理解 results = model(source, stream=True) 的工作原理和优势
1. 核心概念解析
(1) stream=True 的作用
- 生成器模式:当处理视频或图像序列时,
stream=True会将结果包装成一个 生成器(Generator),逐帧生成Results对象,而不是一次性返回所有结果。 - 内存优化:避免同时加载全部帧的检测结果,显著降低内存占用(尤其对长视频或高分辨率输入至关重要)。
(2) Results 对象生成器
- 每次迭代返回一个
Results对象,对应视频的 一帧 或输入列表中的 一个元素。 - 每个
Results对象包含该帧的检测信息(如boxes、masks等)。
2. 工作流程对比
传统方式(stream=False)
results = model("video.mp4") # 一次性处理所有帧
# 所有结果存储在内存中,可能导致OOM(内存不足)
- 内存峰值高:需缓存整个视频的检测结果。
- 延迟高:必须等待全部处理完成才能访问结果。
流式处理(stream=True)
results = model("video.mp4", stream=True) # 生成器
for frame_results in results: # 逐帧处理print(frame_results.boxes) # 实时访问当前帧结果
- 内存友好:同一时间仅处理一帧的数据。
- 实时性:边处理边输出,适合实时分析或长时间视频。
3. 典型使用场景
(1) 视频处理
cap = cv2.VideoCapture("input.mp4")
out = cv2.VideoWriter("output.mp4", cv2.VideoWriter_fourcc(*'mp4v'), 30, (640, 480))# 流式推理
results = model("input.mp4", stream=True)
for frame_results in results:annotated_frame = frame_results.plot() # 绘制检测框out.write(annotated_frame) # 写入输出视频
- 优势:避免因视频过长导致内存爆炸。
- 值得注意,(输出视频只有1KB)通常是由于 视频编解码器配置问题 或 帧尺寸不匹配 导致的。以下是修正后的完整代码,解决写入视频无效的问题:
import cv2
from ultralytics import YOLO# 初始化模型
model = YOLO("../models/yolo11n.pt") # pretrained YOLO11n model# 输入视频路径
input_video = "../videos/test.mp4"# 读取输入视频获取帧尺寸和FPS
cap = cv2.VideoCapture(input_video)
fps = int(cap.get(cv2.CAP_PROP_FPS))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
cap.release()# 定义视频写入器(关键修正点)
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # 或改用 'avc1' 兼容H.264
out = cv2.VideoWriter("output.mp4",fourcc,fps,(width, height) # 必须与原始视频尺寸一致!
)# 流式推理
results = model(input_video, stream=True, imgsz=640) # imgsz可调整for frame_results in results:# 获取带标注的帧(BGR格式)annotated_frame = frame_results.plot() # 自动返回numpy数组 (H,W,3)# 确保帧尺寸与写入器匹配(额外安全检查)if (annotated_frame.shape[1], annotated_frame.shape[0]) != (width, height):annotated_frame = cv2.resize(annotated_frame, (width, height))# 写入帧out.write(annotated_frame)# 释放资源
out.release()
print(f"视频已保存至 output.mp4,尺寸: {width}x{height}, FPS: {fps}")
(2) 实时摄像头流
results = model(0, stream=True) # 摄像头ID=0
for frame_results in results:cv2.imshow("Live", frame_results.plot())if cv2.waitKey(1) == ord('q'): # 按Q退出break
- 优势:低延迟,适合实时监控。
4. 内存优化原理
| 处理方式 | 内存占用曲线 | 特点 |
|---|---|---|
stream=False |  | 内存随帧数线性增长 |
stream=True |  | 内存恒定(仅缓存当前帧) |
5. 注意事项
-
性能权衡:
- 优点:节省内存,适合资源受限环境。
- 缺点:总处理时间可能略长(因无法并行处理所有帧)。
-
不可逆迭代:
results = model(source, stream=True) list(results) # 第一次迭代后生成器耗尽,再次遍历需重新推理 -
与多线程结合:
from concurrent.futures import ThreadPoolExecutordef process_frame(frame_results):return frame_results.plot()with ThreadPoolExecutor() as executor:annotated_frames = list(executor.map(process_frame, results))
6. 类比解释
- 传统方式:像一次性下载整部电影再看 → 占用硬盘空间大。
- 流式处理:像在线边缓冲边播放 → 内存占用稳定。
通过 stream=True,YOLOv8 实现了 高效流水线处理,尤其适合嵌入式设备或大规模视频分析场景。
相关文章:
理解 results = model(source, stream=True) 的工作原理和优势
1. 核心概念解析 (1) streamTrue 的作用 生成器模式:当处理视频或图像序列时,streamTrue 会将结果包装成一个 生成器(Generator),逐帧生成 Results 对象,而不是一次性返回所有结果。内存优化:…...
国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度
以下是 国内互联网大厂推出的分布式数据库 的详细对比,涵盖架构、性能、适用场景、核心技术等维度: 一、主流分布式数据库列表 大厂数据库名称类型适用场景发布时间腾讯云TDSQL分布式HTAP金融、电商、游戏、政企2010年阿里云OceanBase分布式HTAP银行核…...

解释`new`关键字的执行过程,并手动实现一个`myNew`函数。
在 JavaScript 中,new 关键字用于创建一个用户定义的对象实例。它的执行过程分为以下步骤: new 关键字的执行过程 创建空对象: 创建一个新的空对象,其 [[Prototype]](即 __proto__)指向构造函数的 prototy…...
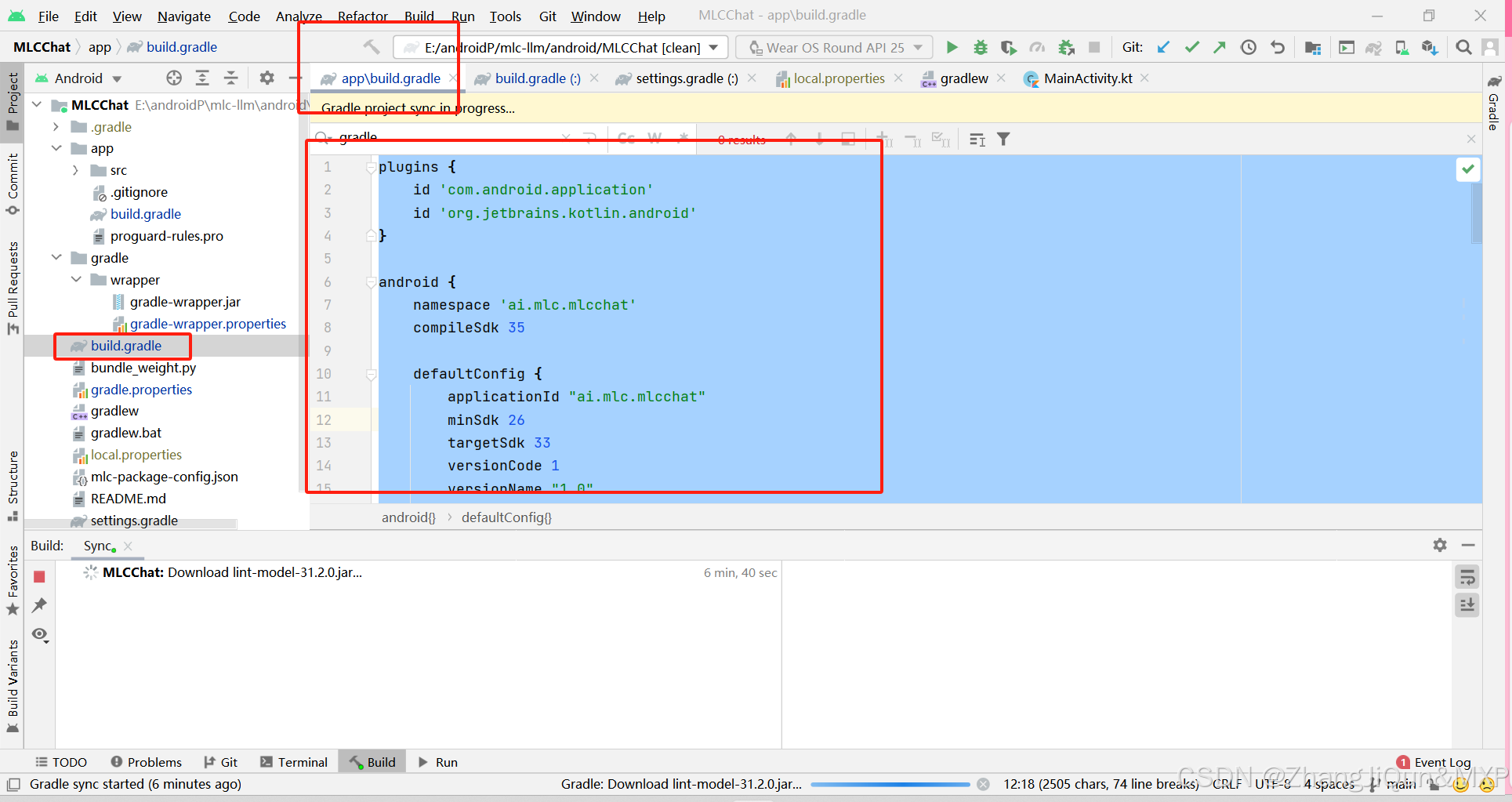
Android 项目配置文件解释
Android 项目配置文件解释 目录 Android 项目配置文件解释1. `plugins` 块2. `android` 块3. `dependencies` 块为什么需要 JDK 和 Kotlin1. plugins 块 plugins {id com.android.applicationid org.jetbrains.kotlin.android }id com.android.application:应用 Android 应用…...

亚马逊热销变维权?5步搭建跨境产品的安全防火墙
“产品热卖,引来维权”——这已经悄然成为越来越多跨境卖家的“热销烦恼”。曾经拼品拼量,如今却要步步谨慎。商标侵权、专利投诉、图片盗用……这些问题一旦发生,轻则下架、账号被限,重则冻结资金甚至封店。 别让“热销”变“受…...

C语言——分支语句
在现实生活中,我们经常会遇到作出选择和判断的时候,在C语言中也同样要面临作出选择和判断的时候,所以今天,就让我们一起来了解一下,C语言是如何作出选择判断的。 目录 1.何为语句? 2.if语句 2.1 if语句的…...
绿盟二面面试题
5000篇网安资料库https://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247486065&idx2&snb30ade8200e842743339d428f414475e&chksmc0e4732df793fa3bf39a6eab17cc0ed0fca5f0e4c979ce64bd112762def9ee7cf0112a7e76af&scene21#wechat_redirect 1. 原理深度&…...
deepseek生成流程图
目录 Mermaid流程图需求询问框架交互显示流程图markdown在线网站 可能会出现的问题语法报错 在职场中,借助AI生成图表是提升效率的重要技能,本篇我们讲解如何使用deepseek生成流程图 Mermaid流程图 需求 学习太差劲了,我想要一个比较好的学…...

界面控件DevExpress WPF v25.1新功能预览 - 文档处理类功能升级
DevExpress WPF拥有120个控件和库,将帮助您交付满足甚至超出企业需求的高性能业务应用程序。通过DevExpress WPF能创建有着强大互动功能的XAML基础应用程序,这些应用程序专注于当代客户的需求和构建未来新一代支持触摸的解决方案。 无论是Office办公软件…...

大塔集团乔迁开新局 企业赋能贯全程
2025年4月15 日,在佛山市佛山大道北175号,大塔集团乔迁开业盛大启幕,业界目光聚焦于此。 点睛仪式 揭牌仪式 彩绸飘扬、嘉宾云集,现场气氛热烈非凡,这一标志性时刻,宣告着大塔集团正式踏上全新发展征程。 …...

新闻业务--草稿箱
本人之前写的侧边栏渲染有点问题,超级管理员和其他的不兼容,所以修改了一下SideMenu: import React, { useState, useEffect } fromreact; import { Layout, Menu } from antd; import { useNavigate } fromreact-router-dom; import axios …...
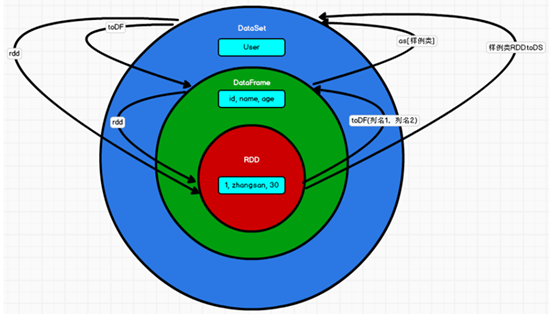
Spark-SQL核心编程(二)(三)
Spark-SQL核心编程(二) DSL 语法 DataFrame 提供一个特定领域语言(domain-specific language, DSL)去管理结构化的数据。 可以在 Scala, Java, Python 和 R 中使用 DSL,使用 DSL 语法风格不必去创建临时视图了。 1.创建一个 DataFrame val d…...

Spring Boot整合Kafka的详细步骤
1. 安装Kafka 下载Kafka:从Kafka官网下载最新版本的Kafka。 解压并启动: 解压Kafka文件后,进入bin目录。 启动ZooKeeper:./zookeeper-server-start.sh ../config/zookeeper.properties。 启动Kafka:./kafka-server-…...

【EI/Scopus顶会矩阵】2025年5-6月涵盖统计建模、数智转型、信息工程、数字系统、自动化系统领域,硕博生执笔未来!
【EI/Scopus顶会矩阵】2025年5-6月涵盖统计建模、数智转型、信息工程、数字系统、自动化系统领域,硕博生执笔未来! 【EI/Scopus顶会矩阵】2025年5-6月涵盖统计建模、数智转型、信息工程、数字系统、自动化系统领域,硕博生执笔未来࿰…...

Kubernetes 节点摘除指南
目录 一、安全摘除节点的标准流程 1. 确认节点名称及状态 2. 标记节点为不可调度 3. 排空(Drain)节点 4. 删除节点 二、验证节点是否成功摘除 1. 检查节点列表 2. 检查节点详细信息 3. 验证 Pod 状态 三、彻底清理节点(可选…...

ReliefF 的原理
🌟 ReliefF 是什么? ReliefF 是一种“基于邻居差异”的特征选择方法,用来评估每个特征对分类任务的贡献大小。 它的核心问题是: “我怎么知道某个特征是不是重要?是不是有能力把不同类别的数据区分开?” 而…...
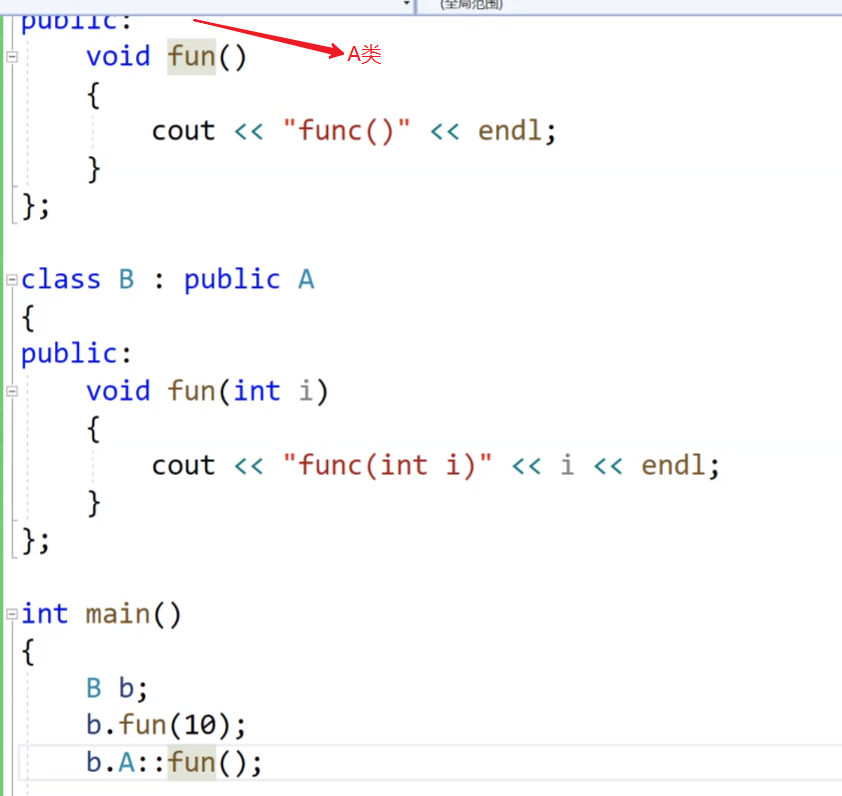
继承:(开始C++的进阶)
我们今天来学习C的进阶: 面向对象三大特性:封装,继承,多态。 封装我们在前面已经学了,我们细细理解,我们的类的封装,迭代器的封装(vector的迭代器可以是他的原生指针,li…...
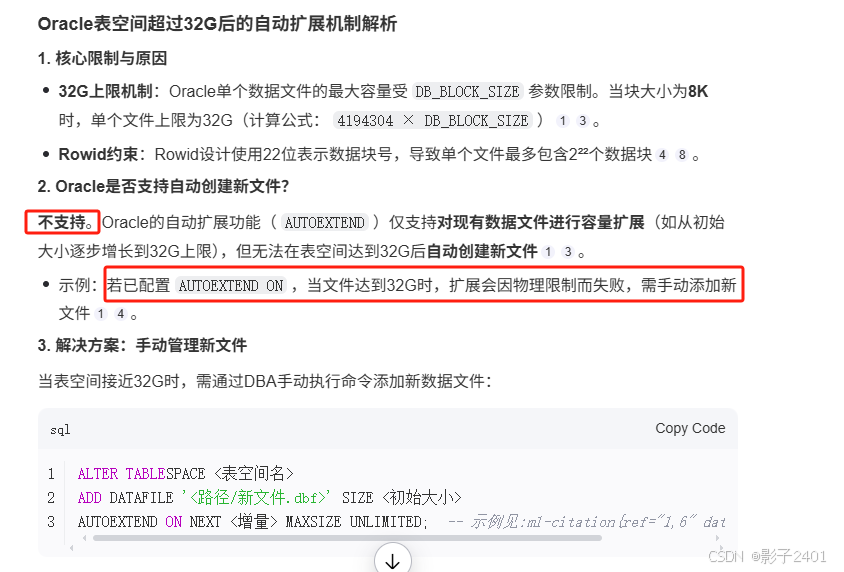
oracle数据库单个表空间达到32G后程序报错表空间不足问题排查、处理
oracle数据库单个表空间达到32G后程序报错表空间不足问题排查、处理 系统宕机tomcat日志报错表空间无法增长,排查发现oralce表空间文件到了32G。 通过AI查了下,“oracle是否支持表空间达到32G后,自动创建新的表空间文件” 答复是oralce不支…...
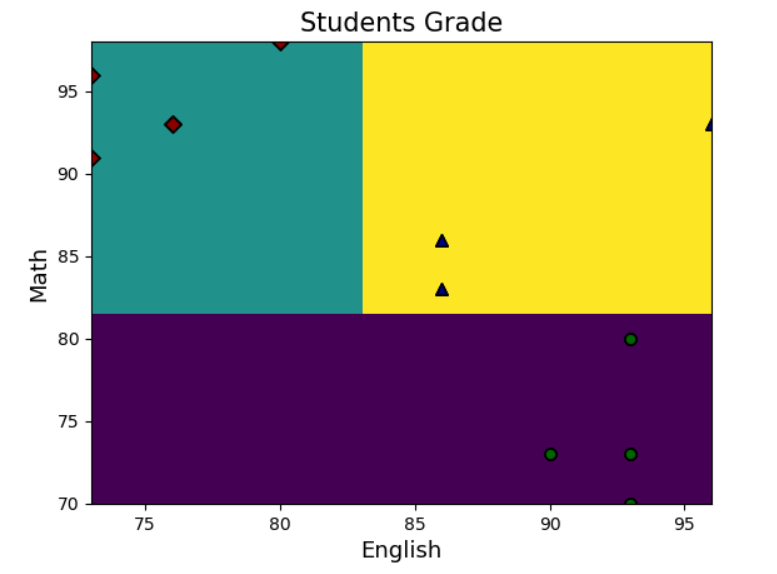
人工智能——梯度提升决策树算法
目录 摘要 14 梯度提升决策树 14.1 本章工作任务 14.2 本章技能目标 14.3 本章简介 14.4 编程实战 14.5 本章总结 14.6 本章作业 本章已完结! 摘要 本章实现的工作是:首先采用Python语言读取含有英语成绩、数学成绩以及学生所属类型的样本数据…...

数据结构学习笔记 :基本概念、算法特性与线性表实现
目录 数据的逻辑结构数据的物理结构算法的五大特性好的算法目标时间复杂度与空间复杂度线性表的顺序存储(顺序表) 6.1 静态分配 6.2 动态分配 6.3 基本操作及时间复杂度 一、数据的逻辑结构 数据的逻辑结构描述数据元素之间的逻辑关系,分为…...
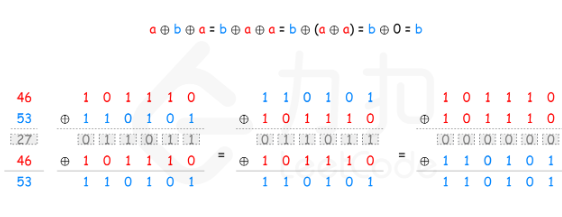
【leetcode hot 100 136】只出现一次的数字
解法一:(异或XOR)相同的数字出现两次则归零 class Solution {public int singleNumber(int[] nums) {int result 0;for(int num:nums){result ^ num;}return result;} }注意: 其他方法:HashList记录次数再查找数组&a…...
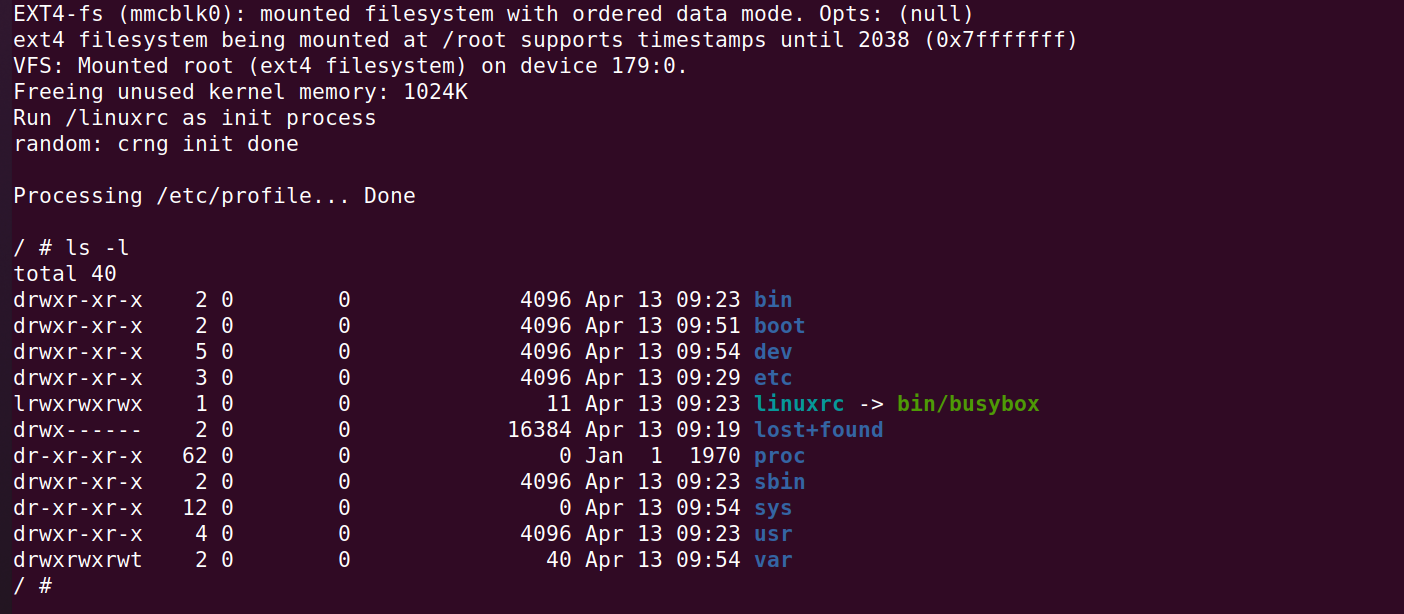
QEMU学习之路(8)— ARM32通过u-boot 启动Linux
QEMU学习之路(8)— ARM32通过u-boot 启动Linux 一、前言 参考文章: Linux内核学习——内核的编译和启动 Linux 内核的编译和模拟执行 Linux内核运行——根文件系统 Linux 内核学习——使用 uboot 加载内核 二、构建Linux内核 1、获取Linu…...
AgentOps - 帮助开发者构建、评估和监控 AI Agent
文章目录 一、关于 AgentOps二、关键集成 🔌三、快速开始 ⌨️2行代码中的Session replays 首类开发者体验 四、集成 🦾OpenAI Agents SDK 🖇️CrewAI 🛶AG2 🤖Camel AI 🐪Langchain 🦜…...

leetcode 122. Best Time to Buy and Sell Stock II
题目描述 这道题可以用贪心思想解决。 本文介绍用动态规划解决。本题分析方法与第121题一样,详见leetcode 121. Best Time to Buy and Sell Stock 只有一点区别。第121题全程只能买入1次,因此如果第i天买入股票,买之前的金额肯定是初始金额…...

【ROS】代价地图
【ROS】代价地图 前言代价地图(Costmap)概述代价地图的参数costmap_common_params.yaml 参数说明costmap_common_params.yaml 示例说明global_costmap.yaml 参数说明global_costmap.yaml 示例说明local_costmap.yaml 参数说明local_costmap.yaml 示例说明…...
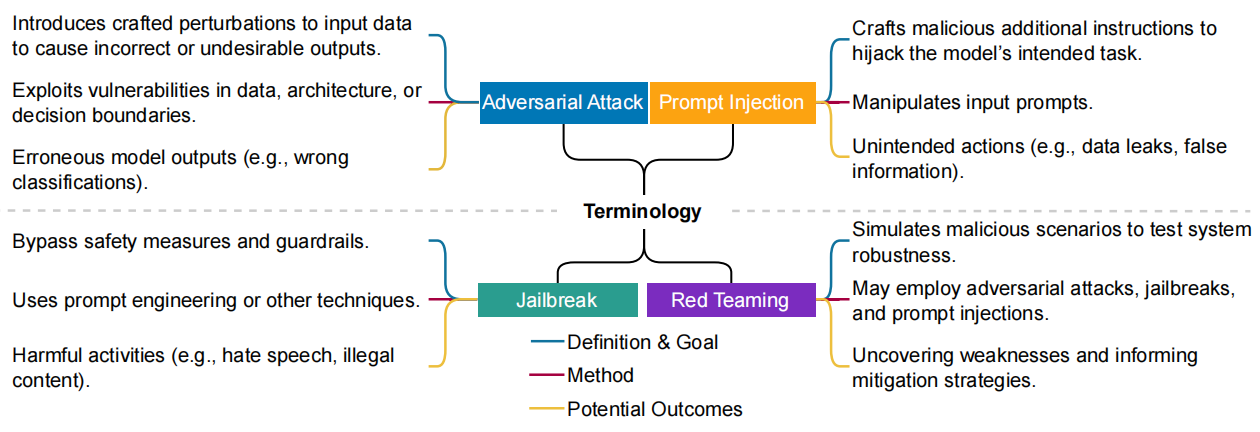
《Against The Achilles’ Heel: A Survey on Red Teaming for Generative Models》全文阅读
《Against The Achilles’ Heel: A Survey on Red Teaming for Generative Models》 突破阿基里斯之踵:生成模型红队对抗综述 摘要 生成模型正迅速流行并被整合到日常应用中,随着各种漏洞暴露,其安全使用引发担忧。鉴于此,红队…...
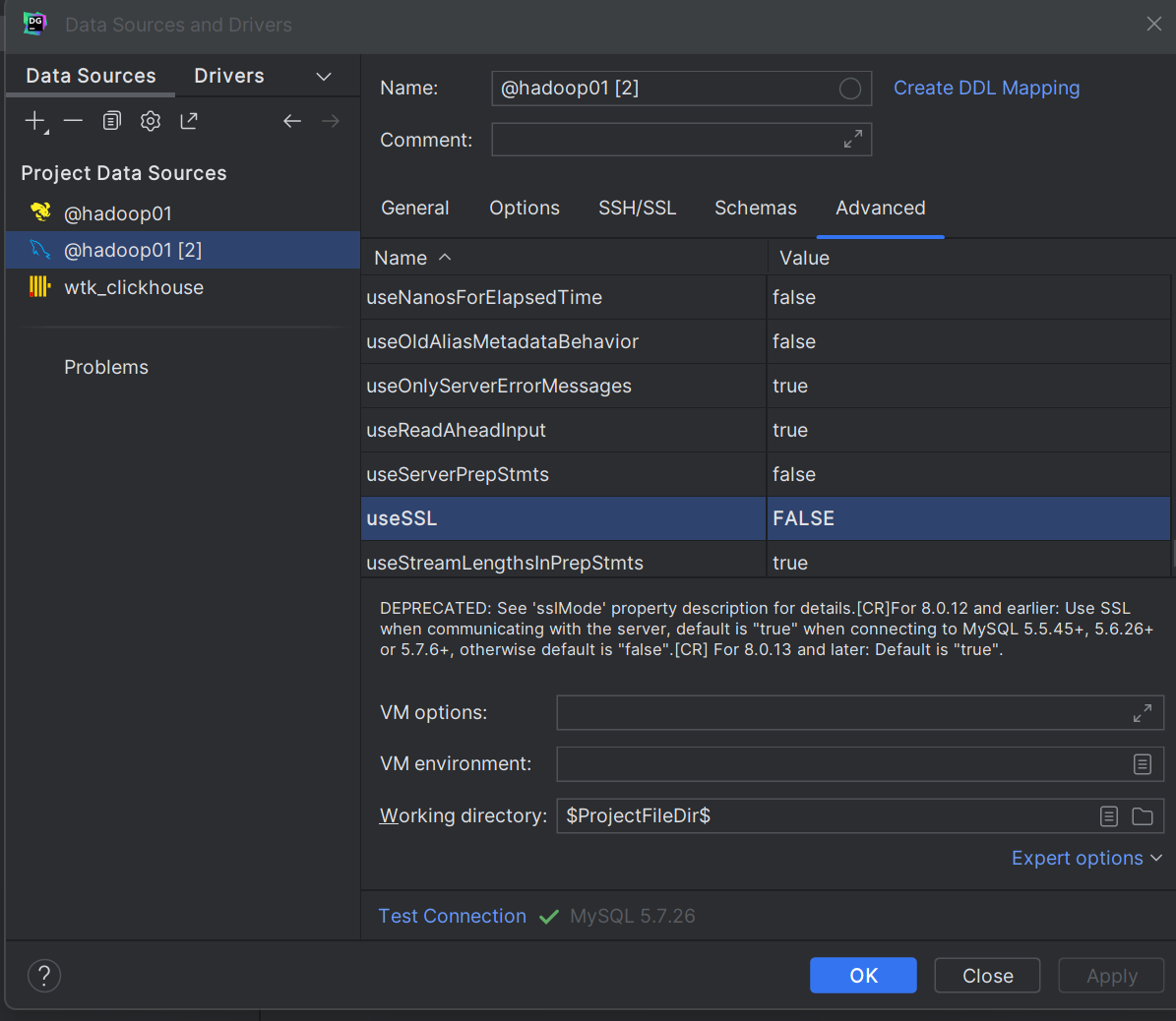
datagrip连接mysql问题5.7.26
1.Case sensitivity: plainmixed, delimitedexac Remote host terminated the handshake. 区分大小写:plain混合,分隔exac 远程主机终止了握手。 原因:usessl 参数用于指定是否使用 SSL(Secure Sockets Layer)加密来保护数据传…...

文件内容课堂总结
Spark-SQL连接Hive Apache Hive是Hadoop上的SQL引擎,Spark SQL编译时可选择是否包含Hive支持。包含Hive支持的版本支持Hive表访问、UDF及HQL。生产环境推荐编译时引入Hive支持。 内嵌Hive 直接使用无需配置,但生产环境极少采用。 外部Hive 需完成以下配置…...
探索亮数据Web Unlocker API:让谷歌学术网页科研数据 “触手可及”
本文目录 一、引言二、Web Unlocker API 功能亮点三、Web Unlocker API 实战1.配置网页解锁器2.定位相关数据3.编写代码 四、Web Scraper API技术亮点 五、SERP API技术亮点 六、总结 一、引言 网页数据宛如一座蕴藏着无限价值的宝库,无论是企业洞察市场动态、制定…...

AF3 create_alignment_db_sharded脚本process_chunk函数解读
AlphaFold3 create_alignment_db_sharded 脚本在源代码的scripts/alignment_db_scripts文件夹下。该脚本中的 process_chunk 函数通过调用 read_chain_dir 函数,读取每个链的多序列比对(MSA)文件并整理成统一格式的字典结构chunk_data 返回。 函数功能: read_chain_dir:读…...