【论文阅读】LLaVA-OneVision: Easy Visual Task Transfer
LLaVA-OneVision: Easy Visual Task Transfer
-
原文摘要
-
研究背景与目标
-
开发动机:
- 基于LLaVA-NeXT博客系列对数据、模型和视觉表征的探索,团队整合经验开发了开源大型多模态模型 LLaVA-OneVision。
-
核心目标:
- 突破现有开源LMM的局限,实现单一模型在三大计算机视觉场景(单图像、多图像、视频)中的高性能表现。
-
关键创新点
-
多场景统一建模:
- 首次实现单一模型在单图像理解、多图像推理和视频理解任务上的全面领先。
-
跨模态迁移学习:
- 模型设计强调模态间知识迁移(如图像到视频),通过共享表征学习,无需针对不同场景单独训练模型。
- 这种设计催生了新兴能力,例如从图像任务中学习到的知识可直接提升视频理解性能。
-
-
-
1. Introduction
-
研究背景与目标
-
AI发展目标:
- 构建 通用多模态助手(General-purpose assistants)是AI领域的核心追求,大型多模态模型(LMM)是实现这一目标的关键技术。
-
LLaVA系列定位:
- LLaVA-OneVision是开源模型,延续了LLaVA系列的研究路线,旨在开发能通过多样化指令完成复杂计算机视觉任务的视觉-语言助手。
-
-
LLaVA系列演进
-
LLaVA初代模型:
- 展示了强大的多模态对话能力,在未见过图像和指令上表现出与GPT-4V相似的行为。
-
LLaVA-1.5:
- 通过纳入更多学术相关指令数据(academic-related instruction data),显著提升能力,在数十个基准测试中达到SOTA性能,且保持数据高效性。
-
LLaVA-NeXT:
- 继承前代优势,通过三项关键技术进一步突破性能边界:
- AnyRes:处理高分辨率图像;
- 扩展高质量指令数据;
- 使用当时最优开源LLM。
- 继承前代优势,通过三项关键技术进一步突破性能边界:
-
-
LLaVA-NeXT的探索
- 原型特性:LLaVA-NeXT提供可扩展和可伸缩的原型,支持多项并行探索:
-
Video blog:
- 发现仅用图像训练的LLaVA-NeXT模型通过零样本模态迁移(zero-shot modality transfer)在视频任务中表现优异,归因于AnyRes将视觉信号处理为图像序列的能力。
-
Stronger blog:
- 验证LLM规模扩展的有效性,仅增大LLM规模即可在部分基准上媲美GPT-4V。
-
Ablation blog:
- 总结除视觉指令数据外的实证探索,包括架构选择(LLM和视觉编码器规模)、视觉表征(分辨率与token数量)、训练策略(可训练模块与高质量数据)。
-
Interleave blog:
- 提出在多图像、多帧(视频)和多视角(3D)新场景中扩展能力的策略,同时保持单图像性能。
-
探索:这些研究在固定计算预算内进行,旨在提供项目推进中的实用见解,而非单纯追求性能极限。
-
- 原型特性:LLaVA-NeXT提供可扩展和可伸缩的原型,支持多项并行探索:
-
LLaVA-OneVision的开发与贡献
-
数据积累与实验:
- 作者团队花了6个月时间,积累并筛选了大量高质量数据集。
- 通过整合前述见解,并在新数据集上执行“yolo run”实验(未对单个组件充分去风险),推出LLaVA-OneVision。
-
模型特点:
- 在现有计算资源下实现,为后续通过数据和模型规模扩展提升能力留有空间。
-
论文贡献总结:
- 大型多模态模型:
- 开发LLaVA-OneVision模型,在单图像、多图像和视频三大视觉场景中提升开源LMM性能边界。
- 任务迁移的新兴能力:
- 通过建模和数据表征设计实现跨场景任务迁移,例如从图像到视频的迁移学习,展现强大的视频理解能力。
- 开源资源:
- 公开多模态指令数据、代码库、模型检查点和视觉聊天演示,推动通用视觉助手发展。
- 大型多模态模型:
-
2. Related Work
-
专有模型与开源模型的现状对比
-
专有LMM的领先性:
- GPT-4V 、GPT-4o 、Gemini 、Claude-3.5 等闭源模型在单图像、多图像和视频场景中均表现卓越,展现了通用多模态能力。
-
开源研究的局限性:
- 单图像场景主导:多数开源工作仅聚焦单图像任务性能提升。
- 多图像探索初期:少数近期研究开始探索多图像场景,但覆盖不足。
- 视频与图像的权衡:现有视频LMM往往以牺牲图像性能为代价优化视频理解,缺乏三场景统一的开放模型。
-
LLaVA-OneVision的定位:
- 旨在填补上述空白,首次实现单一开源模型在三大场景中的SOTA性能,并通过跨场景任务迁移(如图像→视频)展现新兴能力。
-
-
多场景统一模型的早期工作
-
LLaVA-NeXT-Interleave:
- 首次在单图像、多图像和视频三场景中均报告良好性能,LLaVA-OneVision继承其训练方案与数据并进一步优化。
-
其他潜力模型:
- VILA 和 InternLM-XComposer-2.5 虽具备多场景潜力,但未完整评估三场景性能。
-
-
数据策略与知识来源
- 高质量数据的关键作用:
- 模型合成知识:继承LLaVA-NeXT中的知识学习数据。
- 指令调优数据:
- 受 FLAN启发,采用小规模但精细筛选的数据集(与Idefics2、Cambrian-1同期收集但更注重质量)。
- 结论与同行一致:大量视觉指令数据显著提升性能,但LLaVA-OneVision更强调数据质量而非单纯规模。
- 高质量数据的关键作用:
-
LMM设计选择的参考研究
- 相关系统性研究:
- 论文引用近期工作对LMM架构、训练策略的探索,包括:
- 视觉编码器与LLM的连接方式
- 视觉表征(分辨率、token数量)优化
- 数据扩展与模型缩放的影响
- 论文引用近期工作对LMM架构、训练策略的探索,包括:
- 相关系统性研究:
3. Modeling
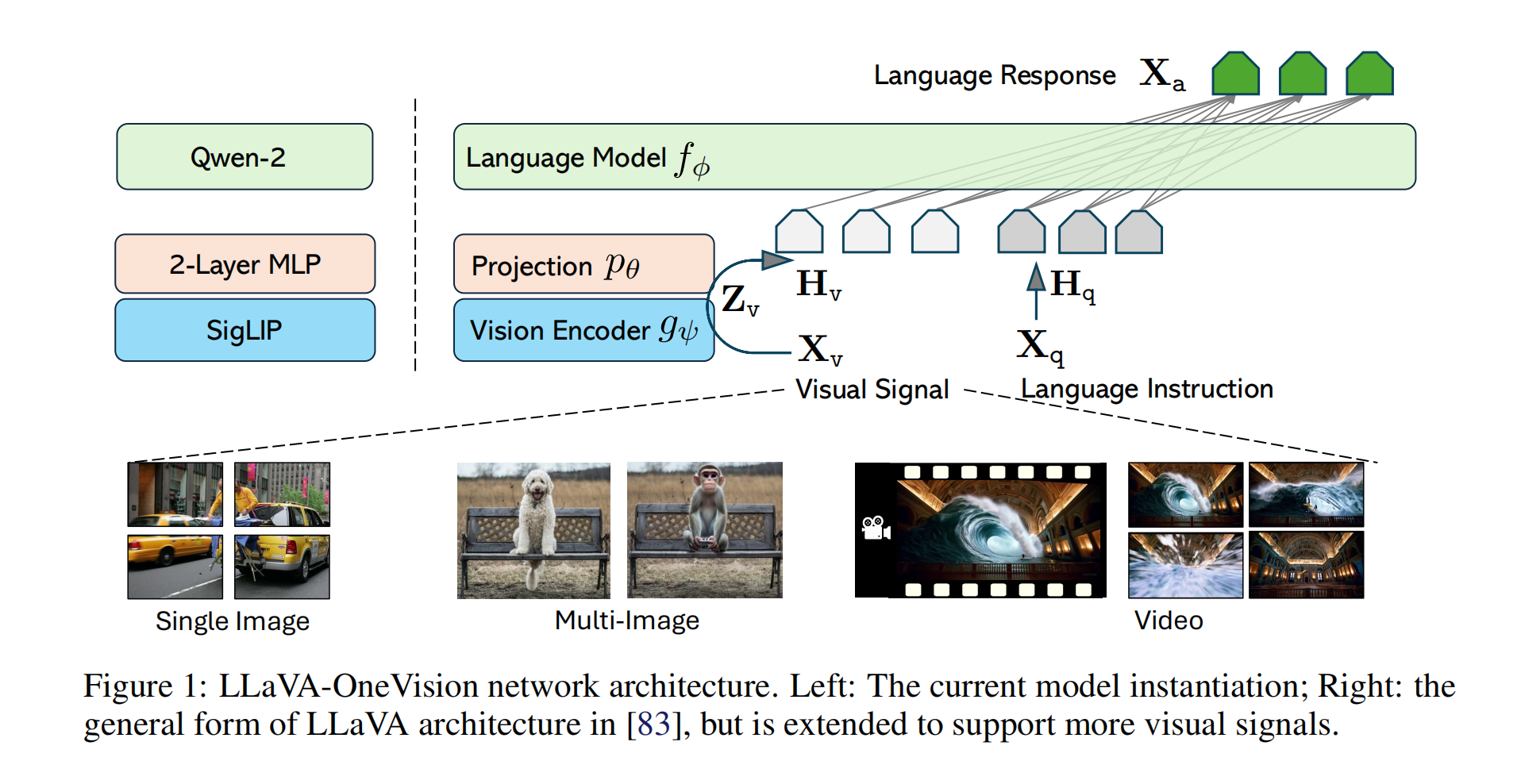
3.1 Network Architecture
-
整体设计原则
- 继承LLaVA系列的极简主义:
- 核心目标:
- 高效利用预训练能力:充分结合LLM与视觉模型的预训练知识。
- 支持数据与模型的强扩展性:确保架构在数据和模型规模增大时性能稳定提升。
- 核心目标:
- 继承LLaVA系列的极简主义:
-
核心组件
-
大型语言模型(LLM)
-
模型选择:
- 采用 Qwen-2 作为语言模型 f ϕ ( ⋅ ) f_\phi(\cdot) fϕ(⋅)(参数为 ϕ \phi ϕ)。
-
选择理由:
- 公开模型中的最优语言能力:在开源检查点中表现最强。
- 多尺寸支持:提供不同参数规模的版本,便于灵活扩展(更强的LLM直接提升多模态能力)。
-
视觉编码器(Vision Encoder)
-
模型选择:
- 使用 SigLIP 作为视觉编码器 g ψ ( ⋅ ) g_\psi(\cdot) gψ(⋅)(参数为 ψ \psi ψ),将输入图像 X v X_v Xv 编码为视觉特征 Z v = g ( X v ) Z_v = g(X_v) Zv=g(Xv)。
-
特征提取策略:
- 同时利用最后一层Transformer之前和之后的网格特征(grid features),以保留不同层级的视觉信息。
-
-
投影器(Projector)
- 结构设计:
- 采用 2层MLP p θ ( ⋅ ) p_\theta(\cdot) pθ(⋅)(参数为 θ \theta θ ),将视觉特征 Z v Z_v Zv 投影到LLM的词嵌入空间,生成视觉token序列 H v = p ( Z v ) H_v = p(Z_v) Hv=p(Zv)。
- 结构设计:
-
-
-
输入输出建模
-
概率计算形式化
-
序列生成公式:
-
对于长度为 L L L 的答案序列 X a X_a Xa,其条件概率为:
p ( X a ∣ X v , X q ) = ∏ i = 1 L p ( x i ∣ X v , X q , < i , X a , < i ) p(X_a | X_v, X_q) = \prod_{i=1}^L p(x_i | X_v, X_{q, <i}, X_{a, <i}) p(Xa∣Xv,Xq)=i=1∏Lp(xi∣Xv,Xq,<i,Xa,<i) -
其中:
- X q , < i X_{q, <i} Xq,<i 和 X a , < i X_{a, <i} Xa,<i 分别表示当前预测token x i x_i xi 之前的所有指令token和答案token。
- **显式引入 X v X_v Xv **:强调所有答案均需基于视觉信号(即视觉特征始终参与解码)。
-
-
-
视觉输入泛化性
- 多场景适配:
- 视觉编码器的输入 X v X_v Xv 形式具有通用性,具体取决于任务场景:
- 单图像:individual image crop。
- 多图像:individual image in a sequence。
- 视频:individual frame in a video sequence。
- 技术实现:通过AnyRes(见3.2节)统一处理不同分辨率和模态的输入。
- 视觉编码器的输入 X v X_v Xv 形式具有通用性,具体取决于任务场景:
- 多场景适配:
-
3.2 Visual Representations
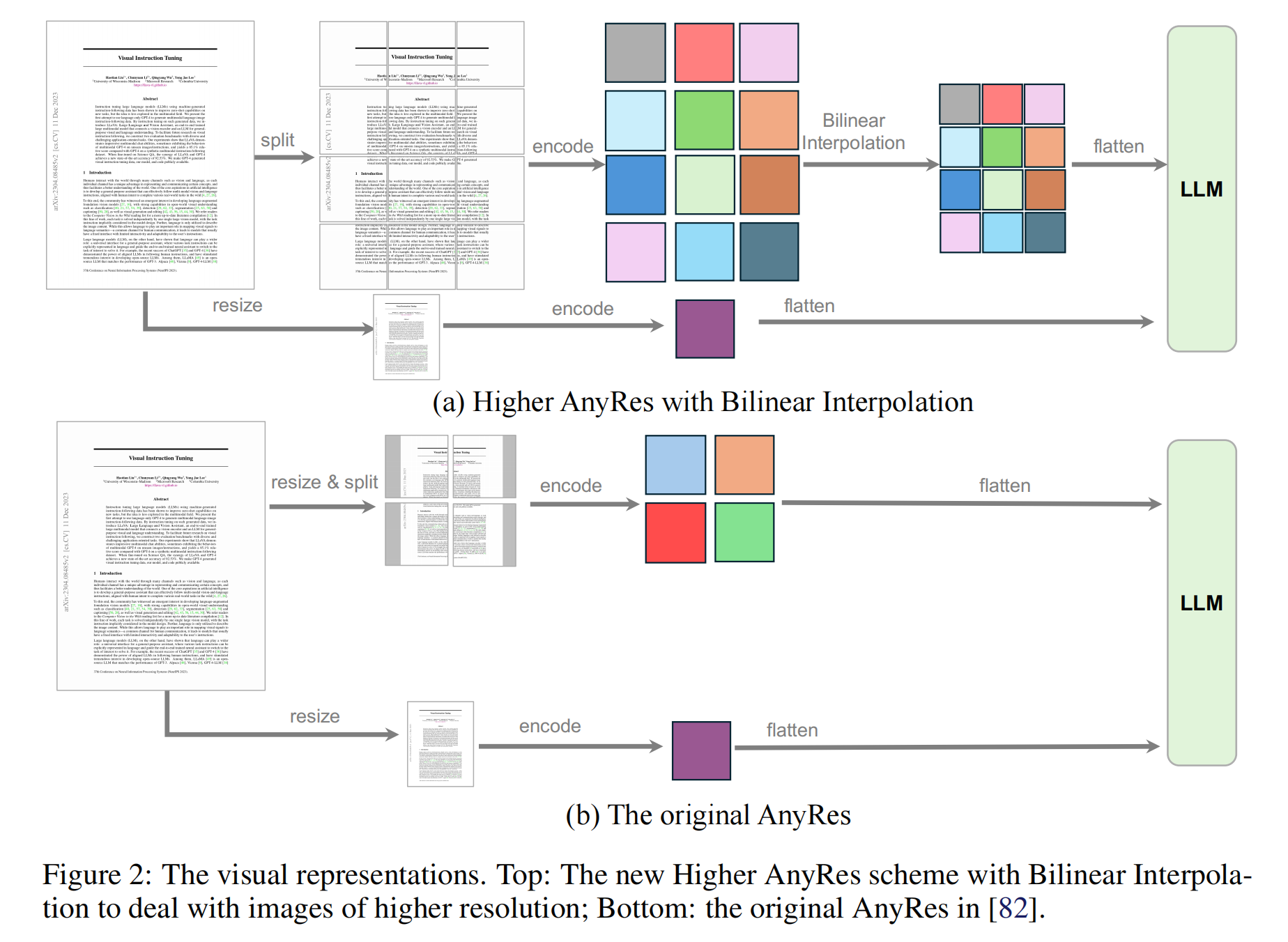
-
视觉表征的核心要素
-
关键因素:视觉信号的表征质量取决于两个变量:
- 原始像素空间的分辨率(resolution)
- 特征空间的token数量(#token)
- 二者共同构成视觉输入表征配置 (resolution, #token)。
-
性能规律:
- 二者规模扩大均可提升性能(尤其依赖视觉细节的任务),但分辨率缩放比token数量更有效。
- 平衡性能与成本:推荐采用带池化的AnyRes策略。
-
-
AnyRes技术实现
- 基础机制
-
图像分块处理:
- 对宽高为 (a, b) 的AnyRes配置,图像被划分为 a × b个裁剪块(crops),每块形状为 (a, b)。
- 每块裁剪保持视觉编码器适配的统一分辨率。(如上图F2)
-
Token计算:
- 每裁剪块生成 T个token,总视觉token数 L = ( a × b + 1 ) × T L = (a \times b + 1) \times T L=(a×b+1)×T(+1对应基础图像resize后的全局特征)。
-
动态Token压缩:
- 设定阈值 τ \tau τ,若 L > τ L > \tau L>τ 则按照如下公式压缩每块token数(必要时使用双线性插值):
T new = { τ a × b + 1 if L > τ T if L ≤ τ T_{\text{new}} = \begin{cases} \frac{\tau}{a \times b + 1} & \text{if } L > \tau \\ T & \text{if } L \leq \tau \end{cases} Tnew={a×b+1τTif L>τif L≤τ
- 设定阈值 τ \tau τ,若 L > τ L > \tau L>τ 则按照如下公式压缩每块token数(必要时使用双线性插值):
-
- 基础机制
-
空间配置优化
-
多配置适应:
- 定义一组空间配置 (a, b) 以支持不同分辨率和长宽比的图像,优先选择需最少裁剪数的配置。
-
Higher AnyRes框架:
-
作为灵活表征框架,可适配多图像和视频场景,通过调整配置平衡性能与成本(如下图F3)。

-
-
-
多场景表征策略
-
单图像场景
-
高分辨率保留:
- 采用最大空间配置 (a, b),避免原始图像resize导致信息损失。
-
长序列token分配:
- 每图像分配大量视觉token,生成长序列以充分表征细节。
-
设计动机:
- 图像的高质量训练样本远多于视频,通过模仿视频的长序列表征,促进图像到视频的能力迁移。
-
-
多图像场景
- 资源优化:
- 仅将基础分辨率图像输入视觉编码器获取特征图,避免高分辨率多裁剪,节省计算资源。
- 资源优化:
-
视频场景
-
帧处理:
- 每帧resize为基础分辨率,经视觉编码器生成特征图。
-
Token-帧数权衡:
- 使用双线性插值减少每帧token数,从而支持更多帧处理,实现性能与成本的更好平衡。
-
-
-
实验设计与扩展性
-
固定计算预算下的设计:
- 当前配置针对跨场景能力迁移优化,在有限算力下最大化多模态性能。
-
算力扩展潜力:
- 若计算资源增加,可提升训练/推理时的每图像(帧)token数以进一步突破性能边界。
-
4. Data
- MLLM训练中采用"质量优于数量"的准则。这一原则之所以关键,源于预训练LLM和视觉Transformer(ViT)中已存储的广博知识。
- 当新的高质量数据可用时,需持续让模型接触这些数据以进行知识补充。
- 本节将探讨高质量知识学习与视觉指令调优的数据来源及策略。
4.1 High-Quality Knowledge
-
核心问题与解决思路
-
低质量数据的局限性:
- 公开网络规模的图像-文本数据(web-scale public image-text data)通常质量低下,导致多模态预训练的数据扩展效率不足。
-
高质量知识学习的必要性:
- 在有限计算预算下,应优先利用预训练LLM和ViT已有的庞大知识库,通过精选数据对其进行精细化增强,而非盲目扩大数据规模。
-
-
高质量知识数据的三大来源
-
重新标注的详细描述数据
-
生成方法:
- 使用当前最强的开源LMM LLaVA-NeXT-34B对以下数据集图像重新生成描述:
- COCO118K
- BLIP558K
- CC3M
- 合并形成350万样本的新数据集。
- 使用当前最强的开源LMM LLaVA-NeXT-34B对以下数据集图像重新生成描述:
-
技术意义:
- 这是self-improvement AI的初步尝试:早期模型生成的数据用于训练后续版本。
-
-
文档/OCR数据
-
构成:
- UReader数据集的文本阅读子集(10万样本):通过PDF渲染获取易处理的文本数据。
- SynDOG EN/CN:合成文档-图像对数据。
- 合并形成110万样本的文档OCR数据集。
-
应用价值:
- 增强模型对文本密集型图像(如扫描文档、海报)的理解能力。
-
-
中文与多语言数据(Chinese and Language Data)
-
中文能力优化:
- 基于ShareGPT4V 原始图像,调用Azure API的GPT-4V生成9.2万条中文详细描述。
-
语言平衡性:
- 从Evo-Instruct 收集14.3万样本,防止模型因过度依赖描述数据而弱化基础语言理解能力。
-
-
-
合成数据的优势与趋势
-
数据构成比例:
- 99.8%的高质量知识数据为合成生成(synthetic data)。
-
合成数据的必然性:
- 成本与版权:真实世界大规模高质量数据收集成本高且受版权限制。
- 可扩展性:合成数据可快速生成且规模可控(如通过GPT-4V生成描述)。
-
行业趋势:
- 随着AI模型能力提升,从大规模合成数据中学习将成为主流范式。
-
4.2 Visual Instruction Tuning Data
-
视觉指令调优的定义与目标
-
概念:
- Visual Instruction Tuning指 MLLM 理解并执行结合视觉媒体(图像/视频)与语言指令的任务,通过整合视觉理解与自然语言处理生成响应。
-
技术目标:
- 使模型能处理开放式指令,而非局限于预定义任务。
-
-
数据收集与分类框架
-
数据来源
- 基础策略:
- 从多样化原始来源收集非平衡比例数据(unbalanced data ratio),结合Cauldron和Cambrian的新子集。
- 高质量维护:延续LLaVA-1.5 等研究结论,强调数据质量对LMM能力的决定性作用。
- 基础策略:
-
三级分类体系
-
视觉输入(Vision Input):
- 按模态分为三类:
- 单图像(Single-image)
- 多图像(Multi-image)
- 视频(Video)
- 按模态分为三类:
-
语言指令(Language Instruction):
-
五大任务类型:
类别 示例任务 技能目标 General QA 图像问答 基础视觉理解 General OCR 文字识别 文本-视觉对齐 Doc/Chart/Screen 文档解析 结构化数据理解 Math Reasoning 数学推理 多模态逻辑推理 Language 多语言描述 跨语言泛化
-
-
语言响应(Language Response):
-
自由形式(Free-form):由GPT-4V/Gemini等生成开放式答案
-
固定形式(Fixed-form):源自学术数据集(如VQAv2、GQA),需人工校正格式
-
-
-
-
数据处理关键步骤
- 对固定形式数据(如多选题),采用LLaVA-1.5提示策略,确保答案格式一致性,避免多源数据冲突。
-
两组训练数据
-
Single-Image Data
-
规模:320万样本
-
平衡策略:
- 从原始数据中筛选各任务类型的代表性样本,避免数据倾斜。
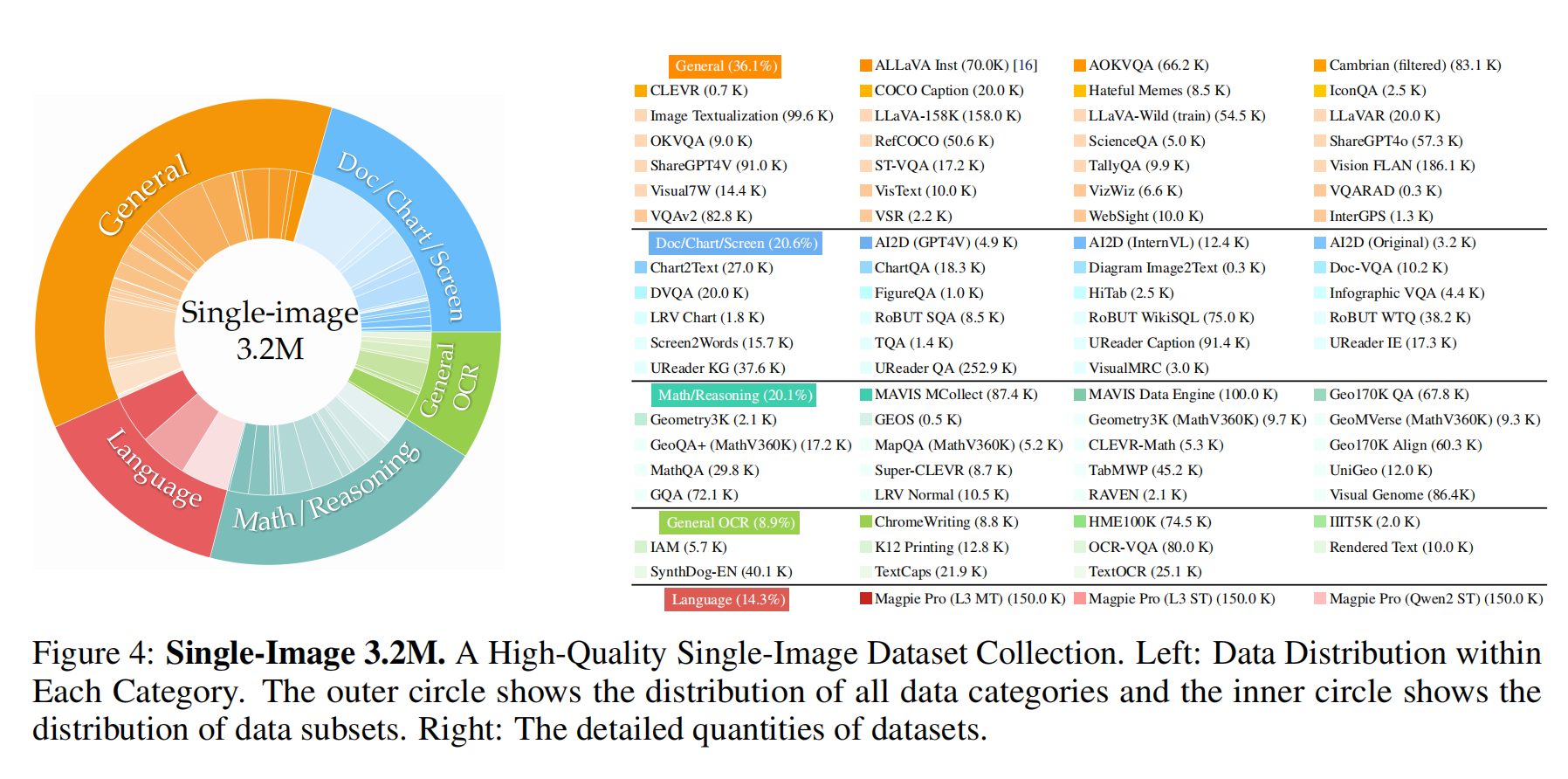
-
-
多模态混合数据(OneVision Data)
- 构成:160万样本
- 多图像:56万
- 视频:35万
- 单图像:80万
- 训练逻辑:
- 不引入新单图像数据,而是复用前期已优化数据,专注于多模态对齐。

- 构成:160万样本
-
5. Training Strategies
-
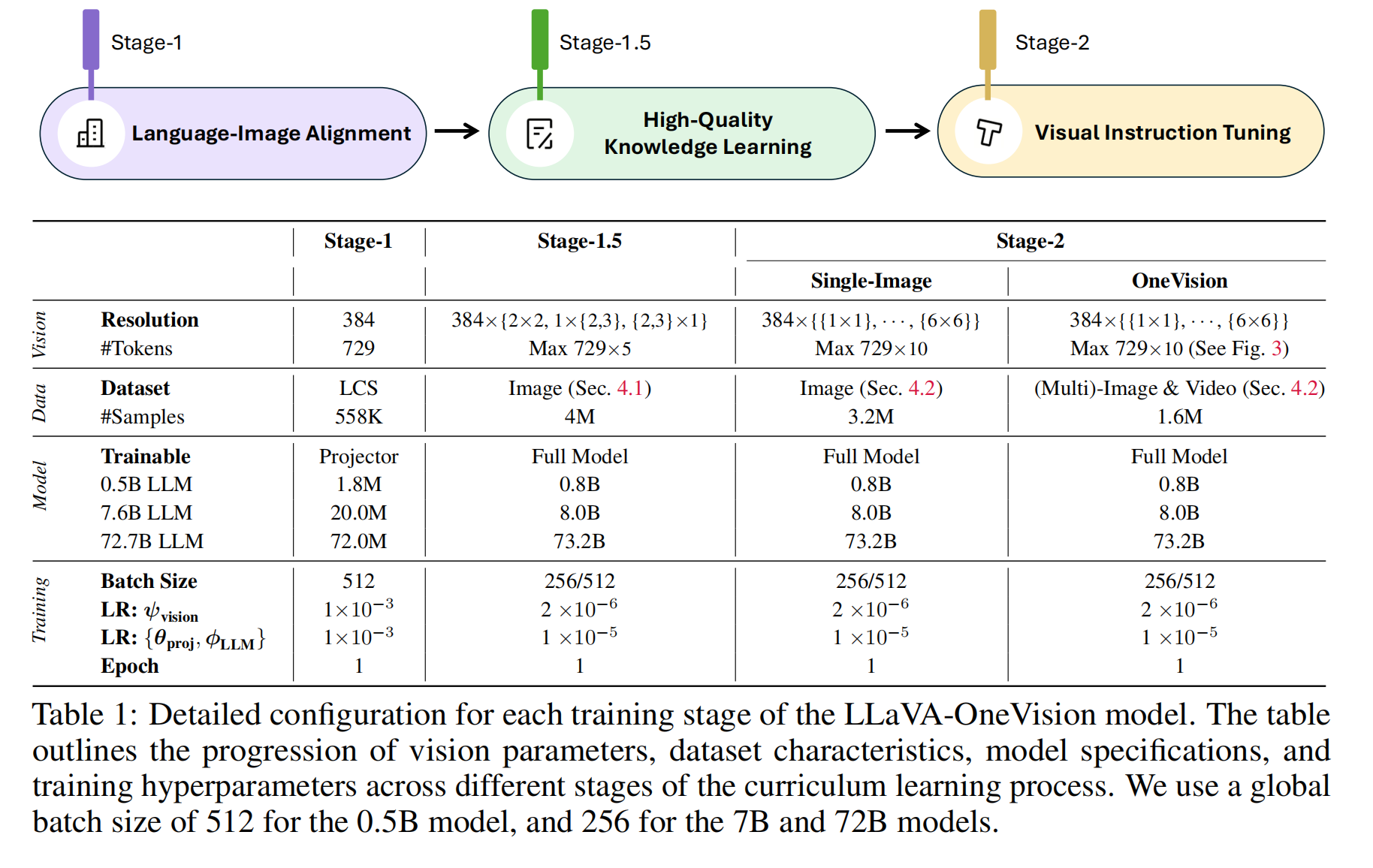
三阶段课程学习框架
-
设计理念
-
功能解耦:将多模态能力分解为三个关键功能模块,分阶段训练以支持消融研究。
-
Curriculum Learning:
- 采用由易到难的训练策略,在固定计算预算下分阶段生成可复用的模型检查点。
-
-
-
阶段详解
-
Stage-1: 语言-图像对齐
-
技术实现:
- 冻结视觉编码器(SigLIP)和LLM(Qwen-2),仅训练2层MLP投影器。
- 使用基础分辨率图像(729 tokens),避免高计算开销。
-
作用: 建立视觉特征与语言空间的基础映射关系,为后续阶段提供稳定的跨模态接口。
-
-
Stage-1.5: 高质量知识学习
-
数据策略:
- 采用4.1节所述的合成高质量数据(如Re-Captioned数据)。
-
训练配置:
-
解锁全模型参数,但视觉编码器学习率设为LLM的1/5(防止视觉特征被过度破坏)。
-
引入AnyRes技术,token数扩展至5倍(平衡计算成本与知识注入)。
-
-
Stage-2: 视觉指令调优
- 两阶段训练:
- 单图像训练(Single-Image Training):
- 使用320万单图像指令数据,覆盖问答/OCR/推理等任务。
- 目标:建立单图像多任务泛化能力。
- 多模态混合训练(OneVision Training):
- 混合数据:56万多图像 + 35万视频 + 80万单图像(从前期数据重采样)。
- 目标:实现跨场景知识迁移(如图像→视频的零样本能力)。
- 单图像训练(Single-Image Training):
- 技术优化:
- token数扩展至10倍(AnyRes最大化),支持高分辨率输入。
- 保持视觉编码器低学习率(仍为LLM的1/5)。
- 两阶段训练:
-
-
关键训练配置
-
渐进式序列长度扩展
-
动态调整策略:
阶段 最大分辨率 Token数 设计意图 Stage-1 基础 729 低成本初始化对齐 Stage-1.5 中等 ~3,645 平衡知识学习与计算开销 Stage-2 高 ~7,290 支持复杂多模态任务
-
-
理论依据: 逐步增加token数比一次性高分辨率训练更稳定。
-
-
参数更新策略
- 差异化学习:
- 投影器:Stage-1全程训练,后续阶段微调。
- 视觉编码器:Stage-1冻结,Stage-1.5/2以**低学习率(LLM的1/5)**更新,保护预训练特征。
- LLM:Stage-1.5/2全参数微调,激发语言侧多模态适配能力。
- 差异化学习:
-
与现有方法的对比
-
vs 传统端到端训练:
- 传统方法(如Flamingo)联合优化所有模块,易导致模态对齐不稳定。
- LLaVA分阶段策略解耦对齐-知识-泛化,更适配有限算力场景。
-
vs 其他开源LMM:
- VILA 仅聚焦单阶段指令调优,缺乏系统性课程设计。
-
6. Experimental Results
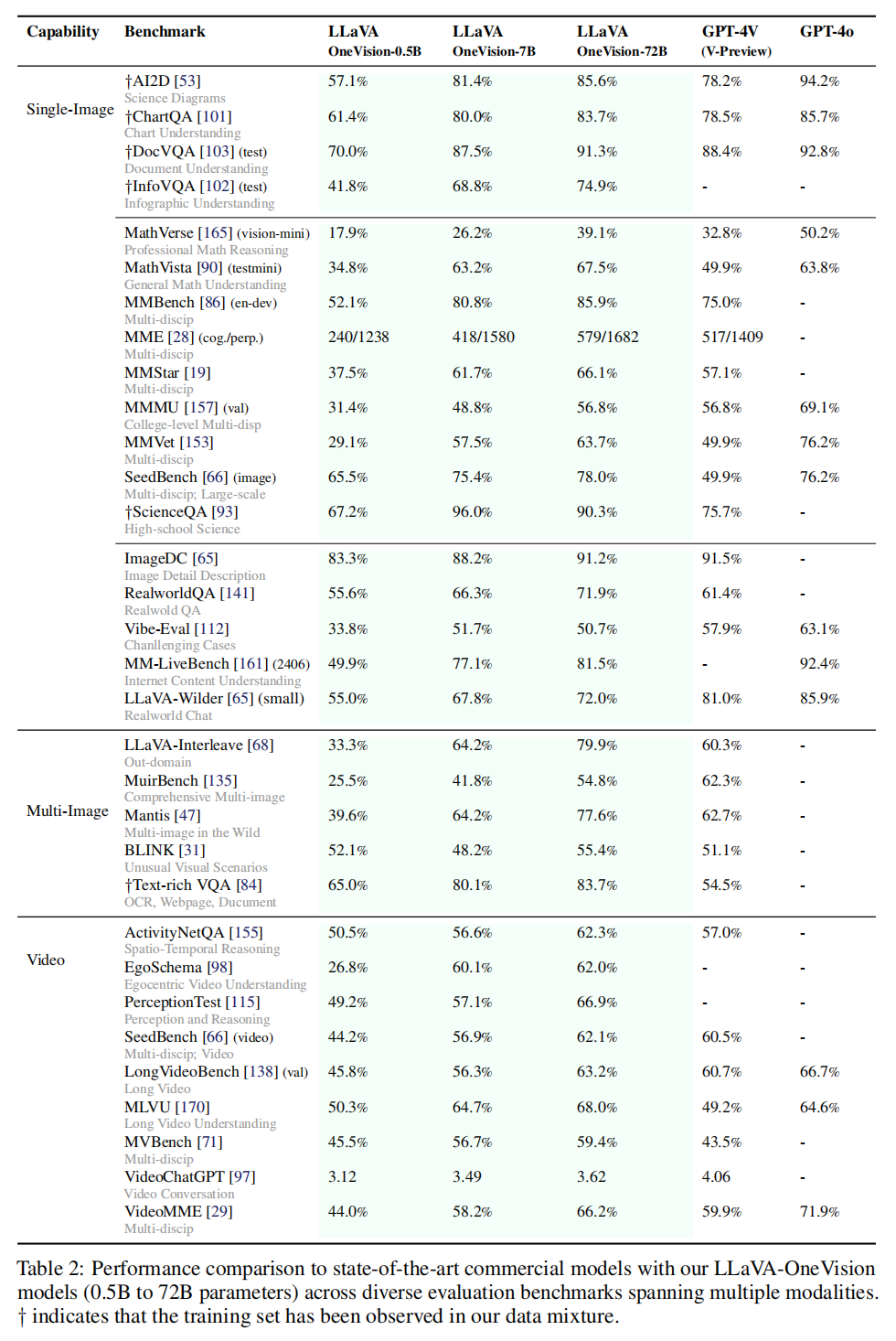
7. Emerging Capabilities with Task Transfer
-
图表联合理解S1
- 模型能够同时理解图表(chart)与示意图(diagram)的组合,尽管训练数据中仅包含单图像图表或示意图任务。
-
GUI操作指导S2
- 通过识别iPhone截图(单图像),生成操作指令,结合OCR与多图像关系推理能力。
-
标记集推理S3
- 首次在开源LMM中实现Set-of-Marks(SoM)推理(如根据图像中的箭头/圆圈标记回答问题),该能力未显式包含于训练数据。
-
图像到视频编辑指令S4
- 根据静态图像生成视频创作提示(如角色动作、场景转换),结合单图像编辑与视频描述任务的知识。
-
视频差异分析S5
- 对比同起点不同结局的两段视频,或同背景不同前景物体的视频,输出细节差异描述。
-
多视角自动驾驶视频理解S6
- 分析四摄像头同步拍摄的自动驾驶视频,描述各视角内容并规划车辆动作。
-
复合子视频理解S7
- 理解垂直分屏视频(如背景一致、前景人物变化的双场景视频),分析布局与叙事(如表13)。
-
视频中的视觉提示理解S8
- 识别视频中半透明圆圈标记的区域,该能力源自单图像视觉提示训练,未使用视频标记数据。
-
视频理解中的图像参照S9
- 回答视频问题时参照外部图像查询,该能力未在LLaVA-NeXT/Interleave中出现。
相关文章:
【论文阅读】LLaVA-OneVision: Easy Visual Task Transfer
LLaVA-OneVision: Easy Visual Task Transfer 原文摘要 研究背景与目标 开发动机: 基于LLaVA-NeXT博客系列对数据、模型和视觉表征的探索,团队整合经验开发了开源大型多模态模型 LLaVA-OneVision。 核心目标: 突破现有开源LMM的局限…...
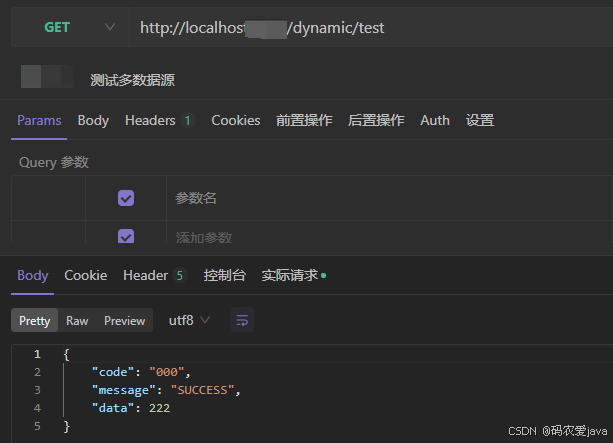
Spring Boot 项目多数据源配置【dynamic datasource】
前言: 随着互联网的发展,数据库的读写分离、数据迁移、多系统数据访问等多数据源的需求越来越多,我们在日常项目开发中,也不可避免的为了解决这个问题,本篇来分享一下在 Spring Boot 项目中使用多数据源访问不通的数据…...
JAVA查漏补缺(2)
AJAX 什么是Ajax Ajax(Asynchronous Javascript And XML),即是异步的JavaScript和XML,Ajax其实就是浏览器与服务器之间的一种异步通信方式 异步的JavaScript 它可以异步地向服务器发送请求,在等待响应的过程中&…...
【Web前端】JavaScript入门与基础(二)
Javascript对象 什么是对象?对象(object)是 JavaScript 语言的核心概念,也是最重要的数据类型。简单说,对象就是一组“键值对”(key-value)的集合,是一种无序的复合数据集合。 var…...

取消 Conda 默认进入 Base 环境
在安装 Conda 后,每次打开终端时默认会进入 base 环境。可以通过以下方法取消这一默认设置。 方法一:使用命令行修改配置 在终端中输入以下命令,将 auto_activate_base 参数设置为 false: conda config --set auto_activate_ba…...
Electron+vite+vue3 从0到1搭建项目,开发Win、Mac客户端
随着前端技术的发展,出现了所谓的大前端。 大前端则是指基于前端技术延伸出来的各种终端平台及应用场景,包括APP、桌面端、手表终端、服务端等。 本篇文章主要是和大家一起学习一下使用Electron 如何打包出 Windows 和 Mac 所使用的客户端APPÿ…...

《深度揭秘:解锁智能体大模型自我知识盲区探测》
当面对超出其训练数据边界和固有知识范畴的问题时,智能体大模型往往会陷入困境,却浑然不知,这便是知识盲区带来的隐患。如何构建能够自动发现自身知识盲区的智能体大模型,成为当下人工智能领域亟待攻克的前沿难题,它关…...

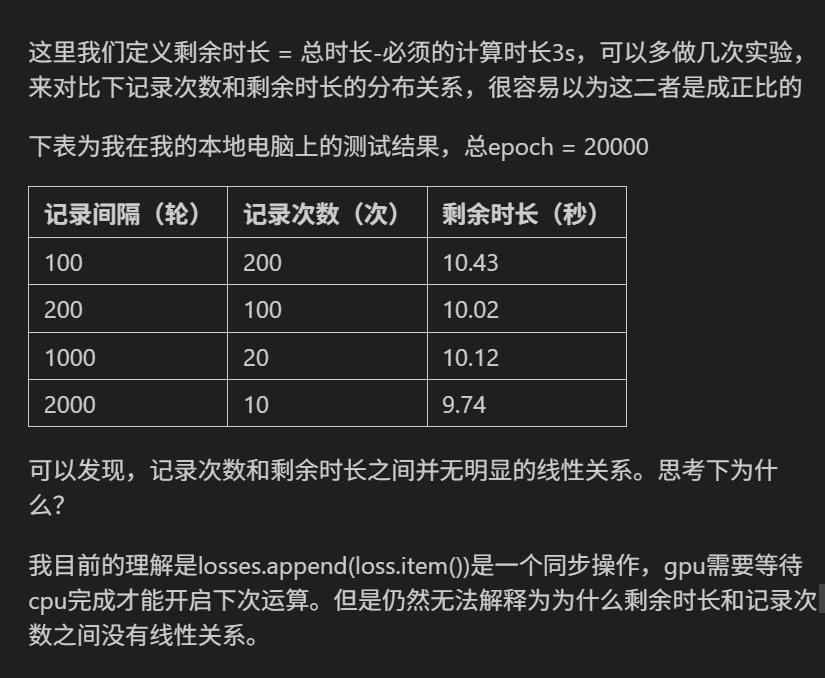
打卡Day33
简单的神经网络 数据的准备 # 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import numpy as np# 加载鸢尾花数据集 iris load_iris() X iris.data # …...

计算机组成原理-基本运算部件定点数的运算
2.2基本运算部件 整理自up主beokayy_ 1.加法器 一位全加器 全加器是最基本的加法单元: 三个输入端:加数Ai,加数Bi,低位传进来的进位C1-1两个输出端:本位和S,向高位的进位C 全加器的逻辑表达式: SiAi⊕Bi⊕Ci-1CiAiBi(Ai⊕Bi)C…...
python打卡day34@浙大疏锦行
知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作self.fc1(x) ①CPU性能查…...

SOC-ESP32S3部分:8-GPIO输出LED控制
飞书文档https://x509p6c8to.feishu.cn/wiki/OSQWwh95niobqUkKyDQcVgsbnFg 这节课,我们将会以ESP32S3外设GPIO的使用为例,带大家学习如何从零开始学会ESP32外设的使用。 例如,这节课我们的需求是,需要通过GPIO控制指示灯的亮灭&…...
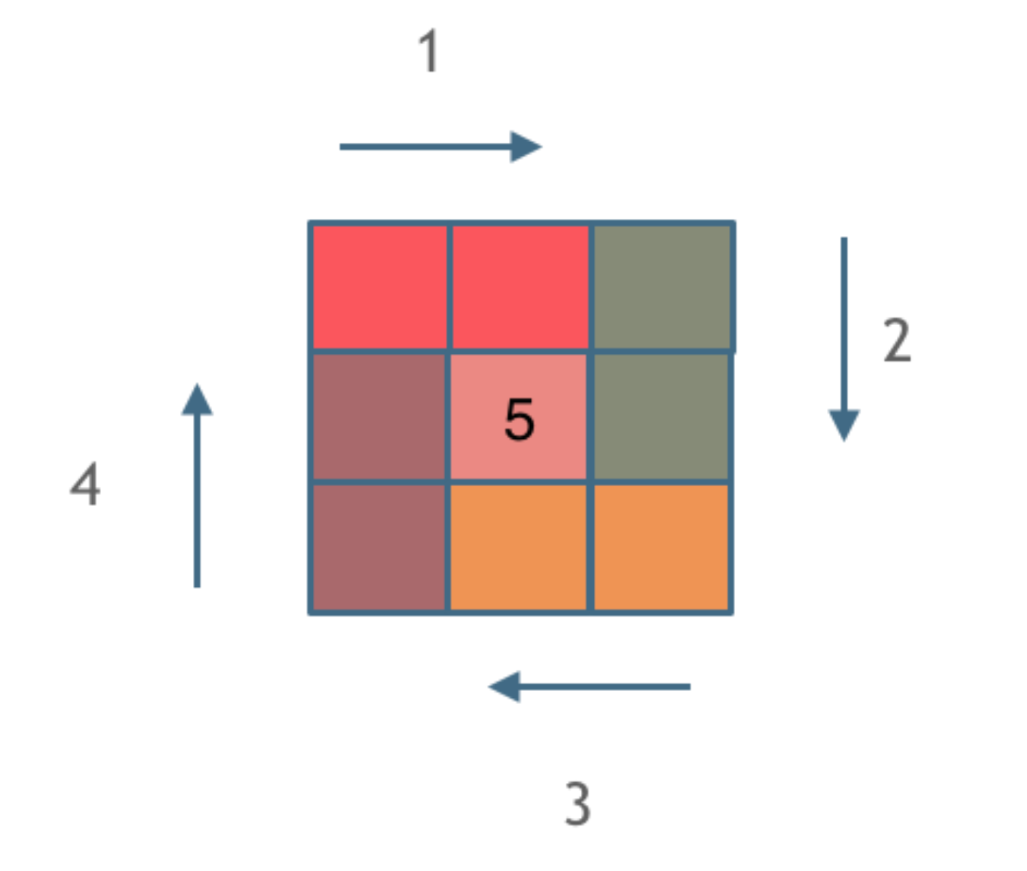
05算法学习_59. 螺旋矩阵 II
05算法学习_59. 螺旋矩阵 II 05算法学习_59. 螺旋矩阵 II题目描述:个人代码:学习思路:第一种写法:题解关键点: 个人学习时疑惑点解答: 05算法学习_59. 螺旋矩阵 II 力扣题目链接: 59. 螺旋矩阵 II 题目描…...

绘制音频信号的各种频谱图,包括Mel频谱图、STFT频谱图等。它不仅能够绘制频谱图librosa.display.specshow
librosa.display.specshow 是一个非常方便的函数,用于绘制音频信号的各种频谱图,包括Mel频谱图、STFT频谱图等。它不仅能够绘制频谱图,还能自动设置轴标签和刻度,使得生成的图像更加直观和易于理解。 ### 函数签名 python libros…...

Linux `>`/`>>` 重定向操作符深度解析与高阶应用指南
Linux `>`/`>>` 重定向操作符深度解析与高阶应用指南 一、核心功能解析1. 基础重定向2. 标准流描述符二、高阶重定向技巧1. 多流重定向2. 文件描述符操作3. 特殊设备操作三、企业级应用场景1. 日志管理系统2. 数据管道处理3. 自动化运维四、安全与权限管理1. 防误操作…...

【自定义类型-联合和枚举】--联合体类型,联合体大小的计算,枚举类型,枚举类型的使用
目录 一.联合体类型 1.1--联合体类型的声明 1.2--联合体的特点 1.3--相同成员的结构体和联合体对比 1.4--联合体大小的计算 1.5--联合体练习 二.枚举类型 2.1--枚举类型的声明 2.2--枚举类型的优点 2.3--枚举类型的使用 🔥个人主页:草莓熊Lotso…...
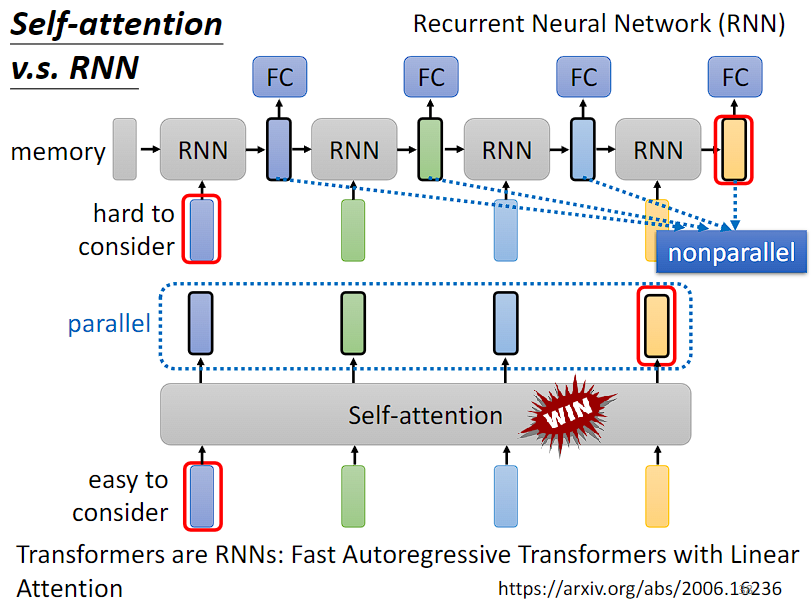
李宏毅《深度学习》:Self-attention 自注意力机制
一,问题分析: 什么情况下需要使用self-attention架构,或者说什么问题是CNN等经典网络架构解决不了的问题,我们需要开发新的网络架构? 要解决什么问题《——》对应开发self-attention架构的目的? 1&#…...

C++初阶-list的使用1
目录 1.std::list简介 2.成员函数 2.1构造函数的使用 2.2list::operator的使用 3.迭代器 4.容量 4.1list::empty函数的使用 4.2list::size函数的使用 4.3list::max_size函数的使用 5.元素访问 6.修饰符 6.1list::assign函数的使用 6.2push_back和pop_back和push_fr…...

Linux中的tty与login之间的关系
agetty 进程和 login 进程之间的关系: 一、简要概括 agetty 是登录前的终端初始化程序。 login 是处理用户登录认证的程序。 关系:agetty 启动后等待用户输入用户名,然后调用 login 进程进行用户认证。 二、详细过程 1. agetty 的作用 a…...
Python web 开发 Flask HTTP 服务
Flask 是一个轻量级的 Web 应用框架,它基于 Python 编写,特别适合构建简单的 Web 应用和 RESTful API。Flask 的设计理念是提供尽可能少的约定和配置,从而让开发者能够灵活地构建自己的 Web 应用。 https://andi.cn/page/622189.html...

分享|16个含源码和数据集的计算机视觉实战项目
本文将分享16个含源码和数据集的计算机视觉实战项目。具体包括: 1. 人数统计工具 2. 颜色检测 3. 视频中的对象跟踪 4. 行人检测 5. 手势识别 6. 人类情感识别 7. 车道线检测 8. 名片扫描仪 9. 车牌识别 10. 手写数字识别 11.鸢尾花分类 12. 家庭照片人脸检测 13. 乐…...
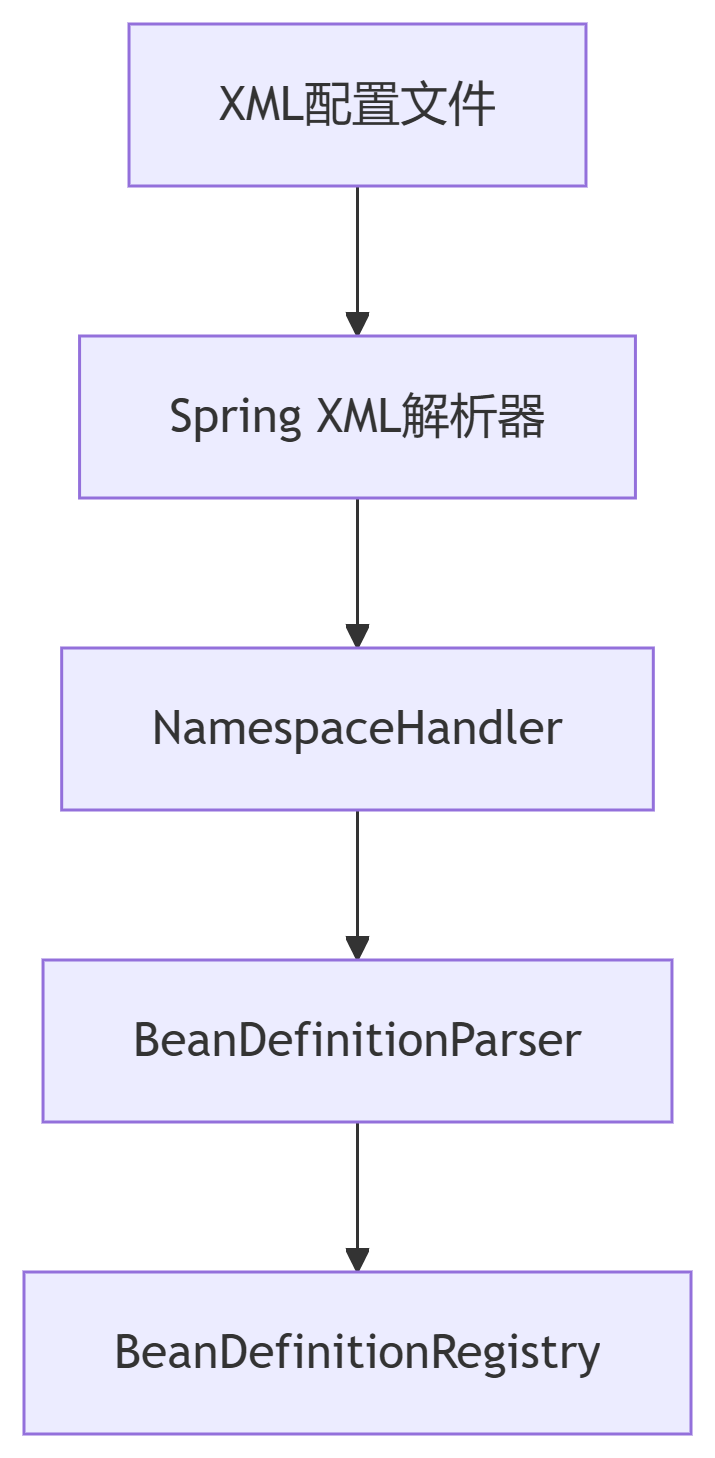
二十三、面向对象底层逻辑-BeanDefinitionParser接口设计哲学
一、引言:Spring XML配置的可扩展性基石 在Spring框架的演进历程中,XML配置曾长期作为定义Bean的核心方式。虽然现代Spring应用更倾向于使用注解和Java Config,但在集成第三方组件、兼容遗留系统或实现复杂配置逻辑的场景下,XML配…...
[Vue]路由基础使用和路径传参
实际项目中不可能就一个页面,会有很多个页面。在Vue里面,页面与页面之间的跳转和传参会使用我们的路由: vue-router 基础使用 要使用我们需要先给我们的项目添加依赖:vue-router。使用命令下载: npm install vue-router 使用路由会涉及到下面几个对象:…...
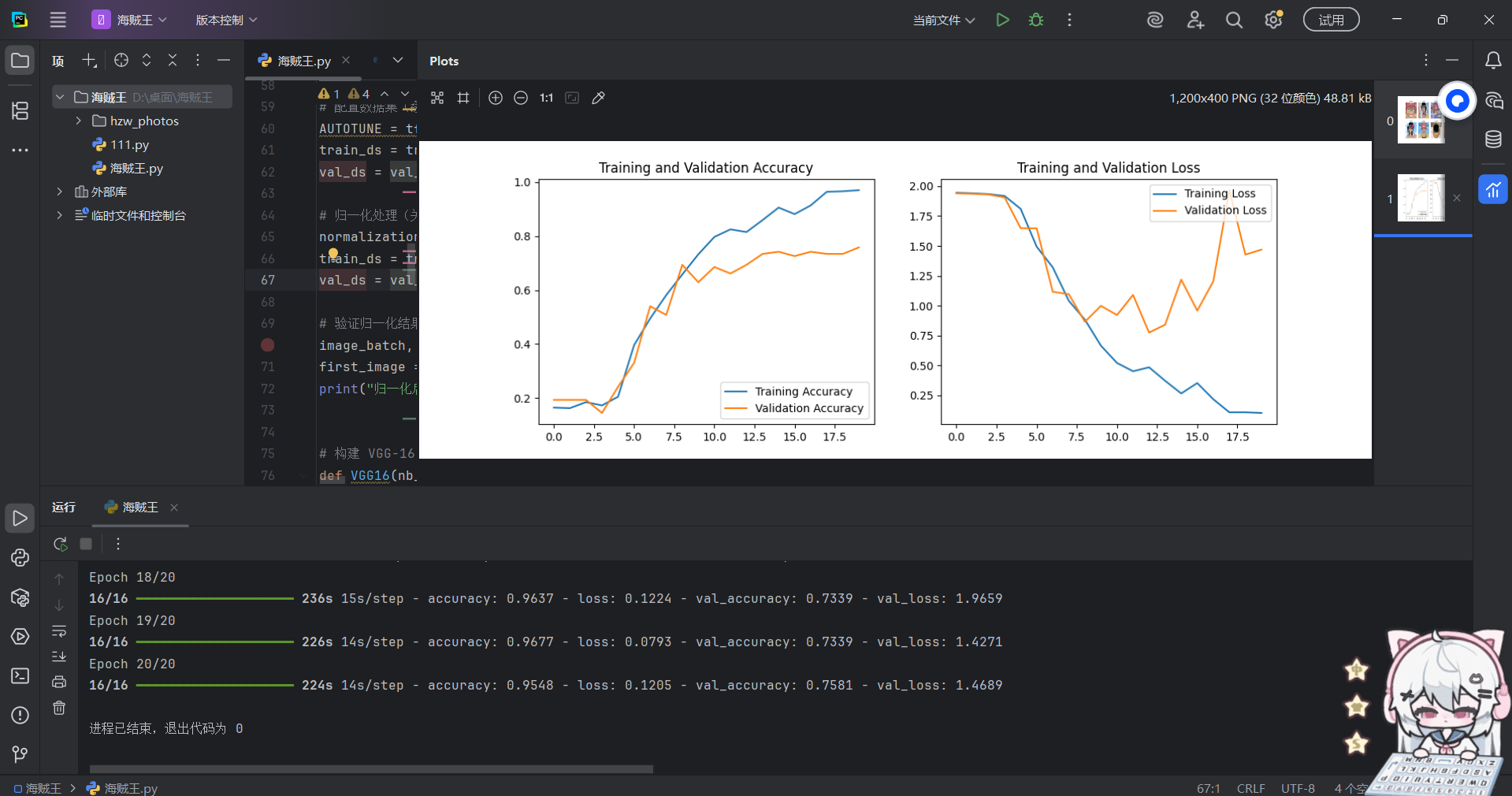
使用VGG-16模型来对海贼王中的角色进行图像分类
动漫角色识别是计算机视觉的典型应用场景,可用于周边商品分类、动画制作辅助等。 这个案例是一个经典的深度学习应用,用于图像分类任务,它使用了一个自定义的VGG-16模型来对《海贼王》中的七个角色进行分类,演示如何将经典CNN模型…...

OSI 网络七层模型中的物理层、数据链路层、网络层
一、OSI 七层模型 物理层、数据链路层、网络层、传输层、会话层、表示层、应用层 1. 物理层(Physical Layer) 功能:传输原始的比特流(0和1),通过物理介质(如电缆、光纤、无线电波)…...

WooCommerce缓存教程 – 如何防止缓存破坏你的WooCommerce网站?
我们在以前的文章中探讨过如何加快你的WordPress网站的速度,并研究过各种形式的缓存。 然而,像那些使用WooCommerce的动态电子商务网站,在让缓存正常工作方面往往会面临重大挑战。 在本指南中,我们将告诉你如何为WooCommerce设置…...
)
AtCoder Beginner Contest 406(ABCD)
前言 我仿佛在梦游…… 一、A - Not Acceptable #include <bits/stdc.h> using namespace std;typedef long long ll; typedef pair<int,int> pii;void solve() {int dueH,dueM,upH,upM;cin>>dueH>>dueM>>upH>>upM;if(upH>dueH){cou…...
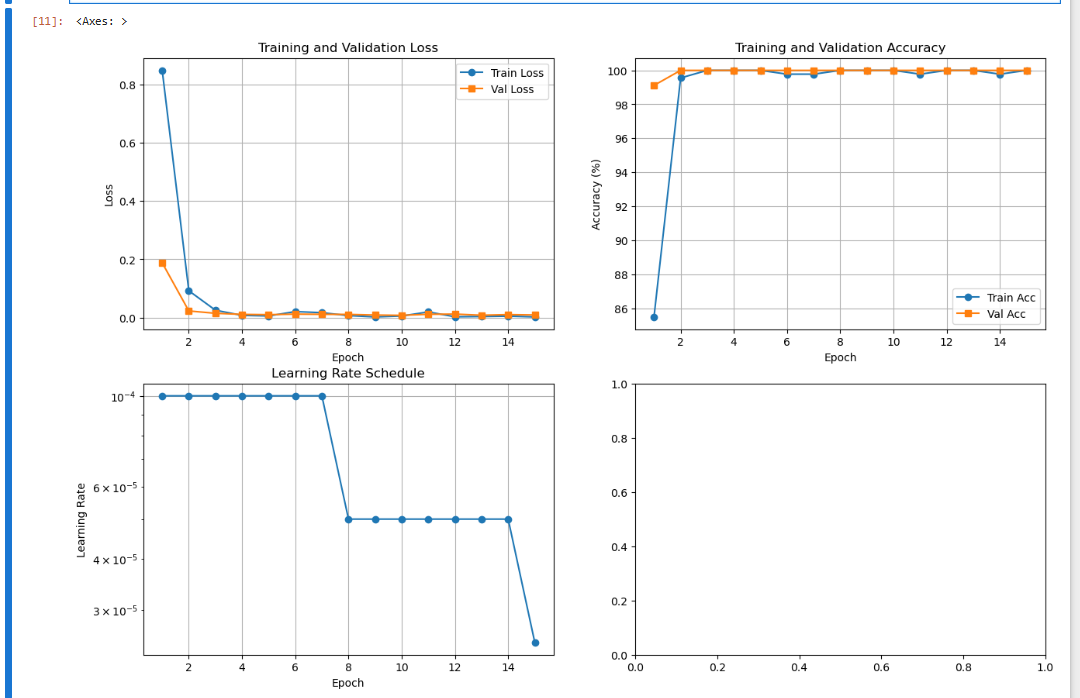
第J2周:ResNet50V2 算法实战与解析
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 学习目标 ✅ 根据TensorFlow代码,编写出相应的Python代码 ✅ 了解ResNetV2和ResNet模型的区别 一、环境配置 二、数据预处理 三、创建、划分数据…...

Live Search API :给大模型装了一个“实时搜索引擎”的插件
6月5号前免费使用。 Live Search 是一项xAI API功能,允许 LLM 在生成响应时查询和考虑实时数据。通过此功能,您可以直接从 API 获得包含实时数据的聊天响应,而无需自己协调网络搜索和大型语言模型(LLM)工具调用。 可以…...
)
每天分钟级别时间维度在数据仓库的作用与实现——以Doris和Hive为例(开箱即用)
在现代数据仓库建设中,时间维度表是不可或缺的基础维表之一。尤其是在金融、电力、物联网、互联网等行业,分钟级别的时间维度表对于高频数据的统计、分析、报表、数据挖掘等场景具有极其重要的作用。本文将以 Doris 为例,详细讲解每天分钟级别时间维度表在数据仓库中的作用、…...
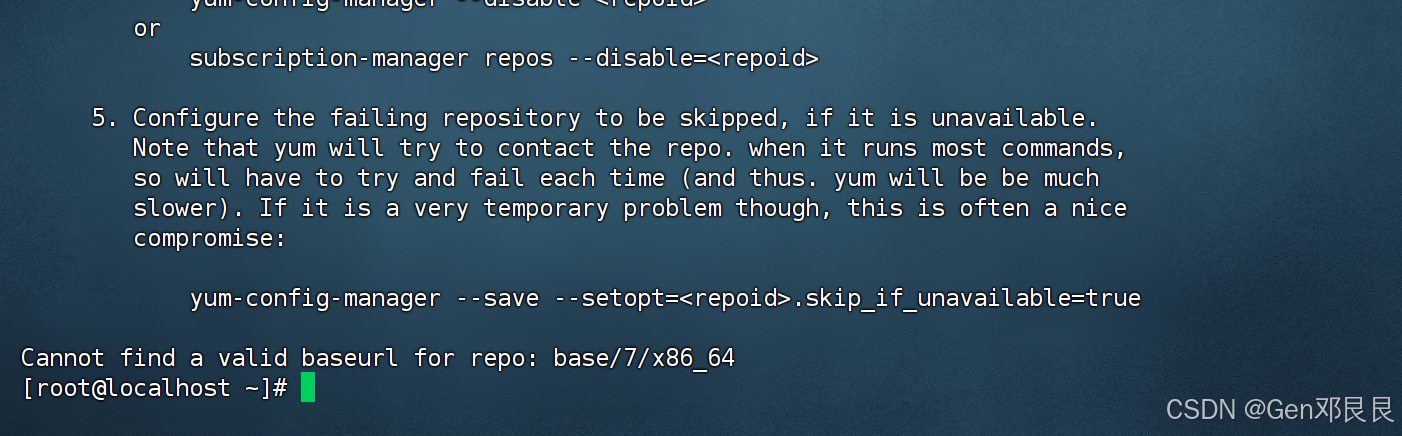
虚拟机Centos7:Cannot find a valid baseurl for repo: base/7/x86_64问题解决
问题 解决:更新yum仓库源 # 备份现有yum配置文件 sudo cp -r /etc/yum.repos.d /etc/yum.repos.d.backup# 编辑CentOS-Base.repo文件 vi /etc/yum.repos.d/CentOS-Base.repo[base] nameCentOS-$releasever - Base baseurlhttp://mirrors.aliyun.com/centos/$relea…...