基于深度文档理解的开源 RAG 引擎RAGFlow的介绍和安装
目录
- 前言
- 1. RAGFlow 简介
- 1.1 什么是 RAGFlow?
- 1.2 RAGFlow 的核心特点
- 2. RAGFlow 的安装与配置
- 2.1 硬件与软件要求
- 2.2 下载 RAGFlow 源码
- 2.3 源码编译 Docker 镜像
- 2.4 设置完整版(包含 embedding 模型)
- 2.5 运行 RAGFlow
- 3. RAGFlow 的应用场景
- 3.1 企业知识管理
- 3.2 客服自动化
- 3.3 研究与学术辅助
- 4. 如何优化 RAGFlow 使用体验
- 4.1 选择合适的 LLM
- 4.2 数据预处理
- 4.3 调整超参数
- 结语
前言
在人工智能和自然语言处理(NLP)快速发展的今天,如何高效地利用海量文本数据成为了企业和个人关注的焦点。检索增强生成(Retrieval-Augmented Generation,简称 RAG)技术正是这一需求下的产物,它结合了信息检索与生成模型,使得大语言模型(LLM)能够在更真实、可控的上下文中提供高质量回答。RAGFlow 是一款开源的 RAG 引擎,专注于深度文档理解,能够处理各种复杂格式的数据,为用户提供精准、可验证的问答服务。本文将详细介绍 RAGFlow 的特点、安装方法以及如何高效利用其功能。
1. RAGFlow 简介
1.1 什么是 RAGFlow?
RAGFlow 是一款基于深度文档理解构建的开源 RAG 引擎。它提供了一套简洁高效的工作流程,使企业和个人用户能够轻松接入 RAG 技术,借助大语言模型处理多种复杂格式的数据。
RAGFlow 的核心目标是通过高效的检索与增强生成(RAG)机制,为用户提供精准的问答结果,同时附带可验证的引用信息,确保生成内容的可信度。github地址为
https://github.com/infiniflow/ragflow/blob/main/README_zh.md
1.2 RAGFlow 的核心特点
- 深度文档理解:支持多种文档格式(如 PDF、Word、Markdown、纯文本等),并能准确提取关键信息。
- 轻量化 RAG 方案:提供简洁的 RAG 流程,降低使用门槛,让用户能够快速上手。
- 可验证的引用:生成的答案不仅具有上下文一致性,还附带清晰的引用来源,提升可信度。
- 灵活的架构:支持外部大语言模型(LLM)与 embedding 服务,用户可根据需求选择不同的 AI 模型。
- 开源可定制:提供完整的源码,支持用户根据自身业务需求进行定制化开发。
2. RAGFlow 的安装与配置
为了使用 RAGFlow,我们首先需要满足一定的前提条件,并完成相应的安装步骤。
2.1 硬件与软件要求
在安装 RAGFlow 之前,建议确保您的系统满足以下最低配置要求:
- CPU:至少 4 核
- 内存(RAM):至少 16GB
- 磁盘空间:至少 50GB
- Docker 版本:>= 24.0.0
- Docker Compose 版本:>= v2.26.1
由于 RAGFlow 依赖于 Docker 进行部署,因此请确保您的系统已经安装了 Docker。如果尚未安装,可以参考官方文档 Install Docker Engine 进行安装。
2.2 下载 RAGFlow 源码
RAGFlow 的源码托管在 GitHub 上,用户可以使用 git 命令进行克隆:
git clone https://github.com/infiniflow/ragflow.git
cd ragflow/
下载完成后,便可以选择不同的方式编译 Docker 镜像。
2.3 源码编译 Docker 镜像
RAGFlow 提供了两种 Docker 镜像构建方式:
轻量版(不包含 embedding 模型)
此版本 Docker 镜像大小约 2GB,依赖外部的大模型和 embedding 服务。适用于希望减少存储占用并使用自定义 embedding 服务的用户。
完整版(包含 embedding 模型)
此版本 Docker 镜像大小约 9GB,已包含 embedding 模型,因此仅需依赖外部的大模型服务。
2.4 设置完整版(包含 embedding 模型)
修改docker目录下的.env文件,注释掉第84行的 RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.0-slim,并将87行的完整版打开RAGFLOW_IMAGE=infiniflow/ragflow:v0.17.0。这就是完整版(包含 embedding 模型)的镜像。

2.5 运行 RAGFlow
完成 Docker 镜像构建后,可以使用以下命令启动 RAGFlow 服务:
cd ragflow/docker
docker compose -f docker-compose.yml up -d
此命令将在后台运行 RAGFlow 服务,并自动管理所需的容器。

3. RAGFlow 的应用场景
3.1 企业知识管理
企业内部通常积累了大量的文档、合同、技术手册等,如何快速检索和利用这些信息是企业管理中的重要挑战。RAGFlow 可以帮助企业构建智能知识库,使员工能够通过自然语言查询快速获取关键信息,提高工作效率。
3.2 客服自动化
在客服领域,RAGFlow 可以结合 FAQ 数据库与实时文档,提供高质量的自动化客户支持,减少人工客服的压力,同时提升用户体验。
3.3 研究与学术辅助
对于研究人员和学生而言,RAGFlow 可以用来快速检索学术论文、技术文档,并提供智能摘要和参考信息,大大提高学习和研究的效率。
4. 如何优化 RAGFlow 使用体验
4.1 选择合适的 LLM
不同的 LLM 在处理不同任务时表现有所不同。用户可以根据需求选择适合的 LLM(如 OpenAI GPT-4、Anthropic Claude、Meta Llama),以获得最佳性能。
4.2 数据预处理
为了提高 RAGFlow 的检索与生成效果,建议在数据导入前进行预处理。例如:
- 统一文档格式,去除冗余信息
- 对长文本进行分段,提高检索效率
- 结合领域特定的 embedding 模型,优化语义搜索
4.3 调整超参数
RAGFlow 允许用户调整多个超参数(如检索数量、回答长度、引用来源权重等),可以根据实际需求进行优化,提升问答的精准度和可信度。
结语
RAGFlow 作为一款开源 RAG 引擎,为企业和个人提供了强大的检索增强生成能力。无论是在企业知识管理、自动化客服,还是学术研究等领域,RAGFlow 都展现出了广阔的应用前景。通过合理的安装部署、优化配置以及合适的数据处理方法,用户可以最大化发挥 RAGFlow 的潜力,实现更加智能、高效的信息检索与问答体验。
相关文章:
基于深度文档理解的开源 RAG 引擎RAGFlow的介绍和安装
目录 前言1. RAGFlow 简介1.1 什么是 RAGFlow?1.2 RAGFlow 的核心特点 2. RAGFlow 的安装与配置2.1 硬件与软件要求2.2 下载 RAGFlow 源码2.3 源码编译 Docker 镜像2.4 设置完整版(包含 embedding 模型)2.5 运行 RAGFlow 3. RAGFlow 的应用场…...

TinyWebServer项目笔记——02 半同步半反应堆线程池
目录 1.基础知识 (1)服务器编程基本框架 (2)五种I/O模型 (3)事件处理模式 (4)并发编程模式 (5)半同步/半反应堆 (6)线程池 &a…...

【技术干货】三大常见网络攻击类型详解:DDoS/XSS/中间人攻击,原理、危害及防御方案
1. DDoS攻击 1.1 什么是DDoS攻击? DDoS(Distributed Denial of Service,分布式拒绝服务攻击)通过操控大量“僵尸设备”(Botnet)向目标服务器发送海量请求,耗尽服务器资源(带宽、CPU…...

用Deepseek写一个五子棋微信小程序
在当今快节奏的生活中,休闲小游戏成为了许多人放松心情的好选择。五子棋作为一款经典的策略游戏,不仅规则简单,还能锻炼思维。最近,我借助 DeepSeek 的帮助,开发了一款五子棋微信小程序。在这篇文章中,我将…...

MWC 2025 | 紫光展锐与中国联通联合发布5G eSIM 平板
2025 年 3 月 3 日至 6 日,在全球移动通信行业的年度盛会 —— 世界移动通信大会(MWC 2025)上,紫光展锐联合中国联通重磅发布了支持eSIM的5G平板VN300E。 该产品采用紫光展锐T9100高性能5G SoC芯片平台,内置8 TOPS算力…...
)
跟着 Lua 5.1 官方参考文档学习 Lua (12)
文章目录 5.7 – Input and Output Facilities补充内容io.input ([file])io.read ()io.write ()io.output ([file])io.lines ([filename])io.flush ()io.close ([file])io.open (filename [, mode])io.popen (prog [, mode])io.tmpfile ()io.type (ob)file:read ()file:lines (…...

操作系统控制台-健康守护我们的系统
引言基本准备体验功能健康守护系统诊断 收获提升结语 引言 阿里云操作系统控制平台作为新一代云端服务器中枢平台,通过创新交互模式重构主机管理体验。操作系统控制台提供了一系列管理功能,包括运维监控、智能助手、扩展插件管理以及订阅服务等。用户可以…...

FreeRTOS任务状态查询
一.任务相关API vTaskList(),创建一个表格描述每个任务的详细信息 char biaoge[1000]; //定义一个缓存 vTaskList(biaoge); //将表格存到这缓存中 printf("%s /r/n",biaoge); 1.uxTaskPriorityGet(…...

blender学习25.3.6
【02-基础篇】Blender小凳子之凳面及凳脚的创作_哔哩哔哩_bilibili 【03-基础篇】Blender小凳子之其他细节调整优化_哔哩哔哩_bilibili 这篇文章写的全,不用自己写了 Blender 学习笔记(一)快捷键记录_blender4.1快捷键-CSDN博客 shifta&a…...

Tensorflow 2.0 GPU的使用与限制使用率及虚拟多GPU
Tensorflow 2.0 GPU的使用与限制使用率及虚拟多GPU 1. 获得当前主机上特定运算设备的列表2. 设置当前程序可见的设备范围3. 显存的使用4. 单GPU模拟多GPU环境 先插入一行简单代码,以下复制即可用来设置GPU使用率: import tensorflow as tf import numpy…...

RabbitMQ 2025/3/5
高性能异步通信组件。 同步调用 以支付为例: 可见容易发生雪崩。 异步调用 以支付为例: 支付服务当甩手掌柜了,不管后面的几个服务的结果。只管库库发,后面那几个服务想取的时候就取,因为消息代理里可以一直装&#x…...

每日一题-----面试
一、什么是孤儿进程?什么是僵尸进程? 1.孤儿进程是指父进程在子进程结束之前就已经退出,导致子进程失去了父进程的管理和控制,成为了 “孤儿”。此时,这些子进程会被系统的 init 进程(在 Linux 系统中&…...

JSP+Servlet实现对数据库增删改查功能
前提概要 需要理解的重要概念 MVC模式: Model(person类):数据模型View(JSP):显示界面Controller(Servlet):处理业务逻辑 请求流程: 浏览器 …...

C++【类和对象】
类和对象 1.this 指针2.类的默认成员函数3.构造函数4.析构函数5.拷贝构造函数 1.this 指针 接上文 this指针存在内存的栈区域。 2.类的默认成员函数 定义:编译器自动生成的成员函数。一个类,我们不写的情况下会默认生成六个成员函数。 3.构造函数 函…...

GStreamer —— 2.13、Windows下Qt加载GStreamer库后运行 - “教程13:播放控制“(附:完整源码)
运行效果(音频) 简介 上一个教程演示了GStreamer工具。本教程介绍视频播放控制。快进、反向播放和慢动作都是技术 统称为 Trick Modes,它们都有一个共同点 修改 Normal playback rate。本教程介绍如何实现 这些效果并在交易中添加了帧步进。特别是,它 显…...

MongoDB winx64 msi包安装详细教程
首先我们可以从官网上选择对应版本和对应的包类型进行安装: 下载地址:Download MongoDB Community Server | MongoDB 这里可以根据自己的需求, 这里我选择的是8.0.5 msi的版本,采用的传统装软件的方式安装。无需配置命令。 下载…...

要查看 SQLite 数据库中的所有表,可以通过查询 SQLite 的系统表 sqlite_master
要查看 SQLite 数据库中的所有表,可以查询 SQLite 的系统表 sqlite_master。 每个 SQLite 数据库都包含一个名为 sqlite_master 的系统表。该表定义了数据库的模式,存储了数据库中所有表、索引、视图和触发器等对象的信息。 通过查询 sqlite_master&am…...

WinUI 3 支持的三种窗口 及 受限的窗口透明
我的目标 希望能够熟悉 WinUI 3 窗口的基本使用方式,了解可能出现的问题 。 WinUI 3 支持三种窗口模式,分别为:常规窗口模式、画中画模式、全屏模式。 窗口模式:常规 即我们最常见的普通窗口。 支持:显示最大化按钮…...

如何借助 ArcGIS Pro 高效统计基站 10km 范围内的村庄数量?
在当今数字化时代,地理信息系统(GIS)技术在各个领域都发挥着重要作用。 特别是在通信行业,对于基站周边覆盖范围内的地理信息分析,能够帮助我们更好地进行网络规划、资源分配以及市场分析等工作。 今天,就…...

Linux网络之数据链路层协议
目录 数据链路层 MAC地址与IP地址 数据帧 ARP协议 NAT技术 代理服务器 正向代理 反向代理 上期我们学习了网络层中的相关协议,为IP协议。IP协议通过报头中的目的IP地址告知了数据最终要传送的目的主机的IP地址,从而指引了数据在网络中的一步…...

如何使用 PyInstaller 打包 Python 脚本?一看就懂的完整教程!
PyInstaller 打包指令教程 1. 写在前面 通常,在用 Python 编写完一个脚本后,需要将它部署并集成到一个更大的项目中。常见的集成方式有以下几种: 使用 PyInstaller 打包。使用 Docker 打包。将 Python 嵌入到 C 代码中,并封装成…...

解锁DeepSpeek-R1大模型微调:从训练到部署,打造定制化AI会话系统
目录 1. 前言 2.大模型微调概念简述 2.1. 按学习范式分类 2.2. 按参数更新范围分类 2.3. 大模型微调框架简介 3. DeepSpeek R1大模型微调实战 3.1.LLaMA-Factory基础环境安装 3.1大模型下载 3.2. 大模型训练 3.3. 大模型部署 3.4. 微调大模型融合基于SpirngBootVue2…...
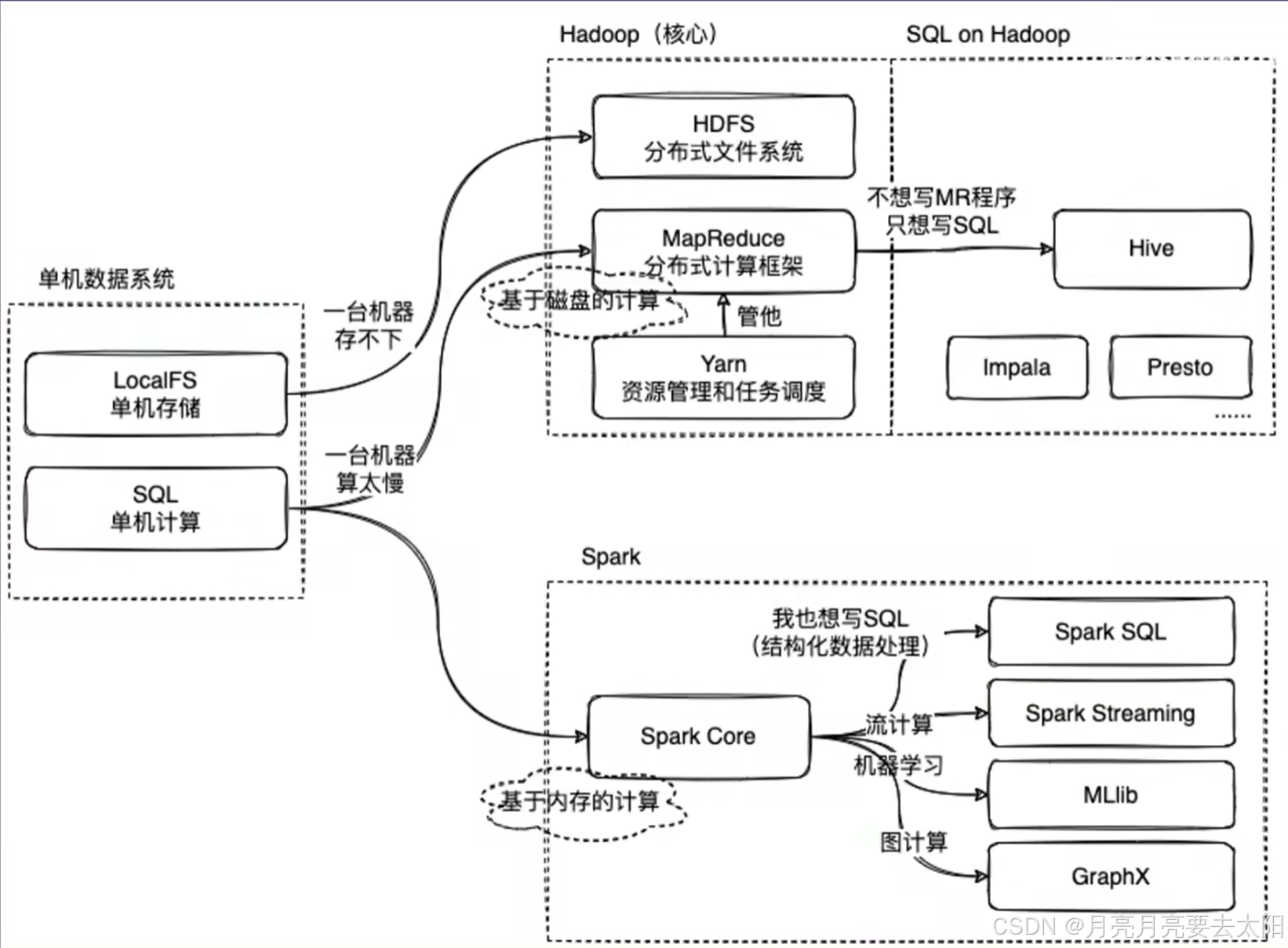
Hadoop、Hive、Spark的关系
Part1:Hadoop、Hive、Spark关系概览 1、MapReduce on Hadoop 和spark都是数据计算框架,一般认为spark的速度比MR快2-3倍。 2、mapreduce是数据计算的过程,map将一个任务分成多个小任务,reduce的部分将结果汇总之后返回。 3、HIv…...

基于VMware虚拟机的Ubuntu22.04系统安装和配置(新手保姆级教程)
文章目录 一、前期准备1. 硬件要求2. 软件下载2-1. 下载虚拟机运行软件 二、安装虚拟机三、创建 Ubuntu 系统虚拟机四、Ubuntu 系统安装过程的配置五、更换国内镜像源六、设置静态 IP七、安装常用软件1. 编译工具2. 代码管理工具3. 安装代码编辑软件(VIM)…...
)
Python|基于DeepSeek大模型,自动生成语料数据(10)
前言 本文是该专栏的第10篇,后面会持续分享AI大模型干货知识,记得关注。 在本专栏之前,笔者在文章《Python|基于DeepSeek大模型,实现文本内容仿写(8)》中,有详细介绍通过Python+DeepSeek大模型,实现对目标文本内容的仿写。 而在本文中,笔者将基于DeepSeek大模型,通…...

基于SpringBoot的历史馆藏系统设计与实现(源码+SQL脚本+LW+部署讲解等)
专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌。 技术范围:SpringBoot、Vue、SSM、HLMT、小程序、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:…...

蓝桥杯[每日两题] 真题:好数 神奇闹钟 (java版)
题目一:好数 题目描述 一个整数如果按从低位到高位的顺序,奇数位(个位、百位、万位 )上的数字是奇数,偶数位(十位、千位、十万位 )上的数字是偶数,我们就称之为“好数”。给定…...

基于BMO磁性细菌优化的WSN网络最优节点部署算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.本算法原理 5.完整程序 1.程序功能描述 无线传感器网络(Wireless Sensor Network, WSN)由大量分布式传感器节点组成,用于监测物理或环境状况。节点部署是 WSN 的关键问…...

学习笔记:Python网络编程初探之基本概念(一)
一、网络目的 让你设备上的数据和其他设备上进行共享,使用网络能够把多方链接在一起,然后可以进行数据传递。 网络编程就是,让在不同的电脑上的软件能够进行数据传递,即进程之间的通信。 二、IP地址的作用 用来标记唯一一台电脑…...

Laya中runtime的用法
文章目录 0、环境:2.x版本1、runtime是什么2、使用实例情景需要做 3、script组件模式 0、环境:2.x版本 1、runtime是什么 简单来说,如果创建了一个scene,加了runtime和没加runtime的区别就是: 没加runtimeÿ…...