MMA: Multi-Modal Adapter for Vision-Language Models论文解读
abstract
预训练视觉语言模型(VLMs)已成为各种下游任务中迁移学习的优秀基础模型。然而,针对少样本泛化任务对VLMs进行微调时,面临着“判别性—泛化性”困境,即需要保留通用知识,同时对任务特定知识进行微调。如何精确识别这两类表示仍然是一个挑战。在本文中,我们为VLMs提出了一种多模态适配器(MMA),以改善文本和视觉分支表示之间的对齐。MMA将不同分支的特征聚合到一个共享特征空间中,以便梯度可以跨分支传递。为了确定如何融入MMA,我们系统地分析了视觉和语言分支中跨不同数据集的特征的判别性和泛化性,发现:(1)高层包含可辨别的数据集特定知识,而低层包含更具泛化性的知识;(2)语言特征比视觉特征更具判别性,并且两种模态的特征之间存在较大的语义鸿沟,尤其是在低层。因此,我们仅在Transformer的少数高层中融入MMA,以实现判别性和泛化性之间的最佳平衡。我们在三个任务上评估了我们方法的有效性:新类别泛化、新目标数据集泛化和域泛化。与许多最先进的方法相比,我们的MMA在所有评估中均取得了领先的性能。代码位于https://github.com/ZjjConan/Multi-Modal-Adapter。
Introduction
研究背景与挑战
视觉语言模型(VLMs)的潜力:
- CLIP等VLMs通过大规模图像-文本对预训练,能够将视觉和语言特征映射到共享空间,在多种下游任务中表现出色。
- 然而,其庞大的参数量(如CLIP有数亿参数)导致少样本微调困难:
- 过拟合风险: 直接微调所有参数容易在小样本数据上过拟合。
- 计算成本高: 全参数微调需要大量资源,不适用于实际应用。
现有方法的局限性
当前主流方法(如提示学习、单模态适配器)存在不足:
- 提示工程(Prompt Engineering):
- 依赖人工设计文本提示,需专业知识且难以优化。
- 单模态适配器:
- 独立优化视觉或文本分支的适配器,未考虑跨模态特征对齐,导致任务特定知识学习不充分。
核心问题:区分性与泛化性困境
关键矛盾:
- 少样本场景下,模型需同时满足:
- 区分性(Discrimination): 学习任务相关的细粒度特征。
- 泛化性(Generalization): 保留预训练获得的通用知识。
现有方法的缺陷:
- 现有适配器(如AdaptFormer)在所有层添加模块,可能破坏低层的通用特征,导致泛化能力下降。
作者的新发现
通过系统分析CLIP模型的视觉和文本编码器特征,作者得出两个关键观察:
- 层次特性:
- 高层特征(靠近输出的层) 具有更强的数据集特异性(高区分性),适合微调。
- 底层特征(靠近输入的层) 包含更多跨任务通用知识(高泛化性),应尽量保留。
- 模态差异:
- 文本特征比视觉特征更具区分性,尤其在低层存在显著跨模态语义鸿沟,导致对齐困难。
解决方案:多模态适配器(MMA)
基于上述发现,作者提出:
- 分层适配策略: 仅在高层Transformer块(如ViT的5-12层)插入适配器,保留底层的通用性。
- 跨模态共享投影:
- 设计独立投影层处理视觉和文本特征,并通过共享投影层促进跨模态梯度传播,增强特征对齐。
主要贡献
- 方法论创新:
- 提出首个针对VLMs的多模态适配器,通过共享投影层实现跨模态特征对齐。
- 基于层次分析的适配器插入策略,平衡区分性与泛化性。
- 实验验证:
- 在少样本场景下的三大任务(新类识别、跨数据集迁移、域泛化)中,MMA均达到SOTA性能。
- 开源代码:
- 提供完整实现代码,促进后续研究。
2. Related Work
视觉语言模型(Vision-Language Models, VLMs)
代表性模型: 包括CLIP、ALIGN、FILIP、Florence、LiT和Kosmos等。
核心方法: 通过对比学习(如CLIP的对比损失)在大规模图像-文本对(如CLIP的4亿对,ALIGN的10亿对)上进行自监督训练,学习跨模态的联合表示。
优势与挑战:
- 优势: 预训练模型在零样本任务中表现优异,无需微调即可应用于多种下游任务。
- 挑战: 直接微调所有参数在少样本场景下会导致过拟合,且难以平衡任务特定知识与预训练通用知识。
VLMs的高效迁移学习(Efficient Transfer Learning)
作者将现有方法分为两类:提示学习(Prompt Learning) 和 适配器(Adapters),并分析其优缺点:
2.1 提示学习(Prompt Learning)
目标: 通过设计输入提示(如文本模板)引导模型输出,避免全参数微调。
典型工作:
- 单模态提示:
- CoOp: 优化连续的文本提示向量。
- CoCoOp: 根据图像实例动态生成提示。
- LASP: 通过文本到文本的损失对齐提示与预训练知识。
- 多模态提示:
- MaPLe: 在视觉和文本编码器中同时插入可学习的提示,并通过耦合函数对齐跨模态特征。
局限性:
- 提示设计依赖人工经验,优化过程可能过拟合到特定任务。
- 多模态提示研究较少,且未充分挖掘跨模态交互。
2.2 适配器(Adapters)
目标: 在预训练模型中插入轻量级模块(如小网络),仅优化新增参数。
典型工作:
- 单模态适配器:
- Clip-Adapter/Tip-Adapter: 在图像编码器后添加适配层。
- AdaptFormer: 在Transformer块中插入适配模块。
- 多模态适配器:
- 如文本-视频检索中的跨模态适配器,但未深入分析特征层次特性。
局限性:
- 大多数适配器仅针对单模态设计,未考虑跨模态对齐。
- 适配器插入位置缺乏理论指导(如是否应覆盖所有层)。
现有工作的不足与本文切入点
问题1:跨模态对齐不足
- 现有方法(如单模态提示或适配器)未有效利用视觉与文本特征的交互,导致模态间语义鸿沟。
问题2:特征特性未系统分析
- 缺乏对不同层次特征的区分性(discriminability)和泛化性(generalizability)的研究,导致适配策略(如插入层数)依赖经验。
3 Method
3.1 Preliminary(CLIP模型基础)
- CLIP结构:CLIP由文本编码器(Text Encoder, T \mathcal{T} T)和图像编码器(Image Encoder, V \mathcal{V} V)组成,通过对比损失在大规模图像-文本对上预训练,使相关样本的特征在共享空间中接近。
- 图像编码器流程:
图像经 PatchEmbed 分割为固定大小的补丁并投影为特征 x 0 x_0 x0,与可学习的类别标记 c 0 c_0 c0 拼接后,通过 L L L 层 Transformer 块 V i \mathcal{V}_i Vi 提取特征,最终由 PatchProj 投影为图像特征 x x x。 - 文本编码器流程:
文本经 TextEmbed 分词并投影为词嵌入 w 0 j w_0^j w0j,通过 L L L 层 Transformer 块 T i \mathcal{T}_i Ti 提取特征,最终由 TextProj 投影为文本特征 w w w。
- 图像编码器流程:
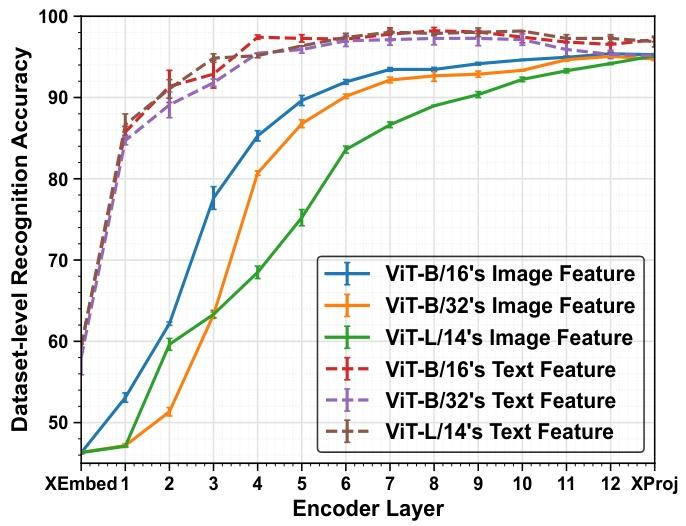
图1. 各种基于Transformer的CLIP模型中不同层的数据集级识别准确率。本实验旨在识别样本所属的数据集。我们使用不同随机种子运行三次,并报告各层识别准确率的平均值和标准差。XEmbed指Transformer块(即自注意力层和前馈层[13])之前的文本或图像嵌入层,而\(X Proj\)指文本或图像投影层。请注意,本实验仅使用所有数据集的训练样本进行评估。
3.2 MMA: Multi-Modal Adapter(多模态适配器设计)
特征分析:判别性与泛化性
- 通过 数据集级识别实验(Dataset-level Recognition)分析CLIP各层特征的特性:
- 高层特征(Transformer高层)包含更多 数据集特定的判别性知识,适合微调;低层特征更具 跨数据集的泛化性,需冻结以保留通用知识。
- 文本特征比 视觉特征更具判别性,且 低层模态间语义鸿沟更大,对齐难度更高,因此仅在高层引入适配器。
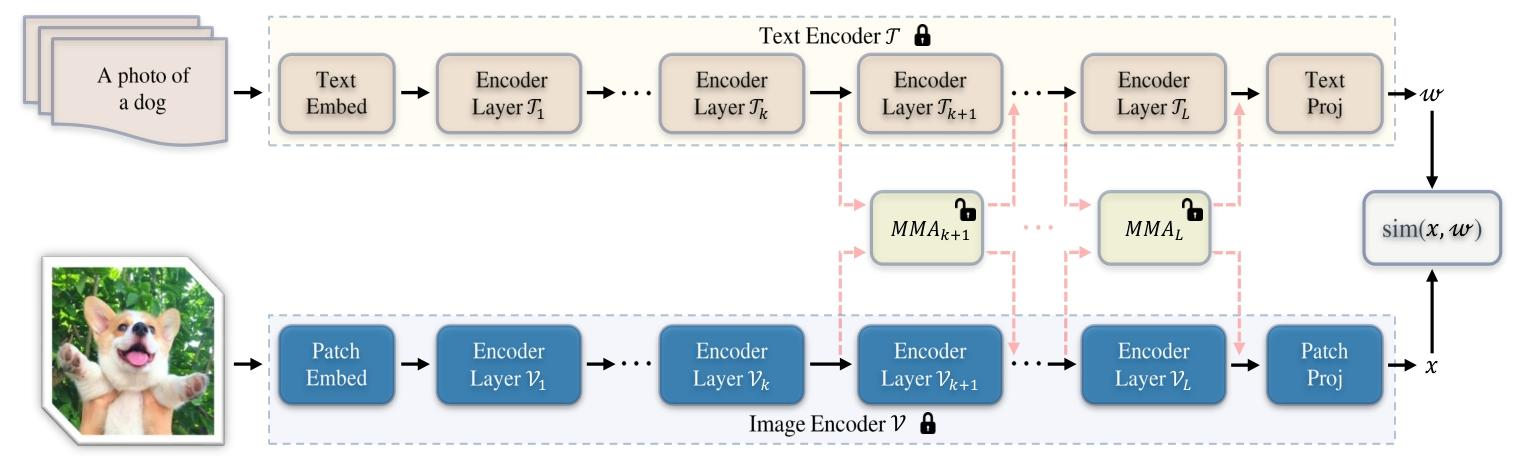
图2. 针对基于Transformer的CLIP模型提出的多模态适配器(MMA)架构图。我们的MMA对图像编码器和文本编码器同时进行调优。训练过程中仅优化额外添加的适配器,而整个预训练CLIP模型的参数保持冻结。基于我们的分析,为了在判别性与泛化性困境之间取得良好平衡,我们的方法仅对每个编码器的少数较高层(≥k)进行调优。此外,MMA在图像和文本表示之间共享权重,以从不同分支学习共享线索。通过这一设计,MMA消除了每对图像-文本对之间特征层面的交互[85],大大降低了计算成本。
宏观设计:仅在高层引入适配器
- 适配器位置:仅在图像和文本编码器的 高层 Transformer 块(从第 k k k 层到最后一层)中添加适配器 A v \mathcal{A}^v Av 和 A t \mathcal{A}^t At,低层保持冻结。
- 图像编码器:
{ [ c i , x i ] = V i ( [ c i − 1 , x i − 1 ] ) , i = 1 , 2 , … , k − 1 [ c j , x j ] = V j ( [ c j − 1 , x j − 1 ] ) + α A j v ( [ c j − 1 , x j − 1 ] ) , j = k , … , L \begin{cases} \left[c_i, x_i\right] = \mathcal{V}_i\left(\left[c_{i-1}, x_{i-1}\right]\right), & i=1,2,\dots,k-1 \\ \left[c_j, x_j\right] = \mathcal{V}_j\left(\left[c_{j-1}, x_{j-1}\right]\right) + \alpha \mathcal{A}_j^v\left(\left[c_{j-1}, x_{j-1}\right]\right), & j=k,\dots,L \end{cases} {[ci,xi]=Vi([ci−1,xi−1]),[cj,xj]=Vj([cj−1,xj−1])+αAjv([cj−1,xj−1]),i=1,2,…,k−1j=k,…,L
其中 α \alpha α 为缩放因子,平衡预训练知识与任务特定知识。 - 文本编码器:
{ [ w i j ] = T i ( [ w i − 1 j ] ) , i = 1 , 2 , … , k − 1 [ w j j ] = T j ( [ w i − 1 j ] ) + α A j t ( [ w i − 1 j ] ) , j = k , … , L \begin{cases} \left[w_i^j\right] = \mathcal{T}_i\left(\left[w_{i-1}^j\right]\right), & i=1,2,\dots,k-1 \\ \left[w_j^j\right] = \mathcal{T}_j\left(\left[w_{i-1}^j\right]\right) + \alpha \mathcal{A}_j^t\left(\left[w_{i-1}^j\right]\right), & j=k,\dots,L \end{cases} ⎩ ⎨ ⎧[wij]=Ti([wi−1j]),[wjj]=Tj([wi−1j])+αAjt([wi−1j]),i=1,2,…,k−1j=k,…,L。
- 图像编码器:
微观设计:跨模态对齐的共享投影层
- 独立投影层:图像和文本分支分别通过独立的 “Down” 和 “Up” 投影层( W k d v , W k u v W_{kd}^v, W_{ku}^v Wkdv,Wkuv 和 W k d t , W k u t W_{kd}^t, W_{ku}^t Wkdt,Wkut)提取任务特定特征。
- 共享投影层:通过共享权重 W k s W_{ks} Wks 聚合双模态特征,促进跨模态梯度传播和语义对齐,公式为:
A k v ( z k ) = W k u v ⋅ δ ( W k s ⋅ δ ( W k d v ⋅ z k ) ) \mathcal{A}_k^v(z_k) = W_{ku}^v \cdot \delta\left(W_{ks} \cdot \delta\left(W_{kd}^v \cdot z_k\right)\right) Akv(zk)=Wkuv⋅δ(Wks⋅δ(Wkdv⋅zk))
其中 z k z_k zk 为图像或文本分支的输入特征, δ \delta δ 为激活函数。
4. Experiments
4.1 实验设置
任务与数据集
-
新类别泛化(Base-to-Novel Generalization)
- 评估模型从基类(Base Classes)迁移到新类(Novel Classes)的能力。
- 数据集:11个图像分类数据集,包括ImageNet、Caltech101(通用目标)、OxfordPets、StanfordCars(细粒度)、SUN397(场景)等。
- 配置:16-shot设置(每类16个训练样本),仅在基类训练,测试基类与新类准确率。
-
跨数据集评估(Cross-Dataset Evaluation)
- 模型在ImageNet上训练后,直接迁移到其他10个数据集(如DTD纹理、EuroSAT卫星图像等)进行测试,评估零样本迁移能力。
-
域泛化(Domain Generalization)
- 测试模型在分布外(Out-of-Distribution)数据集上的鲁棒性,使用ImageNet的4种变体:ImageNet-V2(视觉偏差)、ImageNet-Sketch(草图)、ImageNet-A(对抗样本)、ImageNet-R(真实扰动)。
实现细节
- 模型基础:基于CLIP的ViT-B/16架构,冻结预训练参数,仅优化MMA适配器。
- 适配器配置:
- 新类别泛化:从第5层(k=5)开始添加适配器,共享层维度32,训练5个 epoch,批次大小128(ImageNet)/16(其他数据集)。
- 跨数据集与域泛化:k=9,训练1个 epoch,使用SGD优化器,余弦学习率调度。
- 基线与对比方法:包括CLIP零样本、文本提示学习(CoOp、CoCoOp)、多模态提示学习(MaPLe)、适配器方法(LASP、RPO)等。
4.2 主要结果
1. 新类别泛化(表1)
- 性能对比:
- MMA在11个数据集上的平均调和均值(HM)为79.87%,显著优于SOTA方法(如LASP-V的79.48%、MaPLe的78.55%)。
- 基类准确率(83.20%)与新类准确率(76.80%)均领先,表明其有效平衡了判别性与泛化性。
- 关键发现:
- 文本提示方法(如CoOp)在新类表现较差(63.22%),因缺乏跨模态对齐;MMA通过共享投影层提升对齐,新类准确率提升超3%。
2. 跨数据集评估(表2)
- 零样本迁移能力:
- MMA在10个目标数据集上的平均准确率为66.61%,优于MaPLe(66.30%)、LASP(63.88%)等,尤其在细粒度(如StanfordCars)和遥感数据(EuroSAT)上优势明显。
- 在源数据集ImageNet上,MMA准确率与CoOp相当,但迁移到其他数据集时更鲁棒。
3. 域泛化(表3)
- 分布外鲁棒性:
- MMA在3/4个数据集(ImageNet-V2、ImageNet-A、ImageNet-R)上性能最优,准确率分别为64.33%、51.12%、77.32%,显著优于CLIP和提示学习方法。
- 结果表明,MMA通过高层适配器保留了预训练模型的泛化性,对域 shift 更鲁棒。
4.3 消融实验
1. 适配器层数选择(图4)
- k值影响:
- 当k=5时,HM达到最高79.87%。k<5时(如k=1),低层特征泛化性强但判别性不足,新类准确率下降;k>5时(如k=9),高层特征过度拟合基类,新类性能降低。
- 结论:高层适配器(k=5)最佳,平衡了数据集特定知识与通用知识。
2. 共享投影层的重要性(表4a)
- 对比实验:
- 移除共享投影层(No SharedProj)导致HM从79.87%降至79.20%,验证跨模态对齐的必要性。
- 仅单模态适配器(Only V-Adapter/Only L-Adapter)性能低于双模态,表明融合文本与视觉特征的重要性。
3. 共享层维度与缩放因子α(表4b、4c)
- 维度影响:
- 维度32时性能最佳(HM=79.87%),过大维度(如128)因参数过多导致过拟合,新类准确率下降。
- α的平衡作用:
- α=0.001时,HM最高。α过大会偏向基类拟合(如α=0.01时新类74.32%),过小则难以学习任务特征(α=0.0001时基类79.40%)。
相关文章:
MMA: Multi-Modal Adapter for Vision-Language Models论文解读
abstract 预训练视觉语言模型(VLMs)已成为各种下游任务中迁移学习的优秀基础模型。然而,针对少样本泛化任务对VLMs进行微调时,面临着“判别性—泛化性”困境,即需要保留通用知识,同时对任务特定知识进行微…...

Java中Map集合的遍历方式详解
Java中Map集合的遍历方式详解 一、Map 集合概述二、Map 遍历的基础方式1. **使用 KeySet 迭代器遍历**2. **使用 KeySet 的 for-each 循环** 三、EntrySet 遍历:高效的键值对访问1. **EntrySet 迭代器遍历**2. **EntrySet 的 for-each 循环** 四、Java 8 引入的 Lam…...
使用 Cannonballs 进行实用导体粗糙度建模
在 GB/s 制度下,导体损耗的精确建模是高速串行链路设计成功的前提。未能对粗糙度效果进行建模可能会毁了您的一天。例如,图 1 显示了与测量数据相比,无粗糙度的 40 英寸印刷电路板 (PCB) 走线的模拟总损耗。总损耗是电…...

Spring Boot 注解 @ConditionalOnMissingBean是什么
一句话总结: ConditionalOnMissingBean 是 Spring Boot 提供的一个 条件注解(Conditional Annotation),意思是: 只有当 Spring 容器中 不存在 某个 Bean 时,当前的 Bean 或配置才会被加载。 这是一种典型的…...
)
国外常用支付流程简易说明(无代码)
一、Xendit Xendit 是一家总部位于印度尼西亚的支付解决方案提供商,业务覆盖东南亚多个国家。它允许企业接受信用卡以及多种本地支付方式: 1、如果需要,创建一个 Xendit 帐户并登录Xendit 仪表板。 2、在页面左上角查看您的账户模式。使用…...
(先发再改)测试流程标准文档
Revision Record 修订记录 序号 修改日期 修改章节 修改描述 拟制 审批 修订版本 1 20250520 初稿 v1.0 目录 1. 文档概述... 7 1.1 文档目的... 7 1.1.1 标准化质量保障流程... 7 1.1.2.…...
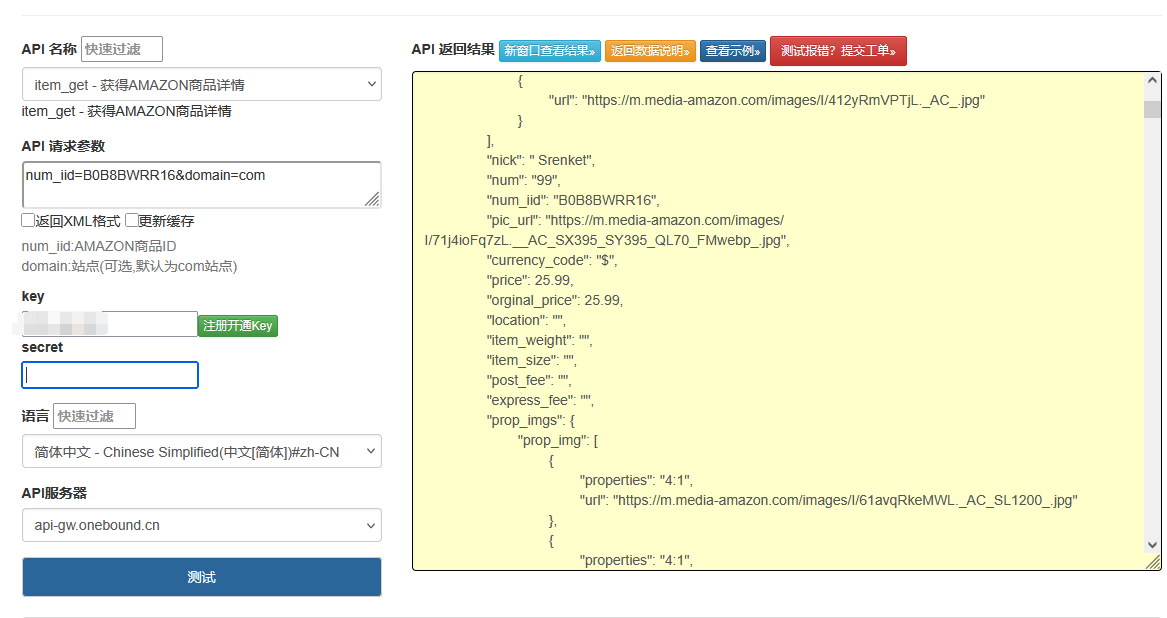
亚马逊SP-API开发实战:商品数据获取与操作
一、API接入准备 开发者注册: 登录亚马逊开发者中心申请SP-API权限 完成MWS迁移(如适用) 认证配置: # OAuth2.0认证示例 import requests auth_url "https://api.amazon.com/auth/o2/token" params { "…...

行为型:策略模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 5、优化技巧 1、核心思想 目的:将算法(行为)抽象出来作为一系列策略类,使他们可以相互替换,使系统拥有“可插拔”扩展的能…...

知识宇宙-学习篇:开源项目 README 文档该如何写?
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、README 文档的重要性1. 项目的第一印象2. 搜索引擎优化的重要载体 二、现代 RE…...

YOLOv12增加map75指标
YOLOv12源码:https://github.com/sunsmarterjie/yolov12 第一步:更改Val.py文件 地址:该文件在yolov12-main\ultralytics\models\yolo\detect下 首先定位到def get_desc(self):这个函数上 代码修正如下: def get_desc(self):&q…...

Avalanche 六期 Workshop 精华合集|Grant 机会、技术深度、项目实战一文回顾!
作为当前区块链技术的前沿代表,Avalanche 以其独特的高吞吐、低延迟、多链架构,为开发者提供了一种颠覆性的 Layer 1 解决方案。不同于传统的 EVM 兼容链,Avalanche 支持开发者自定义执行环境,灵活选择最适合自身业务需求的虚拟机…...

【MySQL】第九弹——索引(下)
文章目录 🌏索引(上)回顾🌏使用索引🪐自动创建索引🪐手动创建索引🚀主键索引🚀普通索引🚀唯一索引🚀复合索引 🪐查看索引🪐删除索引🚀删除主键索引…...

leetcode-295 Find Median from Data Stream
class MaxHeap {private heap: number[];constructor() {this.heap [];}// 插入元素并上浮调整push(num: number): void {this.heap.push(num);this.siftUp(this.heap.length - 1);}// 弹出堆顶元素并下沉调整pop(): number {const top this.heap[0];const last this.heap.p…...

【后端高阶面经:缓存篇】37、高并发系统缓存性能优化:从本地到分布式的全链路设计
一、缓存性能优化的核心价值与分层架构 (一)缓存的多维价值体系 延迟优化 内存访问速度(100ns) vs 磁盘数据库(10ms+),性能提升10万倍+案例:电商详情页通过缓存将响应时间从500ms降至50ms吞吐提升 单机Redis可支撑10万QPS,分担数据库压力案例:秒杀系统通过缓存拦截9…...

西门子 S1500 博途软件舞台威亚 3D 控制方案
西门子 S1500 PLC 是工业自动化领域的主流控制器,适合高精度、高可靠性的舞台威亚控制。下面为你提供基于博途 (TIA Portal) 软件的 3D 控制方案设计。 系统架构设计 舞台威亚 3D 控制系统通常包含以下组件: 硬件层: S1500 PLC 主机伺服驱动…...
)
洛谷 P3374 【模板】树状数组 1(线段树解法)
【题目链接】 洛谷 P3374 【模板】树状数组 1 【题目考点】 1. 线段树 线段树(Segment tree)是一种用来维护区间信息的数据结构。 线段树中每个结点代表一个区间 根结点代表整体区间。 叶子结点代表长为1的单位区间。 对于线段树中的每一个分支结点 [ l , r ] [l, r] [l,r]…...

欣佰特科技| SIL2/PLd 认证 Inxpect毫米波安全雷达:3D 扫描 + 微小运动检测守护工业安全
Inxpect 成立于意大利,专注工业安全技术。自成立起,便致力于借助先进雷达技术提升工业自动化安全标准,解决传统安全设备在复杂环境中的局限,推出获 SIL2/PLd 和 UL 认证的安全雷达产品。 Inxpect 的雷达传感器技术优势明显。相较于…...

大模型量化原理
模型量化的原理是通过降低数值精度来减少模型大小和计算复杂度。让我详细解释其核心原理:我已经为您创建了一个全面的模型量化原理详解文档。总结几个核心要点: 量化的本质 量化的核心是精度换性能的权衡——通过降低数值精度(FP32→INT8&a…...

dify-api的.env配置文件
源码位置:dify\api\.env 本文使用Dify v1.3.1。配置文件中各变量的详细信息表,如下所示: 变量英文名变量中文名默认值变量功能SECRET_KEY秘密密钥XXX用于安全地签署会话cookie的应用秘密密钥。确保在部署时使用强密钥。CONSOLE_API_URL控制…...
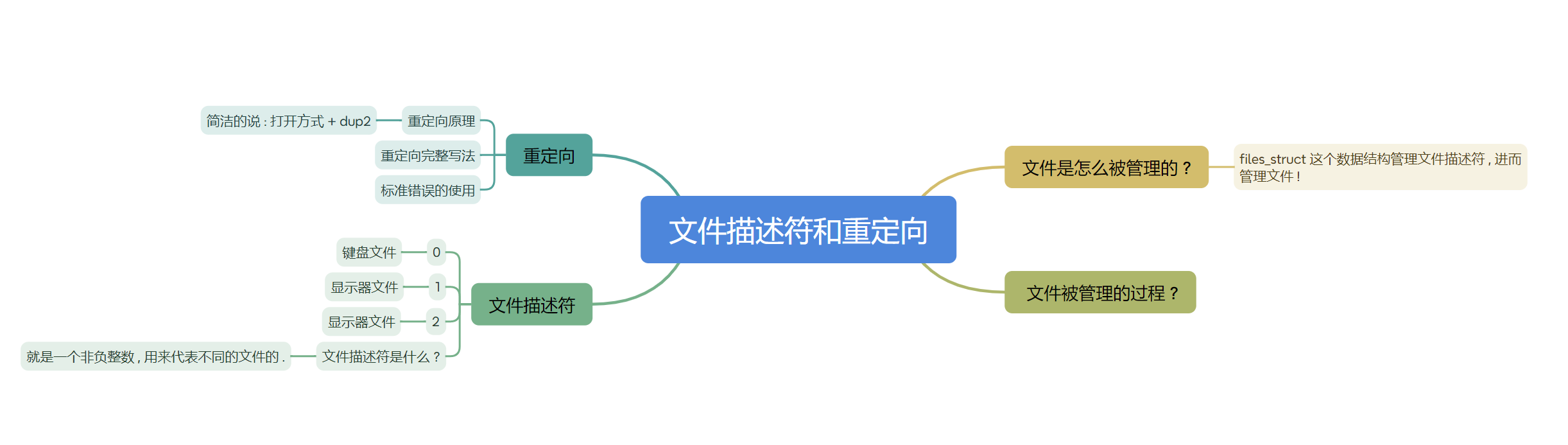
【Linux】Linux 操作系统 - 18 , 重谈文件(二) ~ 文件描述符和重定向原理 , 手把手带你彻底理解 !!!
文章目录 ● 文件描述符一 、Linux 系统对文件的管理(要知道)二 、什么是文件描述符 fd ?三 、再探文件被管理过程(重要)四 、文件描述符 0 、1、21. 文件描述符的分配原则2. 提前认识三个默认打开的文件 ● 重定向原理(重要)一 、重定向现象二 、深入剖析重定向现象(重要)1…...
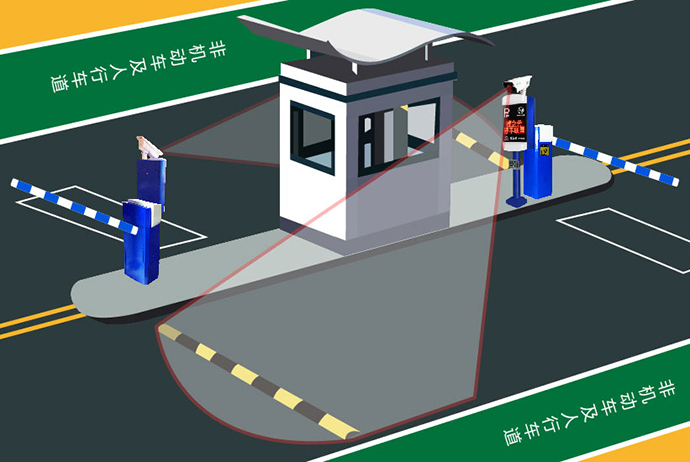
第五十三节:综合项目实践-车牌识别系统
一、项目背景与意义 车牌识别系统(LPR)是智能交通领域的核心技术之一,广泛应用于停车场管理、违章抓拍、高速公路收费等场景。本文将通过Python+OpenCV实现一个完整的车牌识别系统,涵盖图像预处理→车牌定位→字符分割→字符识别四大核心环节。 二、系统架构设计 技术栈组…...
)
AI时代新词-AI伦理(AI Ethics)
一、什么是AI伦理? AI伦理(AI Ethics)是指在人工智能(AI)的设计、开发、部署和使用过程中,涉及的道德、法律和社会问题的综合考量。它关注AI技术对人类社会、文化、价值观以及个人权利的影响,并…...

湖北理元理律师事务所债务优化服务中的“四维平衡“之道
债务问题解决需要兼顾多方利益,湖北理元理律师事务所通过独特的服务模式,在法律、经济、心理、社会四个维度建立平衡点。 一、法律维度的专业把控 合规性审查: 合同效力认定 诉讼时效核查 担保责任界定 程序合法性: 所有协…...

Git Push 失败:HTTP 413 Request Entity Too Large
Git Push 失败:HTTP 413 Request Entity Too Large 问题排查 在使用 Git 推送包含较大编译产物的项目时,你是否遇到过 HTTP 413 Request Entity Too Large 错误?这通常并不是 Git 的问题,而是 Web 服务器(如 Nginx&am…...
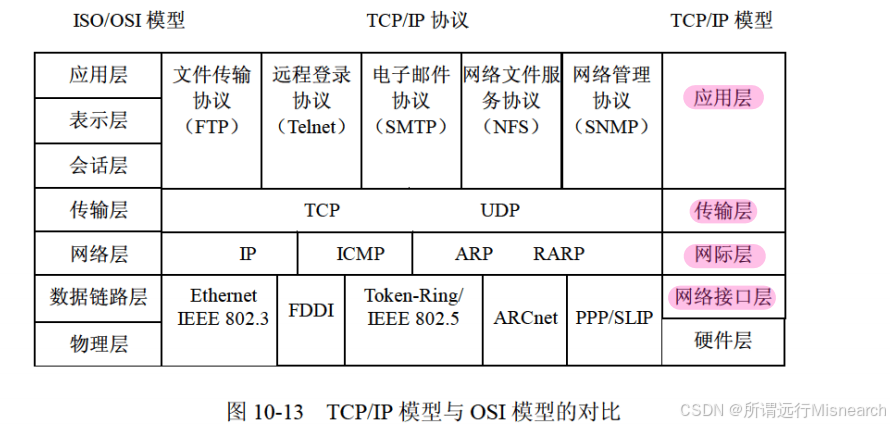
第10章 网络与信息安全基础知识
网络概述 多模光纤的特点:成本低,宽芯线,聚光好,耗散大,低效,用于低速度、短距离的通信。 单模光纤的特点:成本高,窄芯线,需要激光源,耗散小,高效…...
)
GO语言学习(九)
GO语言学习(九) 上一期我们了解了实现web的工作中极为重要的net/http抱的细节讲解,大家学会了实现web开发的一些底层基础知识,在这一期我来为大家讲解一下web工作的一个重要方法,:使用数据库,现…...

go 访问 sftp 服务 github.com/pkg/sftp 的使用踩坑,连接未关闭(含 sftp 服务测试环境搭建)
前言 最近在使用 sftp 服务时,被告知发起了海量的连接,直接把服务器搞崩,ip 被封了。 这是啥情况? golang 写的代码,我就正常的访问 sftp 服务,连接使用过后也都关闭了,咋会出现连接一直连着…...
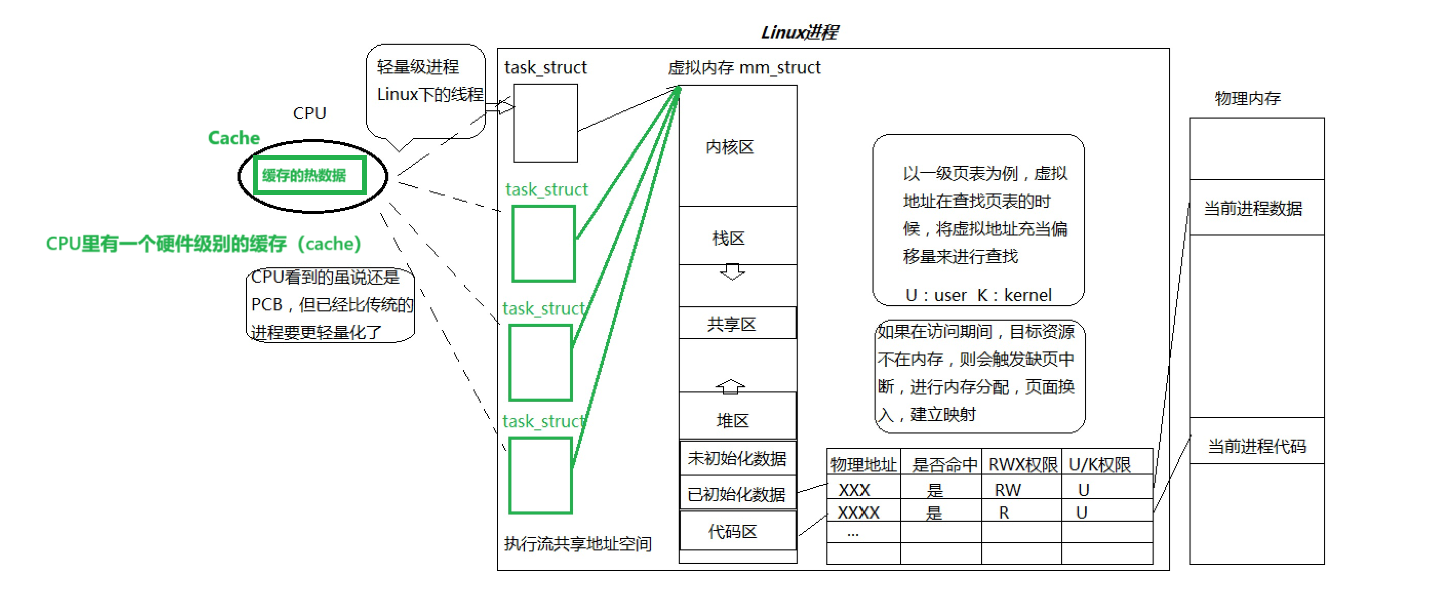
Linux多线程(二)之进程vs线程
文章目录 Linux进程VS线程进程和线程进程的多个线程共享关于进程线程的问题 重谈地址空间Linux线程周边的概念 Linux进程VS线程 进程和线程 进程是资源分配的基本单位(进程是承担分配系统资源的基本实体) 执行流也是资源!线程是进程内部的执…...

【MogDB】测试 ubuntu server 22.04 LTS 安装mogdb 5.0.11
测试 ubuntu server 22.04 LTS 安装mogdb 5.0.11 使用的操作系统镜像是 https://releases.ubuntu.com/22.04/ubuntu-22.04.5-live-server-amd64.iso 装好操作系统后,把root登录打开了,方便后续操作。 测试过程 使用官方命令在线安装ptk rootubuntu22…...
)
AI时代新词-数字孪生(Digital Twin)
一、什么是数字孪生(Digital Twin)? 数字孪生(Digital Twin)是一种通过创建物理实体的虚拟副本,并利用数据和算法来模拟、分析和优化物理实体的性能和行为的技术。数字孪生结合了物联网(IoT&am…...