【Linux】进程通信 — 共享内存
文章目录
- 📖 前言
- 1. 共享内存
- 2. 创建共享内存
- 2.1 ftok()创建key值:
- 2.2 shmget()创建共享内存:
- 2.3 ipcs指令:
- 2.4 shmctl()接口:
- 2.5 shmat()/shmdt()接口:
- 2.6 共享内存没有访问控制:
- 2.7 通过管道对共享内存进行控制:
- 3. 相关概念
📖 前言
上一章我们由进程通信,引入并讲述了管道,匿名管道和命名管道和匿名管道。本章我们将继续讲解进程通信的另一种方式,通过共享内存的方式来进行进程间的通信。还要学习几个系统调用接口,并用代码实现两个进程通过共享内存来进行通信。目标已经确定,接下来就要搬好小板凳,准备开讲了…🙆🙆🙆🙆
本章讲的是system V的共享内存。
1. 共享内存
之前我们学习进程地址空间时就已经对进程地址空间的构成有了相对的认识【进程地址空间 - 复习】:

- 我们知道堆栈相对而生,堆从低地址向高地址生长,栈从高地址向低地址生长,而在这两块空间之间的则是
共享区。 - 堆栈之间的区域特别大,堆栈之间的区域称为共享区,其中共享库就在这里。
假设有种接口:
- 能在物理内存创建空间。
- 通过两个进程调用接口,然后物理内存中的空间映射到自己的地址空间上,然后将空间的起始地址返回给用户,此时用户就能通过页表找到物理内存的空间。
此时两个进程各自都完成了,第一步创建共享内存,第二步分别将共享内存挂接到各自的进程上下文里面。
- 进程间通信的前提是:先让不同的进程,看到同一份资源!
- 共享内存是一种进程间通信机制,它允许多个进程共享同一块物理内存区域(就能同时看到一份资源)。
- 当一个进程向共享内存写入数据时,实际上是将数据直接写入到共享内存所对应的物理内存中。
- 其他进程可以通过读取相同的共享内存区域来获取已写入的数据。
优点:
- 与其他进程间通信方式(如管道、消息队列等)不同。
- 共享内存避免了数据的复制和传输过程,因此具有较高的效率。
- 它可以提供快速的数据交换,特别适用于需要频繁共享大量数据的进程间通信场景。
2. 创建共享内存
2.1 ftok()创建key值:
- 共享内存存在哪里?
- 内核中 —— 内核会给我们维护共享内存的结构!
- 共享内存也要被管理起来!一定是先描述,再组织!
-
- 系统中可能有很多对进程都在用共享内存通信,所以操作系统也要将它们管理起来。
- 我怎么知道,这个共享内存是存在还是不存在?
- 先有方法,标识共享内存的唯一性!
- 共享内存,在内核中,让不同的进程看到同一份共享内存。
- 做法是:让他们拥有同一个key即可!
解释:
- 每个共享内存都是由一个唯一的key值来标识的。在操作系统中,共享内存是进程间进行通信的一种方式,它允许多个进程共享同一块物理内存区域。
- 为了实现这种共享,操作系统会给每个共享内存区域分配一个唯一的key值来标识它,其他进程可以通过这个key值来访问并操作该共享内存区域。
- 这样就可以实现多个进程之间的数据交换和共享。
在共享内存里只要保证这个key是唯一的就可以了。至于这个key是多少不重要。
创建key值的函数:

Linux系统给定了ftok接口,将用户提供的pathname工作路径,以及proj_id项目编号转换为一个共享内存的key(其实就是int类型)。
- 底层会将第一个参数对应路径文件的
inode和指定的项目id这两个数字做组合形成一个唯一值,返回给一个key。 - 底层是一些列的算法设计,相当于是帮我们构建具有唯一性的数字就可以了。
返回值:

成功了返回key值,失败了就返回-1。
2.2 shmget()创建共享内存:
使用前提是要有一个唯一的key值:

- 第二个参数建议设置成页(4KB)的整倍数:
- 操作系统和磁盘lO的基本单位大小是4KB。
- 从磁盘拷贝到内存是以4KB为单位拷贝的。
- 所以共享内存在申请大小时,也一定是4KB的整数倍。
- 操作系统只会按照整4KB来申请共享内存,是向上取整。
如果我们申请的是4097,那么操作系统申请的是8KB,但是我们只能用4097,因为只要了这么多。
-
shmflg的设置:
IPC_CREAT:创建共享内存,如果已经存在,就获取之,不存在就创建之。-
获取:可以获取成功,但是不知道这个共享内存,是本进程创建还是别的进程创建的拿过来的。
IPC_EXCL:必须配合IPC_CREAT使用(用按位或|配合使用),如果不存在指定的共享内存,创建之,如果存在了,出错返回。-
核心作用: 可以保证,如果shmget函数调用成功,一定是一个全新的share memory(共享内存)。
-
- 如果这两个选项合着一起配合使用,一起传, 只要函数调用成功了,得到的一定是个全新的共享内存。
0666或权限值:指定共享内存的访问权限。这些权限值使用八进制表示,例如0666表示可读可写权限。
返回值:

如果成功的话返回一个标志符号,如果失败的话返回-1,errno被设置。
- key值是由谁提供:
key值得由用户来提供。- 如果key值是由操作系统统一提供的话:
-
- 那么调用
shmget接口,获取共享内存的时候,操作系统给一个key值。
- 那么调用
-
- 另一个进程如何知道该进程key值呢??是不可能知道的。
-
- 那么就不能确定唯一性了,那么不同的应用程序可能会得到相同的key。
-
- 这样一来,就有可能导致两个或多个应用程序之间共享同一个共享内存段。
-
- 这样的共享可能会引发数据混乱、冲突以及安全性问题。
- 如果key值是由用户提供的话:
-
- 那么一个进程就可以提供一个key值让操作系统帮它创建一个共享内存,并且约定好让其他进程也使用同样的key值。
-
- 这二者只要有一个创建了共享内存,
能够将key值设置在内核里,那另一个进程则可以用同样的key值找,就可以看到同一个共享内存了。
- 这二者只要有一个创建了共享内存,
-
- 这就叫做看到了同一份共享资源了。
2.3 ipcs指令:
通过上述讲解,我们只要获取到唯一的key值,调用shmget函数就能获得共享内存了,创建好了我们怎样才能知道有哪些IPC资源呢?
看一下ipcs指令的几个选项:
ipcs -c #查看消息队列/共享内存/信号量
ipcs -s #单独查看信号量
ipcs -q #单独查看消息队列
ipcs -m #单独查看共享内存
ipcs -m查看shm list。

- key值是十六进制,我们创建出来看到的则是十进制。
- nattch是挂接上的进程的数量。
- bytes是申请的共享内存大小。

ipcrm -m 删除共享内存:
- 只要在指令后跟上自己要删除的共享内存的shmid值就可以了

如果不显示删除共享内存那么就只能通过重启云主机的方式来删除共享内存了。
为什么删除共享内存要用shmid而不用key呢?
- key是操作系统中用来标识共享内存唯一性的, 在用户层用的是
shmid。 - 在用户层访问共享内存只能用数字
shmid。
2.4 shmctl()接口:
shmctl这个函数可以用于操作共享内存:

- 第一个参数:想对哪个共享内存做操作。
- 第二个参数:想对这个共享内存做什么操作。
- 第三个参数:如果
IPC_RMID如果被设置了,shmid_ds设置成nullptr就可以了,还有一些其他的属性设置。
第二个参数可以是:
IPC_STAT:用于获取共享内存段的状态信息,包括共享内存段大小、访问权限等。IPC_SET:用于设置共享内存段的状态信息,如更改访问权限、起始地址等。IPC_RMID:用于删除共享内存段,释放相关的资源。
此外,第二个参数还可以与其他标志进行按位或操作,以指定额外的选项或标志,例如:
IPC_INFO:用于获取当前共享内存资源的统计信息。SHM_INFO:用于获取当前系统上共享内存段的信息。SHM_STAT:用于获取当前共享内存段的详细信息。
2.5 shmat()/shmdt()接口:

- at是attach的简写,把一个共享内存附在进程上。
- dt是detach的简写,把一个共享内存从进程上脱离下来(去关联)。
返回值:

- 因为
shmat函数的返回值是一个void*类型的指针,所以我们就可以像使用malloc一样的方式使来挂接共享内存了。 - 随后对这个共享内存的操作就像平时使用数组一样的方式来使用了。
同样的道理另一个进程也需要挂接这个共享内存才能实现两个进程通过共享内存来进行通信。
注意:
- 共享内存是一种特殊的内存区域,可以由多个进程同时访问。
- 尽管共享内存由一个进程创建,但它并不属于任何一个特定的进程。
2.6 共享内存没有访问控制:
在我们之前的学习中知道,管道是有访问控制的进程通信方式,当写端没有写入数据的时候(空管道),读端的read接口会进行等待,直到有管道中有数据写入。
而共享内存的申请更想是我们直接向操作一个malloc出来的空间一样,进程只要有权限,就可以直接拿来用,不向管道那样是个文件,还要通过read/write接口来访问。所以操作系统没有办法帮我们进行访问控制
管道:
- 首先将数据从外设拷贝到进程上下文代码里面。
- 再把代码拷贝到管道里面,再调用
write把数据拷贝到另一个进程的上下文。 - 再继续还要将数据拷贝到外设里,一共至少要经历四次拷贝。

共享内存:
- 写到共享内存里,对方立马能看到。
- 用共享内存,如果不考虑外设,最多拷贝一次,一方写入,另一方立马能看到。

2.7 通过管道对共享内存进行控制:
Log.hpp:
#pragma once#include <iostream>
#include <ctime>std::ostream &Log()
{std::cout << "For Debug | " << "timestamp: " << (uint64_t)time(nullptr) << " | ";return std::cout;
}
Comm.hpp:
#pragma once#include <iostream>
#include <cstdio>
#include <cstring>
#include <cerrno>
#include <cstdlib>
#include <cassert>
#include <sys/types.h>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/fcntl.h>
#include "Log.hpp"using namespace std;#define PATH_NAME "/home/Zh_Ser/linux"
#define PROJ_ID 0x14
#define MEM_SIZE 4096#define FIFO_FILE "./.fifo"// hpp是将头文件和源文件写在一起的方式
// 函数的定义可以放在里面,一般在开源的项目里用key_t CreateKey()
{key_t key = ftok(PATH_NAME, PROJ_ID);if (key < 0){cerr << "ftok: " << strerror(errno) << endl;exit(1);}return key;
}// 创建命名管道
void CreatFifo()
{umask(0);if (mkfifo(FIFO_FILE, 0666) < 0){Log() << strerror(errno) << endl;exit(2);}
}#define READER O_RDONLY
#define WRITER O_WRONLYint Open(const string& filename, int flags)
{return open(filename.c_str(), flags);
}int Wait(int fd)
{uint32_t values = 0;ssize_t s = read(fd, &values, sizeof(values));return s;
}void Signal(int fd)
{uint32_t cmd = 1;int s = write(fd, &cmd, sizeof(cmd));
}void Close(int fd, const string filename)
{close(fd);unlink(filename.c_str());
}
IpcShmCli.cpp:
#include "Comm.hpp"
#include "Log.hpp"// 充当使用共享内存的角色
int main()
{int fd = Open(FIFO_FILE, WRITER);cout << "Client: " << fd << endl;// 创建相同的key值key_t key = CreateKey();Log() << "key: " << key << endl;// 等待Server端先创建共享内存sleep(1);// 获取共享内存int shmid = shmget(key, MEM_SIZE, IPC_CREAT);if (shmid < 0){Log() << "IpcShmCli shmget: " << strerror(errno) << endl;return 2;}// 挂接char* str = (char*)shmat(shmid, nullptr, 0);// sleep(5);// 用它// 用共享内存,竟然没有使用任何系统调用接口// 直接向str空间写入while (true){printf("Please Enter# ");fflush(stdout);// 往共享内存写数据ssize_t s = read(0, str, MEM_SIZE);if (s > 0){str[s] = '\0';}Signal(fd);}// 去关联shmdt(str);// 不需要删除return 0;
}
IpcShmSer.cpp:
#include "Comm.hpp"
#include "Log.hpp"// 创建全新的共享内存
const int flags = IPC_CREAT | IPC_EXCL;// 充当创建共享内存的角色
int main()
{// 创建管道CreatFifo();int fd = Open(FIFO_FILE, READER);cout << "Server: " << fd << endl;assert(fd >= 0);// 创建Keykey_t key = CreateKey();Log() << "key: " << key << endl;Log() << "create share memory begin" << endl;int shmid = shmget(key, MEM_SIZE, flags | 0666);if (shmid < 0){Log() << "IpcShmSer shmget: " << strerror(errno) << endl;return 2;}Log() << "create shm success, shmid: " << shmid << endl;// 1. 将共享内存和自己的进程产生关联attchchar* str = (char*)shmat(shmid, nullptr, 0);Log() << "attach shm: " << shmid << "success" << endl;// 用它// 服务器端直接用while (true){sleep(1);// 在管道当中等,让读端进行等待if (Wait(fd) <= 0) break;// 从共享内存里读数据printf("%s\n", str);}// 2. 去关联shmdt的返回值就是shmat的返回值shmdt(str);Log() << "detach shm: " << shmid << "success" << endl;// 删除shmctl(shmid, IPC_RMID, nullptr);Log() << "delete shm: " << shmid << "success" << endl;Close(fd, FIFO_FILE);return 0;
}
我们先执行服务端,再执行用户端,我们会发现一个现象,服务端会等待,当用户端启动后两边才开始都跑起来。
这是open接口的阻塞等待:(重点)
- 在使用open函数打开一个FIFO(命名管道)时,如果以只
写/读方式打开,并且没有其他进程以读/写模式打开相同的FIFO,则会发生阻塞。 - 这是因为FIFO(命名管道)是基于进程间通信的一种机制,要求读和写操作成对出现。
-
- 对于一个命名管道(FIFO),只有在读端和写端同时打开之后,open函数才会返回。
-
- 也就是说,当一个进程以
只读方式打开FIFO,而另一个进程以只写方式打开相同的FIFO时,两个进程都完成打开操作后,它们之前的阻塞状态将被解除。
- 也就是说,当一个进程以
解释:(重点)
- 当你以
只读方式打开FIFO时,如果没有其他进程以写模式打开相同的FIFO,则读取操作会一直等待。 - 同样地,当你以
只写方式打开FIFO时,如果没有其他进程以读模式打开相同的FIFO,则写入操作会一直等待。 - 只有在读端和写端都成功打开之后,两个进程之间的通信才能顺利进行。
- 这种机制确保了读和写操作的同步,保证了数据的正确传输。
- 因此,当你使用open函数打开一个FIFO时,要确保读端和写端都已经打开,才能结束等待并进行进一步的读写操作。
- 如果是同一个
key,第一个进程用shmget第三个参数是IPC_CREAT,第二个进程用shmget第三个参数是IPC_CREAT | IPC_EXCL,那么第二个进程会创建共享内存失败。
- 如果第一个进程在创建共享内存时使用了
shmget函数的第三个参数为IPC_CREAT,则表示如果共享内存不存在就创建一个新的。 - 而第二个进程在创建共享内存时使用了
IPC_CREAT | IPC_EXCL(即同时设置了IPC_CREAT和IPC_EXCL),表示如果共享内存已经存在,则返回错误。 - 因此,在这种情况下,如果第一个进程已经创建了共享内存,那么第二个进程会因为
IPC_EXCL的设置而无法再次创建共享内存,shmget函数会返回一个错误,第二个进程创建共享内存失败。 - 这样可以确保同一个
key只能被一个进程创建共享内存,防止重复创建和竞争条件的发生。
所以正因为有shmget函数第三个参数这样的机制,我们必要时要让参数是IPC_CREAT的进程等一下参数是IPC_CREAT | IPC_EXCL的进程,让后者先把共享内存创建好了,前者直接获取。
若是前者先创建共享内存,后者一旦判断同一个key值已经创建好了一块共享内存,就会返回错误。除非两个shmget函数第三个参数都是IPC_CREAT,这样无论哪个进程先创建共享内存,另一方都可以获取到对方创建的共享内存。
通过共享内存进程通信结果:
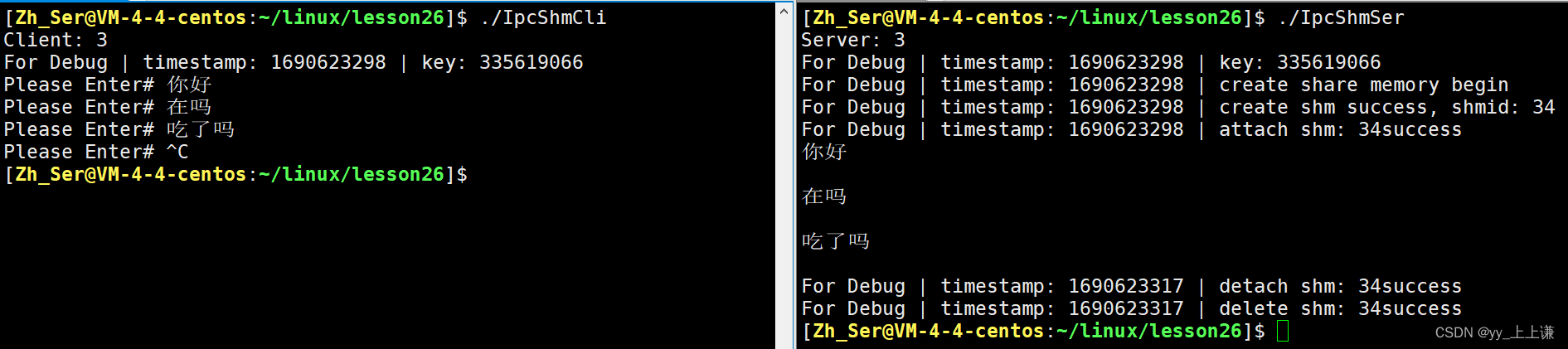
基于共享内存 + 管道的一个访问控制的效果:
- 管道本身提供保护机制,我们自己也做了一次保护机制共享内存 + 管道的机制。
- 如果这两个方案都不提供,裸的共享内存,被双方同时看到。
- 我们两个进程在操作,就可能出现一些来回读写交叉的问题。
- 导致数据不一致的问题,或者是访问控制方面的问题。
3. 相关概念
- 临界资源: 被多个进程能够看到的资源叫做临界资源。
- 如果没有对临界资源进行任何保护,对于临界资源的访问。
- 双方进程在进行访问的时候,就都是乱序的。
- 可能会因为读写交叉而导致的各种乱码、废弃数据、访问控制方面的问题!!
- 临界资源有安全的也有不安全的,取决于内部是否做了保护。
- 临界区: 对多个进程而言,访问临界资源的代码。
- 我的进程代码中,有大量的代码,只有一部分代码,会访问临界资源。
- 两个进程分别对共享资源做读写的代码叫做它们俩的临界区。
- 原子性: 我们把一件事情,要不没做,要么做完了,叫原子性。
- 没有中间状态。
- 互斥: 任何时刻,只允许一个进程,访问临界资源。
相关文章:
【Linux】进程通信 — 共享内存
文章目录 📖 前言1. 共享内存2. 创建共享内存2.1 ftok()创建key值:2.2 shmget()创建共享内存:2.3 ipcs指令:2.4 shmctl()接口:2.5 shmat()/shmdt()接口:2.6 共享内存没有访问控制:2.7 通过管道对共享内存进…...

“从零开始学习Spring Boot:快速搭建Java后端开发环境“
标题:从零开始学习Spring Boot:快速搭建Java后端开发环境 摘要:本文将介绍如何从零开始学习Spring Boot,并详细讲解如何快速搭建Java后端开发环境。通过本文的指导,您将能够快速搭建一个基于Spring Boot的Java后端开发…...
)
行为型-状态模式(State Pattern)
概述 状态模式是一种行为设计模式,它可以让对象在内部状态改变时改变它的行为。简而言之,状态模式允许对象在不同状态下更改其行为,而不需要通过使用大量的条件语句进行手动更改。 优点: 状态模式将与特定状态相关的行为分散到…...

大厂领导为什么喜欢跨层与下属聊天
作为一个在大厂里面浸淫十几年的loser,平时主要精力没用在技术提升上,对于大厂的人情世故各类八卦倒是研究的透彻。 如果你细心观察,会发现一些大的公司里面,领导喜欢跨层与下属去沟通聊天,我待过几家比较大的公司&am…...
三)
Android 面试题 避免OOM(内存优化)三
🔥 OOM介绍(out of memory 内存溢出)🔥 Android和java中都会出现由于不良代码引起的内存泄露,为了使Android应用程序能够快速高效的运行,Android每个应用程序都会有专门Dalvik虚拟机实例来运行,…...

SpringBoot集成Lock4j 底层使用Redission 实现分布锁
Lock4j 在分布式系统中,实现锁的功能对于保证数据一致性和避免并发冲突是非常重要的。Lock4j是一个简单易用的分布式锁框架,而Redisson是一个功能强大的分布式解决方案,可以与Lock4j进行集成。 操作步骤 第一步:添加依赖 首先&…...

TortoiseSVN操作使用
说明 SVN常用于程序代码版本控制,由于业务需求需将生产资料通过SVN进行管控,涉及人员众多,权限分支管理需要细化,特此记录SVN的学习操作. 前言 版本控制是管理信息修改的艺术,它一直是程序员最重要的工具,程序员经常会花时间作出小的修改, 然…...

第五篇-ChatGLM2-6B模型下载
下载chatglm2-6b模型文件 https://huggingface.co/THUDM/chatglm2-6b方法一:huggingface页面直接点击下载 一个一个下载,都要下载方法二:snapshot_download下载文件 可以使用如下代码下载 创建下载环境 conda create --name hfhub pytho…...
)
【Matlab】基于长短期记忆网络的数据分类预测(Excel可直接替换数据)
【Matlab】基于长短期记忆网络的数据分类预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 “基于长短期记忆网络的数据分类预测”是一种利用长短期记忆网络(Long Short-Term Memory, LSTM)进行数据分类任务…...

C++网络编程 TCP套接字基础知识,利用TCP套接字实现客户端-服务端通信
1. TCP 套接字编程流程 1.1 概念 流式套接字编程针对TCP协议通信,即是面向对象的通信,分为服务端和客户端两部分。 1.2 服务端编程流程: 1)加载套接字库(使用函数WSAStartup()),创建套接字&…...

苍穹外卖-day07
苍穹外卖-day07 本项目学自黑马程序员的《苍穹外卖》项目,是瑞吉外卖的Plus版本 功能更多,更加丰富。 结合资料,和自己对学习过程中的一些看法和问题解决情况上传课件笔记 视频:https://www.bilibili.com/video/BV1TP411v7v6/?sp…...

简化Java单元测试数据
用EasyModeling简化Java单元测试 EasyModeling 是我在2021年圣诞假期期间开发的一个 Java 注解处理器,采用 Apache-2.0 开源协议。它可以帮助 Java 单元测试的编写者快速构造用于测试的数据模型实例,简化 Java 项目在单元测试中准备测试数据的工作&…...

P1041 [NOIP2003 提高组] 传染病控制
题目 题目背景 本题是错题,后来被证明没有靠谱的多项式复杂度的做法。测试数据非常的水,各种玄学-做法都可以通过,不代表算法正确。因此本题题目和数据仅供参考。 近来,一种新的传染病肆虐全球。蓬莱国也发现了零星感染者&#…...

TypeScript -- 基础类型
文章目录 TypeScript -- 基础类型let 和 const基本类型写法布尔类型 -- boolean数字类型 -- number字符串类型 -- string数组类型元组类型枚举类型 -- enum任意类型 -- any空值 -- voidNull 和 Undefined不存在的类型 -- never对象 -- object类型断言 TypeScript – 基础类型 1…...

Cookie 与 Session 的作用及区别、结合使用
Cookie的作用 在网站中,http请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。 Cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(Cookie&a…...

【Redis】面试题
1. 为什么要用缓存 1. 提高系统的读写性能。 2. 减轻数据库的压力,防止大量的请求到达数据库,让数据库压力剧增,拖垮数据库。redis数据存储在内存中,高效的数据结构,读写数据比数据库快。 将热点数据存储在redis当中&…...
(学习笔记-硬件结构)CPU如何执行程序?
冯诺依曼模型 冯诺依曼模型主要由五部分组成:运算器、控制器、存储器、输入设备、输出设备。 控制器(Control Unit):从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相…...
 Failed to open/read local data from file/application)
curl: (26) Failed to open/read local data from file/application
Windows10、Windows环境用curl命令上传文件报错: curl: (26) Failed to open/read local data from file/application假设我要上传的文件目录是: F:\我的下载\test.xlsx 错误写法1:使用单引号 curl -X POST "https://xxx/upload&quo…...

2023年深圳杯数学建模 D题 基于机理的致伤工具推断
致伤工具的推断一直是法医工作中的热点和难点。由于作用位置、作用方式的不同,相同的致伤工具在人体组织上会形成不同的损伤形态,不同的致伤工具也可能形成相同的损伤形态。致伤工具品种繁多、形态各异,但大致可分为两类:锐器&…...

DMA传输原理与实现详解(超详细)
DMA(Direct Memory Access,直接内存访问)是一种计算机数据传输方式,允许外围设备直接访问系统内存,而无需CPU的干预。 文章目录 Part 1: DMA的工作原理配置阶段:数据传输阶段: Part 2: DMA数据…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

iPaaS 应用场景深度解析:从系统孤岛到数据自由流动的六大实战路径
写在前面 一个企业的数字化程度越高,系统就越多。系统越多,集成问题就越严重。 这不是假设,而是我们在服务客户过程中反复验证的结论——企业数字化转型的瓶颈,往往不在于"造新系统",而在于"连老系统&q…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

3步解锁网易云音乐NCM加密:让音乐真正属于你
3步解锁网易云音乐NCM加密:让音乐真正属于你 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 还在为下载的网易云音乐只能在特定客户端播放而烦恼吗?当你精心收藏的歌曲被NCM格式"锁"在单一平台时&a…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

为你的Hermes Agent自定义Provider,接入Taotoken多模型池
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为你的Hermes Agent自定义Provider,接入Taotoken多模型池 在构建复杂的AI应用时,开发者常常面临一个核心挑…...

对比不同模型在创意生成任务中的效果与token消耗差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比不同模型在创意生成任务中的效果与token消耗差异 在为一场创意大赛准备素材时,我们面临一个常见的选择:…...
)
DeepSeek安全测试辅助Prompt工程白皮书(含17个CVE靶场验证指令模板)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek安全测试辅助 DeepSeek系列大模型在代码生成、漏洞模式识别与安全上下文理解方面展现出独特优势,可作为安全测试工程师的智能协作者。其对OWASP Top 10、CWE分类体系及常见PoC结构具…...

Nacos CVE-2021-29441漏洞深度解析:User-Agent绕过与鉴权失效
1. 这个漏洞不是“改个Header就能登录”,而是Nacos鉴权体系的一道裂缝CVE-2021-29441这个编号在Nacos社区里曾被轻描淡写地归为“低危”,直到我接手一个金融客户线上告警——他们的Nacos集群在凌晨三点被批量创建了37个高权限用户,所有操作日…...

NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制
NPU跑LLM实战指南:KV Cache动态性如何突破硬件限制 副标题: 从预分配+Attention Mask到三层软件栈,完整解析NPU推理架构 痛点:为什么NPU跑LLM这么难? LLM的生成机制和NPU的硬件特性存在根本冲突: LLM特性 NPU特性 冲突点 逐token生成 固定shape执行 KV Cache动态增长 动…...