数据结构-排序(1)
一,排序的基本概念
1.排序的定义
-
核心概念: 给定一个包含
n个元素的序列(R1, R2, ..., Rn)和一个关键码Ki(通常是记录Ri的一个属性),排序的目标是找到一个排列(p1, p2, ..., pn),使得关键码序列(Kp1, Kp2, ..., Kpn)满足一个特定的非递减(升序)或非递增(降序)关系。 -
通俗理解: 就是把一堆杂乱无章的数据,按照某种规则(比如数字大小、字母顺序、日期先后)排列整齐的过程。
2.排序的目的与重要性
-
提高查找效率: 在有序数据上进行查找(尤其是二分查找)的速度远快于无序数据(顺序查找)。例如,在电话簿中找名字、在字典中查单词。
-
数据组织与呈现: 用户通常期望看到有序的数据,如按价格从低到高显示商品、按分数从高到低排名学生成绩、按时间顺序显示邮件。
-
数据分析和统计的基础: 许多统计计算(如中位数、百分位数)和数据分析操作(如合并、分组、去重)都依赖于或受益于数据的有序性。
-
作为其他算法的子程序: 很多高效的算法(如归并排序用于外部排序、二叉搜索树构建)都需要先对数据进行排序。
-
优化资源使用: 有序数据有时可以减少存储空间(如通过游程编码压缩)或提高某些处理过程(如合并有序文件)的效率。
3.排序的分类(关键维度)
排序算法可以从多个维度进行分类,以下是主要分类方式:
1.按存储位置:
- 内部排序: 整个排序过程完全在内存中进行。适用于数据量较小,可以一次性加载到内存的情况。这是最常见的研究对象。例如:冒泡排序、插入排序、选择排序、快速排序、堆排序、归并排序。
- 外部排序: 待排序的数据量非常大,无法一次性装入内存。排序过程需要在内存和外存(如磁盘)之间进行多次数据交换。通常基于归并排序的思想进行优化。例如:多路归并排序
2.按稳定性:
- 稳定排序: 如果待排序序列中存在关键码相等的记录
Ri和Rj(即Ki = Kj),且在排序前的序列中Ri领先于Rj(即i < j)。如果排序后Ri仍然领先于Rj,则称该排序算法是稳定的。 - 重要性: 当需要按多个关键码进行排序时(例如,先按分数降序排,分数相同的再按学号升序排),稳定性至关重要。第一次排序(按分数)的稳定性保证了分数相同的记录在第二次排序(按学号)时,其原始相对顺序(学号顺序)得以保留。
- 常见稳定排序: 冒泡排序、插入排序、归并排序、基数排序、计数排序。
- 不稳定排序: 不能保证关键码相等的记录的相对位置在排序前后保持一致。
- 常见不稳定排序: 选择排序、快速排序、堆排序、希尔排序。
3.按时间复杂度: (最常用和最重要的分类维度)
-
简单排序 / O(n²) 排序: 平均和最坏情况时间复杂度为 O(n²)。通常实现简单,代码量小,适用于小规模数据或基本有序的数据,但性能在大数据量下较差。
-
冒泡排序、插入排序、选择排序。
-
-
高效排序 / O(n log n) 排序: 平均时间复杂度为 O(n log n)。性能优异,适用于大规模数据。
-
快速排序、归并排序、堆排序。
-
-
线性时间排序 / O(n) 排序: 在特定条件下(如关键码是某个较小范围内的整数)可以达到线性时间复杂度 O(n)。它们通常不是基于比较的排序。
-
计数排序、桶排序、基数排序。
-
-
其他: 希尔排序(时间复杂度介于 O(n log n) 和 O(n²) 之间,具体取决于增量序列)。
4.按是否比较:
-
比较排序: 通过比较元素之间的大小关系来决定它们的相对顺序。排序算法的下界(即任何比较排序算法在最坏情况下所需的比较次数)是 Ω(n log n)。
-
冒泡、插入、选择、快速、归并、堆、希尔排序。
-
-
非比较排序: 不通过直接比较元素大小来确定顺序,而是利用数据的特定属性(如整数范围、位数)进行排序。它们可以突破 Ω(n log n) 的下界,达到 O(n) 的时间复杂度,但应用场景有特定限制。
-
计数排序、桶排序、基数排序。
-
5.按原地性:
-
原地排序: 排序过程中只需要常数级别的额外辅助存储空间(O(1))。主要通过在原始数组内部交换元素来完成排序。
-
冒泡排序、插入排序、选择排序、快速排序、堆排序、希尔排序。
-
-
非原地排序: 排序过程中需要额外的、与数据规模 n 成比例的存储空间(O(n) 或更多)。通常需要额外的数组来存放中间结果或最终结果。
-
归并排序、计数排序、桶排序、基数排序。
-
五、常见排序算法简述 (按时间复杂度)
1.O(n²) 算法:
-
冒泡排序: 反复遍历列表,比较相邻元素,如果顺序错误就交换它们。每一轮遍历将最大的元素“冒泡”到末尾。实现简单,效率低。
-
插入排序: 将列表视为“已排序区”和“未排序区”。每次从未排序区取出第一个元素,在已排序区中从后向前扫描找到合适的位置插入。对部分有序数据和小规模数据高效。
-
选择排序: 反复从未排序部分中选择最小(或最大)元素,将其与未排序部分的第一个元素交换位置。交换次数少,但比较次数固定为 O(n²),不稳定。
2.O(n log n) 算法:
-
快速排序: 采用分治法。选择一个基准元素,将列表划分为两部分:小于基准的部分和大于基准的部分。然后递归地对这两部分进行排序。平均性能极佳,是最常用的通用排序算法之一。原地,不稳定。
-
归并排序: 采用分治法。将列表递归地分成两半,直到每部分只有一个元素(天然有序)。然后反复合并两个已排序的子列表,最终得到完整有序列表。性能稳定 (O(n log n)),稳定,但需要额外 O(n) 空间。是外部排序的基础。
-
堆排序: 利用堆(一种特殊的完全二叉树)这种数据结构。将列表构建成最大堆(或最小堆),堆顶元素就是最大(最小)值。将堆顶元素与末尾元素交换,堆大小减一,然后重新调整堆使其满足堆性质。重复此过程直到堆为空。原地,不稳定,O(n log n) 时间复杂度稳定。
3.O(n) 算法 (非比较,特定条件下):
-
计数排序: 要求输入数据是确定范围(如 0 到 k)内的整数。创建一个计数数组统计每个整数出现的次数,然后根据计数数组重构有序序列。稳定,需要额外 O(k+n) 空间。
-
桶排序: 假设输入数据均匀分布在某个范围内。将数据分到有限数量的有序桶中(例如,范围 [0,1) 分成 10 个桶 [0,0.1), [0.1,0.2), ..., [0.9,1))。对每个桶内进行排序(可用其他算法),然后按桶顺序依次输出。性能依赖于数据分布和桶内排序算法。
-
基数排序: 从最低有效位(LSD)或最高有效位(MSD)开始,对关键码进行逐位排序。通常使用稳定排序(如计数排序)作为其子过程。适用于整数、字符串等有固定位/字符长度的数据。稳定,需要额外空间。
六、如何选择合适的排序算法?
选择排序算法需要考虑多个因素,没有绝对最好的,只有最适合特定场景的:
1.数据规模 (n):
- 很小 (n < 100): 简单排序(插入、冒泡、选择)效率差别不大,选择实现简单或稳定的(如插入)。
- 中等 (100 < n < 1000): 希尔排序、快速排序、归并排序、堆排序表现良好。插入排序对部分有序数据仍有竞争力。
- 很大 (n > 1000): 必须选择 O(n log n) 算法(快排、归并、堆排)或线性排序(如果条件满足)。快排通常是首选(平均性能好)。
2.数据初始状态:
- 基本有序: 插入排序、冒泡排序效率接近 O(n)。
- 完全随机: 快排、堆排、归并排序表现好。
- 部分有序: 适应性算法(如插入、希尔)可能更快。
3.稳定性要求:
- 需要稳定排序:归并排序、插入排序、冒泡排序、计数排序、基数排序。
- 不需要稳定排序:快排、堆排、选择排序、希尔排序。
4.空间限制:
- 内存紧张:选择原地排序(快排、堆排、插入、希尔、冒泡、选择)。
- 内存充足:归并排序、计数排序、桶排序、基数排序可以考虑。
5.关键码类型和范围:
- 如果是小范围整数:计数排序效率极高 (O(n+k))。
- 如果是整数、字符串且有固定长度:基数排序非常高效 (O(d*(n+k)))。
- 如果是浮点数且均匀分布:桶排序可能表现好。
- 通用类型:只能使用比较排序。
6.实现复杂度和维护性:
- 简单排序(冒泡、插入、选择)易于理解和实现。
- 快排、堆排、归并排序实现相对复杂,但标准库通常已优化实现。
七,排序用到的结构与函数
define MAXSIZE 10
typedef struct
{
int r[MAXSIZE+1];
int length;
}SqList;void swap(SqList *L,int i,int j)
{
int temp=L->r[i];
L->r[i]=L->r[j];
L->r[j]=temp;
}相关文章:
)
数据结构-排序(1)
一,排序的基本概念 1.排序的定义 核心概念: 给定一个包含 n 个元素的序列 (R1, R2, ..., Rn) 和一个关键码 Ki(通常是记录 Ri 的一个属性),排序的目标是找到一个排列 (p1, p2, ..., pn),使得关键码序列 (K…...
记录一次session安装应用recyclerview更新数据的bug
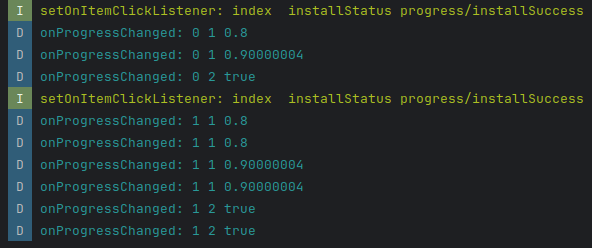
首先抛出异常日志,在 先说结论:因为session安装监听是在点击事件里面,所以会保留旧的对象数据 直接上代码,原有的逻辑是点击时执行session安装,并注册监听回调 private fun installApk(position: Int) {val packageIns…...
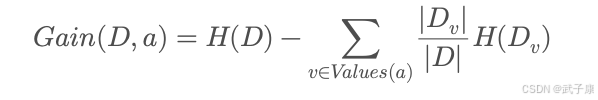
大数据-274 Spark MLib - 基础介绍 机器学习算法 剪枝 后剪枝 ID3 C4.5 CART
点一下关注吧!!!非常感谢!!持续更新!!! 大模型篇章已经开始! 目前已经更新到了第 22 篇:大语言模型 22 - MCP 自动操作 FigmaCursor 自动设计原型 Java篇开…...
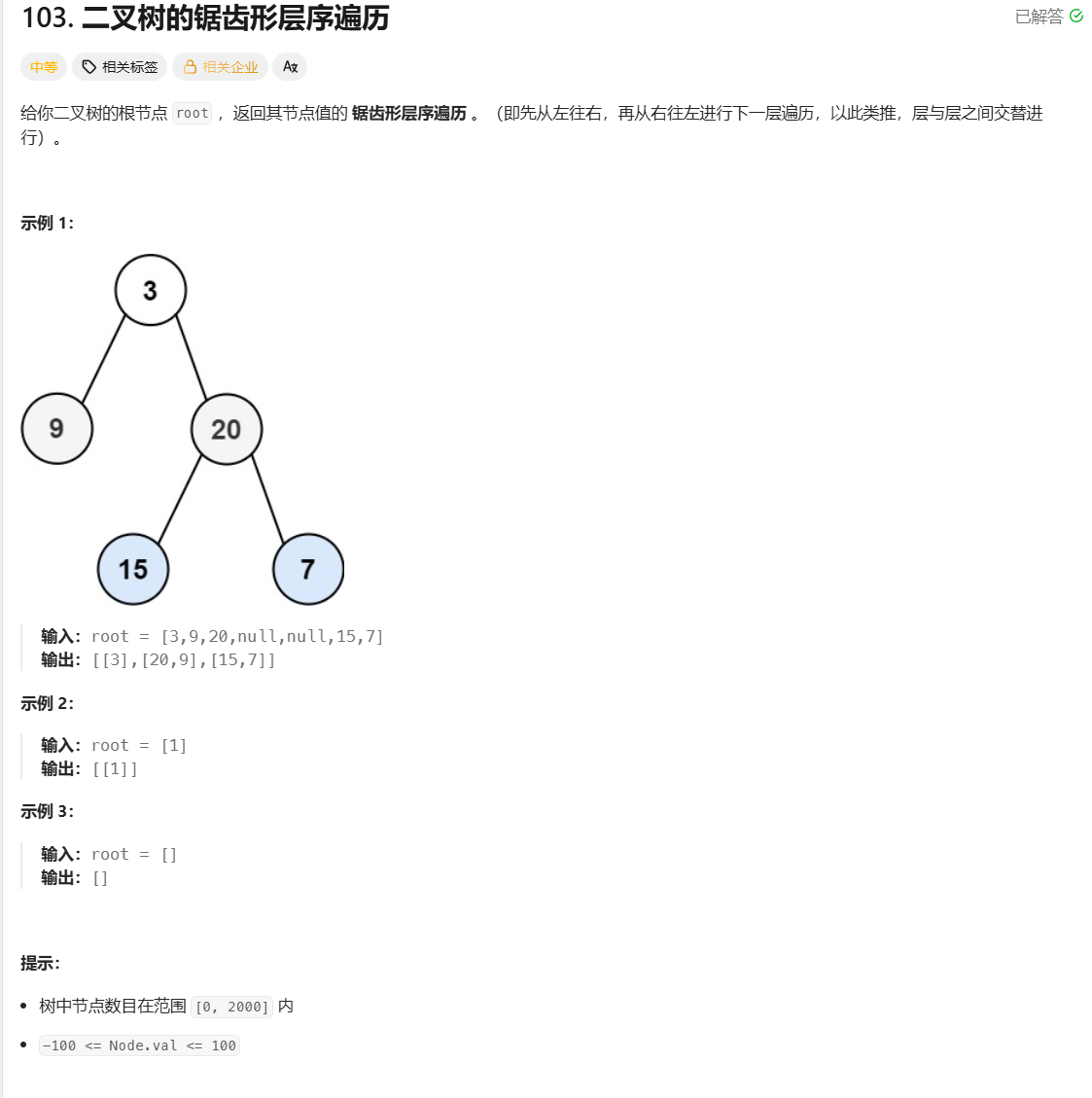
力扣面试150题--二叉树的锯齿形层序遍历
Day 56 题目描述 思路 锯齿形就是一层是从左向右,一层是从右向左,那么我们可以分析样例,对于第奇数层是从左向右,第偶数层是从右向左,于是可以采取一个计数器,采取链表方式,从左向右就是正常插…...

如何在 CentOS / RHEL 上修改 MySQL 默认数据目录 ?
MySQL 是一个广泛使用的开源关系数据库管理系统(RDBMS),为无数的 web 应用程序和服务提供支持。默认情况下,MySQL 将其数据存储在预定义的目录中,这可能并不总是适合您的需求。您可能希望将数据目录移动到另一个位置以获得更好的性能和安全性…...
)
网页前端开发(基础进阶2)
前面学习了html与css,接下来学习JS(JavaScript与Java无关)。 web标准(网页标准)分为3个部分: 1.html主要负责网页的结构(页面的元素和内容) 2.css主要负责网页的表现(…...

简历制作要精而不简
不得不说,不管是春招,还是秋招,我们在求职时,第一步便是制作一份简历。不得不承认,好的简历,就像一块敲门砖,能让面试官眼前一亮,让应聘成功的概率增添一分。 对于一个初次求职者来…...
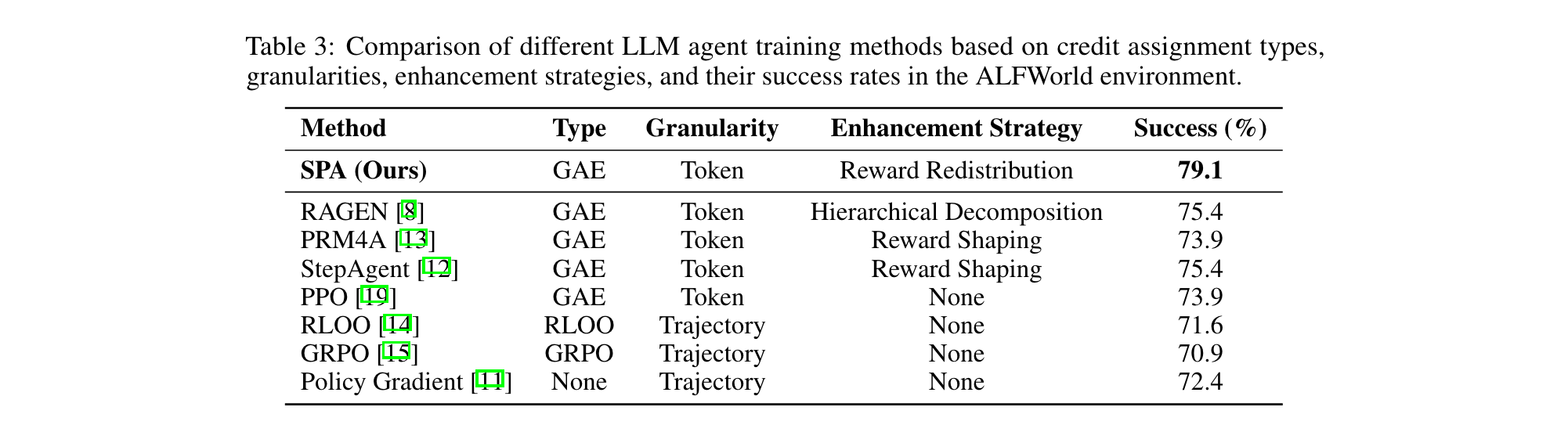
SPA-RL:通过Stepwise Progress Attribution训练LLM智能体
SPA-RL:通过Stepwise Progress Attribution训练LLM智能体 在大语言模型(LLM)驱动智能体发展的浪潮中,强化学习(RL)面临着延迟奖励这一关键挑战。本文提出的SPA-RL框架,通过创新的分步进度归因机…...

【深度学习】9. CNN性能提升-轻量化模型专辑:SqueezeNet / MobileNet / ShuffleNet / EfficientNet
SqueezeNet / MobileNet / ShuffleNet / EfficientNet 一、背景与动机 随着深度神经网络在图像识别任务上取得巨大成功,它们的结构越来越深、参数越来越多。然而在移动端或嵌入式设备中: 存储资源有限推理计算能力弱能耗受限 因此,研究者…...
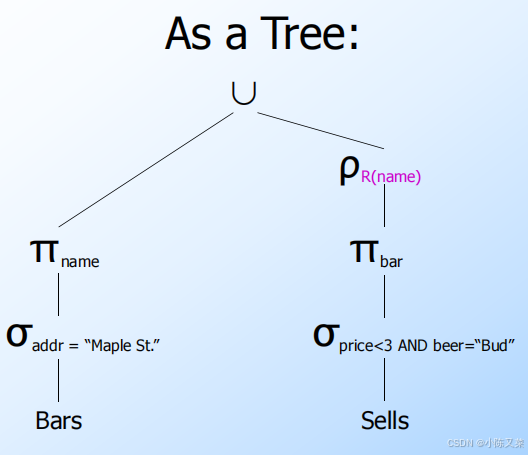
Relational Algebra(数据库关系代数)
目录 What is an “Algebra” What is Relational Algebra? Core Relational Algebra Selection Projection Extended Projection Product(笛卡尔积) Theta-Join Natural Join Renaming Building Complex Expressions Sequences of Assignm…...

【C/C++】面试常考题目
面试中最常考的数据结构与算法题,适合作为刷题的第一阶段重点。 ✅ 分类 & 推荐题目列表(精选 70 道核心题) 一、数组 & 字符串(共 15 题) 题目类型LeetCode编号两数之和哈希表#1盛最多水的容器双指针#11三数…...
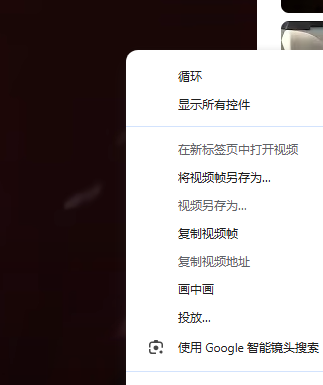
Chorme如何对于youtube视频进行画中画背景播放?
画中画可以让你小窗播放,然后浏览器放后台还可以做点别的事情。 B站直接可以选择小窗播放,游览器最小化就可以,但是youtube的小窗播放游览器一切换就不显示了。 其实是因为youtube的小窗播放不是真的小窗播放。要想真的实现需要在youtube视…...

017搜索之深度优先搜索——算法备赛
深度优先搜索 如果说广度优先搜索是逐层扩散,那深度优先搜索就是一条道走到黑。 深度优先遍历是用递归实现的,预定一条顺序规则(如上下左右顺序) ,一直往第一个方向搜索直到走到尽头或不满足要求后返回上一个叉路口按…...

从单机到集群,再到分布式,再到微服务
我会尽量详细讲解,从单机到集群,再到分布式和微服务每个层次的概念、特点和应用场景。同时也会探讨C是否适合做微服务项目。 一、从单机到集群,再到分布式,再到微服务——详细解析 1. 单机(Single Machine)…...

关于ios点击分享自动复制到粘贴板的问题
前言 Android 系统没有什么特别的要求,实现这个也比较容易。但ios在某些情况下就会出现问题。 如果ios是点击之后,请求接口,再把接口的内容赋值给粘贴板肯定行不通,会被ios系统拦截,导致赋值失败或者赋值为空。建议使…...

Hive的JOIN操作如何优化?
Hive的JOIN操作优化是提升查询性能的关键,尤其是在处理大数据量时。以下是详细的JOIN优化策略和实现方法: 一、MapJoin(小表广播优化) 核心原理 将小表全量加载到每个MapTask的内存中,避免Shuffle,直接在…...

React Native 实现抖音式图片滑动切换浏览组件-媲美抖音体验的滑动式流畅预览组件
写在前面 “如何让用户像刷抖音一样浏览我们的图片列表?” —— 这个需求背后隐藏着性能、体验和交互设计的多重挑战。本文将带你从零实现一个高性能的React Native图片浏览器,支持分页预加载、横向滑动预览、文字展示和缓存优化,打造媲美原…...

睿抗机器人开发者大赛CAIP-编程技能赛-历年真题 解题报告汇总 | 珂学家
前言 汇总 睿抗机器人开发者大赛CAIP-编程技能赛-历年真题 解题报告汇总 2024年 2024 睿抗机器人开发者大赛CAIP-编程技能赛-本科组 (国赛) 解题报告 2024 睿抗机器人开发者大赛CAIP-编程技能赛-本科组(省赛)解题报告 2024 睿抗机器人开发者大赛CAI…...

【c++】【数据结构】AVL树
目录 AVL树的定义AVL树的部分模拟实现平衡因子的引入平衡因子的向上调整旋转算法单旋算法右单旋左单旋 双旋算法左右双旋右左双旋 AVL树的定义 AVL树本质是一种搜索二叉树,传统的二叉搜索树我们都有所了解,其在理想情况下也就是接近满二叉树时拥有极高的…...

【原神 × 插入排序】刷圣遗物也讲算法:圣遗物评分系统背后的排序逻辑你真的懂吗?
📘 改编自:王争《数据结构与算法之美》 🎮 游戏演绎:米哈游《原神》 🧠 核心关键词:插入排序、排序算法、评分系统、属性评价、强化圣遗物、冒泡排序对比 🧭 引言:原神刷本=刷排序? 玩《原神》的玩家每天日常是啥?体力用来刷圣遗物、精通头、暴击头、攻充沙………...

ORB-SLAM2学习笔记:ExtractorNode::DivideNode和ORBextractor::DistributeOctTree函数详解
一、ExtractorNode::DivideNode void ExtractorNode::DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4) {const int halfX = ceil(static_cast<float>(UR.x-UL.x)/2);const int halfY = ceil(static_cast<f…...

nt!MmMapViewInSystemCache函数分析PointerPte的填充
第一部分: 1: kd> kc # 00 nt!MmMapViewInSystemCache 01 nt!CcGetVacbMiss 02 nt!CcGetVirtualAddress 03 nt!CcMapData 04 Ntfs!NtfsMapStream 05 Ntfs!NtfsReadBootSector 06 Ntfs!NtfsMountVolume 07 Ntfs!NtfsCommonFileSystemControl 08 Ntfs!NtfsFspDis…...
)
3D Tiles高级样式设置与条件渲染(3)
二、基于地理距离的条件渲染 1.根据与特定点的距离设置样式 在某些应用中,我们可能需要根据建筑物与某个特定点(如地标建筑)的距离来设置样式。以下代码示例展示了如何根据建筑物与广州塔的距离来设置颜色和可见性: tiles3d.styl…...
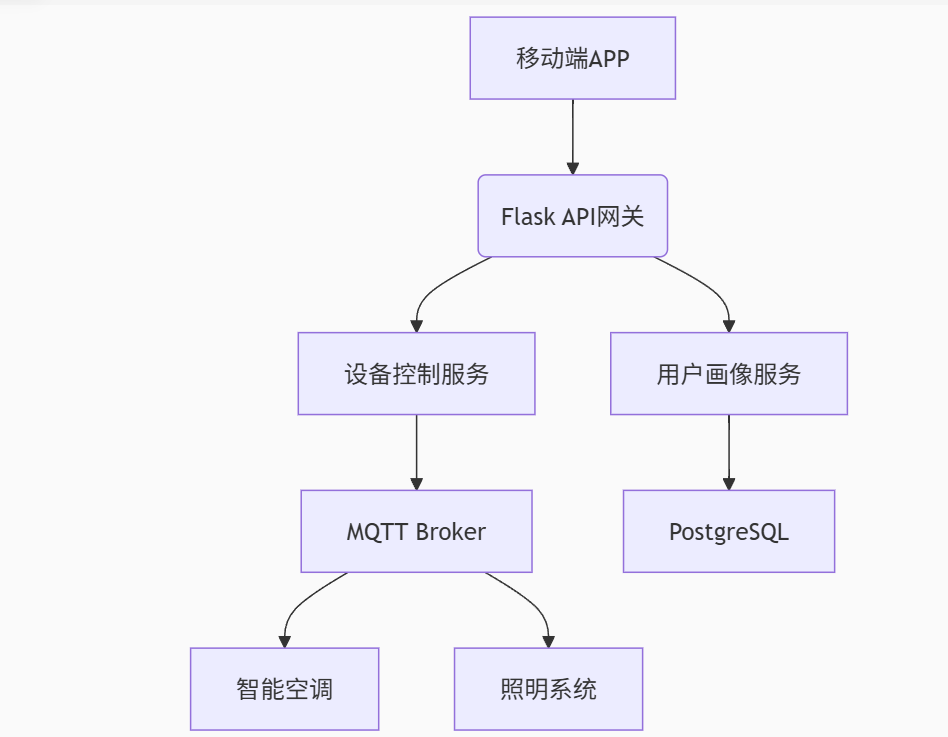
通义灵码深度实战测评:从零构建智能家居控制中枢,体验AI编程新范式
一、项目背景:零基础挑战全栈智能家居系统 目标:开发具备设备控制、环境感知、用户习惯学习的智能家居控制中枢(PythonFlaskMQTTReact) 挑战点: 需集成硬件通信(MQTT)、Web服务(Flask)、前端交互(React) 调用天气AP…...
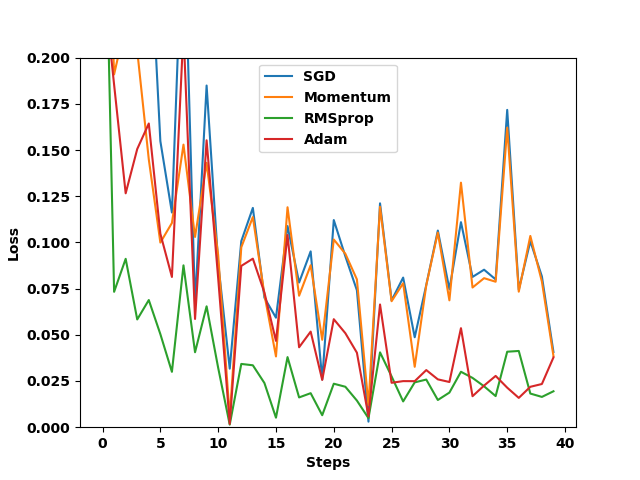
头歌之动手学人工智能-Pytorch 之优化
目录 第1关:如何使用optimizer 任务描述 编程要求 测试说明 真正的科学家应当是个幻想家;谁不是幻想家,谁就只能把自己称为实践家。 —— 巴尔扎克开始你的任务吧,祝你成功! 第2关:optim.SGD 任务描述…...

基于谷歌ADK的智能客服系统简介
Google的智能体开发工具包(Agent Development Kit,简称ADK)是一个开源的、以代码为中心的Python工具包,旨在帮助开发者更轻松、更灵活地构建、评估和部署复杂的人工智能智能体(AI Agent)。ADK 是一个灵活的…...

(一)视觉——工业相机(以海康威视为例)
一、工业相机介绍 工业相机是机器视觉系统中的一个关键组件,其最本质的功能就是将光信号转变成有序的电信号。选择合适的相机也是机器视觉系统设计中的重要环节,相机的选择不仅直接决定所采集到的图像分辨率、图像质量等,同时也与整个系统的运…...
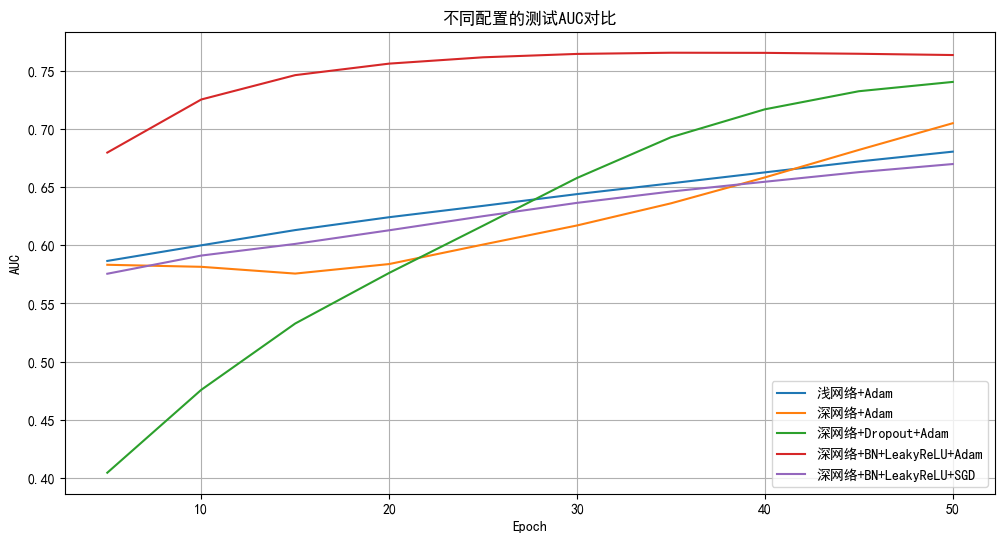
DAY 36 超大力王爱学Python
仔细回顾一下神经网络到目前的内容,没跟上进度的同学补一下进度。 作业:对之前的信贷项目,利用神经网络训练下,尝试用到目前的知识点让代码更加规范和美观。探索性作业(随意完成):尝试进入nn.Mo…...

基于React + TypeScript构建高度可定制的QR码生成器
前言 在现代Web应用中,QR码已成为连接线上线下的重要桥梁。本文将详细介绍如何使用React TypeScript Vite构建一个功能强大、高度可定制的QR码生成器,支持背景图片、文本叠加、HTML模块、圆角导出等高级功能。 前往试试 项目概述 技术栈 前端框架:…...

DeepSeek进阶教程:实时数据分析与自动化决策系统
进阶教程:实时数据分析与自动化决策系统 1. 实时数据流处理架构 class StreamProcessor:def __init__(self):self.window_size = 60 # 滑动窗口大小(秒)self.analytics_engine = AnalyticsEngine() # 复用之前的分析引擎def process_kafka_stream(self, topic):"&quo…...