《AI大模型应知应会100篇》第53篇:Hugging Face生态系统入门
第53篇:Hugging Face生态系统入门
——从模型获取到部署的全流程实战指南

📌 摘要
在人工智能快速发展的今天,Hugging Face已成为自然语言处理(NLP)领域最具影响力的开源平台之一。它不仅提供丰富的预训练模型、强大的工具库,还构建了一个开放的模型共享社区。
本文将深入介绍 Hugging Face 生态系统的核心组件,包括 Transformers、Datasets、Tokenizers 和 Hub 平台,并结合实际案例,带领你完成一个完整的 AI 应用开发流程:从数据准备、模型加载与微调,到本地部署和线上服务搭建。
✅ 目标读者:AI初中级开发者
🧪 实战内容:代码示例、安装部署、性能优化
📈 扩展思考:生态对比、未来趋势
🔍 核心概念与知识点
1. Hugging Face核心组件【实战部分】
1.1 Transformers库:架构设计与核心API详解
transformers 是 Hugging Face 最著名的库,封装了大量主流 NLP 模型(如 BERT、GPT、T5 等),并提供统一接口。
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline# 加载预训练模型与分词器
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("textattack/bert-base-uncased-SST-2")# 使用Pipeline API进行情感分析
nlp = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
result = nlp("I love using Hugging Face libraries!")
print(result) # 输出: [{'label': 'POSITIVE', 'score': 0.9998}]
📌 解释说明:
AutoTokenizer自动识别模型所需的分词器;AutoModelForSequenceClassification支持多种任务;pipeline()是高层封装,适合快速原型开发。
1.2 Datasets库:高效数据处理工作流程
datasets 提供了标准化的数据集接口,支持在线加载、缓存、切片等操作。
from datasets import load_dataset# 加载GLUE中的SST-2数据集
dataset = load_dataset("glue", "sst2")
print(dataset["train"][0]) # 查看第一条样本
输出示例:
{"sentence": "This film was a great waste of my time.","label": 0,"idx": 0
}
📌 解释说明:
load_dataset()支持数百个公开数据集;- 数据格式统一为
DatasetDict,便于后续处理。
1.3 Tokenizers库:自定义分词器开发指南
有时我们需要训练自己的分词器来适配特定语料或语言:
pip install tokenizers
from tokenizers import BertWordPieceTokenizer# 初始化并训练BPE分词器
tokenizer = BertWordPieceTokenizer()
tokenizer.train(files=["your_corpus.txt"], vocab_size=30_000)
tokenizer.save_model("custom_tokenizer")
📌 解释说明:
BertWordPieceTokenizer是BERT常用的子词分词方式;train()接受文本文件列表进行训练;save_model()可导出为标准模型目录。
1.4 Hub平台:模型共享与版本管理最佳实践
Hugging Face Hub 是一个模型仓库,你可以上传、下载、版本化你的模型。
# 登录HF账户
huggingface-cli login
from huggingface_hub import HfApiapi = HfApi()
api.upload_folder(folder_path="my_model",repo_id="username/my_new_model",repo_type="model"
)
📌 解释说明:
upload_folder()可以上传整个模型目录;- 支持 Git 式版本控制(tag、branch);
- 支持私有/公开仓库设置。
2. 模型使用与适配【实战部分】
2.1 预训练模型加载:不同架构模型的加载技巧
from transformers import AutoModel# 自动加载任意架构的模型
model = AutoModel.from_pretrained("distilbert-base-uncased")
print(model.config) # 查看模型配置
📌 解释说明:
AutoModel是泛型类,自动识别模型类型;- 支持 GPT、T5、DistilBERT、XLM-RoBERTa 等多种架构。
2.2 模型转换工具:格式转换与兼容性处理
如果你需要将模型转成 ONNX 或 TorchScript:
transformers-cli convert --model bert-base-uncased --to onnx --output ./onnx_model/
📌 解释说明:
- 支持 ONNX、TensorRT、CoreML 等格式;
- 可用于加速推理或跨平台部署。
2.3 Pipeline API:快速应用开发的最佳实践
from transformers import pipeline# 文本摘要
summarizer = pipeline("summarization")
text = "Hugging Face is an open-source company that develops tools for building NLP applications."
summary = summarizer(text, max_length=30, min_length=10, do_sample=False)
print(summary[0]['summary_text'])
输出:
"Hugging Face develops tools for NLP applications."
📌 解释说明:
pipeline()内部已集成分词、推理、后处理;- 支持多种任务,如问答、翻译、NER、文本生成等。
2.4 AutoClass体系:模型兼容性与代码简化技巧
from transformers import AutoTokenizer, AutoModelForMaskedLM# 自动加载掩码语言模型
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForMaskedLM.from_pretrained("bert-base-uncased")
📌 解释说明:
AutoModelForXXX系列类根据任务自动选择模型头;- 减少手动判断模型类型的麻烦。
3. 微调与训练【实战部分】
3.1 Trainer API实战:完整训练流程示例
from transformers import TrainingArguments, Trainertraining_args = TrainingArguments(output_dir="./results",evaluation_strategy="epoch",learning_rate=2e-5,per_device_train_batch_size=16,num_train_epochs=3,
)trainer = Trainer(model=model,args=training_args,train_dataset=dataset["train"],eval_dataset=dataset["validation"]
)trainer.train()
📌 解释说明:
TrainingArguments控制训练参数;Trainer封装了训练循环、评估、日志等功能;- 支持混合精度、多GPU训练等高级特性。
3.2 分布式训练配置:多GPU/TPU训练设置
# 使用Accelerate库配置分布式训练
from accelerate import Acceleratoraccelerator = Accelerator(mixed_precision="fp16")
device = accelerator.device
📌 解释说明:
Accelerator简化了设备管理和训练流程;- 支持 GPU、TPU、CPU 多种设备;
- 自动处理梯度同步、损失计算等。
3.3 PEFT高效微调:LoRA、P-Tuning实现教程
pip install peft
from peft import LoraConfig, get_peft_modelconfig = LoraConfig(r=8, lora_alpha=16, target_modules=["query", "value"])
model = get_peft_model(model, config)
📌 解释说明:
- LoRA 在原始权重矩阵上添加低秩矩阵,显著减少参数量;
- 适用于大模型微调时节省显存和训练时间。
3.4 Accelerate库应用:混合精度与设备优化
from accelerate import notebook_launcherdef training_function():...notebook_launcher(training_function, num_processes=2)
📌 解释说明:
- 支持多进程训练;
- 可用于 Colab、Kaggle、Slurm 等环境;
- 自动检测可用设备并分配资源。
4. 部署与生产环境【实战部分】
4.1 模型压缩技术:量化与裁剪的实战指南
pip install optimum
from optimum.onnxruntime import ORTQuantizerquantizer = ORTQuantizer.from_pretrained("bert-base-uncased")
quantizer.quantize(save_dir="quantized_bert")
📌 解释说明:
optimum是 Hugging Face 的模型优化库;- 支持动态/静态量化、剪枝、蒸馏等技术;
- 显著提升推理速度和降低内存占用。
4.2 Inference Endpoints:模型部署与API服务设置
在 Hugging Face Inference Endpoints 上部署模型只需几步:
# 创建端点
curl -X POST https://api.huggingface.co/v1/endpoints \-H "Authorization: Bearer YOUR_API_TOKEN" \-d '{"name":"my-model","model":"bert-base-uncased"}'
📌 解释说明:
- 支持自动扩缩容;
- 提供 RESTful API;
- 可对接 AWS、Azure、Google Cloud 等云厂商。
4.3 Gradio与Spaces:快速原型与演示应用搭建
pip install gradio
import gradio as grdef greet(name):return f"Hello {name}!"demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
📌 解释说明:
Gradio是交互式界面构建工具;- 支持图像、音频、文本等多种输入输出;
- 可一键发布到 Hugging Face Spaces。
4.4 本地部署优化:高效推理服务器配置
使用 FastAPI + Transformers 构建本地推理服务:
pip install fastapi uvicorn transformers torch
from fastapi import FastAPI
from transformers import pipelineapp = FastAPI()
classifier = pipeline("sentiment-analysis")@app.post("/predict")
def predict(text: str):return classifier(text)[0]if __name__ == "__main__":import uvicornuvicorn.run(app, host="0.0.0.0", port=8000)
运行服务:
uvicorn main:app --reload
📌 解释说明:
- 使用 FastAPI 构建高性能 Web 接口;
- 可扩展支持多模型、多任务;
- 支持异步请求处理。
🧩 案例与实例
5.1 文本分类系统:从数据准备到部署的完整案例
- 数据加载 →
datasets.load_dataset("imdb") - 模型加载 →
AutoModelForSequenceClassification - 微调训练 →
Trainer - 推理服务 →
FastAPI + Transformers - 前端展示 →
Gradio
5.2 多语言翻译服务:基于Hugging Face的翻译系统构建
translator = pipeline("translation_en_to_fr")
print(translator("Hello, how are you?", max_length=40))
支持中英互译、多语言翻译,模型可选 Helsinki-NLP/opus-mt-en-zh 等。
5.3 企业级搜索引擎:结合Sentence Transformers的实现
pip install sentence-transformers
from sentence_transformers import SentenceTransformer, utilmodel = SentenceTransformer('all-MiniLM-L6-v2')
sentences = ["Apple is looking at buying U.K. startup for $1 billion","Google is considering a bid for the same startup"]embeddings = model.encode(sentences)
cos_sim = util.cos_sim(embeddings[0], embeddings[1])
print(f"Cosine similarity: {cos_sim.item():.4f}")
📌 解释说明:
- 利用句子嵌入做语义搜索;
- 可用于文档检索、问答系统等场景。
🛠️ 实战指南与代码
6.1 环境搭建脚本:开发环境完整配置指南
# 安装基础依赖
pip install transformers datasets tokenizers peft optimum accelerate gradio fastapi uvicorn torch
6.2 微调流程模板:通用微调工作流程代码
见前面章节中的 Trainer 示例。
6.3 模型部署Dockerfile:生产级部署容器配置
FROM python:3.9-slimWORKDIR /appCOPY requirements.txt .
RUN pip install -r requirements.txtCOPY . .CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]
6.4 自动评估脚本:模型性能评估自动化工具
from sklearn.metrics import classification_reportpreds = trainer.predict(dataset["test"]).predictions.argmax(-1)
labels = dataset["test"]["label"]
print(classification_report(labels, preds))
❓常见问题与优化
| 问题 | 解决方案 |
|---|---|
| OOM错误 | 使用 mixed_precision=True 或 gradient_checkpointing=True |
| 推理慢 | 使用 ONNX/TorchScript 导出模型 |
| 模型不收敛 | 调整学习率、warmup_steps、weight_decay |
| 版本冲突 | 使用 pip install transformers==4.28.0 固定版本 |
🧠 总结与扩展思考
7.1 Hugging Face生态与商业平台的对比分析
| 功能 | Hugging Face | Google Vertex AI | Azure Cognitive Services |
|---|---|---|---|
| 模型丰富度 | ✅ 开源模型最多 | ⚠️ 主要自家模型 | ⚠️ 闭源 |
| 成本 | ✅ 免费+付费灵活 | 💰 企业级收费 | 💰 企业级收费 |
| 社区支持 | ✅ 强大活跃 | ❌ | ❌ |
| 部署便捷性 | ✅ HF Inference Endpoints | ✅ | ✅ |
7.2 社区贡献与开源协作的最佳实践
- Fork项目 → 修改代码 → 提PR
- 参与Hackathon、论文复现挑战
- 提交Issue、Bug修复、文档完善
7.3 Hugging Face技术路线图与未来发展趋势
- 更多模态融合(视觉+语言)
- 模型即服务(MaaS)模式深化
- 低代码/可视化工具持续增强
- 与LangChain、LlamaIndex深度整合
📚 参考资料
- Hugging Face官方文档:https://huggingface.co/docs
- Transformers GitHub仓库:https://github.com/huggingface/transformers
- Peft GitHub仓库:https://github.com/huggingface/peft
- Sentence-Transformers官网:https://www.sbert.net/
🧑💻 结语
Hugging Face 不只是一个模型库,而是一个完整的 AI 开发生态系统。掌握它的核心组件与实战技巧,不仅能帮助你快速构建 AI 应用,还能让你更好地理解现代 NLP 技术的发展方向。
欢迎关注《AI大模型应知应会100篇》专栏,持续更新前沿技术干货!
💬 如果你对某一部分特别感兴趣(如模型压缩、微调策略、部署优化),欢迎留言,我们将安排专题深入讲解!
相关文章:
《AI大模型应知应会100篇》第53篇:Hugging Face生态系统入门
第53篇:Hugging Face生态系统入门 ——从模型获取到部署的全流程实战指南 📌 摘要 在人工智能快速发展的今天,Hugging Face已成为自然语言处理(NLP)领域最具影响力的开源平台之一。它不仅提供丰富的预训练模型、强大…...
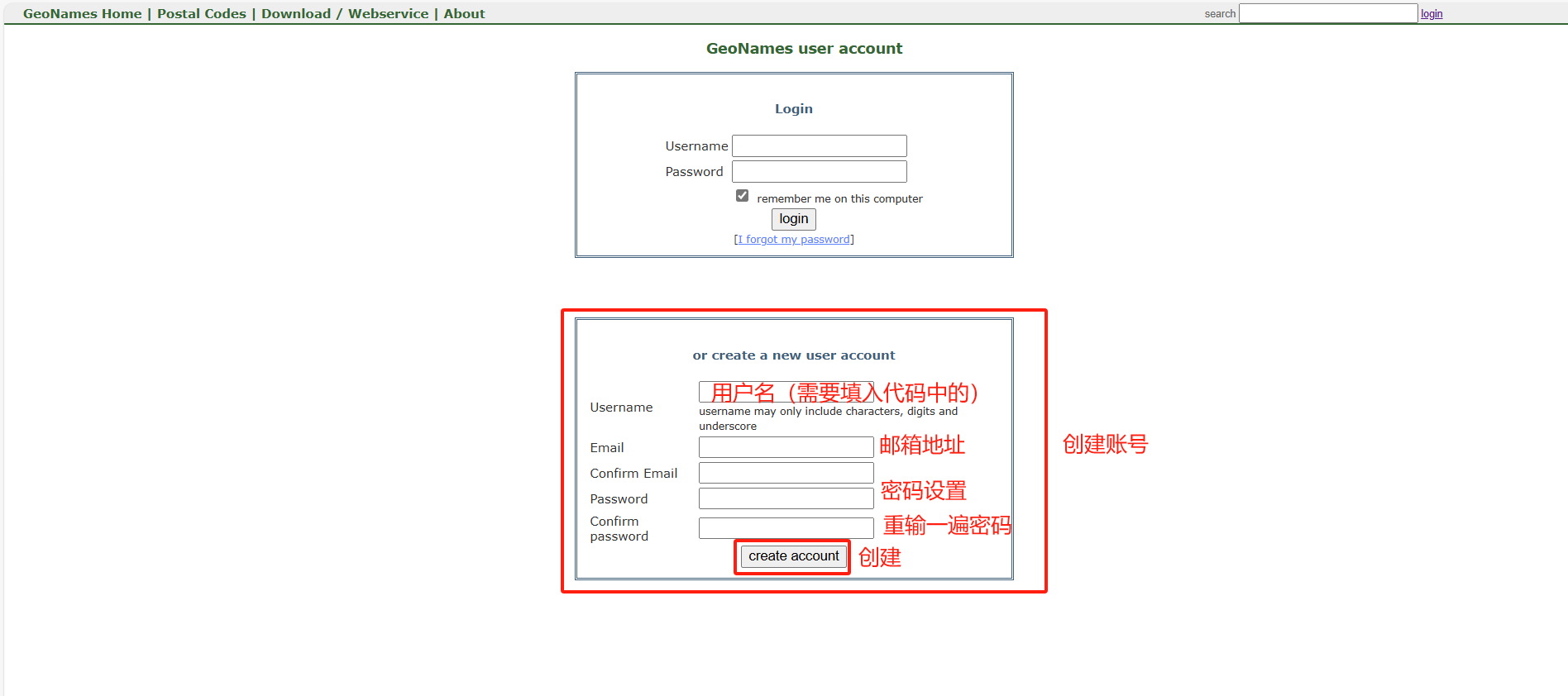
【基于 LangChain 的异步天气查询2】GeoNames实现地区实时气温查询
目录 功能简介 一、创建GeoNames账号 1、进入官网 2、创建账号 二、运行代码 weather_runnable.py main.py 运行结果 功能简介 本文主要通过Langchain,结合GeoNames实现了地区温度的实时查询,并通过GPT-4o对温度进行一段简短的描述。 一、创建Ge…...

嵌入式与物联网:C 语言在边缘计算时代的破局之道
引言 在万物互联的 2025 年,全球物联网设备连接数突破 300 亿台,其中 78% 的嵌入式控制系统仍基于 C 语言开发。这种跨越半个世纪的编程语言,正以新的技术形态在智能汽车、工业物联网、边缘计算等领域重塑竞争力。本文通过三个前沿应用场景&…...

《基于人工智能的智能客服系统:技术与实践》
一、引言 在数字化时代,客户服务已成为企业竞争的关键领域之一。随着人工智能(AI)技术的飞速发展,智能客服系统逐渐成为企业提升服务质量和效率的重要工具。智能客服不仅能够快速响应客户咨询,还能通过自然语言处理&am…...

5. HTML 转义字符:在网页中正确显示特殊符号
在 HTML 开发中,我们经常会遇到需要显示特殊字符的情况,比如 <、>、空格或版权符号等。直接输入这些字符可能会导致 HTML 解析错误或显示异常。接下来通过学习 HTML 转义字符(也称为实体字符),将会掌握了如何在网页中正确显示这些特殊符号的方法。 一、为什么需要转…...

基于nodejs + Koa +Nuxt3的订单系统项目实战
以下是一个基于 Node.js Koa Nuxt3 的订单系统项目实战指南,包含关键实现步骤和代码示例: 一、项目架构设计 project/ ├── backend/ # Koa 后端 │ ├── config/ # 配置文件 │ ├── controllers/ # 控制器 │ ├──…...

软件开发者如何转战AI领域
在人工智能(AI)技术迅猛发展的当下,越来越多的软件工程师开始考虑转型进入AI领域。本文将探讨AI软件行业的现状、所需能力,以及普通软件工程师在转型过程中可以借助的技能和需要补充的知识。 AI软件行业的现状 截至2025年&#…...

服务器数据恢复—硬盘坏道导致EqualLogic存储不可用的数据恢复
服务器存储数据恢复环境&故障: 一台EqualLogic某型号存储中有一组由16块SAS硬盘组建的RAID5阵列。上层采用VMFS文件系统,存放虚拟机文件,上层一共分了4个卷。 磁盘故障导致存储不可用,且设备已经过保。 服务器存储数据恢复过程…...

JAVA实战开源项目:智能学习平台系统 (Vue+SpringBoot) 附源码
本文项目编号 T 181 ,文末自助获取源码 \color{red}{T181,文末自助获取源码} T181,文末自助获取源码 目录 一、系统介绍二、数据库设计三、配套教程3.1 启动教程3.2 讲解视频3.3 二次开发教程 四、功能截图五、文案资料5.1 选题背景5.2 国内…...

Linux系统使用vscode格式化shell脚本
推荐工具及配置方案 BeautySH 特点 纯 Python 实现,轻量级且活跃维护。 配置步骤 安装 BeautySH pip3 install beautyshVSCode 集成 打开命令面板(CtrlShiftP),输入 Tasks: Configure Task,选择 Create tasks.json f…...

牛客练习赛138
目录 A-小s的签到题 无注释版 有注释版 B-行列改写 无注释版 有注释版 C-树上替身追赶游戏 无注释版 有注释版 A-小s的签到题 无注释版 #include<bits/stdc.h> using namespace std; struct f{char ch;int x; }a[110]; bool cmp(f p,f q){if(p.xq.x) return p…...
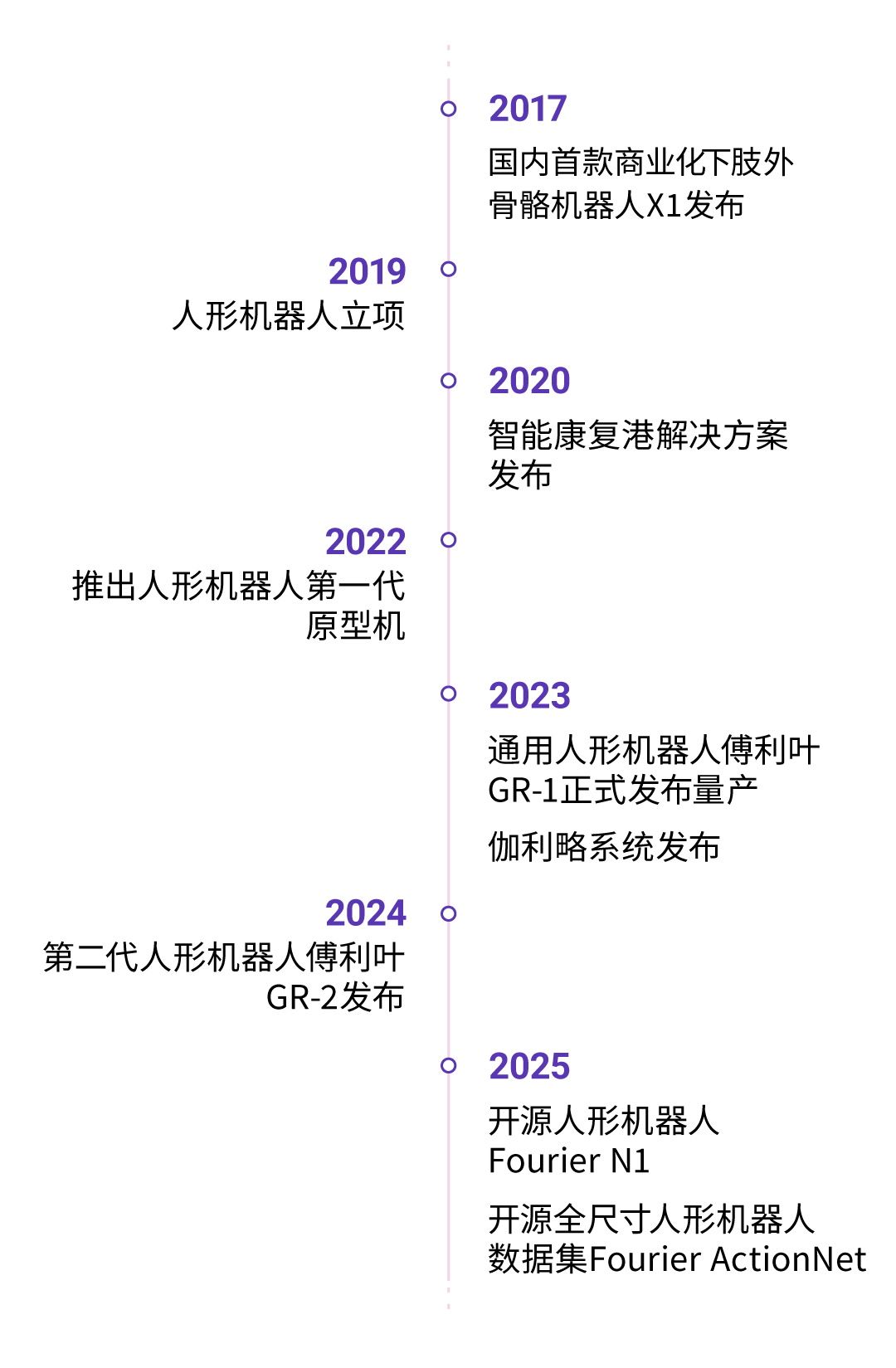
傅利叶十周年,升级核心战略:“有温度”的具身智能蓝图
5月9日,傅利叶十周年庆典暨首届具身智能生态峰会在上海正式召开。本次大会以“十年共创,具身成翼”为主题,汇聚了来自通用机器人与医疗康复领域的顶尖专家学者、合作伙伴与投资机构,共同探索具身智能在未来十年的技术应用与生态发…...
)
JS正则表达式介绍(JavaScript正则表达式)
文章目录 JavaScript正则表达式完全指南正则表达式基础元字符与特殊字符基本元字符. - 点号\d - 数字\D - 非数字\w - 单词字符\W - 非单词字符\s - 空白字符\S - 非空白字符 正则表达式标志常用标志详解g - 全局匹配i - 忽略大小写m - 多行匹配s - 点号匹配所有字符u - Unicod…...
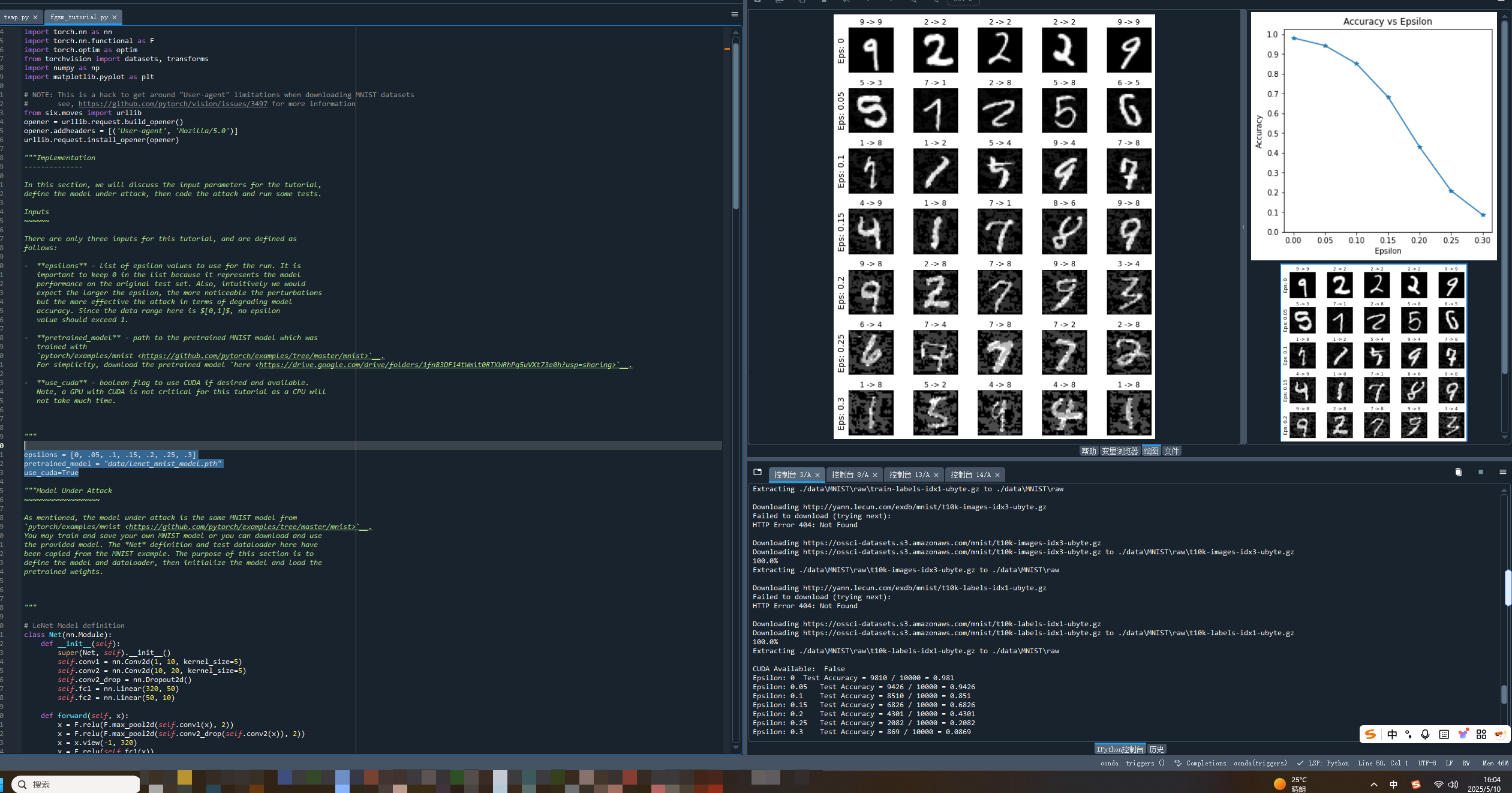
AI安全之对抗样本攻击---FGSM实战脚本解析
一、对抗样本与FGSM的背景 在深度学习安全领域,对抗样本(Adversarial Examples)因其特殊的生成机制备受关注。2015年ICLR会议收录的里程碑式论文《Explaining and Harnessing Adversarial Examples》中,Goodfellow等学者首次系统…...
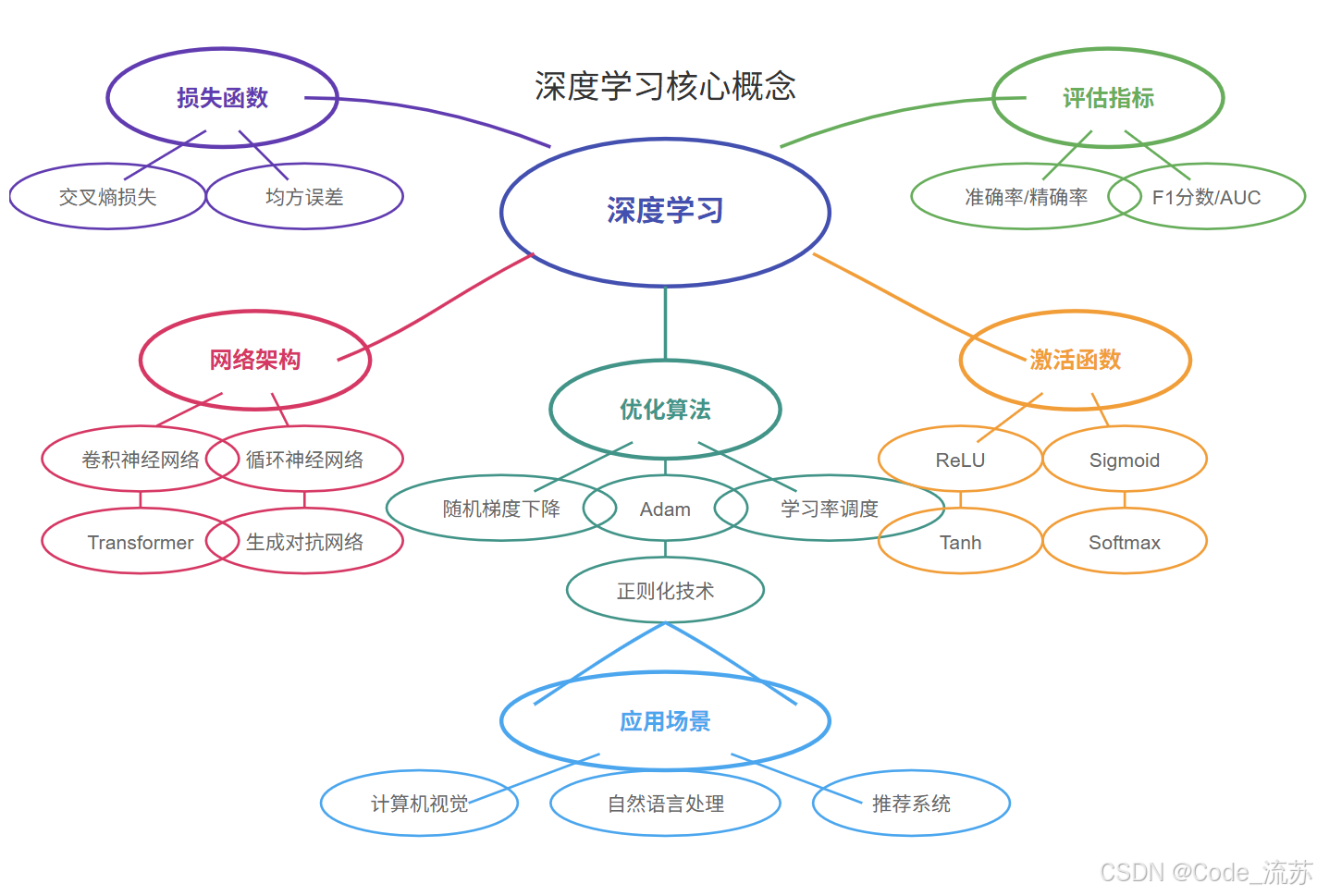
《Python星球日记》 第50天:深度学习概述与环境搭建
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、什么是深度学习?它与传统机器学习的区别1. 深度学习的定义2. 深…...

Android开发-图像显示
在Android应用开发中,图像显示是提升用户体验的重要元素之一。无论是展示产品图片、用户头像还是应用程序图标,合理地使用图像资源可以显著增强界面的吸引力和功能性。本文将详细介绍如何在Android应用中有效地显示图像,包括加载本地与网络图…...

linux搭建hadoop学习
linux搭建hadoop学习 下载安装包: 海外资源可能需要翻墙或者找国内资源 cd /opt wget https://dlcdn.apache.org/hadoop/common/hadoop-2.10.2/hadoop-2.10.2.tar.gz tar -zxvf hadoop-2.10.2.tar.gz mv hadoop-2.10.2 hadoop配置环境变量 # 在/etc/profile文件中添加下面内…...
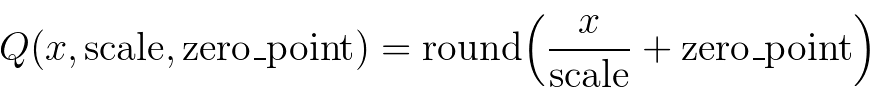
PyTorch API 8 - 工具集、onnx、option、复数、DDP、量化、分布式 RPC、NeMo
文章目录 torch.nn.inittorch.nn.attention工具集子模块 torch.onnx概述基于 TorchDynamo 的 ONNX 导出器基于TorchScript的ONNX导出器贡献与开发 torch.optim如何使用优化器构建优化器每个参数的选项执行优化步骤optimizer.step()optimizer.step(closure) 基类算法如何调整学习…...

0基础 | STM32 | TB6612电机驱动使用
TB6612介绍及使用 单片机通过驱动板连接至电机 原因:单品机I/O口输出电流I小 驱动板:从外部引入高电压,控制电机驱动 电源部分 VM:电机驱动电源输入,输入电压范围建议为3.7~12V GND:逻辑电…...
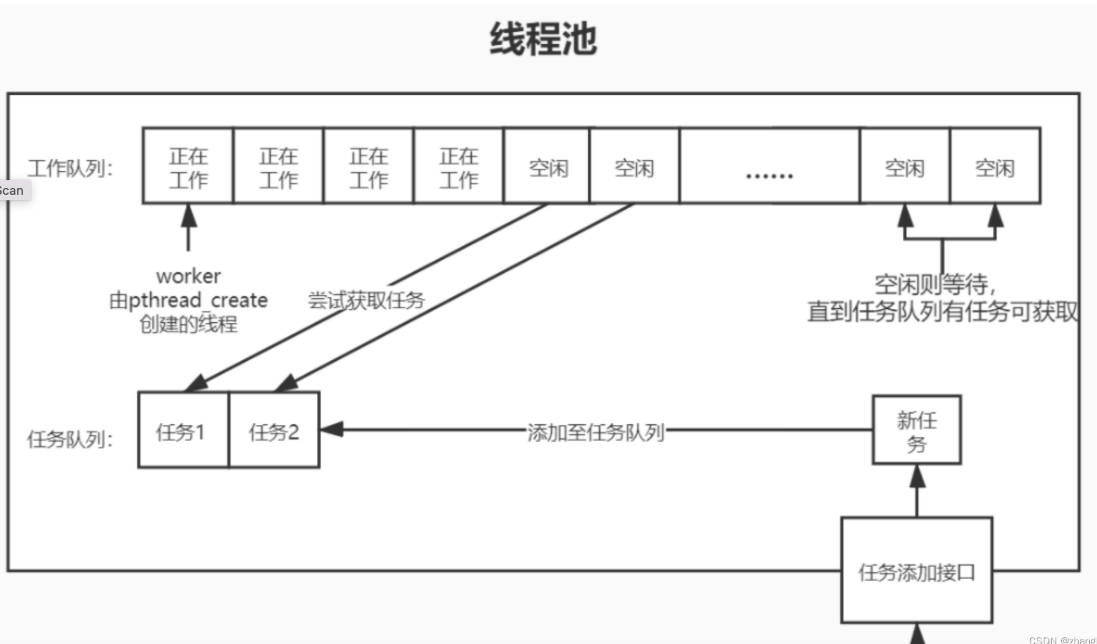
【Linux】POSIX 线程信号量与互斥锁▲
代码要求:高内聚,低耦合 高内聚:元素之间具有很强的关联性,模块的功能单一且集中 低耦合:代码之间的依赖关系尽可能简单,相互之间的影响和交互尽可能少 线程安全问题:多线程访问共享数据&…...

轻松制作高质量视频,实时生成神器LTX-Video重磅登场!
探索LTX-Video:实时视频生成跨越新高度 在如今这个视觉内容主导的数字时代,视频生成成为推动创意表达的关键。而今天,我们将带您深入探索LTX-Video,一个强大的开源项目,致力于通过尖端技术将视频生成提升到一个全新的…...
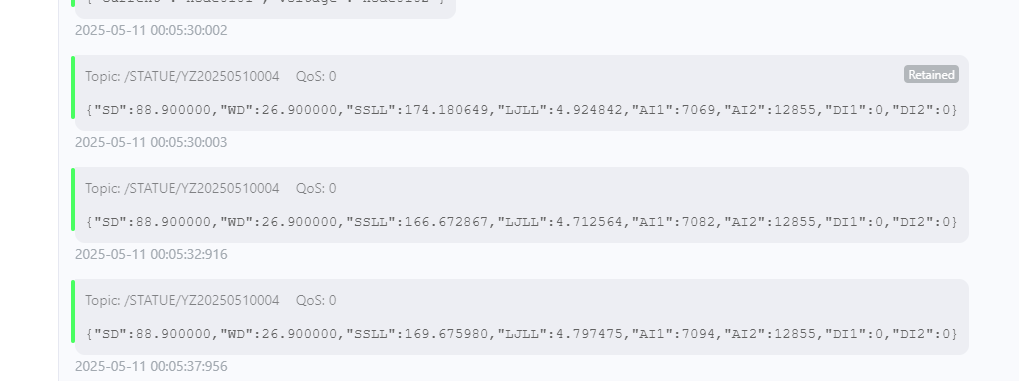
USR-M100采集数据并提交MQTT服务器
本文为记录备忘,不做过多解释。 模块自身带有2路数字量输入,2路模拟量输入,2路485接口 数字量接报警输入,模拟量接压力传感器,液位传感器,485接口分别接流量计,温湿度传感器。 正确接线&…...
内网穿透系列三:开源本地服务公网映射工具 tunnelmole
以下是对 tunnelmole 简要介绍: tunnelmole 是一款开源的内网穿透工具,一行命令就能把本地http服务映射成公网可访问的链接提供公共免费的网络服务,直接下载运行命令即可使用,也支持自行配置搭建私有客户端、服务端参考开源地址&…...

数据集-目标检测系列- 冥想 检测数据集 close_eye>> DataBall
数据集-目标检测系列- 冥想 检测数据集 close * 相关项目 1)数据集可视化项目:gitcode: https://gitcode.com/DataBall/DataBall-detections-100s/overview 2)数据集训练、推理相关项目:GitHub - XIAN-HHappy/ultralytics-yolo-…...

计算机网络:家庭路由器WiFi信号的发射和手机终端接收信号原理?
WiFi路由器与手机之间的信号传输涉及多个技术层面的协作,以下是其工作原理的详细步骤: 一、数据封装与协议处理 应用层数据生成 用户操作(如浏览网页、视频播放)产生数据包,经TCP/IP协议栈逐层封装,添加IP地址(网络层)和MAC地址(数据链路层)。协议封装 数据包被封装…...

用 NGINX 打造高性能 FastCGI 加速 `ngx_http_fastcgi_module`
一、安装与启用 # 在编译 NGINX 源码时加上: ./configure --with-http_fastcgi_module make && sudo make install# 或确保你使用的二进制已内置(大多数发行版都默认包含) nginx -V | grep fastcgi二、基础转发配置 http {server {…...

深度学习 ———— 迁移学习
迁移学习原理 什么是迁移学习? 迁移学习利用在大规模数据集(如ImageNet)上预训练的模型,改装小数据集(如CIFAR-10)。优势: 减少训练时间:预训练模型已学习通用特征(如边…...

论文精读:YOLOE: Real-Time Seeing Anything
文章目录 前言1、背景2、方法2.1.重参Region-Text对齐模块2.2.VisualPrompt模块2.3.PromptFree 2.4.损失函数3、实验3.1.训练集3.2.实验结果 总结 前言 本文介绍一篇来自清华的开放词汇检测论文:YOLOE;源码链接。 1、背景 本文在yolo-world基础上&#x…...

以影像为笔,劳润智在世界舞台上书写艺术之路
在光影交织中,摄影师劳润智的镜头仿佛能穿透喧嚣,捕捉人类情感最细腻的脉动。从疫情下洛杉矶裁缝日常的温馨瞬间,到象征自由与解脱的飞鸟影像,再到探索时间与空间交错的抽象作品,每一幅作品都展现了他对艺术的深度追求与对生活的温柔洞察。 劳润智的作品为他赢得了多个国际奖项…...

vue3 computed方法传参数
我们对computed的基础用法不陌生,比如前端项目中经常会遇到数据处理的情况,我们就会选择computed方法来实现。但大家在碰到某些特殊场景,比如在template模板中for循环遍历时想给自己的计算属性传参,这个该怎么实现呢,很…...