MySQL COUNT(*) 查询优化详解!

目录
- 前言
- 1. COUNT(*) 为什么慢?—— InnoDB 的“计数烦恼” 🤔
- 2. MySQL 执行 COUNT(*) 的方式 (InnoDB)
- 3. COUNT(*) 优化策略:快!准!狠!
- 策略一:利用索引优化带 WHERE 子句的 COUNT(*) (最常见且推荐) 👍
- 策略二:优化不带 WHERE 子句的 COUNT(*) (InnoDB 整表计数)
- 策略三:接受近似计数 (牺牲精确性换取速度) 🚀
- 策略四:维护计数器表 (用空间换时间,用写锁换读锁) ⏱️
- 策略五:缓存计数结果 (应用程序层面的优化) 📦
- 4. EXPLAIN 分析 COUNT(*)
- 5. 总结与选择合适的策略
🌟我的其他文章也讲解的比较有趣😁,如果喜欢博主的讲解方式,可以多多支持一下,感谢🤗!
其他优质专栏: 【🎇SpringBoot】【🎉多线程】【🎨Redis】【✨设计模式专栏(已完结)】…等
如果喜欢作者的讲解方式,可以点赞收藏加关注,你的支持就是我的动力
✨更多文章请看个人主页: 码熔burning
前言
你好呀,需要统计记录总数的开发者们!👋 在数据库操作中,SELECT COUNT(*) 是一个非常常见的需求,用于获取某个条件的记录总数,比如用户总数、订单总数、某个分类下的商品总数等。在分页场景下,为了显示总页数,COUNT(*) 更是必不可少。
然而,你可能已经发现,当表的数据量达到百万甚至千万级别时,一个简单的 COUNT(*) 查询可能会耗时数秒甚至数十秒,严重影响用户体验和系统性能。这到底是怎么回事呢?又该如何优化呢?
1. COUNT(*) 为什么慢?—— InnoDB 的“计数烦恼” 🤔
要理解 COUNT(*) 的慢,首先要区分 MySQL 的不同存储引擎,特别是 MyISAM 和 InnoDB。
-
MyISAM 存储引擎:
- 快! MyISAM 引擎在表的数据行数上有一个精确的元数据存储。执行
SELECT COUNT(*) FROM table_name;(不带WHERE子句)时,MyISAM 可以直接读取这个存储好的值并返回,这是一个 O(1) 的操作,瞬间完成!✨ - 限制: MyISAM 不支持事务、行级锁,在高并发写场景下容易出现表锁,可用性较低,现在已经很少用于核心业务表了。
- 快! MyISAM 引擎在表的数据行数上有一个精确的元数据存储。执行
-
InnoDB 存储引擎:
- 慢! InnoDB 引擎是事务安全的,支持 MVCC(多版本并发控制)。这意味着在同一时刻,不同的事务可能看到同一张表的不同行数(比如一个事务插入了行但还没提交,另一个事务可能看不到)。
- 无法存储精确计数: 由于 MVCC 的存在,InnoDB 不能像 MyISAM 那样存储一个精确的行总数。要获取一个精确的
COUNT(*)值,InnoDB 必须遍历某个版本的聚簇索引(主键索引)或一个合适的二级索引来计数。即使没有WHERE子句,它也需要扫描。 - 带
WHERE子句: 如果带了WHERE子句,InnoDB 需要先根据WHERE条件过滤出符合条件的行,然后再对这些行进行计数。这需要扫描索引(如果条件走了索引)或全表扫描(如果没索引),然后逐行判断并计数。
所以,COUNT(*) 在 InnoDB 大表上的性能问题,根源在于它为了保证事务的精确性,需要进行实际的扫描和计数,而不是像 MyISAM 那样简单读取元数据。
2. MySQL 执行 COUNT(*) 的方式 (InnoDB)
在 InnoDB 存储引擎下,MySQL 执行 COUNT(*) (或者 COUNT(1)) 时,优化器会选择成本最低的方式来计数:
-
如果查询没有
WHERE子句:SELECT COUNT(*) FROM table_name;- MySQL 会选择一个最小的二级索引进行遍历计数。二级索引通常比聚簇索引小(只存储索引列和主键),遍历二级索引比遍历聚簇索引更快。但本质上,这仍然是一个 O(N) 的操作,需要扫描整个索引。
- 如果没有二级索引,就只能扫描聚簇索引(主键索引)。
-
如果查询有
WHERE子句:SELECT COUNT(*) FROM table_name WHERE condition;- MySQL 优化器会像处理其他查询一样,选择最合适的索引来过滤符合
WHERE条件的行。 - 然后,对这些符合条件的行进行计数。
- 如果
WHERE条件可以使用某个索引进行高效过滤(例如type是range,ref,eq_ref),MySQL 会扫描这个索引来定位符合条件的记录。 - 如果这个索引是一个覆盖索引(Index Only Scan),即
WHERE子句中的列都包含在该索引中,那么 MySQL 只需要扫描索引本身就可以完成过滤和计数,无需回表读取完整的行数据。EXPLAIN的Extra列会显示Using index。这是带WHERE子句时最理想的情况。 - 如果没有合适的索引或者索引不是覆盖索引,MySQL 可能需要回表读取完整的行,然后进行计数,这会更慢。
- MySQL 优化器会像处理其他查询一样,选择最合适的索引来过滤符合
COUNT(*) vs COUNT(column) vs COUNT(1)
COUNT(*)和COUNT(1)的效果是相同的:计算符合条件的行数。它们都只关心行的存在,不关心行中的具体列值(除非有WHERE column IS NOT NULL的条件)。MySQL 优化器对COUNT(*)有特别优化,通常会选择最小的索引。在 InnoDB 中,推荐使用COUNT(*)或COUNT(1)。COUNT(column_name)会计算column_name不为NULL的行数。如果该列允许为NULL,它的结果可能少于COUNT(*)。执行时可能需要读取该列的数据,如果该列不在优化器选择的索引中,可能需要回表。
3. COUNT(*) 优化策略:快!准!狠!
既然理解了问题所在,我们就可以对症下药。优化 COUNT(*) 的核心思想是:避免或减少全索引/全表扫描。 根据业务需求对计数的实时性和精确性要求,选择不同的策略。
策略一:利用索引优化带 WHERE 子句的 COUNT(*) (最常见且推荐) 👍
这是处理最常见场景(需要计算符合特定条件的记录数)的王道。核心就是确保 WHERE 子句能够高效地利用索引。
- 方法: 根据
WHERE子句中的过滤条件,设计合适的单列索引或联合索引。 - 目标: 让 MySQL 能够利用索引快速定位到符合条件的记录,最好是能实现索引覆盖 (Using index),只扫描索引本身就能完成过滤和计数。
- 示例:
SELECT COUNT(*) FROM orders WHERE status = 'Paid';-> 在status列上创建索引INDEX idx_orders_status (status);。SELECT COUNT(*) FROM orders WHERE status = 'Paid' AND order_time >= '2025-01-01';-> 在(status, order_time)或(order_time, status)上创建联合索引。如果status选择性较高,(status, order_time)可能更好;如果order_time范围过滤性强,(order_time, status)可能更好,结合EXPLAIN验证。同时,由于COUNT(*)不需要其他列,这个联合索引本身就可能成为覆盖索引。
- 效果: 如果索引设计得当,
EXPLAIN中type会是range,ref,eq_ref等高效类型,rows大大减少,Extra可能显示Using index。性能与符合条件的记录数和索引效率有关。
策略二:优化不带 WHERE 子句的 COUNT(*) (InnoDB 整表计数)
如果你确实需要频繁获取 InnoDB 大表的精确总行数:
- 方法: 确保表上至少有一个非常小的二级索引(例如,一个简单的
INT类型列的索引)。MySQL 会优先选择这个索引进行扫描计数。 - 示例: 如果你的表只有主键,可以考虑为某个允许 NULL 的
INT类型列或者某个非常短的VARCHAR列建立一个普通索引。 - 限制: 这仍然是一个 O(N) 操作,数据量越大越慢,只是比扫描主键索引快。对于超大表,即使这样也可能无法接受。
策略三:接受近似计数 (牺牲精确性换取速度) 🚀
在很多场景下,用户并不需要一个 100% 精确的实时总数,一个近似值就足够了(比如“共有 1000+ 条记录”)。
- 方法 A: 使用
EXPLAIN估算行数:EXPLAIN SELECT * FROM table_name WHERE condition;EXPLAIN输出结果中的rows列就是优化器对符合条件的行数的估算值。- 优点: O(1) 操作,极快。
- 缺点: 非常不准确! 尤其是在有复杂
WHERE条件或数据分布不均时。仅适用于对精确度要求极低的场景。
- 方法 B: 使用
SHOW TABLE STATUS(InnoDB 近似值):SHOW TABLE STATUS LIKE 'table_name';- 结果中的
Rows字段提供了 InnoDB 对表总行数的近似估算。 - 优点: O(1) 操作,极快。
- 缺点: 非常不准确! 估算值可能与实际值相差甚远。不适用于带
WHERE子句的计数。
策略四:维护计数器表 (用空间换时间,用写锁换读锁) ⏱️
如果你需要频繁获取某些固定维度(比如按状态、按分类)的精确计数,并且对计数的实时性要求很高,可以考虑维护一个独立的计数器表。
- 方法:
- 创建一个新的表,例如
counts (dimension_value VARCHAR(...), count INT, PRIMARY KEY (dimension_value))。 - 当主表发生
INSERT,UPDATE,DELETE操作时,通过触发器或在应用代码中同步更新计数器表。INSERT时,对应维度计数 +1。DELETE时,对应维度计数 -1。UPDATE时,如果维度列改变,原维度计数 -1,新维度计数 +1。
- 创建一个新的表,例如
- 优点:
SELECT count FROM counts WHERE dimension_value = '...';是一个 O(1) 或 O(log N) 的极快查询。 - 缺点:
- 增加了数据库设计的复杂性(额外的表和逻辑)。
- 增加了写操作的开销(每次写主表都要更新计数器表)。
- 触发器或应用代码中的更新逻辑需要精心设计,否则容易出现计数不一致的问题。
- 只适用于维度固定的计数场景。
策略五:缓存计数结果 (应用程序层面的优化) 📦
将 COUNT(*) 的结果缓存在应用程序层面(如 Redis, Memcached)或缓存层。
- 方法:
- 第一次需要计数时,执行
COUNT(*)查询(可以是已优化的)。 - 将结果存入缓存,设置过期时间。
- 之后需要计数时,先从缓存获取。
- 在主表数据发生变化 (INSERT, UPDATE, DELETE) 时,更新或失效缓存中的计数。
- 第一次需要计数时,执行
- 优点: 读取缓存非常快,极大地减轻数据库压力。
- 缺点:
- 需要额外的缓存系统。
- 缓存失效/更新策略是难点,要确保数据一致性。
4. EXPLAIN 分析 COUNT(*)
使用 EXPLAIN SELECT COUNT(*) FROM ...; 来分析你的计数查询:
- 看
type列:是否使用了索引?是range,ref,eq_ref还是ALL,index? - 看
key列:是否使用了预期的索引? - 看
rows列:估算的扫描行数。这是最重要的指标,它代表了计数的工作量。优化目标就是大幅降低这个值。 - 看
Extra列:特别是Using index。如果出现它,说明是高效的索引覆盖计数。
5. 总结与选择合适的策略
- 最常用的优化手段: 对于带
WHERE子句的COUNT(*),永远优先通过索引优化WHERE子句,争取实现索引覆盖 (Using index)。这是最直接、最有效且不增加额外复杂性的方法。 - 整表计数 (InnoDB): 确保存在一个小的二级索引,但要接受它是 O(N)。如果 O(N) 仍然无法接受,考虑缓存或维护总计数器。
- 对精确度要求不高: 考虑使用
EXPLAIN估算或SHOW TABLE STATUS。 - 高频、固定维度精确计数: 评估维护计数器表的复杂性和收益。
- 所有频繁计数: 考虑在应用层或缓存层进行缓存。
COUNT(*) 的优化策略选择取决于你的具体业务场景、查询频率、对精确度的要求以及你能接受的额外复杂性。理解 InnoDB 的工作原理,善用索引优化带条件的 COUNT(*),并在必要时采用缓存或冗余计数,就能让你的计数查询变得高效可靠!
希望这篇详细的 COUNT(*) 优化指南对你有帮助!实践出真知,分析你的慢查询日志,用 EXPLAIN 找出瓶颈,然后选择最适合的优化策略吧!🛠️
相关文章:
MySQL COUNT(*) 查询优化详解!
目录 前言1. COUNT(*) 为什么慢?—— InnoDB 的“计数烦恼” 🤔2. MySQL 执行 COUNT(*) 的方式 (InnoDB)3. COUNT(*) 优化策略:快!准!狠!策略一:利用索引优化带 WHERE 子句的 COUNT(*) (最常见且…...
nginx配置协议
1. 7层协议 OSI(Open System Interconnection)是一个开放性的通行系统互连参考模型,他是一个定义的非常好的协议规范,共包含七层协议。直接上图,这样更直观些: 1.1 协议配置 1.1.1 7层配置 这里我们举例…...

自动化创业机器人:现状、挑战与Y Combinator的启示
自动化创业机器人:现状、挑战与Y Combinator的启示 前言 AI驱动的自动化创业机器人,正逐步从科幻走向现实。我们设想的未来是:商业分析、PRD、系统设计、代码实现、测试、运营,全部可以在monorepo中由AI和人类Co-founder协作完成…...

Activity动态切换Fragment
Activity 动态切换 Fragment 是 Android 开发中常见的需求,用于构建灵活的用户界面。 以下是实现 Activity 动态切换 Fragment 的几种方法,以及一些最佳实践: 1. 使用 FragmentManager 和 FragmentTransaction (推荐) 这是最常用和推荐的方…...
UE5 PCG学习笔记
https://www.bilibili.com/video/BV1onUdY2Ei3/?spm_id_from333.337.search-card.all.click&vd_source707ec8983cc32e6e065d5496a7f79ee6 一、安装PCG 插件里选择以下进行安装 移动目录后,可以使用 Update Redirector References,更新下࿰…...

《用MATLAB玩转游戏开发》打砖块:向量反射与实时物理模拟MATLAB教程
《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(2D图形交互)-《打砖块:向量反射与实时物理模拟》MATLAB教程 🎮 文章目录 《用MATLAB玩转游戏开发:从零开始打造你的数字乐园》基础篇(…...
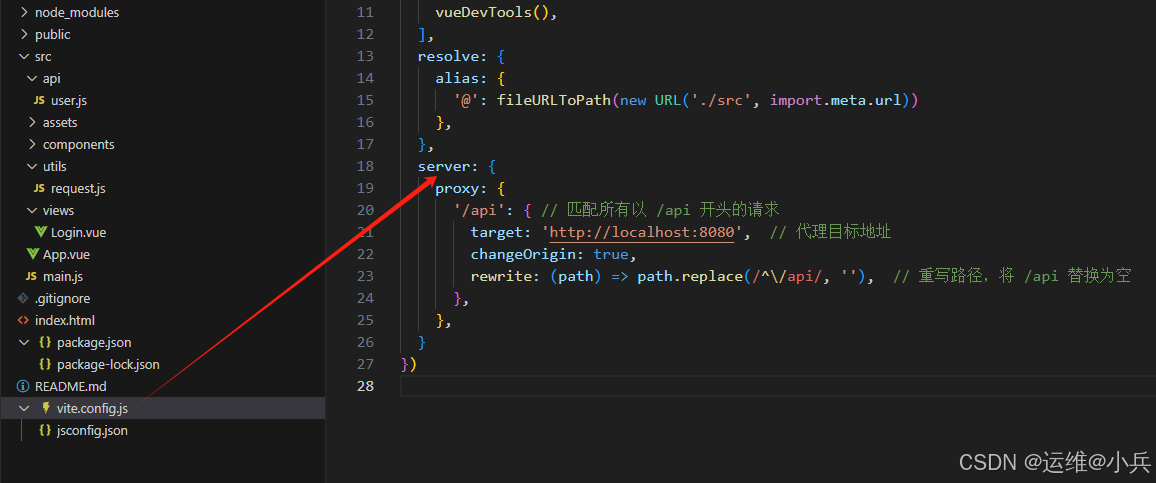
vue配置代理解决前端跨域的问题
文章目录 一、概述二、报错现象三、通过配置代理来解决修改request.js中的baseURL为/api在vite.config.js中增加代理配置 四、参考资料 一、概述 跨域是指由于浏览器的同源策略限制,向不同源(不同协议、不同域名、不同端口)发送ajax请求会失败 二、报错现象 三、…...

java+vert.x实现内网穿透jrp-nat
用java vert.x开发一个内网穿透工具 内网穿透概述技术原理常见内网穿透工具用java vert.x开发内网穿透工具 jrp-nat为什么用java开发内网穿透工具?jrp-nat功能实现图解jrp-nat内网穿透工具介绍jrp-nat内网穿透工具特点jrp-nat软件架构jrp-nat安装教程jrp-nat程序下载…...

Tile is系统详解
TileOS 是一款基于 Debian 的 Linux 发行版,专注于提供高效的平铺窗口管理体验。它结合了 Debian 的稳定性和现代平铺窗口管理器的灵活性,适合追求生产力和资源利用率的用户。以下是其核心技术细节和功能特性的详细解析: 一、系统架构与核心…...

求数组中的两数之和--暴力/哈希表
暴力法太好用了hhhhhhhhhhhhhhhhhhh我好爱鹅鹅鹅鹅鹅鹅呃呃呃呃呃呃呃呃呃呃 #include <iostream> #include <vector> using namespace std; int main(){ int n,target; cin>>n>>target; vector<int> nums(n); for(int i0;i<n;i){ cin>>…...

【程序员AI入门:应用开发】8.LangChain的核心抽象
一、 LangChain 的三大核心抽象 1. ChatModel(聊天模型) 核心作用:与大模型(如 GPT-4、Claude)交互的入口,负责处理输入并生成输出。关键功能: 支持同步调用(model.invoke…...
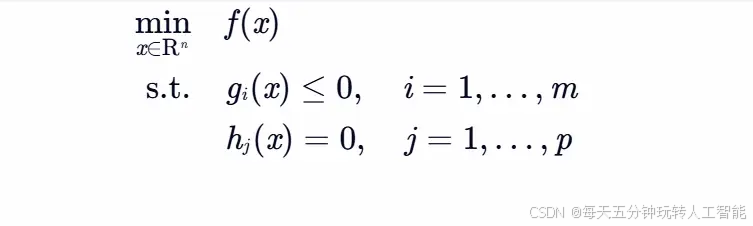
每天五分钟机器学习:KTT条件
本文重点 在前面的课程中,我们学习了拉格朗日乘数法求解等式约束下函数极值,如果约束不是等式而是不等式呢?此时就需要KTT条件出手了,KTT条件是拉格朗日乘数法的推广。KTT条件不仅统一了等式约束与不等式约束的优化问题求解范式,KTT条件给出了这类问题取得极值的一阶必要…...

基于Stable Diffusion XL模型进行文本生成图像的训练
基于Stable Diffusion XL模型进行文本生成图像的训练 flyfish export MODEL_NAME"stabilityai/stable-diffusion-xl-base-1.0" export VAE_NAME"madebyollin/sdxl-vae-fp16-fix" export DATASET_NAME"lambdalabs/naruto-blip-captions"acceler…...

Facebook的元宇宙新次元:社交互动如何改变?
科技的浪潮正将我们推向一个全新的时代——元宇宙时代。Facebook,这个全球最大的社交网络平台,已经宣布将公司名称更改为 Meta,全面拥抱元宇宙概念。那么,元宇宙究竟是什么?它将如何改变我们的社交互动方式呢ÿ…...

概统期末复习--速成
随机事件及其概率 加法公式 推三个的时候ABC,夹逼准则 减法准则 除法公式 相互独立定义 两种分析 两个解法 古典概型求概率(排列组合) 分步相乘、分类相加 全概率公式和贝叶斯公式 两阶段问题 第一个小概率*A在小概率的概率。。。累计 …...
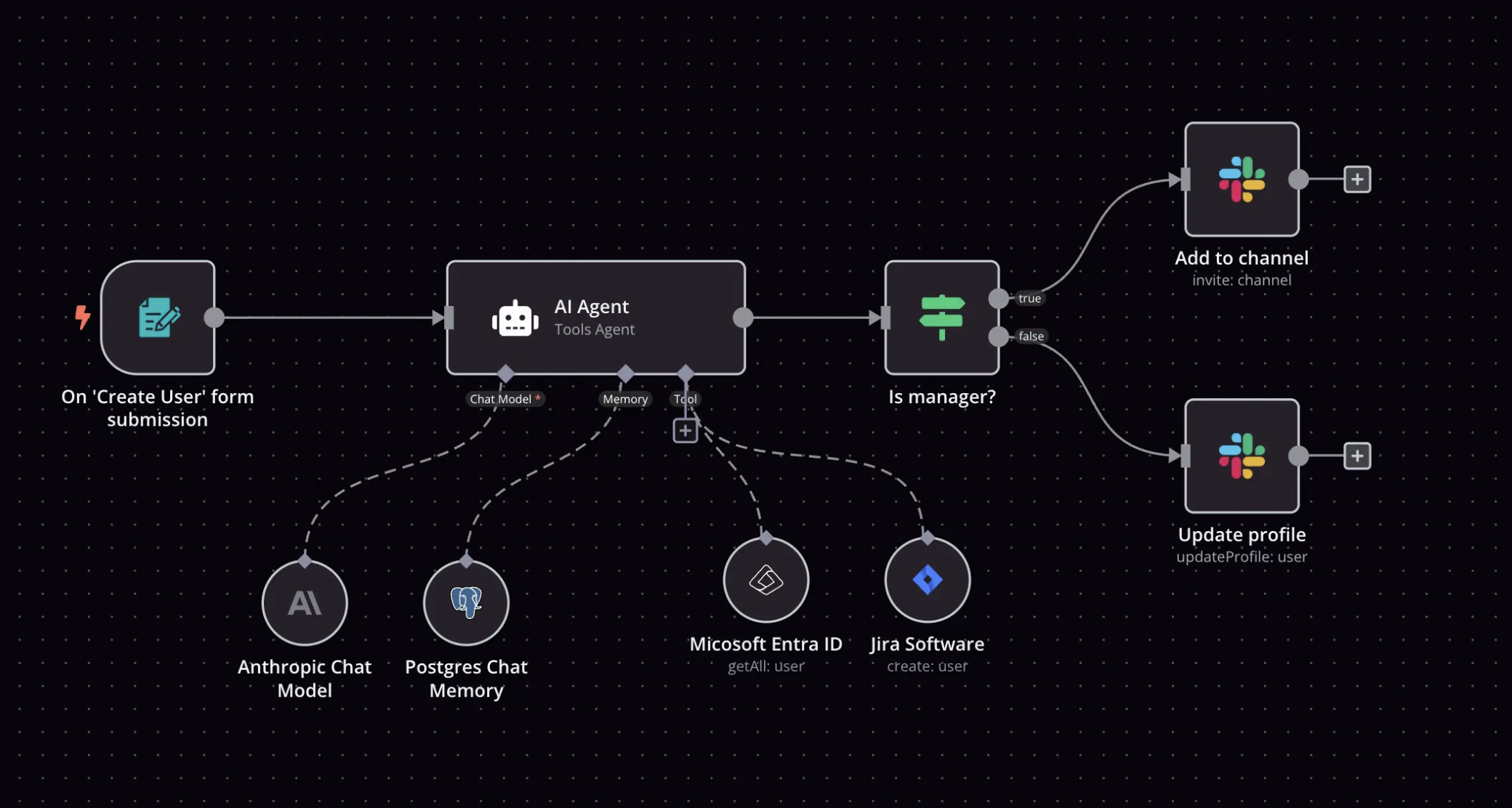
n8n系列(1)初识n8n:工作流自动化平台概述
1. 引言 随着各类自动化工具的涌现,n8n作为一款开源的工作流自动化平台,凭借其灵活性、可扩展性和强大的集成能力,正在获得越来越多技术团队的青睐。 本文作为n8n系列的开篇,将带您全面了解这个强大的自动化平台,探索其起源、特性以及与其他工具的差异,帮助您判断n8n是否…...

Java中Comparator排序原理详解
引言 在Java编程中,集合排序是一个常见需求。很多开发者对于为什么o2-o1实现降序排列而o1-o2实现升序排列感到困惑。本文将从数学角度解析这个问题,帮助读者彻底理解Comparator的排序原理。 问题引入 看看以下排序代码: List<Student&…...

PyQt5基础:QWidget类的全面解析与应用实践
在Python的GUI编程领域,PyQt5是一个强大且广泛应用的库。其中,QWidget类作为所有用户界面对象的基类,是构建丰富多样用户界面的基础。今天,我们就来深入了解QWidget类及其相关应用。 QWidget类概述 QWidget类是PyQt中所有窗口和…...

Python-77:古生物DNA序列血缘分析
问题描述 小U是一位古生物学家,正在研究不同物种之间的血缘关系。为了分析两种古生物的血缘远近,她需要比较它们的DNA序列。DNA由四种核苷酸A、C、G、T组成,并且可能通过三种方式发生变异:添加一个核苷酸、删除一个核苷酸或替换一…...

QT6 源(82):阅读与注释日历类型 QCalendar,本类并未完结,儒略历,格里高利历原来就是公历,
(1)本代码来自于头文件 qcalendar . h : #ifndef QCALENDAR_H #define QCALENDAR_H#include <limits>#include <QtCore/qglobal.h> #include <QtCore/qlocale.h> #include <QtCore/qstring.h> #include <QtCore/…...

CVE体系若消亡将如何影响网络安全防御格局
CVE体系的核心价值与当前危机 由MITRE运营的通用漏洞披露(CVE)项目的重要性不容低估。25年来,它始终是网络安全专业人员理解和缓解安全漏洞的基准参照系。通过提供标准化的漏洞命名与分类方法,这套体系为防御者建立了理解、优先级…...
OpenKylin安装Elastic Search8
一、环境准备 Java安装 安装过程此处不做赘述,使用以下命令检查是否安装成功。 java -version 注意:Elasticsearch 自 7.0 版本起内置了 OpenJDK,无需单独安装。但如需自定义 JDK,可设置 JAVA_HOME。 二、安装Elasticsearch …...
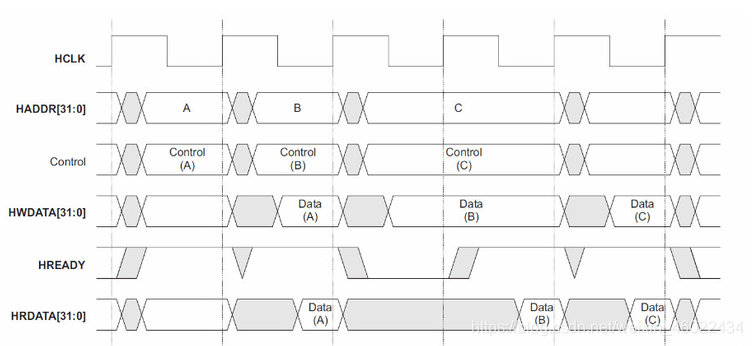
【ARM AMBA AHB 入门 3 -- AHB 总线介绍】
请阅读【ARM AMBA 总线 文章专栏导读】 文章目录 AHB Bus 简介AHB Bus 构成AHB BUS 工作机制AHB 传输阶段 AHB InterfacesAHB仲裁信号 AHB 数据访问零等待传输(no waitstatetransfer)等待传输(transfers with wait states)多重传送(multipletransfer)--Pipeline AHB 控制信号 A…...

多模态大模型中的视觉分词器(Tokenizer)前沿研究介绍
文章目录 引言MAETok背景方法介绍高斯混合模型(GMM)分析模型架构 实验分析总结 FlexTok背景方法介绍模型架构 实验分析总结 Emu3背景方法介绍模型架构训练细节 实验分析总结 InternVL2.5背景方法介绍模型架构 实验分析总结 LLAVA-MINI背景方法介绍出发点…...
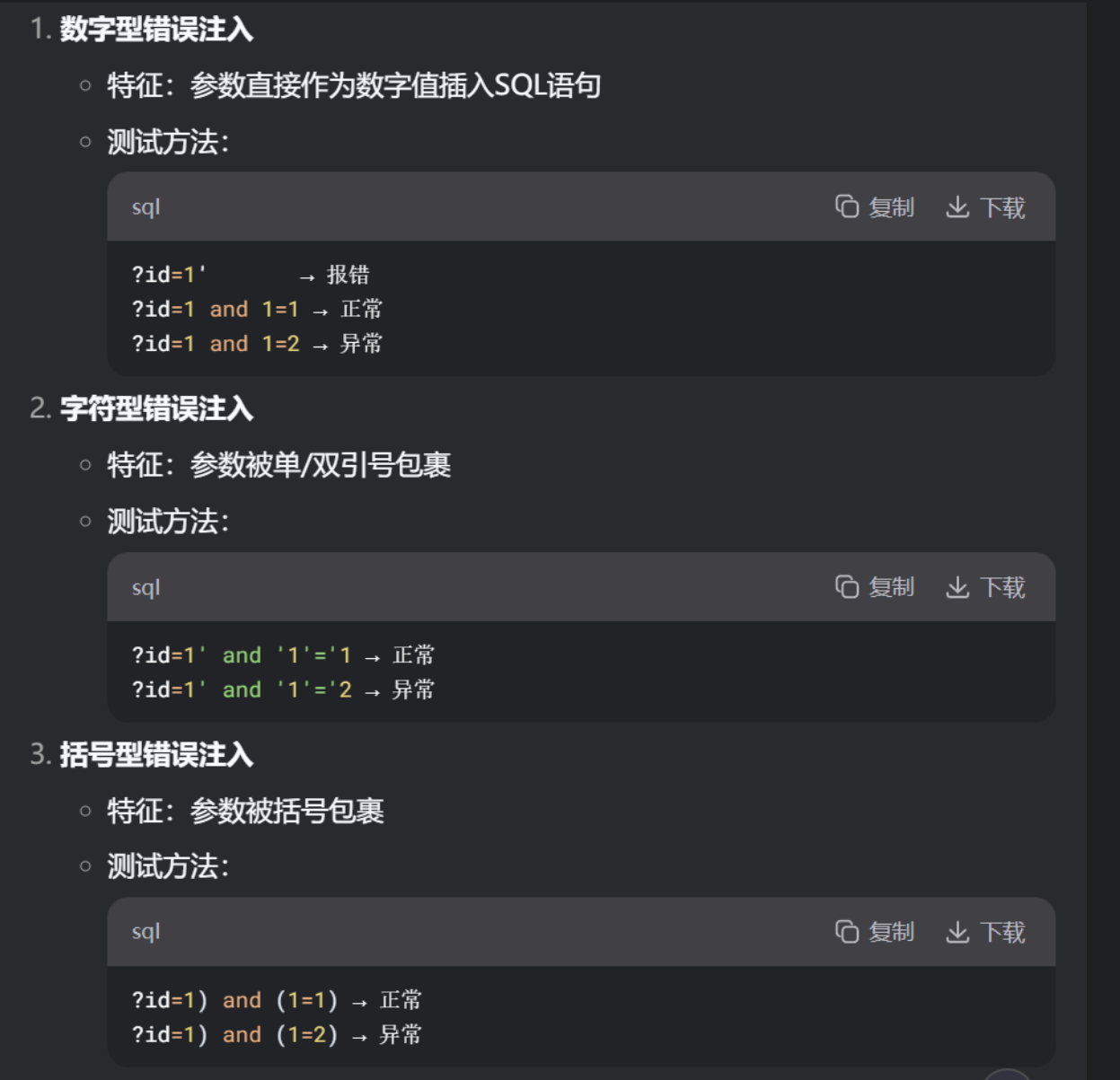
sqli-labs靶场第二关——数字型
一:查找注入类型: 输入 ?id1--与第一关的差别:报错; 说明不是字符型 渐进测试:?id1--,结果正常,说明是数字型 二:判断列数和回显位 ?id1 order by 3-- 正常, 说明有三列&am…...

使用FastAPI微服务在AWS EKS上实现AI会话历史的管理
架构概述 本文介绍如何使用FastAPI构建微服务架构,在AWS EKS上部署两个微服务: 服务A:接收用户提示服务B:处理对话逻辑,与Redis缓存和MongoDB数据库交互 该架构利用AWS ElastiCache(Redis)实现快速响应,…...
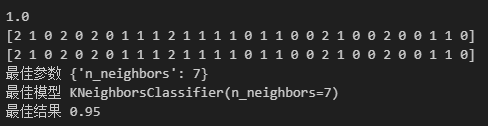
[模型选择与调优]机器学习-part4
七 模型选择与调优 1 交叉验证 (1) 保留交叉验证HoldOut HoldOut Cross-validation(Train-Test Split) 在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集ÿ…...

【计算机网络-数据链路层】以太网、MAC地址、MTU与ARP协议
📚 博主的专栏 🐧 Linux | 🖥️ C | 📊 数据结构 | 💡C 算法 | 🅒 C 语言 | 🌐 计算机网络 上篇文章:传输层-TCP协议TCP核心机制与可靠性保障 下篇文章: 网络…...

学习适应对智能软件对对象的属性进行表征、计算的影响
下面的链接是我新发表的文章。这篇文章是关于智能软件对对象进行标志、表征的问题,这是所有智能实体都无法回避的基本问题。 我最近写了一篇关于奖惩系统的文章。并开始写智能是如何在基础编程的基础上涌现出来的文章。 https://www.oalib.com/articles/6857382 …...

vue 组件函数式调用实战:以身份验证弹窗为例
通常我们在 Vue 中使用组件,是像这样在模板中写标签: <MyComponent :prop"value" event"handleEvent" />而函数式调用,则是让我们像调用一个普通 JavaScript 函数一样来使用这个组件,例如:…...