【深度学习】1. 感知器,MLP, 梯度下降,激活函数,反向传播,链式法则
一、感知机
对于分类问题,我们设定一个映射,将x通过函数f(x)映射到y
1. 感知机的基本结构
感知机(Perceptron)是最早期的神经网络模型,由 Rosenblatt 在 1958 年提出,是现代神经网络和深度学习模型的雏形。
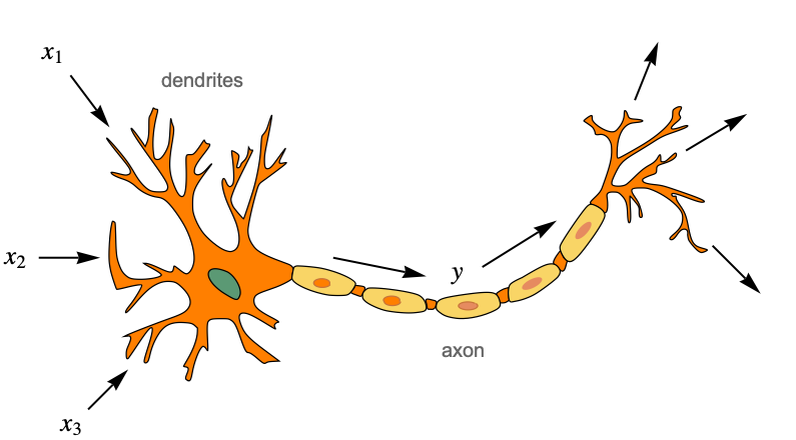
其模拟的是人脑内的神经元。神经元会接受到一些信号(我们给到模型的输入),之后神经元会决定是否激活这个信号,如果需要激活,就会产生一些神经冲动(Nerve Impulses),将信息传播到下一个链接。从而完成了信息端到端的传递。
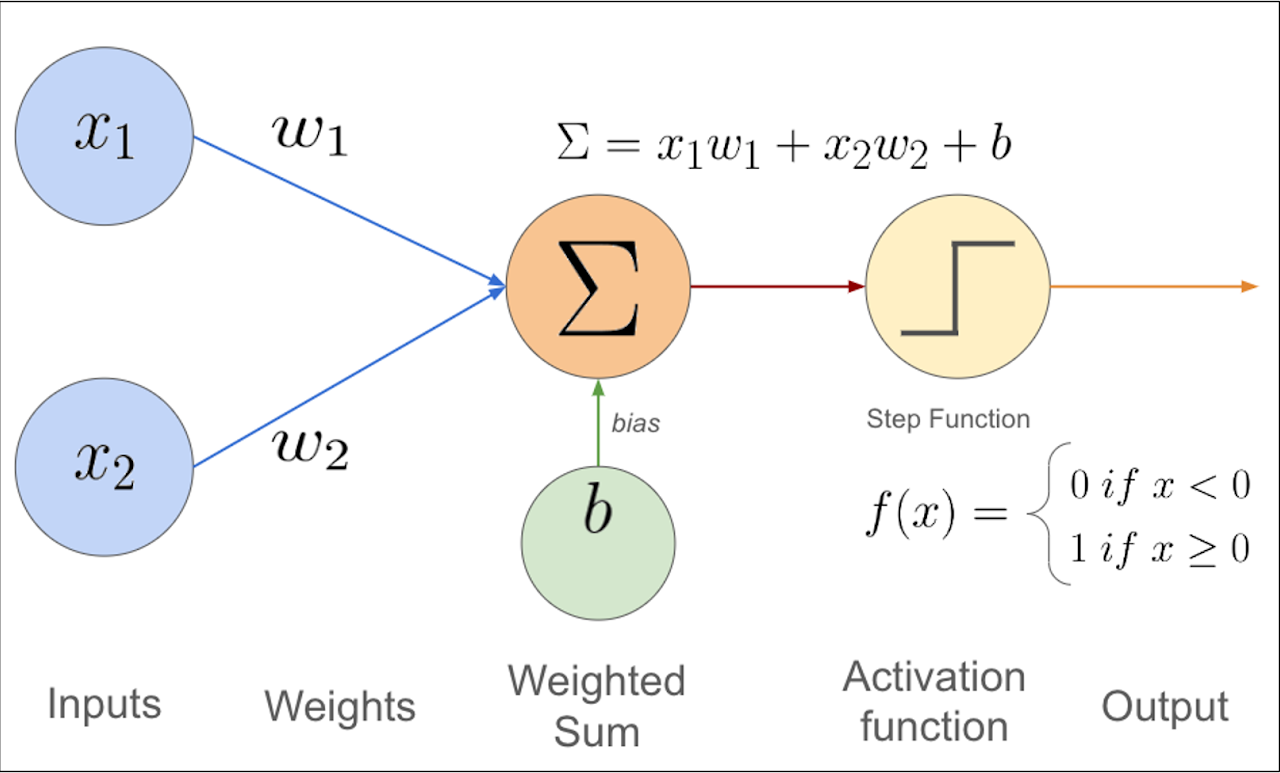
在深度学习中,其定义如下
基本结构如下:
- 输入向量 x = [ x 1 , x 2 , . . . , x d ] \mathbf{x} = [x_1, x_2, ..., x_d] x=[x1,x2,...,xd]
- 权重向量 w = [ w 1 , w 2 , . . . , w d ] \mathbf{w} = [w_1, w_2, ..., w_d] w=[w1,w2,...,wd]
- 偏置项 b b b
- 输出函数: o = sign ( w ⊤ x + b ) o = \text{sign}(\mathbf{w}^\top \mathbf{x} + b) o=sign(w⊤x+b)
sign ( s ) = { + 1 , s ≥ 0 − 1 , s < 0 \text{sign}(s) = \begin{cases} +1, & s \geq 0 \\\\ -1, & s < 0 \end{cases} sign(s)=⎩ ⎨ ⎧+1,−1,s≥0s<0
这是一个线性分类器,决策边界是一个超平面。
2. 感知机的数学定义与决策规则
感知机的核心是对输入的加权求和,并加上一个偏置项 b b b,用于输出一个实值:
y ^ = ∑ i = 1 d w i x i + b = w ⊤ x + b \hat{y} = \sum_{i=1}^{d} w_i x_i + b = \mathbf{w}^\top \mathbf{x} + b y^=i=1∑dwixi+b=w⊤x+b
其中:
- y ^ \hat{y} y^:神经元对期望输出的估计(输出值)
- w \mathbf{w} w:权重向量(weight vector)
- x \mathbf{x} x:输入向量(input vector)
- b b b:偏置项(bias)
决策规则(Decision Rule)
感知机的最终分类结果是通过符号函数决定的:
o = sign ( y ^ ) = { + 1 , y ^ ≥ 0 − 1 , y ^ < 0 o = \text{sign}(\hat{y}) = \begin{cases} +1, & \hat{y} \geq 0 \\\\ -1, & \hat{y} < 0 \end{cases} o=sign(y^)=⎩ ⎨ ⎧+1,−1,y^≥0y^<0
这个函数将连续输出 y ^ \hat{y} y^ 映射到离散类别 { + 1 , − 1 } \{+1, -1\} {+1,−1}。
分类条件判断
感知机判断一个样本是否被正确分类,依据如下公式:
- 如果样本分类正确,则:
y ( w ⊤ x + b ) ≥ 0 y(\mathbf{w}^\top \mathbf{x} + b) \geq 0 y(w⊤x+b)≥0
- 否则(分类错误):
y ( w ⊤ x + b ) < 0 y(\mathbf{w}^\top \mathbf{x} + b) < 0 y(w⊤x+b)<0
这里的 y y y 是样本的真实标签(取值为 +1 或 -1)。这个不等式体现了分类面的位置是否与样本标签方向一致。
对于一个训练样本 ( x i , y i ) (\mathbf{x}_i, y_i) (xi,yi):
- 如果分类正确: y i ( w ⊤ x i + b ) ≥ 0 y_i(\mathbf{w}^\top \mathbf{x}_i + b) \geq 0 yi(w⊤xi+b)≥0
- 否则分类错误。
直观理解:
y 表示 ground truth 真实标签
( w ⊤ x i + b ) (\mathbf{w}^\top \mathbf{x}_i + b) (w⊤xi+b) 表示 y ^ \hat{y} y^ 即模型预测标签
而sign函数,把预测值分为了两个:+1,-1
因此预测正确的情况有两种:(+1, +1) 或者 (-1, -1) 这两种情况二者的乘积都是 >0
预测错误的情况: (+1, -1) 或者 (-1, +1) 这两种情况的乘积 < 0
感知机的损失函数仅考虑错误分类的样本:
m i n L ( w , b ) = − ∑ i ∈ M y i ( w ⊤ x i + b ) min L(\mathbf{w}, b) = -\sum_{i \in \mathcal{M}} y_i (\mathbf{w}^\top \mathbf{x}_i + b) minL(w,b)=−i∈M∑yi(w⊤xi+b)
其中 M \mathcal{M} M 是错误分类样本的集合。
为什么有个负号? 按照原始的公式定义, ∑ i ∈ M y i ( w ⊤ x i + b ) \sum_{i \in \mathcal{M}} y_i (\mathbf{w}^\top \mathbf{x}_i + b) ∑i∈Myi(w⊤xi+b) 的最大值才是我们的优化目标。
此时的乘积是一种分类边界距离的粗略估计,但并不适用于衡量回归或概率分布的“误差大小”。 (因此不能用误差大小的思路来想。)
说回负号,在机器学习中,我们习惯用**最小化(minimization)**问题来构造损失函数,也方便求导。
优化器SGD、Adam等是梯度下降,适配最小化的loss函数
3. 优化算法:梯度下降
通过求偏导得到:
- 权重更新: ∇ w L = − ∑ i ∈ M y i x i \nabla_\mathbf{w} L = - \sum_{i \in \mathcal{M}} y_i \mathbf{x}_i ∇wL=−∑i∈Myixi
- 偏置更新: ∇ b L = − ∑ i ∈ M y i \nabla_b L = - \sum_{i \in \mathcal{M}} y_i ∇bL=−∑i∈Myi
偏导后得到的是梯度,同时包含“变化的方向”与“变化的速率”
每次迭代更新:
w ← w + η y i x i , b ← b + η y i \mathbf{w} \leftarrow \mathbf{w} + \eta y_i \mathbf{x}_i, \quad b \leftarrow b + \eta y_i w←w+ηyixi,b←b+ηyi
具体而言 ∇ w L = − ∑ i ∈ M y i x i \nabla_\mathbf{w} L = - \sum_{i \in \mathcal{M}} y_i \mathbf{x}_i ∇wL=−∑i∈Myixi 告诉我们:朝着这个方向,损失上升最快
所以我们应该:
w ← w − η ∇ w L \mathbf{w} \leftarrow \mathbf{w} - \eta \nabla_\mathbf{w}L w←w−η∇wL
来减小损失
4. 激活函数:Sign 函数
g ( x ) = sign ( w ⊤ x + b ) g(\mathbf{x}) = \text{sign}(\mathbf{w}^\top \mathbf{x} + b) g(x)=sign(w⊤x+b)
定义如下:
sign ( s ) = { + 1 , s ≥ 0 − 1 , s < 0 \text{sign}(s) = \begin{cases} +1, & s \geq 0 \\\\ -1, & s < 0 \end{cases} sign(s)=⎩ ⎨ ⎧+1,−1,s≥0s<0
5. 感知机的局限性
- 感知机无法处理非线性可分问题。
- 经典反例:XOR 任务。
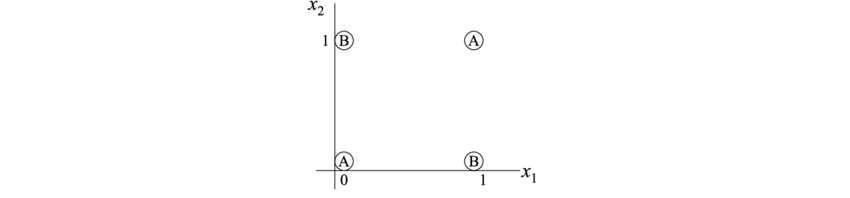
| x1 | x2 | y (XOR) |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
线性模型无法分割这两类。
6. AI 寒冬与转折点
- Minsky 与 Papert 在《Perceptrons》中指出感知机的局限,引发“AI寒冬”。
二、多层感知机(MLP)与非线性建模
1. 多层网络结构
1986年,Hinton 等人提出反向传播算法(Backpropagation):
- 支持隐藏层训练
- 支持非线性组合
组成: 输入层 → 隐藏层 → 输出层
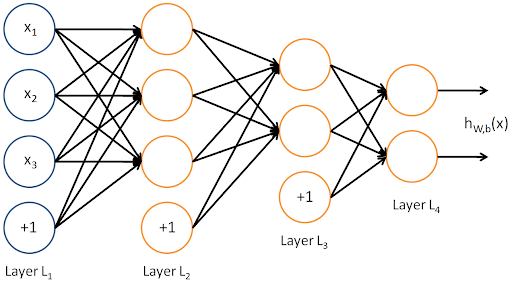
2. 网络表示为函数复合
y = f ( L ) ( … f ( 2 ) ( f ( 1 ) ( x ) ) ) y = f^{(L)}(\dots f^{(2)}(f^{(1)}(x))) y=f(L)(…f(2)(f(1)(x)))
对应结构是一个有向无环图(DAG),每层将上一层的输出作为输入。
3. 非线性激活函数
激活函数必须非线性,否则多层仍等效于单层。
常见激活函数:
-
Sigmoid: f ( s ) = 1 1 + e − s f(s) = \frac{1}{1 + e^{-s}} f(s)=1+e−s1
-
Tanh: f ( s ) = e s − e − s e s + e − s f(s) = \frac{e^s - e^{-s}}{e^s + e^{-s}} f(s)=es+e−ses−e−s
-
ReLU: f ( s ) = max ( 0 , s ) f(s) = \max(0, s) f(s)=max(0,s)
-
Leaky ReLU:
f ( s ) = { s , s ≥ 0 α s , s < 0 f(s) = \begin{cases} s, & s \geq 0 \\\\ \alpha s, & s < 0 \end{cases} f(s)=⎩ ⎨ ⎧s,αs,s≥0s<0 -
GELU: 使用高斯误差函数的平滑激活
4. 通用逼近定理(Universal Approximation Theorem)
通用逼近定理是神经网络理论的核心之一。它说明:
只要一个前馈神经网络具有单隐藏层,且隐藏单元数量足够多,它就能以任意精度逼近任何连续函数。
数学表述
设激活函数 f ( ⋅ ) f(\cdot) f(⋅) 是一个非常数、有界、单调递增的连续函数。
定义 I m = [ 0 , 1 ] m I_m = [0,1]^m Im=[0,1]m 表示 m m m 维单位超立方体, C ( I m ) C(I_m) C(Im) 表示定义在 I m I_m Im 上的所有连续函数的集合。
则对于任意 ε > 0 \varepsilon > 0 ε>0 和任意函数 F ∈ C ( I m ) F \in C(I_m) F∈C(Im),总存在整数 N N N、实数 v i , b i ∈ R v_i, b_i \in \mathbb{R} vi,bi∈R 和向量 w i ∈ R m \mathbf{w}_i \in \mathbb{R}^m wi∈Rm,使得:
F ^ ( x ) = ∑ i = 1 N v i f ( w i ⊤ x + b i ) \hat{F}(x) = \sum_{i=1}^{N} v_i f(\mathbf{w}_i^\top \mathbf{x} + b_i) F^(x)=i=1∑Nvif(wi⊤x+bi)
满足:
∣ F ^ ( x ) − F ( x ) ∣ < ε , ∀ x ∈ I m \left| \hat{F}(x) - F(x) \right| < \varepsilon, \quad \forall x \in I_m F^(x)−F(x) <ε,∀x∈Im
即函数 F ^ ( x ) \hat{F}(x) F^(x) 可以任意逼近 F ( x ) F(x) F(x)。
直观解释
- 神经网络可以通过一个隐藏层 + 足够多的神经元来逼近任何连续函数
- 每个隐藏神经元做一个线性变换 + 激活函数(如 Sigmoid 或 Tanh)
- 输出层再对它们加权求和,实现对复杂函数的拟合
实际意义
| 项目 | 说明 |
|---|---|
| 所需层数 | 仅需单隐藏层(前馈) |
| 所需神经元 | 足够多即可,不一定很深 |
| 所逼近的函数 | 任何连续函数(理论上) |
| 激活函数要求 | 非常数、有界、单调递增、连续 |
引用
Universality Theorem (Hecht-Nielsen, 1989):
“Neural networks with a single hidden layer can be used to approximate any continuous function to any desired precision.”
5. 可视化解释(单输入 → 单输出)
- 增加权重 → 激活函数更陡峭
- 改变偏置 → 平移激活区域(会移动图形,但不会改变图形的形状。)
- 组合多个隐藏神经元 → 构造阶跃、凸包、塔型结构等更复杂函数
在二维输入时,通过构建多个线性超平面与组合,网络可以学习更复杂的输入空间划分。
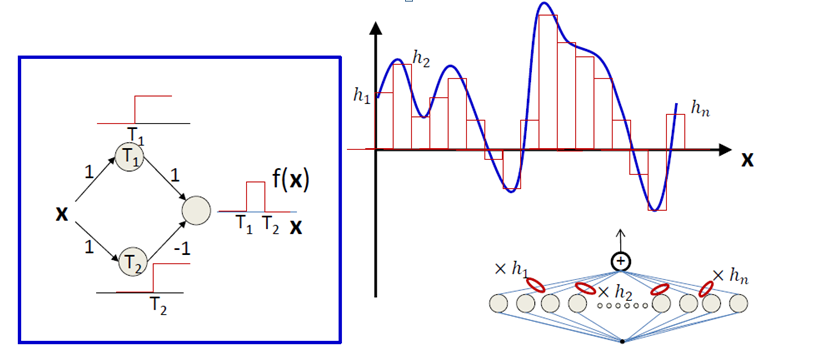
6. 激活函数的作用与常见形式
激活函数是神经元中引入非线性的关键部分,它决定了每个神经元的响应形式。
必须是非线性的:否则就等同于线性分类器
几乎处处连续且可微 ; 单调性:否则会在误差面引入额外的局部极值
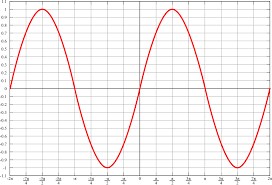
比如 sin 函数就不可以作为激活函数,因为有多个局部极值,不符合单调性。
激活函数的基本结构
一个神经元的输出形式如下:
a = f ( w ⊤ x + b ) a = f(w^\top x + b) a=f(w⊤x+b)
其中:
- f f f 是激活函数
- w ⊤ x + b w^\top x + b w⊤x+b 是线性部分,决定输入的加权求和和偏移
激活函数 f ( ⋅ ) f(\cdot) f(⋅) 的引入,使得神经网络具备学习非线性关系的能力。
常见激活函数
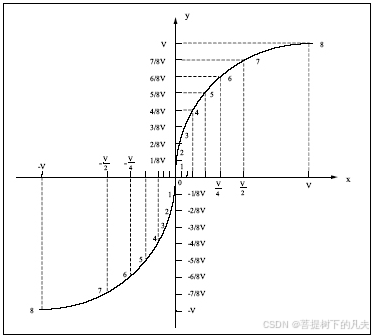
1. Sigmoid(S型函数)
f ( x ) = 1 1 + e − x f(x) = \frac{1}{1 + e^{-x}} f(x)=1+e−x1
-
输出范围: ( 0 , 1 ) (0, 1) (0,1)
-
常用于早期网络、概率建模
-
缺点:梯度容易消失、饱和区间较大
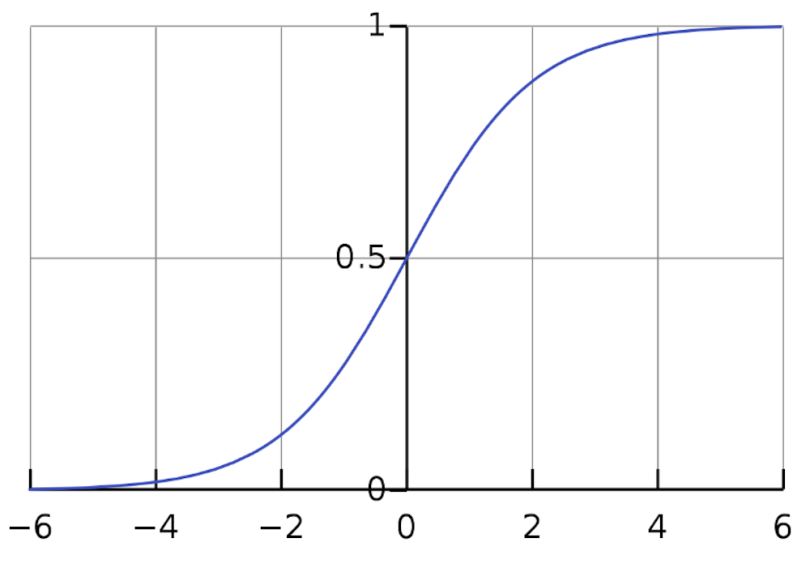
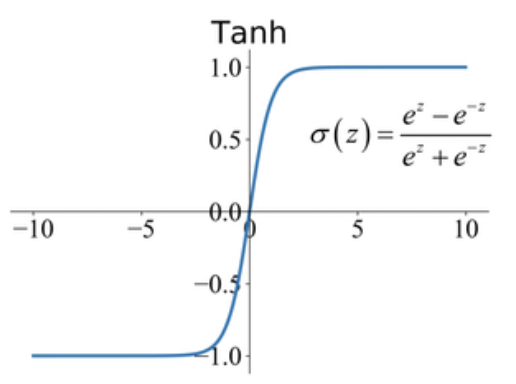
2. Tanh(双曲正切)
f ( x ) = e x − e − x e x + e − x = 2 ⋅ sigmoid ( 2 x ) − 1 f(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} = 2 \cdot \text{sigmoid}(2x) - 1 f(x)=ex+e−xex−e−x=2⋅sigmoid(2x)−1
- 输出范围: ( − 1 , 1 ) (-1, 1) (−1,1)
- 中心化特性优于 sigmoid,训练更稳定
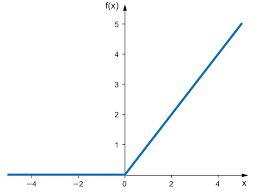
3. ReLU(Rectified Linear Unit)
f ( x ) = max ( 0 , x ) f(x) = \max(0, x) f(x)=max(0,x)
- 当前主流激活函数
- 计算简单,不饱和区域梯度稳定
- 缺点:负区间完全为零(神经元死亡)
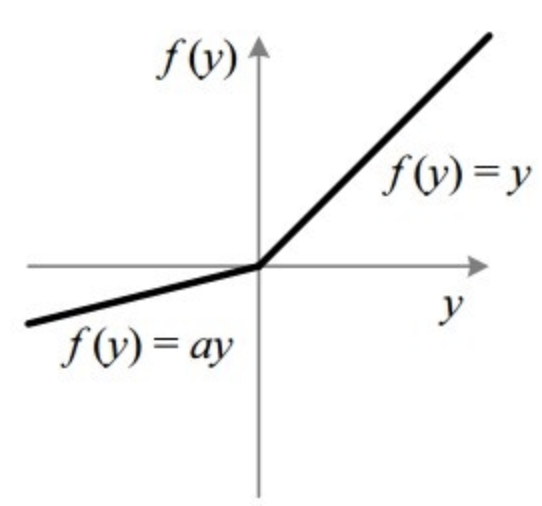
4. Leaky ReLU
f ( x ) = { x , x ≥ 0 α x , x < 0 f(x) = \begin{cases} x, & x \geq 0 \\ \alpha x, & x < 0 \end{cases} f(x)={x,αx,x≥0x<0
-
弥补 ReLU 在负区间完全为 0 的问题
-
α \alpha α 是一个很小的正数(如 0.01)
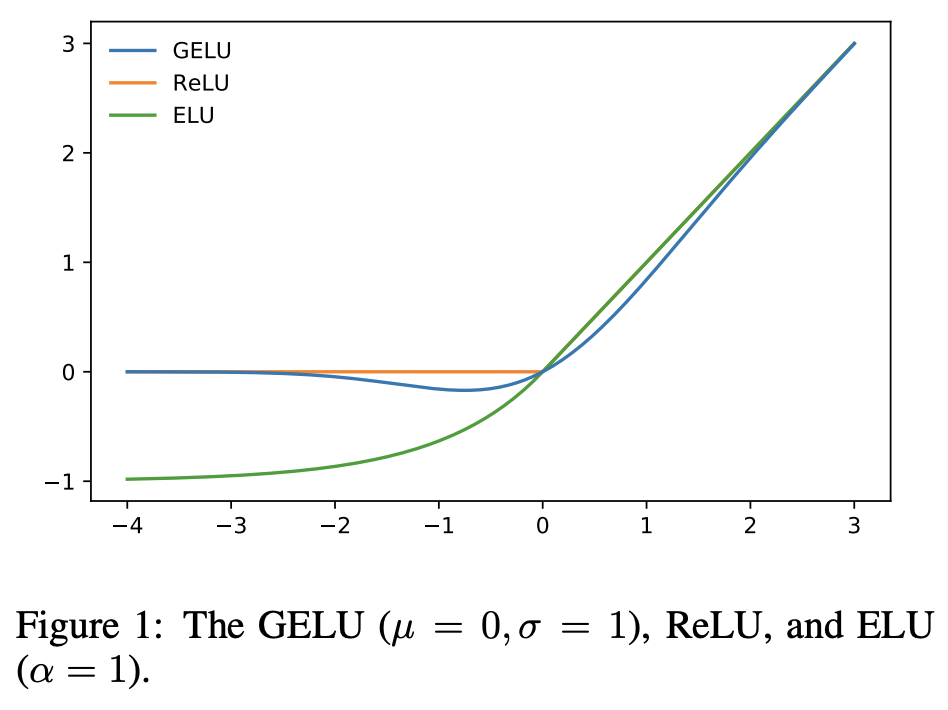
5. GELU(Gaussian Error Linear Unit)
f ( x ) = x ⋅ Φ ( x ) f(x) = x \cdot \Phi(x) f(x)=x⋅Φ(x)
其中 Φ ( x ) \Phi(x) Φ(x) 是标准正态分布的累积分布函数。
- 更平滑的 ReLU 变体
- 被用于 BERT、GPT 等大模型中
激活函数的可视化与作用
- 权重 w w w 控制曲线的陡峭程度(斜率)
- 偏置 b b b 控制曲线在输入空间的位置(左右平移)
- 激活函数本身决定了形状(阶跃、平滑、非线性)
举例说明:
- f ( w x + b ) f(wx + b) f(wx+b) 中改变 w w w 会使 Sigmoid 更陡或更平缓
- 改变 b b b 会让激活区间左移或右移
但注意:
偏置 b b b 不会改变激活函数的形状,只是移动它的激活位置。
而组合多个神经元后,整个网络的输出函数形状就可以被灵活控制,例如拼接成阶梯函数、塔函数等复杂结构。
7. 反向传播与激活函数的梯度问题
在神经网络训练中,我们通过最小化损失函数来更新权重和偏置,这一过程依赖于反向传播算法(Backpropagation)。
反向传播的核心思想是利用链式法则计算每一层参数对损失函数的梯度。
链式法则回顾
对于复合函数:
L = f ( g ( x ) ) ⇒ d L d x = f ′ ( g ( x ) ) ⋅ g ′ ( x ) L = f(g(x)) \Rightarrow \frac{dL}{dx} = f'(g(x)) \cdot g'(x) L=f(g(x))⇒dxdL=f′(g(x))⋅g′(x)
在神经网络中每一层都相当于一次嵌套函数变换,因而可以通过链式法则将梯度从输出层反传至输入层。
激活函数对梯度的影响
梯度的传播会经过每一层的激活函数:
- 若激活函数的导数为零或极小(如 sigmoid 饱和区),则梯度容易消失
- 若激活函数导数过大或不连续,可能造成不稳定训练(如 ReLU 的断点)
各类激活函数的导数
-
Sigmoid:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x) = f(x)(1 - f(x)) f′(x)=f(x)(1−f(x))
→ 导数最大为 0.25,容易出现梯度消失 -
Tanh:
f ′ ( x ) = 1 − f ( x ) 2 f'(x) = 1 - f(x)^2 f′(x)=1−f(x)2
→ 比 sigmoid 好,但也有饱和区 -
ReLU:
f ′ ( x ) = { 1 , x > 0 0 , x ≤ 0 f'(x) = \begin{cases} 1, & x > 0 \\ 0, & x \leq 0 \end{cases} f′(x)={1,0,x>0x≤0
→ 在正区间梯度为 1,负区间为 0(死亡神经元) -
Leaky ReLU:
f ′ ( x ) = { 1 , x > 0 α , x < 0 f'(x) = \begin{cases} 1, & x > 0 \\ \alpha, & x < 0 \end{cases} f′(x)={1,α,x>0x<0
→ 解决了 ReLU 在负区间的“零梯度”问题 -
GELU:
f ′ ( x ) ≈ Φ ( x ) + x ⋅ ϕ ( x ) f'(x) \approx \Phi(x) + x \cdot \phi(x) f′(x)≈Φ(x)+x⋅ϕ(x)
其中 ϕ ( x ) \phi(x) ϕ(x) 是标准正态分布密度函数→ 与ReLU相比平滑,使其能够更好地保留小梯度信息,增强模型的表达能力。
GELU通常比ReLU和Leaky实现更好的收敛性.
激活函数选择对训练的影响
| 激活函数 | 优点 | 缺点 |
|---|---|---|
| Sigmoid | 平滑、输出为概率 | 梯度消失严重 |
| Tanh | 零中心、平滑 | 饱和区影响训练 |
| ReLU | 快速收敛、稀疏激活 | 死亡神经元问题 |
| Leaky ReLU | 缓解死神经元 | 引入超参 α \alpha α |
| GELU | 平滑 & 有理论支持 | 计算复杂 |
因此,在实际模型设计中,需要根据任务和模型深度选择合适的激活函数,以保证训练稳定和效率。
相关文章:
【深度学习】1. 感知器,MLP, 梯度下降,激活函数,反向传播,链式法则
一、感知机 对于分类问题,我们设定一个映射,将x通过函数f(x)映射到y 1. 感知机的基本结构 感知机(Perceptron)是最早期的神经网络模型,由 Rosenblatt 在 1958 年提出,是现代神经网络和深度学习模型的雏形…...
云原生安全:网络协议TCP详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 (注:文末附可视化流程图与专有名词说明表) 1. 基础概念 TCP(Transmission Control Protocol)是…...
使用CentOS部署本地DeekSeek
一、查看服务器的操作系统版本 cat /etc/centos-release二、下载并安装ollama 1、ollama下载地址: Releases ollama/ollama GitHubGet up and running with Llama 3.3, DeepSeek-R1, Phi-4, Gemma 3, Mistral Small 3.1 and other large language models. - Re…...

Spring Boot与Eventuate Tram整合:构建可靠的事件驱动型分布式事务
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、引言 在现代微服务架构中,分布式事务管理一直是复杂系统中的核心挑战之一。传统的两阶段提交(2PC)方案存在性能瓶颈&…...

Python:从脚本语言到工业级应用的传奇进化
一、Python的诞生:一场喜剧与编程的奇妙相遇 1989年的冬天,荷兰程序员Guido van Rossum在阿姆斯特丹的CWI研究所里,用一段独特的代码开启了编程语言的新纪元。这个被命名为"Python"的项目,灵感并非源自冷血的蟒蛇,而是源于Guido对英国喜剧团体Monty Python的痴…...

【排序算法】典型排序算法 Java实现
以下是典型的排序算法分类及对应的 Java 实现,包含时间复杂度、稳定性说明和核心代码示例: 一、比较类排序(通过元素比较) 1. 交换排序 ① 冒泡排序 时间复杂度:O(n)(优化后最优O(n)) 稳定性&…...

node.js如何实现双 Token + Cookie 存储 + 无感刷新机制
node.js如何实现双 Token Cookie 存储 无感刷新机制 为什么要实施双token机制? 优点描述安全性Access Token 短期有效,降低泄露风险;Refresh Token 权限受限,仅用于获取新 Token用户体验用户无需频繁重新登录,Toke…...

[DS]使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码
使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码 摘要:由于 sample_data.csv 是一个占位符文件,用于代表任意数据集,我将使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码…...

探索智能仓颉
探索智能仓颉:Cangjie Magic体验有感 一、引言 在人工智能和智能体开发领域,新的技术和框架不断涌现,推动着行业的快速发展。2025年3月,仓颉社区开源了Cangjie Magic,这是一个基于仓颉编程语言原生构建的LLM Agent开…...

Ubuntu 上开启 SSH 服务、禁用密码登录并仅允许密钥认证
1. 安装 OpenSSH 服务 如果尚未安装 SSH 服务,运行以下命令: sudo apt update sudo apt install openssh-server2. 启动 SSH 服务并设置开机自启 sudo systemctl start ssh sudo systemctl enable ssh3. 生成 SSH 密钥对(本地机器…...
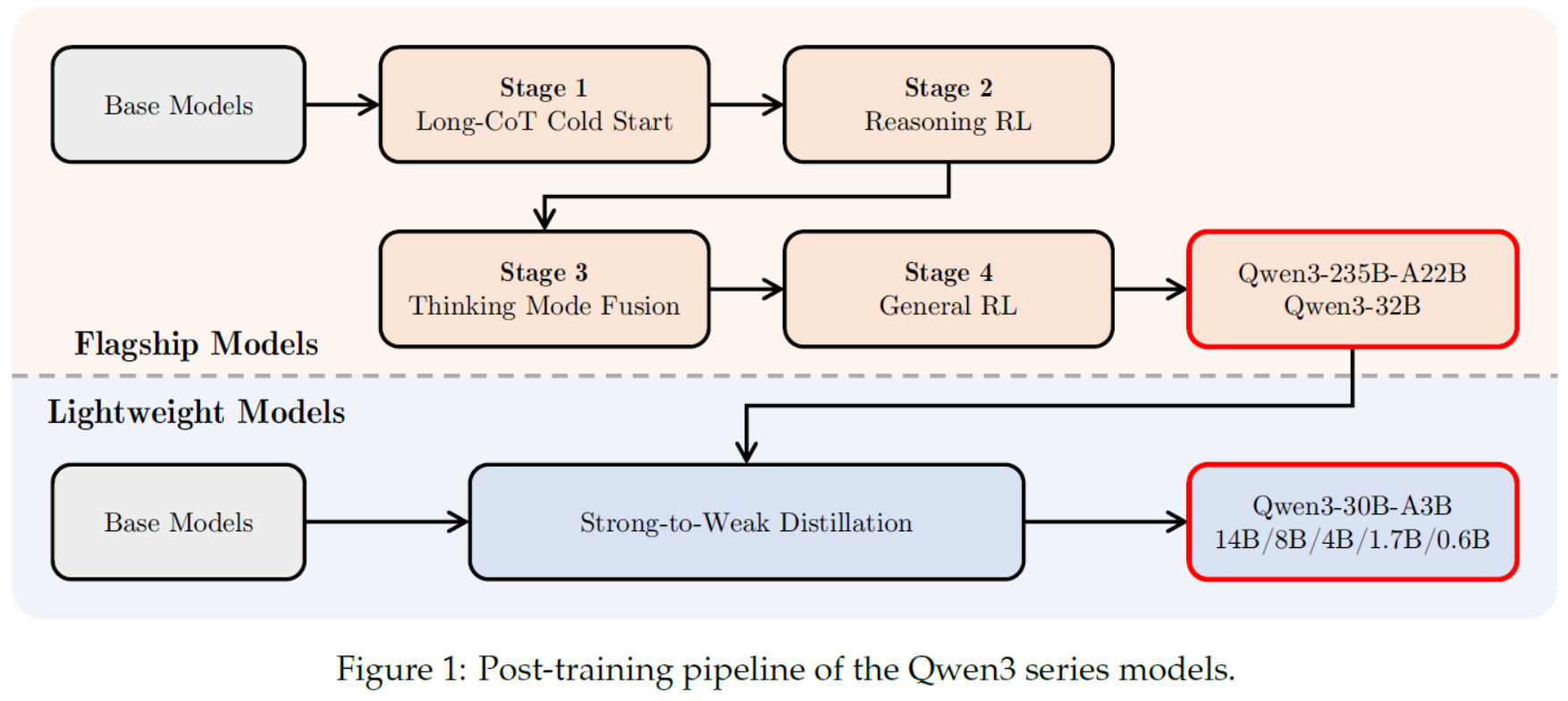
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读 导读:Qwen3是Qwen系列最新的大型语言模型,它通过集成思考和非思考模式、引入思考调度机制、扩展多语言支持以及采用强到弱的知识等创新技术,在性能、效率和多语言能力方面都取得…...

springboot3 configuration
1 多数据库配置 github: https://github.com/baomidou/dynamic-datasource 使用DS()注解来切换数据库 详情介绍:https://www.kancloud.cn/tracy5546/dynamic-datasource/2264611 注意:DS 可以注解在方法上或类上,同时存在就近原则 方法上注…...
从工程实践角度分析H.264与H.265的技术差异
作为音视频从业者,我们时刻关注着视频编解码技术的最新发展。RTMP推流、轻量级RTSP服务、RTMP播放、RTSP播放等模块是大牛直播SDK的核心功能,在这些模块的实现过程中,H.264和H.265两种视频编码格式的应用实践差异是我们技术团队不断深入思考的…...
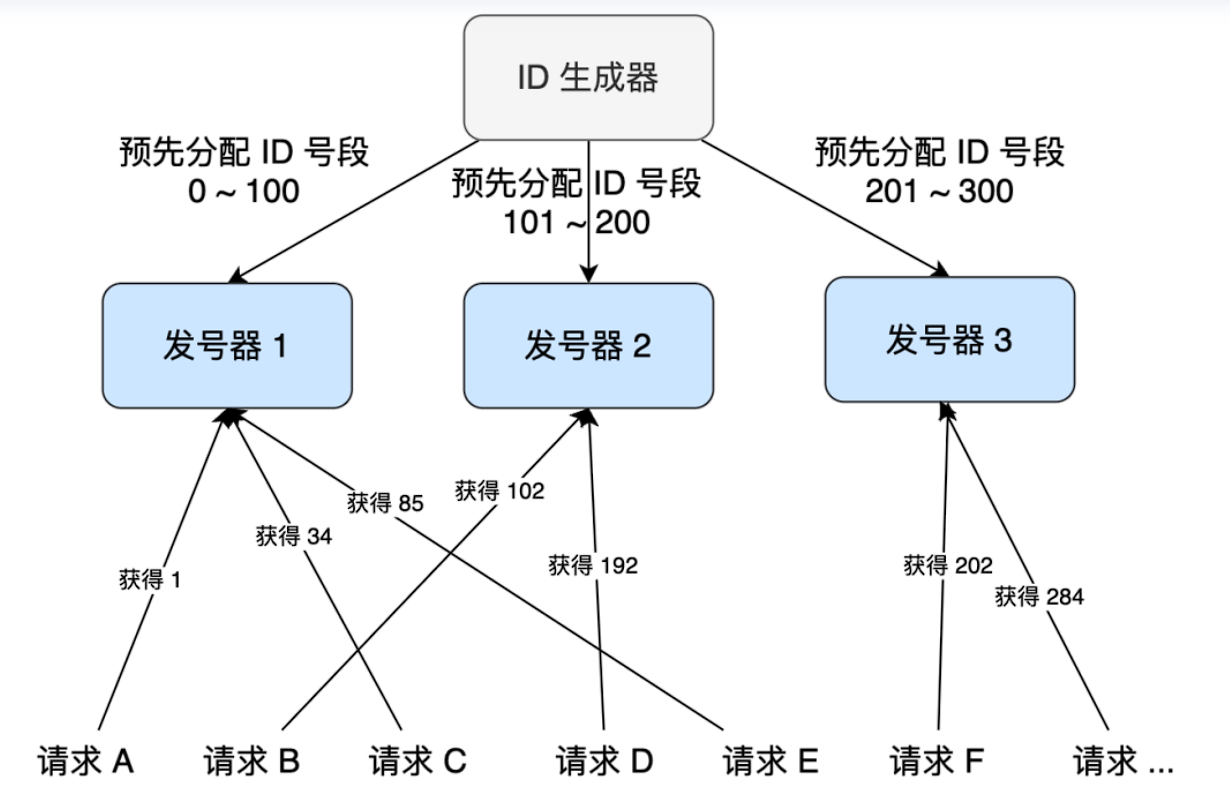
如何设计一个高性能的短链设计
1.什么是短链 短链接(Short URL) 是通过算法将长 URL 压缩成简短字符串的技术方案。例如将 https://flowus.cn/veal/share/3306b991-e1e3-4c92-9105-95abf086ae4e 缩短为 https://sourl.cn/aY95qu,用户点击短链时会自动重定向到原始长链接。其…...
提升工作效率的可视化笔记应用程序
StickyNotes桌面便签软件介绍 StickyNotes是一款极为简洁的桌面便签应用程序,让您能够快速记录想法、待办事项或其他重要信息。这款工具操作极其直观,只需输入文字内容,选择合适的字体大小和颜色,然后点击添加按钮即可创建个性化…...
11|省下钱买显卡,如何利用开源模型节约成本?
不知道课程上到这里,你账户里免费的5美元的额度还剩下多少了?如果你尝试着完成我给的几个数据集里的思考题,相信这个额度应该是不太够用的。而ChatCompletion的接口,又需要传入大量的上下文信息,实际消耗的Token数量其…...

GDB调试工具详解
GDB调试工具详解 一、基本概念 调试信息 编译时需添加 -g 选项(如 gcc -g -o program program.c),生成包含变量名、函数名、行号等调试信息的可执行文件。断点(Breakpoint) 程序执行到指定位置(函数、行号…...

机器学习圣经PRML作者Bishop20年后新作中文版出版!
机器学习圣经PRML作者Bishop20年后新书《深度学习:基础与概念》出版。作者克里斯托弗M. 毕晓普(Christopher M. Bishop)微软公司技术研究员、微软研究 院 科学智 能 中 心(Microsoft Research AI4Science)负责人。剑桥…...

Armadillo C++ 线性代数库介绍与使用
文章目录 Armadillo C 线性代数库介绍与使用主要特点安装Linux (Ubuntu/Debian)macOS (使用 Homebrew)Windows (使用 vcpkg) 基本使用包含头文件矩阵创建与初始化基本运算矩阵分解统计运算保存和加载数据 性能优化建议示例程序与 MATLAB 语法对比 使用Armadillo函数库的稀疏矩阵…...
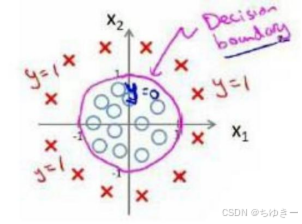
吴恩达机器学习笔记:逻辑回归3
3.判定边界 现在说下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。 在逻辑回归中,我们预测: 当ℎθ (x) > 0.5时,预测 y 1。 当ℎθ (x) < 0.5时,预测 y 0 。 根据…...

大模型知识
############################################################## 一、vllm大模型测试参数和原理 tempreature top_p top_k ############################################################## tempreature top_p top_k 作用:总体是控制模型的发散程度、多样…...

C/C++ 结构体:. 与 -> 的区别与用法及其STM32中的使用
目录 引言 一、深入理解 C/C 结构体:. 与 -> 的区别与用法 1. .(点运算符)详解2. ->(箭头运算符)详解3. . 与 -> 的等价与转换4. 常见错误与调试技巧5. C 特性与运算符重载6. 实战案例:链表与智能…...

docker中使用openresty
1.为什么要使用openresty 我这边是因为要使用1Panel,第一个最大的原因,就是图方便,比较可以一键安装。但以前一直都是直接安装nginx。所以需要一个过度。 2.如何查看openResty使用了nginx哪个版本 /usr/local/openresty/nginx/sbin/nginx …...

Jetpack Compose 中更新应用语言
在 Jetpack Compose 应用中更新语言需要结合传统的 Android 语言配置方法和 Compose 的重组机制。以下是完整的实现方案: 1. 创建语言管理类 object LocaleManager {private var currentLocale: Locale Locale.getDefault()fun setLocale(context: Context, local…...
Java 中的 super 关键字
个人总结: 1.子类构造方法中没有显式使用super,Java 也会默认调用父类的无参构造方法 2.当父类中没有无参构造方法,只有有参构造方法时,子类构造方法就必须显式地使用super来调用父类的有参构造方法。 3.如果父类没有定义任何构造…...

CMake基础:CMakeLists.txt 文件结构和语法
目录 1.CMakeLists.txt基本结构 2.核心语法规则 3.关键命令详解 4.常用预定义变量 5.变量和缓存 6.变量作用域与传递 7.注意事项 1.CMakeLists.txt基本结构 CMakeLists.txt 是 CMake 构建系统的核心配置文件,采用命令式语法组织项目结构和编译流程。主要用于…...
PCM音频数据的编解码
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、pandas是什么?二、使用步骤 1.引入库2.读入数据 总结 前言 提示:这里可以添加本文要记录的大概内容: 例如:…...

WebView2 Win7下部分机器触屏失效的问题
这个问题官方给了解决的方案,相关地址,只需要在项目中运行这个代码即可 public static void DisableWPFTabletSupport(){TabletDeviceCollection devices Tablet.TabletDevices;if (devices.Count > 0){Type inputManagerType typeof(InputManager)…...

Ubuntu 通过指令远程命令行配置WiFi连接
前提设备已经安装了无线网卡。 1、先通过命令行 ssh 登录机器。 2、搜索wifi设备,指令如下: sudo nmcli device wifi 3、输入需要联接的 wifi 名称和对应的wifi密码,指令如下: sudo nmcli device wifi connect wifi名称 passw…...

线程池优雅关闭的哲学
引言 关于并发的哲学,本文将着重强调那些关于线程池优雅关闭的一些技巧,希望对你有所启发。 强制关闭线程池的弊端 对于池化的线程池,如果采用强制关闭的方式将线程池直接关闭,就可能存在上下文消息消息,无法的很好…...