LORA+llama模型微调全流程
LORA+llama.cpp模型微调全流程
准备阶段
1.下载基础大模型
新建一个download.py脚本
from modelscope import snapshot_download#模型存放路径
model_path = '/root/autodl-tmp'
#模型名字
name = 'itpossible/Chinese-Mistral-7B-Instruct-v0.1'
model_dir = snapshot_download(name, cache_dir=model_path, revision='master')
2.下载数据集
下载地址
HF-Mirror
首页 · 魔搭社区
3.搭建lora环境
创建requirements.txt文件
transformers==4.40.0
streamlit==1.24.0
sentencepiece==0.1.99
accelerate==0.29.3
datasets
peft==0.10.0
创建虚拟环境
//创建虚拟环境
python -m venv loar4venv// 激活虚拟环境
.\loar4venv\Scripts\activate// 安装依赖
pip install -r requirements.txt
4.搭建CUDA - 图形处理器开发环境
下载cuda版本为 11.8
CUDA Toolkit Archive | NVIDIA Developer
测试是否安装成功
nvcc --version
Cuda compilation tools, release 11.8, V11.8.89 #安装成功后回复
安装 PyTorch
版本分别为
torch == 2.0.1+cu118
torchaudio == 2.0.2+cu118
torchvision == 0.15.2+cu118
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
5.安装camke
官网地址:https://cmake.org/,点击Download。
6.下载llama.cpp源码
https://github.com/ggerganov/llama.cpp
下载解压缩后,形成第二个项目的文件,同样需要搭建环境, 安装requirements.txt的依赖
开始微调
1.运行训练脚本
创建Lora.py,复制以下代码
from datasets import Dataset
import pandas as pd
from transformers import (AutoTokenizer,AutoModelForCausalLM,DataCollatorForSeq2Seq,TrainingArguments,Trainer, )
import torch,os
from peft import LoraConfig, TaskType, get_peft_model
import warnings
warnings.filterwarnings("ignore", category=UserWarning) # 忽略告警device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("device="+device)# 模型文件路径
model_path = r'/root/autodl-tmp/itpossible/Chinese-Mistral-7B-Instruct-v0.1'
# 训练过程数据保存路径
name = 'ruozhiba'
output_dir = f'./output/Mistral-7B-song'
#是否从上次断点处接着训练
train_with_checkpoint = True# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token#加载数据集
df = pd.read_json(f'./dataset/ruozhiba_qa.json')
ds = Dataset.from_pandas(df)
print(ds)# 对数据集进行处理,需要将数据集的内容按大模型的对话格式进行处理
def process_func_mistral(example):MAX_LENGTH = 384 # Llama分词器会将一个中文字切分为多个token,因此需要放开一些最大长度,保证数据的完整性instruction = tokenizer(f"<s>[INST] <<SYS>>\n\n<</SYS>>\n\n{example['instruction']+example['input']}[/INST]",add_special_tokens=False) # add_special_tokens 不在开头加 special_tokensresponse = tokenizer(f"{example['output']}", add_special_tokens=False)input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为pad_token_id咱们也是要关注的所以 补充为1labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]if len(input_ids) > MAX_LENGTH: # 做一个截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}
inputs_id = ds.map(process_func_mistral, remove_columns=ds.column_names)#加载模型
model = AutoModelForCausalLM.from_pretrained(model_path, device_map=device, torch_dtype=torch.bfloat16, use_cache=False)
print(model)
model.enable_input_require_grads() # 开启梯度检查点时,要执行该方法
config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # 训练模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.1 # Dropout 比例
)model = get_peft_model(model, config)
model.print_trainable_parameters()
args = TrainingArguments(output_dir=output_dir,per_device_train_batch_size=2,gradient_accumulation_steps=2,logging_steps=20,num_train_epochs=2,save_steps=25,save_total_limit=2,learning_rate=1e-4,save_on_each_node=True,gradient_checkpointing=True
)
trainer = Trainer(model=model,args=args,train_dataset=inputs_id,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True)
)
# 如果训练中断了,还可以从上次中断保存的位置继续开始训练if train_with_checkpoint:checkpoints = [os.path.join(output_dir, file) for file in os.listdir(output_dir) if 'checkpoint' in file]if checkpoints:last_checkpoint = max(checkpoints, key=os.path.getctime) # 找到最新的检查点print(f"Resuming training from checkpoint: {last_checkpoint}")trainer.train(resume_from_checkpoint=last_checkpoint)else:print("No checkpoint found in the output directory. Starting training from scratch.")trainer.train()
else:trainer.train()
运行
python Lora.py
2.将检查点checkpoint转换为lora
新建一个checkpoint_to_lora.py,将训练的checkpoint保存为lora
#将checkpoint转换为lora
from transformers import AutoModelForSequenceClassification,AutoTokenizer
import os# 需要保存的lora路径
lora_path= "/root/lora/Mistral-7B-lora-song"
# 模型路径
model_path = '/root/autodl-tmp/itpossible/Chinese-Mistral-7B-Instruct-v0.1'
# 检查点路径
checkpoint_dir = './output/Mistral-7B-song'
checkpoint = [file for file in os.listdir(checkpoint_dir) if 'checkpoint-' in file][-1] #选择更新日期最新的检查点
print("checkpoint="+checkpoint)
model = AutoModelForSequenceClassification.from_pretrained(f'./output/Mistral-7B-song/{checkpoint}')
# 保存模型
model.save_pretrained(lora_path)
tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
# 保存tokenizer
tokenizer.save_pretrained(lora_path)
3.合并模型
新建一个merge.py文件,将基础模型和lora模型合并为一个新的模型文件
#合并模型
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModel
from peft import LoraConfig, TaskType, get_peft_modelmodel_path = '/root/autodl-tmp/itpossible/Chinese-Mistral-7B-Instruct-v0.1'
lora_path = "/root/lora/Mistral-7B-lora-song"
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("device="+device)
# 合并后的模型路径
output_path = r'/root/autodl-tmp/itpossible/merge'# 等于训练时的config参数
config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False, # 训练模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.1 # Dropout 比例
)base = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True)
base_tokenizer = AutoTokenizer.from_pretrained(model_path)
lora_model = PeftModel.from_pretrained(base,lora_path,torch_dtype=torch.float16,config=config
)
model = lora_model.merge_and_unload()
model.save_pretrained(output_path)
base_tokenizer.save_pretrained(output_path)
4.量化模型
转换模型文件需要在llamaCpp的环境下运行
需要将多个safetensors合并为一个bin
激活环境后运行convert.py
执行转换脚本
python convert.py /root/autodl-tmp/itpossible/merge --outtype f16 --outfile /root/autodl-tmp/itpossible/convert.bin
可以得到一个convert.bin文件,这之后merge文件就没用了
开始编译
# 进入到llm/llama.cpp目录
cd llm/llama.cpp#创建build文件夹
mkdir build#进入build
cd build# 构建
cmake ..
cmake --build . --config Release
编译成功后在llamaCpp\build\bin\Release生成llama-quantize.exe
量化模型
量化convert.bin
bin/Release/quantize.exe D:\root\autodl-tmp\itpossible\convert.bin D:\root\autodl-tmp\itpossible\quantized.bin q4_0官方文档提供了多种量化格式,常用的就是q4_0。
分块量化(Block-wise Quantization)
- q4_k_m:4位量化,中等优化级别。
- q4_k_s:4位量化,轻量化级别。
- q5_k_m:5位量化,中等优化级别。
- q5_k_s:5位量化,轻量化级别。
- q6_k:6位量化。
- q8_0:8位量化。
K-Quantization(混合精度量化)
- q2_k:2位量化,混合精度优化。
- q2_k_s:2位量化,轻量化版本。
- q3_k_m:3位量化,中等优化级别。
- q3_k_s:3位量化,轻量化版本。
- q3_k_l:3位量化,高优化级别。
其他量化格式
- q4_0:4位量化,朴素方法。
- q4_1:4位量化,改进型朴素方法。
- q5_0:5位量化,朴素方法。
- q5_1:5位量化,改进型朴素方法。
- f16:半精度浮点(16位)。
- bf16:脑浮点(16位)。
- f32:全精度浮点(32位)。
特殊量化格式
- iq2_xxs:2位量化,极小模型。
- iq2_xs:2位量化,较小模型。
- iq2_s:2位量化,标准模型。
- iq2_m:2位量化,中等模型。
- iq3_xxs:3位量化,极小模型。
- iq3_xs:3位量化,较小模型。
- iq3_s:3位量化,标准模型。
- iq3_m:3位量化,中等模型。
- iq4_nl:4位非线性量化。
- iq4_xs:4位量化,较小模型。
5.ollama使用模型
需要将quantized.bin文件制作为ollama可以使用的模型
创建Modelfile 文件
创建一个test.Modelfile 文件,添加的内容如下
FROM D:\huggingface\itpossible\quantized.bin
TEMPLATE "[INST] {{ .Prompt }} [/INST]"
创建模型
指定生成的模型路径
设置模型文件保存位置,打开系统环境变量配置,添加一个环境变量OLLAMA_MODELS=D:\huggingface\ollama(自己指定任意一个文件夹路径),然后点确定。
运行
//ollama create 模型名字 -f Modelfile文件路径
ollama create chinese_song_q4 -f C:\Users\Administrator\Desktop\ollama\test.Modelfile
生成的模型
相关文章:
LORA+llama模型微调全流程
LORAllama.cpp模型微调全流程 准备阶段 1.下载基础大模型 新建一个download.py脚本 from modelscope import snapshot_download#模型存放路径 model_path /root/autodl-tmp #模型名字 name itpossible/Chinese-Mistral-7B-Instruct-v0.1 model_dir snapshot_download(na…...

02_使用Docker在服务器上部署Jekins实现项目的自动化部署
02_使用Docker在服务器上部署jenkins实现项目的自动化部署 一、使用docker拉取阿里云容器私有镜像仓库内的jenkins镜像 登录阿里云Docker Registry $ sudo docker login --usernamewxxxo1xxx registry.cn-shanghai.aliyuncs.com用于登录的用户名为阿里云账号全名,…...
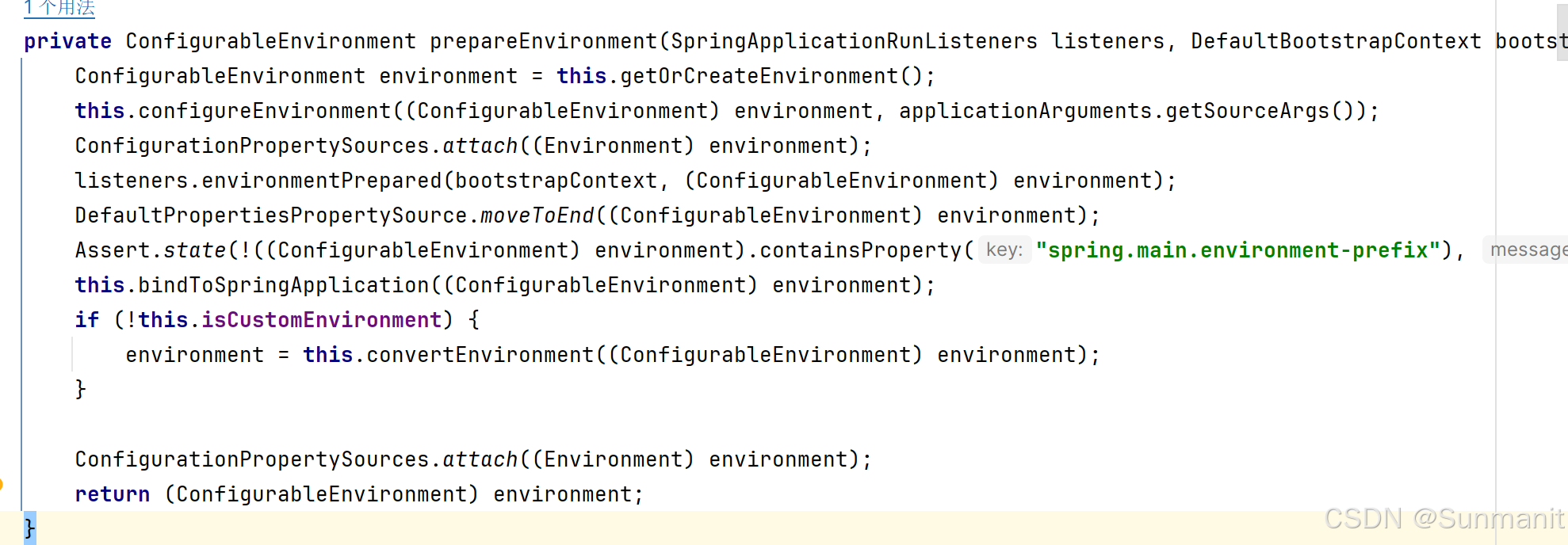
Spring 执行流程(源码)
我们对SpringApplication中的run()方法内部进行一些简单的分析 1. //记录一下程序启动开始的事件,用于之后的统计耗时 long startTime System.nanoTime(); //通过调用SpringApplication的**createBootstrapContext()**方法,创建**bootstrapContext**…...

Python学习之numpy
Python学习之numpy 数组是Numpy库的核心数据结构。 NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。 Numeric,即 NumPy 的前身,是由 Jim Hugunin 开发的。 也开发了另一个包 Numarr…...

安装完 miniconda3 ,cmd无法执行 conda 命令
提示:安装 miniconda3 文章目录 前言一、安装二、安装完,cmd 无法执行 conda 前言 提示:版本 系统:win10 codna: miniconda3 安装完 miniconda3 ,cmd无法执行 conda 命令 提示:以下是本篇文章正文内容&am…...
和自注意力(Self-Attention))
PyTorch 实现图像版多头注意力(Multi-Head Attention)和自注意力(Self-Attention)
本文提供一个适用于图像输入的多头注意力机制(Multi-Head Attention)PyTorch 实现,适用于 ViT、MAE 等视觉 Transformer 中的注意力计算。 模块说明 输入支持图像格式 (B, C, H, W)内部转换为序列 (B, N, C),其中 N H * W多头注…...

从 Credit Metrics 到 CPV:现代信用风险模型的进化与挑战
文章目录 一、信用风险基础二、Credit Risk 模型核心思想关键假设模型框架实施步骤优缺点适用场景 三、Credit Metrics 模型核心思想关键假设模型框架实施步骤优缺点适用场景 四、Credit Portfolio View 模型核心思想关键假设模型框架实施步骤优缺点适用场景 五、总结 一、信用…...
Docker快速安装MongoDB并配置主从同步
目录 一、创建相关目录及授权 二、下载并运行MongoDB容器 三、配置主从复制 四、客户端远程连接 五、验证主从同步 六、停止和恢复复制集 七、常用命令 一、创建相关目录及授权 创建主节点mongodb数据及日志目录并授权 mkdir -p /usr/local/mongodb/mongodb1/data mkdir …...

Kafka 中的事务
Kafka 中的 事务(Transactions) 是为了解决 消息处理的原子性和幂等性问题,确保一组消息要么全部成功写入、要么全部失败,不出现中间状态或重复写入。事务机制尤其适合于 “精确一次(Exactly-Once)” 的处理…...

C++ 内存访问模式优化:从架构到实践
内存架构概览:CPU 与内存的 “速度博弈” 层级结构:从寄存器到主存 CPU 堪称计算的 “大脑”,然而它与内存之间的速度差距,宛如高速公路与乡间小路。现代计算机借助多级内存体系来缓和这一矛盾,其核心思路是…...

Golang系列 - 内存对齐
Golang系列-内存对齐 常见类型header的size大小内存对齐空结构体类型参考 摘要: 本文将围绕内存对齐展开, 包括字符串、数组、切片等类型header的size大小、内存对齐、空结构体类型的对齐等等内容. 关键词: Golang, 内存对齐, 字符串, 数组, 切片 常见类型header的size大小 首…...

SOMEIP通信矩阵解读
目录 1 摘要2 SOME/IP通信矩阵详细属性定义与示例2.1 服务基础属性2.2 数据类型定义2.3 服务实例与网络配置参数2.4 SOME/IP-SD Multicast 配置(SOME/IP服务发现组播配置)2.5 SOME/IP-SD Unicast 配置2.6 SOME/IP-SD ECU 配置参数详解 3 总结 1 摘要 本…...

Excel + VBA 实现“准实时“数据的方法
Excel 本身是静态数据处理工具,但结合 VBA(Visual Basic for Applications) 可以实现 准实时数据更新,不过严格意义上的 实时数据(如毫秒级刷新)仍然受限。以下是详细分析: 1. Excel + VBA 实现“准实时”数据的方法 (1) 定时刷新(Timer 或 Application.OnTime) Appl…...

网络原理 - HTTP/HTTPS
1. HTTP 1.1 HTTP是什么? HTTP (全称为 “超文本传输协议”) 是⼀种应用非常广泛的应用层协议. HTTP发展史: HTTP 诞生于1991年. 目前已经发展为最主流使用的⼀种应用层协议 最新的 HTTP 3 版本也正在完善中, 目前 Google / Facebook 等公司的产品已经…...

C++设计模式-解释器模式:从基本介绍,内部原理、应用场景、使用方法,常见问题和解决方案进行深度解析
一、解释器模式的基本介绍 1.1 模式定义与核心思想 解释器模式(Interpreter Pattern)是一种行为型设计模式,其核心思想是为特定领域语言(DSL)定义语法规则,并构建一个解释器来解析和执行该语言的句子。它…...
OCC Shape 操作
#pragma once #include <iostream> #include <string> #include <filesystem> #include <TopoDS_Shape.hxx> #include <string>class GeometryIO { public:// 加载几何模型:支持 .brep, .step/.stp, .iges/.igsstatic TopoDS_Shape L…...

深度学习入门(四):误差反向传播法
文章目录 前言链式法则什么是链式法则链式法则和计算图 反向传播加法节点的反向传播乘法节点的反向传播苹果的例子 简单层的实现乘法层的实现加法层的实现 激活函数层的实现ReLu层Sigmoid层 Affine层/SoftMax层的实现Affine层Softmax层 误差反向传播的实现参考资料 前言 上一篇…...
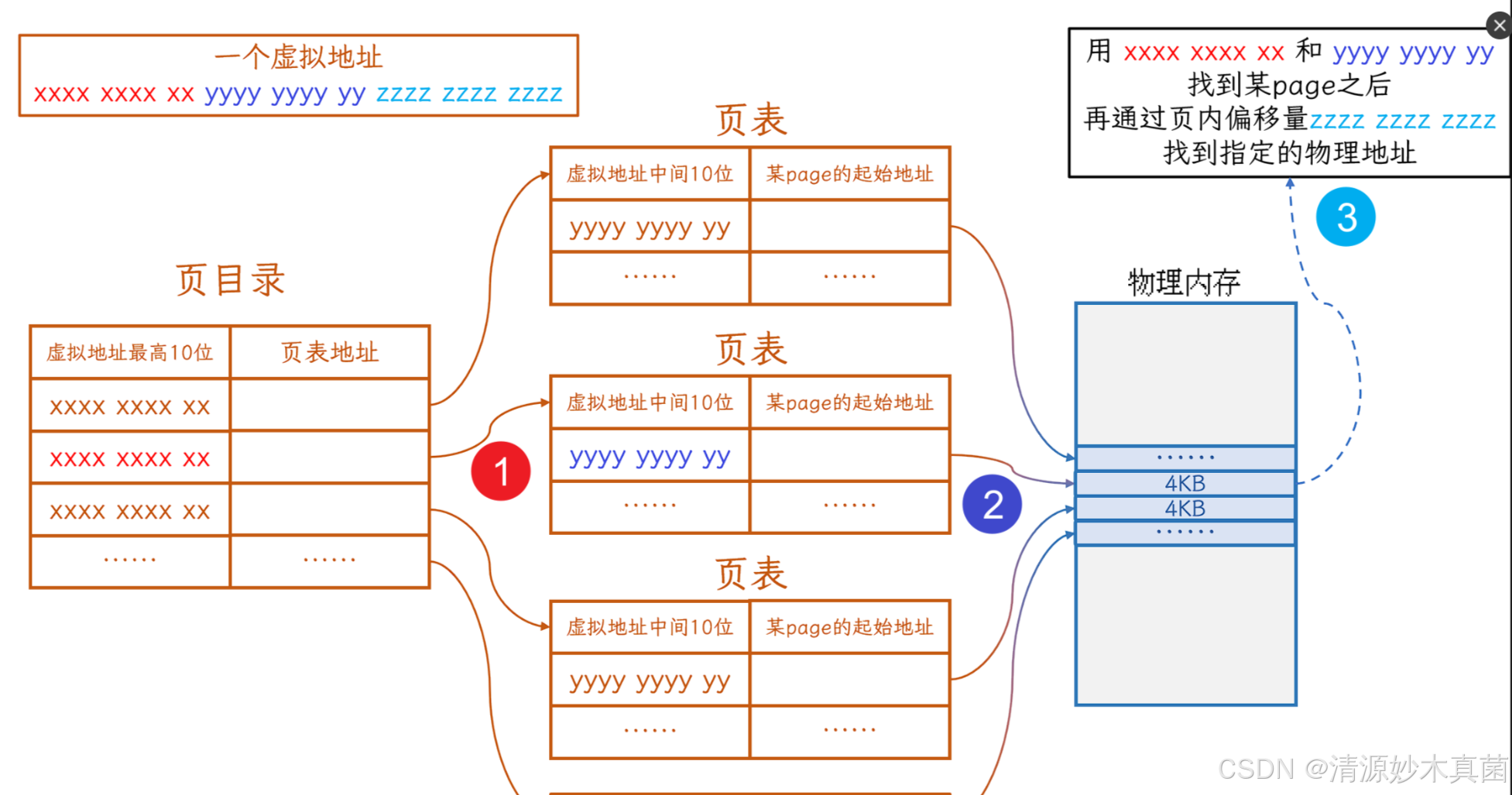
Linux:页表详解(虚拟地址到物理地址转换过程)
文章目录 前言一、分页式存储管理1.1 虚拟地址和页表的由来1.2 物理内存管理与页表的数据结构 二、 多级页表2.1 页表项2.2 多级页表的组成 总结 前言 在我们之前的学习中,我们对于页表的认识仅限于虚拟地址到物理地址转换的桥梁,然而对于具体的转换实现…...

AF3 OpenFoldDataLoader类解读
AlphaFold3 data_modules 模块的 OpenFoldDataLoader 类继承自 PyTorch 的 torch.utils.data.DataLoader。该类主要对原始 DataLoader 做了批数据增强与控制循环迭代次数(recycling)相关的处理。 源代码: class OpenFoldDataLoader(torch.utils.data.DataLoader):def __in…...

初见TypeScript
类型语言,在代码规模逐渐增大时,类型相关的错误难以排查。TypeScript 由微软开发,它本质上是 JavaScript 的超集,为 JavaScript 添加了静态类型系统,让开发者在编码阶段就能发现潜在类型错误,提升代码质量&…...

常见的 JavaScript 框架和库
在现代前端开发中,JavaScript框架和库成为了构建高效、可维护应用程序的关键工具。本文将介绍四个常见的JavaScript框架和库:React、Vue.js、Angular 和 Node.js,并探讨它们的特点、使用场景及适用场合。 1. React — 构建用户界面的JavaScri…...

机器学习代码基础——ML2 使用梯度下降的线性回归
ML2 使用梯度下降的线性回归 牛客网 描述 编写一个使用梯度下降执行线性回归的 Python 函数。该函数应将 NumPy 数组 X(具有一列截距的特征)和 y(目标)作为输入,以及学习率 alpha 和迭代次数,并返回一个…...
PostgreSQL 一文从安装到入门掌握基本应用开发能力!
本篇文章主要讲解 PostgreSQL 的安装及入门的基础开发能力,包括增删改查,建库建表等操作的说明。navcat 的日常管理方法等相关知识。 日期:2025年4月6日 作者:任聪聪 一、 PostgreSQL的介绍 特点:开源、免费、高性能、关系数据库、可靠性、稳定性。 官网地址:https://w…...
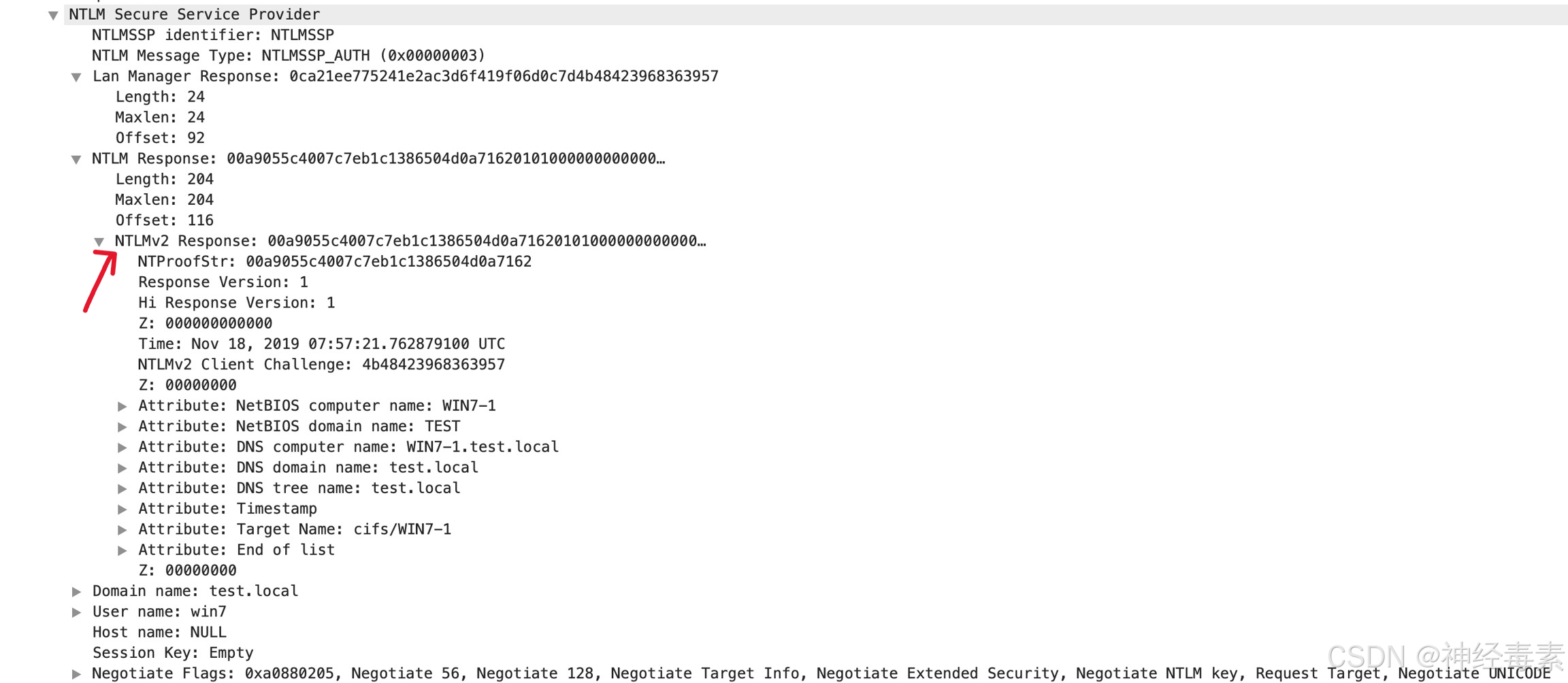
WEB安全--内网渗透--LMNTLM基础
一、前言 LM Hash和NTLM Hash是Windows系统中的两种加密算法,不过LM Hash加密算法存在缺陷,在Windows Vista 和 Windows Server 2008开始,默认情况下只存储NTLM Hash,LM Hash将不再存在。所以我们会着重分析NTLM Hash。 在我们内…...

查询条件与查询数据的ajax拼装
下面我将介绍如何使用 AJAX 动态拼装查询条件和获取查询数据,包括前端和后端的完整实现方案。 一、前端实现方案 1. 基础 HTML 结构 html 复制 <div class"query-container"><!-- 查询条件表单 --><form id"queryForm">…...
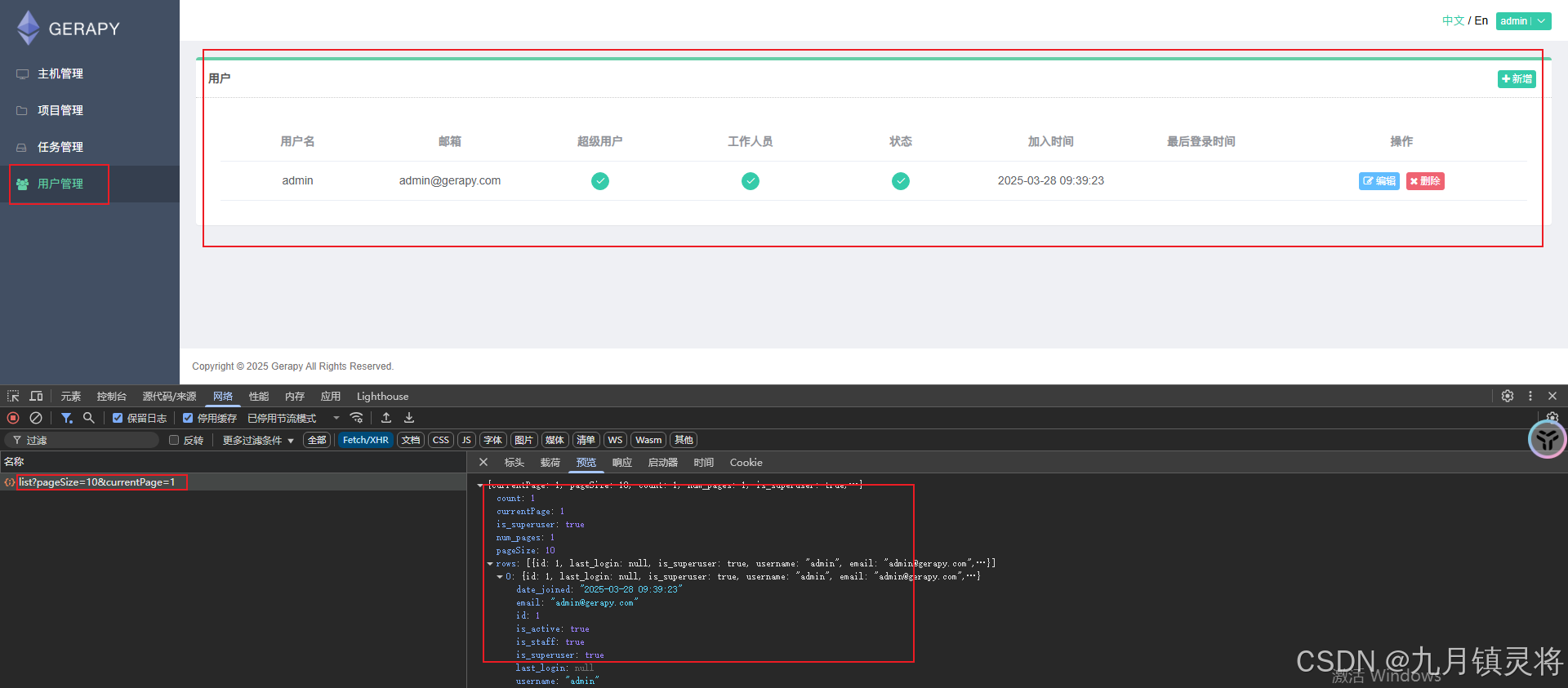
8.用户管理专栏主页面开发
用户管理专栏主页面开发 写在前面用户权限控制用户列表接口设计主页面开发前端account/Index.vuelangs/zh.jsstore.js 后端Paginator概述基本用法代码示例属性与方法 urls.pyviews.py 运行效果 总结 欢迎加入Gerapy二次开发教程专栏! 本专栏专为新手开发者精心策划了…...

室内指路机器人是否支持与第三方软件对接?
嘿,你知道吗?叁仟室内指路机器人可有个超厉害的技能,那就是能和第三方软件 “手牵手” 哦,接下来就带你一探究竟! 从技术魔法角度看哈:好多室内指路机器人都像拥有超能力的小魔法师,采用开放式…...

Apache BookKeeper Ledger 的底层存储机制解析
Apache BookKeeper 的 ledger(账本)是其核心数据存储单元,底层存储机制结合了日志追加(append-only)、分布式存储和容错设计。Ledger 的数据存储在 Bookie 节点的磁盘上,具体实现涉及 Journal(日…...

从代码上深入学习GraphRag
网上关于该算法的解析都停留在大概流程上,但是具体解析细节未知,由于代码是PipeLine形式因此阅读起来比较麻烦,本文希望通过阅读项目代码来解析其算法的具体实现细节,特别是如何利用大模型来完成图谱生成和检索增强的实现细节。 …...

通俗地讲述DDD的设计
通俗地讲述DDD的设计 前言为什么要使用DDDDDD架构分层重构实践关键问题解决方案通过领域事件机制解耦服务依赖:防止逻辑下沉 领域划分电商场景下的领域划分 结语完结撒花,如有需要收藏的看官,顺便也用发财的小手点点赞哈,…...