(学习笔记-硬件结构)CPU如何执行程序?
冯诺依曼模型
冯诺依曼模型主要由五部分组成:运算器、控制器、存储器、输入设备、输出设备。

控制器(Control Unit):从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相关部件执行指令所包含的操作。
运算器(ALU):处理数据,完成各种算术运算和逻辑运算。
计算机运算时,运算器的操作对象和操作种类由控制器决定。运算器操作的数据从内存中读取,处理的结果再写入内存(或暂时放在内部寄存器中),而且运算器对内存数据的读写是由控制器来进行的。
存储器(Memory):存储程序和各种数据。
- 内部存储器(内存、主存):存取速度快,容量小价格高。用来存放即将执行的程序和数据,可供CPU直接读取。
- 随机存储器(RAM):可以被CPU随机读取(读取任何一个地址数据的速度是一样的,写入任何一个地址数据的速度也是一样的),一般存放CPU将要执行的程序、数据,断电丢失。
- 只读存储器(ROM):只能被CPU读,不能轻易被CPU写,用来存储永久性的程序和数据,比如:系统引导程序、监控程序等。掉电易失。
- 高速缓存存储器(cache):Cache是计算机中的一个高速小容量存储器,其中存放的是CPU近期要执行的指令和数据,其存取速度可以和CPU的速度匹配,一般采用静态RAM充当Cache。
- 外部存储器:存取速度慢。用来存放暂时不用的程序和数据,可以和内存交换数据,不需要依赖电来存储数据。如硬盘、光盘...
输入设备与输出设备:鼠标、键盘、显示器、打印机等
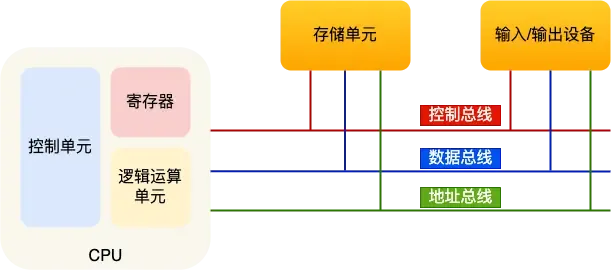
存储单元与输入输出设备要和中央处理器打交道的话离不开总线。所以他们的关系如下:
内存
我们的程序和数据都存储在内存,存储的区域是线性的。
在计算机数据存储中,存储数据的基本单位是字节(byte), 1字节 = 8 位(bit)。每个字节都对应一个内存地址。
内存的地址是从 0 开始编号的,然后自增排序,最后一个地址为内存总字节数-1,这种结构与程序中的数组类似,所以内存中读写任何一个数据的速度都是相同的。
中央处理器
中央处理器也就是CPU,32位和64位CPU的主要区别在于一次性能计算多少字节数据:
- 32位CPU一次可以计算4个字节
- 64位CPU一次可以计算8个字节
这里的32位和64位,通常称为CPU的位宽,代表的是CPU一次可以计算(运算)的数据量。
之所以CPU要这样设计,是为了能计算更大的数值,如果是8位CPU那么一次只能计算一个字节- 0~255范围内的数值,这样就无法完成1000*500的计算,为了能一次计算大数的运算,CPU需要支持多个byte一起计算,所以CPU位宽越大,可以计算的数值就越大,比如32位CPU能计算的最大整数是4294967295。
CPU内部还有一些组件,常见的有寄存器、控制单元和逻辑运算单元。其中,控制单元负责控制CPU的工作,逻辑运算单元负责计算,而寄存器可以分为多种类型,每种寄存器的功能不尽相同。
为什么有了内存还需要寄存器?
因为内存离CPU太远了,而寄存器就在CPU内,紧挨着控制单元和逻辑运算单元,速度会更快。
常见寄存器种类:
- 通用寄存器,用来存放需要进行运算的数据,比如需要进行加和运算的两个数据
- 程序计数器,用来存储CPU要执行的下一条指令[所在的内存地址],注意不是存储下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令[的地址]。
- 指令寄存器,用来存放当前正在执行的指令,也就是指令本身,指令被执行完之前都存储在这里。
总线
总线是用于CPU和内存以及其他设备之间的同学,总线分为三种:
- 地址总线,用于指定CPU将要操作的内存地址
- 数据总线,用于读写内存的数据
- 控制总线,用于发送和接收信号,比如中断、设备复位等信号
当CPU要读写内存数据的时候,一般需要通过下面这三个总线:
- 首先要通过[地址总线]来指定内存的地址
- 然后通过[控制总线]控制是读或写的命令
- 最后通过[数据总线]来传输数据
线路位宽与CPU位宽
数据是如何通过线路传输的呢?其实是通过操作电压,低电压表示0,高电压表示1.
如果构造了 高低高 这样的电压,其实就是 101 二进制,十进制表示5,如果只有一条线路,就意味着每次只能传递1bit的数据,即0 或 1 ,那么传输 101 这个数据,就需要3次才能传输完成,这样效率非常低。
这样一位一位传输的方式,称为串行,下一个bit必须等待上一个bit传输完成才能进行传输。想一次传多一些数据,增加线路即可,这时数据就可以并行传输。
为了避免低效率的串行传输方式,线路的位宽最好一次能够访问到所有的内存地址。
CPU想要操作[内存地址]就需要[地址总线]:
- 如果地址总线只有1条,那每次只能表示 [ 0 或 1]这两种地址,所以CPU能操作的内存地址最大数量为 2 个。(不能理解为同时操作两个内存地址)
- 如果地址总线有2条,那么能表示00、01、10、11四种地址,所以CPU能操作的内存地址最大数量为 4 个
那么,想要CPU操作4G的内存,就需要 32条地址总线。
CPU的位宽最好不要小于线路的位宽 ,比如32位CPU控制40位宽的地址总线和数据总线的话,工作起来会非常麻烦,所以32位的CPU最好和32位宽的线路搭配,因为32位CPU一次最多只能操作32位宽的地址总线和数据总线。
如果用32位CPU去加和两个64位大小的数字·,就需要把这两个64位的数字分成2个低位32位数字和2个高位32位数字来计算,先加两个低位的32位数字,算出进位,然后加和两个高位的32位数字,最后再加上进位就能算出结果了,可以发现32位CPU并不能一次性算出加和两个64位的数字的结果。
对于64位CPU就可以一次性算出加和两个64位数字的结果,因为64位CPU可以一次读入64位的数字,并且64位CPU内部的逻辑运算单元也支持64位数字的计算。
但是并不代表64位CPU性能比32位CPU高很多,很少应用需要算超过32位的数字,所以如果计算的数额不超过32位数字的情况下,32位和64位CPU之间没什么区别,只有当计算超过32位数字的情况下,64位的优势才能体现出来。
另外,32位CPU最大只能操作4GB内存,就算装了8GB的内存条,也没用。而64位CPU寻址范围则很大,理论最大寻址空间为.
程序执行的基本过程
程序实际上是一条一条的指令,所以程序的运行过程就是把每一条指令一步一步的执行起来,负责执行指令的就是CPU。
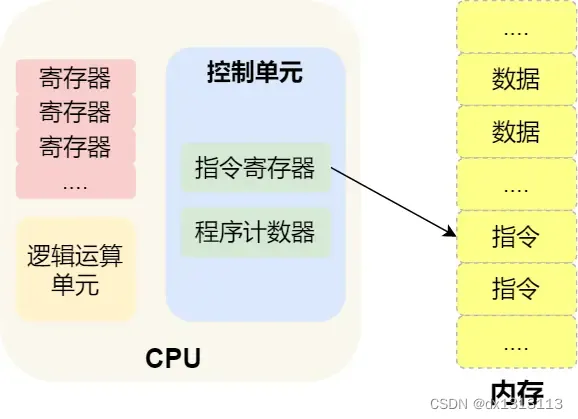
CPU执行程序的过程如下:
- CPU读取[程序计数器]的值,这个值是指令的内存地址,然后CPU的[控制单元]操作[地址总线]指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过[数据总线]将指令数据传给CPU,CPU收到内存传来的数据后,将这个指令数据存入到[指令寄存器]。
- [程序计数器]的值自增,表示指向下一个指令[地址]。这个自增的大小由CPU的位宽决定,比如32位的CPU,指令是4个字节,需要4个内存地址存放,因此[程序计数器]的值会加4。
- CPU分析[指令寄存器]中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给[逻辑运算单元]运算;如果是存储类型的指令,则交由[控制单元]执行。
总结:一个程序执行的时候,CPU会根据程序计数器的内存地址,从内存里面把需要执行的指令读到指令寄存器里面执行,然后根据指令长度自增,开始顺序读取下一条指令。
CPU从程序计数器读取指令、到执行、再到下一条指令,这个过程会不断循环,直到程序结束,这个不断循环的过程被称为CPU的指令周期
a = 1 + 2的具体执行过程
CPU是不认识 a = 1 + 2 这个字符串的,这些字符串只是方便我们认识,想要这段程序能跑起来,还需要把整个程序翻译成汇编语言的程序,这个过程被称为编译
除此之外,我们还需要用汇编器翻译成机器码,这些机器码由 0 和 1 组成机器语言,这一条条机器码,就是一条条的计算机指令,这个才是CPU认识的东西。
a = 1 + 2 在32位CPU的执行过程。
程序编译过程中,编译器通过分析代码,发现 1 和 2 是数据,于是程序运行时,内存会有一个专门的区域来存放这些数据,这个区域就是[数据段]。
- 数据1被存放到0x200位置
- 数据2被存放到0x204位置
数据和指令是分开存放的,存放数据的区域称为[数据段],存放指令的区域称为[正文段]。
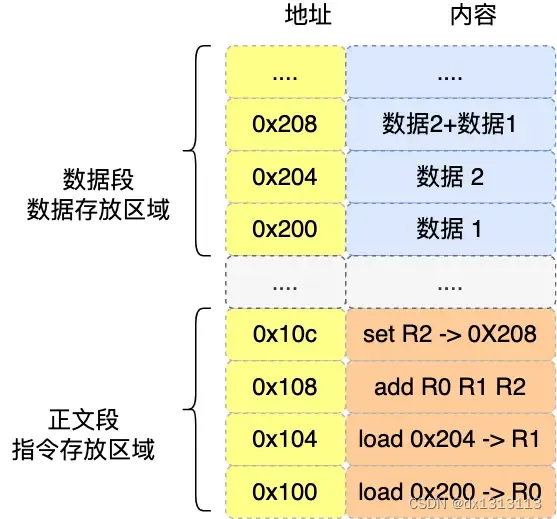
编译器会把 a = 1 + 2 翻译成 4 条指令,存放到正文段中。如图,这4条指令被存放到了0x100~0x10c的区域中:
- 0x100的内容是 load 指令将0x200地址中的数据 1 装入到寄存器 R0 ;
- 0x104的内容是 load 指令将0x204地址中的数据 2 装入到寄存器 R1 ;
- 0x108的内容是 add 指令将寄存器 R0 和 R1 的数据相加,并把结果存放到寄存器 R2 ;
- 0x10c的内容是 store 指令将寄存器 R2 中的数据存回数据段中的0x208地址中,这个地址也就是变量 a 内存中的地址;
编译完成后,具体执行程序的时候,程序计数器会被设置为0x100地址,然后依次执行这4条指令。(上面的例子中,由于是在32位CPU执行的,因此指令是占32位大小,所以每条指令的地址隔4个字节。数据的大小事根据程序中指定的变量类型,比如 int 类型的数据占4个字节,char类型的数据占1个字节)
总结
64位相比32位优势在哪? 64位CPU性能一定比32位CPU高很多吗?
64位相比32位CPU的优势主要体现在两个方面:
- 64位CPU可以一次计算超过32位的数字,而32位CPU如果要计算超过32位的数字,要分多步骤进行计算,效率就没那么高,但是大部分应用程序很少会计算那么大的数字,所以只有运算大数字的时候,64位CPU的优势才能体现出来,否则和32位CPU的计算性能相差不大。
- 通常来说64位CPU的地址总线是48位,而32位CPU的地址总线是32位,所以64位CPU可以寻址更大的物理内存空间。如果一个32位CPU的地址总线是32位那么该CPU的最大寻址能力是4G,即使使用8G大小的内存,也还是只能寻址到4G大小的地址,而如果一个64位CPU的地址总线是48位,那么该CPU的最大寻址范围是
,远超于32位CPU的最大寻址能力。
32位软件和64位软件的区别?32位操作系统能够运行在64位电脑上吗?
64位和32位软件,实际上代表指令是64位还是32位:
- 如果32位指令在64位机器上执行,需要一套兼容机制就可以做到兼容运行了。但是如果64位指令在32位机器上运行,就比较困难,因为32位寄存器存不下64位的指令。
- 操作系统其实也是一种程序,操作系统也分为32位和64位,其代表的意思就是操作系统中程序的指令是多少位,64位操作系统指令为64位,不能装在32位的机器上。
硬件的64位和32位指的是CPU的位宽,软件的32位和64位指的是指令的位宽。
相关文章:
(学习笔记-硬件结构)CPU如何执行程序?
冯诺依曼模型 冯诺依曼模型主要由五部分组成:运算器、控制器、存储器、输入设备、输出设备。 控制器(Control Unit):从内存中取指令、翻译指令、分析指令,然后根据指令的内存向有关部件发送控制命令,控制相…...
 Failed to open/read local data from file/application)
curl: (26) Failed to open/read local data from file/application
Windows10、Windows环境用curl命令上传文件报错: curl: (26) Failed to open/read local data from file/application假设我要上传的文件目录是: F:\我的下载\test.xlsx 错误写法1:使用单引号 curl -X POST "https://xxx/upload&quo…...

2023年深圳杯数学建模 D题 基于机理的致伤工具推断
致伤工具的推断一直是法医工作中的热点和难点。由于作用位置、作用方式的不同,相同的致伤工具在人体组织上会形成不同的损伤形态,不同的致伤工具也可能形成相同的损伤形态。致伤工具品种繁多、形态各异,但大致可分为两类:锐器&…...

DMA传输原理与实现详解(超详细)
DMA(Direct Memory Access,直接内存访问)是一种计算机数据传输方式,允许外围设备直接访问系统内存,而无需CPU的干预。 文章目录 Part 1: DMA的工作原理配置阶段:数据传输阶段: Part 2: DMA数据…...
【《React Hooks实战》——指导你使用hook开发性能优秀可复用性高的React组件】
使用React Hooks后,你很快就会发现,代码变得更具有组织性且更易于维护。React Hooks是旨在为用户提供跨组件的重用功能和共享功能的JavaScript函数。利用React Hooks, 可以将组件分成多个函数、管理状态和副作用,并且不必声明类即…...

Ajax详细讲解
Ajax(Asynchronous JavaScript And XML)即异步 JavaScript 和 XML,是一组用于在网页上进行异步数据交换的 Web 开发技术,可以在不刷新整个页面的情况下向服务器发起请求并获取数据,然后将数据插入到网页中的某个位置。…...
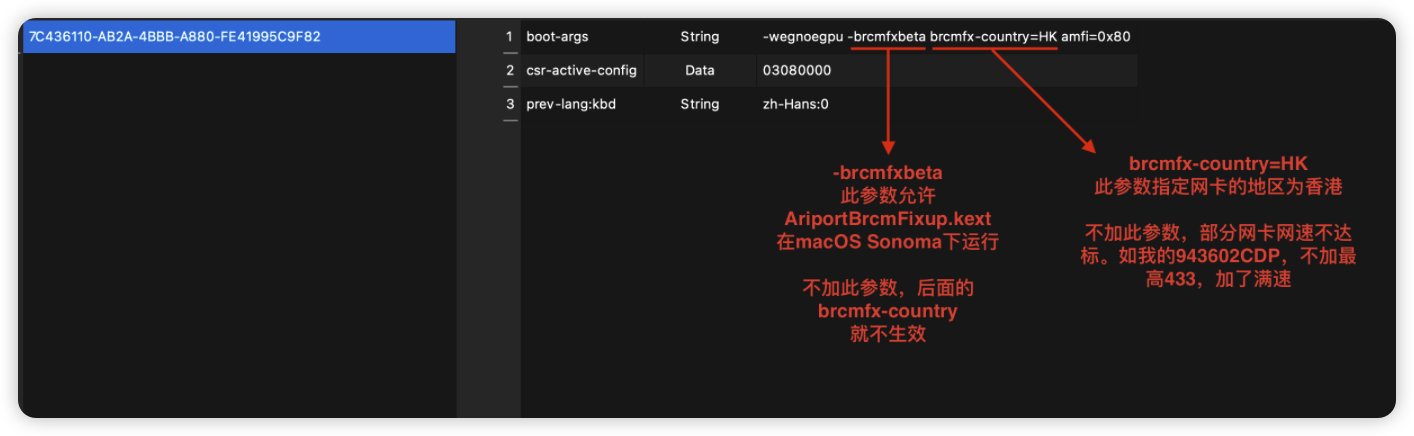
黑苹果如何在macOS Sonoma中驱动博通网卡
准备资源(百度:黑果魏叔 下载) 资源包中包含:AirportBrcmFixup.kext/IOSkywalkFamily.kext/IO80211FamilyLegacy.kext/OpenCore-Patcher 使用方法: 1.将 csr-active-config 设置为 03080000 全选代码 复制 2.在 …...

JVM-Cpu飙升排查及解决
https://blog.csdn.net/m0_37542440/article/details/123679011 1. 问题情况 在服务器上执行某个任务时,系统突然运行缓慢,top 发现cpu飙升,一度接近100%,最终导致服务假死。 2. 问题排查 1. 执行 “top” 命令:查看所…...

exoplayer3 ffmpeg 扩展库编译 aar,导入集成
exoplayer3 ffmpeg 扩展库编译 aar,导入集成。 已经编译完成的aar:https://download.csdn.net/download/mhhyoucom/88086822 编译项目方法: github下载项目:https://github.com/google/ExoPlayer FFmpeg 模块提供 ,…...
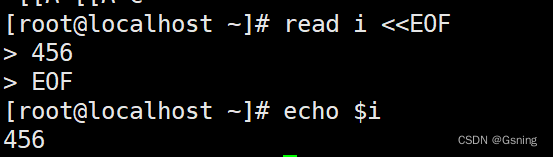
Shell免交互
免交互 免交互就是:不需要人为控制就可以完成的自动化操作,自动化运维 Shell脚本和免交互是一个概念,是有两种写法。 Here Document 免交互 使用I/O(输入/输出)重定向的方式将命令的列表提供给交互式的程序或者命令cat read 是一种标准输入…...
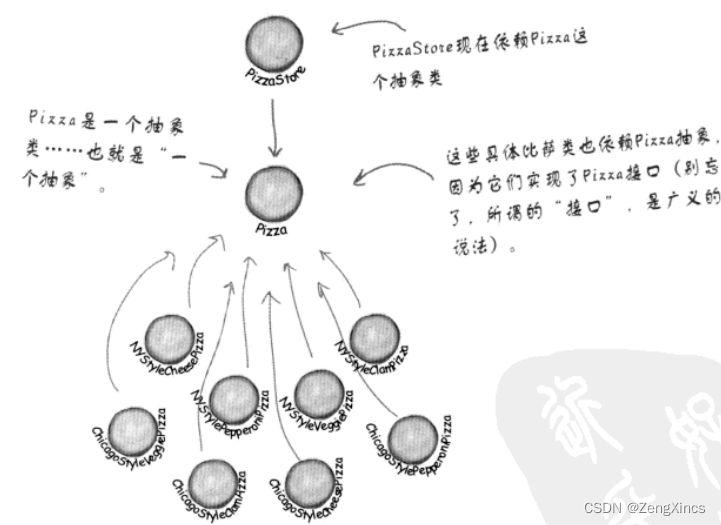
设计模式之四:工厂模式
引言:除了使用new操作符之外,还有更多制造对象的方法。同时,实例化这个活动不应该总是公开地进行。 1.简单工厂模式 这里有一些相关的具体类,要在运行时有一些具体条件来决定究竟实例化哪个类。这样的代码(if..elseif…...
斩获CVPR 2023竞赛2项冠军|美团街景理解中视觉分割技术的探索与应用
总第569篇 2023年 第021篇 视觉分割技术在街景理解中具有重要地位,同时也面临诸多挑战。美团街景理解团队经过长期探索,构建了一套兼顾精度与效率的分割技术体系,在应用中取得了显著效果。同时,相关技术斩获了CVPR 2023竞赛2项冠军…...
)
UE4/5C++多线程插件制作(十五、将模板统一,修改统一后的其他类,修改继承,修改返回类型等)
目录 MTPManageBase.h MTPAbandonable.h MTPAbandonableManage.h MTPThreadInterface.h MTPThreadAgendyManage.h MTPThreadTaskManage.h MTPManage.cpp MTPThreadTaskManage.h...
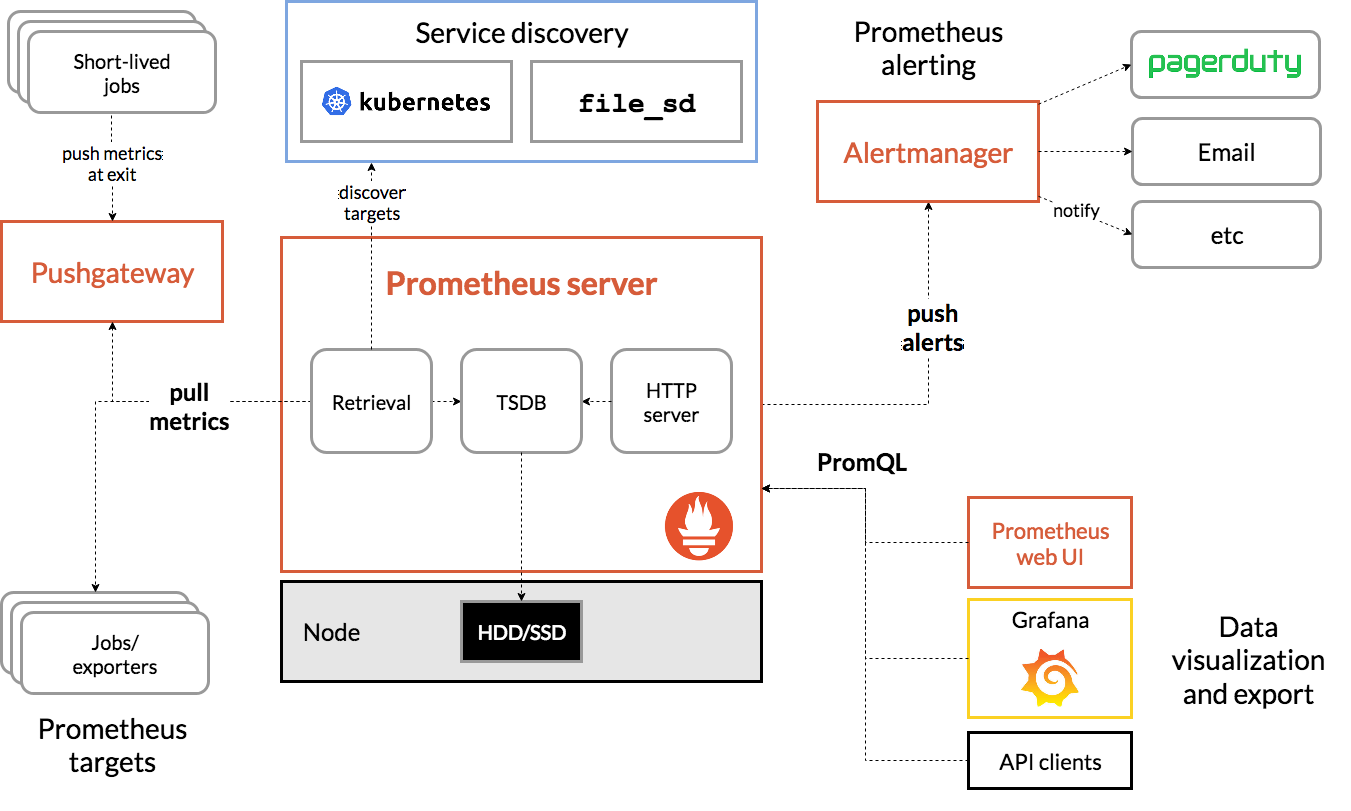
K8S系统监控:使用Metrics Server和Prometheus
Kubernetes 也提供了类似的linux top的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。 Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的…...

数据结构基础之排序算法
在数据结构中,常见的排序算法有以下几种: 冒泡排序(Bubble Sort):通过比较相邻元素并交换它们的位置,每轮将最大(或最小)的元素冒泡到末尾,重复执行直到排序完成。 fun…...
Spark(37):Streaming DataFrame 和 Streaming DataSet 创建
目录 0. 相关文章链接 1. 概述 2. socket source 3. file source 3.1. 读取普通文件夹内的文件 3.2. 读取自动分区的文件夹内的文件 4. kafka source 4.1. 导入依赖 4.2. 以 Streaming 模式创建 Kafka 工作流 4.3. 通过 Batch 模式创建 Kafka 工作流 5. Rate Source…...

SpringBoot集成Thymeleaf
Spring Boot 集成 Thymeleaf 模板引擎 1、Thymeleaf 介绍 Thymeleaf 是适用于 Web 和独立环境的现代服务器端 Java 模板引擎。 Thymeleaf 的主要目标是为开发工作流程带来优雅的自然模板,既可以在浏览器中正确显示的 HTML,也可以用作静态原型…...
:牛客在线编程03 二叉树)
算法练习(2):牛客在线编程03 二叉树
package jz.bm;import jz.TreeNode;import java.util.*;public class bm3 {/*** BM23 二叉树的前序遍历*/public int[] preorderTraversal (TreeNode root) {ArrayList<Integer> list new ArrayList<>();preOrder(root, list);int[] res new int[list.size()];fo…...

回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测
回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiLSTM时间卷积…...
Linux 系列 常见 快捷键总结
强制停止 Ctrl C 退出程序、退出登录 Ctrl D 等价 exit 查看历史命令 history !命令前缀,自动匹配上一个命令 (历史命令中:从最新——》最老 搜索) ctrl r 输入内去历史命令中检索 # 回车键可以直接执行 ctrl a 跳到命令开头 …...

Godot PCK解包原理与专业逆向实践指南
1. 这不是“解压软件”,而是Godot游戏逆向工程的第一把手术刀你刚下载了一款用Godot引擎开发的独立游戏,想研究它的UI动效逻辑,或者复刻一段粒子特效,又或者只是单纯好奇——那个让你反复通关三次的像素风过场动画,图层…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

VMware ESXi 9.1.0.0集成NVME+网卡驱动版发布|新特性+驱动集成+部署升级+FAQ全指南
一、ESXi 9.1.0.0 正式版核心新特性 VMware ESXi 9.1.0.0(2026 年 5 月发布)是 vSphere 9.1 核心组件,聚焦硬件兼容扩展、性能跃升、安全加固、运维简化四大方向,重点强化 NVMe 存储与网卡生态适配,以下为关键更新&am…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

谷氨酸发酵过程的软测量建模【附模型】
✨ 长期致力于软测量、谷氨酸发酵、动力学模型、支持向量机、高斯过程、变量选择、异常状态研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)多阶段高斯…...

终极指南:5步快速掌握免费的3D点云标注工具labelCloud
终极指南:5步快速掌握免费的3D点云标注工具labelCloud 【免费下载链接】labelCloud A lightweight tool for labeling 3D bounding boxes in point clouds. 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 想要为自动驾驶、机器人视觉或3D目标检测…...

Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南
Atomic Layout核心概念解析:Composition组件如何实现布局与间距分离的终极指南 【免费下载链接】atomic-layout Build declarative, responsive layouts in React using CSS Grid. 项目地址: https://gitcode.com/gh_mirrors/at/atomic-layout Atomic Layout…...