【Redis】面试题
1. 为什么要用缓存
1. 提高系统的读写性能。
2. 减轻数据库的压力,防止大量的请求到达数据库,让数据库压力剧增,拖垮数据库。redis数据存储在内存中,高效的数据结构,读写数据比数据库快。
将热点数据存储在redis当中,可以提高热点数据的访问速度。
2. 什么是redis
- redis是开源的,数据存储在内存的非关系型数据库。
- 可以作为数据库存储数据,缓存数据,也可以作为消息中心件。
- redis的网络请求模块是一个单线程的,基于多路复用的性能I/O模型实现redis单线程机制下的数据高速访问。
- 具备数据持久化的功能,提供了AOF和RDB两种数据持久化机制,确保服务宕机之后,数据不会丢失。
- 哨兵机制和Cluster集群模式确保redis的高可用。
3. redis中的线程模型
https://www.cnblogs.com/reecelin/p/13538382.htmlredis开发了自己的文件事件处理器。文件事件处理器由Socket、IO多路复用程序、文件事件分派器,事件处理器四部分组成。IO多路复用程序就是指一个线程处理多个I/O流。多路复用程序会一直监听socket产生的套接字上的连接请求和数据请求,
一旦有请求到达,会触发对应的事件,redis会将这些事件放进一个事件队列,文件事件分派器会对队列中的事件不断处理,
根据事件类型调用不同的文件事件处理器来处理。
因为redis是讲事件放入事件队列中,redis无需一直轮询是否有请求实际发生。这样redis就不会阻塞在某一个特定的套接字上。文件事件处理器由三种:连接应答事件处理器命令请求事件处理器命令回复事件处理器事件种类:AE_READABLE: 客户端连接请求时,连接应答事件与socket的AE_READABLE的事件连接起来客户端命令请求时,命令请求事件与socket的AE_READABLE的事件连接起来AE_WRITEABLE:服务端有数据回传给客户端时,服务端讲命令回复事件处理器与socket的AE_WRITEABLE事件连接起来。示例:当客户端与服务端有需要返回的写命令操作时:客服端发起对redis的连接,redis中的socket的连接监听套接字触发AE_READABLE事件,事件进入队列,文件事件分派器分派事件,连接应答事件处理器与AE_READABLE建立关联。客服端发起写命令,redis中的套接字产生AE_READABLE事件,事件进入队列,文件事件分派器分派事件,命令请求事件处理器与AE_READABLE建立关联
4. redis持久化实现有哪些?有什么区别?
AOF:记录redis的写后命令。优点:数据安全:AOF有三种写回策略,当配置always时,同步写回,基本不会丢失数据。当配置everysec时,每秒写回,不会影响每次的写操作,可能会丢失1s的数据。
缺点:恢复速度:服务宕机之后,AOF需要根据命令执行恢复数据,速度慢。阻碍主线程:当AOF文件过大的时候,主线程需要fork bgrewirteaof线程来进行AOF文件的重写,阻碍主线程。比RDB占用更多的空间RDB:内存快照,记录某一时刻的内存数据。优点: 存放的是内存快照数据,数据恢复速度比AOF快。性能最大化,fork bgsave子线程来完成数据记录,让主线程继续处理命令。缺点:数据安全性低,RDB是每隔一段时间数据持久化,持久化之间服务宕机数据将会丢失。内存快照频率不好把握。如何选择:结合AOF和RDB一起使用。每次内存快照使用RDB方式,在内存快照期间使用AOF方式持久化数据
5. redis哨兵机制
6. redis的Cluster集群模式
7. 为什么使用redis而不是使用memcache
支持的数据类型不同memcache:仅支持key-value的数据结构。redis:不仅支持key-value的string字符串数据结构,还支持hash、set、list、sorted set基本数据结构,还支持Bitmap、HyperLogLog、GEO等数据结构。数据持久化memcache:不支持数据持久化,如果服务宕机,数据就全丢失了。redis:支持AOF\RDB两种方式的数据持久化,可以定期的讲数据持久化到磁盘,当服务宕机后,可以根据持久化数据恢复数据。存储的数据类型大小memcache:单个value的最大值为1mredis:单个value的最大值为512m集群模式memcache:不支持集群模式,如果硬要实现集群模式,需要客户端自己实现,然后往集群中的分片写数据redis:原生就支持集群模式,不需要而外的开发来实现。在企业级的场景下单单进支持key-value的数据结构就已经不能满足业务的需求,所以使用redis。
8. 为什么单线程模型的redis效率那么高?
首先:redis并不是所有的操作都是单线程的。redis中的单线程是指网络IO和数据的读写是单线程的。redis中的数据持久化,异步删除,集群数据同步等是由而外的线程实现的。redis效率为什么那么高?1. 纯内存操作。2. 高效的数据结构。3. 基于非阻塞的多路复用的I/O模型实现的。4. 网络IO和数据读写的单线程可以避免多线程频繁的上下文切换,避免多线程开发的并发控制问题。
9. 为什么redis把数据都存在内存中
1. 提高数据的访问效率。内存的访问效率在几十纳秒到几百纳秒之间,而磁盘的访问效率在几微妙甚至几毫秒之间。
如果数据放到磁盘当中,磁盘I/O将会严重影响redis的响应效率。2. redis提供数据持久化功能,不用担心服务重启数据丢失问题。
10. redis的同步机制
redis提供主从库模式,一个主库可以有多个从库。redis的写操作只会写到主库,为了保持主从库的数据同步,这里就涉及到数据同步。同步机制:主从库之间的第一次同步:
11. redis缓存淘汰机制
不进行淘汰
设置了过期时间的数据淘汰:volatile-ttl:先过期的先淘汰。volatile-random: 随机淘汰。volatile-lru: lru算法淘汰。volatile-lfu:lfu算法淘汰。所有key中数据淘汰:allkeys-random: 随机淘汰。allkeys-lru: lru算法淘汰。allkeys-lfu: lfu算法淘汰。
12. lfu淘汰算法、lfu淘汰算法
13. redis为什么设计成单线程?
1. 多线程处理会涉及到多线程竞争同一个资源的问题,使用单线程可以避免多线程硬气的并发资源访问问题。
2. redis的多路复用I/O使得单线程的redis也能高效的处理客服端请求。
3. redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽,所以没有必要多线程
14. redis实例有哪些阻塞点?
- 集合全量查询和聚合操作:HGETALL、SMEMBERS,以及集合的聚合统计- bigkey删除操作- 清空数据库:FLUSHDB、FLUSHALL操作- AOF日志同步写回- AOF日志重写- 从库加载RDB文件:从库接收到RDB文件之后,会清空数据库并加载RDB文件。
15. 什么是bigkey有什么影响?
占用内存空间很大的key。1. 网络阻塞,获取bigkey时,传输的数据量较大,增加带宽压力。
2. 操作效率低。
3. 删除bigkey可能会阻塞主线程。因为删除bigkey,释放键值对占用的内存空间,操作系统需要向释放掉的内空块
插入一个空闲内存块连表,如果释放大量内存,空间内存块链表操作时间会增加。
17. redis的集群模式有哪些?
18. 是否使用过 Redis Cluster 集群,集群的原理是什么?
19. Redis Cluster 集群方案什么情况下会导致整个集群不可用?
20. Redis 集群架构模式有哪几种?
21. 说说 Redis 哈希槽的概念
22. Redis 常见性能问题和解决方案有哪些
- Master 最好不要做任何持久化工作,如 RDB 内存快照和 AOF 日志文件;
- 如果数据比较重要,某个 Slave 开启 AOF 备份数据,策略设置为每秒同步一次;
- 为了主从复制的速度和连接的稳定性,Master 和 Slave 最好在同一个局域网内;
- 尽量避免在压力很大的主库上增加从库;
- 采用主-从-从集群结构
23.
24. 如果有大量的 key 需要设置同一时间过期,一般需要注意什么?
注意缓存雪崩如果大量key相同时间过期,可能大量请求缺失缓存,都请求到数据库,给数据库造成很大压力,导致数据库崩溃,服务无法正常提供请求。如何解决大量key相同时间过期的问题?给数据的过期时间加一个随机值,分散数据。
25. 缓存和数据库谁先更新呢?
为了保持缓冲和数据库的一致性,有两种数据更新方式1. 先删除缓存、后更新数据库没有并发请求的情况下先删除缓存,如果数据库更新失败,数据库的数据还是旧数据,这个时候可以删除重试解决。有并发请求的情况下A请求删除缓存之后,有B请求进来发现缓存缺失,B又查询数据库重新缓存数据,这个时候A再更新数据库,缓存的数据还是旧的可以采用延迟双删解决2. 先更新数据库,后删除缓存没有并发请求的情况下 数据库更新成功,缓存删除失败,有请求进来读取到的还是旧缓存,可以采用重试缓存删除解决有并发请求的情况下数据库更新成功,缓存还未被删除,期间的请求读取到的还是旧缓存。更新数据库到缓存删除的期间可能会存在数据不一致的问题。那该如何选择那种处理方式呢?两种方案不使用外力作用都没有办法保证数据强一致性要求如果对数据一致性要求没有那么高的情况下,建议使用先更新数据库,后删除缓存为什么呢?1. 因为先删除缓存后更新数据库,可能请求缓存缺少,造成数据库压力增大。2. 先删除缓存,后更新数据库的延迟双删的等待时间不好设置。如果对数据强一致性要求我们就需要先在Redis缓存客户端暂存并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性
26. 怎么提高缓存命中率?
- 数据提前缓存
- 加大内存,缓存更多的数据
- 设置合适的淘汰策略
27. 缓存雪崩、缓存击穿、缓存穿透、缓存预热、缓存更新、缓存降级等问题?
- 缓存雪崩:原因:同一时间大量缓存失效,大量请求同时到达数据库,对数据库造成巨大压力,甚至服务宕机,无法提供使用。解决办法:1. 相同过期时间的key加随机值,分散过期时间。2. 源头上解决:系统实现上加锁或者队列的方式保证不会有大量的请求对数据库一次性的读写。- 缓存击穿:原因:访问非常频繁的数据在缓存中没有,导致大量请求到达数据库解决办法:1. 热点数据不设置过期时间。- 缓存穿透:原因:访问的数据在数据库和缓存中都没有。解决办法: 1. 缓存空值或者缺省值。2. 布隆过滤器
28. redis的数据类型,以及每种数据类型的使用场景?
五大基本数据类型1. string
2. hash
3. set
4. list
5. sorted set我讲下我项目中的使用情况吧
1. string类型,当然是应用最广泛的,比如我的项目发送验证码缓存验证码,接口并发控制等都使用string类型2. hash:key-value的键值对格式。我做的Api接口鉴权底层使用的就是hash格式。redis key为前缀+用户id,hashkey为应用编码
value为权限点编码数组3. set类型:实现用户的共同关注功能、SCARD命令计算用户的关注数。redis key为用户id、value存放关注的用户的id集合,计算两个用户的共同关注,取交集。当然还可以做其他去重、并集、差集等功能。不过Set的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致Redis实例阻塞,你可以从主从集群中选择一个从库,让它专门负责聚合计算,或者是把数据读取到客户端,在客户端来完成聚合统计4. sorted set:排行榜功能。
5. list
6. bitmap:统计用户一年访问页面的总天数其他数据类型
bitmap:统计
hyperLogLog: 统计页面的访问量
GEO:范围统计
29. redis是如何保证高可用的?
- 持久化机制
- 主从模式与哨兵机制
- Redis Cluster集群模式
相关文章:

【Redis】面试题
1. 为什么要用缓存 1. 提高系统的读写性能。 2. 减轻数据库的压力,防止大量的请求到达数据库,让数据库压力剧增,拖垮数据库。redis数据存储在内存中,高效的数据结构,读写数据比数据库快。 将热点数据存储在redis当中&…...
(学习笔记-硬件结构)CPU如何执行程序?
冯诺依曼模型 冯诺依曼模型主要由五部分组成:运算器、控制器、存储器、输入设备、输出设备。 控制器(Control Unit):从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相…...
 Failed to open/read local data from file/application)
curl: (26) Failed to open/read local data from file/application
Windows10、Windows环境用curl命令上传文件报错: curl: (26) Failed to open/read local data from file/application假设我要上传的文件目录是: F:\我的下载\test.xlsx 错误写法1:使用单引号 curl -X POST "https://xxx/upload&quo…...

2023年深圳杯数学建模 D题 基于机理的致伤工具推断
致伤工具的推断一直是法医工作中的热点和难点。由于作用位置、作用方式的不同,相同的致伤工具在人体组织上会形成不同的损伤形态,不同的致伤工具也可能形成相同的损伤形态。致伤工具品种繁多、形态各异,但大致可分为两类:锐器&…...

DMA传输原理与实现详解(超详细)
DMA(Direct Memory Access,直接内存访问)是一种计算机数据传输方式,允许外围设备直接访问系统内存,而无需CPU的干预。 文章目录 Part 1: DMA的工作原理配置阶段:数据传输阶段: Part 2: DMA数据…...
【《React Hooks实战》——指导你使用hook开发性能优秀可复用性高的React组件】
使用React Hooks后,你很快就会发现,代码变得更具有组织性且更易于维护。React Hooks是旨在为用户提供跨组件的重用功能和共享功能的JavaScript函数。利用React Hooks, 可以将组件分成多个函数、管理状态和副作用,并且不必声明类即…...

Ajax详细讲解
Ajax(Asynchronous JavaScript And XML)即异步 JavaScript 和 XML,是一组用于在网页上进行异步数据交换的 Web 开发技术,可以在不刷新整个页面的情况下向服务器发起请求并获取数据,然后将数据插入到网页中的某个位置。…...
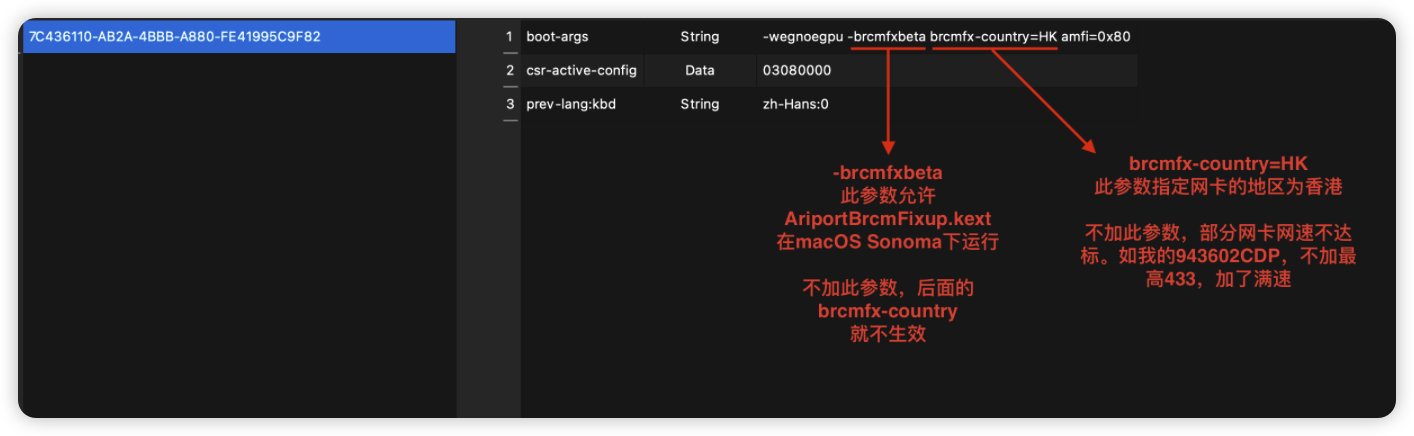
黑苹果如何在macOS Sonoma中驱动博通网卡
准备资源(百度:黑果魏叔 下载) 资源包中包含:AirportBrcmFixup.kext/IOSkywalkFamily.kext/IO80211FamilyLegacy.kext/OpenCore-Patcher 使用方法: 1.将 csr-active-config 设置为 03080000 全选代码 复制 2.在 …...

JVM-Cpu飙升排查及解决
https://blog.csdn.net/m0_37542440/article/details/123679011 1. 问题情况 在服务器上执行某个任务时,系统突然运行缓慢,top 发现cpu飙升,一度接近100%,最终导致服务假死。 2. 问题排查 1. 执行 “top” 命令:查看所…...

exoplayer3 ffmpeg 扩展库编译 aar,导入集成
exoplayer3 ffmpeg 扩展库编译 aar,导入集成。 已经编译完成的aar:https://download.csdn.net/download/mhhyoucom/88086822 编译项目方法: github下载项目:https://github.com/google/ExoPlayer FFmpeg 模块提供 ,…...
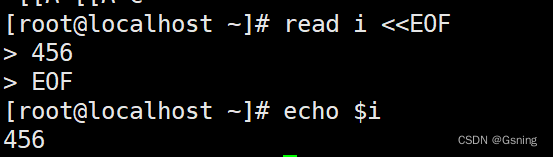
Shell免交互
免交互 免交互就是:不需要人为控制就可以完成的自动化操作,自动化运维 Shell脚本和免交互是一个概念,是有两种写法。 Here Document 免交互 使用I/O(输入/输出)重定向的方式将命令的列表提供给交互式的程序或者命令cat read 是一种标准输入…...
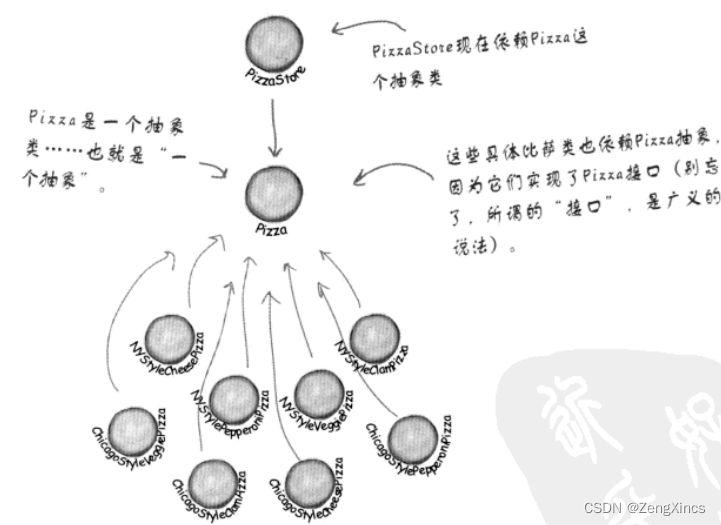
设计模式之四:工厂模式
引言:除了使用new操作符之外,还有更多制造对象的方法。同时,实例化这个活动不应该总是公开地进行。 1.简单工厂模式 这里有一些相关的具体类,要在运行时有一些具体条件来决定究竟实例化哪个类。这样的代码(if..elseif…...
斩获CVPR 2023竞赛2项冠军|美团街景理解中视觉分割技术的探索与应用
总第569篇 2023年 第021篇 视觉分割技术在街景理解中具有重要地位,同时也面临诸多挑战。美团街景理解团队经过长期探索,构建了一套兼顾精度与效率的分割技术体系,在应用中取得了显著效果。同时,相关技术斩获了CVPR 2023竞赛2项冠军…...
)
UE4/5C++多线程插件制作(十五、将模板统一,修改统一后的其他类,修改继承,修改返回类型等)
目录 MTPManageBase.h MTPAbandonable.h MTPAbandonableManage.h MTPThreadInterface.h MTPThreadAgendyManage.h MTPThreadTaskManage.h MTPManage.cpp MTPThreadTaskManage.h...
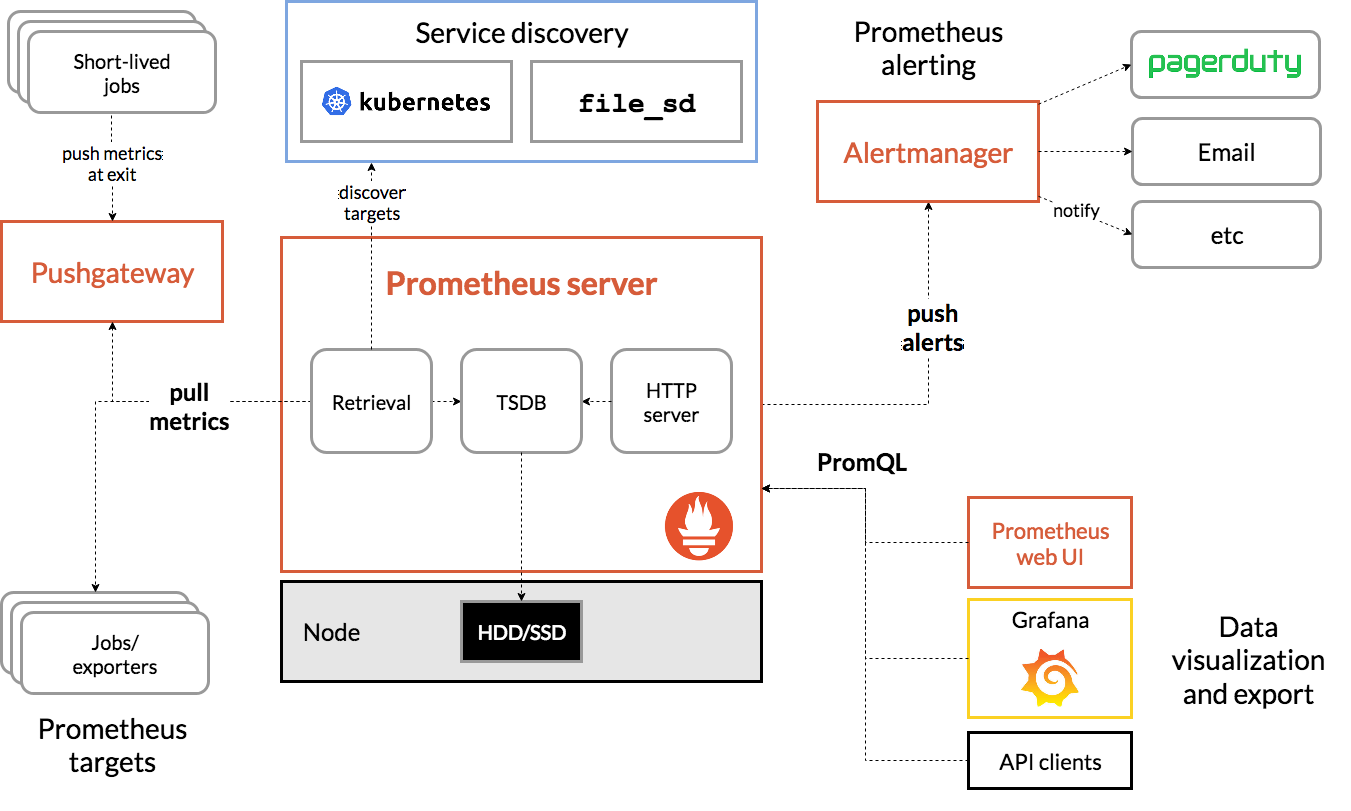
K8S系统监控:使用Metrics Server和Prometheus
Kubernetes 也提供了类似的linux top的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。 Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的…...

数据结构基础之排序算法
在数据结构中,常见的排序算法有以下几种: 冒泡排序(Bubble Sort):通过比较相邻元素并交换它们的位置,每轮将最大(或最小)的元素冒泡到末尾,重复执行直到排序完成。 fun…...
Spark(37):Streaming DataFrame 和 Streaming DataSet 创建
目录 0. 相关文章链接 1. 概述 2. socket source 3. file source 3.1. 读取普通文件夹内的文件 3.2. 读取自动分区的文件夹内的文件 4. kafka source 4.1. 导入依赖 4.2. 以 Streaming 模式创建 Kafka 工作流 4.3. 通过 Batch 模式创建 Kafka 工作流 5. Rate Source…...

SpringBoot集成Thymeleaf
Spring Boot 集成 Thymeleaf 模板引擎 1、Thymeleaf 介绍 Thymeleaf 是适用于 Web 和独立环境的现代服务器端 Java 模板引擎。 Thymeleaf 的主要目标是为开发工作流程带来优雅的自然模板,既可以在浏览器中正确显示的 HTML,也可以用作静态原型…...
:牛客在线编程03 二叉树)
算法练习(2):牛客在线编程03 二叉树
package jz.bm;import jz.TreeNode;import java.util.*;public class bm3 {/*** BM23 二叉树的前序遍历*/public int[] preorderTraversal (TreeNode root) {ArrayList<Integer> list new ArrayList<>();preOrder(root, list);int[] res new int[list.size()];fo…...

回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测
回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiLSTM时间卷积…...

ThinkPad开机嘀嘀响或报2100/2110错误?可能是硬盘松了!自己动手检测与修复指南
ThinkPad开机嘀嘀响或报2100/2110错误?三步排查硬盘接触不良问题ThinkPad用户对那个标志性的开机"嘀嘀"声再熟悉不过——正常情况下它意味着系统自检通过。但当这个声音变成急促的报警音,伴随屏幕上出现"2100 Detection error"或&qu…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由
QMCDecode终极指南:3步解锁QQ音乐加密格式,实现跨平台音乐自由 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目…...

HarmonyOS ArkTS DateUtil 日期增减与日历计算完整指南
文章目录 背景一、引言二、日期增减方法详解使用示例 三、日历计算方法详解四、Demo 演示:日期增减结果展示五、Demo 演示:月历视图完整实现六、日历视图关键点解析为什么要填充前置空格?getLastDayOfMonth 的实现技巧 七、小结 背景 近期发现…...

炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南
炉石传说自动对战助手:5分钟上手,彻底解放双手的终极指南 【免费下载链接】Hearthstone-Script Hearthstone script(炉石传说脚本) 项目地址: https://gitcode.com/gh_mirrors/he/Hearthstone-Script 还在为每天重复的炉石…...

基于ESP32的AIS转WiFi转换器:实现NMEA 0183数据无线传输
1. 项目概述:从VHF-AIS接收器到iPad的无线桥梁作为一名经常在海上折腾电子设备的航海爱好者,我最近遇到了一个挺实际的需求:我的主力导航设备是iPad上的iSailor应用,它功能强大、界面友好,但有个“硬伤”——它需要通过…...

Windows终极PDF处理工具:3步免费安装Poppler完整指南
Windows终极PDF处理工具:3步免费安装Poppler完整指南 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 你是否曾经为在Windows上处理PDF文…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...