nlp系列(6)文本实体识别(Bi-LSTM+CRF)pytorch
模型介绍
LSTM:长短期记忆网络(Long-short-term-memory),能够记住长句子的前后信息,解决了RNN的问题(时间间隔较大时,网络对前面的信息会遗忘,从而出现梯度消失问题,会形成长期依赖问题),避免长期依赖问题。
Bi-LSTM:由前向LSTM与后向LSTM组合而成。
模型结构
Bi-LSTM
同LSTM,区别在于模型的输出和结构上不同,如下图:

一共有两个LSTM网络,一个网络从一句话的首段进行学习,另一个网络从一句话的末端进行学习。
相关详情请看nlp系列(5)文本实体识别(LSTM)pytorch 中模型详解
CRF
CRF(条件随机场):是一个判别模型,用于解决标注偏差问题,使用P(Y|X)建模,为全局归一化
适用领域:词性标注、分词、命名实体识别等
以命名实体为例:

损失计算:
lg P ( Y ∣ X ) = − l g e s ( X , Y ) ∑ y ‾ ϵ Y x e s ( X , y ‾ ) = − S ( X , y ) + lg ∑ y ‾ ϵ Y x e s ( X , y ‾ ) \lg P(Y|X) = -lg \frac{e^s(X,Y)}{\sum_{\overline{y}\epsilon Y_x}{e^s(X,\overline y)}} = - S(X, y) + \lg\sum_{\overline{y}\epsilon Y_x}{e^s(X,\overline y)} lgP(Y∣X)=−lg∑yϵYxes(X,y)es(X,Y)=−S(X,y)+lgyϵYx∑es(X,y)
推荐一个视频讲解,全程手写推导,讲得很细
机器学习-白板推导系列(十七)-条件随机场CRF(Conditional Random Field)
数据介绍
数据集用的是论文【ACL 2018Chinese NER using Lattice LSTM】中从新浪财经收集的简历数据。每一句话用换行进行隔开。
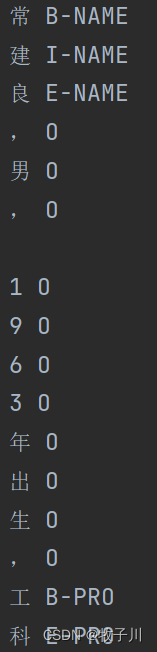


图2 数据样式
模型准备
方法一:使用ptorch库自带的CRF库,其CRF库关键函数介绍链接
def forward(self, sentence, tags=None, mask=None):# sentence=(batch, seq_len) tags=(batch, seq_len) masks=(batch, seq_len)# 1. 从 sentence 到 Embedding 层embeds = self.word_embeds(sentence).permute(1, 0, 2) # shape [seq_len, batch_size, embedding_size]# 2. 从 Embedding 层到 Bi-LSTM 层# Bi-lstm 层的隐藏节点设置# 隐藏层就是(h_0, c_0) num_directions = 2 if self.bidirectional else 1# h_0 的结构:(num_layers*num_directions, batch_size, hidden_size)self.hidden = (torch.randn(2, sentence.shape[0], self.hidden_dim // 2, device=self.device),torch.randn(2, sentence.shape[0], self.hidden_dim // 2, device=self.device))# input=(seq_length, batch_size, embedding_num)# output(lstm_out)=(seq_length, batch_size, num_directions * hidden_size)# h_0 = (num_layers*num_directions, batch_size, hidden_size)lstm_out, self.hidden = self.lstm(embeds, self.hidden)# 3. 从 Bi-LSTM 层到全连接层# 从 Bi-lstm 的输出转为 target_size 长度的向量组(即输出了每个 tag 的可能性)# 输出 shape=(seq_length, batch_size, len(tag_to_ix))lstm_feats = self.linear(lstm_out)# 4. 全连接层到 CRF 层if tags is not None:# 训练用if mask is not None:loss = -1. * self.crf(emissions=lstm_feats.permute(1, 0, 2), tags=tags, mask=mask, reduction='mean')# outputs=(batch_size,) 输出 log 形式的 likelihoodelse:loss = -1. * self.crf(emissions=lstm_feats.permute(1, 0, 2), tags=tags, reduction='mean')return losselse:# 测试if mask is not None:prediction = self.crf.decode(emissions=lstm_feats.permute(1, 0, 2), mask=mask)else:prediction = self.crf.decode(emissions=lstm_feats.permute(1, 0, 2))return prediction
方法2:编写CRF实现代码
def argmax(vec):"""返回 vec 中每一行最大的那个元素的下标"""# return the argmax as a python int_, idx = torch.max(vec, 1)# 获取该元素:tensor只有一个元素才能调用item方法return idx.item()def log_sum_exp(vec, device):"""vec 维度为 1*5Compute log sum exp in a numerically stable way for the forward algorithm前向算法是不断累积之前的结果,这样就会有个缺点指数和累积到一定程度后,会超过计算机浮点值的最大值,变成inf,这样取log后也是inf为了避免这种情况,用一个合适的值clip去提指数和的公因子,这样就不会使某项变得过大而无法计算计算一维向量 vec 与其最大值的 log_sum_exp"""max_score = vec[0, argmax(vec)] # max_score的维度为1max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) # 维度为 1*5return max_score.to(device) + torch.log(torch.sum(torch.exp(vec - max_score_broadcast))).to(device)class BiLSTM_CRF(nn.Module):def __init__(self, vocab_size, tag_to_index, embedding_dim, hidden_dim):# 调用父类的initsuper(BiLSTM_CRF, self).__init__()self.embedding_dim = embedding_dim # word embedding dim 嵌入维度: 词向量维度self.hidden_dim = hidden_dim # Bi-LSTM hidden dim 隐藏层维度self.vocab_size = vocab_size # 词汇量大小self.tag_to_index = tag_to_index # 标签转下标的词典self.target_size = len(tag_to_index) # 输出维度:目标取值范围大小,标签预测类别数self.device = "cuda:0" if torch.cuda.is_available() else "cpu"''' Embedding 的用法A simple lookup table that stores embeddings of a fixed dictionary and size.This module is often used to store word embeddings and retrieve them using indices. The input to the module is a list of indices, and the output is the corresponding word embeddings.一个简单的查找表,用于存储固定字典和大小的嵌入。该模块通常用于存储词嵌入并使用索引检索它们。模块的输入是索引列表,输出是相应的词嵌入。requires_grad: 用于说明当前量是否需要在计算中保留对应的梯度信息'''self.word_embeds = nn.Embedding(vocab_size, embedding_dim)'''embedding_dim:特征维度hidden_dim:隐藏层层数num_layers:循环层数bidirectional:是否采用 Bi-LSTM(前向LSTM+反向LSTM)'''self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2, num_layers=1, bidirectional=True)# 将 Bi-LSTM 提取的特征向量映射到特征空间,即经过全连接得到发射分数self.hidden2tag = nn.Linear(hidden_dim, self.target_size)# 转移矩阵的参数初始化,transitions[i,j]代表的是从第j个tag转移到第i个tag的转移分数# 转移矩阵是随机的,在网络中会随着训练不断更新self.transitions = nn.Parameter(torch.randn(self.target_size, self.target_size))# 初始化所有其他 tag 转移到 START_TAG 的分数非常小,即不可能由其他 tag 转移到 START_TAG# 初始化 STOP_TAG 转移到所有其他 tag 的分数非常小,即不可能由 STOP_TAG 转移到其他 tag# 转移矩阵: 列标 转 行标# 规定:其他 tag 不能转向 start,stop 也不能转向其他 tagself.transitions.data[self.tag_to_index[START_TAG], :] = -10000 # 从任何标签转移到 START_TAG 不可能self.transitions.data[:, self.tag_to_index[STOP_TAG]] = -10000 # 从 STOP_TAG 转移到任何标签不可能# 初始化 hidden layerself.hidden = self.init_hidden()def init_hidden(self):# 初始化 Bi-LSTM 的参数 h_0, c_0return (torch.randn(2, 1, self.hidden_dim // 2).to(self.device),torch.randn(2, 1, self.hidden_dim // 2).to(self.device))def _get_lstm_features(self, sentence):# 通过 Bi-LSTM 提取特征self.hidden = self.init_hidden()embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)'''默认参数意义:input_size,hidden_size,num_layershidden_size : LSTM在运行时里面的维度。隐藏层状态的维数,即隐藏层节点的个数torch里的LSTM单元接受的输入都必须是3维的张量(Tensors):第一维体现的每个句子的长度,即提供给LSTM神经元的每个句子的长度,如果是其他的带有带有序列形式的数据,则表示一个明确分割单位长度,第二维度体现的是batch_size,即每一次给网络句子条数第三维体现的是输入的元素,即每个具体的单词用多少维向量来表示'''lstm_out, self.hidden = self.lstm(embeds, self.hidden)lstm_out = lstm_out.view(len(sentence), self.hidden_dim)lstm_feats = self.hidden2tag(lstm_out)return lstm_featsdef _score_sentence(self, feats, tags):"""CRF 的输出,即 emit + transition scores"""# 计算给定 tag 序列的分数,即一条路径的分数score = torch.zeros(1).to(self.device)tags = torch.cat([torch.tensor([self.tag_to_index[START_TAG]], dtype=torch.long).to(self.device), tags])# 转移 + 前向for i, feat in enumerate(feats):# 递推计算路径分数:转移分数 + 发射分数score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]score = score + self.transitions[self.tag_to_index[STOP_TAG], tags[-1]]return scoredef _forward_alg(self, feats): # 预测序列的得分,就是 Loss 的右边第一项"""前向算法:feats 表示发射矩阵(emit score),是 Bi-LSTM 所有时间步的输出 意思是经过 Bi-LSTM 的 sentence 的每个 word 对应于每个 label 的得分"""# 通过前向算法递推计算 alpha 初始为 -10000init_alphas = torch.full((1, self.target_size), -10000.).to(self.device) # 用-10000.来填充一个形状为[1,target_size]的tensor# 初始化 step 0 即 START 位置的发射分数,START_TAG 取 0 其他位置取 -10000 start 位置的 alpha 为 0# 因为 start tag 是4,所以tensor([[-10000., -10000., -10000., 0., -10000.]]),# 将 start 的值为零,表示开始进行网络的传播,init_alphas[0][self.tag_to_index[START_TAG]] = 0.# 将初始化 START 位置为 0 的发射分数赋值给 previous 包装进变量,实现自动反向传播previous = init_alphas# 迭代整个句子for obs in feats:# The forward tensors at this timestep# 当前时间步的前向 tensoralphas_t = []for next_tag in range(self.target_size):# 取出当前tag的发射分数,与之前时间步的tag无关'''Bi-LSTM 生成的矩阵是 emit score[观测/发射概率], 即公式中的H()函数的输出CRF 是判别式模型emit score: Bi-LSTM 对序列中每个位置的对应标签打分的和transition score: 是该序列状态转移矩阵中对应的和Score = EmissionScore + TransitionScore'''# Bi-LSTM的生成矩阵是 emit_score,维度为 1*5emit_score = obs[next_tag].view(1, -1).expand(1, self.target_size).to(self.device)# 取出当前 tag 由之前 tag 转移过来的转移分数trans_score = self.transitions[next_tag].view(1, -1)# 当前路径的分数:之前时间步分数 + 转移分数 + 发射分数next_tag_var = previous.to(self.device) + trans_score.to(self.device) + emit_score.to(self.device)# 对当前分数取 log-sum-expalphas_t.append(log_sum_exp(next_tag_var, self.device).view(1))# 更新 previous 递推计算下一个时间步previous = torch.cat(alphas_t).view(1, -1)# 考虑最终转移到 STOP_TAGterminal_var = previous + self.transitions[self.tag_to_index[STOP_TAG]]# 计算最终的分数scores = log_sum_exp(terminal_var, self.device)return scores.to(self.device)def _viterbi_decode(self, feats):"""Decoding的意义:给定一个已知的观测序列,求其最有可能对应的状态序列"""# 预测序列的得分,维特比解码,输出得分与路径值backpointers = []# 初始化 viterbi 的 previous 变量init_vvars = torch.full((1, self.target_size), -10000.).cpu() # 这就保证了一定是从START到其他标签init_vvars[0][self.tag_to_index[START_TAG]] = 0# 第 i 步的 forward_var 保存第 i-1 步的维特比变量previous = init_vvarsfor obs in feats:# 保存当前时间步的回溯指针bptrs_t = []# 保存当前时间步的 viterbi 变量viterbivars_t = []for next_tag in range(self.target_size):# 其他标签(B,I,E,Start,End)到标签next_tag的概率# 维特比算法记录最优路径时只考虑上一步的分数以及上一步 tag 转移到当前 tag 的转移分数# 并不取决与当前 tag 的发射分数next_tag_var = previous.cpu() + self.transitions[next_tag].cpu() # previous 保存的是之前的最优路径的值# 找到此刻最好的状态转入点best_tag_id = argmax(next_tag_var) # 返回最大值对应的那个tag# 记录点bptrs_t.append(best_tag_id)viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))# 更新 previous,加上当前 tag 的发射分数 obs# 从 step0 到 step(i-1) 时 5 个序列中每个序列的最大 scoreprevious = (torch.cat(viterbivars_t).cpu() + obs.cpu()).view(1, -1)# 回溯指针记录当前时间步各个 tag 来源前一步的 tagbackpointers.append(bptrs_t)# 考虑转移到 STOP_TAG 的转移分数# 其他标签到STOP_TAG的转移概率terminal_var = previous.cpu() + self.transitions[self.tag_to_index[STOP_TAG]].cpu()best_tag_id = argmax(terminal_var)path_score = terminal_var[0][best_tag_id]# 通过回溯指针解码出最优路径best_path = [best_tag_id]# best_tag_id 作为线头,反向遍历 backpointers 找到最优路径for bptrs_t in reversed(backpointers):best_tag_id = bptrs_t[best_tag_id]best_path.append(best_tag_id)# 去除 START_TAGstart = best_path.pop()assert start == self.tag_to_index[START_TAG] # Sanity checkbest_path.reverse() # 把从后向前的路径正过来return path_score, best_pathdef neg_log_likelihood(self, sentence, tags):# CRF 损失函数由两部分组成,真实路径的分数和所有路径的总分数。# 真实路径的分数应该是所有路径中分数最高的。# log 真实路径的分数/log所有可能路径的分数,越大越好,构造 crf loss 函数取反,loss 越小越好feats = self._get_lstm_features(sentence) # 经过LSTM+Linear后的输出作为CRF的输入# 前向算法分数forward_score = self._forward_alg(feats) # loss的log部分的结果# 真实分数gold_score = self._score_sentence(feats, tags) # loss的后半部分S(X,y)的结果# log P(y|x) = forward_score - gold_scorereturn forward_score - gold_score# 这里 Bi-LSTM 和 CRF 共同前向输出def forward(self, sentence):"""重写原 module 里的 forward"""sentence = sentence.reshape(-1)# 通过 Bi-LSTM 提取发射分数lstm_feats = self._get_lstm_features(sentence)# 根据发射分数以及转移分数,通过 viterbi 解码找到一条最优路径score, tag_seq = self._viterbi_decode(lstm_feats)return score, tag_seq
模型预测
注:模型只训练了一轮,预测结果与实际会有差异。
方法一:


源码获取
Bi-LSTM-CRF 实体识别
硬性的标准其实限制不了无限可能的我们,所以啊!少年们加油吧!
相关文章:
nlp系列(6)文本实体识别(Bi-LSTM+CRF)pytorch
模型介绍 LSTM:长短期记忆网络(Long-short-term-memory),能够记住长句子的前后信息,解决了RNN的问题(时间间隔较大时,网络对前面的信息会遗忘,从而出现梯度消失问题,会形成长期依赖…...

zookeeper-3.7.1集群
1.下载&解压安装包apache-zookeeper-3.7.1-bin.tar.gz 解压到/app/ &改名zookeeper-3.7.1 [rootnode1 app]# tar -zxvf apache-zookeeper-3.7.1-bin.tar.gz -C /app/ [rootnode1 app]# mv apache-zookeeper-3.7.1-bin zookeeper-3.7.1 ---- 删除docs [rootnode1…...

ubuntu上安装firefox geckodriver 实现爬虫
缘由:当时在windows 上运行chrom 的时候 发现要找到 浏览器和 webdirver 相匹配的 版本比较麻烦,当时搞了大半天才找到并安装好。 这次在ubuntu上尝试用firefox 实现爬虫 文章分为三个部分: 环境搭建浏览器弹窗输入用户名,密码的…...
)
【Matlab】基于长短期记忆网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于长短期记忆网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 "基于长短期记忆网络(Long Short-Term Memory, LSTM)的时间序列预测"是一种使用LSTM神经网络来预测时间…...
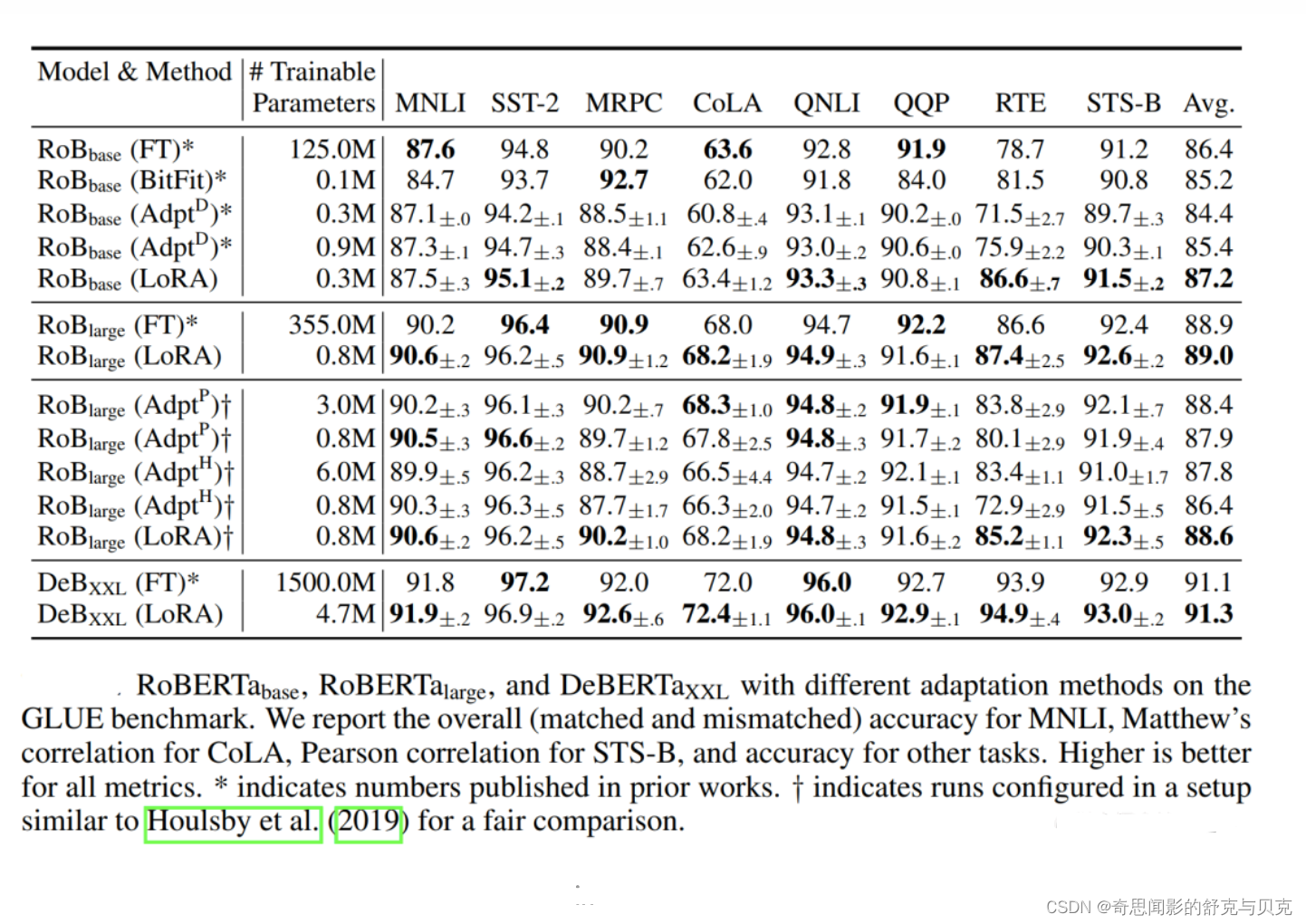
[NLP]LLM高效微调(PEFT)--LoRA
LoRA 背景 神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank),因…...

vue3 vant上传图片
在 Vue 3 中使用 Vant 组件库进行图片上传,您可以使用 Vant 的 ImageUploader 组件。ImageUploader 是 Vant 提供的图片上传组件,可以方便地实现图片上传功能。 以下是一个简单的示例,演示如何在 Vue 3 中使用 Vant 的 ImageUploader 组件进行…...

深入理解linux内核--内存管理
RAM的某些部分永久分配给内核, 来存放内核代码及静态内核数据结构。 RAM的其余部分称为动态内存, 这不仅是进程所需的宝贵资源, 也是内核本身所需的宝贵资源。页框管理 Intel的Pentinum处理器可采用两种不同的页框大小: 4KB&…...
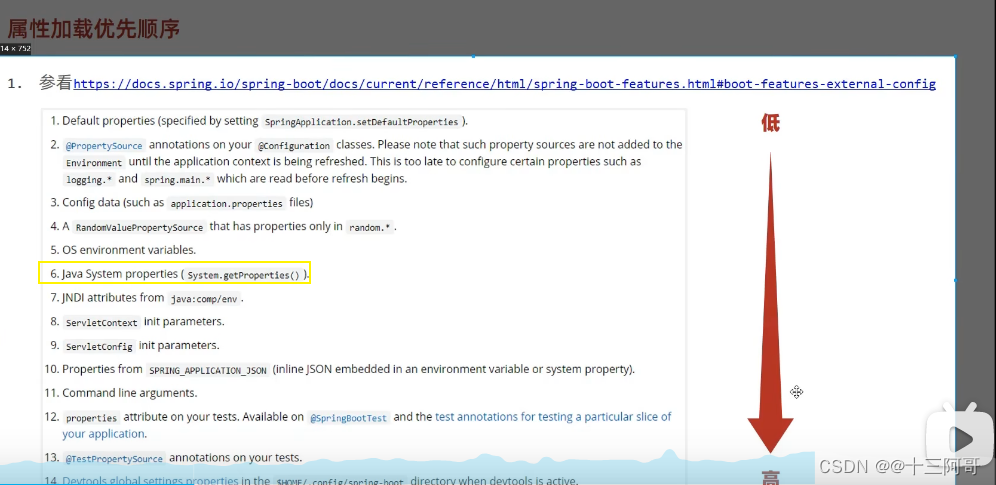
SpringBoot热部署的开启与关闭
1、 开启热部署 (1)导入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-devtools</artifactId> </dependency>(2)设置 此时就搞定了。。。 2、…...
)
k8s集群部署(使用kubeadm部署工具进行快速部署,相关对应版本为docker20.10.0+k8s1.23.0+flannel)
1. 安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 一台或多台机器,操作系统 CentOS7.x-86_x64硬件配置:2GB或更多RAM,2个CPU或更多CPU,硬盘20GB或更多可以访问外网,需要拉…...

20230729 git github gitee
1.gitee与gitHub概念? Gitee(码云)是开源中国社区推出的代码托管协作开发平台,支持Git和SVN,提供免费的私有仓库托管。Gitee专为开发者提供稳定、高效、安全的云端软件开发协作平台,无论是个人、团队、或是…...

php建造者模式
一,建造者模式,也叫做生成器模式,是创建设计模式的一种,它能将一个复杂的对象的创建过程分离开来,使你能够分步骤的创建对象。建造者模式也允许你使用相同的建造代码创造出不同类型和形式的对象。 建造者模式一般包括四…...

linux---》用户操作/su和sudo/普通权限/特殊权限/解压压缩/软件管理,rpm和yum/源码安装nginx
用户操作 ####创建用户####1 创建sa和sutdents组 groupadd sa groupadd students # 2 用户可以属于多个组,只能属于一个主组,附加组可以有多个 G useradd -u 5001 -g students -G sa -c "注释" -s /bin/bash lqz666 # 3 设置密码 passwd lqz6…...

tinkerCAD案例:20. Simple Button 简单按钮和骰子
文章目录 tinkerCAD案例:20. Simple Button 简单按钮Make a Trick Die tinkerCAD案例:20. Simple Button 简单按钮 Project Overview: 项目概况: This is a series of fun beginner level lessons to hone your awesome Tinkercad skills a…...

Java - 为什么要用BigDecimal?
🤔️为什么要用BigDecimal? 当然是因为使用Double计算,在某些对精度要求很高的场景下会出现问题💀不信你看⤵️ Test void test12() {// 丢失精度double result 0.2 0.1;System.out.println(result); // 输出结果为 0.300000000…...
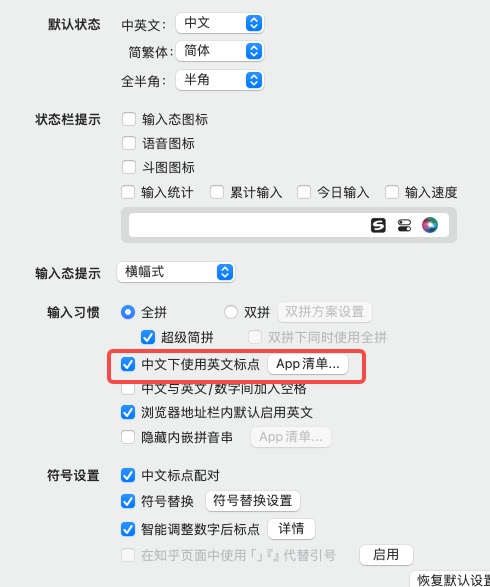
mac 删除自带的ABC输入法保留一个搜狗输入法,搜狗配置一下可以减少很多的敲击键盘和鼠标点击次数
0. 背景 对于开发者来说,经常被中英文切换输入法所困扰,我这边有一个方法,删除mac默认的ABC输入法 仅仅保留搜狗一个输入法,配置一下搜狗输入:哪些指定为英文输入,哪些指定为中文输入(符号也可…...

JiaYu说:如何做好IT类的技术面试?
IT类的技术面试 面试IT公司的小技巧IT技术面试常见的问题嵌入式技术面试嵌入式技术面试常见的问题嵌入式软件/硬件面试题 JiaYu归属嵌入式行业,所以这里只是以普通程序员的角度去分析技术面试的技巧 当然,也对嵌入式技术面试做了小总结,友友们…...

RL 实践(6)—— CartPole【REINFORCE with baseline A2C】
本文介绍 REINFORCE with baseline 和 A2C 这两个带 baseline 的策略梯度方法,并在 CartPole-V0 上验证它们和无 baseline 的原始方法 REINFORCE & Actor-Critic 的优势参考:《动手学强化学习》完整代码下载:7_[Gym] CartPole-V0 (REINFO…...
Python numpy库的应用、matplotlib绘图、opencv的应用
numpy import numpy as npl1 [1, 2, 3, 4, 5]# array():将列表同构成一个numpy的数组 l2 np.array(l1) print(type(l2)) print(l2) # ndim : 返回数组的轴数(维度数) # shape:返回数组的形状,用元组表示;元组的元素…...

SpringBoot 如何进行 统一异常处理
在Spring Boot中,可以通过自定义异常处理器来实现统一异常处理。异常处理器能够捕获应用程序中抛出的各种异常,并提供相应的错误处理和响应。 Spring Boot提供了ControllerAdvice注解,它可以将一个类标记为全局异常处理器。全局异常处理器能…...

数据库索引优化与查询优化——醍醐灌顶
索引优化与查询优化 哪些维度可以进行数据库调优 索引失效、没有充分利用到索引-一索引建立关联查询太多JOIN (设计缺陷或不得已的需求) --SQL优化服务器调优及各个参数设置 (缓冲、线程数等)–调整my.cnf数据过多–分库分表 关于数据库调优的知识点非常分散。不同的 DBMS&a…...
)
Python基础语法:生成器 generator(yield)
一、简介根据指定的规则循环生成数据,当条件不成立时则生成数据结束。数据不是一次性全部生成出来,而是使用一个,再生成一个,好处是可以节约大量的内存。就像设计模式中的懒汉式。适合处理大数据或流数。生成器是一种特殊的迭代器…...

鸿蒙系统微博应用锁常见问题解答
为微博设置应用锁后,不少用户会有各种疑问:忘记密码怎么办?会不会影响消息推送?能不能只锁定某些功能?应用锁耗电吗?本文将针对这些高频问题逐一解答,帮助您更好地使用鸿蒙系统(Harm…...
)
Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析)
更多请点击: https://intelliparadigm.com 第一章:Midjourney锐化效果失效真相(2024官方未公开的渲染管线瓶颈解析) 自2024年V6.2版本起,大量用户反馈 --stylize 与 --sharp 参数组合下图像边缘锐化效果显著弱化&am…...

如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南
如何用Python脚本榨干百度网盘带宽:pan-baidu-download终极指南 【免费下载链接】pan-baidu-download 百度网盘下载脚本 项目地址: https://gitcode.com/gh_mirrors/pa/pan-baidu-download 在数字时代,百度网盘已成为我们存储和分享大型文件的默认…...

Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Hermes Agent 框架如何对接 Taotoken 作为自定义模型供应商并配置环境变量 Hermes Agent 是一个流行的 AI 代理开发框架࿰…...

Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken用量看板功能详解,助你洞察团队AI资源消耗模式 对于技术管理者或项目负责人而言,清晰了解团队的AI…...

量子机器学习与傅里叶分析:革新期权定价的混合计算范式
1. 项目概述:当量子机器学习遇见金融定价在金融工程的核心地带,期权定价一直是个计算密集型的硬骨头。传统的蒙特卡洛模拟虽然通用,但为了达到足够的精度,动辄需要百万甚至千万次的路径模拟,计算成本高昂。近年来&…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

收藏|2026年大模型算法岗崛起!程序员小白入门高薪赛道全攻略
前些年,算法岗位一直稳居技术圈高薪行列,无数程序员争相入局,也成为计算机专业毕业生求职首选方向。 伴随大模型技术飞速迭代落地,行业就业格局迎来重大变革。如今含金量最高、人才缺口最大、长期发展潜力顶尖的岗位,已…...