基于CNN-BiLSTM-GRU的深度Q网络(Deep Q-Network,DQN)求解移动机器人路径规划,MATLAB代码
一、深度Q网络(Deep Q-Network,DQN)介绍
1、背景与动机
深度Q网络(DQN)是深度强化学习领域的里程碑算法,由DeepMind于2013年提出。它首次在 Atari 2600 游戏上实现了超越人类的表现,解决了传统Q学习在高维状态空间中的应用难题。DQN在机器人路径规划领域展现出巨大潜力,能够帮助机器人在复杂环境中找到最优路径。
传统Q学习在状态空间维度较高时面临以下挑战:
- Q表无法存储高维状态的所有可能情况
- 特征提取需要手动设计,泛化能力差
- 更新过程容易导致Q值估计不稳定
DQN通过引入深度神经网络作为Q函数的近似器,并采用经验回放和目标网络等技术,有效解决了上述问题。
2、核心思想
DQN的核心思想是使用深度神经网络来近似Q函数,即:
Q ∗ ( s , a ) ≈ Q ( s , a ; θ ) Q^*(s, a) \approx Q(s, a; \theta) Q∗(s,a)≈Q(s,a;θ)
其中, s s s 表示状态, a a a 表示动作, θ \theta θ 表示神经网络的参数。
目标是找到一组参数 θ ∗ \theta^* θ∗,使得网络输出的Q值与实际的Q值尽可能接近。通过不断与环境交互收集数据,使用梯度下降法优化网络参数。
3、算法流程
DQN的算法流程可以概括为以下步骤:
-
初始化:
- 初始化Q网络参数 θ \theta θ
- 初始化目标网络参数 θ − \theta^- θ− 并与Q网络参数同步
- 初始化经验回放缓冲区 D D D
-
与环境交互:
- 在当前状态 s s s 下,根据 ϵ \epsilon ϵ-贪婪策略选择动作 a a a
- 执行动作 a a a,观察奖励 r r r 和下一个状态 s ′ s' s′
- 将经验 ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) 存入经验回放缓冲区 D D D
-
采样与更新:
- 从经验回放中随机采样一批数据 { ( s i , a i , r i , s i ′ ) } \{(s_i, a_i, r_i, s_i')\} {(si,ai,ri,si′)}
- 计算目标Q值:
y i = { r i if s i ′ is terminal r i + γ max a ′ Q ( s i ′ , a ′ ; θ − ) otherwise y_i = \begin{cases} r_i & \text{if } s_i' \text{ is terminal} \\ r_i + \gamma \max_{a'} Q(s_i', a'; \theta^-) & \text{otherwise} \end{cases} yi={riri+γmaxa′Q(si′,a′;θ−)if si′ is terminalotherwise
其中, γ \gamma γ 是折扣因子( 0 ≤ γ ≤ 1 0 \leq \gamma \leq 1 0≤γ≤1) - 计算当前Q值: Q ( s i , a i ; θ ) Q(s_i, a_i; \theta) Q(si,ai;θ)
- 计算损失函数:
L ( θ ) = 1 N ∑ i = 1 N ( y i − Q ( s i , a i ; θ ) ) 2 L(\theta) = \frac{1}{N} \sum_{i=1}^{N} (y_i - Q(s_i, a_i; \theta))^2 L(θ)=N1i=1∑N(yi−Q(si,ai;θ))2 - 使用梯度下降法更新Q网络参数 θ \theta θ
-
同步目标网络:
- 每隔一定步数(如C步),将Q网络参数 θ \theta θ 同步到目标网络 θ − \theta^- θ−
-
重复:
- 重复上述过程直到收敛
4、关键技术
1. 经验回放(Experience Replay)
经验回放通过存储代理与环境交互的经验,并随机采样小批量数据进行更新,解决了以下问题:
- 数据相关性:传统Q学习使用相关数据更新,容易导致估计偏差
- 数据利用效率:每个经验只使用一次,数据利用率低
经验回放的数学表达为:
D = { e 1 , e 2 , … , e N } , e i = ( s i , a i , r i , s i ′ ) D = \{e_1, e_2, \dots, e_N\}, \quad e_i = (s_i, a_i, r_i, s_i') D={e1,e2,…,eN},ei=(si,ai,ri,si′)
每次更新时,从 D D D 中随机采样小批量数据 B ⊆ D B \subseteq D B⊆D。
2. 目标网络(Target Network)
目标网络通过维持一个固定的网络来计算目标Q值,避免了Q值估计的不稳定。目标网络的参数 θ − \theta^- θ− 每隔一定步数与Q网络参数 θ \theta θ 同步:
θ − ← θ every C steps \theta^- \leftarrow \theta \quad \text{every C steps} θ−←θevery C steps
3. ϵ \epsilon ϵ-贪婪策略
ϵ \epsilon ϵ-贪婪策略在探索与利用之间取得平衡:
a = { random action with probability ϵ arg max a Q ( s , a ; θ ) with probability 1 − ϵ a = \begin{cases} \text{random action} & \text{with probability } \epsilon \\ \arg\max_a Q(s, a; \theta) & \text{with probability } 1-\epsilon \end{cases} a={random actionargmaxaQ(s,a;θ)with probability ϵwith probability 1−ϵ
其中, ϵ \epsilon ϵ 随时间逐渐衰减,从初始值(如1.0)逐渐降低到较小值(如0.1)。
5、数学推导
1. Q学习更新公式
Q学习的目标是找到最优策略下的Q值:
Q ∗ ( s , a ) = E r [ r + γ max a ′ Q ∗ ( s ′ , a ′ ) ] Q^*(s, a) = \mathbb{E}_r[r + \gamma \max_{a'} Q^*(s', a')] Q∗(s,a)=Er[r+γa′maxQ∗(s′,a′)]
其中, E r \mathbb{E}_r Er 表示对奖励分布的期望。
2. 损失函数
DQN使用均方误差(MSE)作为损失函数:
L ( θ ) = E s , a , r , s ′ [ ( y − Q ( s , a ; θ ) ) 2 ] L(\theta) = \mathbb{E}_{s,a,r,s'} \left[ (y - Q(s, a; \theta))^2 \right] L(θ)=Es,a,r,s′[(y−Q(s,a;θ))2]
其中, y = r + γ max a ′ Q ( s ′ , a ′ ; θ − ) y = r + \gamma \max_{a'} Q(s', a'; \theta^-) y=r+γmaxa′Q(s′,a′;θ−) 是目标Q值。
3. 梯度更新
使用梯度下降法更新参数 θ \theta θ:
θ ← θ + α ∇ θ L ( θ ) \theta \leftarrow \theta + \alpha \nabla_\theta L(\theta) θ←θ+α∇θL(θ)
其中, α \alpha α 是学习率, ∇ θ L ( θ ) \nabla_\theta L(\theta) ∇θL(θ) 是损失函数对参数的梯度。
6、与传统Q学习的对比
| 特性 | 传统Q学习 | DQN |
|---|---|---|
| 状态表示 | 离散状态或手工特征 | 深度神经网络自动提取特征 |
| 数据利用 | 每个数据只使用一次 | 经验回放多次利用数据 |
| 稳定性 | Q值估计容易发散 | 目标网络提高稳定性 |
| 适用场景 | 低维状态空间 | 高维状态空间(如图像) |
7、局限性
- 样本效率低:需要大量交互数据
- 超参数敏感:对 ϵ \epsilon ϵ、学习率、折扣因子等敏感
- 奖励稀疏问题:在奖励稀疏环境中表现不佳
- 计算资源需求高:需要强大的计算设备支持
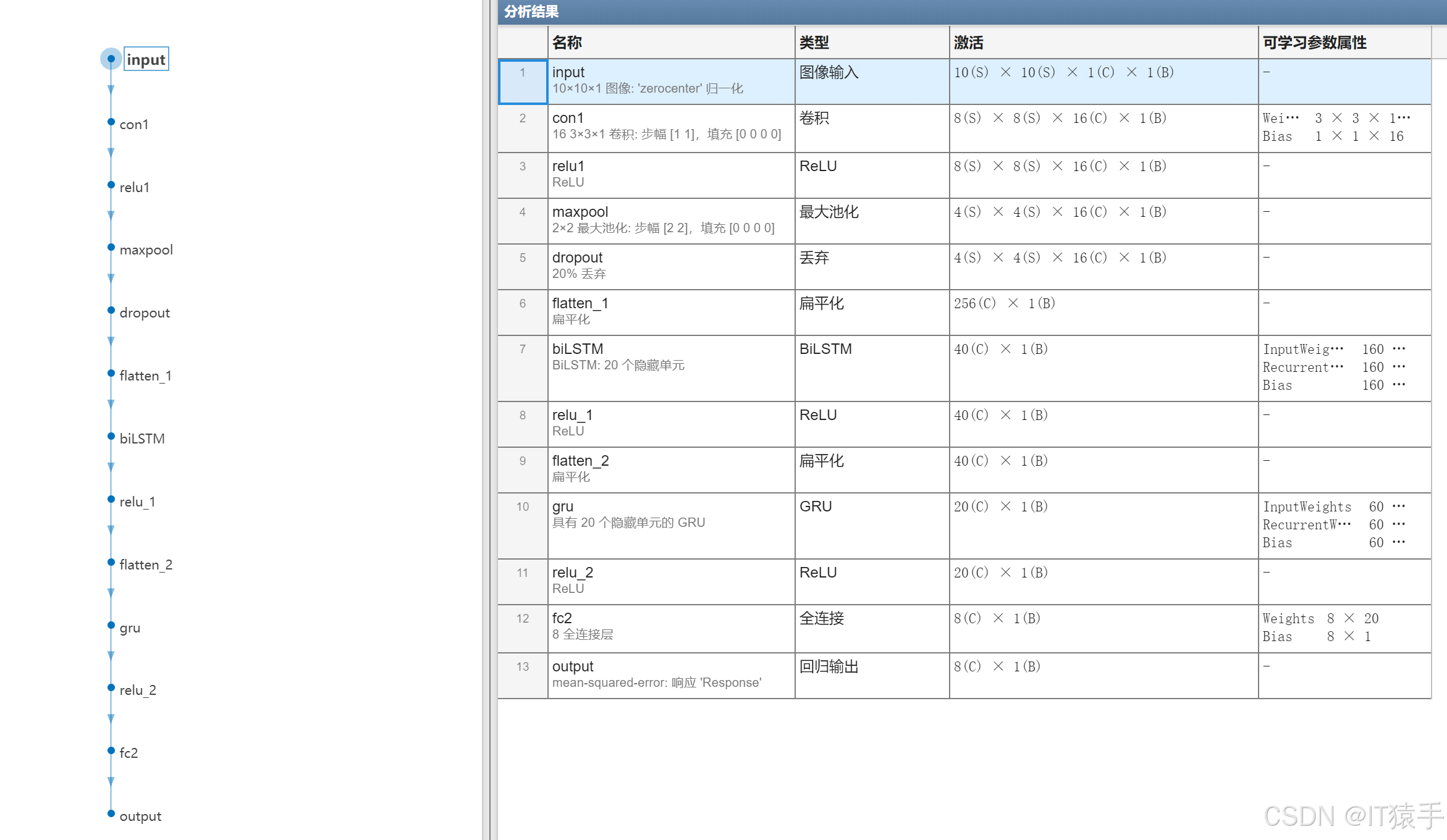
二、构建CNN-BiLSTM-GRU深度神经网络作为Q函数的近似器
输入是10*10大小含有障碍物的地图,输出是机器人8个方向的动作Q值,用于指导机器人选择最优动作。
三、DQN求解机器人路径规划
3.1 环境设置
- 状态空间:机器人当前的位置或状态,以及与目标位置的关系。
- 动作空间:机器人可以采取的所有可能动作,如移动到相邻位置。
- 奖励函数:定义机器人在执行动作后获得的即时奖励。例如,到达目标点给予高奖励,碰撞给予负奖励,距离目标点越近奖励越高。
3.2 网络设计
DQN网络输入是10×10大小的地图状态,输出是机器人8个方向的动作Q值。网络结构如下:
- 输入层:接收10×10的地图作为输入。
- 隐藏层:包含卷积层、LSTM、GRU等,用于提取地图特征。
- 输出层:输出8个方向动作的Q值。
3.3 训练过程
- 初始化:初始化经验池,随机初始化Q网络的参数,并初始化目标网络,其参数与Q网络相同。
- 获取初始状态:机器人从环境中获取初始状态。
- 选择动作:根据当前状态和ε-贪心策略选择动作。
- 执行动作并观察:机器人执行动作并观察新的状态和获得的奖励。
- 存储经验:将经验(状态、动作、奖励、新状态)存储在经验池中。
- 样本抽取与学习:从经验池中随机抽取样本,并使用这些样本来更新Q网络。
- 目标网络更新:定期将Q网络的参数复制到目标网络。
3.4 路径规划
在训练完成后,使用训练好的DQN网络来规划路径。机器人根据当前状态和Q值函数选择最优动作,逐步接近目标位置。
四、部分MATLAB代码及结果
%% 画图
analyzeNetwork(dqn_net)figure
plot(curve,'r-',LineWidth=2);
saveas(gca,'11.jpg')figure
imagesc(~map)
hold on
plot(state_mark(:,2),state_mark(:,1),'c-',LineWidth=2);
colormap('gray')
scatter(start_state_pos(2) ,start_state_pos(1),'MarkerEdgeColor',[0 0 1],'MarkerFaceColor',[0 0 1], 'LineWidth',1);%start point
scatter(target_state_pos(2),target_state_pos(1),'MarkerEdgeColor',[0 1 0],'MarkerFaceColor',[0 1 0], 'LineWidth',1);%goal point
text(start_state_pos(2),start_state_pos(1),'起点','Color','red','FontSize',10);%显示start字符
text(target_state_pos(2),target_state_pos(1),'终点','Color','red','FontSize',10);%显示goal字符
title('基于DQN的机器人路径规划')
saveas(gca,'12.jpg')







五、完整MATLAB代码见下方名片
相关文章:
基于CNN-BiLSTM-GRU的深度Q网络(Deep Q-Network,DQN)求解移动机器人路径规划,MATLAB代码
一、深度Q网络(Deep Q-Network,DQN)介绍 1、背景与动机 深度Q网络(DQN)是深度强化学习领域的里程碑算法,由DeepMind于2013年提出。它首次在 Atari 2600 游戏上实现了超越人类的表现,解决了传统…...
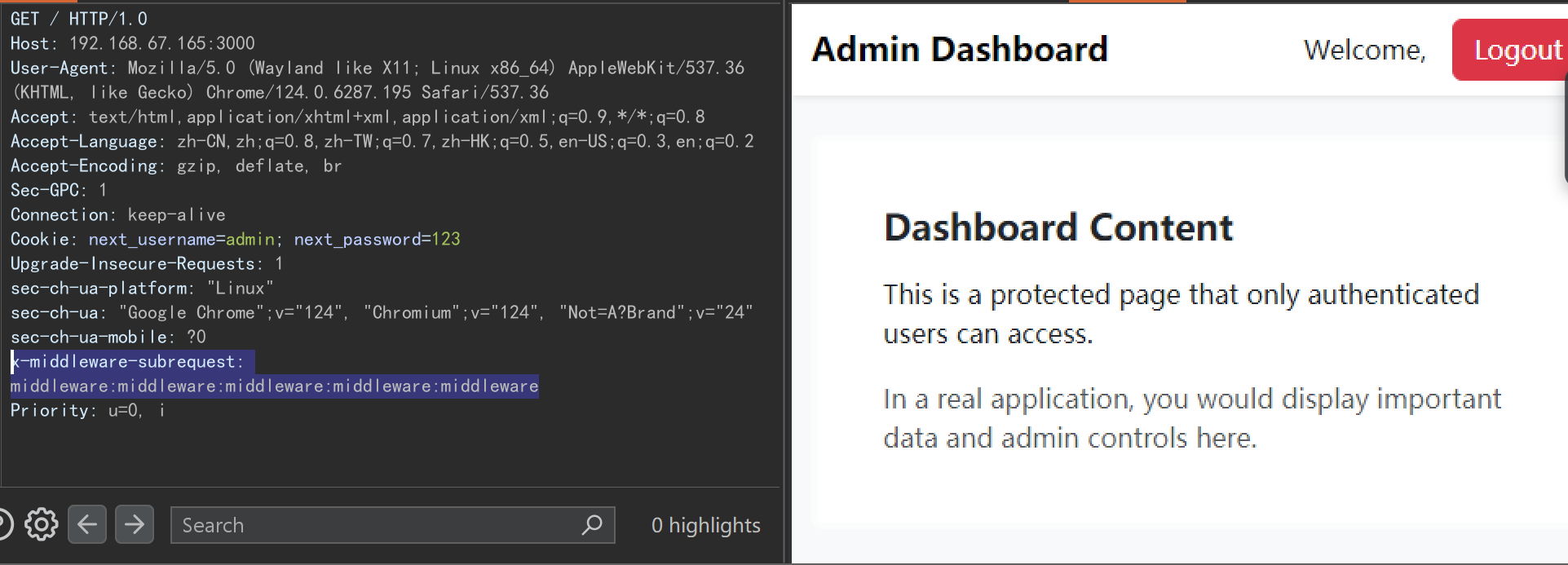
CVE-2025-29927 Next.js 中间件鉴权绕过漏洞
Next.js Next.js 是一个基于 React 的现代 Web 开发框架,用来构建高性能、可扩展的 Web 应用和网站。 CVE-2025-29927 Next.js 中间件鉴权绕过漏洞 CVE-2025-29927是Next.js框架中的一个授权绕过漏洞,允许攻击者通过特制的HTTP请求绕过在中间件中执行…...
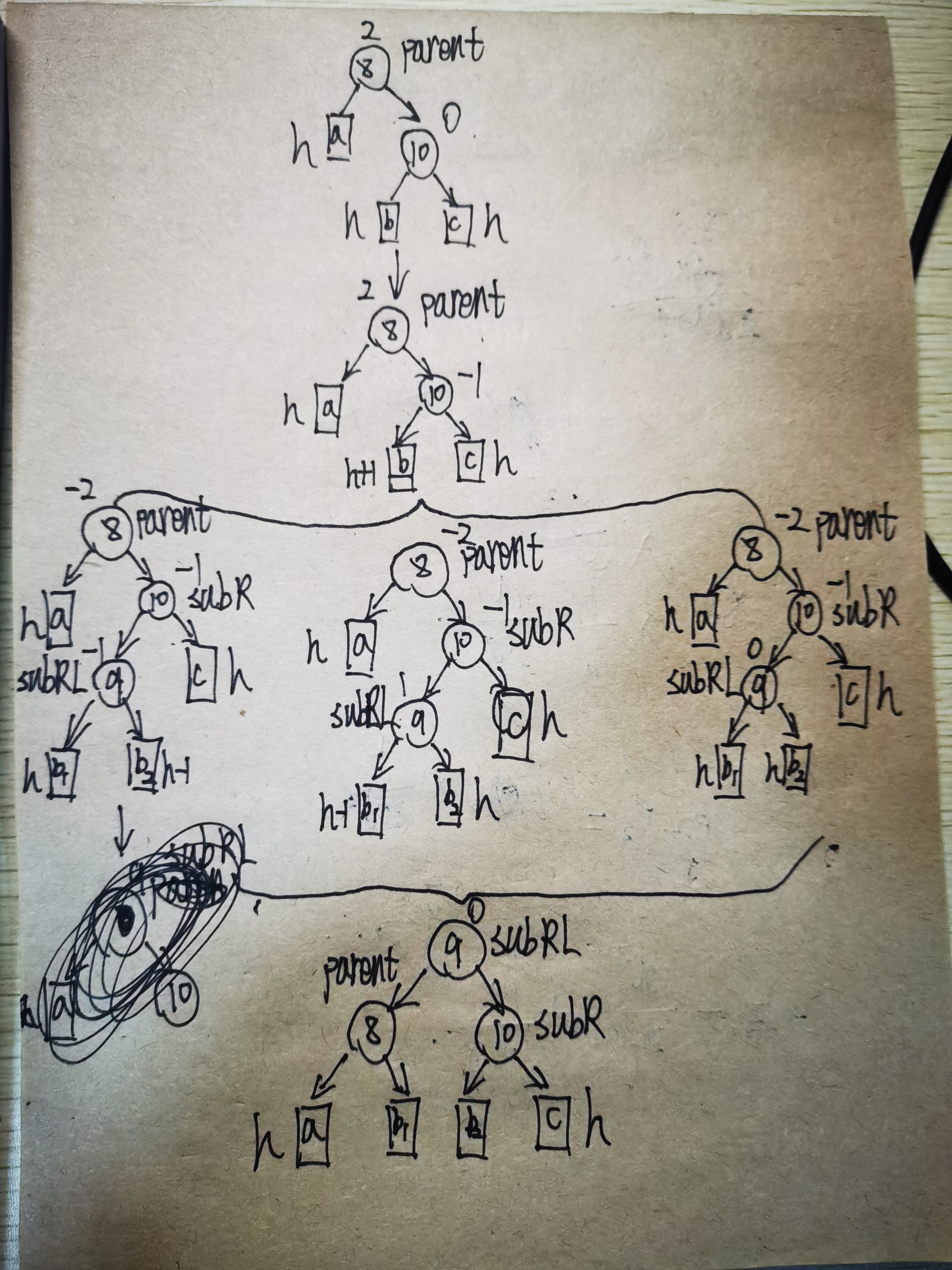
数据结构(五)——AVL树(平衡二叉搜索树)
目录 前言 AVL树概念 AVL树的定义 AVL树的插入 右旋转 左旋转 左右双旋 右左双旋 插入代码如下所示 AVL树的查找 AVL树的遍历 AVL树的节点个数以及高度 判断平衡 AVL树代码如下所示 小结 前言 前面我们在数据结构中介绍了二叉搜索树,其中提到了二叉搜…...

C++类型转换详解
目录 一、内置 转 内置 二、内置 转 自定义 三、自定义 转 内置 四、自定义 转 自定义 五、类型转换规范化 1.static_case 2.reinterpret_cast 3.const_cast 4.dynamic_cast 六、RTTI 一、内置 转 内置 C兼容C语言,在内置类型之间转换规则和C语言一样的&am…...

【前端】【React】性能优化三件套useCallback,useMemo,React.memo
一、总览:性能优化三件套 useCallback(fn, deps):缓存函数,避免每次渲染都新建函数。useMemo(fn, deps):缓存值(计算结果),避免重复执行计算。React.memo(Component):缓存组件的渲染…...
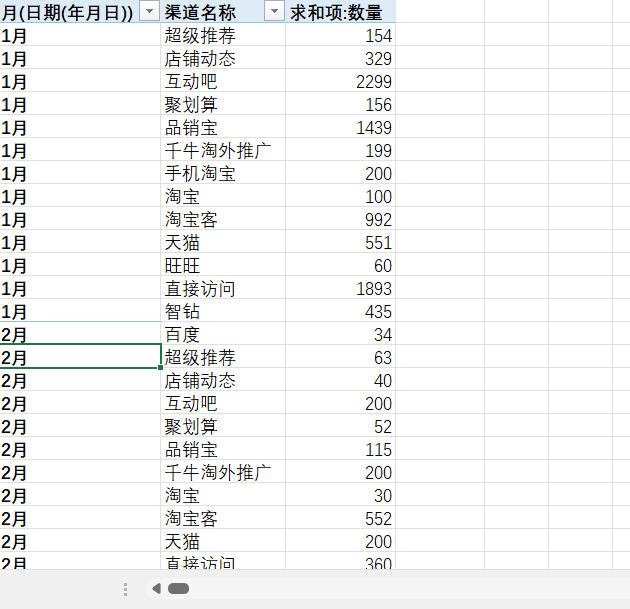
excel数据透视表大纲格式改为表格格式
现有这样一个数据透视表: 想要把他变成这样的表格格式: 操作步骤: 第一步: 效果: 第二步: 效果: 去掉分类汇总: 效果: 去掉展开/折叠按钮: 操作方式…...

pycharm中安装Charm-Crypto
一、安装依赖 1、安装gcc、make、perl sudo apt-get install gcc sudo apt-get install make sudo apt-get install perl #检查版本 gcc -v make -v perl -v 2、安装依赖库m4、flex、bison(如果前面安装过pypbc的话,应该已经装过这些包了) sudo apt-get update sudo apt…...
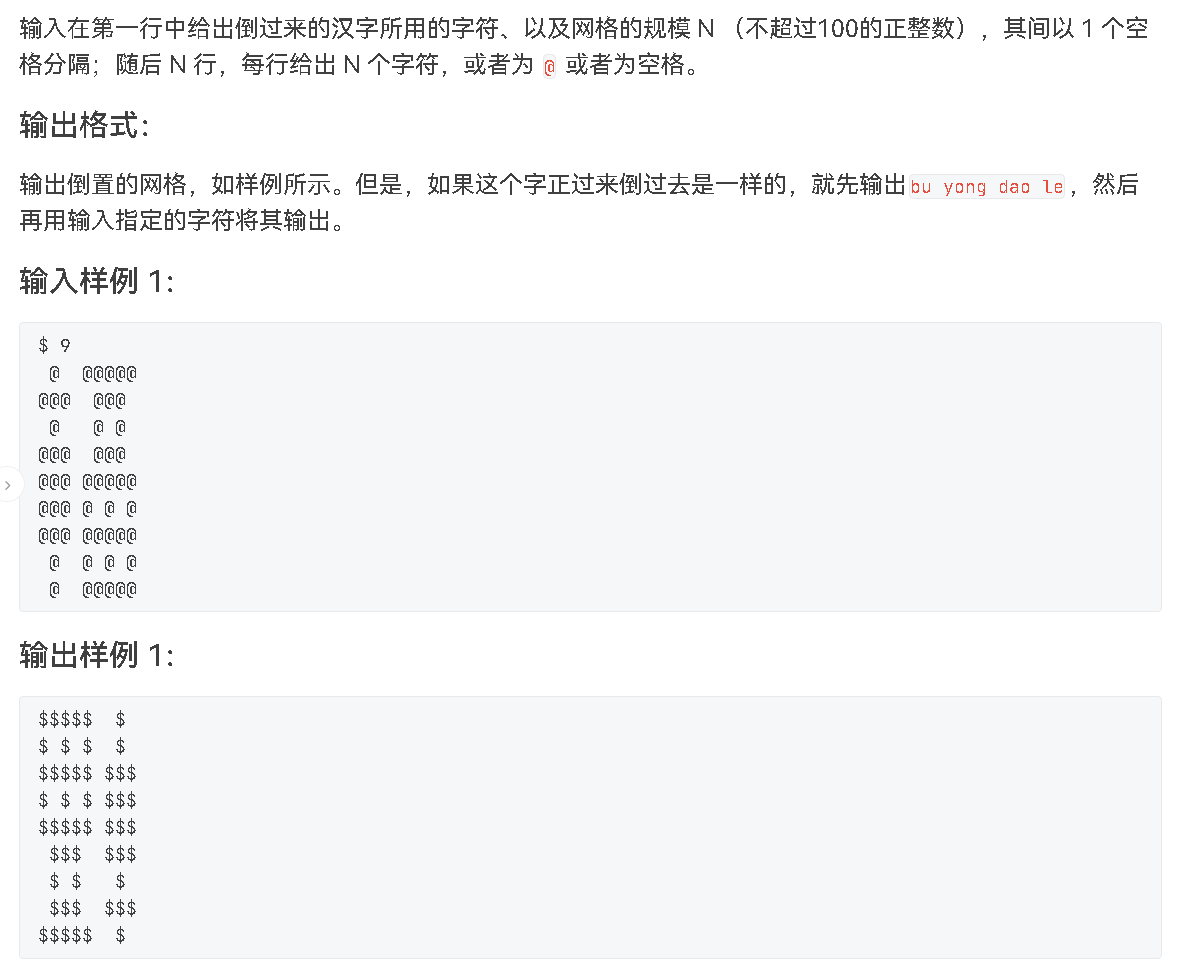
天梯集训+代码打卡笔记整理
1.着色问题 直接标注哪些行和列是被标注过的,安全格子的数量就是未标注的行*列 #include <bits/stdc.h> using namespace std;const int N 1e510; int hang[N],lie[N];int main(){int n,m;cin>>n>>m;int q;cin>>q;while(q--){int x,y;ci…...

python基础语法:缩进规则
Python 的缩进规则是其语法的重要组成部分,它通过缩进来表示代码块的层次结构,而不是像其他语言(如 C 或 Java)那样使用大括号 {}。以下是 Python 缩进规则的详细说明: 1. 缩进的基本规则 代码块的标识:Pyt…...

支付系统设计入门:核心账户体系架构
👉目录 1 账户记账理论 2 账户设计 3 账户性能问题 4 账户核心架构 5 小结 第三方支付作为中立的第三方,截断了用户和商户的资金流,资金先从用户账户转移到第三方支付平台账户,得到双方确认后再从支付平台账户转移到商户账户。 支…...
[LevelDB]Block系统内幕解析-元数据块(Meta Block)元数据索引块(MetaIndex Block)索引块(Index Block)
本文内容组织形式 Block的基本信息作用示意图举例说明 源码解析Footer格式写入&读取编码&解码 元数据块(Meta Block)构建&读取 元数据索引块构建&读取 索引块定义构建&读取核心方法-FindShortestSeparator&FindShortSuccessor作…...
leetcode:905. 按奇偶排序数组(python3解法)
难度:简单 给你一个整数数组 nums,将 nums 中的的所有偶数元素移动到数组的前面,后跟所有奇数元素。 返回满足此条件的 任一数组 作为答案。 示例 1: 输入:nums [3,1,2,4] 输出:[2,4,3,1] 解释:…...

抖音视频下载工具
抖音视频下载工具 功能介绍 这是一个基于Python开发的抖音视频下载工具,可以方便地下载抖音平台上的视频内容。 主要特点 支持无水印视频下载自动提取视频标题作为文件名显示下载进度条支持自动重试机制支持调试模式 使用要求 Python 3.10Chrome浏览器必要的P…...
断言与反射——以golang为例
断言 x.(T) 检查x的动态类型是否是T,其中x必须是接口值。 简单使用 func main() {var x interface{}x 100value1, ok : x.(int)if ok {fmt.Println(value1)}value2, ok : x.(string)if ok {//未打印fmt.Println(value2)} }需要注意如果不接受第二个参数就是OK,这…...
】商务部信用对接、法律咨询与视频面试功能开发全攻略)
【家政平台开发(27)】商务部信用对接、法律咨询与视频面试功能开发全攻略
本【家政平台开发】专栏聚焦家政平台从 0 到 1 的全流程打造。从前期需求分析,剖析家政行业现状、挖掘用户需求与梳理功能要点,到系统设计阶段的架构选型、数据库构建,再到开发阶段各模块逐一实现。涵盖移动与 PC 端设计、接口开发及性能优化,测试阶段多维度保障平台质量,…...
【数据结构】排序算法(下篇·开端)·深剖数据难点
前引:前面我们通过层层学习,了解了Hoare大佬的排序精髓,今天我们学习的东西可能稍微有点难度,因此我们必须学会思想,我很受感慨,借此分享一下:【用1520分钟去调试】,如果我们遇到了任…...
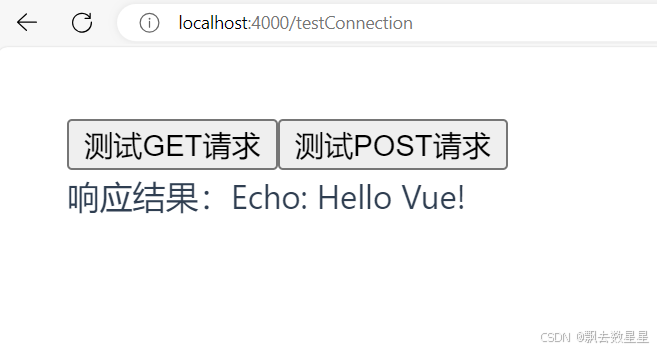
山东大学软件学院创新项目实训开发日志(9)之测试前后端连接
在正式开始前后端功能开发前,在队友的帮助下,成功完成了前后端测试连接: 首先在后端编写一个测试相应程序: 然后在前端创建vue 并且在index.js中添加一下元素: 然后进行测试,测试成功: 后续可…...

【VUE3】Eslint 与 Prettier 的配置
目录 0 前言 1 VSCode 中的 Eslint 与 prettier 插件 2 两种方案 3 eslint.config.js 4 eslint-plugin-prettier 插件 5 eslint-config-prettier 插件 6 安装插件命令 7 其他配置 8 参考资料 0 前言 黑马程序员视频地址:160-Vue3大事件项目-ESlint配合P…...

蓝桥杯C++组算法知识点整理 · 考前突击(上)【小白适用】
【背景说明】本文的作者是一名算法竞赛小白,在第一次参加蓝桥杯之前希望整理一下自己会了哪些算法,于是有了本文的诞生。分享在这里也希望与众多学子共勉。如果时间允许的话,这一系列会分为上中下三部分和大家见面,祝大家竞赛顺利…...

springboot调用python文件,python文件使用其他dat文件,适配windows和linux,以及docker环境的方案
介绍 后台是用springboot技术,其他同事做的算法是python,现在的需求是springboot调用python,python又需要调用其他的数据文件,比如dat文件,这个文件是app通过蓝牙获取智能戒指数据以后,保存到后台…...
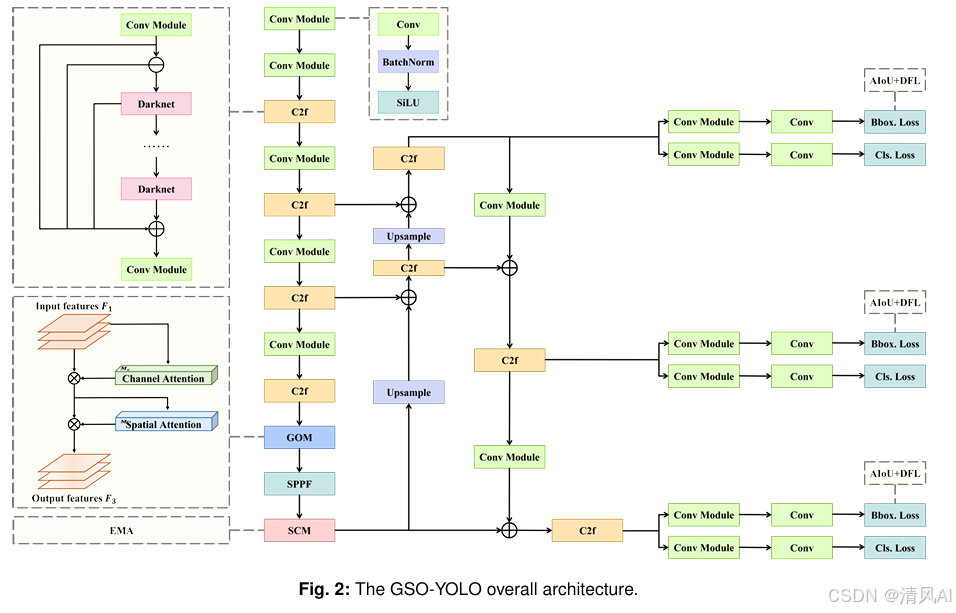
GSO-YOLO:基于全局稳定性优化的建筑工地目标检测算法解析
论文地址:https://arxiv.org/pdf/2407.00906 1. 论文概述 《GSO-YOLO: Global Stability Optimization YOLO for Construction Site Detection》提出了一种针对建筑工地复杂场景优化的目标检测模型。通过融合全局优化模块(GOM)、稳定捕捉模块(SCM)和创新的AIoU损失函…...

Python 中使用单例模式
有这么一种场景,Web服务中有一个全局资源池,在需要使用的地方就自然而言引用该全局资源池即可,此时可以将该资源池以单例模式实现。随后,需要为某一特殊业务场景专门准备一个全局资源池,于是额外复制一份代码新建了一个…...

系统思考—提升解决动态性复杂问题能力
感谢合作伙伴的信任推荐! 客户今年的人才发展重点之一,是提升管理者应对动态性、复杂性问题的能力。 在深入交流后,系统思考作为关键能力模块,最终被纳入轮训项目——这不仅是一次培训合作,更是一场共同认知的跃迁&am…...
)
Java基础 - 反射(2)
文章目录 示例5. 通过反射获得类的private、 protected、 默认访问修饰符的属性值。6. 通过反射获得类的private方法。7. 通过反射实现一个工具BeanUtils, 可以将一个对象属性相同的值赋值给另一个对象 接上篇: 示例 5. 通过反射获得类的private、 pro…...

Python proteinflow 库介绍
ProteinFlow是一个开源的Python库,旨在简化蛋白质结构数据在深度学习应用中的预处理过程。以下是其详细介绍: 功能 数据处理:支持处理单链和多链蛋白质结构,包括二级结构特征、扭转角等特征化选项。 数据获取:能够从Protein Data Bank (PDB)和Structural Antibody Databa…...

P1162 洛谷 填涂颜色
题目描述 思考 看数据量 30 而且是个二维的,很像走迷宫 直接深搜! 而且这个就是搜连通块 代码 一开始的15分代码,想的很简单,对dfs进行分类,如果是在边界上,就直接递归,不让其赋值,…...
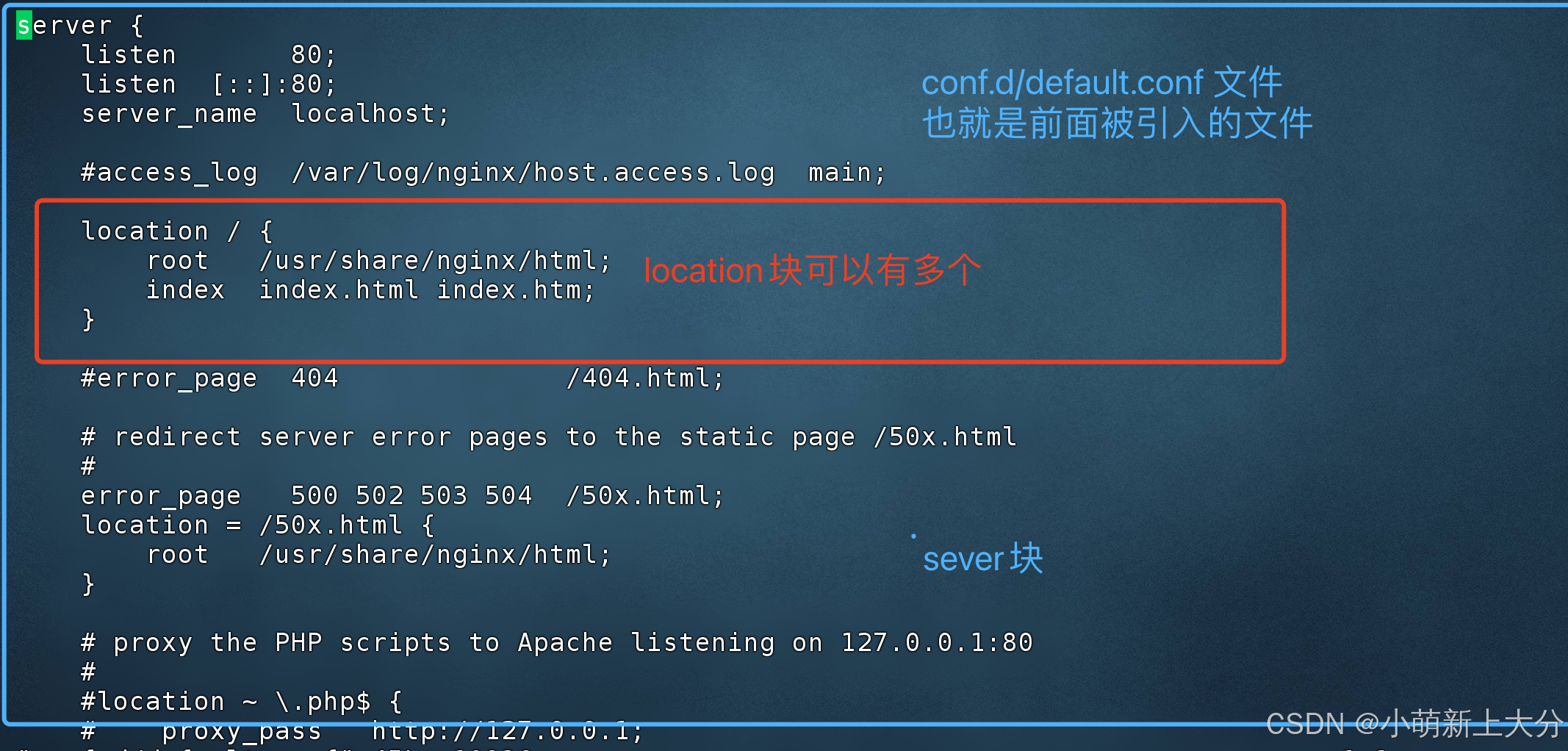
docker安装nginx,基础命令,目录结构,配置文件结构
Nginx简介 Nginx是一款轻量级的Web服务器(动静分离)/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。其特点是占有内存少,并发能力强. 🔗官网 docker安装Nginx 🐳 一、前提条件 • 已安装 Docker(dock…...

SQLI漏洞公开报告分析
文章目录 1. 闭合 )2. 邀请码|POST参数|时间盲注 | **PostgreSQL**3. POST|order by参数|布尔盲注|Oracle4. SOAP请求|MSSQL|布尔盲注5. MySQL 时间盲注漏洞6. GET|普通回显注入7. ImpressCMS 1.4.2 | CVE | POST | 布尔盲注8. Mysql | post | 布尔/时间盲注9. 登录口 | post |…...

SpringBoot项目部署之启动脚本
一、启动脚本方案 1. 基础启动方式 1.1 直接运行JAR java -jar your-app.jar --spring.profiles.activeprod优点:简单直接,适合快速测试缺点:终端关闭即终止进程 1.2 后台运行 nohup java -jar your-app.jar > app.log 2>&1 &…...
用Django和AJAX创建一个待办事项应用
用Django和AJAX创建一个待办事项应用 推荐超级课程: 本地离线DeepSeek AI方案部署实战教程【完全版】Docker快速入门到精通Kubernetes入门到大师通关课AWS云服务快速入门实战目录 用Django和AJAX创建一个待办事项应用让我们创建一个简单的 Django 项目,其中包含不同类型的 A…...