NLP学习路线图(十九):GloVe
自然语言处理(NLP)的核心挑战在于让机器理解人类语言的丰富含义。词向量(Word Embeddings)技术通过将词语映射到高维实数空间,将离散的符号转化为连续的向量,为NLP任务奠定了坚实基础。在众多词向量模型中,GloVe(Global Vectors for Word Representation)以其独特的设计理念和优异的性能脱颖而出,成为NLP领域不可或缺的工具。
一、词向量:自然语言的数学之舞
1.1 从离散符号到连续空间
-
独热编码的困境: 传统方法使用独热编码表示词语(如“猫”=[0,0,1,0,...,0])。这种方法维度高、稀疏性强,无法表达词语间的任何语义或语法关系。
-
分布式假说: “一个词的含义由其周围的词决定”。词向量模型基于此假说,将语义相似的词映射到向量空间中相近的位置。
-
密集向量优势: 词向量(如“猫”=[0.25, -0.72, 0.83, ..., 0.05])是低维、密集的实数向量。向量间的距离(如余弦相似度)能有效度量词语相似度,并支持向量运算(如“国王 - 男人 + 女人 ≈ 女王”)。
1.2 词向量发展简史
-
神经语言模型(Bengio et al., 2003): 首次提出通过学习神经网络的参数来获取词向量。
-
Word2Vec(Mikolov et al., 2013): 里程碑式工作,包含Skip-gram和CBOW两种高效模型,通过预测上下文词或中心词来训练词向量。
-
GloVe(Pennington et al., 2014): 巧妙结合了全局统计信息(词共现矩阵)和局部上下文窗口训练的优点。
-
上下文相关词向量(ELMo, BERT, GPT): 后续模型(如ELMo, BERT, GPT)能根据词语所在的具体上下文生成动态词向量,性能远超静态词向量(如Word2Vec, GloVe),但GloVe因其简单高效和良好的基础性能,仍被广泛使用。
二、GloVe:全局与局部信息的优雅融合
GloVe的核心思想在于:词语的含义可以通过它们在语料库中与其它词的共现模式来捕捉,且共现概率的比值比概率本身更能区分语义特征。
2.1 共现矩阵:词语关系的全局快照
-
定义: 构建一个
|V| x |V|的矩阵X,其中X_{ij}表示在整个语料库中,词j出现在词i的上下文窗口内的总次数(|V|是词汇表大小)。 -
构建过程:
-
遍历语料库中的每个词(中心词
i)。 -
对于每个中心词,定义其左右一定距离(如5-10词)内的词为其上下文词
j。 -
统计每一对
(i, j)共现的次数,填入矩阵X。 -
通常会对距离较远的上下文词赋予较小的权重(如按
1/d衰减,d是词间距)。
-
-
示例: 考虑句子 “I enjoy playing football and tennis.” (窗口大小=2)
-
X_{enjoy, playing} += 1 -
X_{enjoy, I} += 1/1(距离为1) -
X_{enjoy, football} += 1/1 -
X_{enjoy, and} += 1/2(距离为2) -
X_{playing, enjoy} += 1/1 -
X_{playing, football} += 1/1 -
X_{playing, I} += 1/2 -
X_{playing, and} += 1/1 -
... (以此类推)
-
2.2 GloVe的精髓:共现概率比值的启示
-
关键观察: 假设我们想区分“冰”和“蒸汽”。考虑它们与某些探测词(如“固体”、“气体”、“水”、“时尚”)的共现概率:
-
P(solid|ice)高,P(solid|steam)低 -> 比值P(solid|ice)/P(solid|steam)很大。 -
P(gas|ice)低,P(gas|steam)高 -> 比值P(gas|ice)/P(gas|steam)很小。 -
P(water|ice)和P(water|steam)都比较高 -> 比值 接近1。 -
P(fashion|ice)和P(fashion|steam)都很低 -> 比值 接近1。
-
-
核心洞见: 共现概率的比值
P(k|i)/P(k|j)能够明确地区分相关词(如k=solid, gas)和不相关词(如k=water, fashion),并能区分i和j的不同语义特征(如冰是固体,蒸汽是气体)。 -
GloVe的目标: 词向量的学习目标应该使得词向量之间的点积能够很好地表达共现概率的对数比值。
2.3 GloVe的目标函数:数学之美
基于上述洞见,GloVe模型希望找到词向量 w_i, w_j 和上下文向量 \tilde{w}_k,使得以下关系尽可能成立:
w_i^T \tilde{w}_k + b_i + \tilde{b}_k \approx log(X_{ik})其中:
-
w_i是词i作为中心词时的向量。 -
\tilde{w}_k是词k作为上下文词时的向量(GloVe最终通常使用w_i + \tilde{w}_i作为词i的最终向量)。 -
b_i和\tilde{b}_k是偏置项。 -
log(X_{ik})是词i和词k共现次数的对数。
目标函数(损失函数)J:
J = \sum_{i, j=1}^{|V|} f(X_{ij}) (w_i^T \tilde{w}_j + b_i + \tilde{b}_j - log(X_{ij}))^2-
核心部分:
(w_i^T \tilde{w}_j + b_i + \tilde{b}_j - log(X_{ij}))^2衡量模型预测值w_i^T \tilde{w}_j + b_i + \tilde{b}_j与目标值log(X_{ij})的平方误差。 -
权重函数
f(X_{ij}): GloVe设计的关键创新点!-
作用:
-
避免罕见词噪声:
X_{ij}=0时(词i和j从不共现),log(X_{ij})无定义且无意义。f(0)=0使得这些项不参与计算。 -
平衡高频低频词贡献: 高频词组合(如 “the”, “and”)携带的语义信息通常少于中低频但有意义的组合(如 “ice”, “solid”)。
f(X)应该给高频词组合赋予相对较低的权重,给中低频有意义的组合赋予较高权重。 -
防止权重过大: 对非常高频的词组合,权重也不应无限增长。
-
-
GloVe的 f(x) 定义:
f(x) = \begin{cases}
(x / x_{max})^{\alpha} & \text{if } x < x_{max} \\
1 & \text{otherwise}
\end{cases}-
x_{max}:一个截断阈值(通常设为100)。 -
α:一个经验指数(通常设为3/4)。 -
特性:
-
x=0时,f(x)=0。 -
x < x_{max}时,f(x)随x增长而增长,但呈次线性关系 (x^{3/4}),抑制了高频词组合的权重。 -
x >= x_{max}时,f(x)=1,避免权重过大。
-
-
效果: 这个函数确保了模型主要关注那些频繁共现且具有实际语义信息的词对,有效平衡了数据量和信息密度。
2.4 训练过程:优化目标
-
初始化: 随机初始化所有词向量
w_i,\tilde{w}_j和偏置项b_i,\tilde{b}_j。 -
随机梯度下降(SGD): 这是优化
J的主要方法。
- 每次迭代中,随机采样一个非零的共现计数
X_{ij}(及其对应的词对(i, j))。 - 计算损失函数
J对于当前样本的梯度∇J(w_i, \tilde{w}_j, b_i, \tilde{b}_j)。 - 根据梯度和学习率
η更新参数:
w_i \leftarrow w_i - \eta \cdot \frac{\partial J}{\partial w_i}
\tilde{w}_j \leftarrow \tilde{w}_j - \eta \cdot \frac{\partial J}{\partial \tilde{w}_j}
b_i \leftarrow b_i - \eta \cdot \frac{\partial J}{\partial b_i}
\tilde{b}_j \leftarrow \tilde{b}_j - \eta \cdot \frac{\partial J}{\partial \tilde{b}_j}-
迭代: 重复步骤2直到损失函数收敛或达到预设的迭代次数。
-
最终词向量: 训练完成后,通常将中心词向量和上下文词向量相加作为每个词的最终表示:
w_i^{final} = w_i + \tilde{w}_i。实践表明这能稳定并略微提升性能。
三、GloVe vs. Word2Vec:理念与实践的碰撞
| 特征 | GloVe | Word2Vec (Skip-gram) |
|---|---|---|
| 训练基础 | 全局词共现矩阵 (统计整个语料库) | 局部上下文窗口 (逐句逐词预测) |
| 目标 | 最小化共现计数对数的预测误差 | 最大化上下文词出现的概率 (softmax或负采样) |
| 信息利用 | 显式利用全局统计信息 | 通过多次采样窗口隐式学习统计信息 |
| 训练效率 | 通常更快:矩阵操作高效,易于并行 | 相对慢:需要大量窗口采样和预测 |
| 罕见词 | 处理较好:权重函数 f(x) 降低高频词影响 | 依赖负采样技巧,罕见词学习可能不充分 |
| 向量运算 | 相似度高,都支持类比任务 (king-man+woman≈queen) | 相似度高 |
| 实现 | 需构建/存储(可能很大的)共现矩阵 | 直接处理原始文本流,内存占用可能更友好 |
总结区别:
-
GloVe 像位严谨的统计学家: 它先对整个语料库进行详尽的“人口普查”(构建共现矩阵),然后从中提炼出词语关系的精确数学模型(优化目标函数)。这种方法系统性强,能高效利用全局统计规律。
-
Word2Vec 像位敏锐的观察者: 它不关心整体数据,而是聚焦于一个个具体的语言实例(局部窗口),通过无数次观察局部上下文来归纳词语的用法。这种方法更灵活,直接面向预测任务。
四、动手实践:Python实现简易版GloVe
以下是一个使用PyTorch实现简化版GloVe核心训练过程的代码示例(省略了共现矩阵构建等预处理细节):
import torch
import torch.nn as nn
import torch.optim as optimclass GloVeModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(GloVeModel, self).__init__()# 中心词嵌入和偏置self.w_i = nn.Embedding(vocab_size, embedding_dim)self.b_i = nn.Embedding(vocab_size, 1)# 上下文词嵌入和偏置self.w_j = nn.Embedding(vocab_size, embedding_dim)self.b_j = nn.Embedding(vocab_size, 1)# 初始化self.w_i.weight.data.uniform_(-0.5, 0.5)self.w_j.weight.data.uniform_(-0.5, 0.5)self.b_i.weight.data.zero_()self.b_j.weight.data.zero_()def forward(self, i_idx, j_idx):"""计算中心词i和上下文词j的组合输出"""w_i = self.w_i(i_idx) # [batch_size, emb_dim]b_i = self.b_i(i_idx).squeeze(1) # [batch_size]w_j = self.w_j(j_idx) # [batch_size, emb_dim]b_j = self.b_j(j_idx).squeeze(1) # [batch_size]# 计算点积 + 偏置 (近似 log(X_ij))return torch.sum(w_i * w_j, dim=1) + b_i + b_j # [batch_size]def weight_func(x, x_max=100.0, alpha=0.75):"""计算GloVe权重函数f(x)"""wx = (x / x_max) ** alphawx = torch.min(wx, torch.ones_like(wx)) # min(wx, 1)return wxdef train_glove(cooccurrences, vocab_size, embedding_dim=100, lr=0.05, x_max=100.0, alpha=0.75, epochs=50):"""cooccurrences: 列表,元素为元组 (i_index, j_index, X_ij)"""model = GloVeModel(vocab_size, embedding_dim)optimizer = optim.Adam(model.parameters(), lr=lr)for epoch in range(epochs):total_loss = 0.0# 随机打乱共现对torch.manual_seed(epoch) # 可重现indices = torch.randperm(len(cooccurrences))for idx in indices:i_idx, j_idx, X_ij = cooccurrences[idx]# 将索引转换为Tensori_idx = torch.tensor([i_idx], dtype=torch.long)j_idx = torch.tensor([j_idx], dtype=torch.long)X_ij_tensor = torch.tensor([X_ij], dtype=torch.float)# 前向传播:模型预测值model_output = model(i_idx, j_idx)# 目标值:log(X_ij)target = torch.log(X_ij_tensor)# 计算加权损失weight = weight_func(X_ij_tensor, x_max, alpha)loss = weight * (model_output - target) ** 2# 反向传播与优化optimizer.zero_grad()loss.backward()optimizer.step()total_loss += loss.item()print(f"Epoch {epoch+1}/{epochs}, Loss: {total_loss / len(cooccurrences):.4f}")# 获取最终词向量 (w_i + w_j)embeddings = model.w_i.weight.data + model.w_j.weight.datareturn embeddings.numpy() # 转换为Numpy数组方便使用# 假设我们有一个小的词汇表 (size=5) 和一些共现数据
vocab = {"apple": 0, "banana": 1, "fruit": 2, "eat": 3, "ripe": 4}
vocab_size = len(vocab)
# 示例共现数据: [(中心词索引, 上下文词索引, 共现次数X_ij)]
cooccurrences = [(0, 2, 15.0), (2, 0, 15.0), # apple - fruit(1, 2, 12.0), (2, 1, 12.0), # banana - fruit(0, 3, 8.0), (3, 0, 8.0), # apple - eat(1, 3, 7.0), (3, 1, 7.0), # banana - eat(0, 4, 5.0), (4, 0, 5.0), # apple - ripe(1, 4, 6.0), (4, 1, 6.0), # banana - ripe(2, 3, 10.0), (3, 2, 10.0), # fruit - eat(2, 4, 4.0), (4, 2, 4.0) # fruit - ripe
]# 训练模型
embeddings = train_glove(cooccurrences, vocab_size, embedding_dim=10, epochs=100)# 查看结果 (例如,"apple"和"banana"的向量应该比较接近"fruit")
print("Apple vector:", embeddings[0])
print("Banana vector:", embeddings[1])
print("Fruit vector:", embeddings[2])实际应用建议:
-
使用成熟库: 在实际项目中,强烈推荐使用
gensim库 (gensim.models.word2vec支持训练,gensim.downloader提供预训练模型) 或官方 GloVe 实现,它们经过了高度优化,支持大规模语料库训练。 -
预训练模型: 直接下载官方或社区提供的基于维基百科、Common Crawl 等海量语料训练好的 GloVe 词向量 (如
glove.6B.300d.txt包含 40 万词,300 维向量) 是最高效的方式。from gensim.models import KeyedVectors # 下载地址: https://nlp.stanford.edu/projects/glove/ glove_model = KeyedVectors.load_word2vec_format('glove.6B.300d.txt', binary=False, no_header=True) print(glove_model.most_similar('king', topn=5)) # [('queen', 0.7698541283607483), ('prince', 0.684330940246582), ...] result = glove_model.most_similar(positive=['woman', 'king'], negative=['man'], topn=1) print(result[0][0]) # 应该输出 'queen' 或类似词
五、GloVe的应用场景与局限性
应用场景:
-
文本表示基础: 作为下游NLP任务(文本分类、情感分析、命名实体识别、机器翻译)的输入特征。
-
词义相似度/相关度计算: 计算词向量间的余弦相似度,评估词语相似度或寻找近义词。
-
词语类比推理: 解决 “king is to queen as man is to ?” 这类问题。
-
初始化更复杂模型: 为RNN、LSTM、Transformer等模型提供更好的词嵌入初始化起点,加速训练并提升最终性能(尤其在数据有限时)。
-
信息检索与推荐: 计算查询词与文档词的语义相似度,提升搜索和推荐的相关性。
局限性:
-
静态表示: GloVe为每个词生成一个固定的向量,无法处理一词多义(Polysemy)。例如,“bank” (河岸/银行) 在不同上下文中含义不同,但GloVe只能提供一个折中的向量。
-
无法处理新词(OOV): 模型训练完成后,词汇表即固定。遇到未登录词(Out-Of-Vocabulary, OOV)时,只能使用特殊标记(如
<UNK>)或简单启发式方法(如字符级嵌入),效果不佳。 -
依赖共现统计: 模型效果严重依赖于训练语料库的质量、规模和领域适应性。在特定领域(如医疗、法律)应用时,使用通用语料库训练的GloVe效果可能不好,需要领域语料微调或重新训练。
-
上下文无关: 与Word2Vec一样,GloVe缺乏捕捉复杂上下文信息的能力。后续的上下文相关模型(ELMo, BERT)在这方面有质的飞跃。
六、总结:GloVe的遗产与启示
GloVe模型是词向量发展史上的重要里程碑。它通过全局共现矩阵与局部上下文预测思想的巧妙结合,以及对共现概率比值这一关键洞见的数学建模,实现了高效且效果优异的词向量训练。其设计的加权损失函数 f(X_{ij}) 是平衡数据利用的关键创新。
虽然以BERT、GPT为代表的上下文相关预训练语言模型已成为当前NLP的主流,它们能生成动态的、包含丰富上下文信息的词表示,性能远超静态词向量模型,但GloVe并未过时:
-
轻量高效: GloVe模型相对小巧,训练和推理速度快,资源消耗低。在许多对计算资源敏感或不需要复杂上下文建模的场景(如快速构建基线系统、小型应用)中,GloVe仍是实用选择。
-
理论基础清晰: GloVe基于明确的统计动机(共现概率比值)设计,其数学形式和优化目标清晰易懂,为理解词向量学习提供了宝贵的理论视角。
-
优秀的基线: GloVe生成的词向量作为下游任务的输入特征或初始化向量,依然能提供强有力的基线性能。
-
教育价值: 理解GloVe的原理是深入掌握词嵌入技术和现代NLP模型的重要基石。
相关文章:
NLP学习路线图(十九):GloVe
自然语言处理(NLP)的核心挑战在于让机器理解人类语言的丰富含义。词向量(Word Embeddings)技术通过将词语映射到高维实数空间,将离散的符号转化为连续的向量,为NLP任务奠定了坚实基础。在众多词向量模型中&…...
如何使用DAXStudio将PowerBI与Excel连接
如何使用DAXStudio将PowerBI与Excel连接 之前分享过一篇自动化文章:PowerBI链接EXCEL实现自动化报表,使用一个EXCEL宏工作薄将PowerBI与EXCEL连接起来,今天分享另一个方法:使用DAX Studio将PowerBI与EXCEL连接。 下面是使用DAX S…...

软考 系统架构设计师系列知识点之杂项集萃(79)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(78) 第141题 软件测试一般分为两个大类:动态测试和静态测试。前者通过运行程序发现错误,包括()等方法;后者采用人工和计算机…...
)
神经网络基础:从单个神经元到多层网络(superior哥AI系列第3期)
🧠 神经网络基础:从单个神经元到多层网络(superior哥AI系列第3期) 哈喽!各位AI探索者们!👋 上期我们把数学"怪兽"给驯服了,是不是感觉还挺轻松的?今天我们要进…...

UVa12298 Super Joker II
UVa12298 Super Joker II 题目链接题意输入格式输出格式 分析AC 代码 题目链接 UVa12298 Super Joker II 题意 有一副超级扑克,包含无数张牌。对于每个正合数p,恰好有4张牌:黑桃p,红桃p,梅花p和方块p(分别…...

面向对象系统中对象交互的架构设计哲学
更多精彩请访问:通义灵码2.5——基于编程智能体开发Wiki多功能搜索引擎-CSDN博客 一、对象交互的本质与设计矛盾 在面向对象范式(OOP)中,对象间的交互实质上是软件组件解耦与功能复用的动态平衡过程。每个对象作为独立的计算单元,既需要维护…...
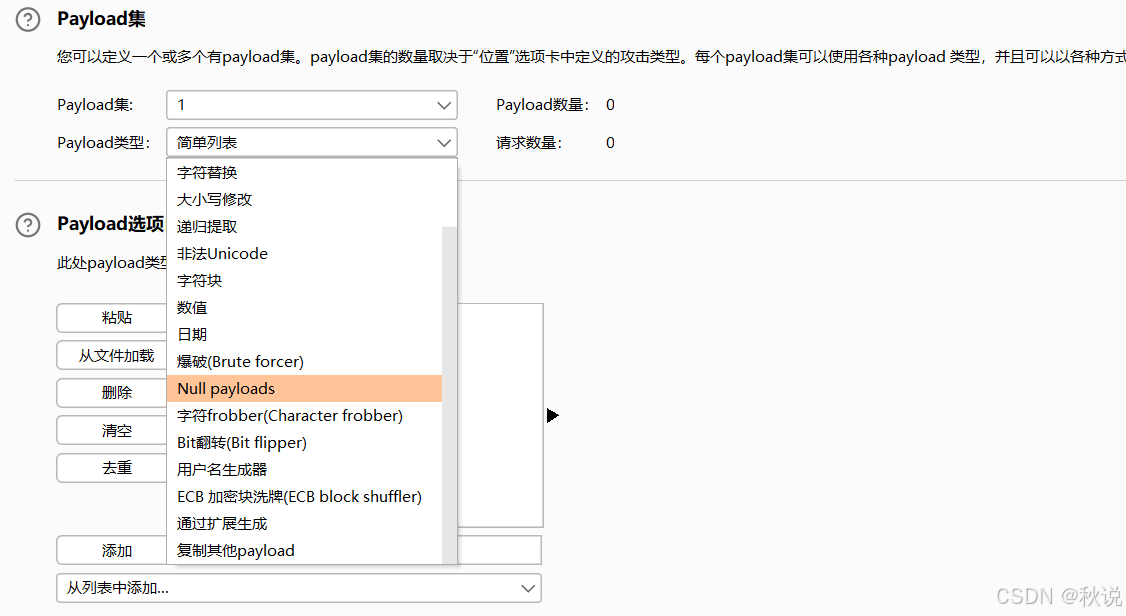
【网络安全】SRC漏洞挖掘思路/手法分享
文章目录 Tip1Tip2Tip3Tip4Tip5Tip6Tip7Tip8Tip9Tip10Tip11Tip12Tip13Tip14Tip15Tip16Tip17Tip18Tip19Tip20Tip21Tip22Tip23Tip24Tip25Tip26Tip27Tip28Tip29Tip30Tip1 “复制该主机所有 URL”:包含该主机上的所有接口等资源。 “复制此主机里的链接”:包括该主机加载的第三…...

【AFW+GRU(CNN+RNN)】Deepfakes Detection with Automatic Face Weighting
文章目录 Deepfakes Detection with Automatic Face Weighting背景pointsDeepfake检测挑战数据集方法人脸检测面部特征提取自动人脸加权门控循环单元训练流程提升网络测试时间增强实验结果Deepfakes Detection with Automatic Face Weighting 会议/期刊:CVPRW 2020 作者: …...

【面试】音视频面试
C内存模型 H.265(HEVC)相比H.264(AVC)的核心优势 1. 压缩效率显著提升 在相同画质下,H.265的码率比H.264降低约40-50%,尤其适用于4K/8K超高清场景。通过**更大的编码单元(CTU,最大…...

性能优化 - 案例篇:缓冲区
文章目录 Pre1. 引言2. 缓冲概念与类比3. Java I/O 中的缓冲实现3.1 FileReader vs BufferedReader:装饰者模式设计3.2 BufferedInputStream 源码剖析3.2.1 缓冲区大小的权衡与默认值 4. 异步日志中的缓冲:Logback 异步日志原理与配置要点4.1 Logback 异…...

Java编程之建造者模式
建造者模式(Builder Pattern)是一种创建型设计模式,它将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。这种模式允许你分步骤构建一个复杂对象,并且可以在构建过程中进行不同的配置。 模式的核…...

基于TI DSP控制的光伏逆变器最大功率跟踪mppt
基于TI DSP(如TMS320F28335)控制的光伏逆变器最大功率跟踪(MPPT)程序通常涉及以下几个关键部分:硬件电路设计、MPPT算法实现、以及DSP的编程。以下是基于TI DSP的光伏逆变器MPPT程序的一个示例,主要采用扰动…...

Python玩转自动驾驶仿真数据生成:打造你的智能“路测场”
Python玩转自动驾驶仿真数据生成:打造你的智能“路测场” 说到自动驾驶,很多人第一时间想到的是那些造车新势力、激光雷达、传感器、深度学习模型……确实,这些都是自动驾驶的核心硬核。但我今天想和你聊聊一个“幕后功臣”——仿真数据生成。没错,自动驾驶离不开大数据,更…...

从测试角度看待CI/CD,敏捷开发
什么是敏捷开发? 是在高强度反馈的情况下,短周期,不断的迭代产品,满足用户需求,抢占更多的市场 敏捷开发是什么? 是一种产品快速迭代的情况下,降低出错的概率,具体会落实到公司的…...

agent mode 代理模式,整体要求,系统要求, 系统指令
1. 起因, 目的: 我发现很多时候,我在重复我的要求。很烦。决定把一些过程记录下来,提取一下。 2. 先看效果 无。 3. 过程: 要求: 这2个文件,是我与 AI 聊天的一些过程记录。 请阅读这2个文件,帮我提取出一些共同…...
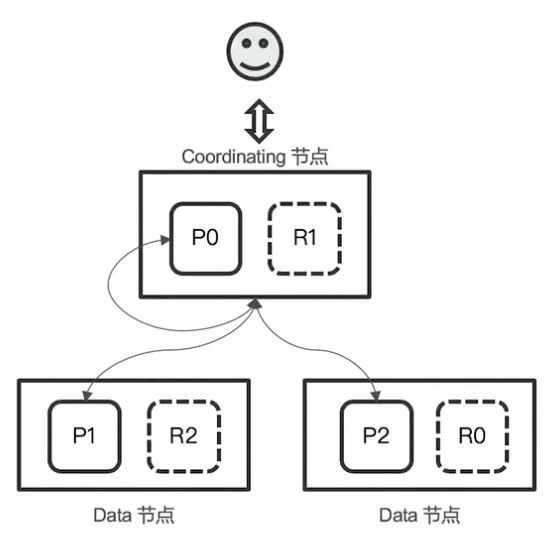
ES101系列07 | 分布式系统和分页
本篇文章主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时还会提到分页遍历和深度遍历问题的解决方案。 节点 节点是一个 ElasticSearch 示例 其本质就是一个 Java 进程一个机器上可以运行多个示例但生产环境推荐只运行一个…...
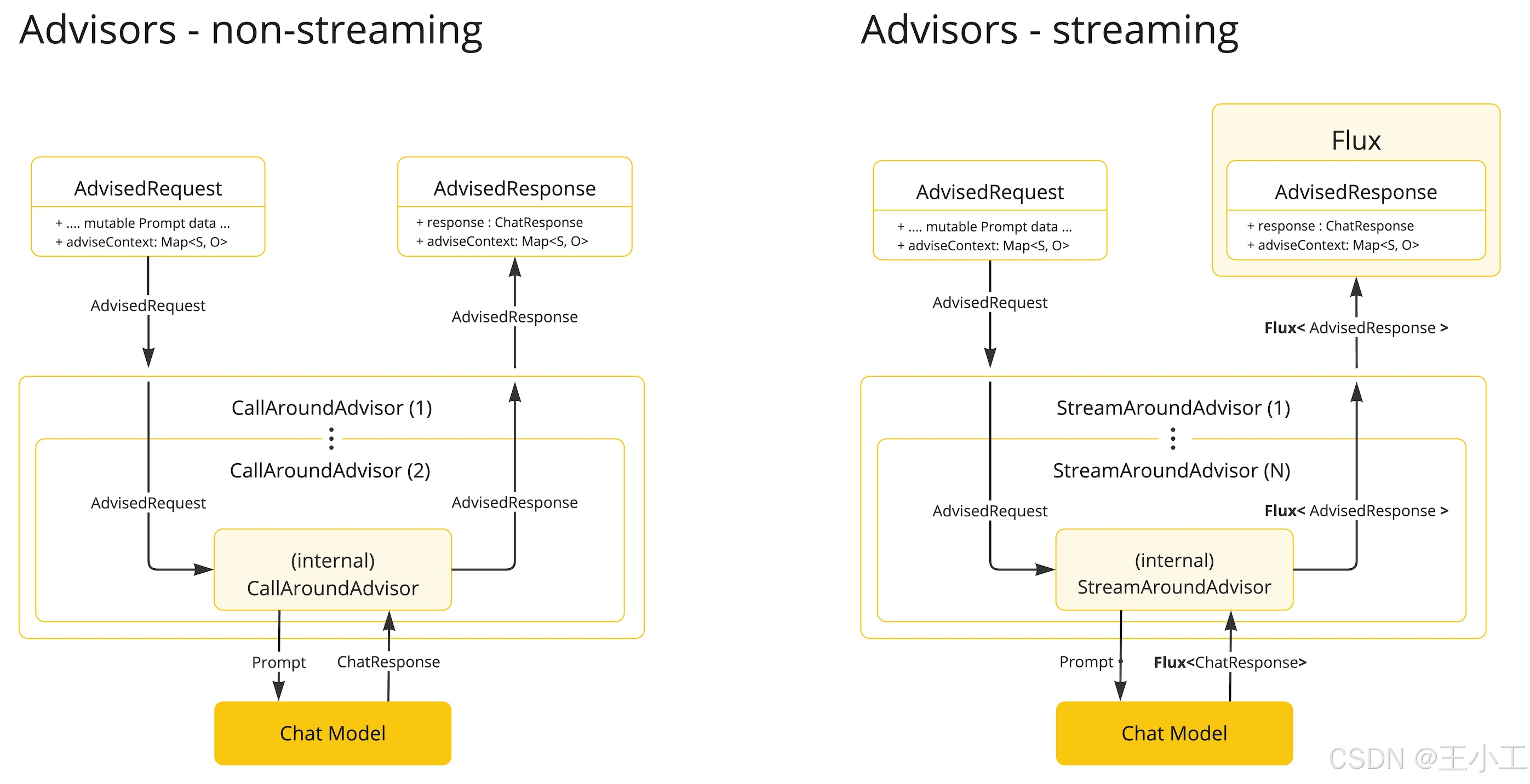
Spring AI Advisor机制
Spring AI Advisors 是 Spring AI 框架中用于拦截和增强 AI 交互的核心组件,其设计灵感类似于 WebFilter,通过链式调用实现对请求和响应的处理5。以下是关键特性与实现细节: 核心功能 1. 请求/响应拦截 通过 AroundAdvisor 接口动态修…...
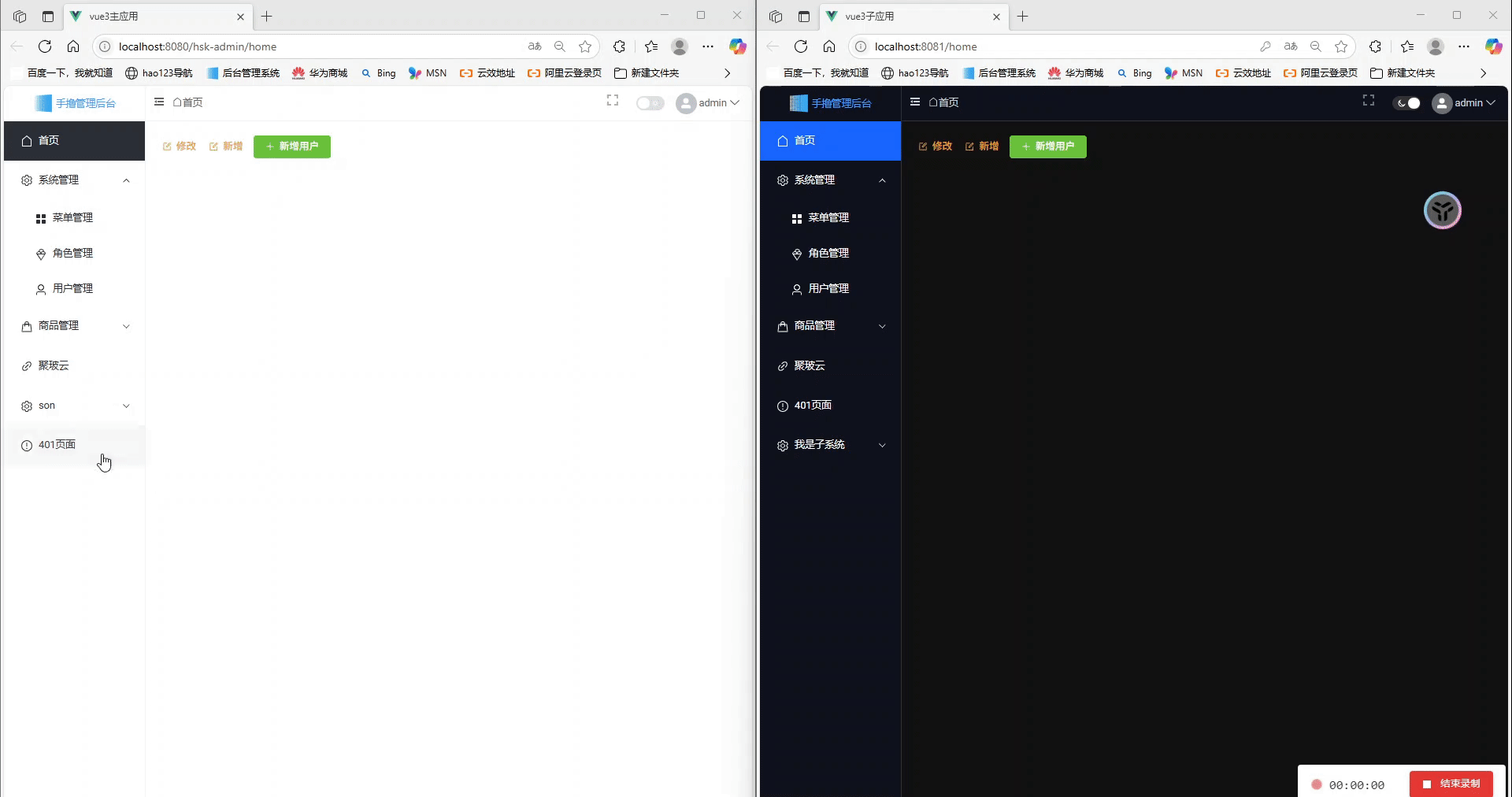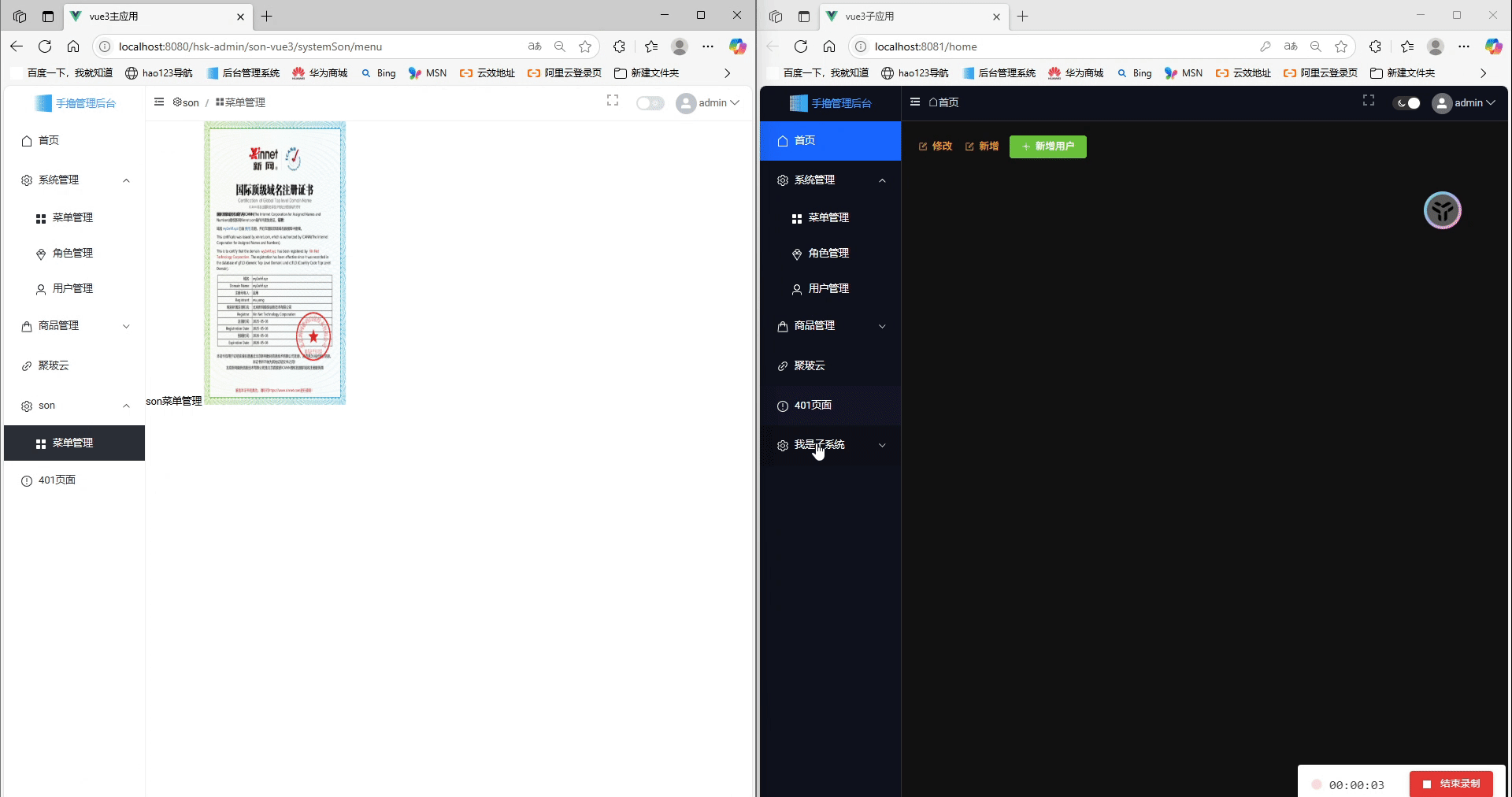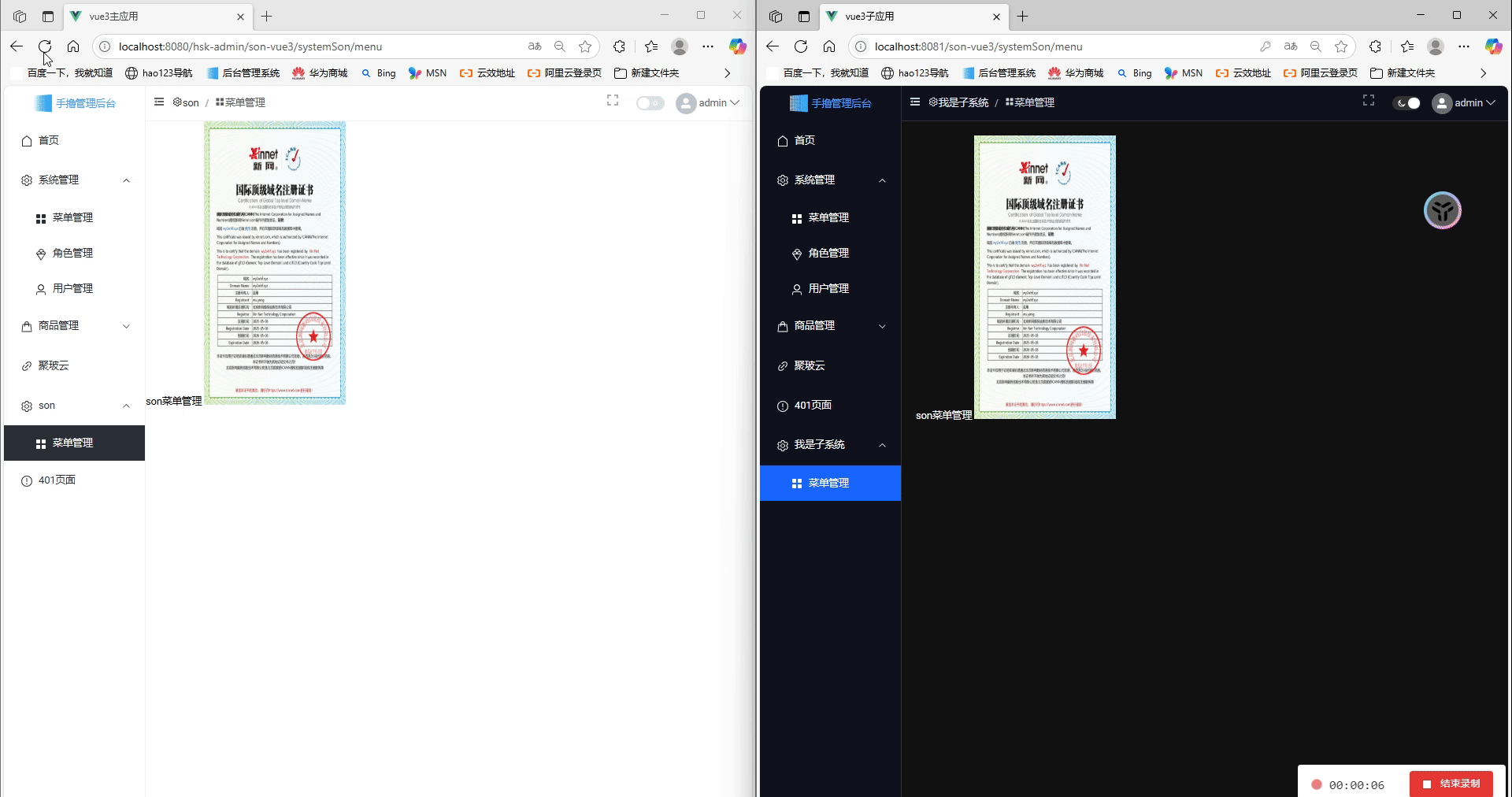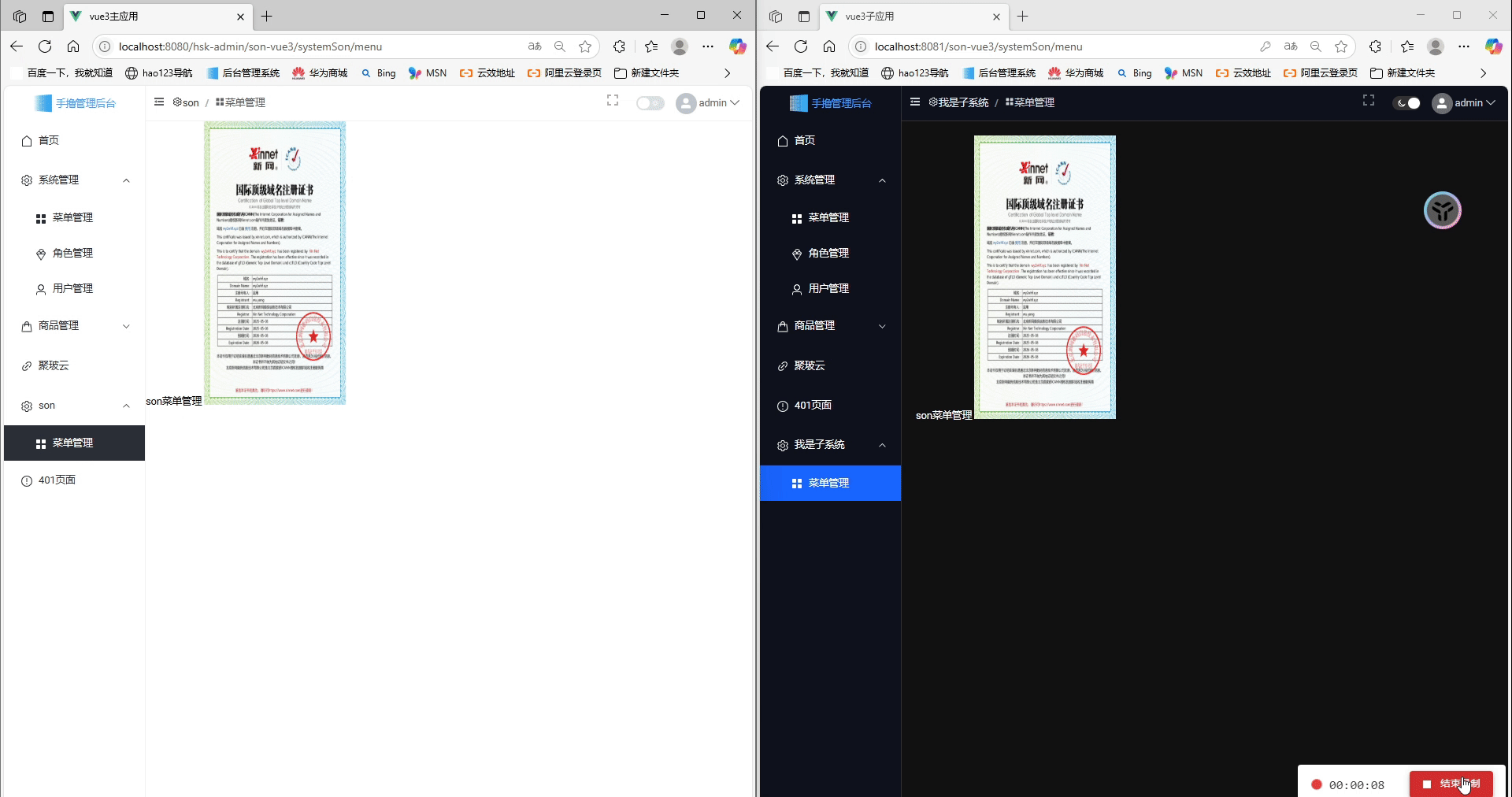
Vue3 + Vite:我的 Qiankun 微前端主子应用实践指南
前言 实践文章指南 vue微前端qiankun框架学习到项目实战,基座登录动态菜单及权限控制>>>>实战指南:Vue 2基座 Vue 3 Vite TypeScript微前端架构实现动态菜单与登录共享>>>>构建安全的Vue前后端分离架构:利用长Token与短Tok…...

使用ArcPy生成地图系列
设置地图布局 在生成地图系列之前,需要先设置地图布局。这包括定义地图的页面大小、地图框的位置和大小、标题、图例等元素。ArcPy提供了arcpy.mp.ArcGISProject方法来加载ArcGIS Pro项目文件(.aprx),并操作其中的地图布局。 Py…...
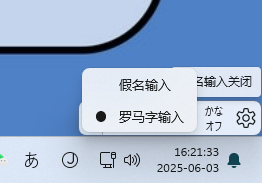
日语输入法怎么使用罗马字布局怎么安装日语输入法
今天帮客户安装日语输入法的时候遇到了一个纠结半天的问题,客户一直反馈说这个输入法不对,并不是他要的功能。他只需要罗马字的布局,而不是打出来字的假名。 片假名、平假名,就好像英文26个字母,用于组成日文单词。两…...

U盘挂载Linux
在 只能使用 Telnet 的情况下,如果希望通过 U盘 传输文件到 Linux 系统,可以按照以下步骤操作: 📌 前提条件 U盘已插入 Linux 主机的 USB 接口。Linux 主机支持自动挂载 U盘(大多数现代发行版默认支持)。T…...

数据结构:栈(Stack)和堆(Heap)
目录 内存(Memory)基础 程序是如何利用主存的? 🎯 静态内存分配 vs 动态内存分配 栈(stack) 程序执行过程与栈帧变化 堆(Heap) 程序运行时的主存布局 内存(Memo…...

用 Vue 做一个轻量离线的“待办清单 + 情绪打卡”小工具
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

3D Gaussian splatting 05: 代码阅读-训练整体流程
目录 3D Gaussian splatting 01: 环境搭建3D Gaussian splatting 02: 快速评估3D Gaussian splatting 03: 用户数据训练和结果查看3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云3D Gaussian splatting 05: 代码阅读-训练整体流程3D Gaussian splatting 06: 代码…...

Linux——计算机网络基础
一、网络 1.概念 由若干结点和连接结点的链路组成。结点可以是计算机,交换机,路由器等。 2.互联网 多个网络连接起来就是互联网。 因特网:最大的互联网。 二、IP地址和MAC地址 1.IP地址 (1)概念 IP地址是给因…...

第2章_Excel_知识点笔记
来自: 第2章_Excel_知识点笔记 原笔记 Excel 知识点总结(第2章) Excel_2.1 知识点 基础操作 状态栏:快速查看计数/求和等数据(右键可配置)。筛选(CtrlShiftL):按条件显…...

缩量和放量指的是什么?
在股票市场中,“缩量”和“放量”是描述成交量变化的两个核心概念,它们反映了市场参与者的情绪和资金动向,对判断股价趋势有重要参考价值。以下是具体解析: 📉 一、缩量(成交量明显减少) 1. 定…...
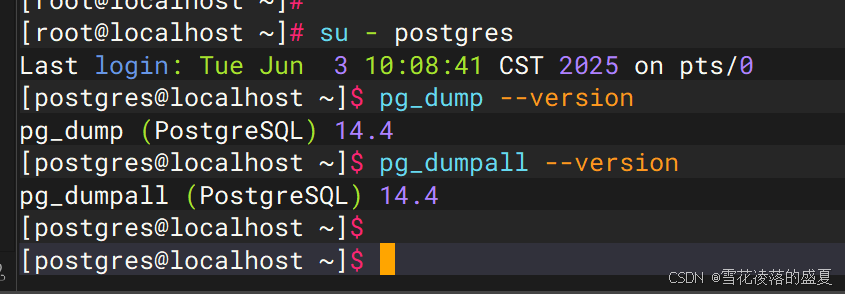
PostgreSQL数据库备份
文章目录 pg_dump 和 pg_dumpall使用 pg_dump 备份单个数据库示例 使用 pg_dumpall 备份整个数据库集群基本用法 恢复备份恢复 pg_dump 备份恢复 pg_dumpall 备份 Tips pg_dump 和 pg_dumpall 在 PostgreSQL 中,pg_dump 和 pg_dumpall 是两个常用的备份工具&#x…...

企业级Spring MVC高级主题与实用技术讲解
企业级Spring MVC高级主题与实用技术讲解 本手册旨在为具备Spring MVC基础的初学者,系统地讲解企业级应用开发中常用的高级主题和实用技术,涵盖RESTful API、统一异常处理、拦截器、文件处理、国际化、前端集成及Spring Security基础。内容结合JavaConf…...
js-day7
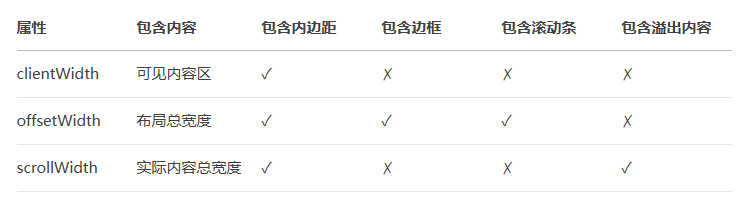
JS学习之旅-day7 1.事件流1.1 事件流与两个阶段说明1.2 事件捕获1.3 事件冒泡1.4 阻止1.5 解绑事件 2. 事件委托3. 其他事件3.1 页面加载事件3.2 页面滚动事件3.3 页面尺寸事件 4. 元素尺寸与位置 1.事件流 1.1 事件流与两个阶段说明 事件流指的是事件完整执行过程中的流动路…...