搜索引擎工作原理|倒排索引|query改写|CTR点击率预估|爬虫
写在前面
使用搜索引擎是我们经常做的事情,搜索引擎的实现原理。
什么是搜索引擎
搜索引擎是一种在线搜索工具,当用户在搜索框输入关键词时,搜索引擎就会将与该关键词相关的内容展示给用户。比较大型的搜索引擎有谷歌,百度,必应。
像我们嵌入在app里面的搜索,也是搜索引擎。只不过上面的搜索引擎是 搜全网,把全网的网站放到自己的数据库中,app里面的搜索一般只是站内信息的搜索。
搜索引擎的原理
相对成熟的搜索引擎工作原理可以分为爬虫、索引、排名三个步骤:
- 爬虫(Crawler):这是一种自动化程序,爬虫可以搜索网页并将找到的网页保存到搜索引擎的数据库中,以便进行索引。
- 索引(Indexing):索引是搜索引擎给每个网页分配一个关键字,以便搜索引擎能够快速地找到对应的网页。
- 排名(Ranking):排序是搜索引擎根据搜索结果进行打分排序,根据相关性的高低进行排名,以便用户能够找到最相关的网页。当然,一些搜索引擎偶尔也会在排名中穿插广告。
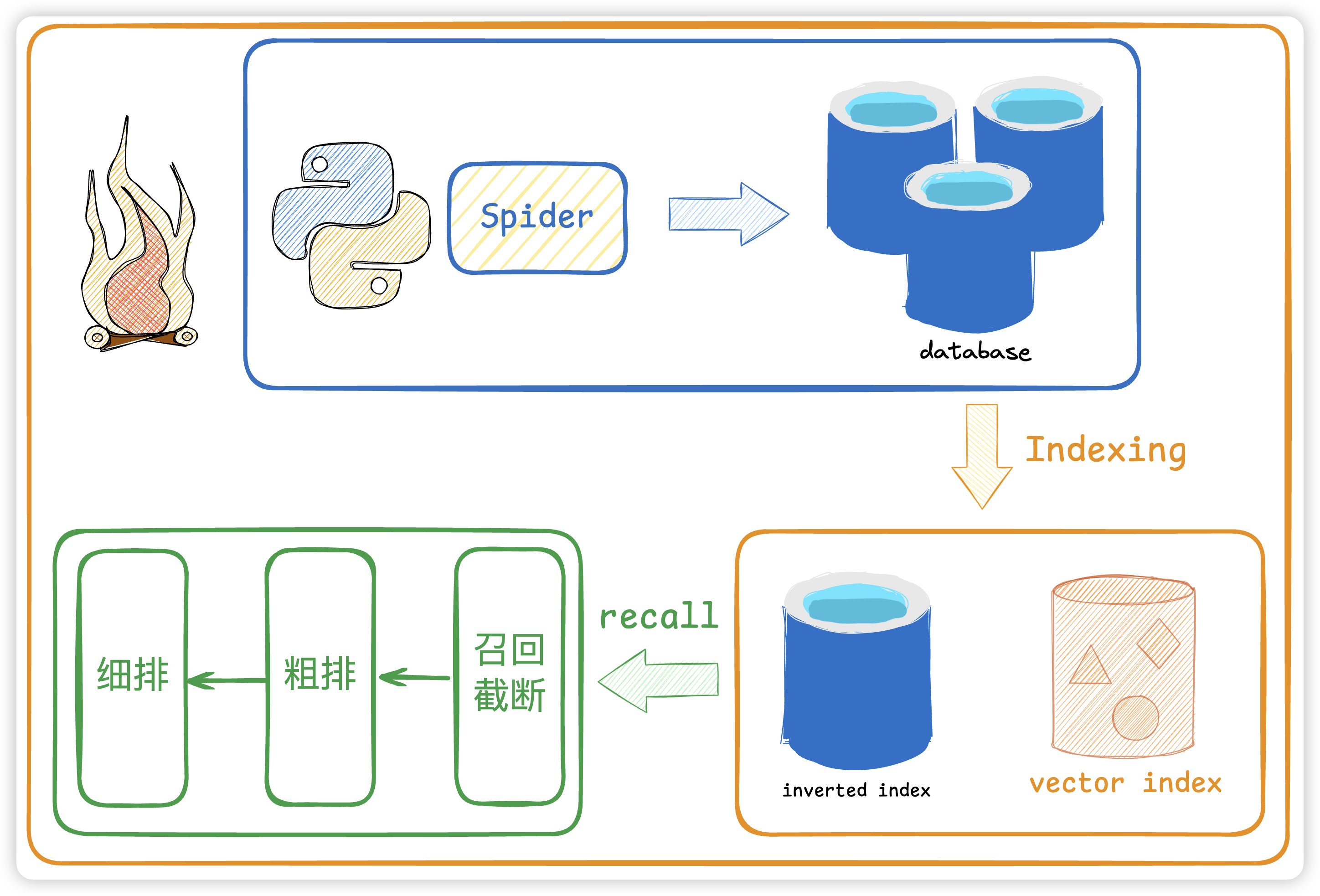
那么我们一点点来讲讲搜索引擎的这三个步骤。
爬虫
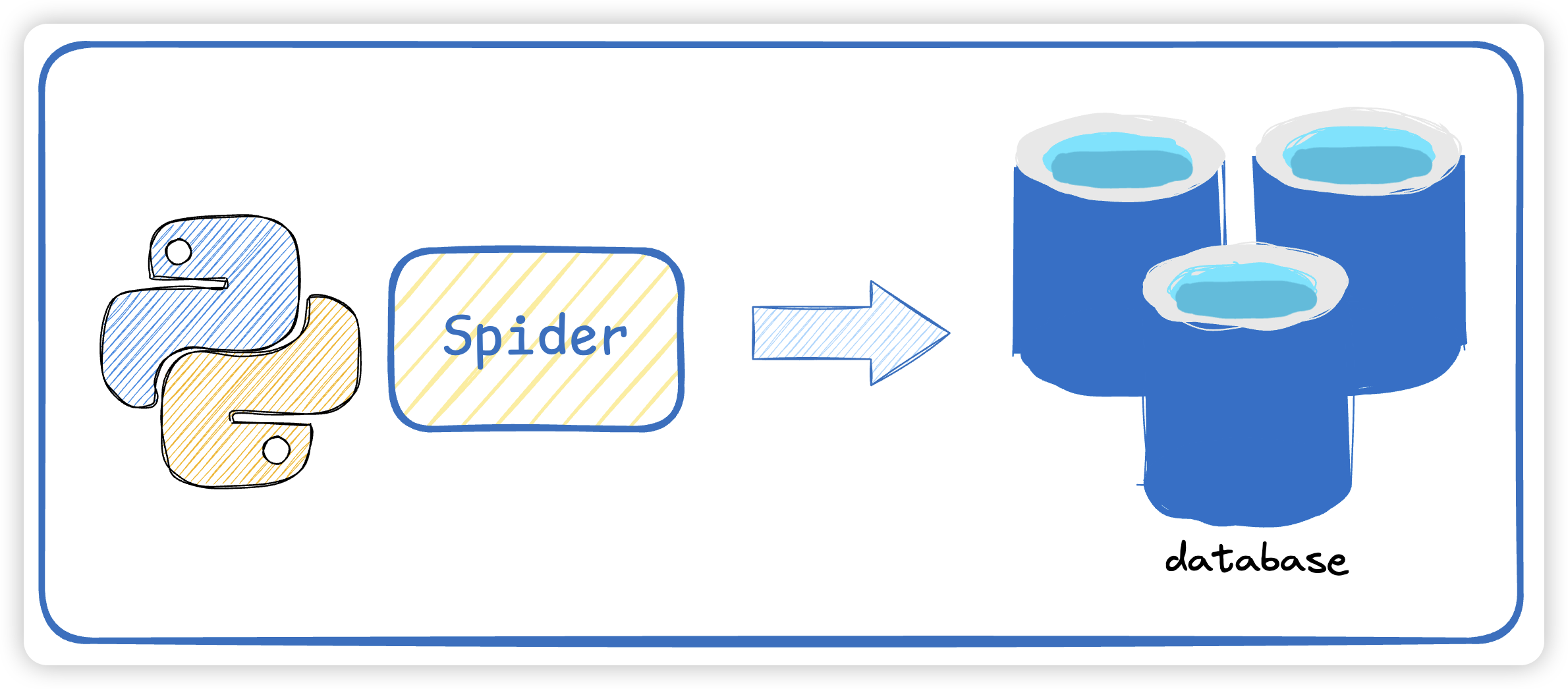
搜索引擎会派出一个抓取网页的代码程序用来发现新网页,通常被称为爬虫。这是一种自动抓取网络信息的程序,通过模拟人类访问网站的行为,自动访问网站,抓取网站上的信息,将抓取到的信息保存到数据库中。
首先,爬虫会从一个或多个指定的网址开始,然后根据程序设定的规则,从网页中抓取所需要的信息,并将抓取的信息保存到自己的数据库中。抓取的过程中,爬虫会不断地从网页中提取出新的网址,然后继续抓取,这一过程会一直持续下去,直到爬虫抓取到所有符合要求的信息为止。
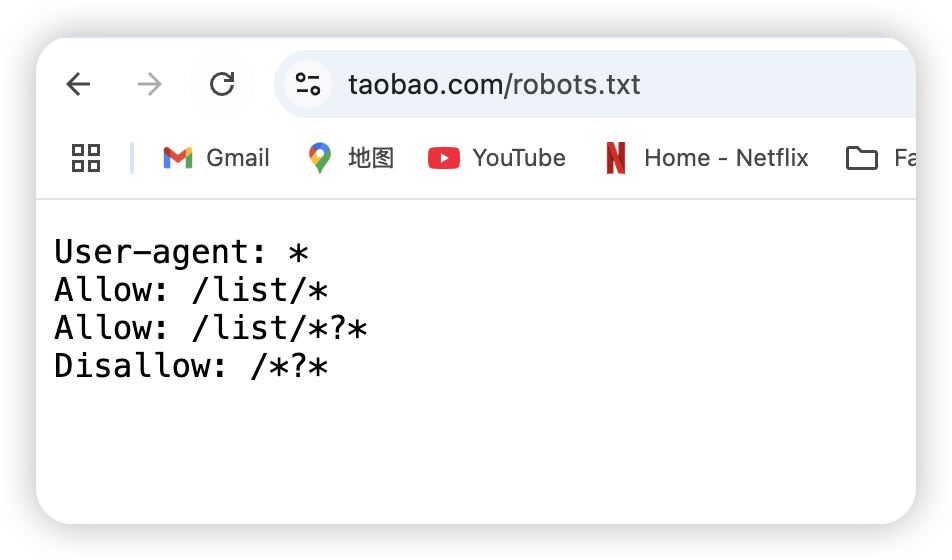
而爬虫会根据项目的robots.txt文件的内容来选择是否爬取该网站的信息。比如这个就是 B站 的 robots.txt。
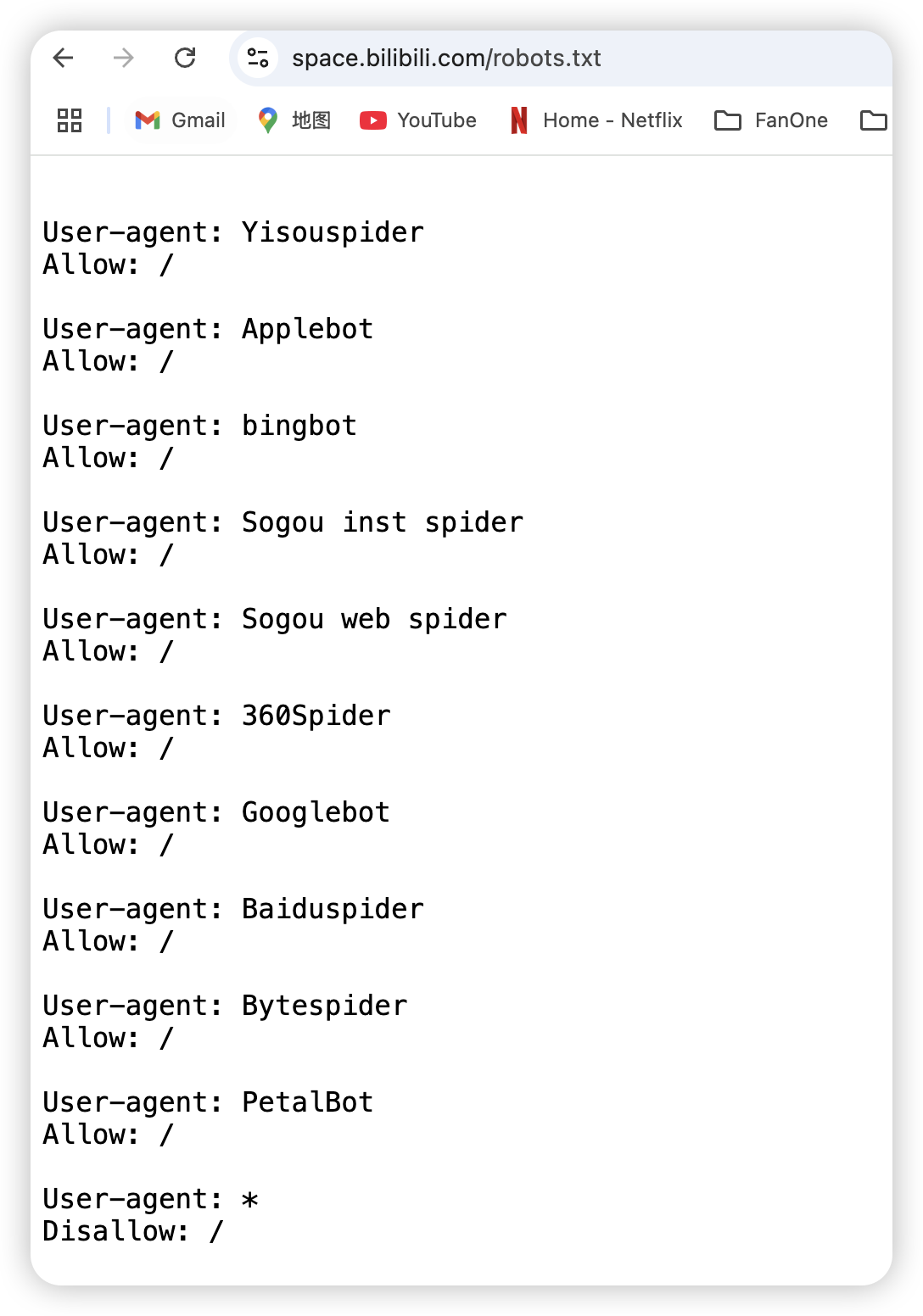
我们可以看到,b站的robots.txt 和其他网站的robots.txt 都是类似的,都希望自己的页面被各个搜索引擎的爬虫收录。一般的网站都希望被搜索引擎的爬虫访问,这样网站的流量入口就多了一个。
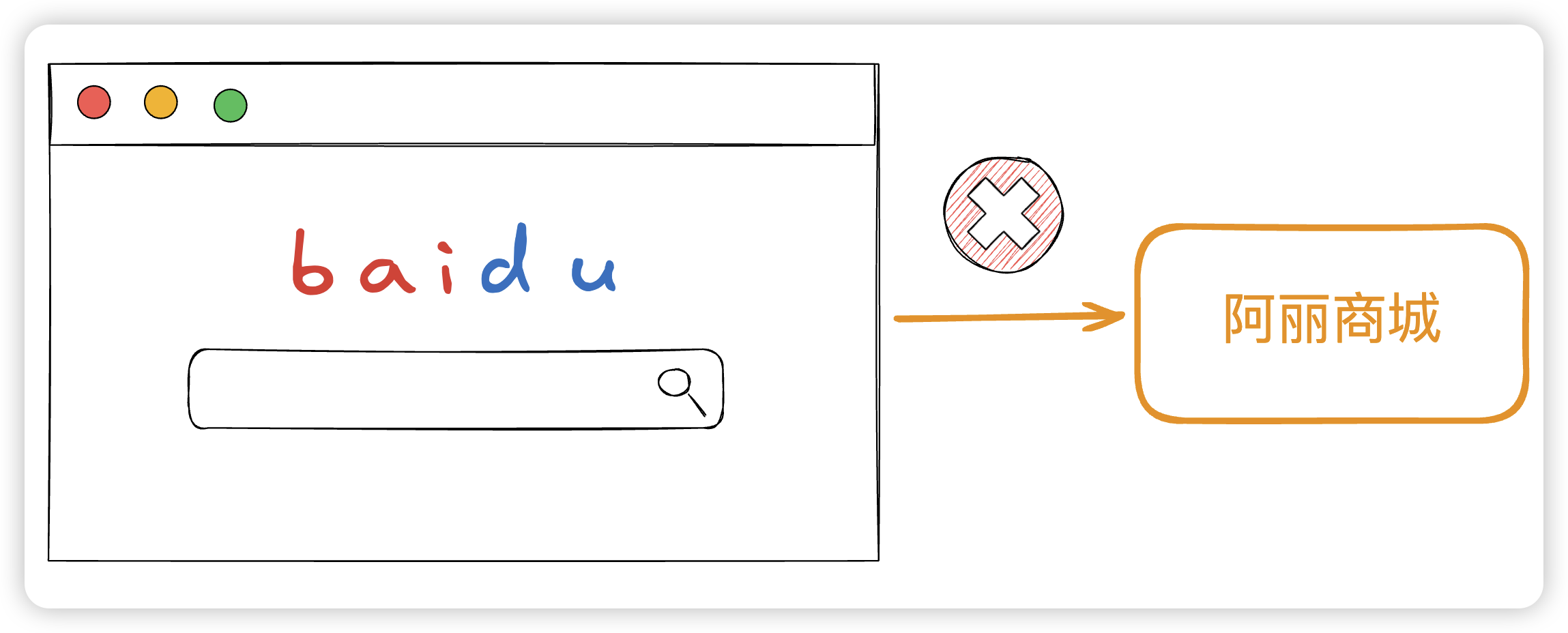
当然也有一些网站不希望自己被搜索引擎爬取,比如淘宝,这样大家只能在淘宝的网站搜索商品,而不能在其他入口搜索淘宝的商品。
看到这里,你可能会疑惑,搜索引擎不是全网搜索吗? 难道有些网站,还会出现在百度能搜出来,在其他搜索引擎就搜不出来情况?
其实我们所谓的搜索引擎全网搜,这个全网是一个 伪全网 。我们进入百度的搜索引擎页面,其实我们进入了是百度这个网站,只是这个网站的爬虫收录了很多其他的网站,让你以为你是在全网
举个例子,我新上线了一个网站,就叫 “阿丽商城” ,我不想让我的网页被百度收录,那我就可以在 robots.txt 设置不让百度的爬虫爬去收录。这样当你百度 “阿丽商城” 的时候,在百度的网站上就没有任何 “阿丽商城” 的信息了。
索引
我们了解完爬虫之后,我们来讲讲索引。2025年全球的域名数量已经突破 3.68亿, 每个网站又有数不胜数的子页面,网页内容等等,再加上这个信息爆炸的时代,搜索引擎的数据库中已经收录了数以万亿级的网站信息,这时候,为了快速找到对应的网址,我们就要对这些网站信息建立索引。
索引一般分成正排索引和倒排索引:
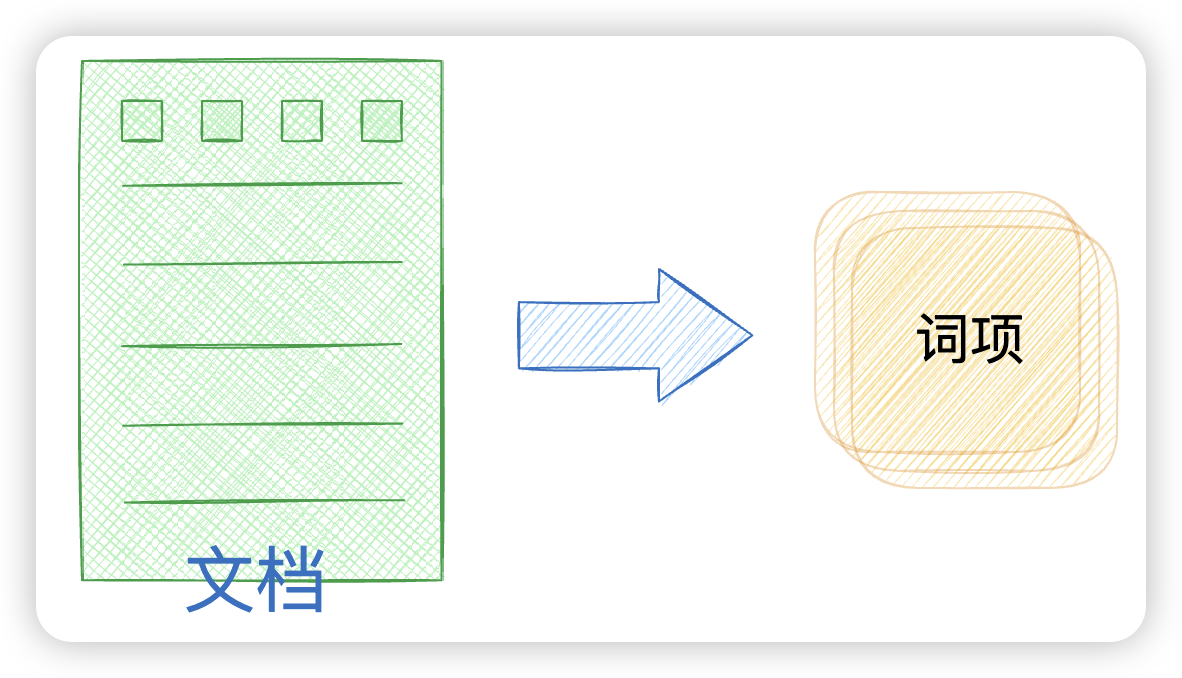
正排索引是一种"文档→词项"的索引结构,它按照文档的顺序存储每个文档中包含的词项。
比如有一组网页
- 网页A:山西苹果是一种水果
- 网页B:橘子是一种水果
- 网页C:广西苹果是一种苹果
这样当你看到网页A,就知道山西苹果是一种水果的这个词项。
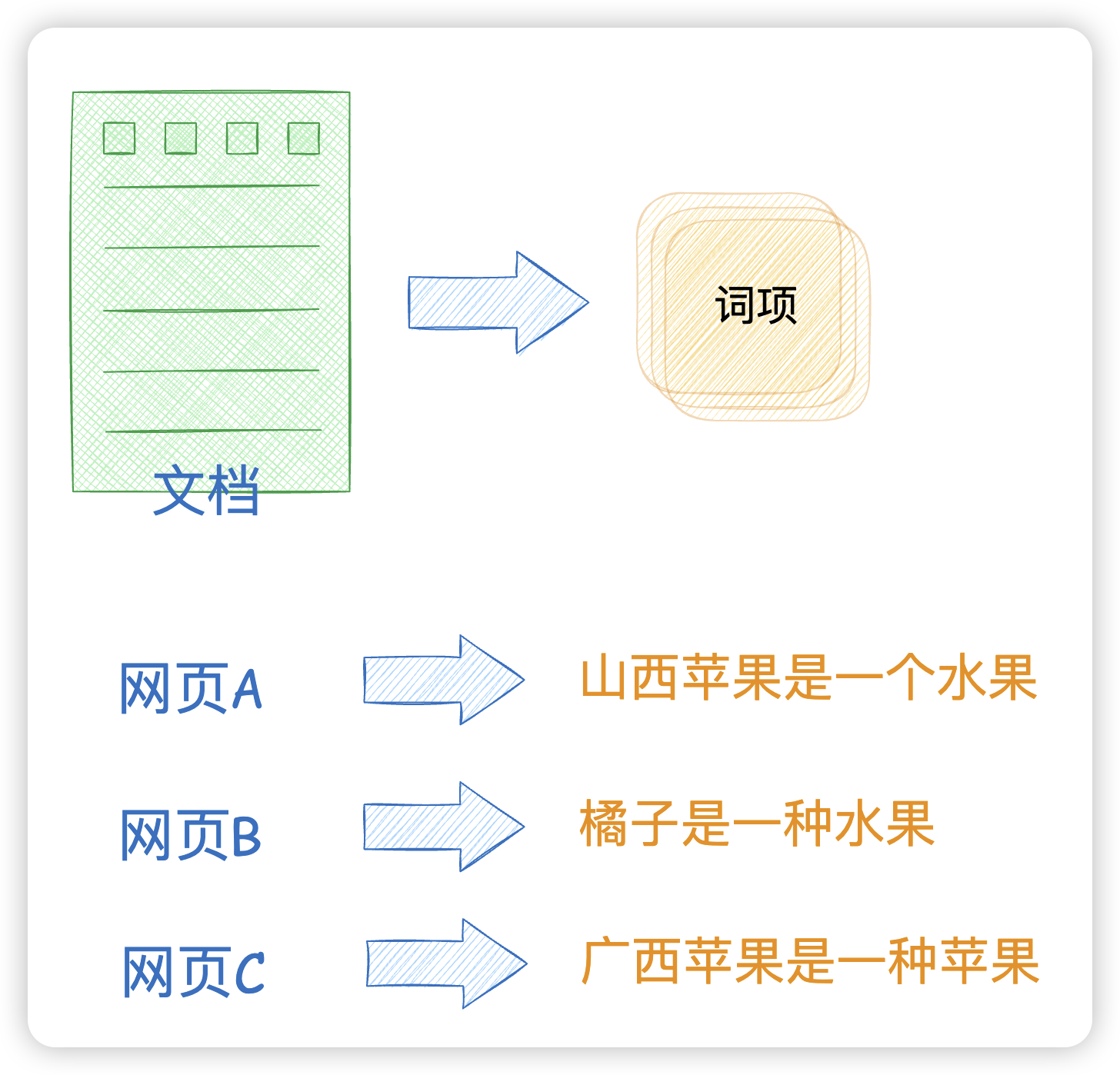
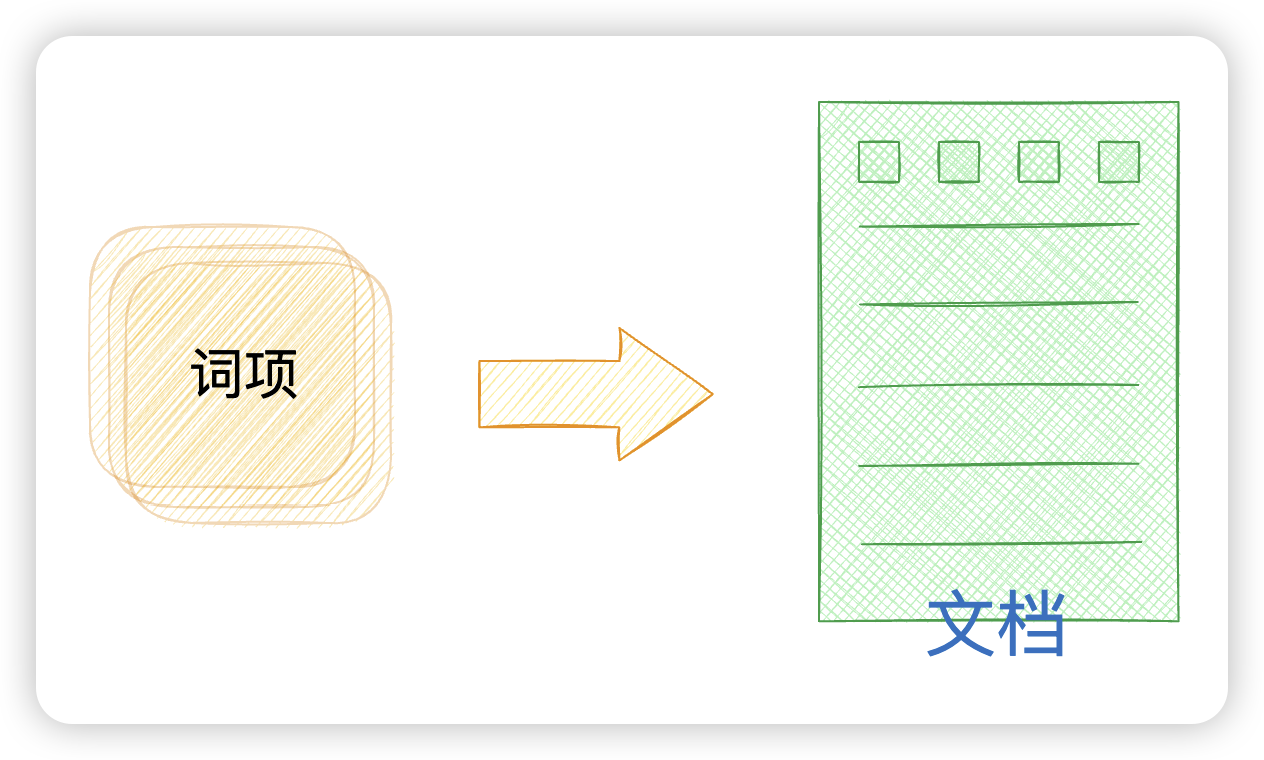
而搜索引擎一般是建立倒排索引,一种"词项→文档"的索引结构,记录每个词项出现在哪些文档中。
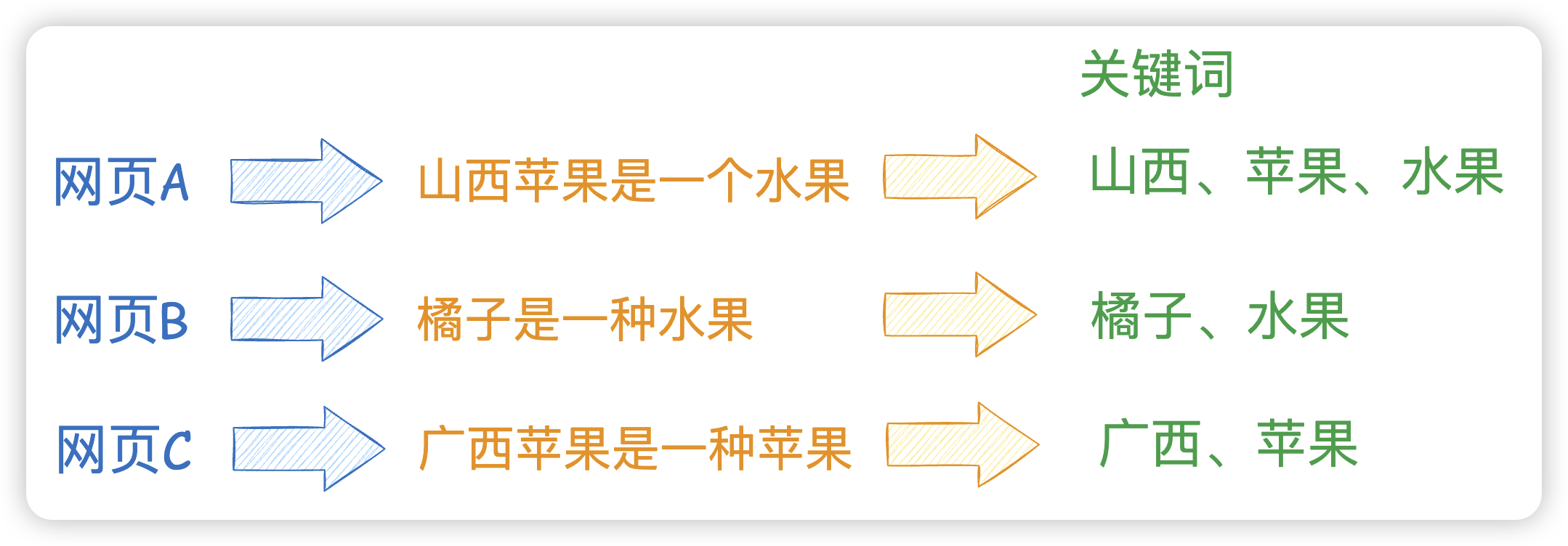
按照上面的例子建立倒排索引,那么就需要先提取关键词,还是上面的例子:
- 网页A:山西苹果是一种水果 -> 提取关键字
山西、苹果、水果 - 网页B:橘子是一种水果 -> 提取关键字
橘子、水果 - 网页C:广西苹果是一种苹果 -> 提取关键字
广西、苹果
倒排索引表如下:
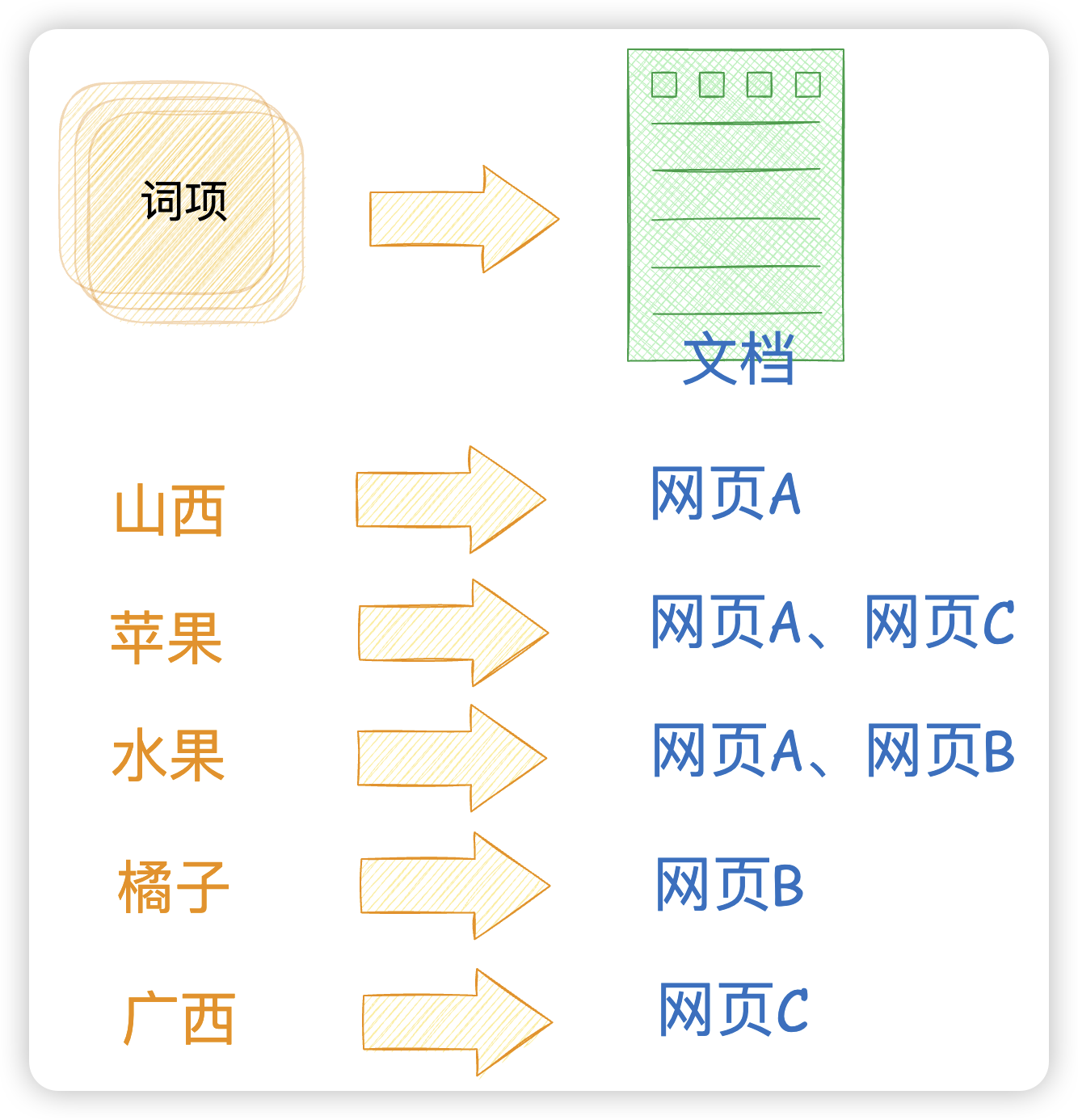
当我们搜索苹果的时候就会出现网页A和网页C,搜索水果的时候,就会出现网页A和网页B。
当然不仅只有倒排索引,还会有其他的索引结构,比如向量索引。当用户搜索的时候,会根据不同的索引数据源、不同的策略做召回,尽可能的召回多点数据,文本召回,向量召回,离线召回,这种叫多路召回。
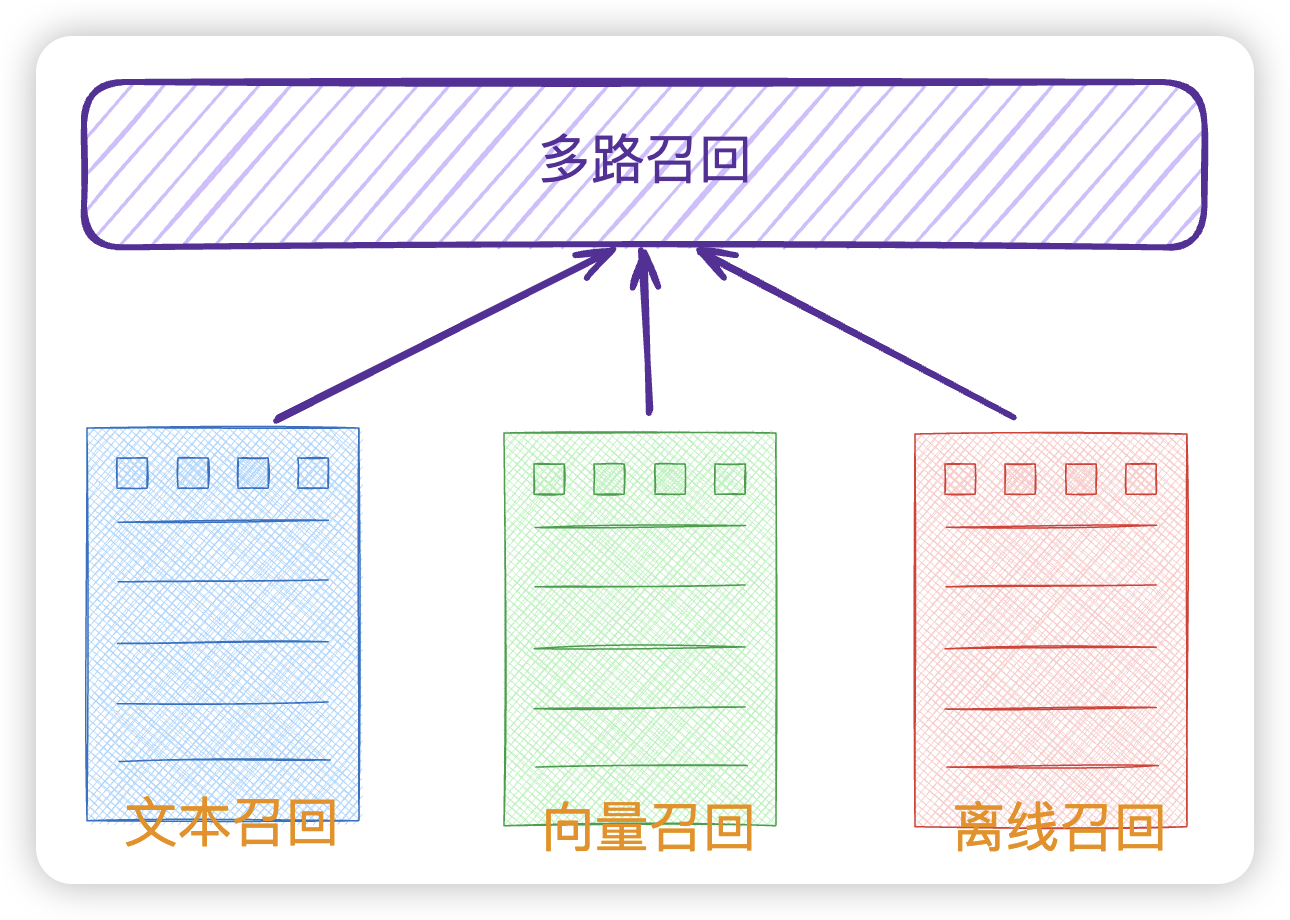
最近这两年,随着大模型的兴起,也开始有了生成式召回。
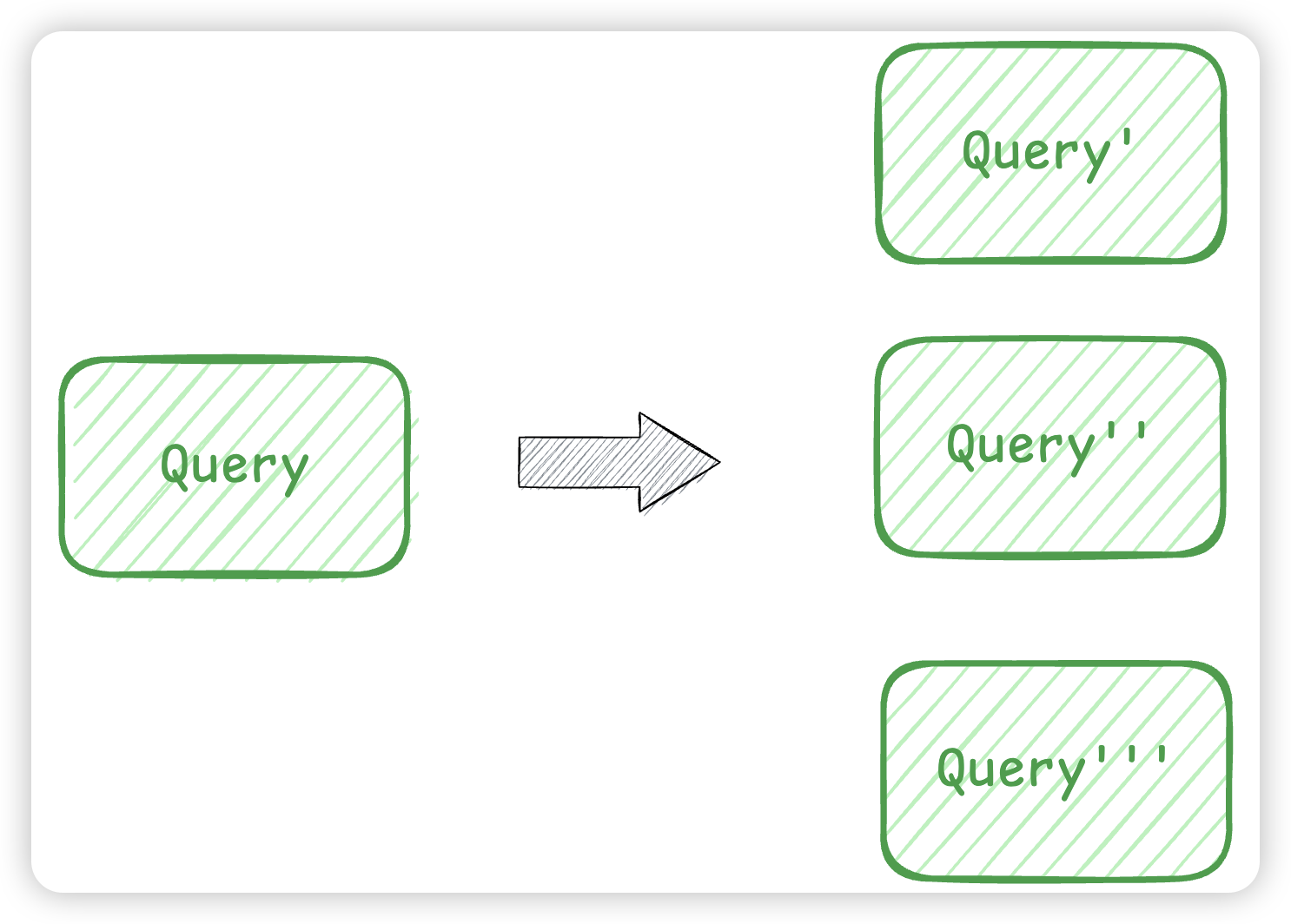
此外搜索引擎还会进行query搜索词改写,虽然向量召回能召回语义类似的词,但是文本召回不行。而query改写能提高我们的召回准确率:
- 扩展相关词,确保不遗漏重要结果,提高召回率,比如搜索”苹果CEO“,改写成苹果公司CEO,TimCook
- 纠正错误查询,更精准匹配用户意图,提升准确率,比如苹里公司改写成苹果公司
- 即使查询不完美,也能得到理想结果,改善用户体验,搜索”附近火锅“,会附带上了地点信息改写成xxx地点附近的火锅
接着问题出现了,我们召回成千上万个可能相关的网页,究竟是哪些网页出现在前面呢?这就涉及到了搜索引擎最后一个步骤,结果的计算排名。
排名
经过这么多年的发展,谷歌的页面排名规则已经非常复杂,但是没有人知道具体规则是什么。在召回尽可能多的数据之后,会进行召回截断、粗排、精排,这三种情况会呈现漏洞式削峰,从数万到数千、再到数百条数据,最后再次进行打分排序。
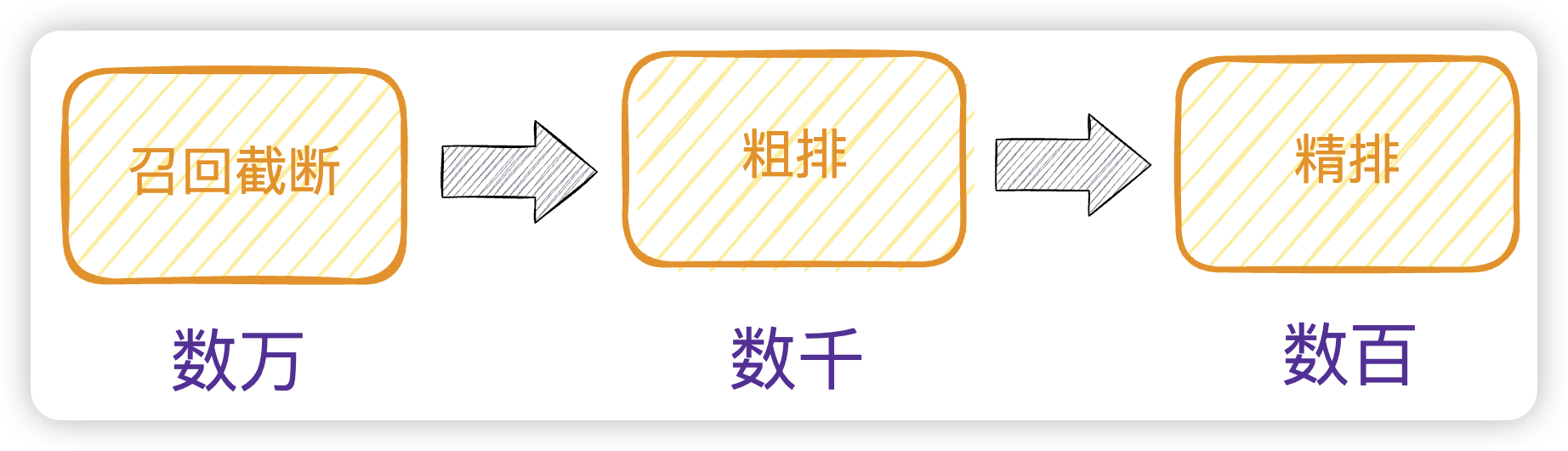
而点击率预估模型就是来做筛选的事情,这个模型顾名思义,预算估计每个召回网页的点击率会是多少,从而将点击率高的网页排在前面。
那么影响点击率的因素有哪些呢?
- 内容相关性: 页面标题与用户查询关键词的相关性,相关性越高的页面,排名就越靠前,也越能满足用户需求。
- 内容质量:
现在越来越提倡高质量内容输出了,也就是说哪怕你的内容相关性很高,但是其质量低下,也很难获得很好的排名。比如页面充斥了关键词堆砌、来源模糊的信息,重复度很高等。 - 链接权重: 链接主要有站内链接和站外链接两种,某种角度上来说,某个页面得到的链接越多,在一定程度上反映了该页面内容丰富,相对应的链接权重也就越高,比如
维基百科。 - 页面加载速度: 现在这年代,网页的加载速度越来越重要了,
每个人愿意在我们网页上停留的时间可能1秒都不到,这时候如果我们页面要过好几秒才能加载成功,用户可能早就不耐烦的关闭网页走人了。那我们前面做了那么多高质量的内容也就失去了意义。 - 竞价排名: 通过竞标方式与特定的关键词挂钩。广告金主针对某一关键词给出的竞标金额越高,当访问者以该关键词搜索时,该广告金主的网站排名越靠前。
当然排序规则远远不止上面说的这些,还有很多可能的规则,这里就不再一一列举。
参考文献
https://dmthought.com/search-engine-working-principle/
https://zhuanlan.zhihu.com/p/208846943
https://www.xnbeast.com/google-algorithm-ranking-factors/
相关文章:
搜索引擎工作原理|倒排索引|query改写|CTR点击率预估|爬虫
写在前面 使用搜索引擎是我们经常做的事情,搜索引擎的实现原理。 什么是搜索引擎 搜索引擎是一种在线搜索工具,当用户在搜索框输入关键词时,搜索引擎就会将与该关键词相关的内容展示给用户。比较大型的搜索引擎有谷歌,百度&…...

Python实例题:Python自动工资条
目录 Python实例题 题目 python-automatic-payroll-slipPython 自动生成工资条脚本 代码解释 加载文件: 获取表头: 写入表头: 生成工资条: 保存文件: 运行思路 注意事项 Python实例题 题目 Python自动工资…...

Function Calling万字实战指南:打造高智能数据分析Agent平台
个人主页:Guiat 归属专栏:科学技术变革创新 文章目录 1. Function Calling:智能交互的新范式1.1 Function Calling 技术概述1.2 核心优势分析 2. 数据分析Agent平台架构设计2.1 系统架构概览2.2 核心组件解析2.2.1 函数注册中心2.2.2 Agent控…...

spark MySQL数据库配置
Spark 连接 MySQL 数据库的配置 要让 Spark 与 MySQL 数据库实现连接,需要进行以下配置步骤。下面为你提供详细的操作指南和示例代码: 1. 添加 MySQL JDBC 驱动依赖 你得把 MySQL 的 JDBC 驱动添加到 Spark 的类路径中。可以通过以下两种方式来完成&a…...

python四则运算计算器
python四则运算计算器 是谁说,python不好写计算器的,我亲自写个无ui的计算器功能,证明这是谣言 step1:C:\Users\wangrusheng\Downloads\num.txt 15 - 4 * 3 10 / 2(5 3) * 2 6 / 31/2 * 8 3/4 * 4 - 0.52.5 * (4 1.6) - 9 / 3-6 12 * (…...

线对板连接器的兼容性问题:为何老旧设计难以满足现代需求?
线对板连接器作为电子设备的核心纽带,正面临前所未有的兼容性挑战。某智能工厂升级生产线时发现,沿用十年的2.54毫米间距连接器,在接入新型工业相机时出现30%的信号丢包率,而切换至0.4毫米超密间距连接器后,数据传输速…...
AI517 AI本地部署 docker微调(失败)
本地部署AI 计划使用OLLAMA进行本地部署 修改DNS 访问github 刷新缓存 配置环境变量 OLLAMA安装成功 部署成功 计划使用docker进行微调 下载安装docker 虚拟化已开启 开启上面这些 准备下载ubuntu docker ragflow dify 用git去泡...

VR和眼动控制集群机器人的方法
西安建筑科技大学信息与控制工程学院雷小康老师团队联合西北工业大学航海学院彭星光老师团队,基于虚拟现实(VR)和眼动追踪技术实现了人-集群机器人高效、灵活的交互控制。相关研究论文“基于虚拟现实和眼动的人-集群机器人交互方法” 发表于信…...

python训练营打卡第26天
函数专题1:函数定义与参数 知识点回顾: 函数的定义变量作用域:局部变量和全局变量函数的参数类型:位置参数、默认参数、不定参数传递参数的手段:关键词参数传递参数的顺序:同时出现三种参数类型时 作业&…...
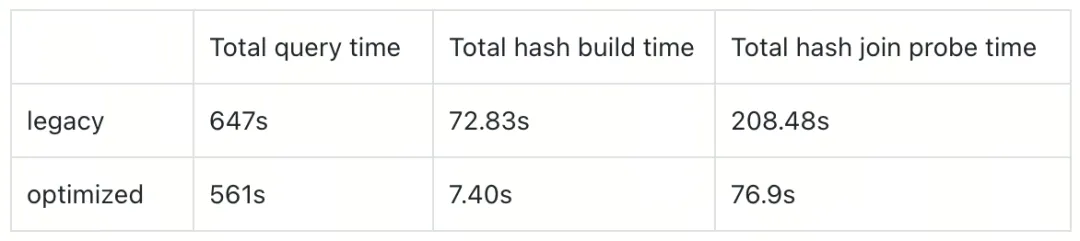
TiDB 中新 Hash Join 的设计与性能优化
原文来源: https://tidb.net/blog/11667c37 本文作者:徐飞 导读 在数据库管理系统(DBMS)中,连接操作(Join)是查询处理的核心环节之一,其性能直接影响到整个系统的响应速度和效率…...
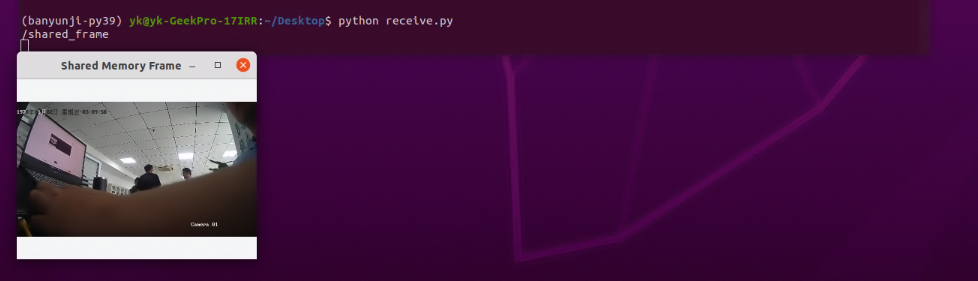
1.共享内存(python共享内存实际案例,传输opencv frame)
主进程程序 send.py import cv2 import numpy as np from multiprocessing import shared_memory, resource_trackercap cv2.VideoCapture(0) if not cap.isOpened():print("无法打开 RTSP 流,请检查地址、网络连接或 GStreamer 配置。") else:# 创建共…...

网页常见水印实现方式
文章目录 1 明水印技术实现1.1 DOM覆盖方案1.2 Canvas动态渲染1.3 CSS伪元素方案2 暗水印技术解析2.1 空域LSB算法2.2 频域傅里叶变换3 防篡改机制设计3.1 MutationObserver防护3.2 Canvas指纹追踪4 前后端实现对比5 攻防博弈深度分析5.1 常见破解手段5.2 进阶防御策略6 选型近…...

oracle主备切换参考
主备正常切换操作参考:RAC两节点->单机 (rac和单机的操作区别:就是关闭其它节点,剩一个节点操作即可) 1.主库准备 检查状态 SQL> select inst_id,database_role,OPEN_MODE from gv$database; INST_ID DATA…...

Java大师成长计划之第25天:Spring生态与微服务架构之容错与断路器模式
📢 友情提示: 本文由银河易创AI(https://ai.eaigx.com)平台gpt-4-turbo模型辅助创作完成,旨在提供灵感参考与技术分享,文中关键数据、代码与结论建议通过官方渠道验证。 在微服务架构中,系统通常…...

【ARM】MDK如何将变量存储到指定内存地址
1、 文档目标 在嵌入式系统开发中,通过MDK(Microcontroller Development Kit)进行工程配置,将指定的变量存储到指定的内存地址上是一项非常重要的技术。这项操作不仅能够满足特定硬件架构的需求,还能优化系统的性能和…...
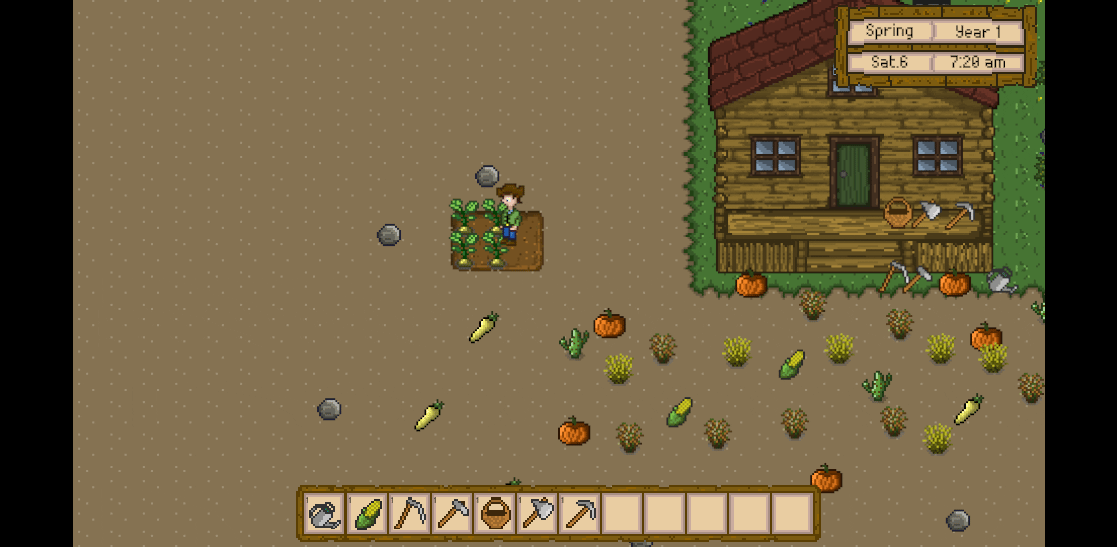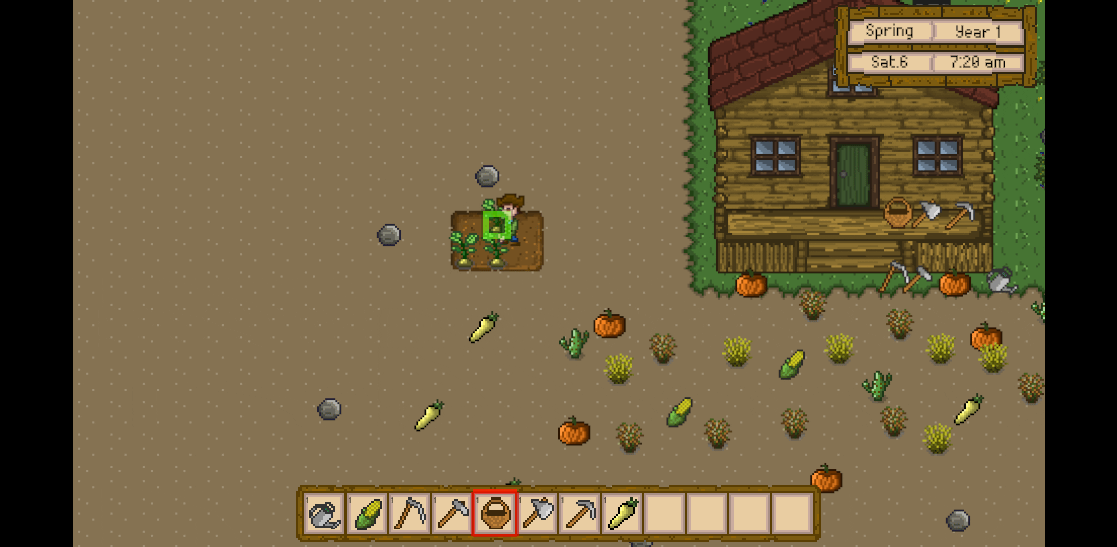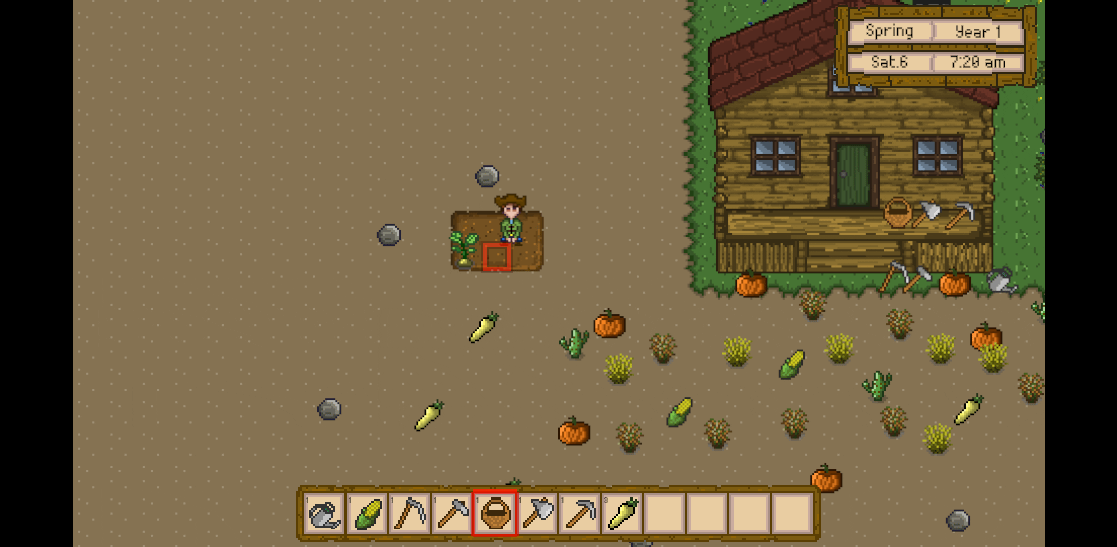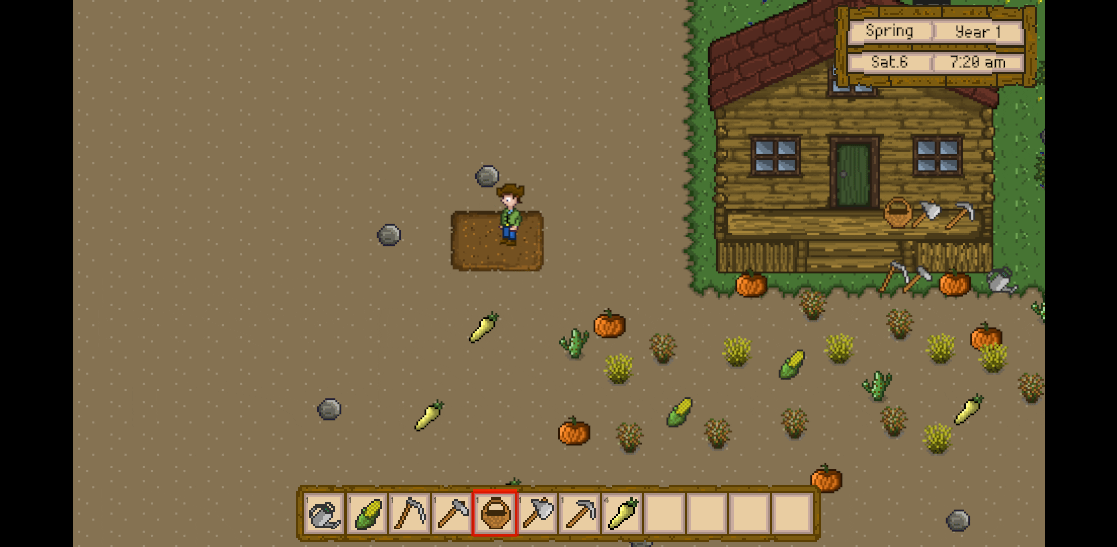
Unity3D仿星露谷物语开发44之收集农作物
1、目标 在土地中挖掘后,洒下种子后逐渐成长,然后使用篮子收集成熟后的农作物,工具栏中也会相应地增加该农作物。 2、修改CropStandard的参数 Assets -> Prefabs -> Crop下的CropStandard,修改其Box Collider 2D的Size(Y…...
langchain—chatchat
署部 下载项目 git clone --recursive https://github.com/chatchat-space/Langchain-Chatchat.git 进入目录 cd Langchain-Chatchat anaconda环境准备 创建python环境 conda create -n langchain_env python3.10 -y 激活环境 conda activate langchain_env 验证pyhton环境…...
 % mod,保证mod是质数)
经典算法 求C(N, K) % mod,保证mod是质数
求C(N, K) % mod,保证mod是质数 问题描述 给你三个整数N,K,mod保证mod是一个质数,求组合数C(N, K) % mod。 输入描述 输入有多组,输入第一行为两个整数T,mod。接下来2 - T 1行,每行输入N, K。 输出描…...

【LeetCode 热题 100】二叉树的最大深度 / 翻转二叉树 / 二叉树的直径 / 验证二叉搜索树
⭐️个人主页:小羊 ⭐️所属专栏:LeetCode 热题 100 很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~ 目录 二叉树的中序遍历二叉树的最大深度翻转二叉树对称二叉树二叉树的直径二叉树的层序遍历将有序数组转换为二叉搜索树验…...
关于软件测试开发的一些有趣的知识
文章目录 一、什么是测试?二、为什么要软件测试软件测试三、测试的岗位有哪些四 、软件测试和开发的区别五、走测试岗位为什么还要学开发。4、优秀的测试人员具备的素质我为什么走测试岗位 一、什么是测试? 其实这个问题说简单也不简单,说难…...
uni-app 开发HarmonyOS的鸿蒙影视项目分享:从实战案例到开源后台
最近,HBuilderX 新版本发布,带来了令人兴奋的消息——uni-app 现在支持 Harmony Next 平台的 App 开发。这对于开发者来说无疑是一个巨大的福音,意味着使用熟悉的 Vue 3 语法和开发框架,就可以为鸿蒙生态贡献自己的力量。 前言 作…...

售前工作.工作流程和工具
第一部分 售前解决方案及技术建议书的制作 售前解决方案编写的标准操作步骤SOP: 售前解决方案写作方法_哔哩哔哩_bilibili 第二部分 投标过程关键活动--商务标技术方案 1. 按项目管理--售前销售项目立项 销售活动和销售线索的跟踪流程和工具 1)拿到标书ÿ…...
GPU与NPU异构计算任务划分算法研究:基于强化学习的Transformer负载均衡实践
点击 “AladdinEdu,同学们用得起的【H卡】算力平台”,H卡级别算力,按量计费,灵活弹性,顶级配置,学生专属优惠。 引言 在边缘计算与AI推理场景中,GPU-NPU异构计算架构已成为突破算力瓶颈的关键技…...

学习ai课程大纲
以下是一个通用的 AI 课程大纲,涵盖从基础到进阶的核心内容,适用于大学课程或自学规划。你可以根据自身需求(如入门、进阶、专项方向)调整内容和深度。 人工智能(AI)课程大纲 第一部分:基础理论…...

基于CentOS7制作OpenSSL 1.1的RPM包
背景:CentOS7 已经不再维护了,有时候需要升级某些组件,网上却没有相关的资源了。尤其是制作OpenSSH 9.6 的RPM包,就会要求OpenSSL为1.1的版本。基于此,还是自己制作吧,以下是踩坑过程。 1、官网提供的源码包…...

数据分析_Python
1 分析内容 1.1 数据的整体概述 提供数据集的基本信息,包括数据量、时间跨度、地理范围和主要字段. import pandas as pd# 创建示例数据 data {姓名: [张三, 李四, 王五, 赵六, 钱七, 孙八, 周九, 吴十],年龄: [25, 30, 35, 40, 45, 50, 55, 60],性别: [男, 男, 女, 女, 男,…...

TCP/UDP协议原理和区别 笔记
从简单到难吧 区别就是TCP一般用于安全稳定的需求,UDP一般用于不那么需要完全数据的需求,比如说直播,视频等。 再然后就是TPC性能慢于UDP。 再然后我们看TCP的原理(三次握手,数据传输,四次挥手࿰…...

深入浅出:C++数据处理类与计算机网络的巧妙类比
深入浅出:C数据处理类与计算机网络的巧妙类比 引言 在计算机编程中,我们常常会遇到一些看似简单的代码结构,却能巧妙地映射到复杂的计算机网络概念中。本文将通过一个简单的C数据处理类,探讨其与计算机网络中硬件设备和协议的类…...

【滑动窗口】LeetCode 209题解 | 长度最小的子数组
长度最小的子数组 前言:滑动窗口一、题目链接二、题目三、算法原理解法一:暴力枚举解法二:利用单调性,用滑动窗口解决问题那么怎么用滑动窗口解决问题?分析滑动窗口的时间复杂度 四、编写代码 前言:滑动窗口…...

在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程
在RK3588上使用NCNN和Vulkan加速ResNet50推理全流程 前言:为什么需要关注移动端AI推理一、环境准备与框架编译1.1 获取NCNN源码1.2 安装必要依赖1.3 编译NCNN二、模型导出与转换2.1 生成ONNX模型2.2 转换NCNN格式三、模型量化加速3.1 生成校准数据3.2 执行量化操作四、性能测试…...