《逃离云端束缚,拥抱GPT本地部署》
《逃离云端束缚,拥抱GPT本地部署》

一、GPT 热潮与本地部署的兴起
自 OpenAI 推出 ChatGPT 以来,全球范围内掀起了一股人工智能的热潮,其强大的自然语言处理能力和广泛的应用场景,让人们对人工智能的未来充满了想象。GPT(Generative Pretrained Transformer)作为一种基于 Transformer 架构的预训练语言模型,通过在大规模文本数据上的训练,能够生成高质量的自然语言文本,无论是撰写文章、回答问题,还是进行对话交互,都表现出惊人的能力。
ChatGPT 在短短几个月内就吸引了数亿用户,成为了科技领域的焦点。它的出现,不仅改变了人们与计算机交互的方式,也为众多行业带来了新的机遇和变革。从内容创作到客户服务,从教育到医疗,GPT 的应用正在逐渐渗透到各个领域。在内容创作方面,它可以快速生成新闻报道、小说、诗歌等,为创作者提供灵感和素材;在客户服务领域,它能够实时回答用户的问题,提供高效的解决方案,大大提高了服务效率和质量。
随着 GPT 的广泛应用,数据安全和隐私问题也日益受到关注。许多企业和个人担心,将数据发送到云端进行处理,可能会面临数据泄露和隐私侵犯的风险。此外,网络连接的稳定性和延迟也会影响 GPT 的使用体验。在一些网络条件较差的地区,用户可能会遇到响应缓慢甚至无法连接的问题。为了解决这些问题,本地部署的概念应运而生。
本地部署,即将 GPT 模型部署在本地的服务器或计算机上,用户可以在本地环境中运行模型,无需依赖云端服务。这样一来,数据的安全性和隐私性得到了更好的保障,用户可以完全掌控自己的数据,不用担心数据被泄露或滥用。同时,本地部署还可以提高模型的响应速度,减少网络延迟的影响,提升用户体验。尤其是对于一些对数据安全要求较高的行业,如金融、医疗、政府等,本地部署具有更大的吸引力。在金融领域,银行和证券机构需要处理大量的客户敏感信息,本地部署可以确保这些信息不会被泄露出去,保护客户的利益;在医疗行业,患者的病历和健康数据属于高度隐私信息,本地部署可以为这些数据提供更安全的存储和处理环境。
二、本地部署 GPT,你不可不知的优势
(一)数据隐私与安全
在数字化时代,数据已成为企业和个人最宝贵的资产之一。对于许多组织来说,数据的安全性和隐私性至关重要。当使用云端的 GPT 服务时,数据需要上传到远程服务器进行处理,这就意味着数据脱离了用户的直接控制范围。一旦云服务提供商的系统遭受攻击,或者出现内部管理不善的情况,数据泄露的风险就会大大增加。
以一家金融机构为例,它们每天都要处理大量的客户交易数据、个人身份信息和财务状况数据。这些数据包含了客户的敏感信息,如果被泄露,不仅会给客户带来巨大的损失,还会严重损害金融机构的声誉和信誉。根据相关数据显示,一次严重的数据泄露事件可能导致企业面临数百万甚至数亿美元的损失,包括法律赔偿、客户流失和品牌形象受损等。
而本地部署 GPT 则可以有效避免这些风险。所有的数据处理都在本地的服务器或计算机上进行,数据无需离开本地网络,从而最大程度地保护了数据的隐私和安全。企业可以根据自身的安全策略和要求,对本地服务器进行严格的访问控制和安全防护措施,如设置防火墙、加密数据存储、定期进行安全审计等,确保数据不被非法获取或篡改。
(二)成本效益分析
从成本角度来看,本地部署 GPT 在长期使用中具有显著的优势。云端使用 GPT 通常采用按次付费或订阅的模式,随着使用量的增加,费用也会相应地不断攀升。对于一些使用频率较高的企业或个人来说,这可能会成为一笔不小的开支。
例如,一家小型内容创作公司,每天需要使用 GPT 生成大量的文章、文案和创意内容。如果使用云端的 GPT 服务,按照每次调用的费用计算,每月的费用可能高达数千元甚至上万元。而且,随着业务的增长,使用量的增加,费用还会进一步上升。
而本地部署虽然在初期需要投入一定的硬件和软件成本,如购买服务器、显卡、存储设备等硬件,以及获取相关的软件许可。但是从长期来看,一旦部署完成,除了硬件的维护和电力消耗等少量成本外,几乎没有其他额外的费用。对于大型企业来说,它们可以利用现有的数据中心基础设施,进一步降低本地部署的成本。通过合理规划和配置硬件资源,企业可以实现资源的高效利用,提高性价比。
(三)摆脱网络限制
在一些特殊场景下,网络连接可能不稳定甚至无法连接,这时候云端的 GPT 服务就无法正常使用。而本地部署的 GPT 则不受网络限制,即使在没有网络的环境下,也能稳定运行,为用户提供持续的服务。
比如在偏远地区的野外作业、海上航行的船只、地下矿井等网络信号薄弱或没有网络的地方,本地部署的 GPT 可以为工作人员提供及时的帮助和支持。在野外地质勘探中,地质学家可以使用本地部署的 GPT 对采集到的地质数据进行分析和解释,获取相关的地质信息和结论;在海上航行的船只上,船员可以利用本地部署的 GPT 进行气象预测、航线规划和故障诊断等工作,确保航行的安全和顺利。
此外,对于一些对实时性要求较高的应用场景,如在线客服、智能语音助手等,网络延迟可能会影响用户体验。本地部署的 GPT 可以直接在本地设备上运行,减少了数据传输的时间,大大提高了响应速度,能够实现快速的交互和反馈,提升用户的满意度 。在在线客服场景中,用户的问题可以立即得到本地 GPT 的回答,无需等待网络传输和云端处理的时间,提高了服务效率和客户满意度。
三、开启本地部署之旅:准备工作
(一)硬件要求解析
本地部署 GPT 对硬件的要求较高,不同规模的模型对硬件的需求也有所不同。对于小型的 GPT 模型,如 GPT-2 的较小版本,可能只需要一台普通的计算机即可满足基本需求。然而,对于大型的 GPT 模型,如 GPT-3 或更高级的版本,就需要强大的计算资源来支持。
首先是 CPU,它在模型的运行中起着关键作用。虽然 GPU 在深度学习计算中占据主导地位,但 CPU 负责管理和协调整个系统的运行,包括数据的预处理、模型的加载和调度等。对于小型模型,一款中高端的多核心 CPU,如英特尔酷睿 i7 或 AMD 锐龙 7 系列,通常能够提供足够的处理能力。这些 CPU 具有较高的时钟频率和多核心架构,可以同时处理多个任务,确保模型在运行过程中不会因为 CPU 性能不足而出现卡顿或延迟。
而对于大型模型,由于需要处理海量的数据和复杂的计算任务,对 CPU 的性能要求就更高了。一般建议选择服务器级别的 CPU,如英特尔至强系列或 AMD 霄龙系列。这些 CPU 具有更多的核心数和更高的缓存容量,能够在多线程任务中表现出色。它们还支持更高级的技术,如超线程技术和睿频加速技术,可以进一步提升性能。在处理大规模的文本数据时,服务器级 CPU 能够快速地进行数据的读取、解析和预处理,为 GPU 提供充足的数据供应,保证模型的高效运行。
GPU 是本地部署 GPT 的核心硬件之一,其性能直接影响到模型的训练和推理速度。GPU 的并行计算能力使其非常适合处理深度学习中的矩阵运算和复杂的数学计算。对于小型模型,一块中高端的消费级 GPU,如 NVIDIA GeForce RTX 3060 或 AMD Radeon RX 6650 XT,就可以满足需求。这些 GPU 具有较高的显存带宽和 CUDA 核心数,能够在合理的时间内完成模型的推理任务。以 RTX 3060 为例,它拥有 8GB 的 GDDR6 显存和 3584 个 CUDA 核心,在处理一些小型的自然语言处理任务时,能够快速地生成文本结果,为用户提供及时的响应。
对于大型模型,如拥有数十亿甚至数万亿参数的 GPT 模型,就需要专业的高端 GPU 或多个 GPU 组成的集群来提供足够的计算能力。NVIDIA A100 和 H100 等专业级 GPU 是不错的选择。A100 采用了 NVIDIA 的安培架构,拥有 80GB 的 HBM2e 显存和 6912 个 CUDA 核心,能够提供强大的计算性能。在处理大规模的语言模型时,A100 可以显著缩短训练时间,提高模型的训练效率。如果单个 GPU 的性能仍然无法满足需求,可以考虑使用多个 GPU 组成的集群,通过并行计算来进一步提升计算能力。在一些大型的数据中心中,会使用多个 A100 GPU 组成的集群来进行 GPT 模型的训练和推理,以满足大规模业务的需求。
内存也是影响模型运行的重要因素。足够的内存可以确保模型的参数和数据能够被快速加载和访问,提高模型的运行效率。对于小型模型,16GB 或 32GB 的内存通常是足够的。在这个内存容量下,模型可以顺利地加载和运行,不会出现内存不足的情况。当处理一些简单的文本生成任务时,16GB 内存的计算机可以快速地将模型参数加载到内存中,并在推理过程中及时处理输入数据,生成输出文本。
而对于大型模型,由于模型参数众多,数据量庞大,需要的内存就更多了。一般建议配置 64GB 以上的内存,甚至 128GB 或更高。在处理拥有数十亿参数的 GPT 模型时,64GB 的内存可能仍然会显得捉襟见肘,而 128GB 或更高的内存可以确保模型在运行过程中不会因为内存不足而出现性能下降或错误。一些研究机构在进行大型模型的训练时,会配置 256GB 甚至 512GB 的内存,以保证模型能够稳定高效地运行。
存储方面,需要有足够的空间来存储模型文件、数据集和中间计算结果。高速的固态硬盘(SSD)是首选,因为它可以提供更快的数据读写速度,减少数据加载的时间。对于小型模型,500GB 或 1TB 的 SSD 通常可以满足需求。这些存储空间可以存储模型文件、少量的数据集以及在运行过程中产生的中间结果。当模型进行训练时,SSD 可以快速地读取训练数据,将其传输到内存中供模型使用,同时也能够快速地将训练过程中产生的中间结果保存下来。
对于大型模型,由于数据集和模型文件都非常大,可能需要多个 TB 的存储空间。此时,可以考虑使用企业级的 SSD 阵列或网络附加存储(NAS)设备。这些存储设备不仅提供了更大的存储空间,还具有更高的可靠性和数据传输速度。一些大型企业在进行 GPT 模型的本地部署时,会使用由多个 SSD 组成的阵列,总存储容量可以达到数十 TB 甚至数百 TB,以满足大规模数据存
相关文章:
《逃离云端束缚,拥抱GPT本地部署》
《逃离云端束缚,拥抱GPT本地部署》 一、GPT 热潮与本地部署的兴起 自 OpenAI 推出 ChatGPT 以来,全球范围内掀起了一股人工智能的热潮,其强大的自然语言处理能力和广泛的应用场景,让人们对人工智能的未来充满了想象。GPT(Generative Pretrained Transformer)作为一种基于…...
头歌之动手学人工智能-机器学习 --- PCA
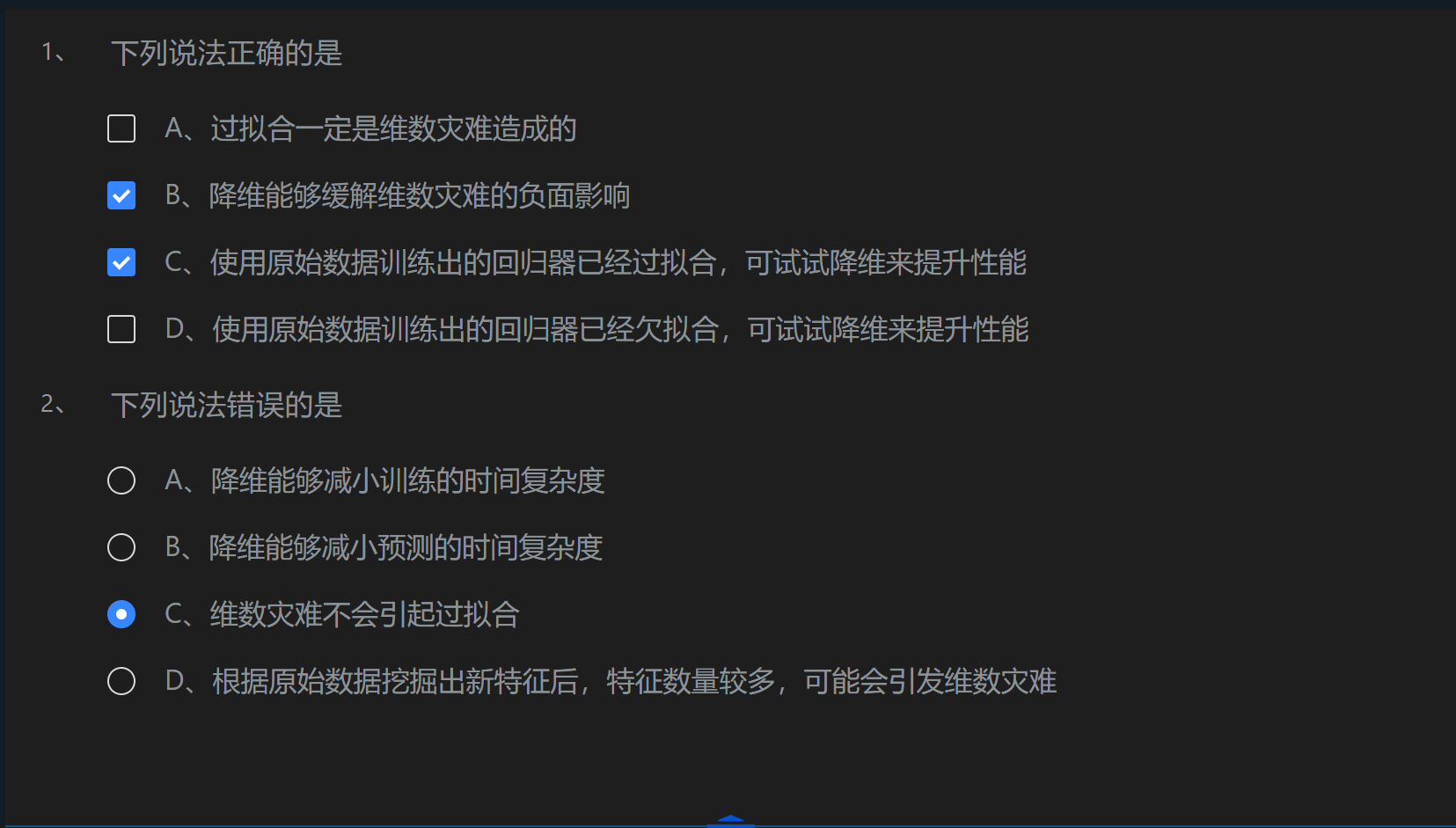
目录 第1关:维数灾难与降维 第2关:PCA算法流程 任务描述 编程要求 测试说明 第3关:sklearn中的PCA 任务描述 编程要求 测试说明 第1关:维数灾难与降维 第2关:PCA算法流程 任务描述 本关任务:补充…...
研0调研入门
一、Web of Science 使用教程 1. 访问与注册 访问入口:通过高校图书馆官网进入(需IP权限),或直接访问 Web of Science官网。注册/登录:若机构已订阅,用学校账号登录;个人用户可申请试用或付费…...
神经网络基础[ANN网络的搭建]
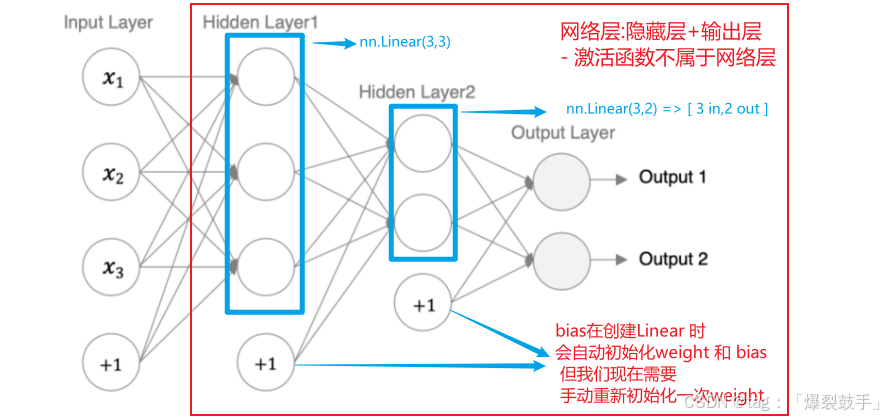
神经网络 人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的计算模型。各个神经元传递复杂的电信号,树突接收到输入信号…...
五、web自动化测试01
目录 一、HTML基础1、HTML介绍2、常用标签3、基础案例3.1 前端代码3.2 自动化测试 二、CSS定位1、css介绍2、案例3、代码优化 三、表单自动化1、案例2、元素属性定位 四、后台基础数据自动化1、登录1.1 id与class定位1.2 定位一组元素 2、商品新增 一、HTML基础 可参考学习 链…...
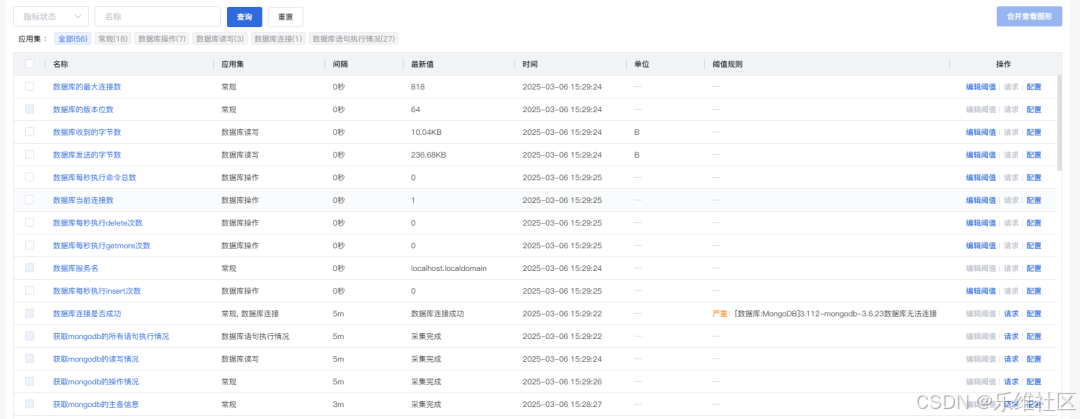
数据库监控 | MongoDB监控全解析
PART 01 MongoDB:灵活、可扩展的文档数据库 MongoDB作为一款开源的NoSQL数据库,凭借其灵活的数据模型(基于BSON的文档存储)、水平扩展能力(分片集群)和高可用性(副本集架构)&#x…...
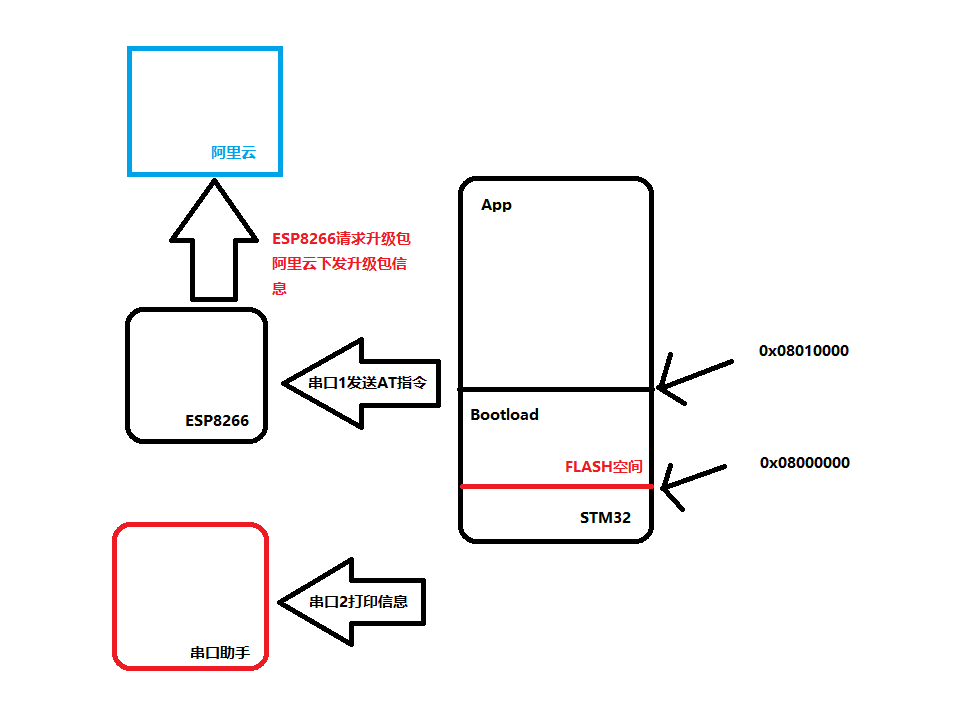
STM32F407使用ESP8266实现阿里云OTA(中)
文章目录 前言一、程序分析二、程序讲解1. main函数2. Get_Version()函数3. esp_Init()函数4. Check_Updata()函数结语前言 从上一章STM32F407使用ESP8266实现阿里云OTA(上)中我们已经对连接阿里云和从阿里云获取升级包的流程非常的熟悉了。所以本章我们进行STM32的程序开发…...

sql server 与navicat测试后,连接qt
先用Navicat测试和sql的连通性,Navicat和sql连通之后,qt也能和sql连通了。 Navicat和Sqlserver Management 能连上,项目无法连接本地 Navicat 连接SQLServer 数据库 QT国内镜像网站 Navicat连接SqlServer的问题点 Sql Server的基本配置以及使…...

Django 入门实战:从环境搭建到构建你的第一个 Web 应用
Django 入门实战:从环境搭建到构建你的第一个 Web 应用 恭喜你选择 Django 作为你学习 Python Web 开发的起点!Django 是一个强大、成熟且功能齐全的框架,非常适合构建中大型的 Web 应用程序。本篇将通过一个简单的例子,带你走完…...

ROS2---时间戳对齐
一、ROS2时间系统架构 时间模型 仿真时间(Simulation Time):由/clock话题驱动,适用于离线仿真与调试。真实时间(Real Time):基于系统硬件时钟,支持PTP协议(IEEE 1588&…...

Sublime Text相关设置
一直知道Sublime Text的自由度很高,但是之前使用从未更改过配置,有一天突然想改改设置试一下,感觉打开了新大陆,特此记录一下 设置默认语法 单击 Tools→Developer→New Snippet 弹出一个窗口,把下面这段代码粘贴进去…...
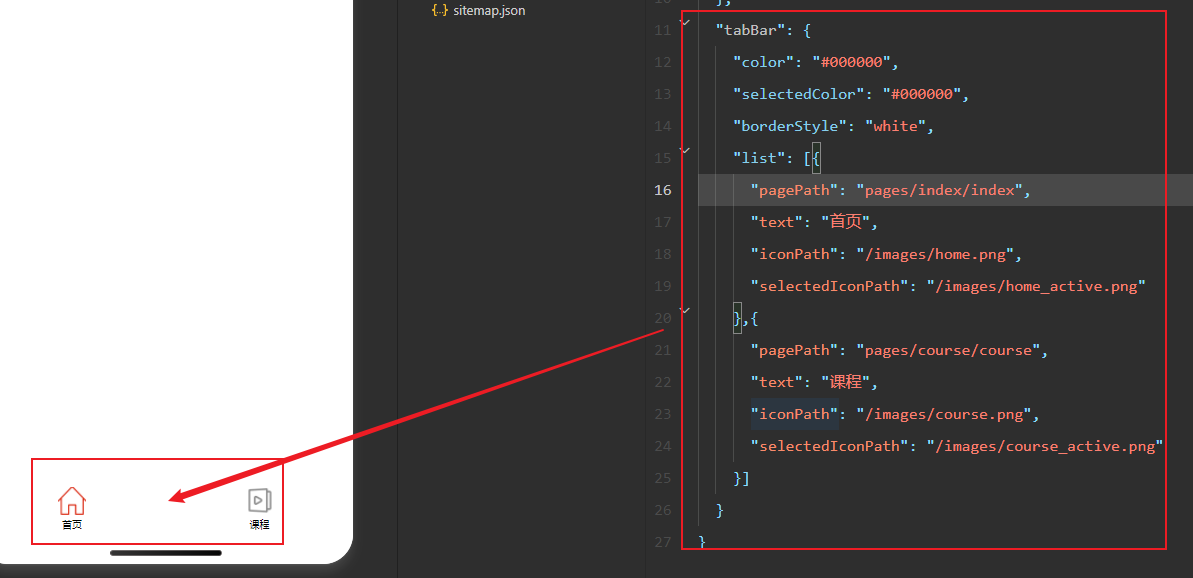
微信小程序 tabbar底部导航栏
官方文档:https://developers.weixin.qq.com/miniprogram/dev/reference/configuration/app.html#tabBar 一、常规菜单格式 在app.json 文件中配置,其他关键点详见官方文档,后续更新不规则图标的写法...

【Maven】项目管理工具
Maven:一个项目管理工具 前言 传统项目管理存在的问题: 依赖管理混乱 需要自己去网上搜 jar 包,找对版本很痛苦(还容易找错)某个库依赖另一个库(传递依赖),你得自己挨个找齐不小心…...

多线程事务?拿捏!
场景:有一批1万或者10万数据,插入数据库,怎么做 事务中进行批量提交 publList<List<OrderPo>> partition Lists.partition(list, 450);StopWatch stopWatch new StopWatch();stopWatch.start();// 顺序插入for (List<OrderPo> sub…...

Unity InputSystem触摸屏问题
最近把Unity打包后的windows软件放到windows触摸屏一体机上测试,发现部分屏幕触摸点击不了按钮,测试了其他应用程序都正常。 这个一体机是这样的,一个电脑机箱,外接一个可以触摸的显示屏,然后UGUI的按钮就间歇性点不了…...

Linux Awk 深度解析:10个生产级自动化与云原生场景
看图猜诗,你有任何想法都可以在评论区留言哦~ 摘要 Awk 作为 Linux 文本处理三剑客中的“数据工程师”,凭借字段分割、模式匹配和数学运算三位一体的能力,成为处理结构化文本(日志、CSV、配置文件)的终极工具。本文聚…...
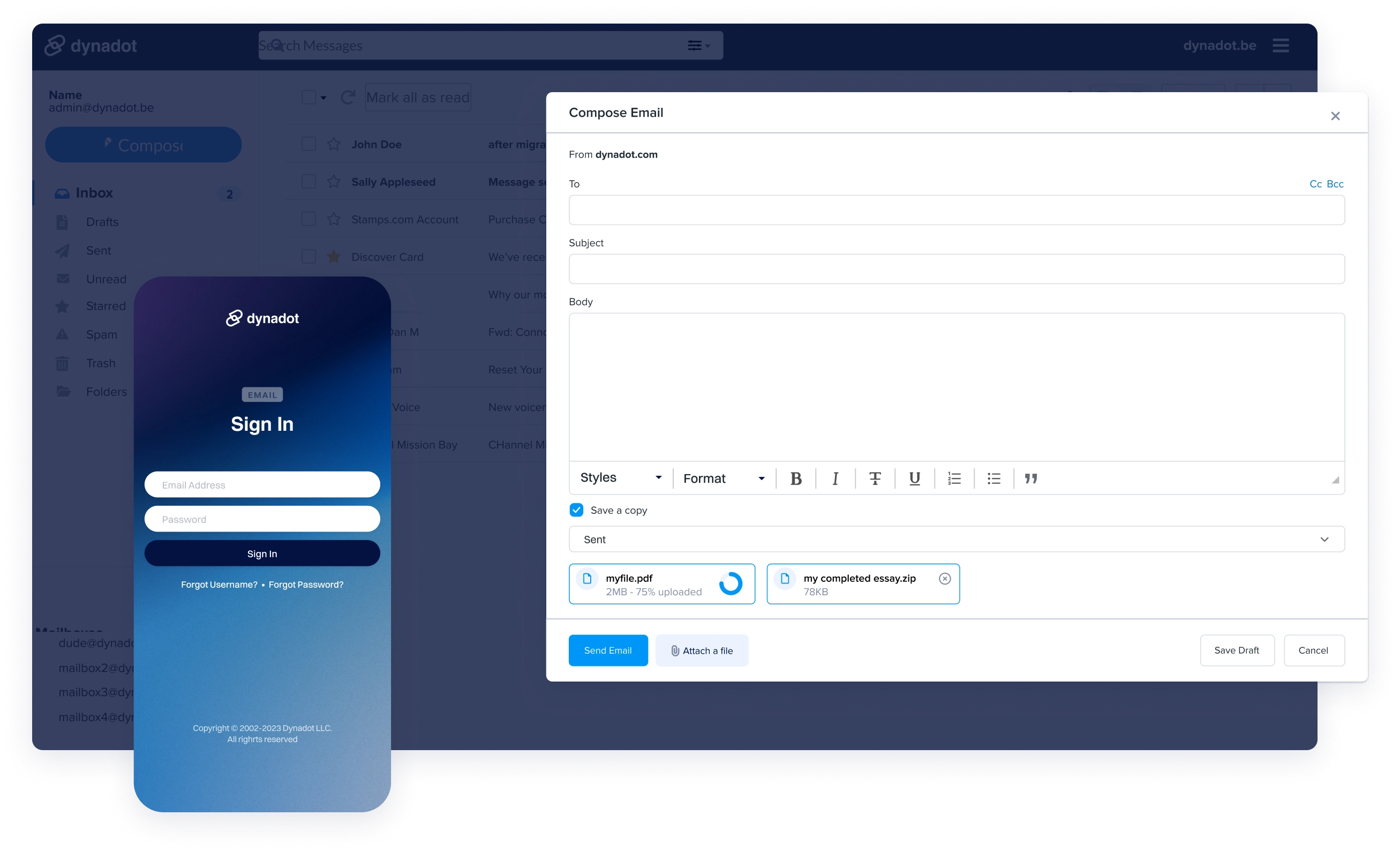
免费版还是专业版?Dynadot 域名邮箱服务选择指南
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...
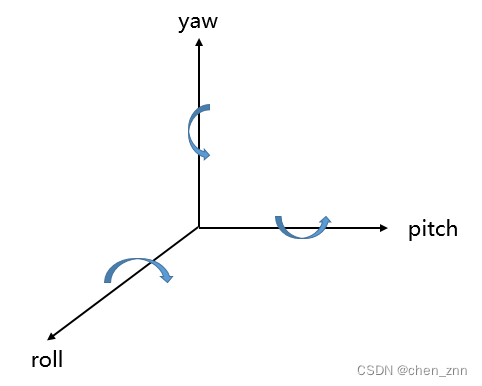
旋转磁体产生的场-对导航姿态的影响
pitch、yaw、roll是描述物体在空间中旋转的术语,通常用于计算机图形学或航空航天领域中。这些术语描述了物体绕不同轴旋转的方式: Pitch(俯仰):绕横轴旋转,使物体向前或向后倾斜。俯仰角度通常用来描述物体…...

动态哈希映射深度指南:从基础到高阶实现与优化
哈希表是计算机科学中最高效的数据结构之一,而动态哈希映射通过智能扩容机制,在实时系统中展现出极强的适应性。本文将深入探讨其实现细节,结合主流框架源码解析,并给出可落地的性能优化方案。 一、动态哈希的数学本质 1. 哈希函…...
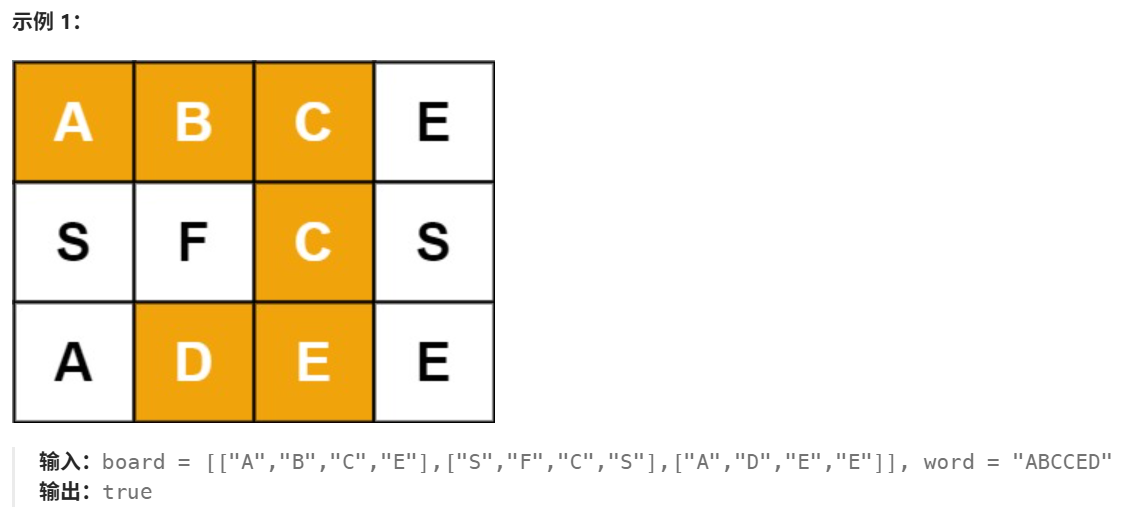
Day11(回溯法)——LeetCode79.单词搜索
1 前言 今天主要刷了一道热题榜中回溯法的题,现在的计划是先刷热题榜专题吧,感觉还是这样见效比较快。因此本文主要介绍LeetCode79。 2 LeetCode79.单词搜索(LeetCode79) OK题目描述及相关示例如下: 2.1 题目分析解决及优化 感觉回溯的方…...
)
高精度并行2D圆弧拟合(C++)
依赖库 Eigen3 GLM Ceres-2.1.0 glog-0.6.0 gflag-2.2.2 基本思路 Step 1: RANSAC找到圆弧,保留inliers点; Step 2:使用ceres非线性优化的方法,拟合inliers点,得到圆心和半径; -------…...

Linux端口占用问题排查与解决
在 Linux 中,当遇到端口被占用的情况(如你遇到的 8000 端口),可以通过以下步骤查看并处理: 1. 查看占用端口的进程 使用 netstat 或 ss 命令(推荐 ss,更现代): sudo netstat -tulnp | grep :8000 # 或 sudo ss -tulnp | grep :8000输出示例: tcp 0 0 0.0.0.0:…...
PostgreSQL 分区表——范围分区SQL实践
PostgreSQL 分区表——范围分区SQL实践 1、环境准备1-1、新增原始表1-2、执行脚本新增2400w行1-3、创建pg分区表-分区键为创建时间1-4、创建24年所有分区1-5、设置默认分区(兜底用)1-6、迁移数据1-7、创建分区表索引 2、SQL增删改查测试2-1、查询速度对比…...
、A2A、数据库查询与信息检索的实现)
4.3 工具调用与外部系统集成:API调用、MCP(模型上下文协议)、A2A、数据库查询与信息检索的实现
工具调用与外部系统集成是智能代理(Agent)系统实现复杂功能和企业级应用的核心支柱。Agent通过API调用访问实时服务,**模型上下文协议(Model Context Protocol, MCP)**标准化数据交互,Agent-to-Agent&#…...
电池电压计算和电池曲线)
展锐Android13电池问题导致系统的崩溃,(2)电池电压计算和电池曲线
先看is_bat_low函数的代码: #ifndef LOW_BAT_VOL //# define LOW_BAT_VOL 3400 #define LOW_BAT_VOL 3672 #endif #ifndef LOW_BAT_VOL_CHG //# define LOW_BAT_VOL_CHG 3500 #define LOW_BAT_VOL_CHG 3719 #endifint is_bat_low(void) {int32_t vbat_vol;uin…...
SpringCloud 微服务复习笔记
文章目录 微服务概述单体架构微服务架构 微服务拆分微服务拆分原则拆分实战第一步:创建一个新工程第二步:创建对应模块第三步:引入依赖第四步:被配置文件拷贝过来第五步:把对应的东西全部拷过来第六步:创建…...
【Python爬虫基础篇】--4.Selenium入门详细教程
先解释:Selenium:n.硒;硒元素 目录 1.Selenium--简介 2.Selenium--原理 3.Selenium--环境搭建 4.Selenium--简单案例 5.Selenium--定位方式 6.Selenium--常用方法 6.1.控制操作 6.2.鼠标操作 6.3.键盘操作 6.4.获取断言信息 6.5.…...

【Python爬虫详解】第四篇:使用解析库提取网页数据——XPath
在前一篇文章中,我们介绍了如何使用BeautifulSoup解析库从HTML中提取数据。本篇文章将介绍另一个强大的解析工具:XPath。XPath是一种在XML文档中查找信息的语言,同样适用于HTML文档。它的语法简洁而强大,特别适合处理结构复杂的网…...

二分小专题
P1102 A-B 数对 P1102 A-B 数对 暴力枚举还是很好做的,直接上双层循环OK 二分思路:查找边界情况,找出最大下标和最小下标,两者相减1即为答案所求 废话不多说,上代码 //暴力O(n^3) 72pts // #include<bits/stdc.h> // usin…...

Langchain检索YouTube字幕
创建一个简单搜索引擎,将用户原始问题传递该搜索系统 本文重点:获取保存文档——保存向量数据库——加载向量数据库 专注于youtube的字幕,利用youtube的公开接口,获取元数据 pip install youtube-transscript-api pytube 初始化 …...