在面临范围查找时,优势就没有了,同时B树由于每个结点都会有data值,则每个非叶子结点管理的叶子节点会更少一些,所以B树要比B+更高,自顶向下查找的时候,IO的次数会更多,效率会更低一些。
3.聚簇索引(索引和数据放在一起)和非聚簇索引(索引和数据分离存储)
1.
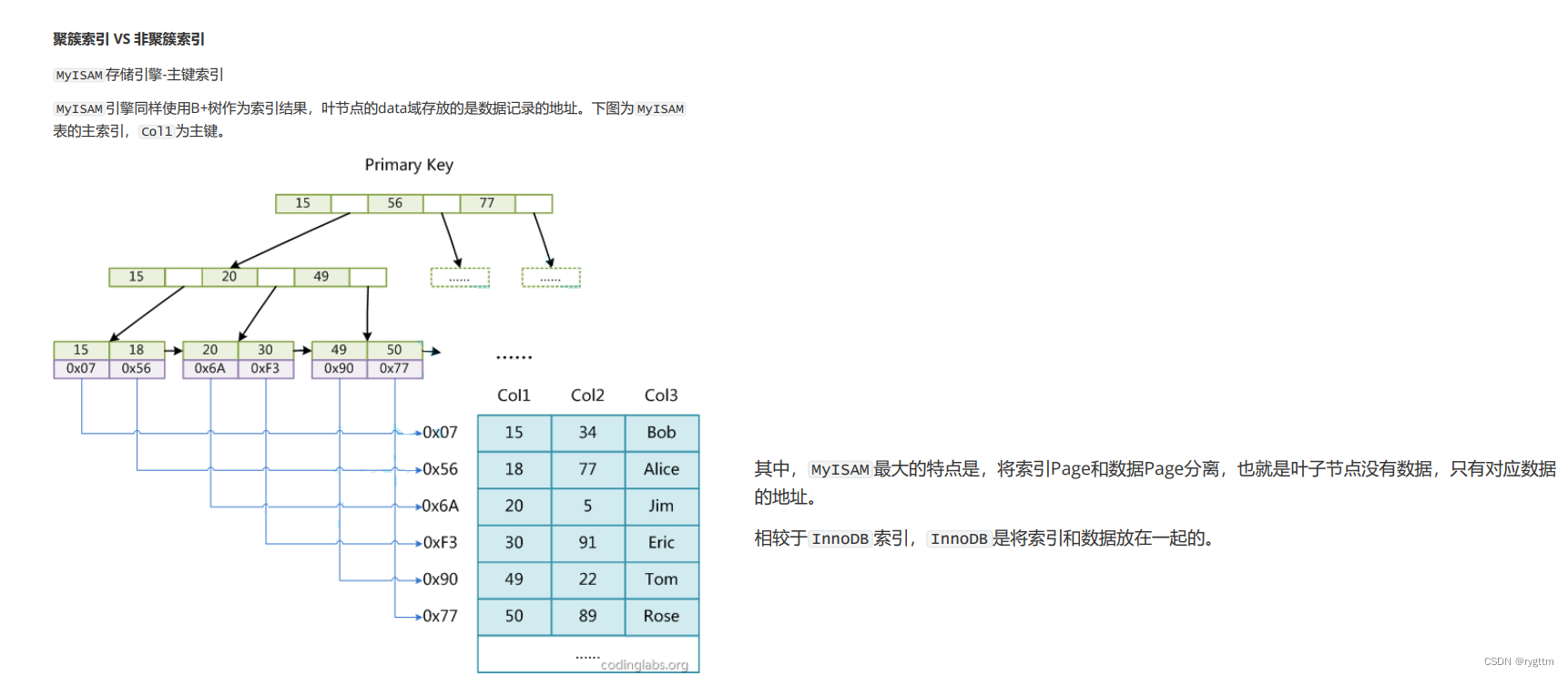
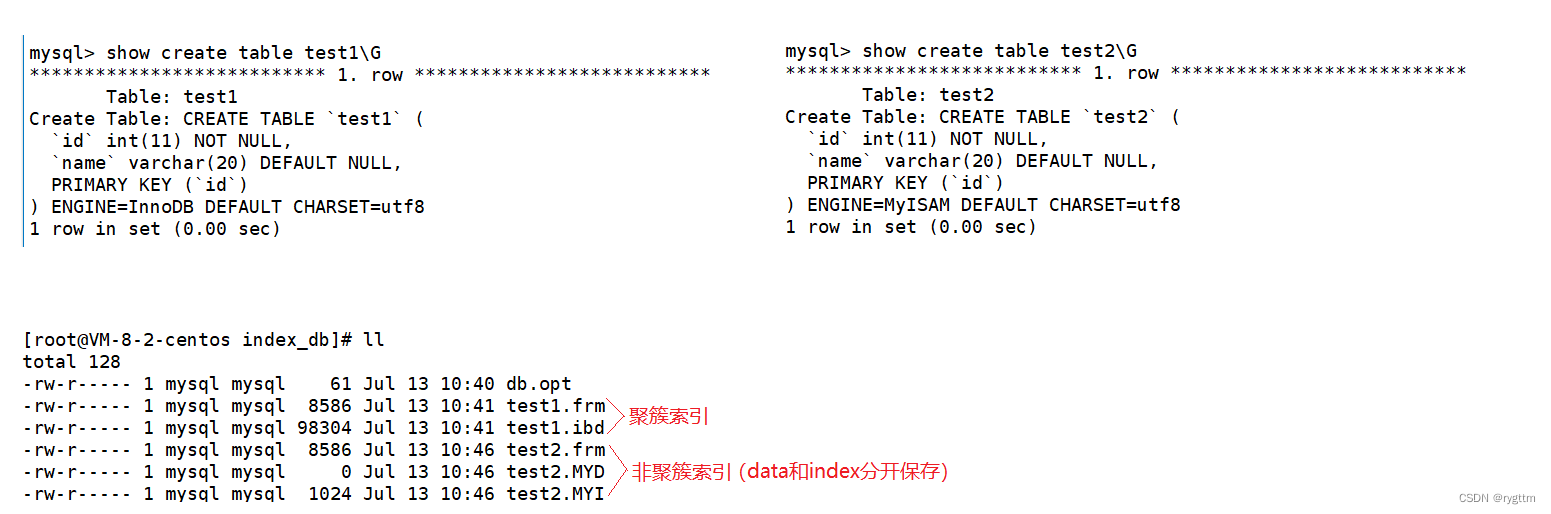
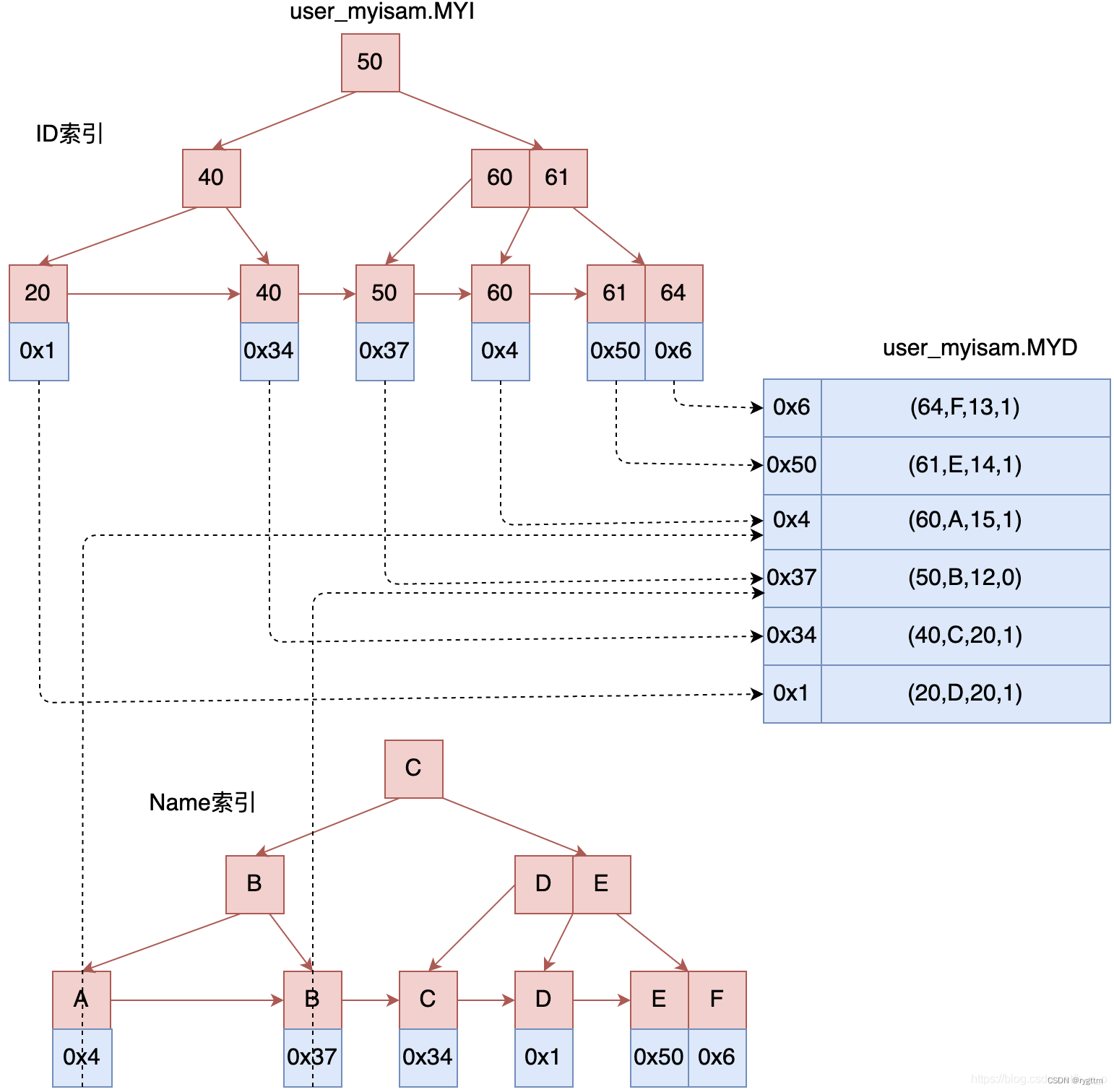
MyISAM使用非聚簇索引,即将index和data分离存储,叶子节点不直接存储数据,而是只存储数据的地址。
2.
MySQL除了建立主键索引外,还可以建立其他索引,例如普通索引,唯一键索引等等,除主键外的索引一般叫做辅助索引,MyISAM的辅助索引和主键索引没什么区别,叶子节点同样存储的是记录的地址。
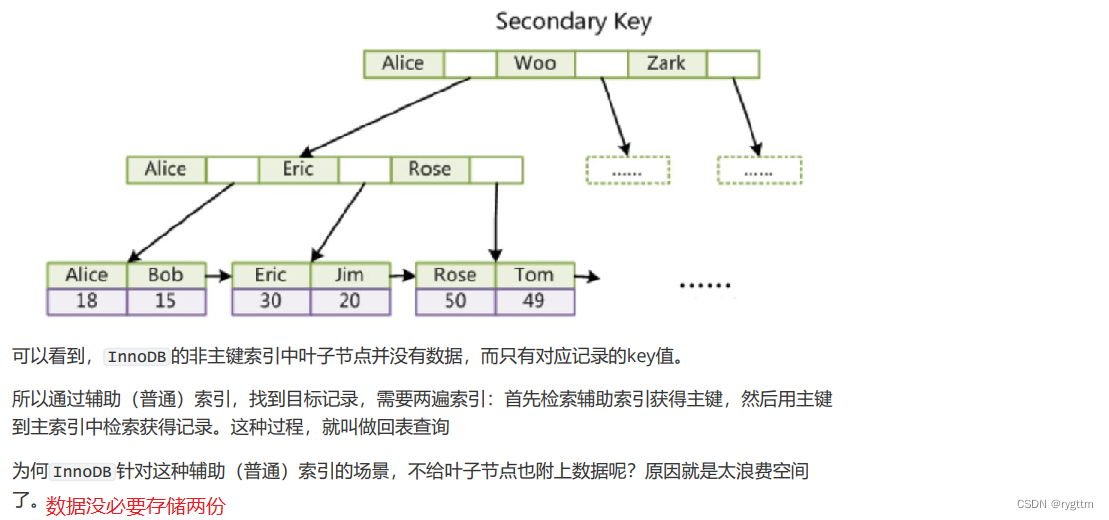
3.
对于InnoDB来说,他的辅助索引和主键索引与MyISAM就不一样了,InnoDB的辅助索引的叶子结点存储的不是记录,而是记录所对应的主键值,查找到对应的主键值之后,再根据主键值回到主键索引表进行查询,直到查找到完整的记录,所以像innodb这样的聚簇索引,在建立辅助索引后,如果按照辅助索引的键值来进行查找的话,则在获得主键之后,还要进行回表查询。
4.索引的操作
1.
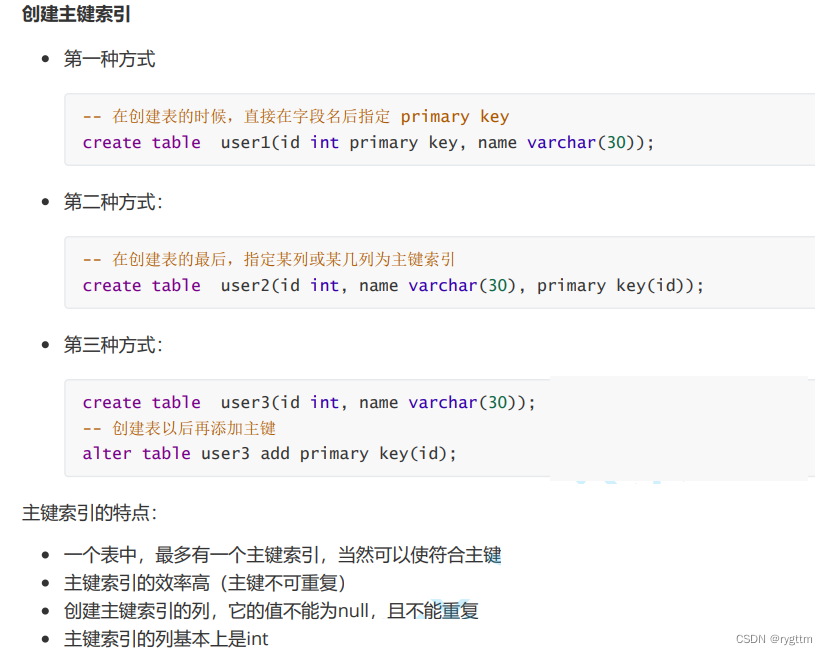
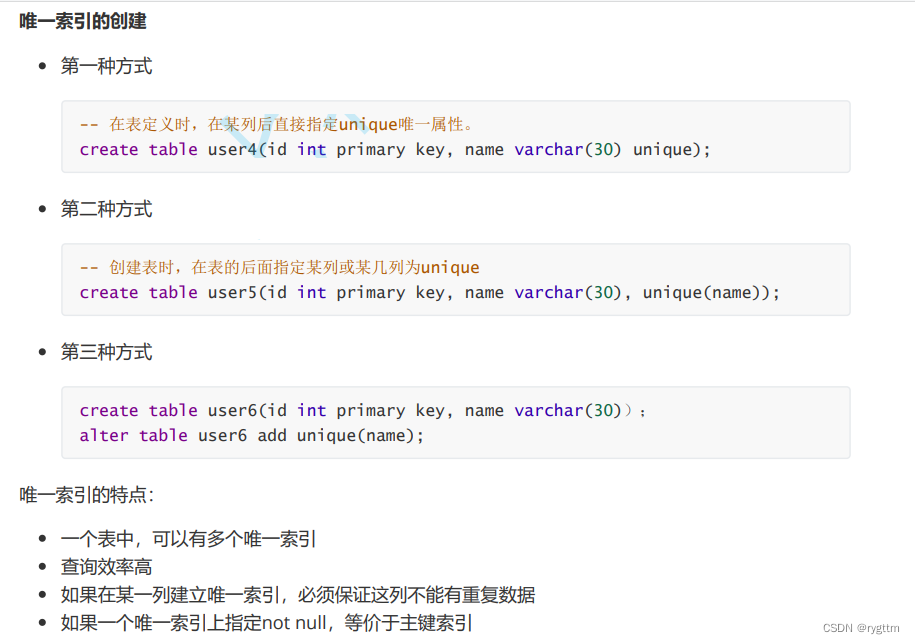
主键索引,唯一索引对应的数据结构是B+树,普通索引对应的数据结构是B树。
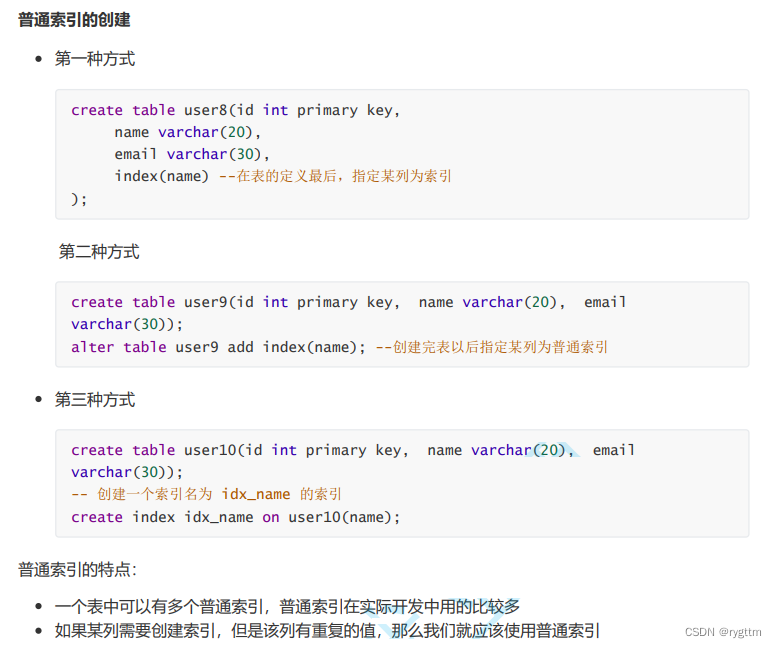
2.
下面是实际在进行索引操作时,常用的一些SQL语句,比如删除索引:alter table table_name drop XXX,构建索引:alter table table_name add 索引(column_name),查询索引:show index from table_name,创建普通索引:create index index_name on table_name(column_name)

3.
除了给单个列字段创建索引之外,我们还可以给多个列字段同时创建索引,这样的索引称之为复合索引,当我们频繁的用一个字段查找另一个字段的时候,就可以给这两个字段创建复合索引。

4.
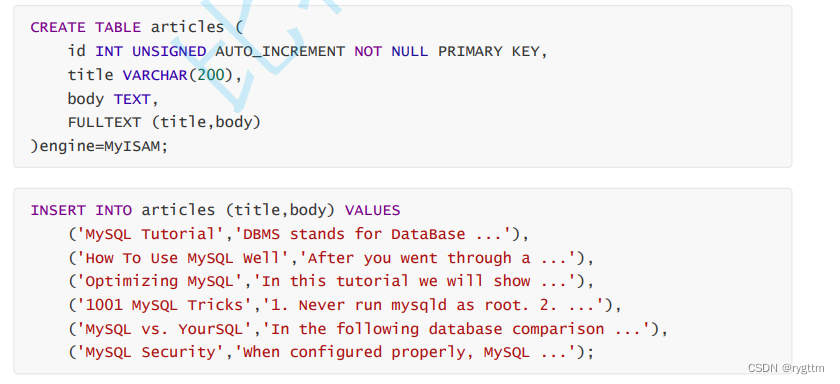
全文索引要求表的存储引擎必须是MyISAM,而且默认的全文索引只支持英文,不支持中文。
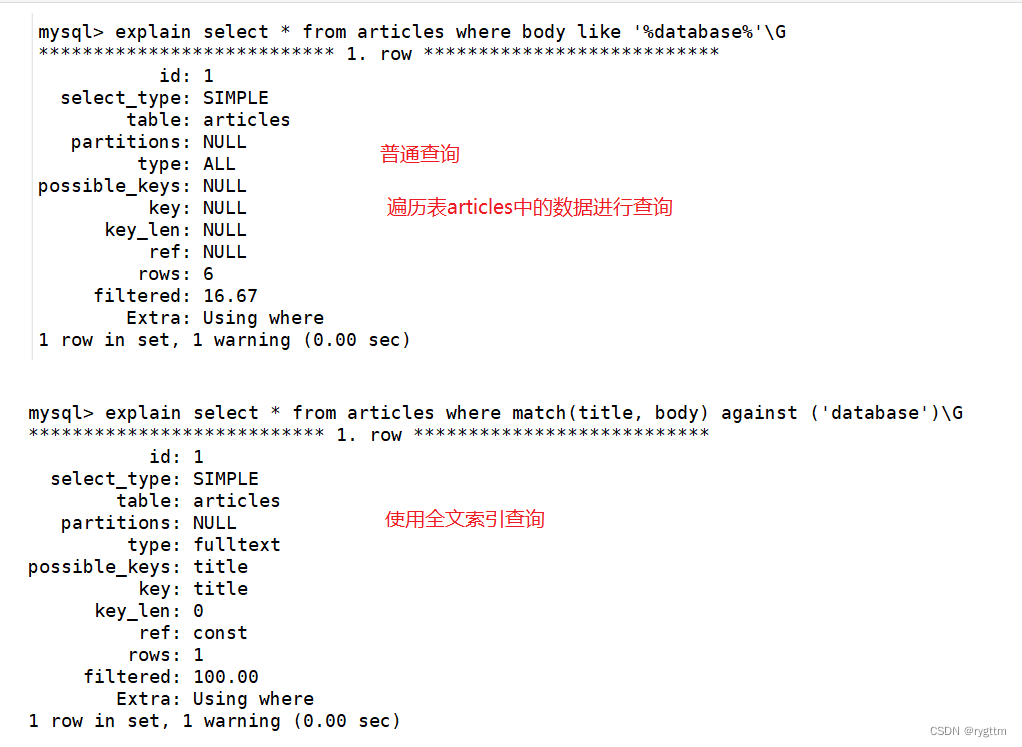
在下面的sql语句创建出来的表里面,如果要查询有没有database数据,可以通过select * from articles where body like ‘%database%’,但这种查询的方式并没有使用到全文索引,这一点我们可以在SQL语句的前面加上explain查看一下,select * from articles where match(title, body) against (‘database’)

二、MySQL事务管理(重点)
1.什么是事务?
1.
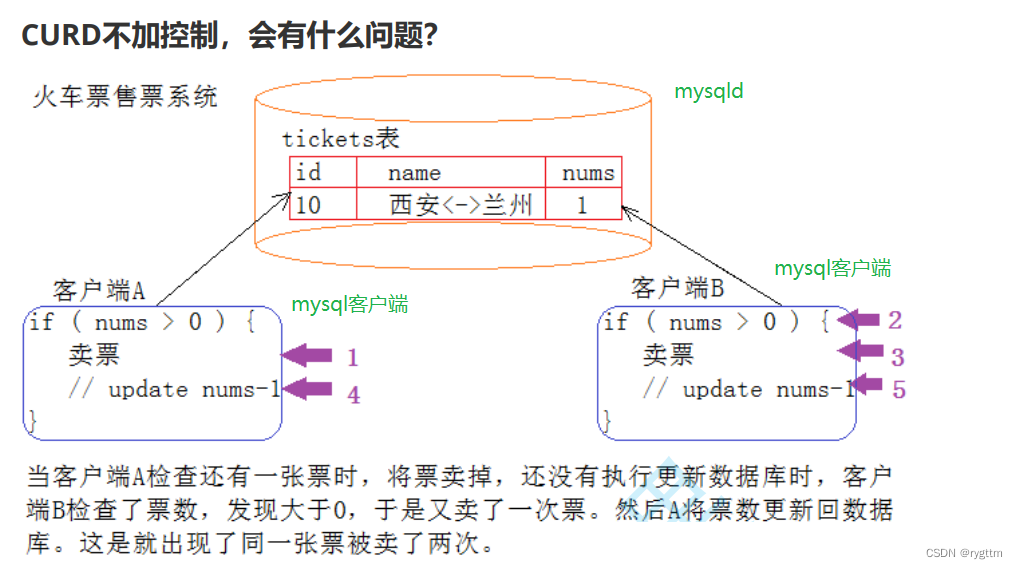
如果对一张表的CURD不加控制,则在多客户端,多sql语句提交的情况下,则一定会出现各种逻辑问题,一张票多卖了两次,所以在mysqld服务器高并发的处理来自多个客户端的sql语句请求时,如果不对sql语句加控制,则一定会出现各种各样的问题,因为每个客户端对MySQL服务器的操作都不是原子的。
2.
所以对表的CURD操作应该满足一些属性,例如买票的过程应该是原子的,买票之间不能互相影响,应该隔离开,买完票之后,数据应该作持久化,买前和买后应该都是确定的状态,要么成功,要么不成功,要具有回滚的能力,比如买票中途数据库出现了问题,服务器断电,数据库被攻击等等,数据库应该将状态回滚到买票前的状态。
而事务是由一组DML语句组成,多条DML语句就是为了完成一个任务,这一组DML语句是一个整体,要么全部执行成功,要么全部执行不成功,不会出现中间状态,而MySQL中一定不止一个事务在运行,所以多个事务之间也需要控制,事务也不简单的只是一组DML语句的集合,还需要满足四个属性。
原子性:一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中
间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个
事务从来没有执行过一样。回滚有自动回滚和手动回滚两种方式,当MySQL服务宕机时,MySQL自己会自动回滚正在执行到一半的事务
隔离性:数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务
并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交( Read
uncommitted )、读提交( read committed )、可重复读( repeatable read )和串行化
( Serializable )
持久性:事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失,其实就是将数据落盘,对数据作持久化。
一致性:在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。
上面的四个性质中,一致性其实是由前面的三个性质共同实现的,所以只要满足了前面的三个性质,就满足了事务的一致性。
3.
只有InnoDB存储引擎支持事务。事务本质上是为了应用层提供服务的,应用层不会关心具体事务实现的细节,他们只会使用事务。

4.
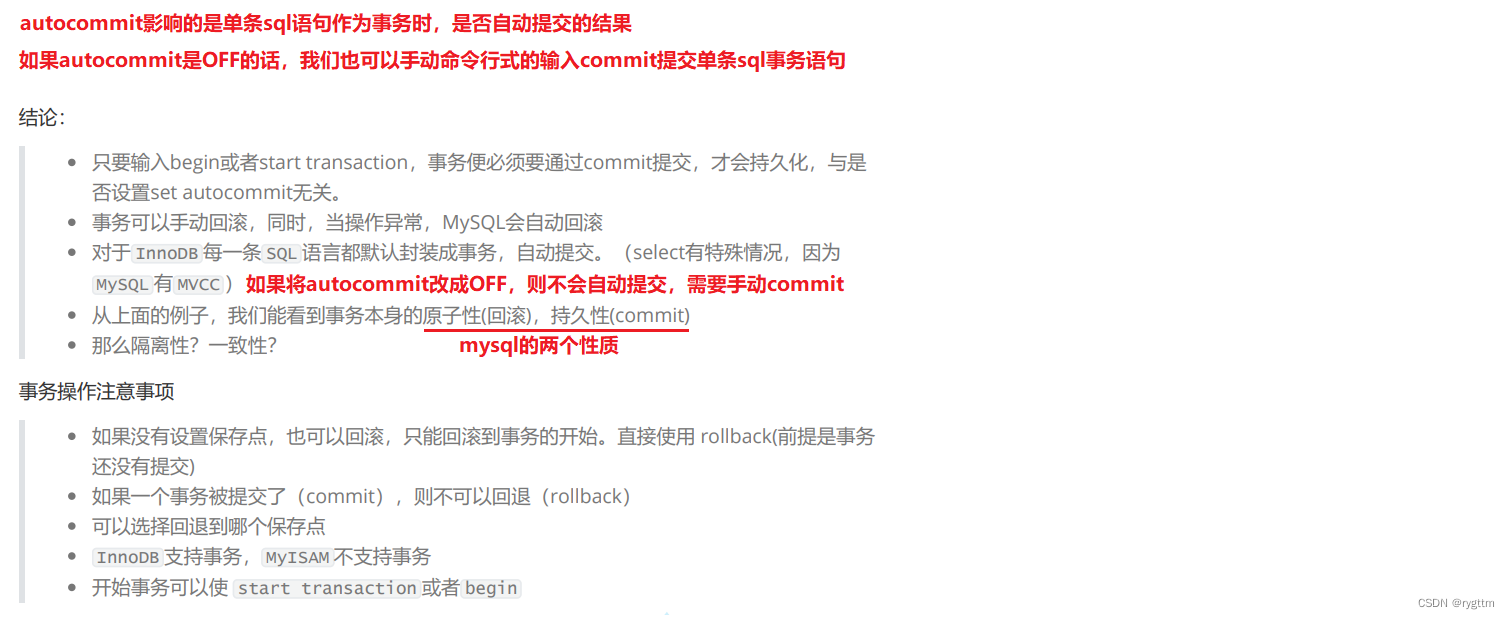
事务的提交方式一般有两种,自动提交和手动提交,其实这个提交方式只会影响单条sql语句作为事务时的提交结果,我们后面会验证这个结论。

2.事务常见操作方式
1.
读未提交是事务隔离级别中最低的,在这样的隔离级别下,可以很方便的演示事务的诸多性质。
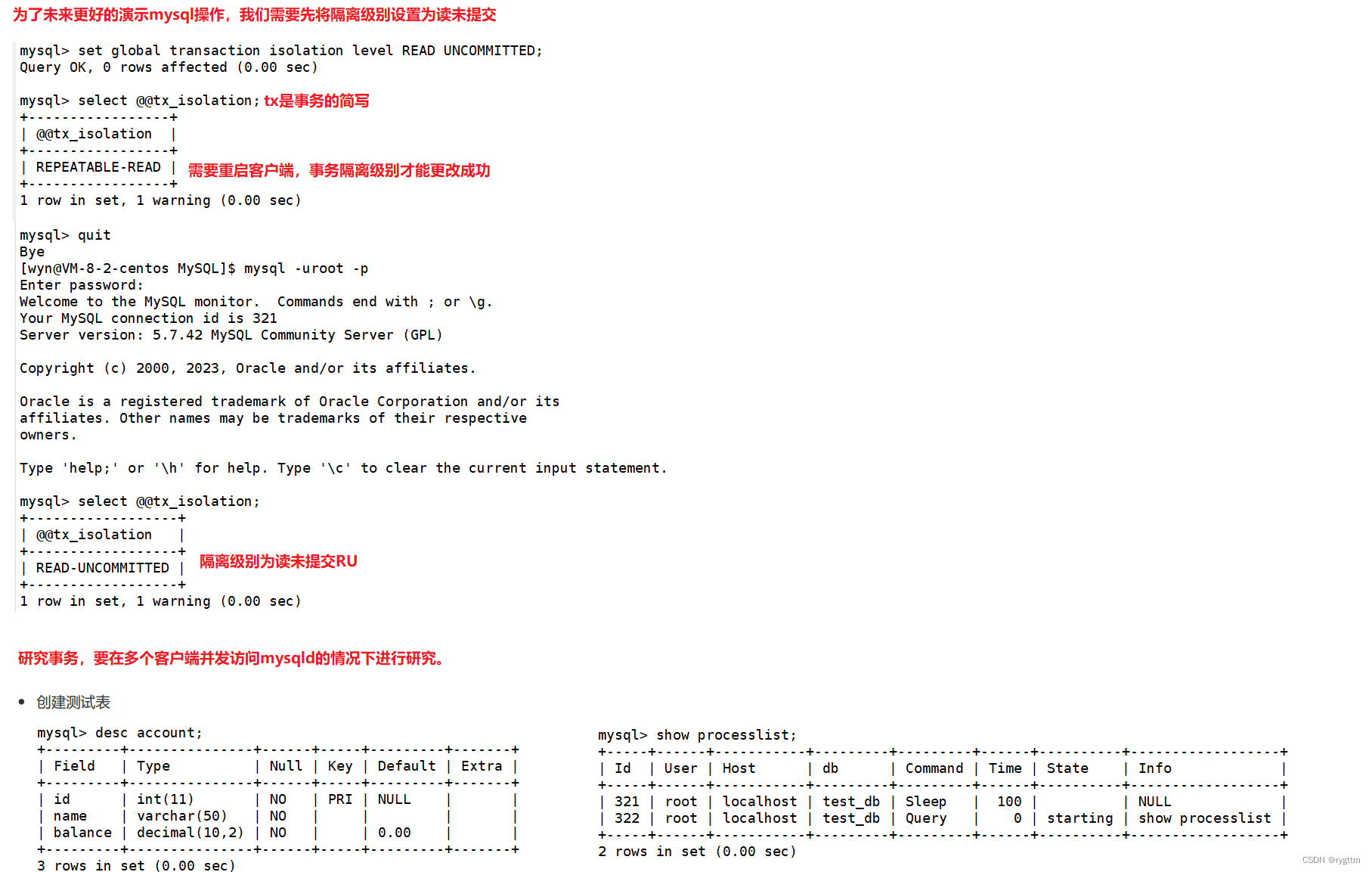
2.
begin之后事务就启动了,begin之后的多条sql语句都属于该事务内的sql语句,在事务内可以savepoint设置回滚点,MySQL支持定向回滚和直接回滚到最开始,如果没有设置回滚点直接rollback的话,则会直接回滚到最开始,此时事务也会结束,所以事务的结束方式有两种,一种是commit,另一种就是直接rollback回滚到最开始,此时事务默认结束,所以回滚操作是事务结束的一种方式。
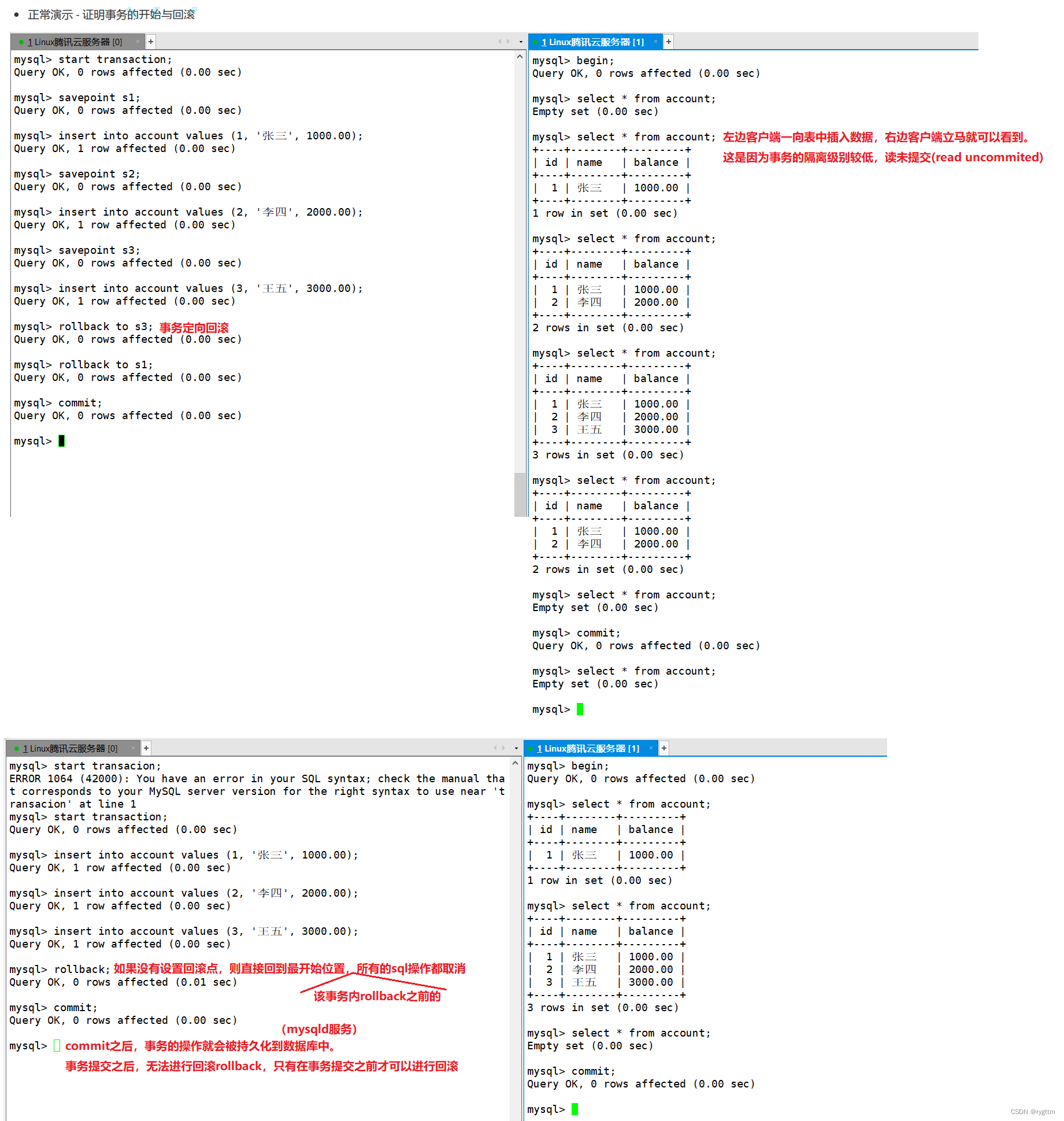
3.
只要事务commit之后,事务的操作就会被持久化到磁盘上,数据会落盘,不会受到数据库宕机或客户端崩溃的影响。
begin之后,也就是开启一个事务之后,事务都是自己手动提交的,并不会自动提交,所以autocommit是ON还是OFF对begin之后,事务的提交方式都没有影响。
单条语句在MySQL中会默认为一个事务,autocommit影响的是单条语句作为事务时的提交方式,平常我们在命令行上敲单个的sql语句时,这一个语句会作为事务立马提交,因为autocommit默认是ON打开的,但如果将autocommit关闭之后,可以看到只要没commit,所有的sql语句操作,右边的客户端是看不到的。
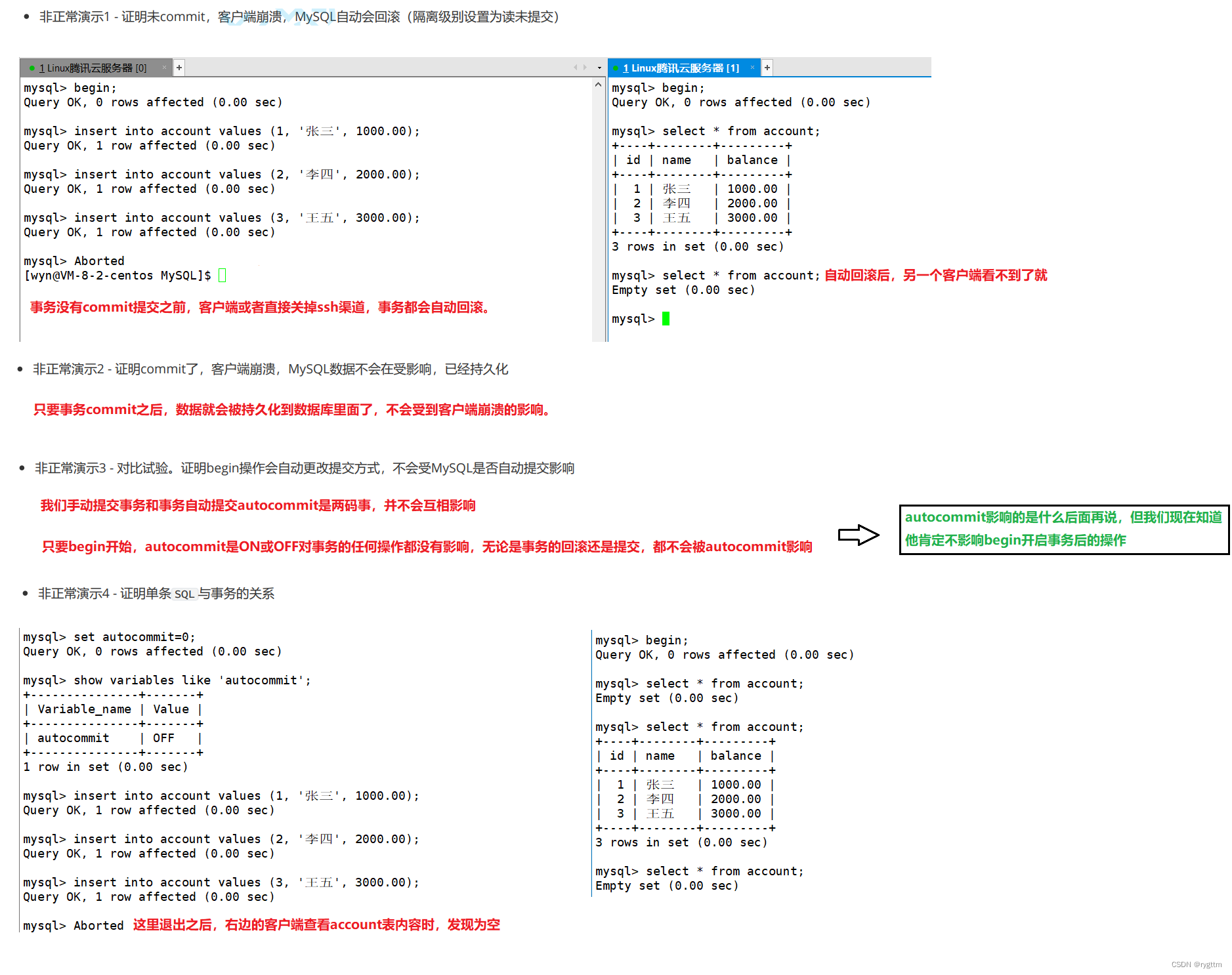
4.
所以autocommit影响的是单条sql语句作为事务时的提交情况。
3.事务隔离级别
1.
一个事务的执行结果反馈给用户的是原子性,即用户只会感受到事务执行前和执行后的状态变化,但实际事务在执行时,一定是有过程的,所以多个事务在执行时,可能会互相干扰,所以事务之间需要隔离,而隔离程度的体现就是隔离级别,像多个读事务之间并发执行时,隔离级别就可以降到最低,因为多个读事务之间并不会互相影响。
但对于读写并发时,就需要其他的隔离级别来控制多个事务的执行,其实最麻烦的并发场景就是读写并发了,因为像读读并发就不需要太高隔离级别,直接RU即可,而写写并发必须用最高的隔离级别,只能串行化执行,但读写并发就比较麻烦,可能会使用到RC和RR级别。
而隔离级别的实现主要都是通过加锁来实现的,不同的隔离级别使用不同的锁

2.
设置事务隔离级别有两种设置的方式,一种是设置全局的隔离级别,一种是设置当前会话的隔离级别,会话的隔离级别可以简写为@@tx_isolation,每次新起一个MySQL会话时,默认就会使用全局的隔离级别作为当前会话的配置。
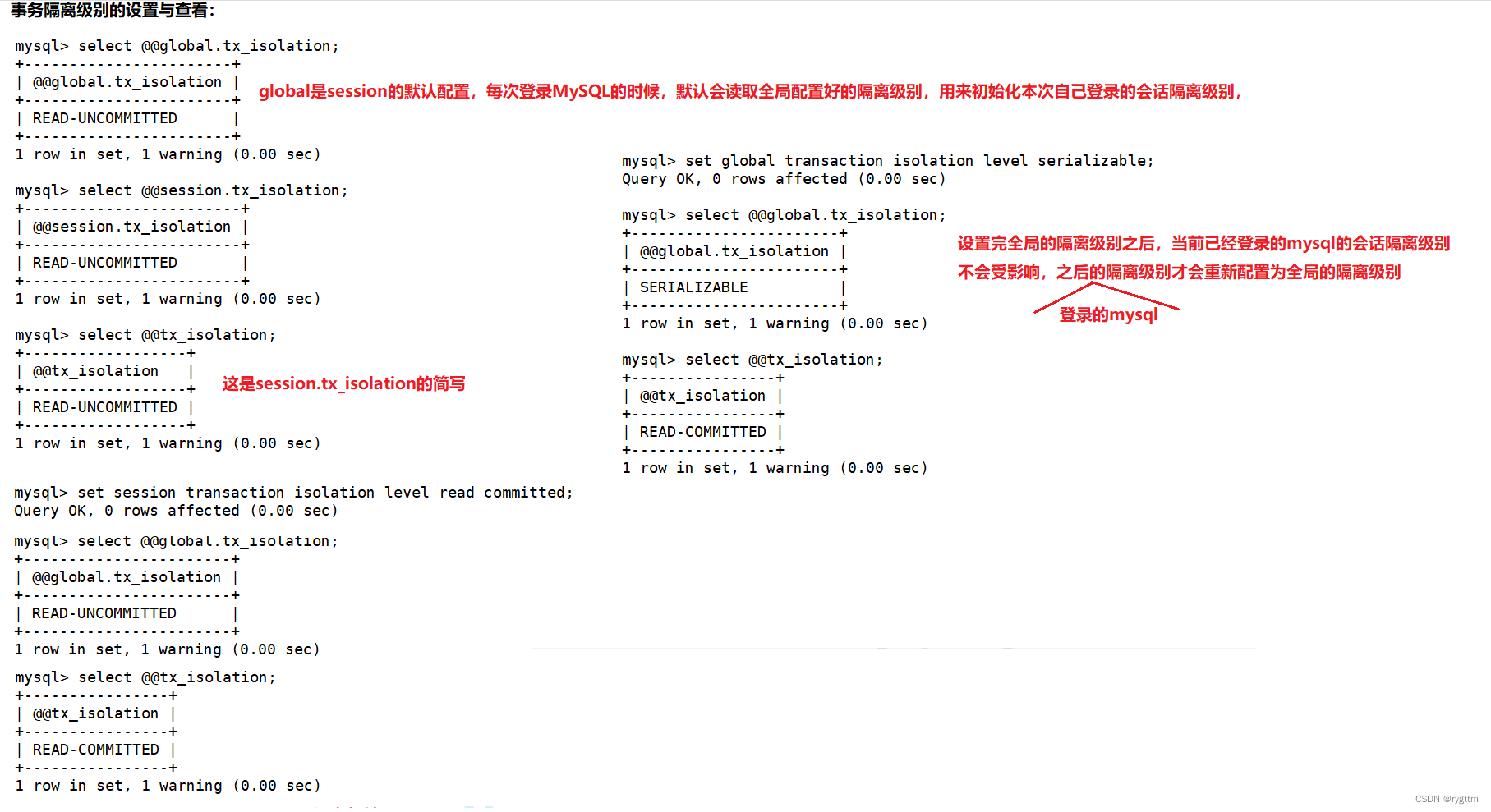
3.
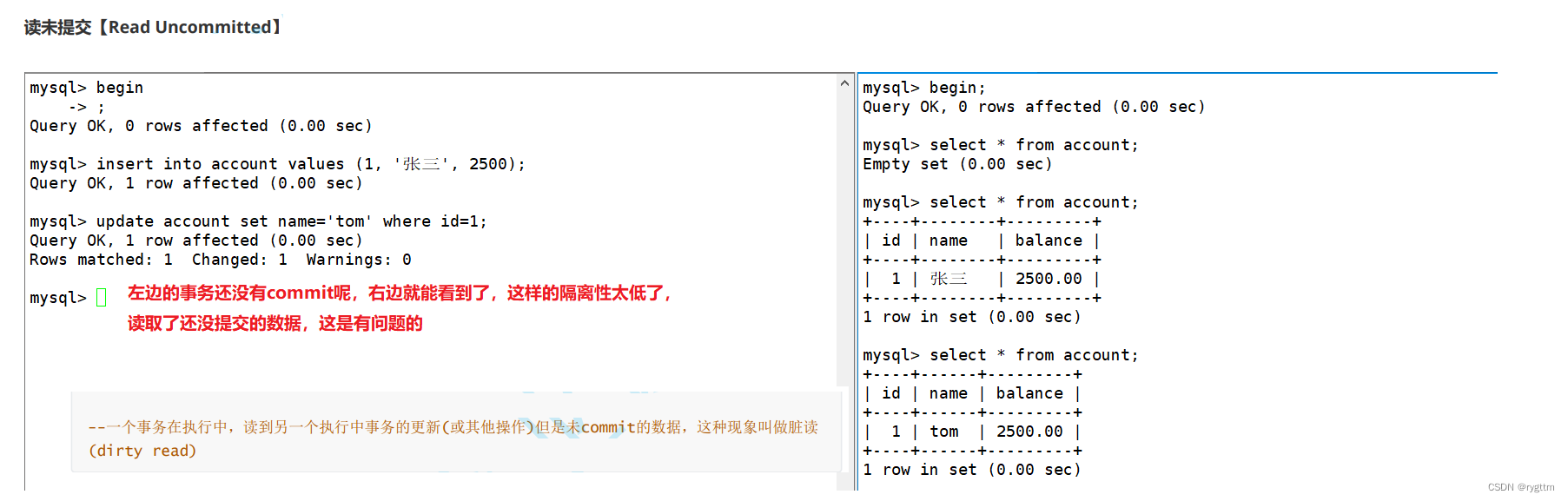
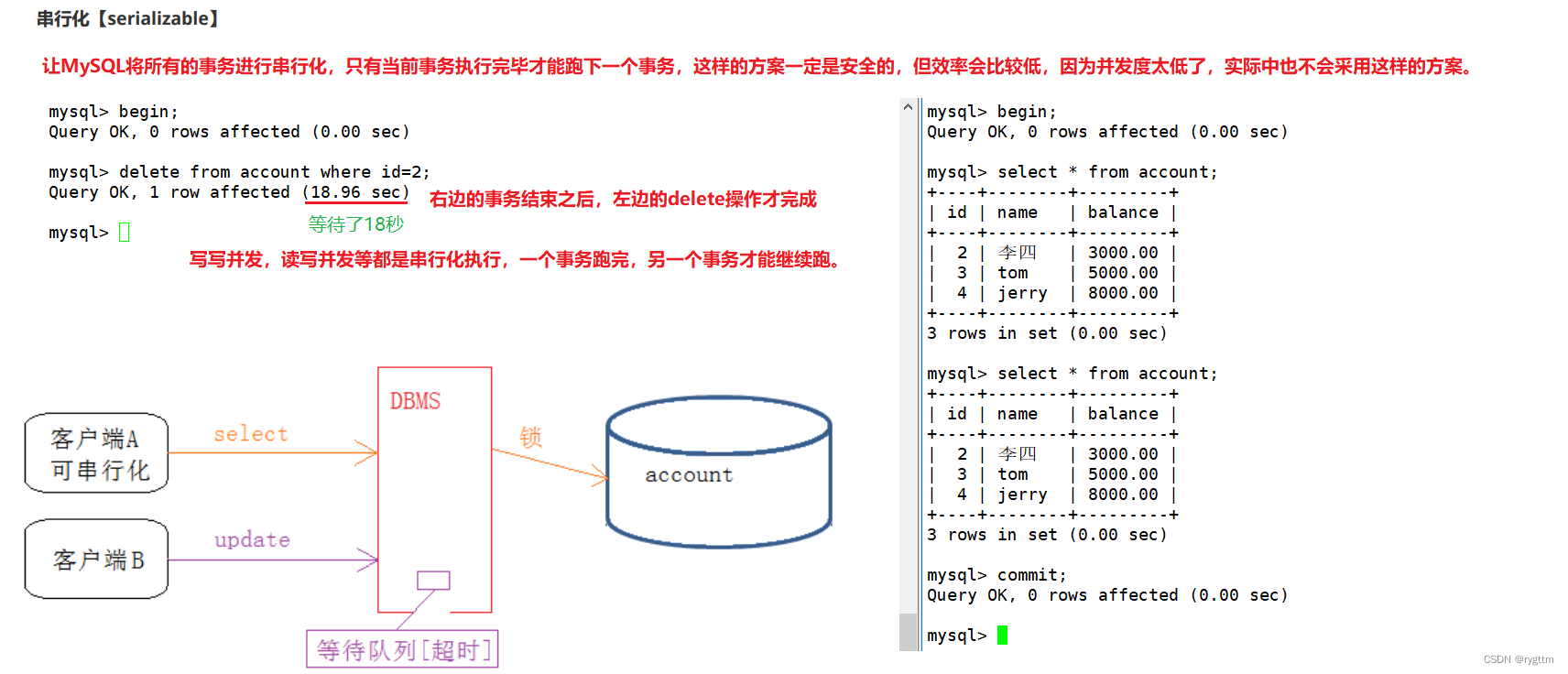
读未提交是隔离等级最低的隔离级别,虽然并发度比较高,但几乎没有加锁,同时产生的问题也会比较多,例如脏读,幻读,不可重复读等并发问题,脏读是RU级别最典型的问题,读取到一个事务还未提交的数据,很容易影响到上层的决策,所以这样的并发问题是不可容忍的。
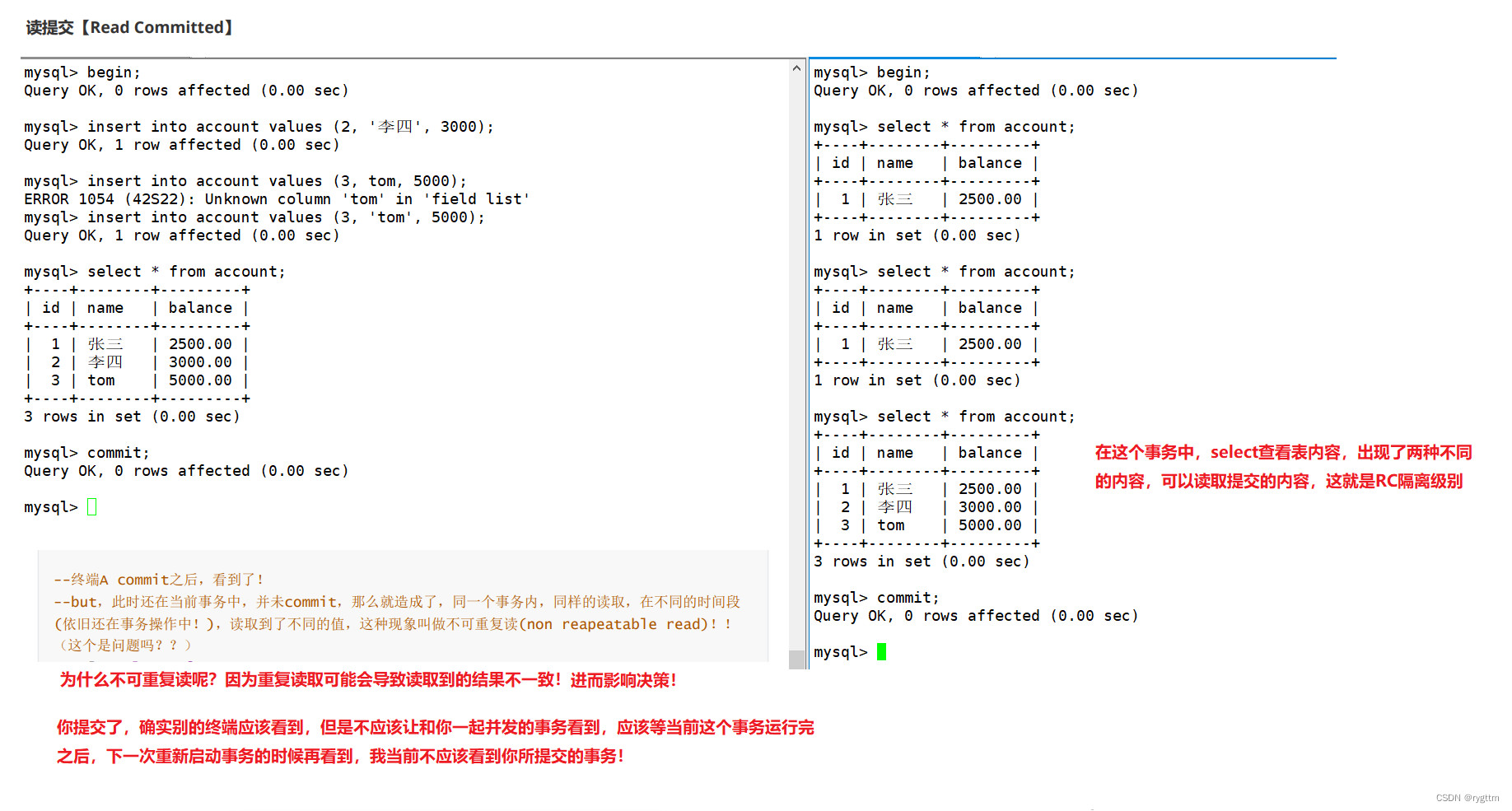
4.
读提交隔离级别最典型的并发问题就是不可重复读,因为重复读可能会读取到不一样的结果,这也会影响上层决策。读提交就是当前事务可以读取到其他事务提交后的内容,这本身并没有什么问题,但A事务提交后的内容不应该让当前正在和A事务并发的其他事务看到,应该让A事务执行完之后,其他此时重新启动的事务看到A事务提交后的内容,所以读提交也有他自己的并发问题。
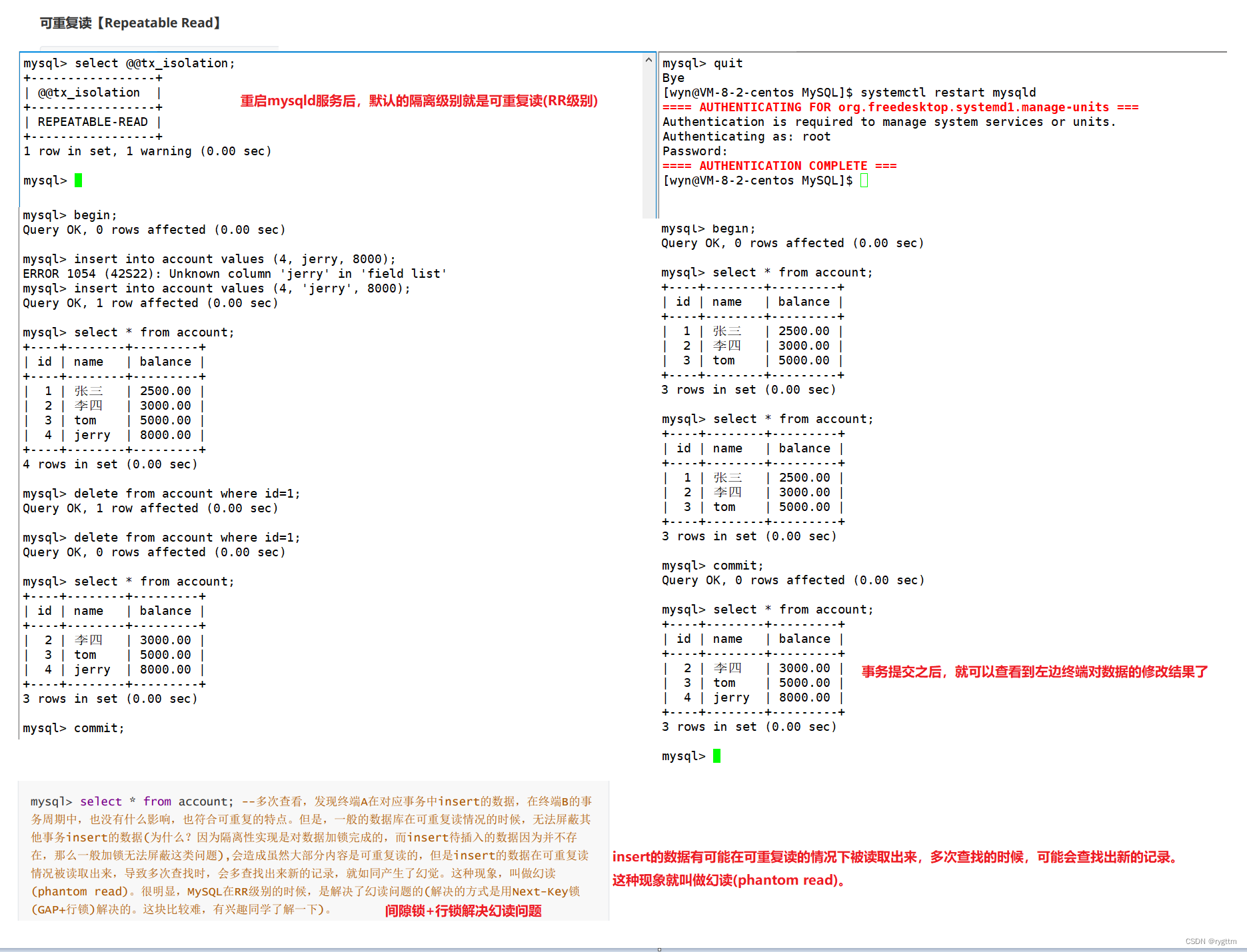
5.
RR级别也就是可重复读级别是MySQL默认的隔离级别,只要你重启mysqld服务器,隔离级别就会默认设置为RR级别。
在MySQL下可以看到终端B并没有出现并发问题,但实际上在其他的数据库中,事务隔离级别在RR级别下还会有幻读的问题,只不过MySQL通过间隙锁+行锁的方式解决了幻读的问题,其他的一些数据库没有解决。
幻读指的是其他事务insert的数据可能在重复读的情况下被读取出来,因为隔离是对数据进行加锁完成的,而insert的数据本身并不存在,所以一般加锁的方式无法解决幻读问题,但MySQL解决了。
值得注意的是,幻读指的是其他事务insert时,重复读可能会读取出来插入数据后的表,就像出现了幻觉一样。如果其他事务update,delete数据,则重复读还是可以避免产生并发问题的,因为他们操纵的是已有的数据。
其实在RR级别下,为什么读取是可重复读的呢?sql第一次读取的时候,就直接给数据加上行锁,保证其他事务对数据无法进行update和delete,同时给数据加上间隙锁,如果表有索引,则在当前记录的附近加上间隙锁,防止insert数据的行为。
6.
串行化的隔离级别太简单粗暴了,无论事务是执行什么操作,都必须被严格强制以串行化的方式执行,这样的并发度太低,效率很慢,实际中不会采用这样的方案,可能会产生超时或锁竞争的问题产生,这种隔离级别太极端了。
7.
从表格就可以看到隔离级别越高,产生的并发问题就越少,但随之数据库的并发性能也就越低,所以往往需要在安全和性能之间寻找一个平衡点,这个平衡点就是RR可重复读隔离级别,同时也是数据库默认的隔离级别。
一致性从技术角度来看,是依靠AID的技术来实现的,但其实一致性和用户逻辑强相关,一致性不仅仅需要在技术层面上支持好,同样也需要程序员在用户逻辑层面维护好数据库事务的一致性。
4.MVCC(提高读写并发时数据库的性能)
1.
多版本并发控制MVCC是一个并发效率很高的读写冲突的控制方式,在并发读写数据库时,MVCC可以做到在读操作时,不用阻塞写操作,在写操作时,不用阻塞读操作,极大的提高了数据库读写并发时的性能。
此外MVCC也解决了RR级别下的幻读问题,以及脏读,不可重复读等问题。
MVCC是一把提升数据库性能的利剑。
2.
MVCC为事务分配单向增长的事务ID,事务对数据修改时,会保存一个版本,版本与事务ID关联。
所以每个事务都有自己的事务ID,可以根据事务ID的大小决定事务到来的先后顺序,事务ID越大,事务越新。
mysqld一定会面临处理多个事务的情况,所以mysqld要对多个事务作管理,也就是先描述再组织,所以每个事务都会对应着一个结构体对象。
3.
MVCC实现的表中会有三个隐藏列字段,DB_TRX_ID用于记录创建表中当前这条记录的事务ID,或最后一次修改当前这条记录的事务ID,DB_ROLL_PTR指针指向这条记录的上一个历史版本,DB_ROW_ID就是我们很早之前谈论索引时的隐藏主键,如果表中没有主键,则MySQL默认会创建一棵以DB_ROW_ID为键值的聚簇索引,也就是B+树。
除了上述三个隐藏列字段之外,还有一个标志删除位flag。

4.
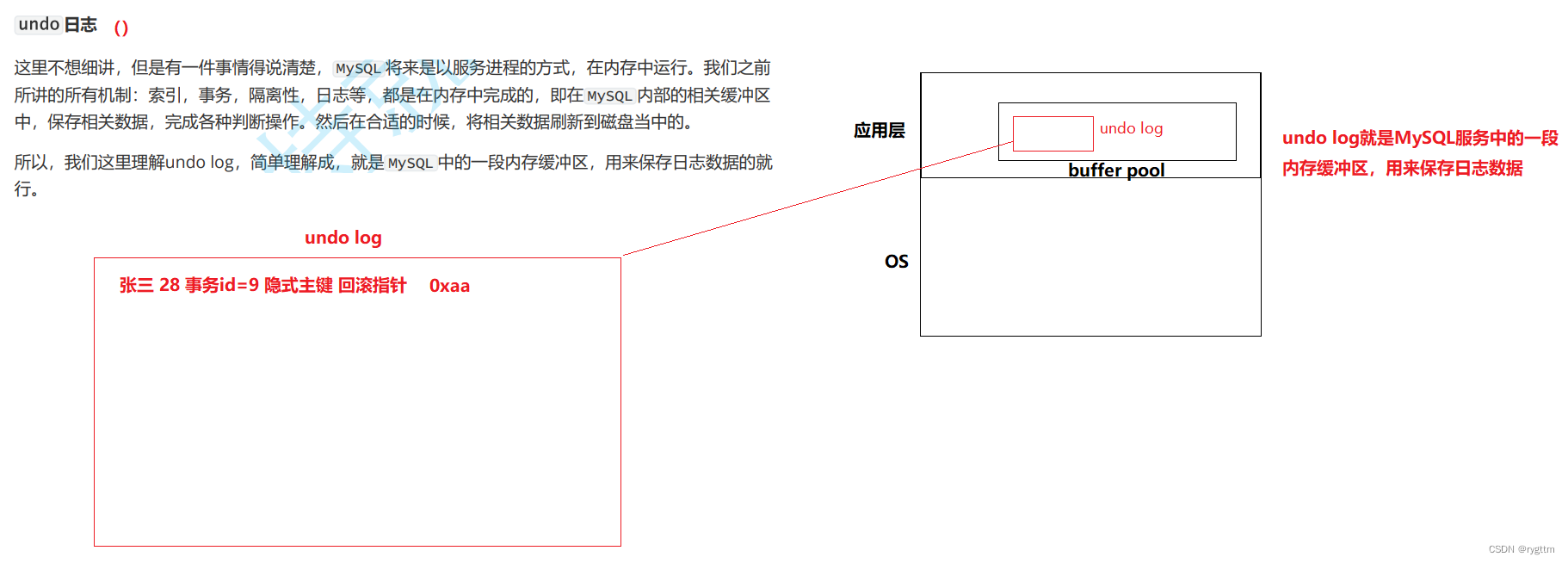
undo log也是实现MVCC的一个重要角色,可以将其理解为一个,保存事务对表中记录更改的版本链的缓冲区,事务的隔离和回滚操作的实现都离不开undo log
5.
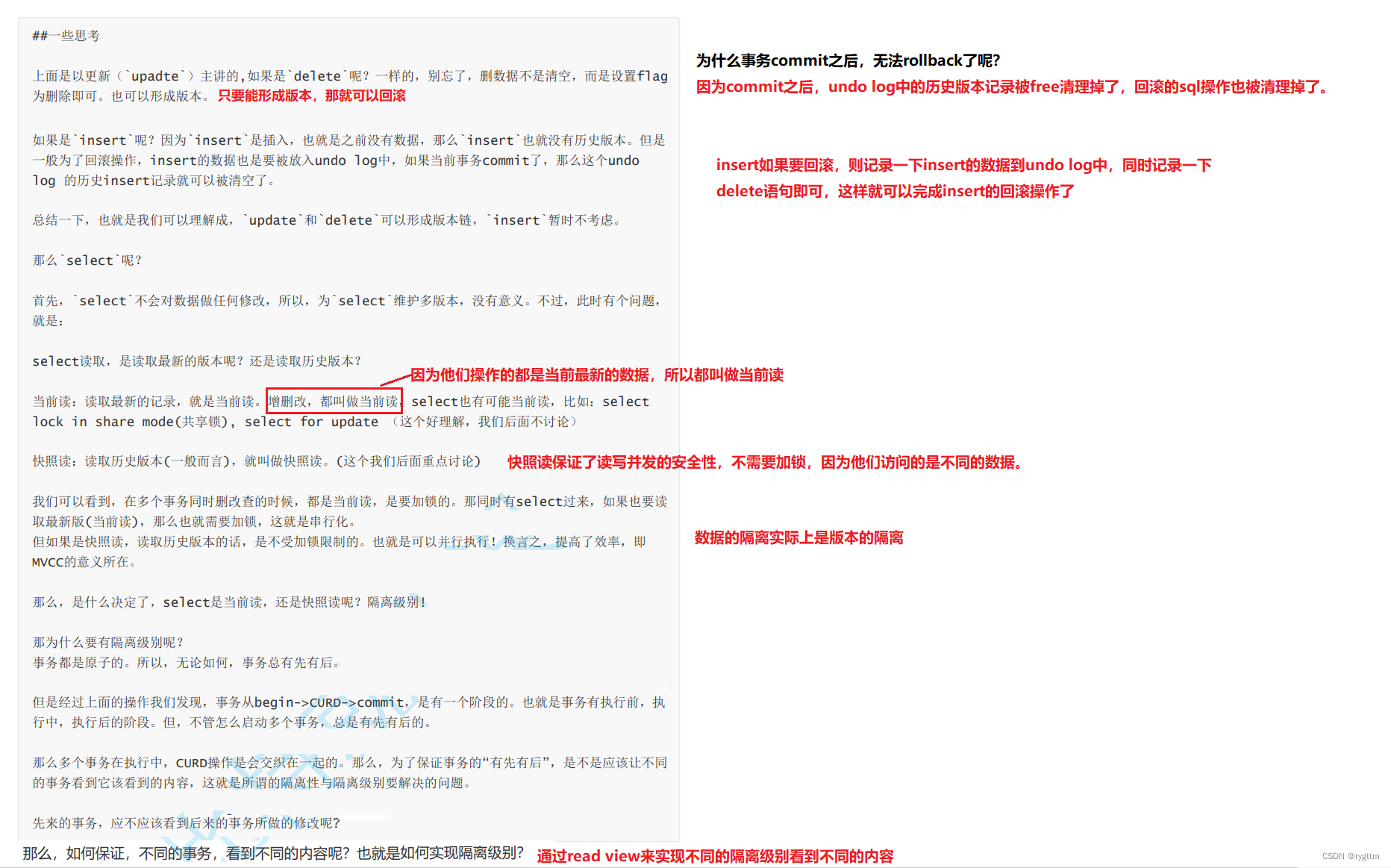
增删改都会形成当前记录的历史版本,select没必要形成历史版本,但select在读取的时候有两种选择,一种是读取最新的记录,另一种是读取历史版本的记录,也就是当前读和快照读,快照读保证了读写并发的安全性和并发度,不需要通过加锁来实现,因为快照读和增删改操作的数据是不同的记录版本,一个是历史数据,一个是当前数据。
undo log中的一条条历史版本,称为一个个的快照,一旦事务提交之后,这些快照就会被free掉,所以undo log中的记录是有进有出的,不用担心undo log会被记录打满。

实现事务隔离不仅仅需要历史版本数据,还离不开read view,通过read view才可以真正实现出事务隔离,也就是不同的事务在select读的时候,应该看到怎样的版本信息。
读视图read view是事务在第一次执行快照读的时候就产生了的,而read view其实就是类ReadView实例化出来的对象,一般习惯称之为快照,在这个快照对象内部有四个成员变量是非常重要的,也是实现事务隔离的重要技术实现。
m_ids保存read view生成时,系统中正在活跃的事务ID
up_limit_id保存的是m_ids中事务ID最小的事务ID
low_limit_id保存的是当前已出现过的事务ID最大值+1,也就是系统即将分配给下一个事务的ID
creator_trx_id保存的是创建当前记录的事务ID
所以我们现在左手有read view,右手有历史版本链中所有的记录的DB_TRX_ID,而当前事务select读的时候,应该读取到什么样的版本记录,其实就是由read view和历史版本链所决定的。

下面的图其实就已经诠释了事务可见性的算法。
如果版本链中的某个记录对应的ID大于或等于limit ID,说明这个记录对应的事务是在创建快照之后新起的事务,那么这条记录就不应该被创建快照的事务所看到。
如果版本链中的某个记录对应的ID小于up ID或等于creator_trx_id,则说明这个记录是在创建快照之前早就已经提交的事务,或者这条记录本身就是由创建快照的事务所做的更改,则说明这条记录应该被当前事务所看到。
如果版本链中的某个记录对应的ID在m_ids里面,那就说明该记录对应的事务还没提交完呢,创建read view的事务不应该看到这条记录,一旦看到那就是脏读。如果版本链中的某个记录对应的ID不在m_ids里面,同时小于limit ID,大于up ID,则说明该事务已经提交了,但为什么他的ID不小于up ID呢,其实是因为该事务到来的时间比较晚,但该事务是短事务,执行的很快,快照形成时,该事务早已执行完毕了,所以这样的版本记录是可见的。

下面是源码对应的事务可见性的处理策略,changes_visible是MySQL判断当前事务快照读应该看到什么样记录的一个函数,trx_id_t是外面传的一个参数,该参数应该被不断更新为版本链中的各个记录所对应的事务id,以判断该记录是否该被调用changes_visible函数的事务所看到。
例如当id<m_up_limit_id或id= =m_creator_trx_id时,当前记录应该被看到,所以返回true,id>=m_low_limit_id,当前记录不应该被看到,返回false,或者如果m_ids里面的事务是空的,同时Id是小于m_low_limit_id的话,则说明该记录对应的事务是早就已经提交了的,是可以看到的。
如果上面的判断条件都不满足的话,判断当前记录对应id是否在m_ids里面,如果在则不能看到,返回false,如果不在则可以看到,返回true。
如果当前记录不应该被看到,则继续遍历下一个版本链中的记录。

值得注意的是,read view在第一次事务进行快照读的时候就形成了,在事务运行期间,像RR级别就会一直使用该read view。
下面的实验是典型的一个trx_id不在m_ids里面,同时也小于limit_id,大于up_id的情况,这种情况的记录是可见的,当前事务可以看到。

所以我们可以总结一下MVCC实现的基本原理,以及事务快照读可见性的原理,通过给每个事务对记录的增删改都分配对应的历史版本信息,就像写时拷贝一样,只要对记录作修改,则在undo log中形成该事务的历史版本链,同时给每个事务根据到来顺序的不同分配一个逐渐增长的事务id,当事务在快照读的时候会首先形成一个快照read view,read view对象内部有四个重要的成员变量,分别是up_limit_id,low_limit_id,creator_id,m_ids,通过这四个字段和undo log里面的版本链记录之间的比较,得到创建read view的事务应该看到什么样的记录。
5.RR与RC的本质区别
1.
在MVCC下,快照读并不会加锁,所以他和写并不是互斥的。在事务A作出修改后,提交之前,事务B形成快照,则修改的记录对应的事务ID刚好在快照内的m_ids里面,则事务B不应该看到事务A对记录做出的修改。如果想要看到最新的数据,则可以使用加共享锁的方式来读取,此时读取到的数据就是最新的,但这并不意味着最新的就一定是正确的,我们不希望一个事务在运行期间读取到的结果发生不同。
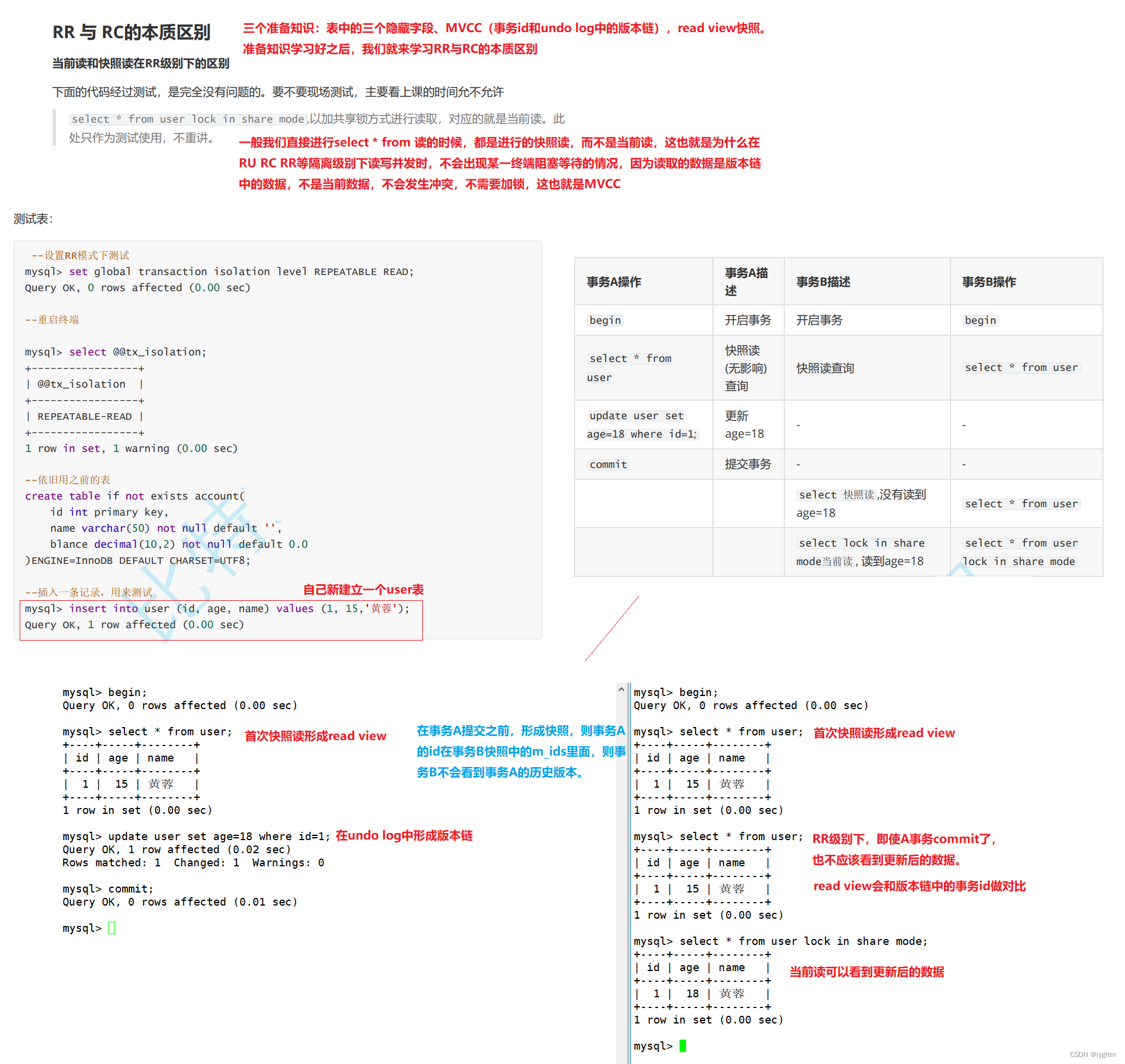
2.
在事务B快照读之前,事务A完成了对记录的修改并提交,那么事务B就应该在他自己执行的整个期间都一直能够看到事务A对记录做出的修改,因为事务A都已经提交了,无论是RR还是RC都应该看到。
如果从MVCC实现原理角度来讲的话,则可能是两种情况,一种是事务A的ID小于up_limit_id或事务ID不在m_ids里面,也就是说要么事务A到来的特别早,并提前提交了,形成快照的事务应该看到,或者是事务A到来的比形成快照的事务晚,但事务A是一个短事务,在当前事务形成快照之前,事务A就执行完并且提交了,那么快照事务也应该看到。所以,无论对应哪种情况,事务B都应该看到事务A对记录做出的修改。
需要直到的是,事务读到的数据是新的还是旧的并不重要,事务在执行期间读到的数据始终都不变这才是重要的!
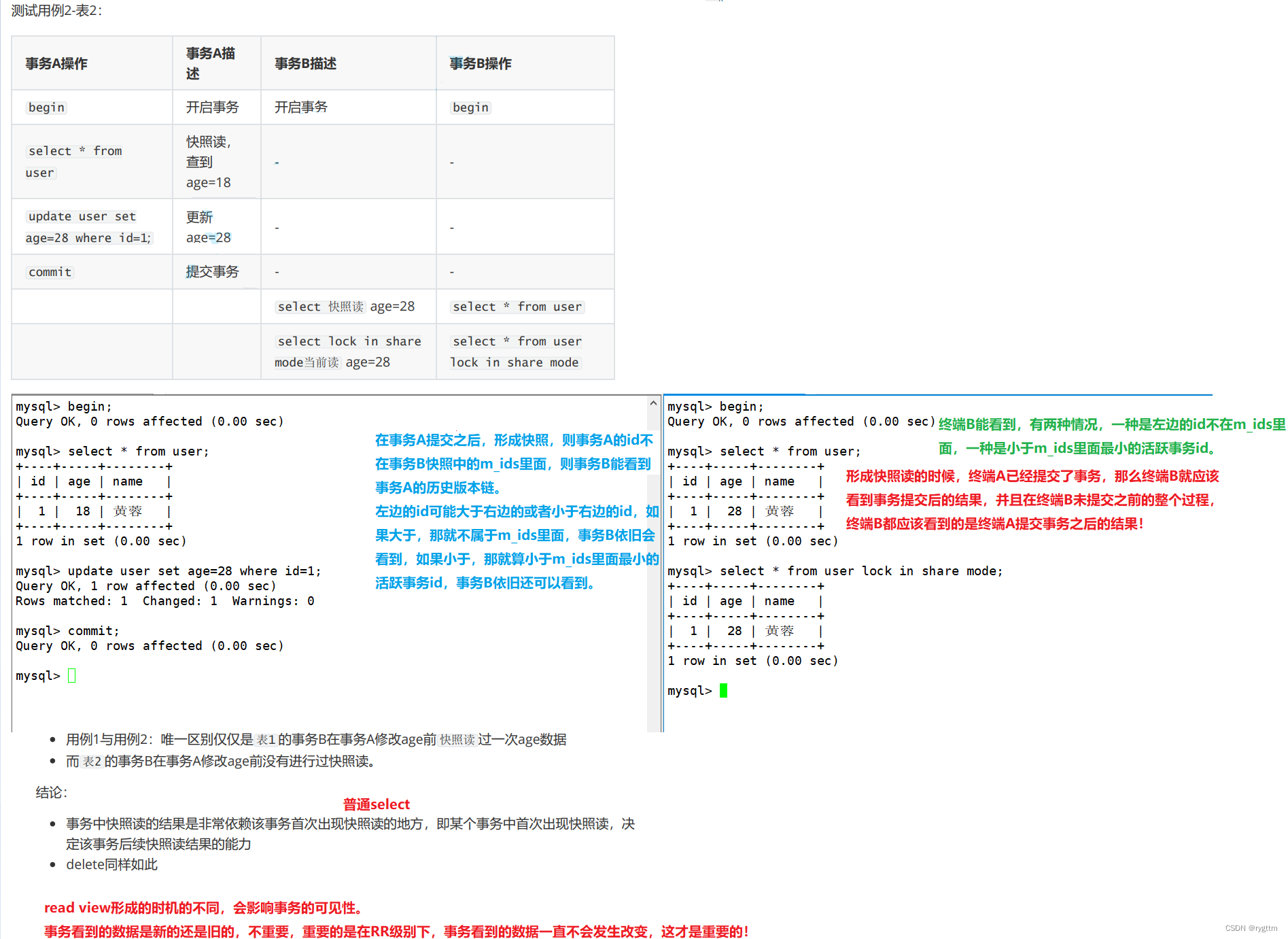
3.
RR与RC的本质区别就是快照的形成,RR级别下事务第一次形成快照后,则在后面事务整个的执行期间,会一直使用该快照,这也就是为什么RR级别下是可重复读的,因为read view对象一直不变。而RC级别下事务每次快照读的时候,都会重新生成新的read view,这也就是为什么RC级别下可以看到其他事务提交之后的内容,因为RC级别会生成新的read view,重新进行可见性的判断。
两者之间的差别再说的本质一些,RR级别下第一次快照读的时候,会new一个read view对象,并且在该事务执行期间一直使用这个read view对象,RC级别下每次快照读的时候,都会重新new一个read view对象,并delete掉原来的read view对象,所以在该事务执行期间,一直使用不断更新的read view对象。

RU级别一直都是当前读,没有加锁控制,RR和RC都是快照读(MVCC),串行化也是当前读,不过是加锁控制的,所以串行化无论是读读之间,还是读写之间,还是写写之间都是需要竞争锁的,这也就是为什么串行化并发度低的原因,因为无论什么操作都加锁。

三、MySQL视图特性
1.
视图实际中用的并不多,但我们也稍微了解一下。
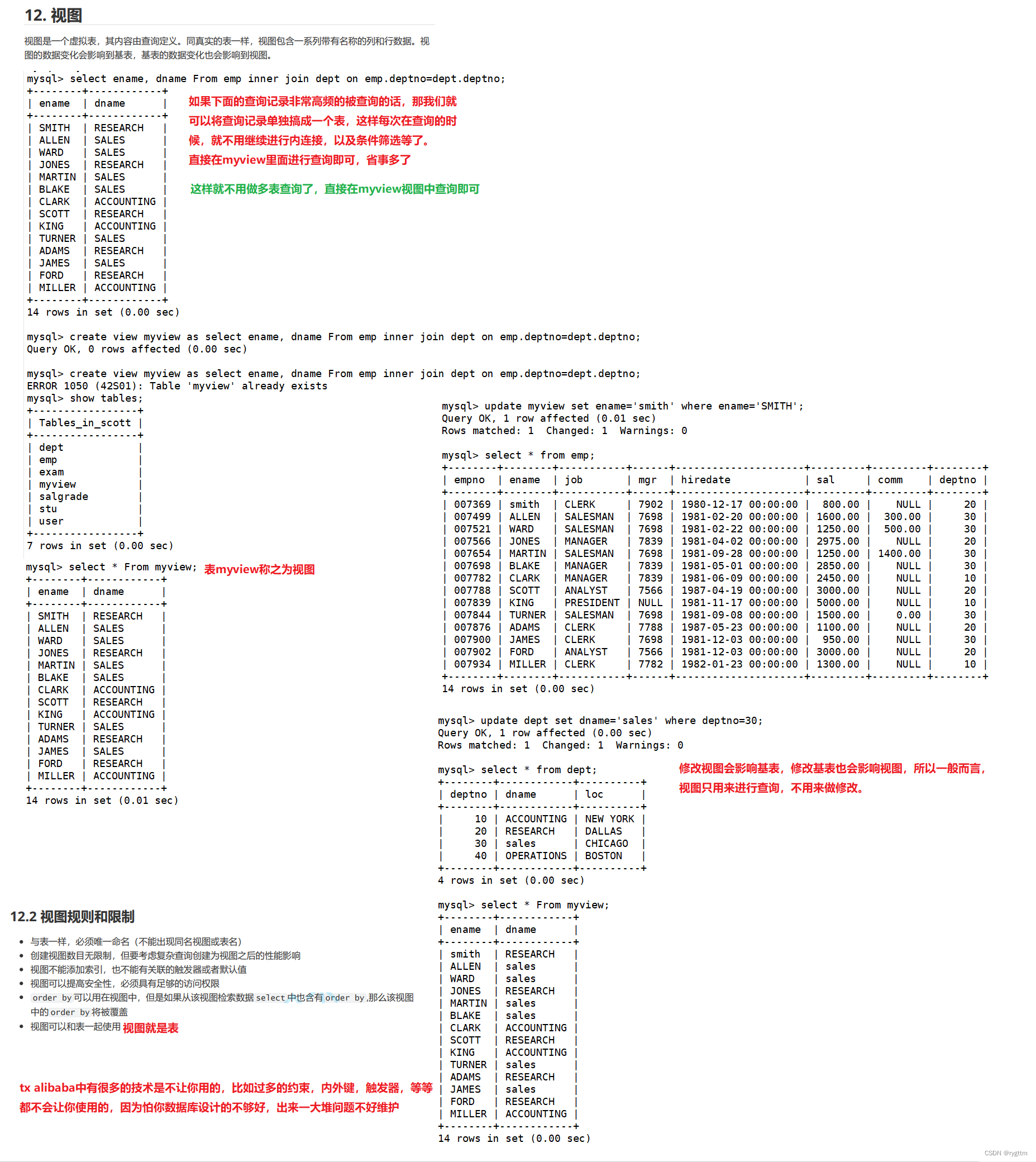
创建视图是根据select查询结果来创建的,create view view_name as select ……,创建出来的视图其实就是一张表,如果修改视图中的数据,则原表中的数据也会随之被修改,所以一般而言,视图只用来查询,不会用来作修改,因为基表中的数据会受牵连。
如果你高频的只查询一部分表的数据,则可以选择给这一部分数据创建视图,下次查询时直接从视图中查询即可。
四、MySQL用户管理
1.
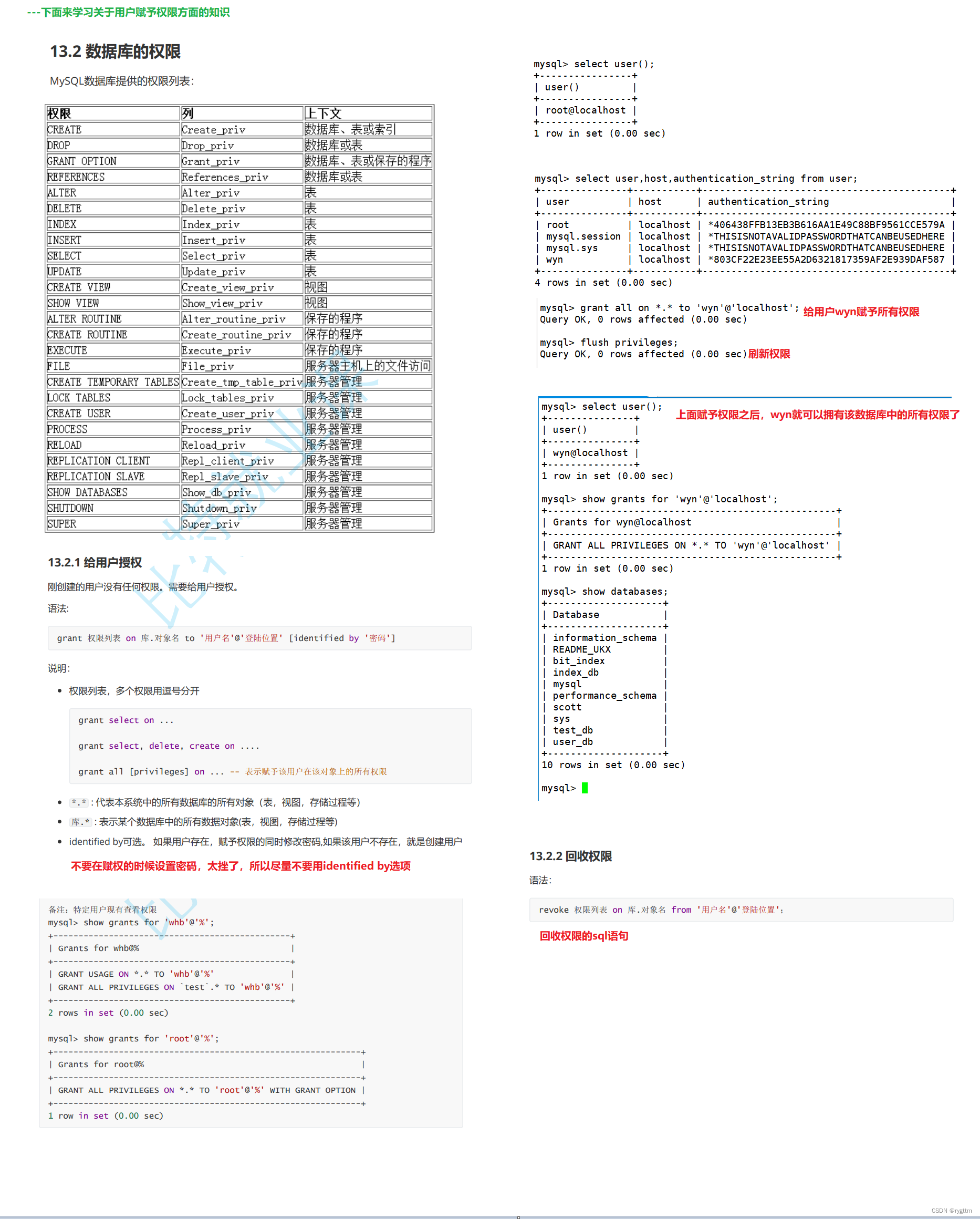
MySQL安装好之后会有一个默认的database叫做mysql,在该数据库内部会存在一个user表,该表中存放了当前mysqld服务下所有的用户的信息,包括很多的字段,最常用的几个字段就是host,user,authentication_string,用户密码是经过password()函数加密过的,所以我们看不懂。

2.
新建用户时,要指定用户名,主机名,以及登录时需要认证的密码,新建用户之后,为了让我们新建的用户生效,最好刷新一下权限flush privileges。
删除用户时,需要指定用户名和host登录方法。
root用户可以更改所有用户的登录密码,所以修改秘密时,建议直接使用root用户的身份来修改所有用户的密码。

我们可以指定的给用户赋予权限,比如对某一个具体的库,某一个具体的表,赋予查询,增加,删除,修改等权限,赋予权限时也可以指定密码,不过尽量在创建用户时就指定好密码,不要在赋权时指定密码。回收权限可以使用revoke指令来回收。
五、API和图形化界面的客户端
1.
除了我们之前一直用的命令行式的客户端之外,还可以使用C语言连接数据库,使用API的方式来作为客户端访问数据库服务,我们可以直接使用yum install -y mysql-community-server下载,一般下载的时候会自动给我们把开发包下载好,如果没有开发包,则可以使用yum install -y mysql-devel手动下载开发包,下载安装好之后我们就可以使用vscode,以API的方式来连接并使用数据库了。

安装好之后,在/usr/include/mysql下会存在C语言连接数据库时使用的头文件,在/lib64/mysql下会存在着连接数据库需要的动态库和静态库。
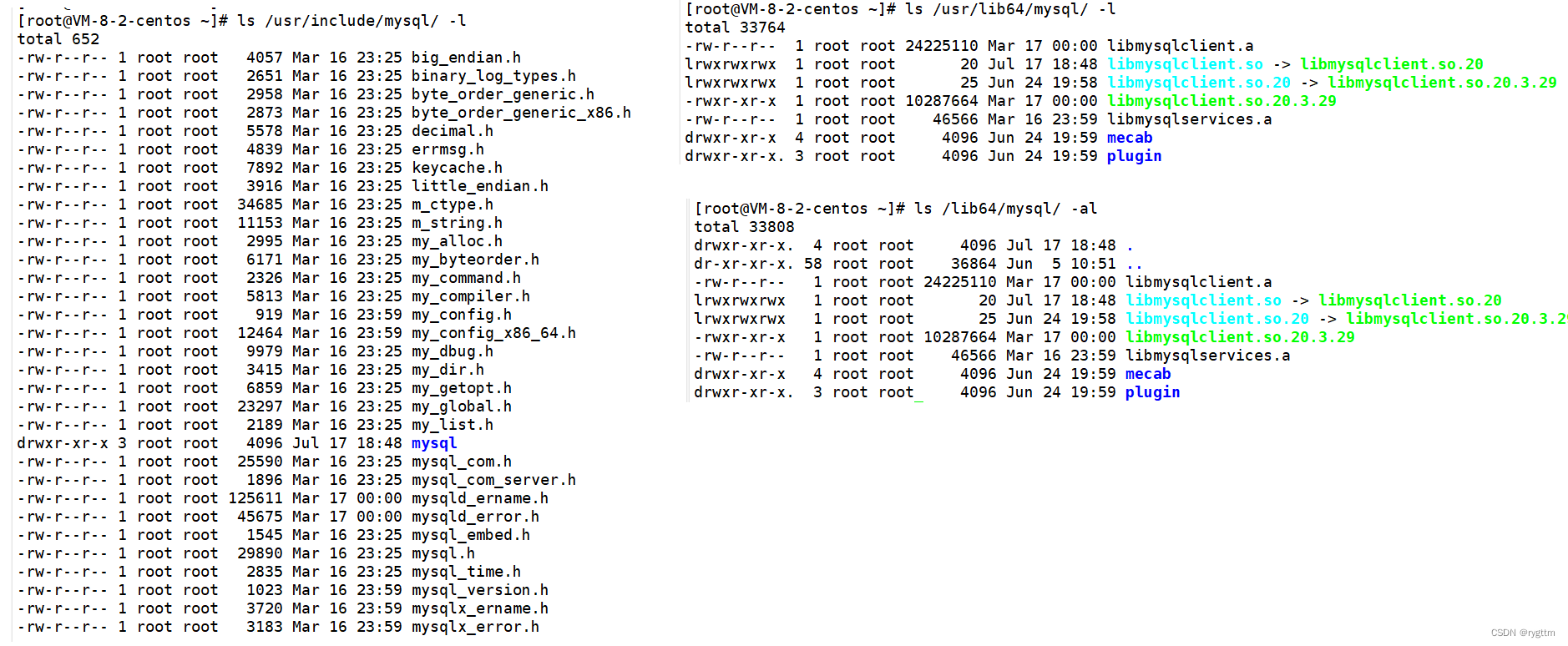
2.
准备好开发环境之后,我们尝试连接一下数据库。
使用mysql.h头文件,指明编译器搜索头文件时的路径。连接库的时候,需要指明链接器的链接路径,以及需要链接的库的名称,这些字段都需要在makefile里面确定好。
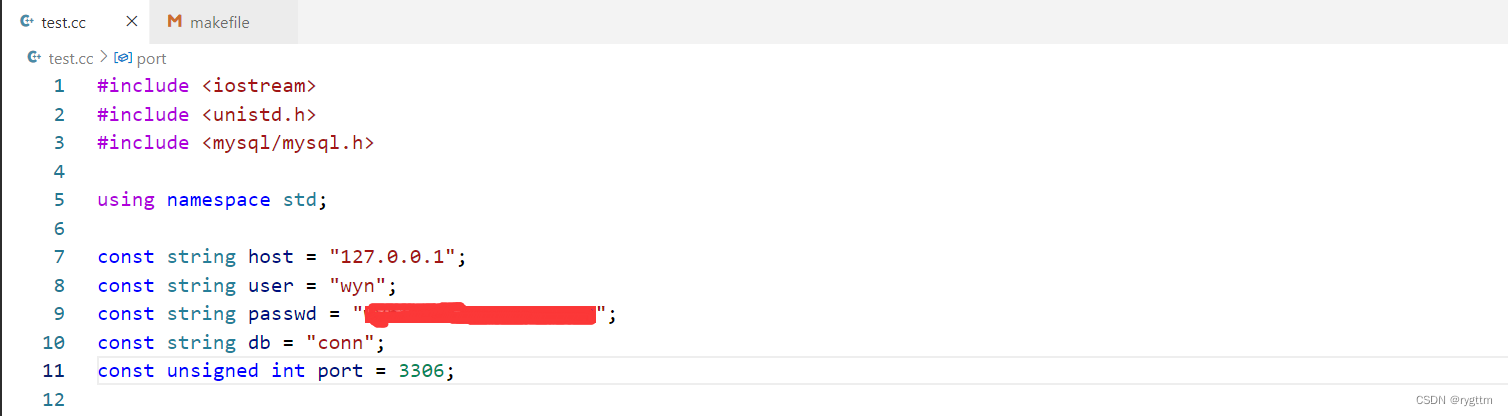

链接库前必须先调用mysql_init进行初始化,mysql_init会返回一个类似于文件描述符的东西,使用myfd就可以对数据库进行操作。初始化好之后,调用mysql_real_connect进行数据库的连接,连接时需要传递对应的参数,例如密码,用户名,登陆方式,database名称,端口号等等
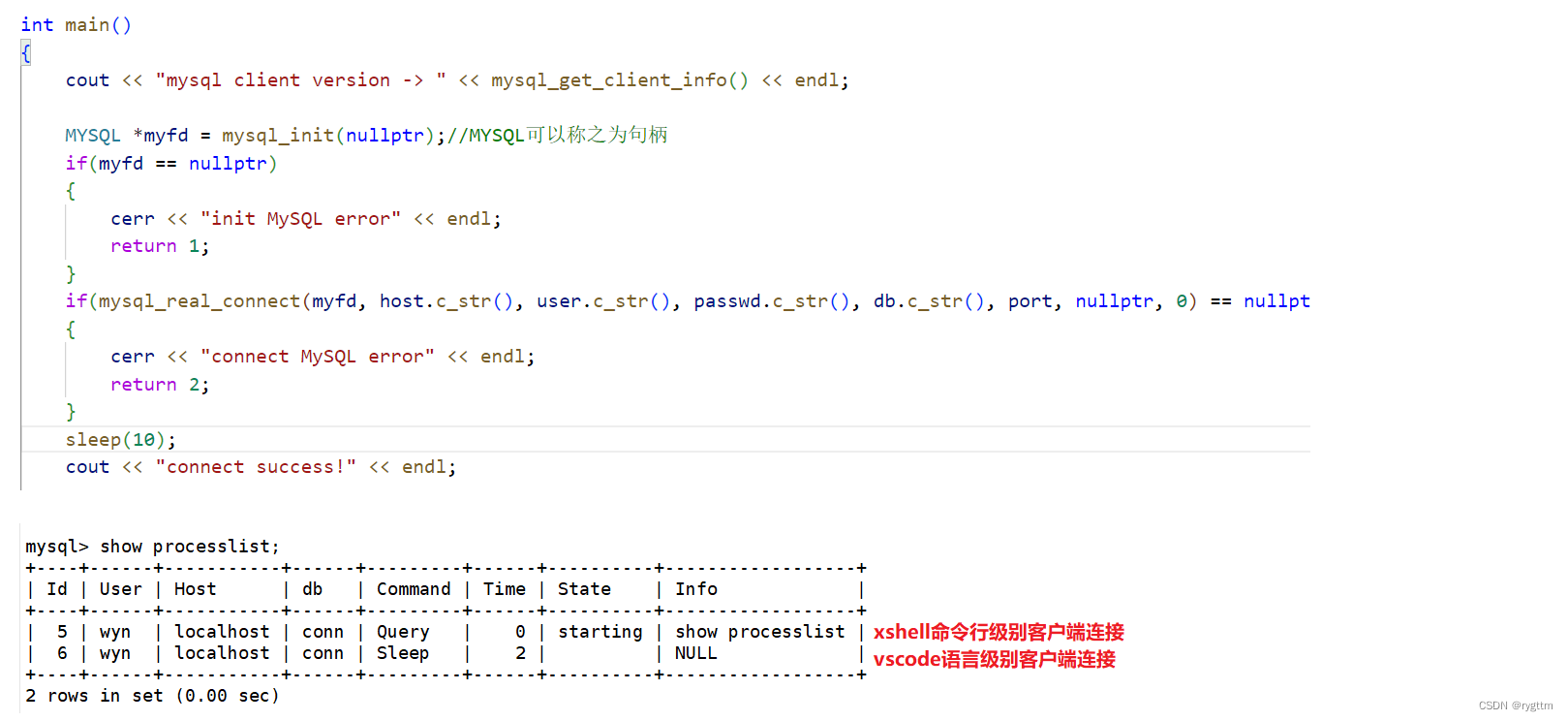
mysql_query用于给数据库下发MySQL命令,第一个参数为myfd,也就是那个文件描述符,下发的指令为增删改时,我们返回给客户端的结果只需要是Query OK or Query failed 即可,这样处理起来并不难,我们可以通过API的方式自己实现一个类似于命令行式的客户端,难度并不大,只需要调用mysql_query即可,难的是select查询语句,因为查询是需要返回命令行处理结果的,所以想要实现查询命令的下发,仅仅有mysql_query是不够的,还需要其他API的帮助。
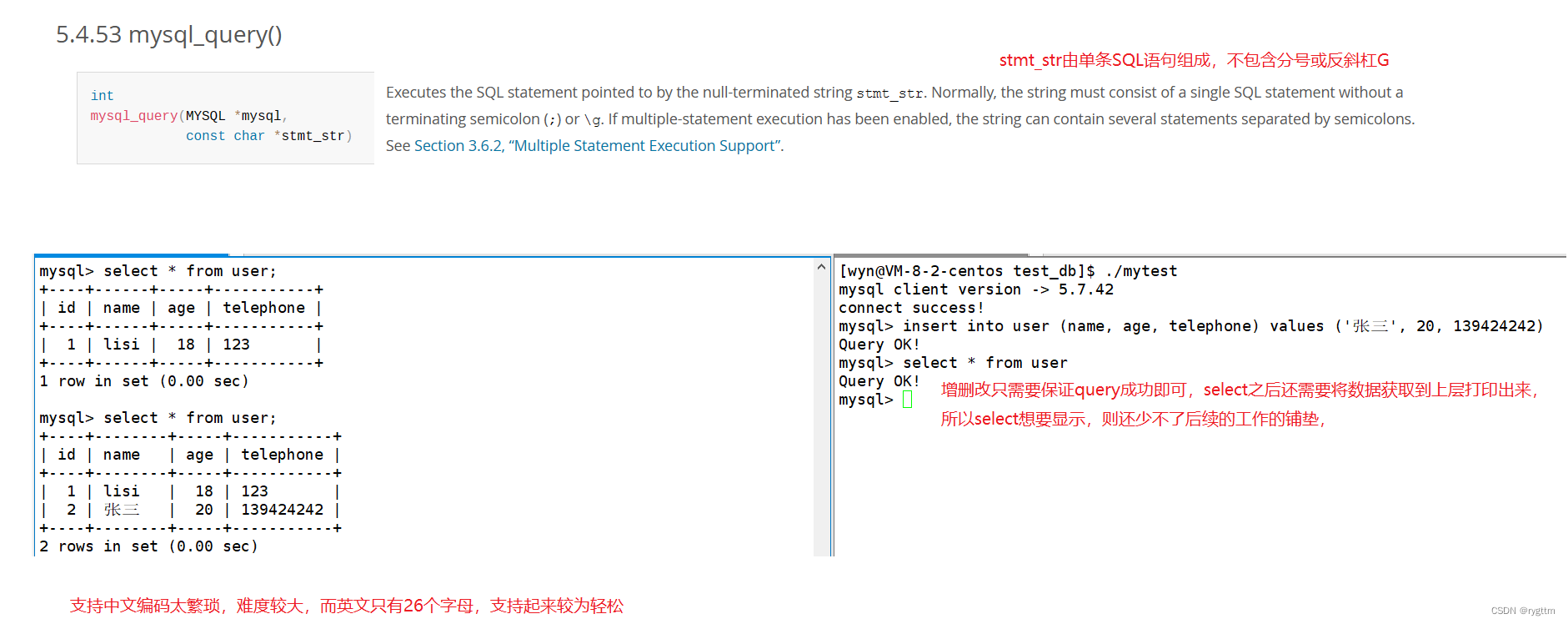

下面我们来实现当下发的语句为查询语句时,如何打印出查询sql的返回结果。
mysql_store_result会将语句的执行结果放到res里面,我们只需要将信息从res提取出来并打印到显示器上即可,mysql_num_rows用于获取结果集的行数,mysql_nums_fields用于获取结果集的列数,mysql_fetch_fields用于获取列名是什么,返回的指针会指向一个一维数组,一维数组中的内容就是各个列字段的名称。mysql_fetch_row获取结果集中的内容,连续调用mysql_fetch_row,他会像迭代器一样,自动帮我们跳转到下一行,并将下一行的地址返回到line里面,所以我们依次打印出每行的内容即可。
mysql_fetch_field用起来不如mysql_fetch_fields方便,后者直接返回一个一维数组即可,我们遍历这个数组将数组的内容输出即可,这样比较方便。
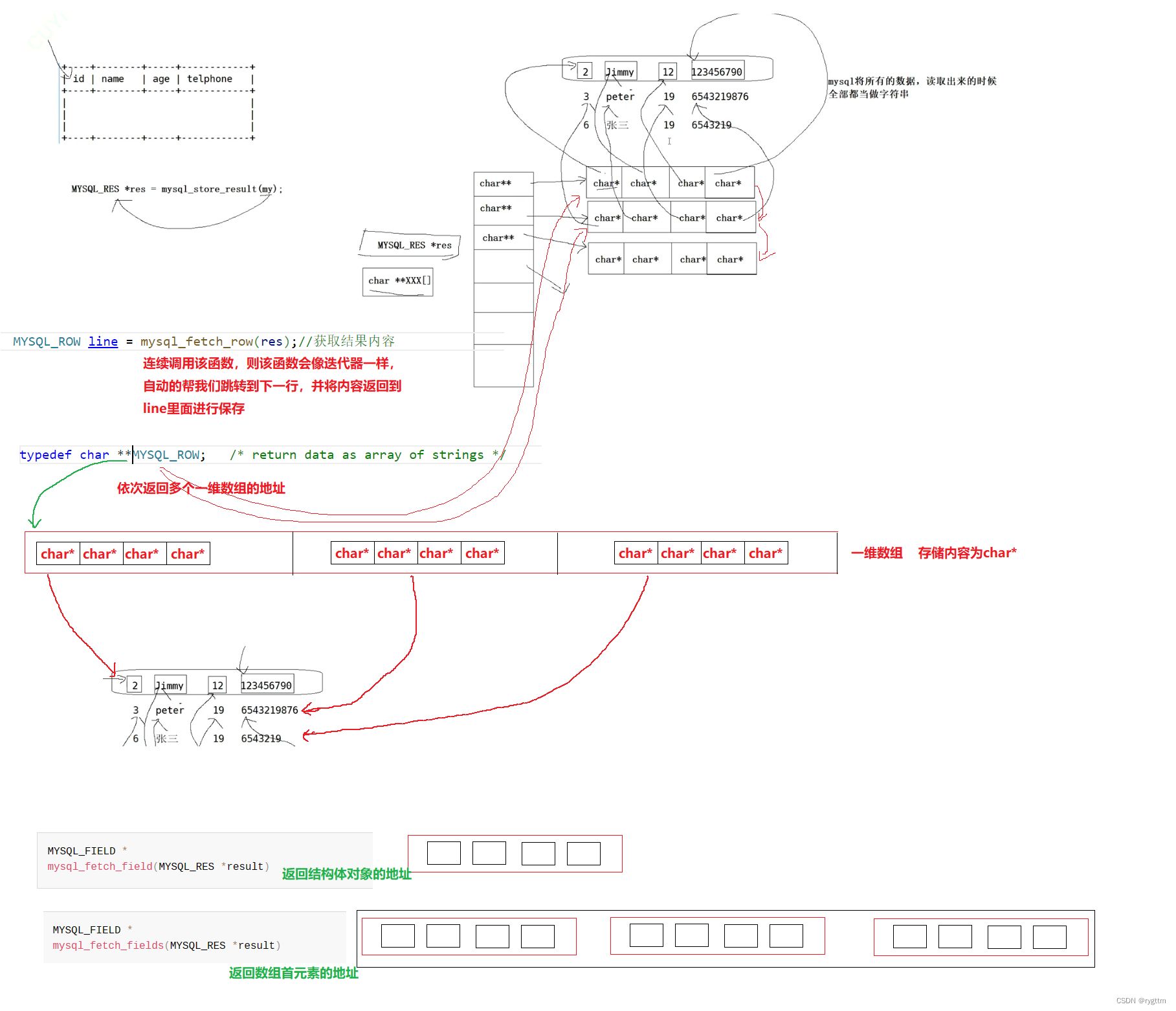
下面是具体的代码实现,别忘了关闭mysql链接和释放掉结果集res,res是动态申请的,所以也要释放。


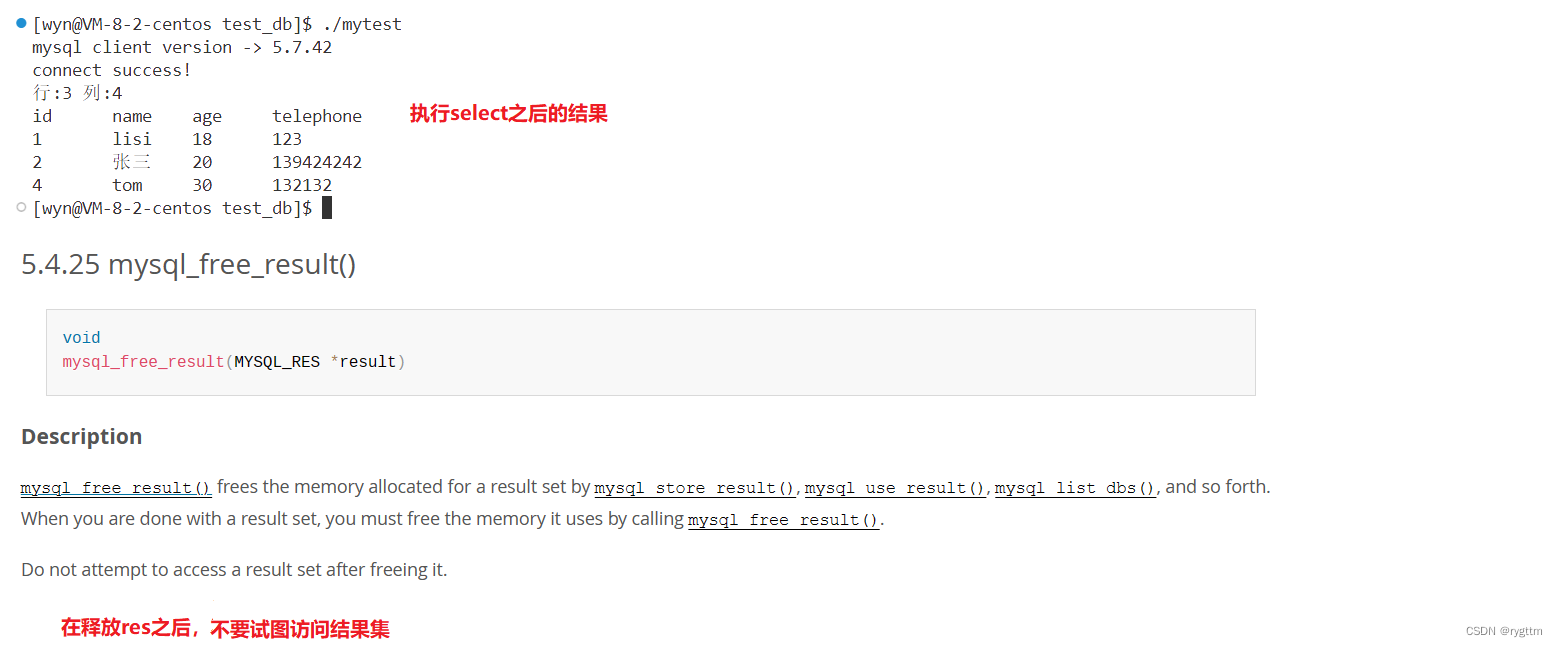
下面是执行查询语句后的结果
3.
MySQL Workbench用起来只能说还凑合,感觉还是不如直接敲命令行爽,不过我们实际工作当中肯定用的都是图形化界面来访问数据库服务。使用的成本也比较低,大家可以自己下载一个玩一玩

相关文章:
【MySQL】MySQL索引、事务、用户管理
20岁的男生穷困潦倒,20岁的女生风华正茂,没有人会一直风华正茂,也没有人会一直穷困潦倒… 文章目录 一、MySQL索引特性(重点)1.磁盘、OS、MySQL,在进行数据IO时三者的关系2.索引的理解3.聚簇索引࿰…...

函数重载与引用
文章目录 一、函数重载1. 重载规则2.重载列子3.函数名修饰规则 二、引用1.本质2.特性1. 引用必须在定义时初始化2 . 一个变量可以有多个引用3 . 引用一旦引用一个实体,就不能引用其他实体 3.引用例子4.引用的权限5.效率比较6.指针跟引用的区别 一、函数重载 函数重…...
如何快速模拟一个后端 API
第一步:创建一个文件夹,用来存储你的数据 数据: {"todos": [{ "id": 1, "text": "学习html44", "done": false },{ "id": 2, "text": "学习css", "…...
DLA :pytorch添加算子
pytorch的C extension写法 这部分主要介绍如何在pytorch中添加自定义的算子,需要以下cuda基础。就总体的逻辑来说正向传播需要输入数据,反向传播需要输入数据和上一层的梯度,然后分别实现这两个kernel,将这两个kernerl绑定到pytorch即可。 a…...
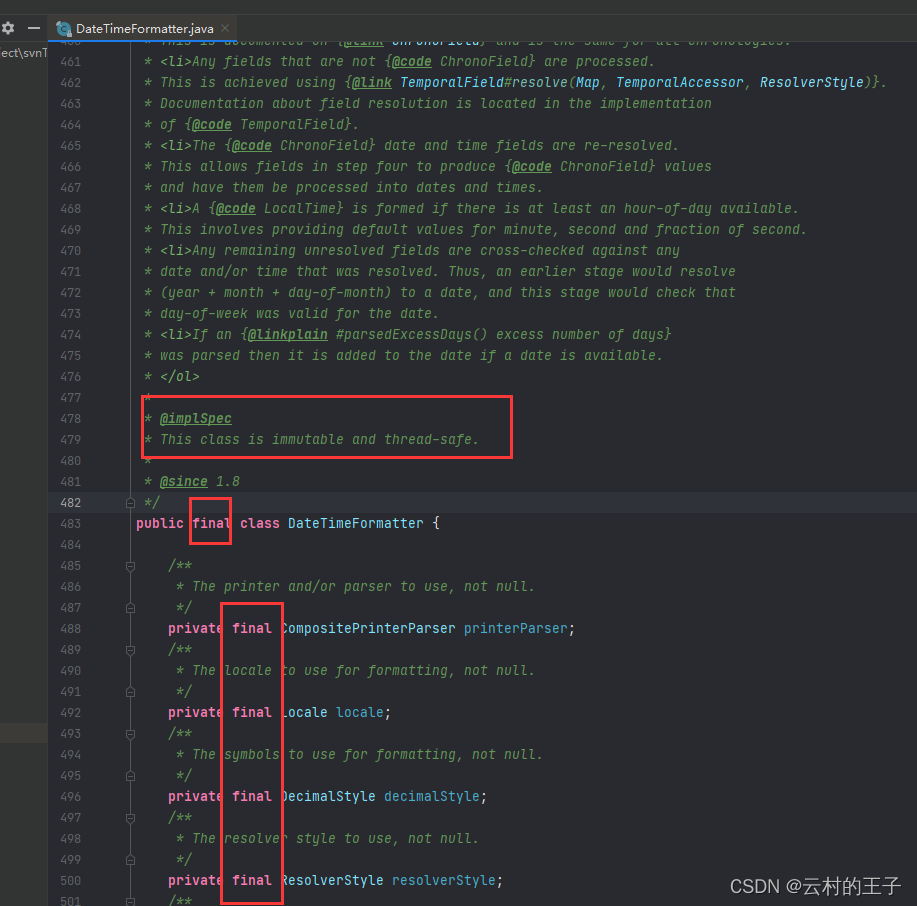
Java特殊时间格式转化
平常开发过程当中,我们可能会见到有的日期格式是这样的。 1、2022-12-21T12:20:1608:00 2、2022-12-21T12:20:16.0000800 3、2022-12-21T12:20:16.00008:00下面来说一下这种时间格式怎么转换 第一种:2022-12-21T12:20:1608:00 代码如下: p…...

在CSDN学Golang云原生(Kubernetes声明式资源管理Kustomize)
一,生成资源 在 Kubernetes 中,我们可以通过 YAML 或 JSON 文件来定义和创建各种资源对象,例如 Pod、Service、Deployment 等。下面是一个简单的 YAML 文件示例,用于创建一个 Nginx Pod: apiVersion: v1 kind: Pod m…...

后台管理系统中常见的三栏布局总结:使用element ui构建
vue2 使用 el-menu构建的列表布局: 列表可以折叠展开 <template><div class"home"><header><el-button type"primary" click"handleClick">切换</el-button></header><div class"conte…...
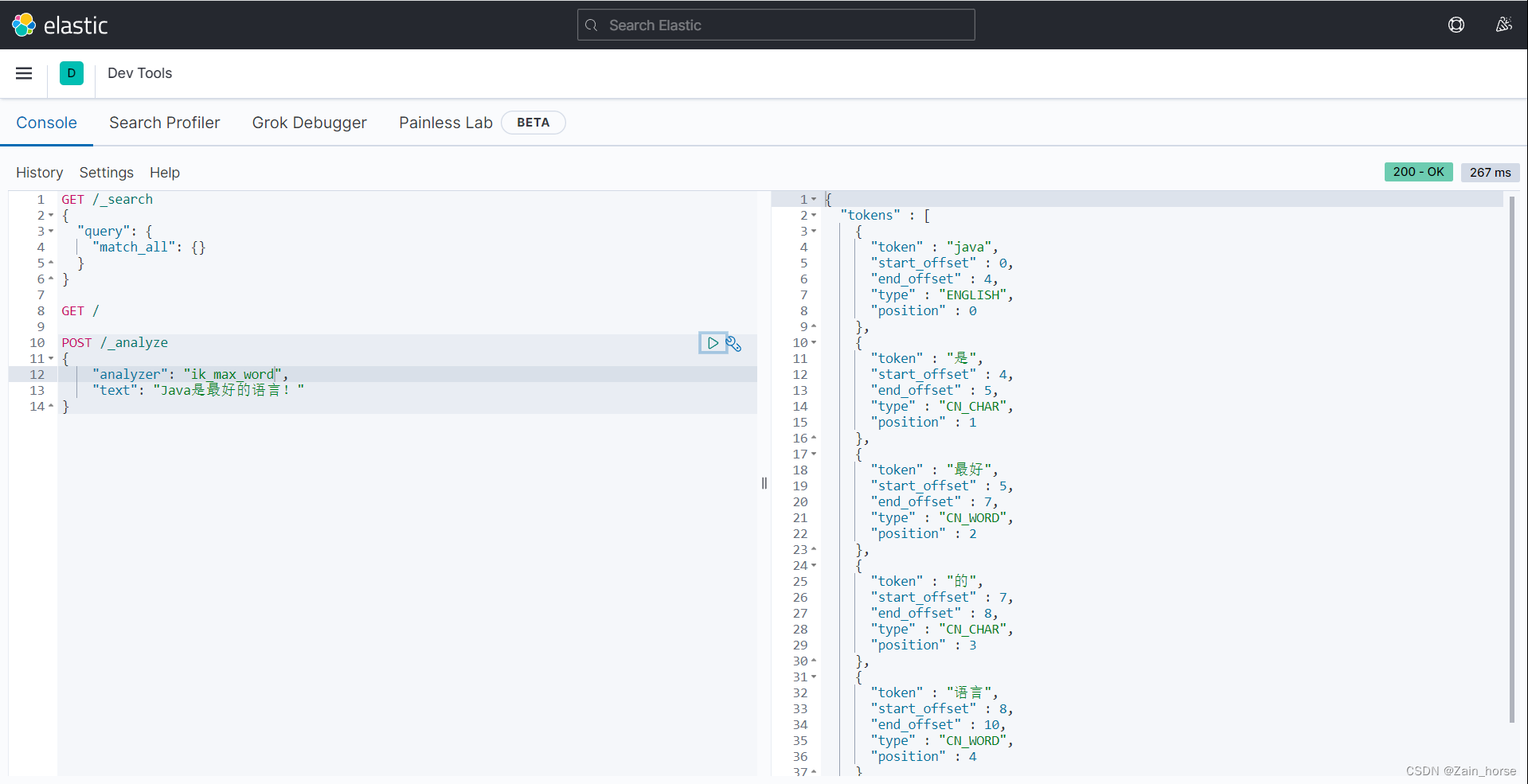
SpringCloud学习路线(10)——分布式搜索ElasticSeach基础
一、初识ES (一)概念: ES是一款开源搜索引擎,结合数据可视化【Kibana】、数据抓取【Logstash、Beats】共同集成为ELK(Elastic Stack),ELK被广泛应用于日志数据分析和实时监控等领域࿰…...

CSS翻转DIV展示顺序
项目国际化开发中,阿拉伯语是从右往左读的,在做样式兼容时,一些表单代码块也需要 label在右,表单在左。如果整个项目改div的话代价太大了,所以需要做样式翻转。 html <div class"container"><div …...

python 源码中 PyId_stdout 如何定义的
python 源代码中遇到一个变量名 PyId_stdout,搜不到在哪里定义的,如下只能搜到引用的位置(python3.8.10): 找了半天发现是用宏来构造的声明语句: // filepath: Include/cpython/object.h typedef struct …...

Mybatis映射关系mybatis核心配置文件
目录 1.Mybatis映射关系 1.1一对一映射之resultType 1.2resultMap处理映射关系 2.mybatis核心配置文件 1. properties(属性) 2. settings(设置) 3.typeAliases(类型别名) 4.environments࿰…...

Mybatis中limit用法与分页查询
错误示范 错误示范一: <select id"fileInspectionList" resultType"map">SELECT <include refid"aip_n_static_cols"/>FROM sys_inspection_form WHERE<if test" type admin.toString() ">dept_id …...
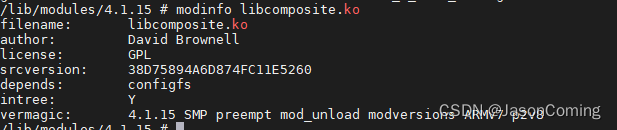
libcomposite: Unknown symbol config_group_init (err 0)
加载libcomposite.ko 失败 问题描述 如图,在做USB OTG 设备模式的时候需要用到libcomposite.ko驱动,加载失败了。 原因&解决方法 有一个依赖叫configfs.ko的驱动没有安装。可以从内核代码的fs/configfs/configfs.ko中找到这个驱动。先加载confi…...
Spring Tool Suite 4
参考:Spring tool suite4 安装及配置_springtoolsuite4_猿界零零七的博客-CSDN博客 下载:Spring | Tools 将下载的JAR进行解压两次,直至解压出contents中的sts 双击启动 第一次打开需要指定工作区文件夹 配置Maven的config 安装插件...

带你读论文第三期:微软研究员、北大博士陈琪,荣获NeurIPS杰出论文奖
Datawhale干货 来源:WhalePaper,负责人:芙蕖 WhalePaper简介 由Datawhale团队成员发起,对目前学术论文中比较成熟的 Topic 和开源方案进行分享,通过一起阅读、分享论文学习的方式帮助大家更好地“高效全面自律”学习&…...

农业中的计算机视觉 2023
物体检测应用于检测田间收割机和果园苹果 一、说明 欢迎来到Voxel51的计算机视觉行业聚焦博客系列的第一期。每个月,我们都将重点介绍不同行业(从建筑到气候技术,从零售到机器人等)如何使用计算机视觉、机器学习和人工智能来推动…...

掌握三个基础平面构成法则 优漫动游
1.图形重复:通过重复使用同一种或类似的图形元素,创造出一种有节奏、有重复感的视觉效果。这种设计手法可以使海报看起来更加统一和协调,增强视觉冲击力。 掌握三个基础平面构成法则 2.字体重复:通过重复使用同一种或类似的字体元素,创造出一种有序…...
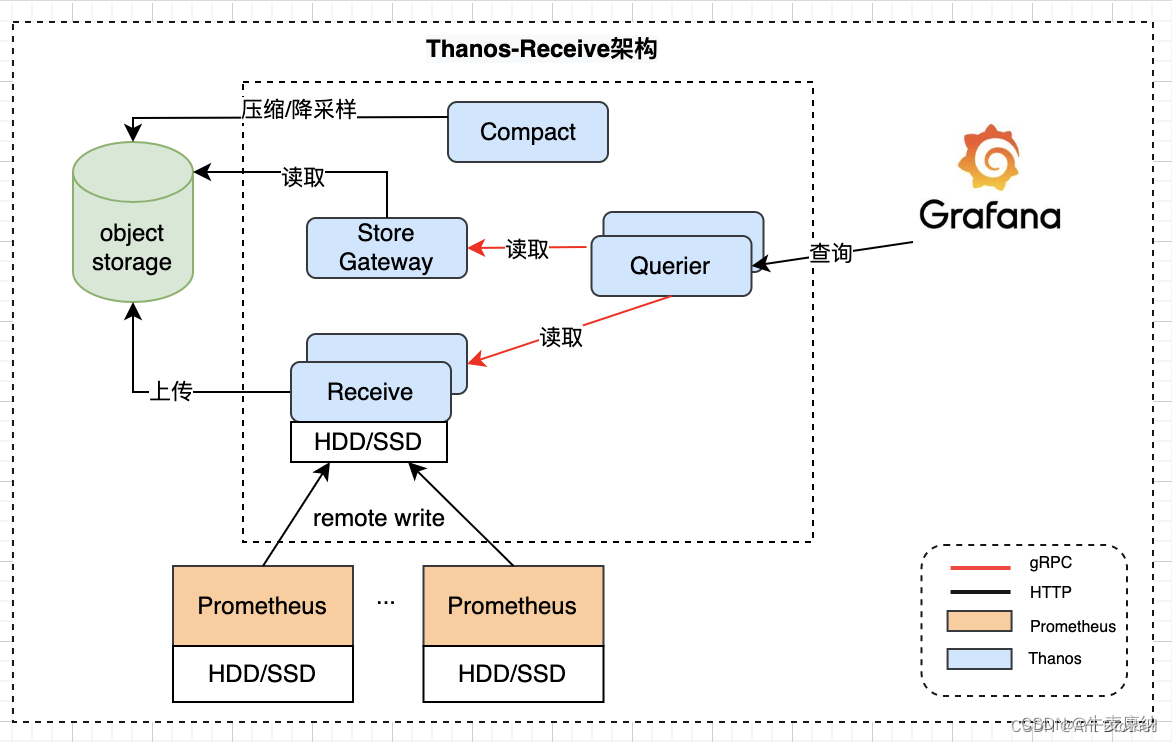
叶工好容5-日志与监控
目录 前言 平台维度 docker运行状态 cAdvisor-日志采集者 Heapster-日志收集 metrics-server-出生决定成败 kube-state-metrics-不完美中的完美 应用维度 日志 部署方式 输出方式 工具选择 日志接入 监控 serviceMonitor Annotation Prometheus扩展性 Thanos …...
Dubbo 指定调用固定ip+port dubbo调用指定服务 dubbo调用不随机 dubbo自定义调用服务 dubbo点对点通信 dubbo指定ip
1. 在写分布式im时nami-im: 分布式im, 集群 zookeeper netty kafka nacos rpc主要为gate(长连接服务) logic (业务) lsb (负载均衡)store(存储) - Gitee.com,需要指定某一…...

BCNet论文精读
Title—标题 Boundary Constraint Network(边界约束网络) With Cross Layer Feature Integration(跨层特征融合) for Polyp Segmentation(息肉分割) 结构分析 标题结构由三部分组成,分别是本文…...

从怀疑到真香!2026我日常办公离不开的这款在线文字转换器太好用了
刚入职那半年我踩过太多坑:一周三次新人培训,怕漏记知识点全程录音,下课手动整理1小时录音要熬3小时,知识点散得根本没法复习;部门周会做完记录,散会就要我出整理好的纪要,赶工赶得饭都吃不上&a…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...

SkillVLA:通过技能复用应对双-臂操纵中的组合多样性
26年3月来自新加坡国立、北京中关村学院、上海创新研究院、上海AI实验室、上海交大和复旦的论文“SkillVLA: Tackling Combinatorial Diversity in Dual-Arm Manipulation via Skill Reuse”。 视觉-语言-动作(VLA)模型近期取得的进展,已充分…...

航空航天为什么离不开高强镁合金?国产替代到哪一步了
飞机每减重一千克,全年大约节省四千两百美元的燃油费用——这是航空工程师熟悉的经验值。在商业航空领域,这个数字还只是财务账;在战斗机、导弹和卫星的世界里,减重的收益被换算成更远的航程、更大的载荷、更高的机动性࿰…...

Taotoken平台快速获取APIKey并开始你的第一个Python调用示例
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken平台快速获取APIKey并开始你的第一个Python调用示例 1. 准备工作:注册与登录 要开始使用Taotoken,…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能
SMUDebugTool终极指南:如何深度掌控AMD Ryzen处理器的隐藏性能 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: ht…...

HarmonyOS 6学习:解决图片放大后无法移动至边缘的matrix4矩阵变换技巧
从"卡在中间"到"自由拖拽":一次完整的图片缩放平移边界问题攻关在HarmonyOS 6应用开发中,我最近遇到了一个看似简单却让人头疼的图片查看器问题:用户双指放大图片后,想要拖动查看边缘细节,却发现图…...

别让依赖毁了你的实验:记一次Vision Mamba复现中causal_conv1d与mamba-ssm的版本“打架”事件
Vision Mamba复现实战:破解依赖冲突的工程化解决方案在深度学习项目的复现过程中,依赖管理往往是最容易被忽视却又最常导致问题的环节。最近在复现Vision Mamba模型时,我遭遇了一场典型的Python依赖"战争"——causal_conv1d与mamba…...