Java面试八股--04-MySQL
致谢:感谢整理!2025年 Java 面试八股文(20w字)_java面试八股文-CSDN博客
目录
1、Select语句完整的执行顺序
2、MySQL事务
3、MyISAM和InnoDB的区别
4、悲观锁和乐观锁怎么实现
5、聚簇索引与非聚簇索引区别
6、什么情况下mysql会索引失效
1.对索引列使用函数或计算
2.隐式类型转换
3.使用LIKE前导通配符
4.组合索引为遵循最左前缀原则
5.使用OR连接非索引列
6.索引列参与!=、NOT、IS NULL判断
7.数据量过小或索引选择性低
8.全表扫描低成本低于索引查询
9.索引列使用IN或BETWEEN的范围过大
7、B+tree与B-tree区别
编辑
介绍:
1.数据结构设计
2.查询性能
3.存储与I/O效率
4.插入与删除
5.适用场景
8、以M有SQL为例Linux下如何排查问题
一、快速应急(止血)
二、系统资源排查
CPU 负载
内存使用
磁盘 I/O
网络流量
三、MySQL 内部诊断
四、进阶工具性能剖析
五、故障复盘与优化日志归档
9、如何处理慢查询
1. 定位慢查询来源
2. 优化SQL语句与索引
3. 执行计划与资源分析
4. 数据库配置优化
5. 自动化监控与智能优化
总结
10、MySQL优化
11、SQL语句优化案例
12、你们公司有哪些数据库设计规范
13、有没有设计过数据表?你是如何设计的
14、常见面试SQL
1、Select语句完整的执行顺序
SQL Select 语句完整的执行顺序:
(1)from子句组装来自不同的数据源的数据;
(2)where子句基于指定的条件对记录行进行筛选;
(3)group by子句将数据划分为多个分组;
(4)使用聚集函数进行计算;
(5)使用having子句筛选分组;
(6)计算所有的表达式;
(7)select的字段;
(8)使用order by 对结果集进行排序。
2、MySQL事务
事务的基本要素(ACID)
1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节。事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样。也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位
2.一致性(Consistency):事务开始前和结束后,数据库的完整性约束没有被破坏 。比如A向B转账,不可能A扣了钱,B却没收到。
3.隔离性(Isolation):同一时间,只允许一个事务请求同一数据,不同的事务之间彼此没有任何干扰。比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
4.持久性(Durability):事务完成后,事务对数据库的所有更新将被保存到数据库,不能回滚。
MySQL事务隔离级别:
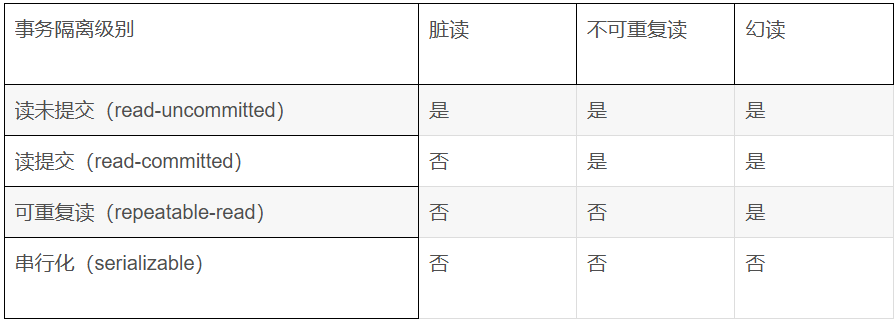
事务的并发问题
脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据室脏数据。
不可重复读:事务A多次读取同一数据,事务B在事务A多次读取的过程中,对数据做了更新并提交,导致事务A多次读取同一数据时,结果不一致。
幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
小结:不可重复读的和幻读很容易混淆,不可重复读侧重于修改,幻读侧重于新增或删除。解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表
3、MyISAM和InnoDB的区别
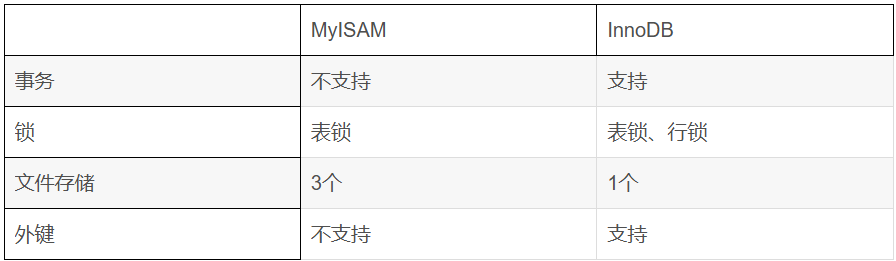
索引结构
InnoDB:主键索引为聚集索引,数据直接存储在索引的叶子结点,逐渐查询极快。
MyISAM:所有索引均为非聚集索引,索引与数据分离,需通过地址二次查找。
适用场景
| 场景 | 推荐引擎 | 理由 |
|---|---|---|
| 高并发写入、事务需求 | InnoDB | 行级锁、事务支持 |
| 复杂查询(OLTP) | InnoDB | 缓冲池优化、索引效率高 |
| 只读或读多写少 | MyISAM | 简单结构、全表扫描快 |
| 日志记录、数据仓库 | MyISAM | 无事务需求,写入后很少修改 |
总结
-
InnoDB 是现代应用的首选,尤其在需要事务、高并发或数据可靠性时。
-
MyISAM 适用于简单查询、只读场景,但已逐渐被 InnoDB 取代。
-
MySQL 5.5+ 默认使用 InnoDB,建议优先选择。
4、悲观锁和乐观锁怎么实现
悲观锁和乐观锁是两种常见的并发控制机制,用于解决多线程或分布式环境下数据竞争的问题。它的核心区别在于对并发冲突的预期以及实现方式。
悲观锁:
核心思想:默认并发操作会频繁发生冲突,因此在访问数据时直接加锁,确保独占操作。
数据库层面
1、行级锁(InnoDB)
使用SELECT ... FOR UPDATE显式锁定目标行,其他事务需要等待锁释放
特点:
- 锁在事务提交或回滚后释放。
- 需要确保事务尽量短,避免长事务导致性能问题。
2、表级锁(MyISAM)
MyISAM引擎默认在写操作时自动加表级锁
适用场景:
-
写操作频繁,冲突概率高(如账户扣款)。
-
需要强一致性保证。
乐观锁:
核心思想:默认并发冲突比较少,只在提交数据时检查是否发生冲突,若冲突则重试或者放弃。
数据库层面
- 版本号机制:为表添加一个版本号字段(如version),更新是校验版本号
- 时间戳机制:类似版本号,但使用时间戳字段update_time作为校验依据
对比总结
| 特性 | 悲观锁 | 乐观锁 |
|---|---|---|
| 冲突预期 | 默认高概率冲突,提前加锁 | 默认低概率冲突,提交时校验 |
| 实现复杂度 | 简单(直接加锁) | 复杂(需处理冲突重试逻辑) |
| 性能 | 高并发下可能阻塞,吞吐量低 | 无锁竞争,吞吐量高 |
| 适用场景 | 强一致性、短事务、写多读少 | 最终一致性、长事务、读多写少 |
| 典型应用 | 银行转账、订单支付 | 商品库存、评论点赞 |
选择建议
-
若系统并发冲突频繁,或要求强一致性(如金融系统),优先选择悲观锁。
-
若系统读多写少,或能容忍短暂不一致(如电商库存),优先选择乐观锁。
-
分布式场景中,乐观锁更易扩展(如结合 Redis 或 ZooKeeper)。
5、聚簇索引与非聚簇索引区别
都是B+树的数据结构
聚簇索引:将数据存储于索引放在一起,并且按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序于索引顺序是一致的,即:只要索引是相邻的,那么对应的数据也一定是相邻地存放在磁盘上的
非聚簇索引:叶子结点不存储数据、存储的是数据行地址,也就是说根据索引查找到数据行的位置再取磁盘查找数据,这个就有类似一本书的目录,比如我们要找第三章第一节,那么我们先在这个目录里面找,找到对应的页码后再去对应的页码看文章。
优势:
1、查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高。
2、聚簇索引对于范围查询的效率很高,因为其数据时按照大小排列的
3、聚簇索引适合用在排序的场合,非聚簇索引不适合
劣势:
1、维护索引很昂贵,特别是插入新行或者主键被更新导至要分页(pagesplit)的时候。建议在大量插入新行后,选在负载较低的时间段,通过OPTIMIZETABLE优化表,因为必须被移动的行数据可能造成碎片。使用独享表空间可以弱化碎片
2、表因为使用uuId(随机ID)作为主键,使数据存储稀疏,这就会出现聚簇索引有可能有比全表扫面更慢,所以建议使用int的auto_increment作为主键
3、如果主键比较大的话,那辅助索引将会变的更大,因为辅助索引的叶子存储的是主键值,过长的主键值,会导致非叶子节点占用占用更多的物理空间。
6、什么情况下mysql会索引失效
MySQL索引失效会导致查询的性能急剧下降,甚至触发全表扫描。以下是常见的索引失效场景以及其原因和优化方法:
失效条件:
- where后面使用函数
- 使用or条件
- 模糊查询%放在前边
- 类型转换
- 组合索引(最佳左前缀匹配原则)
1.对索引列使用函数或计算
失效原因:索引存储的是列的原始值,对列进行函数操作或计算后,MySQL无法直接匹配索引结构。
示例:
-- 索引失效(对 date 字段使用函数)
SELECT * FROM orders WHERE YEAR(create_time) = 2023;-- 索引失效(对 price 进行计算)
SELECT * FROM products WHERE price * 0.9 > 100;
优化方法:
将函数或计算移至表达式另一侧:
-- 优化后(直接使用时间范围)
SELECT * FROM orders
WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31';-- 优化后(避免对列计算)
SELECT * FROM products WHERE price > 100 / 0.9;2.隐式类型转换
失效原因:索引列与查询值的类型不一致,触发隐式类型转换(如字符串转数字)。
示例:
-- user_id 是 VARCHAR 类型,但查询使用数字(导致类型转换)
SELECT * FROM users WHERE user_id = 10086;优化方法:
保持一致:
SELECT * FROM users WHERE user_id = '10086';3.使用LIKE前导通配符
失效原因:以%或_开头的模糊查询无法利用索引的有序性。
示例:
-- 索引失效(前导通配符)
SELECT * FROM articles WHERE title LIKE '%数据库%';优化方法:
避免前导通配符,或使用全文索引(如MATCH...AGAINST):
-- 仅后缀模糊匹配(可能走索引)
SELECT * FROM articles WHERE title LIKE '数据库%';4.组合索引为遵循最左前缀原则
失效原因:组合索引按最左列优先排序,如果查询没有包含最左列,索引失效。
示例:
-- 组合索引为 (a, b, c)
SELECT * FROM table WHERE b = 2 AND c = 3; -- 未使用 a 列,索引失效优化方法:
调整查询条件顺序,确保包含最左列:
SELECT * FROM table WHERE a = 1 AND b = 2 AND c = 3;5.使用OR连接非索引列
失效原因:若OR的某一侧字段无索引,优化器可能放弃使用索引。
示例:
-- name 有索引,age 无索引
SELECT * FROM users WHERE name = '张三' OR age = 25; -- 索引失效优化方法:
为OR两侧字段都添加索引,或改用UNION:
SELECT * FROM users WHERE name = '张三'
UNION
SELECT * FROM users WHERE age = 25;6.索引列参与!=、NOT、IS NULL判断
失效原因:非等值查询(如!=、NOT、IN)可能导致优化器选择全表扫描。
-- 索引失效
SELECT * FROM orders WHERE status != 'paid';
SELECT * FROM users WHERE email IS NULL;优化方法:
避免高频使用非等值查询,或结合覆盖索引优化:
-- 覆盖索引(仅查索引列)
SELECT id FROM users WHERE email IS NULL;7.数据量过小或索引选择性低
失效原因:
- 表数据量过小(如几百行),优化器认为全表扫描更快。
- 索引选择性低(如性别字段只有男/女),索引效率不如全表扫描。
示例:
-- 性别字段索引选择性低
SELECT * FROM users WHERE gender = '男';优化方法:
选择性低的字段避免单独建索引,可结合其他字段建组合索引。
8.全表扫描低成本低于索引查询
失效原因:当查询需要访问大部分数据时,优化器可能直接选择全表扫描。
示例:
-- 查询表中 90% 的数据
SELECT * FROM logs WHERE create_time > '2000-01-01';优化方法:
限制查询范围或强制使用索引(需谨慎):
SELECT * FROM logs USE INDEX(idx_time) WHERE create_time > '2023-01-01';9.索引列使用IN或BETWEEN的范围过大
失效原因:IN列表过长或BETWEEN范围过广,优化器可能放弃索引。
示例:
-- IN 列表包含数千个值
SELECT * FROM products WHERE id IN (1, 2, 3, ..., 10000);优化方法:
分批次查询或改用临时表关联。
7、B+tree与B-tree区别
原理:分批次的将磁盘块加载进内存中进行检索,若查到数据,则直接返回,若查不到,则释放内存,并重新加载同等数据量的索引进内存,重新遍历
B+tree:
结构: 数据 向下的指针 指向数据的指针
特点:
1,节点排序
2 .一个节点了可以存多个元索,多个元索也排序了
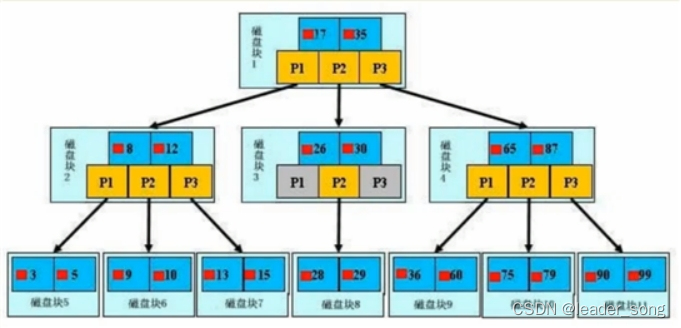
B-tree:
结构: 数据 向下的指针
特点:
1.拥有B树的特点
2.叶子节点之间有指针
3.非叶子节点上的元素在叶子节点上都冗余了,也就是叶子节点中存储了所有的元素,并且排好顺序
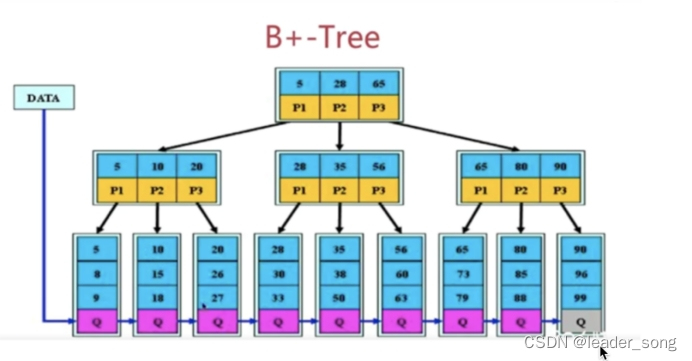
从结构上看,B+Tree 相较于 B-Tree 而言 缺少了指向数据的指针 也就红色小方块;
Mysq|索引使用的是B+树,因为索引是用来加快查询的,而B+树通过对数据进行排序所以是可以提高查询速度的,然后通过一个节点中可以存储多个元素,从而可以使得B+树的高度不会太高,在Mysql中一个Innodb页就是一个B+树节点,一个Innodb页默认16kb,所以一般情况下一颗两层的B+树可以存2000万行左右的数据,然后通过利用B+树叶子节点存储了所有数据并且进行了排序,并且叶子节点之间有指针,可以很好的支持全表扫描,范围查找等SQL语句
介绍:
1.数据结构设计
| 特性 | B树(B-Tree) | B+树(B+ Tree) |
|---|---|---|
| 节点存储内容 | 每个节点存储键(Key)和对应的数据(Value) | 非叶子节点仅存储键,叶子节点存储键和数据 |
| 叶子节点链接 | 叶子节点独立,无链表连接 | 叶子节点通过指针形成有序双向链表 |
| 数据分布 | 数据可能分布在所有节点 | 数据仅存储在叶子节点 |
2.查询性能
| 场景 | B树 | B+树 |
|---|---|---|
| 单值查询 | 可能在非叶子节点命中数据(更快) | 必须遍历到叶子节点才能获取数据 |
| 范围查询 | 需中序遍历,效率较低(无链表支持) | 通过叶子节点链表直接遍历,效率极高 |
| 查询稳定性 | 查询时间波动较大(数据分布不均) | 查询时间稳定(所有查询必须到叶子节点) |
3.存储与I/O效率
| 特性 | B树 | B+树 |
|---|---|---|
| 节点容量 | 节点存储键+数据,单节点键数量较少 | 非叶子节点仅存键,单节点可容纳更多键 |
| 树高度 | 相对较高(相同数据量下) | 更矮胖(键密度高,减少磁盘I/O次数) |
| 空间利用率 | 非叶子节点存储数据,空间利用率较低 | 非叶子节点仅存键,空间利用率更高 |
4.插入与删除
| 操作 | B树 | B+树 |
|---|---|---|
| 分裂与合并 | 频繁(数据分布在所有节点) | 主要在叶子节点操作,非叶子节点仅调整键 |
| 复杂度 | 较高(需处理数据和键的重新分配) | 较低(数据仅存于叶子节点) |
5.适用场景
| 场景 | B树 | B+树 |
|---|---|---|
| 数据库索引 | 较少使用(如MongoDB的某些存储引擎) | 主流选择(如MySQL InnoDB、Oracle) |
| 文件系统 | 适用(如早期文件系统) | 更高效(如NTFS、ReiserFS) |
| 内存数据库 | 可能更优(减少指针跳转) | 适用但需权衡链表维护成本 |
总结
| 维度 | B树 | B+树 |
|---|---|---|
| 设计目标 | 快速随机访问 | 高效范围查询和顺序扫描 |
| 优势 | 单点查询可能更快 | 高I/O效率、适合大规模数据存储 |
| 劣势 | 范围查询性能差、树高度较高 | 单点查询需访问叶子节点 |
| 典型应用 | 内存受限或随机访问密集场景 | 数据库、文件系统等磁盘存储场景 |
为什么数据库(如MySQL)选择B+树?
- 范围查询优化:叶子节点的链表结构天然支持高效范围查询(如WHERE id > 100)。
- 更低的树高度:减少磁盘I/O次数(适合海量数据)。
- 稳定的查询性能:所有查询最终落到叶子节点,时间波动小。
- 更适合磁盘预读:连续存储的叶子节点匹配磁盘块读取特性。
8、以M有SQL为例Linux下如何排查问题
类似提问方式:如果线上环境出现问题比如网站卡顿重则瘫痪?
一、快速应急(止血)
临时重启服务(仅限极端情况)
# 强制终止 MySQL 进程(慎用!可能丢失数据)
kill -9 $(pidof mysqld)
# 安全重启 MySQL
systemctl restart mysql限制流量入口
# 通过 iptables 临时屏蔽外部请求(示例屏蔽 80 端口)
iptables -A INPUT -p tcp --dport 80 -j DROP紧急杀会话
-- 登录 MySQL,终止长时间运行的查询
SHOW PROCESSLIST;
KILL <query_id>;二、系统资源排查
CPU 负载
# 查看 CPU 使用率及负载(重点看 %us 用户态、%sy 内核态)
top -c
htop# 按进程查看 CPU 占用(-p 指定进程)
pidstat -p <mysql_pid> 1 5内存使用
# 检查内存和 Swap 使用情况
free -h
vmstat 1 5# 查看 MySQL 内存分配
mysql> SHOW VARIABLES LIKE '%buffer%';磁盘 I/O
# 查看磁盘 I/O 压力(关注 %util、await)
iostat -x 1 5# 定位高 I/O 进程(按进程统计)
iotop网络流量
# 检查网络连接和带宽(排查 DDoS 或异常连接)
iftop -P
netstat -antp | grep ESTABLISHED三、MySQL 内部诊断
慢查询分析
-- 查看是否开启慢查询日志
SHOW VARIABLES LIKE 'slow_query_log';-- 临时开启慢查询日志(立即生效)
SET GLOBAL slow_query_log = ON;
SET GLOBAL long_query_time = 1; -- 阈值设为 1 秒-- 使用工具分析慢日志(示例)
pt-query-digest /var/lib/mysql/slow.log
锁与事务
-- 查看当前锁等待
SELECT * FROM information_schema.INNODB_LOCK_WAITS;-- 检查长事务
SELECT * FROM information_schema.INNODB_TRX\G-- 查看表级锁(MyISAM)
SHOW OPEN TABLES WHERE In_use > 0;
连接数暴增
-- 查看最大连接数限制
SHOW VARIABLES LIKE 'max_connections';-- 检查当前连接数与来源
SHOW STATUS LIKE 'Threads_connected';
SHOW PROCESSLIST;-- 临时调整连接数(立即生效)
SET GLOBAL max_connections = 1000;
四、进阶工具
性能剖析
# 使用 perf 分析 CPU 热点(需 root)
perf top -p <mysql_pid>
内存泄漏检测
# 查看 MySQL 内存分配(valgrind 需重启)
valgrind --tool=memcheck --leak-check=full mysqld
死锁分析
-- 开启 InnoDB 监控(记录到错误日志)
SET GLOBAL innodb_print_all_deadlocks = ON;
五、故障复盘与优化
日志归档
备份 /var/log/mysql/error.log 和慢查询日志。
配置调优
调整 innodb_buffer_pool_size(通常设为物理内存的 70%~80%)。
架构改进
引入读写分离、分库分表、缓存(Redis)等。
监控告警
部署 Prometheus + Grafana 监控 MySQL 核心指标。
排查流程图
网站卡顿/瘫痪
│
├─ 应急处理:重启服务、限流、杀会话
│
├─ 系统资源检查:CPU、内存、磁盘、网络
│
├─ MySQL 内部分析:慢查询、锁、连接数、缓存
│
└─ 根因定位:日志分析、工具诊断
│
├─ 优化配置
├─ 架构升级
└─ 监控加固
9、如何处理慢查询
1. 定位慢查询来源
- 分析日志工具:使用
mysqldumpslow或pt-query-digest统计高频慢SQL,定位耗时最长的查询:SET GLOBAL slow_query_log='ON'; SET GLOBAL long_query_time=1; -- 设置慢查询阈值日志文件路径可通过
slow_query_log_file查看 -
分析日志工具:使用
mysqldumpslow或pt-query-digest统计高频慢SQL,定位耗时最长的查询: -
mysqldumpslow -s t -t 10 /path/to/slow.log # 按时间排序取前10条
2. 优化SQL语句与索引
- 添加缺失索引:对频繁查询的
WHERE条件列、JOIN字段建立索引。例如:
ALTER TABLE user_info ADD INDEX idx_name(name);避免全表扫描。
- 修复失效索引场景:
- 类型转换:字符串字段传参数时需加引号,避免隐式转换(如
userId='123'而非userId=123)。 - OR条件优化:若
OR中部分字段无索引,拆分为多条SQL用UNION合并。 - LIKE通配符:避免以
%开头,可改用覆盖索引(如SELECT id FROM table WHERE name LIKE '%abc')。
- 类型转换:字符串字段传参数时需加引号,避免隐式转换(如
- 联合索引设计:遵循最左匹配原则,将区分度高的字段放左侧,范围查询字段放最后。例如:
CREATE INDEX idx_status_time ON orders(status, create_time); -- 支持 WHERE status=1 或 WHERE status=1 AND create_time>'2023-01-01' -- 但不支持单独 WHERE create_time>'2023-01-01'
3. 执行计划与资源分析
- EXPLAIN解析:通过
EXPLAIN查看SQL是否使用索引、扫描行数:EXPLAIN SELECT * FROM user WHERE userId LIKE '%123'; -- 若type为ALL则未走索引 - PROFILE性能诊断:启用
profiling分析SQL各阶段耗时:SET profiling=1; SHOW PROFILES; -- 查看具体执行阶段耗时
4. 数据库配置优化
- 调整连接数限制:若出现连接超限,可通过控制台提升连接数上限至150%,或优化业务代码释放闲置连接。
- 参数调优:根据负载调整
innodb_buffer_pool_size(缓存数据和索引)、max_connections等参数。
5. 自动化监控与智能优化
- AI驱动索引推荐:基于历史数据训练模型,自动推荐缺失索引(如美团DAS平台方案),减少人工分析成本。
- 定期慢查询清理:结合业务低峰期执行
OPTIMIZE TABLE重建碎片化表,或对大表进行分库分表。
总结
处理慢查询需系统性排查,优先从日志定位问题SQL,针对性优化索引与查询结构,辅以配置调优。复杂场景可引入自动化工具(如AI索引推荐)提升效率。
10、MySQL优化
(1)尽量选择较小的列
(2)将where中用的比较频繁的字段建立索引
(3)select子句中避免使用"*"
(4)当只需要一行数据的时候使用limit 1
(5)避免在所有列上使用计算。not in和<>等操作
(6)保证单表数据不会超过200w,适时分割表。针对查询慢的语句,可以使用explain来分析该语句具体的执行情况。
(7)避免改变索引列的类型
(8)选择最有效的表名顺序,from字句中写在最后的表是基础表,将被最先处理,在from子句中包含多个表的情况下,你必须选择记录条数最少的表为基础表。
(9)避免在索引列上面进行计算
(10)尽量缩小子查询的结果
11、SQL语句优化案例
例1:where 子句中可以对字段进行 null 值判断吗?
可以,比如select id from i where num is null 这样的sql也是可以的。但是最好不要给数据库六NULL,尽可能的使用NOT NULL 填充数据库。不要以为NULL不需要空间,比如:char(100)型,在字段建立时,空间就固定了,不管是否插入值(NULL也包含在内),都是占用100个字符的空间,如果是varchar这样的变长字段,null不占用空间。可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0。
例2:如何优化?下面的语句?
select * from admin left join log on admin.admin_id = log.admin_id where log.admin_id >10
优化为:select * from (select * from admin where admin_id>10) T1 lef join log on T1.admin_id = log.admin_id。
使用JOIN时候,应该用小的结果驱动大的结果(left join 左边的表的结果尽量小如果有条件应该放到左边先处理,right join 同理反向),尽量把牵涉到多表联合查询拆分为多个query(多个连表查询效率低,容易到之后锁表和阻塞)
例3:limit 的基数比较大时使用 between
l例如:select * from admin order by admin_id limit 100000,10
优化为:select * from admin where admin_id between 100000 and 100010 order by admin_id。
例4:尽量避免在列上做运算,这样导致索引失效
例如:select * from admin where year(admin_time)>2014
优化为:select * from admin where admin_time>'2014-01-01'
12、你们公司有哪些数据库设计规范
(一)基础规范
1、表存储引擎必须使用InnoD,表字符集默认使用utf8,必要时候使用utf8mb4
解读:
(1)通用,无乱码风险,汉字节,英文1字节
(2)utf8mb4是utf8的超集,有存储4字节例如表情符号时,使用它
2、禁止使用存储过程,视图,触发器,Event
解读:
(1)对数据库性能影响较大,互联网业务,能让站点层和服务层干的事情,不要交到数据库层
(2)调试,排错,迁移都比较困难,扩展性较差
3、禁止在数据库中存储较大文件,例如照片,可以将大文件存储在对象存储系统,数据库中存储路径。
4、禁止在线上环境做数据库压力测试
5、测试,开发,线上数据库环境必须隔离
(二)命名规范
1、库名,表名,列名必须用小写,采用下划线分隔
解读:abc,Abc,ABC都是给自己埋坑
2、库名,表名,列名必须见名知义,长度不超过32字符
解读:tmp,wushan谁知道这些库是干嘛的
3、库备份必须以bak为前缀,以日期为后缀
4、从库必须以-s为后缀
5、备库必须以-ss为后缀
(三)表设计规范
1、单实例表个数必须控制在2000个以内
2、单表分表个数必须控制在1024个以内
3、表必须有主键,推荐使用UNSIGNED整数为主键
潜在坑:删除无主键的表,如果是row模式的主从架构,从库会挂
4、禁止使用外键,如果要抱枕完整性,应该由应用程式实现
解读:外键让表之间相互耦合,影响update/delete等SQL性能,可能造成死锁,高并发下容易称为数据库瓶颈
5、建议将大字段,访问频度低的字段拆分到单独的表中存储,分离冷热数据
(四)列设计规范
1、根据业务区分使用tinyint/int/bright,分别会占用1/4/8字节
2、根据业务区分使用char/varchar
解读:
(1)字段长度固定,或者长度近似的业务场景,适合使用char,能够减少碎片,查询性能高
(2)字段长度相差大,或者更新较少的业务场景,适合使用varchar能够减少空间。
3、根据业务区分使用datetime/timestamp
解读:前者占用5个字节,后者占用4个字节,存储年使用YEAR,存储日期使用DATE,存储时间使用datetime
4、必须把字段定义为NOT NULL并设默认值
解读:
(1)NULL的列使用索引,索引统计,值都更加复杂,MySQL更难优化
(2)NULL需要更多的存储空间
(3)NULL只能采用IS NULL或者IS NOT NULL,而在=/=!/in/not in时有大坑
5、使用INT UNSIGNED存储IPv4,不要用char(15)
6、使用varchar(20)存储手机号,不要使用整数
解读:
(1)牵扯到国家代号,可能出现+/-/()等字符,例如+86
(2)手机号不会用来做数学运算
(3)varchar可以模糊查询,例如like ‘138%’
7、使用TINYINT来代替ENUM
解读:ENUM增加新值要进行DDL操作
(五)索引规范
1、唯一索引使用uniq_[字段名]来命名
2、非唯一索引使用idx_[字段名]来命名
3、单张表索引数量建议控制在5个以内
解读:
(1)互联网高并发业务,太多索引会影响写性能
(2)生成执行计划时,如果索引太多,会降低性能,并可能导致MySQL选择不到最优索引
(3)异常复杂的查询需求,可以选择ES等更为适合的方式存储
4、组合索引字段数不建议超过5个
解读:如果5个字段还不能极大缩小row范围,八成是设计有问题
5、不建议在频繁更新的字段上建立索引
6、非必要不要进行JOIN查询,如果要进行JOIN查询,被JOIN的字段必须类型相同,并建立索引
解读:踩过因为JOIN字段类型不一致,而导致全表扫描的坑么?
7、理解组合索引最左前缀原则,避免重复建设索引,如果建立了(a,b,c),相当于建立了(a), (a,b), (a,b,c)
(六)SQL规范
1、禁止使用select *,只获取必要字段
解读:
(1)select *会增加cpu/io/内存/带宽的消耗
(2)指定字段能有效利用索引覆盖
(3)指定字段查询,在表结构变更时,能保证对应用程序无影响
2、insert必须指定字段,禁止使用insert into T values()
解读:指定字段插入,在表结构变更时,能保证对应用程序无影响
3、隐式类型转换会使索引失效,导致全表扫描
4、禁止在where条件列使用函数或者表达式
解读:导致不能命中索引,全表扫描
5、禁止负向查询以及%开头的模糊查询
解读:导致不能命中索引,全表扫描
6、禁止大表JOIN和子查询
7、同一个字段上的OR必须改写问IN,IN的值必须少于50个
8、应用程序必须捕获SQL异常
解读:方便定位线上问题
说明:本规范适用于并发量大,数据量大的典型互联网业务,可直接参考。
13、有没有设计过数据表?你是如何设计的

14、常见面试SQL
例1:
用一条SQL语句查询出每门课都大于80分的学生姓名
name kecheng fenshu
张三 语文 81
张三 数学 75
李四 语文 76
李四 数学 90
王五 语文 81
王五 数学 100
王五 英语 90
答1:
select distinct name from table where name not in (select distinct name from table where fenshu<=80)
答2:
select name from table group by name having min(fenshu)>80
例2:
学生表 如下:
自动编号 学号 姓名 课程编号 课程名称 分数
1 2005001 张三 0001 数学 69
2 2005002 李四 0001 数学 89
3 2005001 张三 0001 数学 69
删除除了自动编号不同,其他都相同的学生冗余信息
答:
delete tablename where 自动编号 not in(select min(自动编号) from tablename group by学号, 姓名, 课程编号, 课程名称, 分数)
例3:
一个叫team的表,里面只有一个字段name,一共有4条纪录,分别是a,b,c,d,对应四个球队,现在四个球队进行比赛,用一条sql语句显示所有可能的比赛组合.
答:
- select a.name, b.name
- from team a, team b
- where a.name < b.name
例4:
怎么把这样一个表
year month amount
1991 1 1.1
1991 2 1.2
1991 3 1.3
1991 4 1.4
1992 1 2.1
1992 2 2.2
1992 3 2.3
1992 4 2.4
查成这样一个结果
year m1 m2 m3 m4
1991 1.1 1.2 1.3 1.4
1992 2.1 2.2 2.3 2.4
1.select year,
2.(select amount from aaa m where month=1 and m.year=aaa.year)as m1,
3.(select amount from aaa m where month=1 and m.year=aaa.year)as m2,
4.(select amount from aaa m where month=3 and m.year=aaa.year) as m3,
5.(select amount from aaa m where month=4 and m.year=aaa.year) as m4
6.from aaa group by year
例5:
说明:复制表(只复制结构,源表名:a新表名:b)
答:
select * into b from a where 1<>1(where1=1,拷贝表结构和数据内容)
ORACLE:
1.create table b
2.As
3.Select * from a where 1=2
[<>(不等于)(SQL Server Compact)
比较两个表达式。 当使用此运算符比较非空表达式时,如果左操作数不等于右操作数,则结果为 TRUE。 否则,结果为 FALSE。]
例6:
原表:
courseid coursename score
1 java 70
2 oracle 90
3 xml 40
4 jsp 30
5 servlet 80
为了便于阅读,查询此表后的结果显式如下(及格分数为60):
courseid coursename score mark
1 java 70 pass
2 oracle 90 pass
3 xml 40 fail
4 jsp 30 fail
5 servlet 80 pass
写出此查询语句
select courseid, coursename ,score ,if(score>=60, "pass","fail") as mark from course 例7:
表名:购物信息
购物人 商品名称 数量
A 甲 2
B 乙 4
C 丙 1
A 丁 2
B 丙 5
给出所有购入商品为两种或两种以上的购物人记录
答:
select * from 购物信息 where 购物人 in (select 购物人 from 购物信息 group by 购物人 having count(*) >= 2); 例8:
info 表
date result
2005-05-09 win
2005-05-09 lose
2005-05-09 lose
2005-05-09 lose
2005-05-10 win
2005-05-10 lose
2005-05-10 lose
如果要生成下列结果, 该如何写sql语句?
date win lose
2005-05-09 2 2
2005-05-10 1 2
答1:
select date, sum(case when result = "win" then 1 else 0 end) as "win", sum(case when result = "lose" then 1 else 0 end) as "lose" from info group by date;答2:
select a.date, a.result as win, b.result as lose
from
(select date, count(result) as result from info where result = "win" group by date) as a
join
(select date, count(result) as result from info where result = "lose" group by date) as b
on a.date = b.date;例9
mysql 创建了一个联合索引(a,b,c) 以下 索引生效 的是(1,2,4)
1、where a = 1 and b = 1 and c =12、where a = 1 and c = 13、where b = 1 and c = 1,4、where b = 1 and a =1 and c = 1相关文章:
Java面试八股--04-MySQL
致谢:感谢整理!2025年 Java 面试八股文(20w字)_java面试八股文-CSDN博客 目录 1、Select语句完整的执行顺序 2、MySQL事务 3、MyISAM和InnoDB的区别 4、悲观锁和乐观锁怎么实现 5、聚簇索引与非聚簇索引区别 6、什么情况下my…...
:そう)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(31):そう
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(31):そう 1、前言(1)情况说明(2)工程师的信仰2、知识点(1)复习(2) そう1,いAくな+さそうでう。2,なAな + そうです。3,いいです ー>よさそうです。4、x Xの状況(じょうきょう)5、みたい & ら…...
设计模式——访问者设计模式(行为型)
摘要 访问者设计模式是一种行为型设计模式,它将数据结构与作用于结构上的操作解耦,允许在不修改数据结构的前提下增加新的操作行为。该模式包含关键角色如元素接口、具体元素类、访问者接口和具体访问者类。通过访问者模式,可以在不改变对象…...

实验设计与分析(第6版,Montgomery著,傅珏生译) 第10章拟合回归模型10.9节思考题10.1 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第10章拟合回归模型10.9节思考题10.1 R语言解题。主要涉及线性回归、回归的显著性、回归系数的置信区间。 vial <- seq(1, 10, 1) Viscosity <- c(160,171,175,182,184,181,188,19…...

《对象创建的秘密:Java 内存布局、逃逸分析与 TLAB 优化详解》
大家好呀!今天我们来聊聊Java世界里那些"看不见摸不着"但又超级重要的东西——对象在内存里是怎么"住"的,以及JVM这个"超级管家"是怎么帮我们优化管理的。放心,我会用最接地气的方式讲解,保证连小学…...
LeetCode 高频 SQL 50 题(基础版) 之 【高级查询和连接】· 下
上部分链接:LeetCode 高频 SQL 50 题(基础版) 之 【高级查询和连接】 上 题目:1164. 指定日期的产品价格 题解: select product_id,10 price from Products group by product_id having min(change_date) > 201…...

Java并发编程:读写锁与普通互斥锁的深度对比
在Java并发编程中,锁是实现线程安全的重要工具。其中,普通互斥锁(如synchronized和ReentrantLock)和读写锁(ReentrantReadWriteLock)是两种常用的同步机制。本文将从多个维度深入分析它们的区别、适用场景及…...

Spring Boot Actuator未授权访问漏洞修复
方案1:在网关的配置文件里增加以下配置 management:endpoints:web:exposure:include: []enabled-by-default: falseendpoint:health:show-details: ALWAYS 方案二:直接在nginx配置拦截actuator相关接口 location /actuator { return 403; …...
机器学习——SVM
1.什么是SVM 支持向量机(support vector machines,SVM)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了…...
【音视频】FFmpeg 硬件(NVDIA)编码H264
FFmpeg 与x264的关系 ffmpeg软编码是使⽤x264开源项⽬,也就是说ffmpeg软编码H264最终是调⽤了x264开源项⽬,所以我们要先理解ffmpeg和x264的调⽤关系,这⾥我们主要关注x264_init。对于x264的参数都在 ffmpeg\libavcodec \libx264.c x264\co…...

贪心算法应用:超图匹配问题详解
贪心算法应用:超图匹配问题详解 贪心算法在超图匹配问题中有着广泛的应用。下面我将从基础概念到具体实现,全面详细地讲解超图匹配问题及其贪心算法解决方案。 一、超图匹配问题基础 1. 超图基本概念 **超图(Hypergraph)**是普…...
所需的总数量函数:numMoments)
OpenCV CUDA模块结构分析与形状描述符------计算指定阶数的矩(Moments)所需的总数量函数:numMoments
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于计算指定阶数的矩(Moments)所需的总数量。 在图像处理中,矩(moments)是一…...
【Web应用】若依框架:基础篇13 源码阅读-前端代码分析
文章目录 ⭐前言⭐一、课程讲解过程⭐二、自己动手实操⭐总结 标题详情作者JosieBook头衔CSDN博客专家资格、阿里云社区专家博主、软件设计工程师博客内容开源、框架、软件工程、全栈(,NET/Java/Python/C)、数据库、操作系统、大数据、人工智能、工控、网…...
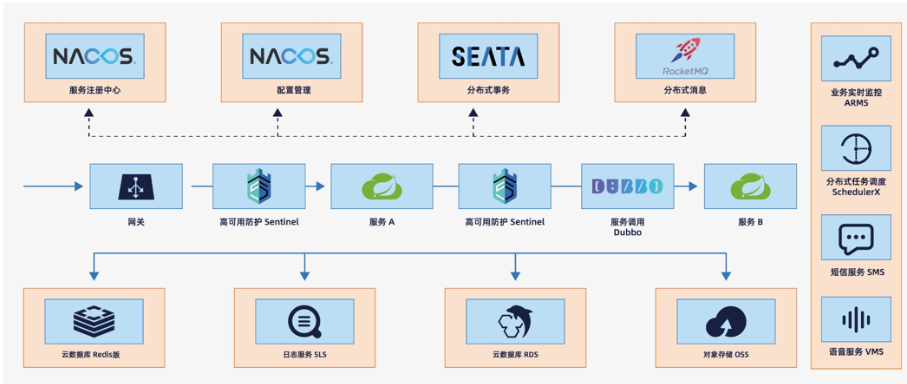
[java八股文][JavaSpring面试篇]SpringCloud
了解SpringCloud吗,说一下他和SpringBoot的区别 Spring Boot是用于构建单个Spring应用的框架,而Spring Cloud则是用于构建分布式系统中的微服务架构的工具,Spring Cloud提供了服务注册与发现、负载均衡、断路器、网关等功能。 两者可以结合…...

深度学习篇---face-recognition的优劣点
face_recognition库是一个基于 Python 的开源人脸识别工具,封装了 dlib 库的深度学习模型,具有易用性高、集成度强的特点。以下从技术实现、应用场景等维度分析其优劣势: 一、核心优势 1. 极简 API 设计,开发效率极高 代码量少:几行代码即可实现人脸检测、特征提取和比对…...
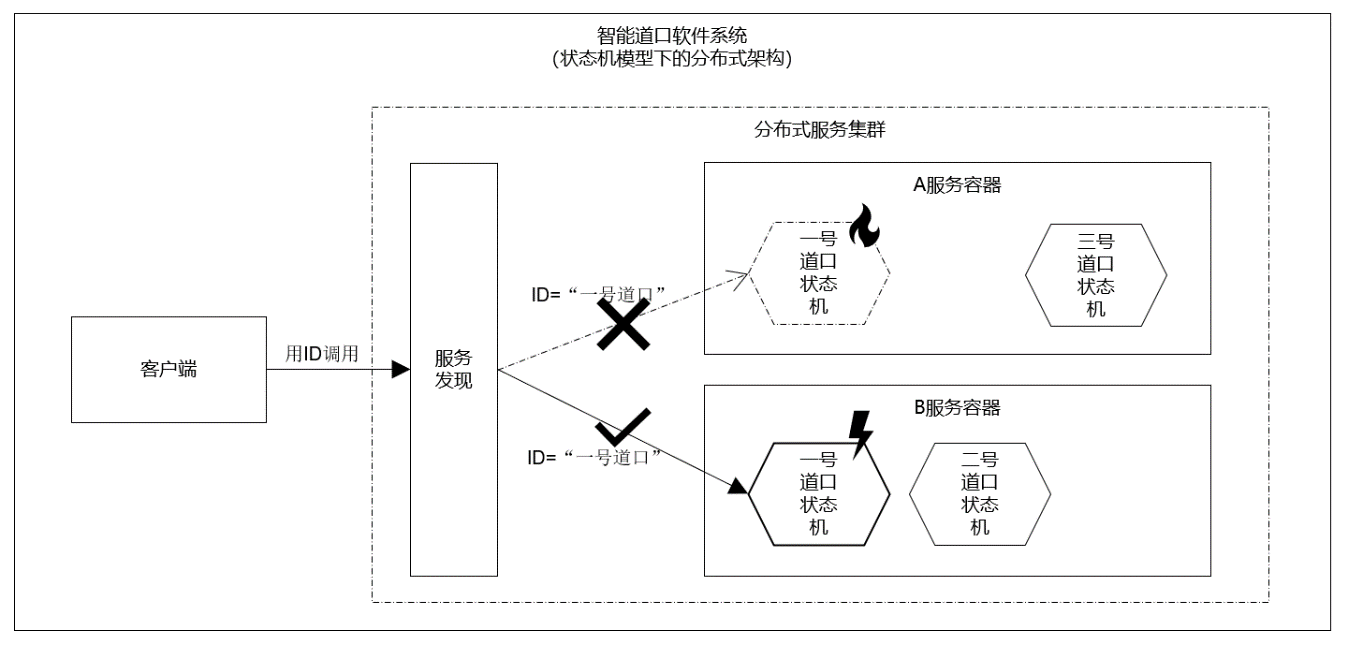
基于分布式状态机的集装箱智能道口软件架构方法
集装箱码头对进出场道口的通过能力始终是要求最高的,衡量道口的直接指标为道口通行效率,道口通行效率直接体现了集装箱码头的作业效率以及对外服务水平,进而直接影响到码头的综合能力。所以,码头普遍使用智能道口实现24小时无人值…...

Oracle的Hint
racle的Hint是用来提示Oracle的优化器,用来选择用户期望的执行计划。在许多情况下,Oracle默认的执行方式并不总是最优的,只不过由于平时操作的数据量比较小,所以,好的执行计划与差的执行计划所消耗的时间差异不大&…...

手动事务的使用
使用原因: 公司需要写一个定时任务,涉及增改查操作, 定时将前端页面配置的字典数据(标签数据)同步到数据库特定的表(标签表) 查询字典表数据 字典有,数据库表没有新增 都有,判断名称,名称不同修…...
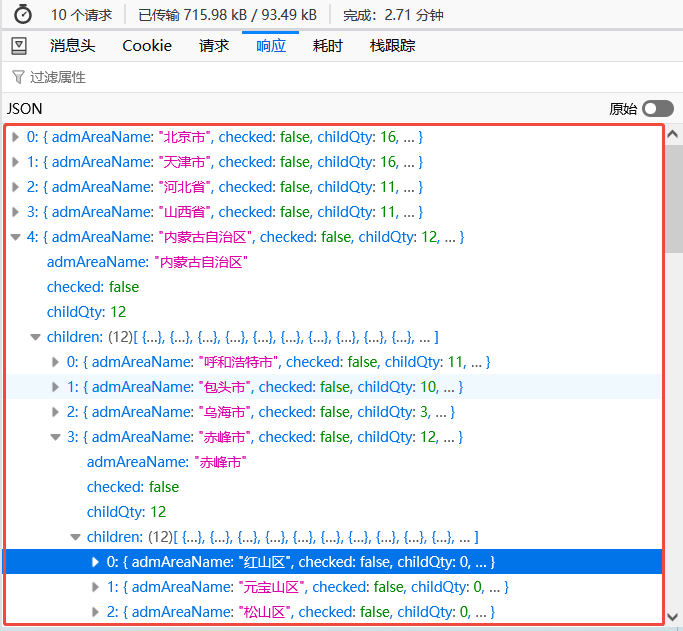
Vue 树状结构控件
1、效果图如下所示: 2、网络请求的数据结构如下: 3、新建插件文件:menu-tree.vue,插件代码如下: <template><div class"root"><div class"parent" click"onParentClick(pare…...

Spring Boot的启动流程,以及各个扩展点的执行顺序
目录 1. 初始化阶段执行顺序 1.1 Bean的构造方法(构造函数) 1.2 PostConstruct 注解方法 1.3 InitializingBean 的 afterPropertiesSet() 1.4 Bean(initMethod "自定义方法") 2. 上下文就绪后的扩展点 2.1 ApplicationContext 事件监听…...
【LUT技术专题】图像自适应3DLUT代码讲解
本文是对图像自适应3DLUT技术的代码解读,原文解读请看图像自适应3DLUT文章讲解 1、原文概要 结合3D LUT和CNN,使用成对和非成对的数据集进行训练,训练后能够完成自动的图像增强,同时还可以做到极低的资源消耗。下图为整个模型的…...

Apache Doris 在数据仓库中的作用与应用实践
在当今数字化时代,企业数据呈爆炸式增长,数据仓库作为企业数据管理和分析的核心基础设施,其重要性不言而喻。而 Apache Doris,作为一款基于 MPP(Massively Parallel Processing,大规模并行处理)…...
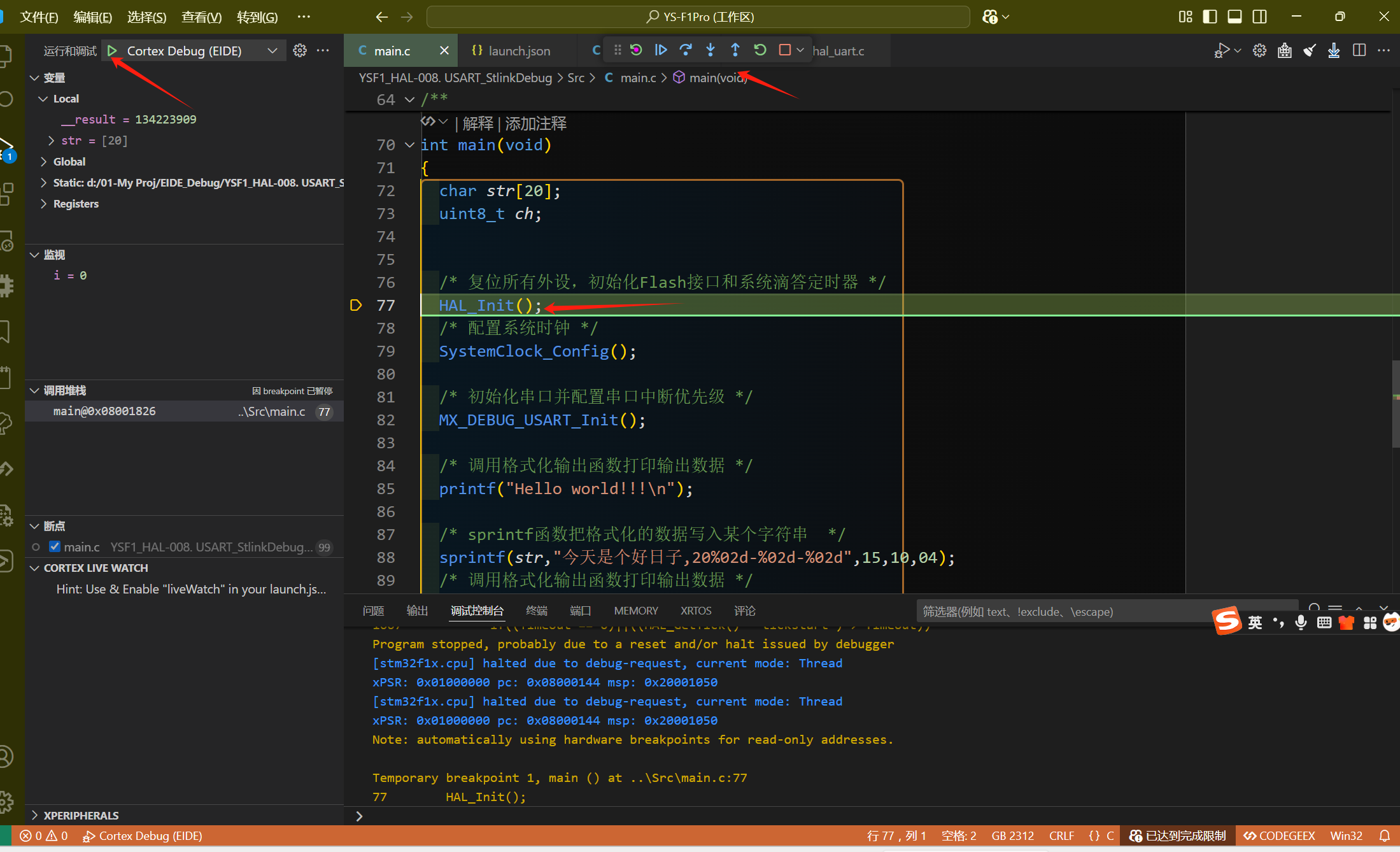
vscode使用“EIDE”和“Cortex-Debug”插件利用st-link插件实现程序烧写以及调试工作
第一步:安装vscode插件“EIDE”EIDE和“Cortex-Debug”。 第二步:配置EIDE 2.1安装“实用工具”: 2.2 EIDE插件配置:根据安装的keil C51 keil MDK IAR的相关路径设置 第三步:配置Cortex-Debug插件 点击settings.jso…...

Spring @Value注解的依赖注入实现原理
Spring Value注解的依赖注入实现原理 一,什么是Value注解的依赖注入二,实现原理三,代码实现1. 定义 Value 注解2. 实现 InstantiationAwareBeanPostProcessor3. 实现 AutowiredAnnotationBeanPostProcessor4. 占位符解析逻辑5. 定义 StringVa…...

三、kafka消费的全流程
五、多线程安全问题 1、多线程安全的定义 使用多线程访问一个资源,这个资源始终都能表现出正确的行为。 不被运行的环境影响、多线程可以交替访问、不需要任何额外的同步和协同。 2、Java实现多线程安全生产者 这里只是模拟多线程环境下使用生产者发送消息&…...

商品模块中的多规格设计:实现方式与电商/ERP系统的架构对比
在商品管理系统中,多规格设计(Multi-Specification Product Design)是一个至关重要但又极具挑战性的领域。无论是面向消费者的电商系统,还是面向企业管理的ERP系统,对商品规格的处理方式直接影响库存管理、订单履约、数…...
动手学线性神经网络:从数学原理到代码实现)
(三)动手学线性神经网络:从数学原理到代码实现
1 线性回归 线性回归是一种基本的预测模型,用于根据输入特征预测连续的输出值。它是机器学习和深度学习中最简单的模型之一,但却是理解更复杂模型的基础。 1.1 线性回归的基本元素 概念理解: 线性回归假设输入特征和输出之间存在线性关系。…...
Axure形状类组件图标库(共8套)
点击下载《月下倚楼图标库(形状组件)》 原型效果:https://axhub.im/ax9/02043f78e1b4386f/#g1 摘要 本图标库集锦精心汇集了8套专为Axure设计的形状类图标资源,旨在为产品经理、UI/UX设计师以及开发人员提供丰富多样的设计素材,提升原型设计…...

20250530-C#知识:String与StringBuilder
String与StringBuilder string字符串在开发中经常被用到,不过在需要频繁对字符串进行增加和删除时,使用StringBuilder有利于提升效率。 1、String string是一种引用类型而非值类型(某些方面像值类型)使用“”进行两个string对象的…...

从 Docker 到 Containerd:Kubernetes 容器运行时迁移实战指南
一、背景 Kubernetes 自 v1.24 起移除了 dockershim,不再原生支持 Docker Engine,用户需迁移至受支持的 CRI 兼容运行时,如: Containerd(推荐,高性能、轻量级) CRI-O(专为 Kuberne…...