本地缓存大杀器-Caffeine
本地缓存大杀器-Caffeine
- 一、 背景
- 二、 应用
- 三、 实现原理
- 四、 核心设计
- 五、 总结
一、 背景
1、 本地缓存作为一种高效的缓存方式,能够显著减少对远程数据源的访问,从而快速响应请求。而在众多本地缓存工具中,Caffine 凭借其卓越的性能和丰富的功能脱颖而出,成为开发者们的得力助手,堪称本地缓存的 “大杀器”。
2、 在传统的应用架构中,每次请求数据都可能需要从数据库、远程 API 等数据源获取,这不仅会增加网络延迟,还会对数据源造成较大压力。随着业务的发展,当并发请求量逐渐增大时,这种方式会导致系统响应缓慢,用户体验急剧下降。本地缓存的出现,很好地缓解了这些问题,它将经常被访问的数据存储在应用程序本地内存中,下次请求相同数据时,可直接从内存读取,大大提高了数据读取速度。
3、 不止用于加速数据查询场景,在某些序列化或者对象转换的场景也可用本地缓存做到对象复用。
二、 应用
maven项目在pom.xml文件中添加如下依赖:
<dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>3.1.8</version>
</dependency>
引入依赖后,就可以开始使用 Caffine 构建缓存实例。示例如下:
public static void main(String[] args) {// 淘汰监听Caffeine<Object, Object> caffeine = Caffeine.newBuilder().initialCapacity(1024) // 初始化容量,避免频繁扩容.weakKeys() // 弱引用的key,只有这一种选择,在gc时会被回收.softValues() // 软引用的值,有两种选择,soft or weak,soft时内存不足时回收.evictionListener((key, val, removalCause) -> {if (removalCause == RemovalCause.EXPLICIT) { // 移除事件} else if (removalCause == RemovalCause.SIZE) { // 容量超限事件} else if (removalCause == RemovalCause.REPLACED) { // 更新事件} else if (removalCause == RemovalCause.COLLECTED) { // 回收事件} else if (removalCause == RemovalCause.EXPIRED) { // 过期事件}// nothing})/*Executor 主要用于执行异步操作,例如异步加载缓存项、异步清理过期缓存项等。*/.executor(Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors() - 1)) // 执行调度任务的执行器,不传默认 ForkJoinPool.commonPool().recordStats() // 统计数据.ticker(Ticker.systemTicker()) // 提供时间的度量,使得缓存能够根据时间来判断缓存项是否过期、是否需要刷新等。/*DisabledScheduler:这是一个禁用调度功能的调度器。使用它时,Caffeine 不会主动调度过期缓存项的清理任务,只有在进行读写操作时才会顺便检查并清理过期项。场景:当你希望减少调度带来的开销,或者缓存项的过期清理不需要严格的定时控制时,可以使用该调度器。默认调度器。ExecutorServiceScheduler:允许你使用自定义的 ExecutorService 来执行调度任务。这意味着你可以根据自身的并发需求和性能要求,灵活配置线程池的大小和行为。场景:当你有特定的线程池配置需求,例如需要控制线程数量、线程优先级等,以满足复杂的并发场景时,可以使用该调度器。GuardedScheduler:用于对另一个调度器进行包装,提供额外的保护机制。它可以防止在调度任务执行过程中抛出异常,确保调度器的稳定性。场景:当你使用的底层调度器可能会抛出异常,而你希望避免这些异常影响整个缓存系统的正常运行时,可以使用该调度器。SystemScheduler:使用系统默认的调度机制,依赖于 Java 的 ScheduledExecutorService 来执行调度任务。它提供了一个简单、方便的默认调度方案。场景:当你没有特殊的调度需求,只需要一个基本的调度功能时,可以使用该调度器。*/.scheduler(Scheduler.guardedScheduler(new Scheduler() {@Overridepublic @NonNull Future<?> schedule(@NonNull Executor executor, @NonNull Runnable runnable, @Positive long l, @NonNull TimeUnit timeUnit) {return CompletableFuture.runAsync(runnable, executor);}})) // 调度器:控制缓存项的过期调度,也就是决定何时对过期的缓存项进行清理。.maximumSize(2048) // 基于大小的淘汰策略.weigher(Weigher.boundedWeigher(new Weigher<>() { // 权重计算@Overridepublic @NonNegative int weigh(@NonNull Object object, @NonNull Object object2) {return object2.toString().length();}})).maximumWeight(1000) // 基于权重的淘汰策略,这里需要实现权重的逻辑,上述两种策略二选一.expireAfterWrite(Duration.ofMinutes(3)) // 写之后多久过期.expireAfterAccess(Duration.ofMinutes(3)) // 访问(包括读取和写入)之后多久过期.expireAfter(new Expiry<Object, Object>() {// nanos@Overridepublic long expireAfterCreate(@NonNull Object object, @NonNull Object object2, long l) {return 1000 * 1000 * 60 * 3L;}@Overridepublic long expireAfterUpdate(@NonNull Object object, @NonNull Object object2, long l, @NonNegative long l1) {return 1000 * 1000 * 60 * 3L;}@Overridepublic long expireAfterRead(@NonNull Object object, @NonNull Object object2, long l, @NonNegative long l1) {return 1000 * 1000 * 60 * 3L;}}) // 自定义 Expiry 接口来控制每项的过期时间。可以根据不同的键值对设置不同的过期时间。;// 同步处理LoadingCache<Object, Object> cache = caffeine.build(new CacheLoader<Object, Object>() {@Overridepublic @Nullable Object load(@NonNull Object object) throws Exception {return null;}});cache.put(new Object(), new Object());cache.get(new Object());cache.getIfPresent(new Object());// 异步处理AsyncLoadingCache<Object, Object> asyncCache = caffeine.buildAsync(new AsyncCacheLoader<Object, Object>() {@Overridepublic @NonNull CompletableFuture<Object> asyncLoad(@NonNull Object object, @NonNull Executor executor) {return CompletableFuture.supplyAsync(()->{return null;});}});asyncCache.put(new Object(), CompletableFuture.completedFuture(new Object()));asyncCache.getIfPresent(new Object());}
三、 实现原理
1、 Caffine 的高性能得益于其巧妙的实现原理。它采用了分段锁(Striped Locking)和分段哈希表(Striped Hash Table)的设计,大大减少了锁竞争,提高了并发性能。在多线程环境下,多个线程可以同时访问不同的分段,从而避免了单一锁带来的性能瓶颈。
2、 Caffine 在缓存淘汰策略方面也做了深入优化。它默认采用的是 W-TinyLFU 算法,这是一种结合了时间(Time)和频率(Frequency)的高效淘汰算法。该算法会记录数据的访问频率和时间,优先淘汰访问频率低且时间较久的数据。同时,Caffine 还提供了其他多种淘汰策略供开发者选择,如 LRU(最近最少使用)、LFU(最不经常使用)等,开发者可以根据实际业务需求进行配置。
3、 在数据加载方面,Caffine 支持异步加载和同步加载两种方式。异步加载可以在数据过期或缺失时,在后台线程中加载数据,避免了阻塞请求线程,提高了系统的响应速度。同步加载则适用于对数据一致性要求较高的场景,确保在获取数据时,数据已经被正确加载到缓存中。
四、 核心设计
1、 Caffine 的核心设计围绕着性能、易用性和灵活性展开。其架构设计使得缓存操作尽可能高效,减少不必要的开销。缓存的存储结构采用了高效的数据结构,如哈希表和双向链表等,保证了数据的快速插入、查询和删除操作。
在功能设计上,Caffine 提供了丰富的接口和配置选项,满足不同开发者和业务场景的需求。无论是简单的缓存存储,还是复杂的缓存过期、淘汰、刷新等功能,都能通过简洁的 API 实现。同时,Caffine 还支持与 Spring Cache 等框架的集成,方便在企业级应用中快速应用。
Caffine 对内存的管理也十分精细。它通过一系列优化策略,如弱引用(Weak Reference)、软引用(Soft Reference)等,合理控制缓存占用的内存大小,避免内存泄漏和过度占用,确保应用程序在长时间运行过程中保持稳定的性能。
五、 总结
1、 Caffine 作为一款强大的本地缓存工具,凭借其出色的性能、丰富的功能和灵活的设计,成为了开发者提升应用性能的重要选择。它在减少数据访问延迟、提高系统并发能力等方面表现卓越,能够有效降低对远程数据源的依赖,提升用户体验。
2、 无论是小型应用还是大型企业级项目,Caffine 都能发挥重要作用。在使用过程中,开发者可以根据实际业务需求,合理配置缓存的各种参数,选择合适的淘汰策略和数据加载方式,以达到最佳的缓存效果。
3、 随着技术的不断发展,相信 Caffine 会持续优化和完善,为开发者带来更多便利,在本地缓存领域继续发挥其 “大杀器” 的作用,助力各类应用程序实现更高效、更快速的发展。
今天很晚了,后续源码分析待定。
相关文章:

本地缓存大杀器-Caffeine
本地缓存大杀器-Caffeine 一、 背景二、 应用三、 实现原理四、 核心设计五、 总结 一、 背景 1、 本地缓存作为一种高效的缓存方式,能够显著减少对远程数据源的访问,从而快速响应请求。而在众多本地缓存工具中,Caffine 凭借其卓越的性能和丰…...
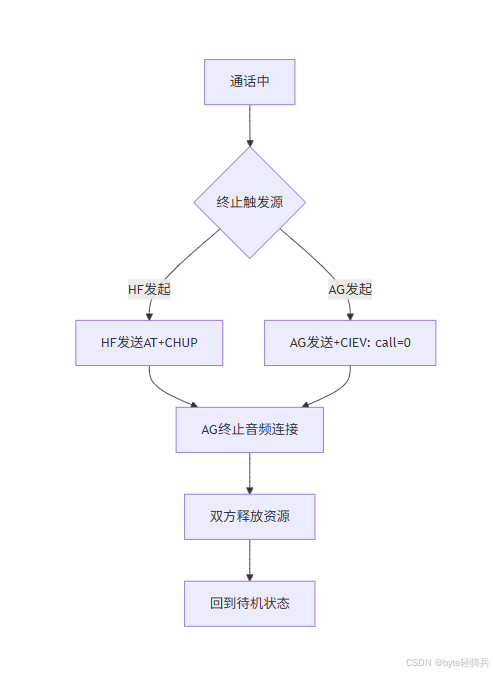
【HFP】蓝牙语音通话控制深度解析:来电拒接与通话终止协议
目录 一、来电拒接的核心流程与信令交互 1.1 拒接场景的分类与触发条件 1.2 HF 端拒接流程 1.3 AG 端拒接流程 二、通话终止流程:主动断开与异常中断 2.1 终止场景的界定 2.2 HF 端终止流程 2.3 AG 端终止流程 三、信令协议的核心要素:AT 命令与…...
使用QML Tumbler 实现时间日期选择器
目录 引言相关阅读项目结构示例实现与代码解析示例一:时间选择器(TimePicker)示例二:日期时间选择器(DateTimePicker) 主窗口整合运行效果总结下载链接 引言 在现代应用程序开发中,时间与日期选…...
智能吸顶灯/摄影补光灯专用!FP7195双通道LED驱动,高效节能省空间 !
一、双路调光技术背景与市场需求 随着LED照明技术的快速发展和智能照明需求的激增,双路调光技术正成为照明行业的重要发展方向。传统单路调光方案只能实现整体亮度的统一调节,而双路调光则能够实现对两个独立通道的精确控制。今天,由我来为大…...

如何解决PyQt从主窗口打开新窗口时出现闪退的问题
在PyQt5中,当从主窗口打开新窗口时,经常会出现闪退现象,这通常是由于对象生命周期管理不当或事件循环错误等所导致。 1. 确保新窗口实例被正确引用 新窗口的实例若未被主窗口引用,可能会被Python的垃圾回收机制销毁。 错误示例&…...

分布式微服务架构,数据库连接池设计策略
在分布式微服务架构中,数据库连接池的设计远比单体应用复杂,涉及资源隔离、连接管理、性能调优和高可用等问题。下面是面向专业软件架构师的系统化分析与策略建议: 一、核心挑战 每个服务独立运行,连接池分散 每个微服务维护自己的…...
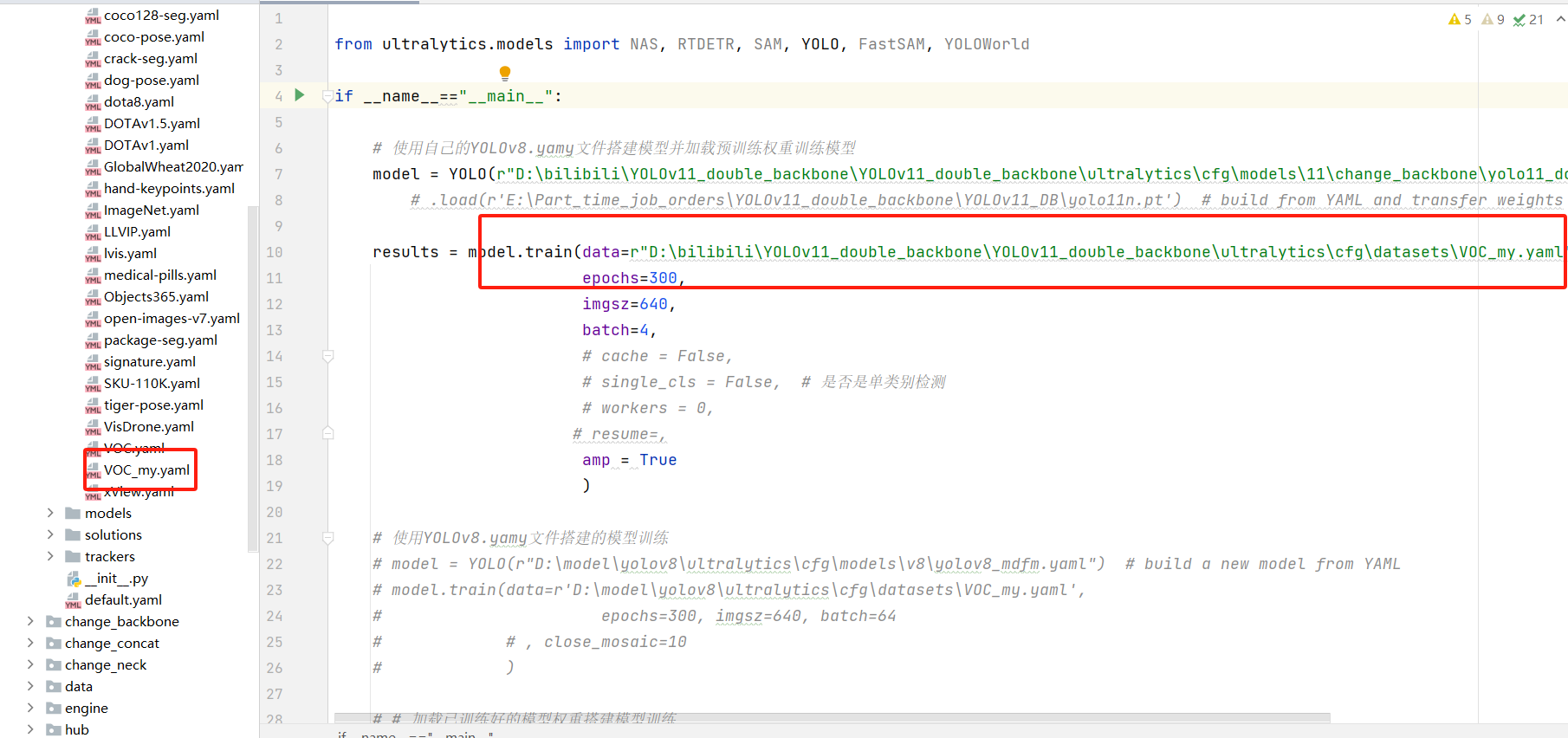
YOLOv11改进-双Backbone架构:利用双backbone提高yolo11目标检测的精度
一、引言:为什么我们需要双Backbone? 在目标检测任务中,YOLO系列模型因其高效的端到端检测能力而备受青睐。然而,传统YOLO模型大多采用单一Backbone结构,即利用一个卷积神经网络(CNN)作为特征提…...

redis经典问题
1.缓存雪崩 指缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。 解决方案: 1)Redis 高可用,主从哨兵,Redis cluster,避免全盘崩…...

《逃离云端束缚,拥抱GPT本地部署》
《逃离云端束缚,拥抱GPT本地部署》 一、GPT 热潮与本地部署的兴起 自 OpenAI 推出 ChatGPT 以来,全球范围内掀起了一股人工智能的热潮,其强大的自然语言处理能力和广泛的应用场景,让人们对人工智能的未来充满了想象。GPT(Generative Pretrained Transformer)作为一种基于…...
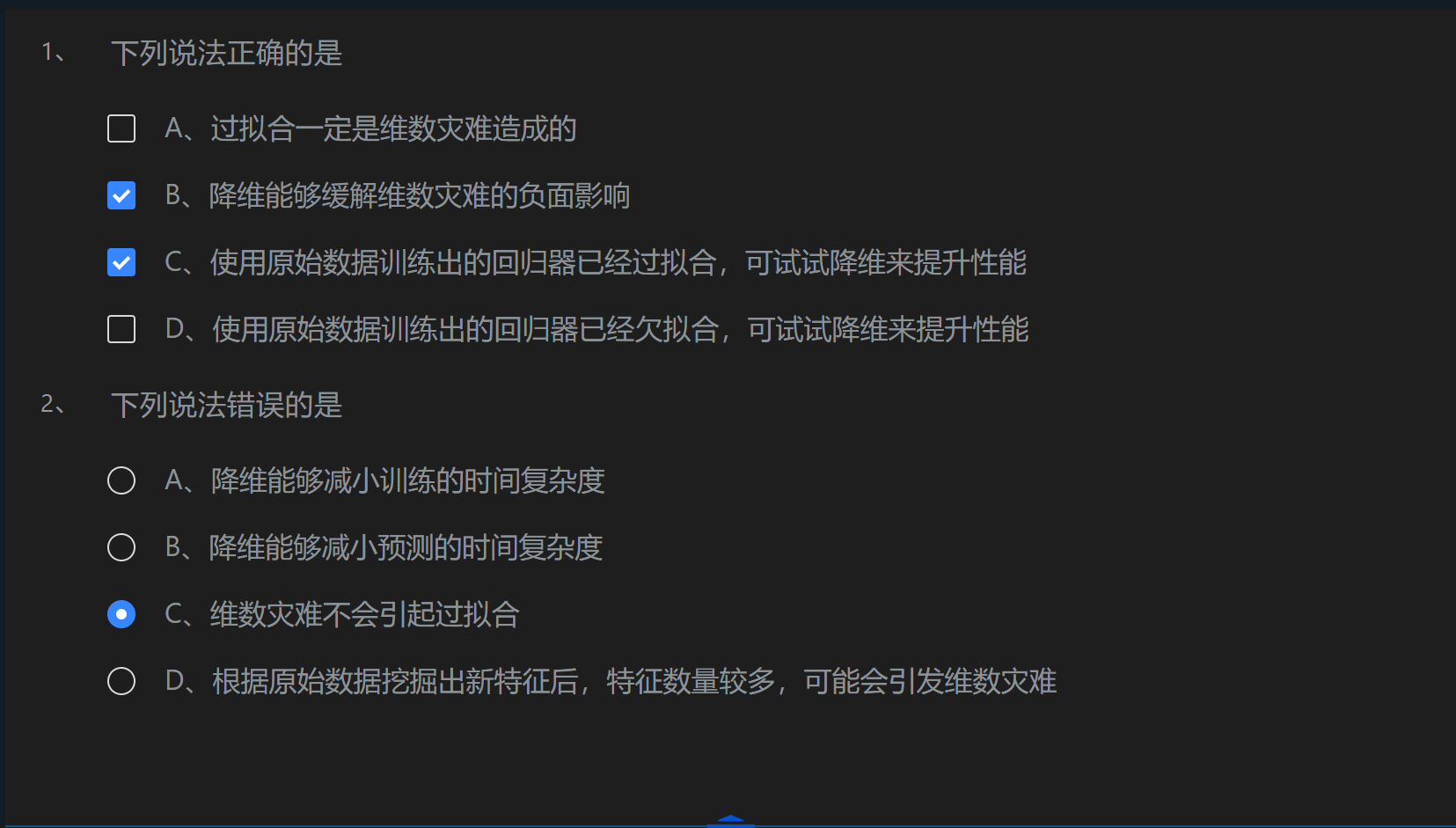
头歌之动手学人工智能-机器学习 --- PCA
目录 第1关:维数灾难与降维 第2关:PCA算法流程 任务描述 编程要求 测试说明 第3关:sklearn中的PCA 任务描述 编程要求 测试说明 第1关:维数灾难与降维 第2关:PCA算法流程 任务描述 本关任务:补充…...
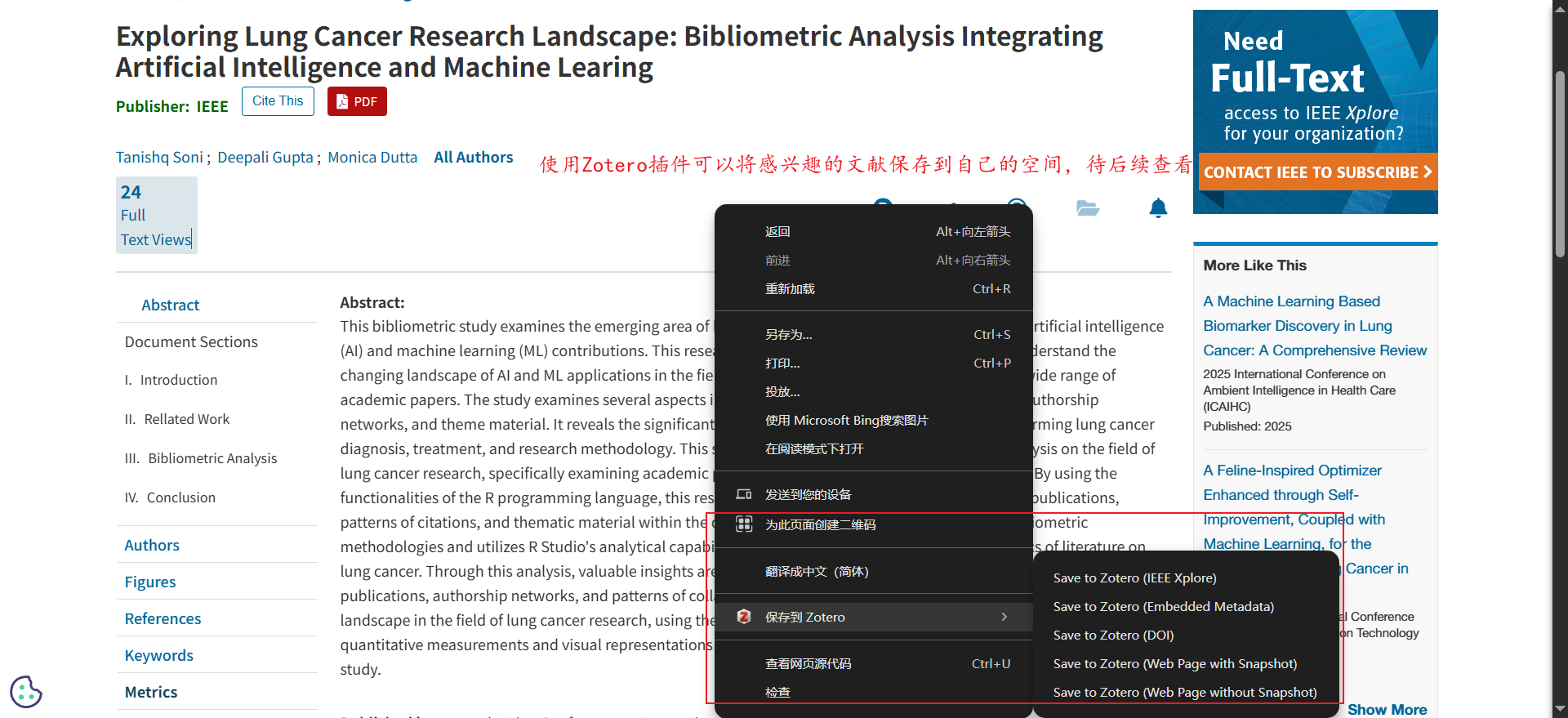
研0调研入门
一、Web of Science 使用教程 1. 访问与注册 访问入口:通过高校图书馆官网进入(需IP权限),或直接访问 Web of Science官网。注册/登录:若机构已订阅,用学校账号登录;个人用户可申请试用或付费…...
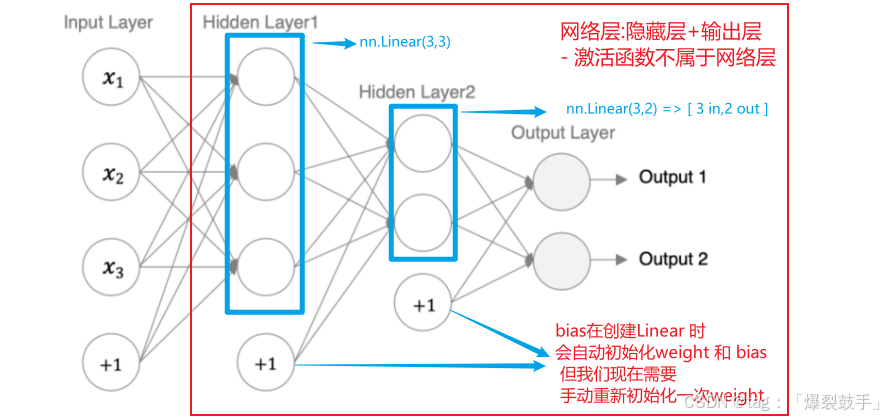
神经网络基础[ANN网络的搭建]
神经网络 人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。各个神经元传递复杂的电信号,树突接收到输入信号…...
五、web自动化测试01
目录 一、HTML基础1、HTML介绍2、常用标签3、基础案例3.1 前端代码3.2 自动化测试 二、CSS定位1、css介绍2、案例3、代码优化 三、表单自动化1、案例2、元素属性定位 四、后台基础数据自动化1、登录1.1 id与class定位1.2 定位一组元素 2、商品新增 一、HTML基础 可参考学习 链…...
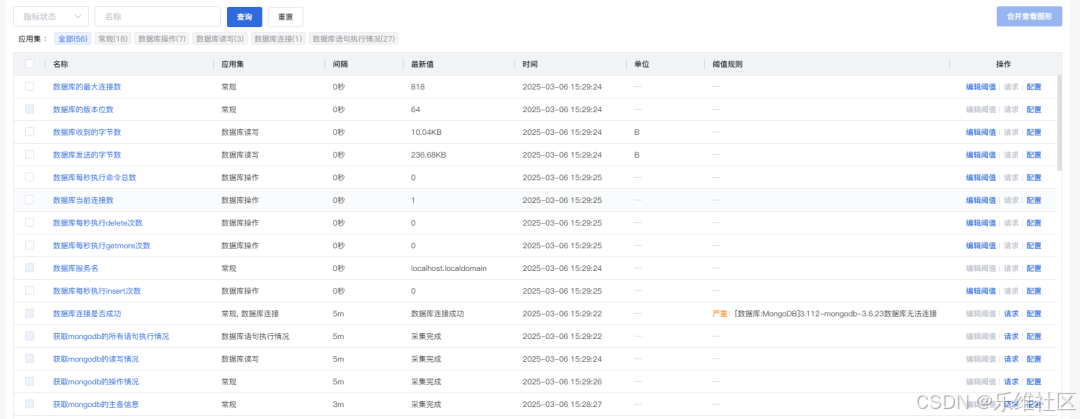
数据库监控 | MongoDB监控全解析
PART 01 MongoDB:灵活、可扩展的文档数据库 MongoDB作为一款开源的NoSQL数据库,凭借其灵活的数据模型(基于BSON的文档存储)、水平扩展能力(分片集群)和高可用性(副本集架构)&#x…...
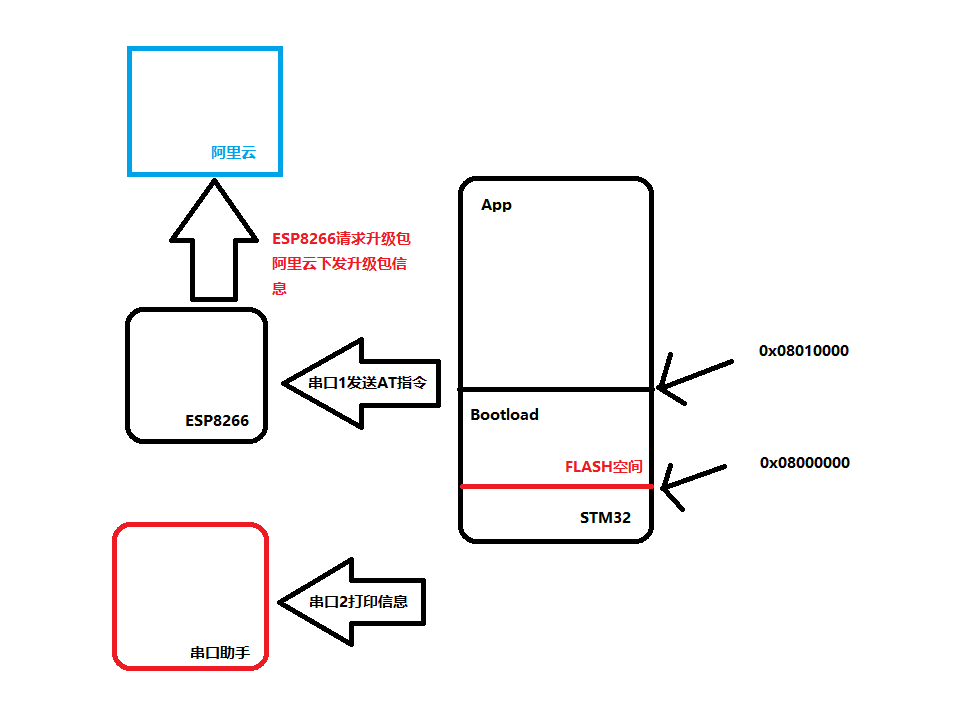
STM32F407使用ESP8266实现阿里云OTA(中)
文章目录 前言一、程序分析二、程序讲解1. main函数2. Get_Version()函数3. esp_Init()函数4. Check_Updata()函数结语前言 从上一章STM32F407使用ESP8266实现阿里云OTA(上)中我们已经对连接阿里云和从阿里云获取升级包的流程非常的熟悉了。所以本章我们进行STM32的程序开发…...

sql server 与navicat测试后,连接qt
先用Navicat测试和sql的连通性,Navicat和sql连通之后,qt也能和sql连通了。 Navicat和Sqlserver Management 能连上,项目无法连接本地 Navicat 连接SQLServer 数据库 QT国内镜像网站 Navicat连接SqlServer的问题点 Sql Server的基本配置以及使…...

Django 入门实战:从环境搭建到构建你的第一个 Web 应用
Django 入门实战:从环境搭建到构建你的第一个 Web 应用 恭喜你选择 Django 作为你学习 Python Web 开发的起点!Django 是一个强大、成熟且功能齐全的框架,非常适合构建中大型的 Web 应用程序。本篇将通过一个简单的例子,带你走完…...

ROS2---时间戳对齐
一、ROS2时间系统架构 时间模型 仿真时间(Simulation Time):由/clock话题驱动,适用于离线仿真与调试。真实时间(Real Time):基于系统硬件时钟,支持PTP协议(IEEE 1588&…...

Sublime Text相关设置
一直知道Sublime Text的自由度很高,但是之前使用从未更改过配置,有一天突然想改改设置试一下,感觉打开了新大陆,特此记录一下 设置默认语法 单击 Tools→Developer→New Snippet 弹出一个窗口,把下面这段代码粘贴进去…...
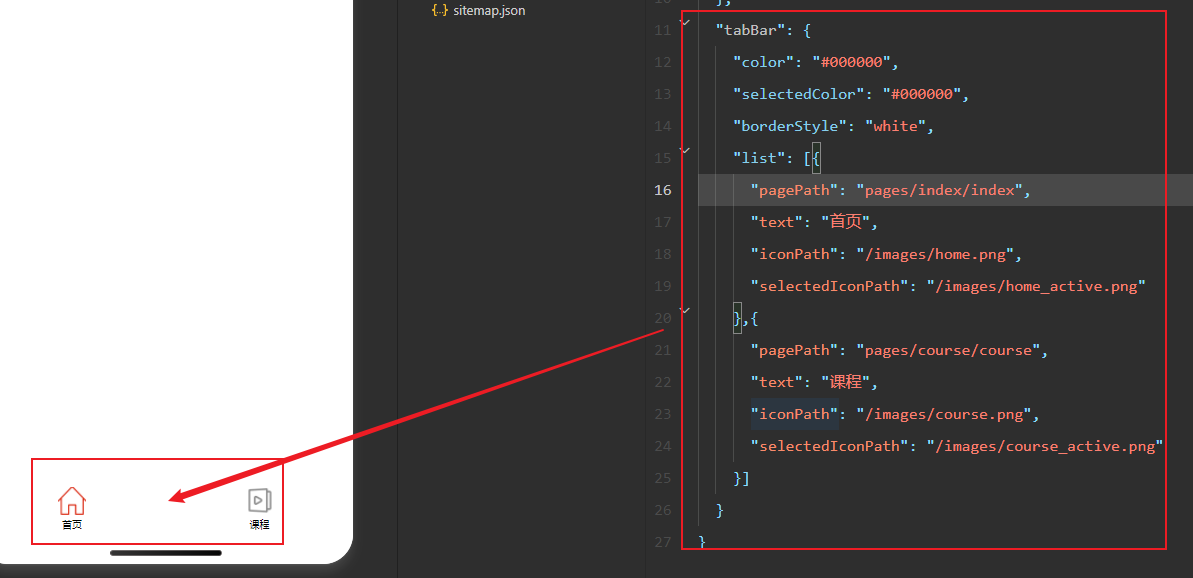
微信小程序 tabbar底部导航栏
官方文档:https://developers.weixin.qq.com/miniprogram/dev/reference/configuration/app.html#tabBar 一、常规菜单格式 在app.json 文件中配置,其他关键点详见官方文档,后续更新不规则图标的写法...

【Maven】项目管理工具
Maven:一个项目管理工具 前言 传统项目管理存在的问题: 依赖管理混乱 需要自己去网上搜 jar 包,找对版本很痛苦(还容易找错)某个库依赖另一个库(传递依赖),你得自己挨个找齐不小心…...

多线程事务?拿捏!
场景:有一批1万或者10万数据,插入数据库,怎么做 事务中进行批量提交 publList<List<OrderPo>> partition Lists.partition(list, 450);StopWatch stopWatch new StopWatch();stopWatch.start();// 顺序插入for (List<OrderPo> sub…...

Unity InputSystem触摸屏问题
最近把Unity打包后的windows软件放到windows触摸屏一体机上测试,发现部分屏幕触摸点击不了按钮,测试了其他应用程序都正常。 这个一体机是这样的,一个电脑机箱,外接一个可以触摸的显示屏,然后UGUI的按钮就间歇性点不了…...

Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要 Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚…...
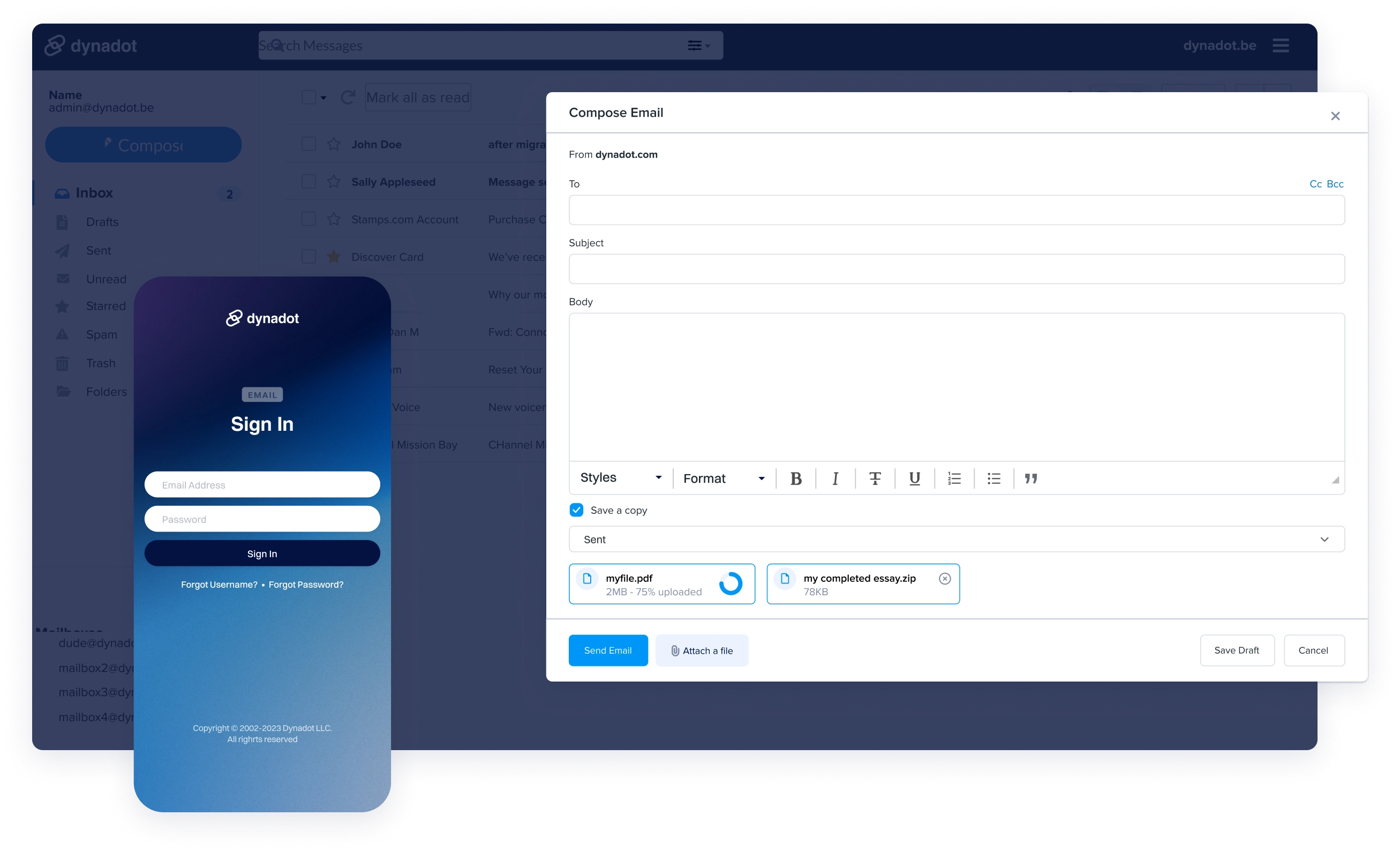
免费版还是专业版?Dynadot 域名邮箱服务选择指南
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...
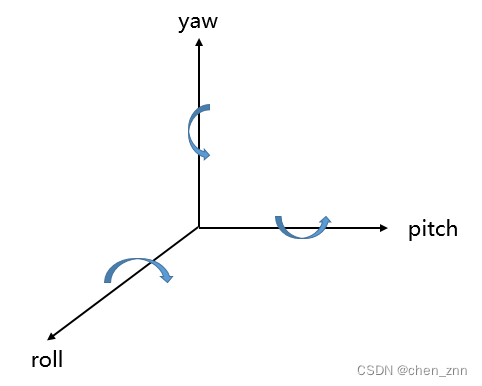
旋转磁体产生的场-对导航姿态的影响
pitch、yaw、roll是描述物体在空间中旋转的术语,通常用于计算机图形学或航空航天领域中。这些术语描述了物体绕不同轴旋转的方式: Pitch(俯仰):绕横轴旋转,使物体向前或向后倾斜。俯仰角度通常用来描述物体…...

动态哈希映射深度指南:从基础到高阶实现与优化
哈希表是计算机科学中最高效的数据结构之一,而动态哈希映射通过智能扩容机制,在实时系统中展现出极强的适应性。本文将深入探讨其实现细节,结合主流框架源码解析,并给出可落地的性能优化方案。 一、动态哈希的数学本质 1. 哈希函…...
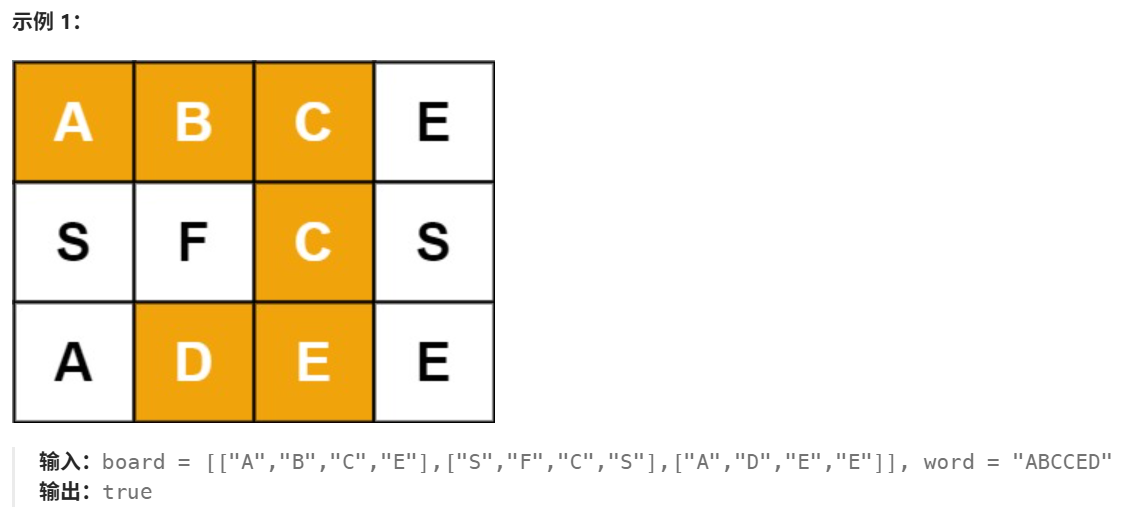
Day11(回溯法)——LeetCode79.单词搜索
1 前言 今天主要刷了一道热题榜中回溯法的题,现在的计划是先刷热题榜专题吧,感觉还是这样见效比较快。因此本文主要介绍LeetCode79。 2 LeetCode79.单词搜索(LeetCode79) OK题目描述及相关示例如下: 2.1 题目分析解决及优化 感觉回溯的方…...
)
高精度并行2D圆弧拟合(C++)
依赖库 Eigen3 GLM Ceres-2.1.0 glog-0.6.0 gflag-2.2.2 基本思路 Step 1: RANSAC找到圆弧,保留inliers点; Step 2:使用ceres非线性优化的方法,拟合inliers点,得到圆心和半径; -------…...

Linux端口占用问题排查与解决
在 Linux 中,当遇到端口被占用的情况(如你遇到的 8000 端口),可以通过以下步骤查看并处理: 1. 查看占用端口的进程 使用 netstat 或 ss 命令(推荐 ss,更现代): sudo netstat -tulnp | grep :8000 # 或 sudo ss -tulnp | grep :8000输出示例: tcp 0 0 0.0.0.0:…...