DMA传输原理与实现详解(超详细)
DMA(Direct Memory Access,直接内存访问)是一种计算机数据传输方式,允许外围设备直接访问系统内存,而无需CPU的干预。

文章目录
- Part 1: DMA的工作原理
- 配置阶段:
- 数据传输阶段:
- Part 2: DMA数据组成
- Part 3: DMA传输过程的实现
- Part 4: DMA中断处理和性能优化
- DMA中断处理:
- DMA性能优化:
- Part 5: STM32实现DMA
- 基于标准库
- 基于HAL库
Part 1: DMA的工作原理
DMA(Direct Memory Access,直接内存访问)是一种计算机数据传输方式,允许外围设备直接访问系统内存,而无需CPU的干预。下面详细介绍DMA的工作原理:
配置阶段:
-
配置源地址(Source Address):通过指定源地址,DMA可以知道需要传输数据的起始位置。
-
配置目标地址(Destination Address):指定目标地址,将数据传输到系统内存中的相应位置。
-
配置数据长度(Data Length):DMA需要知道需要传输的数据长度,以便正确地读取和写入数据。
-
配置控制信息(Control Information):例如传输模式、中断使能等参数,用于指定传输的具体配置。
数据传输阶段:

-
外设发起传输请求:外围设备(如网络接口卡、硬盘控制器)向DMA控制器发起传输请求。
-
DMA控制器响应请求:DMA控制器接收到传输请求后,暂停CPU的访问,并通过请求信号(如DMA请求信号)获取对系统总线的控制权。
-
读取数据:DMA控制器从外设读取数据,并存储在内部缓冲区中。
-
数据传输:DMA控制器将数据从内部缓冲区传输到系统内存中的目标地址。
-
传输完成通知:当数据传输完成后,DMA控制器会释放对系统总线的控制权,并发出传输完成的中断信号,通知CPU。
-
CPU处理中断:CPU接收到传输完成的中断信号后,会执行相应的中断处理程序。
Part 2: DMA数据组成
DMA传输涉及的数据主要有以下几种组成:
-
源地址(Source Address):源地址表示数据传输的起始地址,即外设设备中数据缓冲区的地址。DMA将从这个地址开始读取数据。
-
目标地址(Destination Address):目标地址表示数据传输的目的地址,即系统内存中的指定地址。DMA将数据传输到这个地址。
-
数据长度(Data Length):数据长度表示需要传输的数据大小。它可以以字节、字或者其他单位进行表示。
-
控制信息(Control Information):控制信息包括传输模式、中断使能等参数。在传输过程中,DMA根据这些参数来控制数据的传输行为。
此外,还有一些额外的参数和寄存器与DMA相关,用于配置和控制DMA的操作,例如:
-
DMA通道选择(DMA Channel Selection):在具有多个DMA通道的系统中,选择要使用的DMA通道。
-
DMA传输模式(DMA Transfer Mode):指定DMA传输的模式,如单次传输模式、循环传输模式等。
-
DMA中断使能(DMA Interrupt Enable):用于控制DMA传输完成时是否产生中断。
Part 3: DMA传输过程的实现
DMA的传输过程涉及多个步骤,包括启动DMA、请求传输、数据读取和写入等操作。

下面是DMA传输过程的一个简单实现示例:
- 配置DMA参数:
在开始DMA传输之前,需要先配置DMA相关的参数,如源地址、目标地址、数据长度和控制信息等。这些参数通常通过设置相应的寄存器来实现。
// 配置DMA
void configureDMA(uint32_t sourceAddr, uint32_t destAddr, uint32_t dataLength) {// 配置源地址和目标地址writeDMARegister(SOURCE_ADDRESS_REG, sourceAddr);writeDMARegister(DESTINATION_ADDRESS_REG, destAddr);// 配置数据长度writeDMARegister(DATA_LENGTH_REG, dataLength);// 配置控制信息,如传输模式、中断使能等writeDMARegister(CONTROL_INFO_REG, controlInfo);
}
- 启动DMA传输:
配置完成后,通过设置相应的使能寄存器,启动DMA传输。
// 启动DMA传输
void startDMA() {// 设置DMA使能位writeDMARegister(ENABLE_REG, 1);// 发送传输请求sendDMARequest();
}
- 请求传输:
外设设备发出DMA请求,请求DMA控制权,开始数据传输过程。DMA控制器收到传输请求后,暂停CPU的访问,并通过请求信号(如DMA请求信号)获取对系统总线的控制权。
// 发送DMA传输请求
void sendDMARequest() {// 发送DMA请求信号给DMA控制器setDMARequestSignal();
}
- 数据读取和写入:
DMA控制器根据配置的参数,从外设设备中读取数据,并将其写入系统内存中的目标地址。
// 读取数据并写入内存
void transferData() {// 从外设读取数据uint32_t data = readDataFromPeripheral();// 写入内存writeDataToMemory(data);
}
- 传输完成通知:
当数据传输完成后,DMA控制器会释放对系统总线的控制权,并发送传输完成的中断信号,通知CPU。
// DMA中断处理函数
void handleDMAInterrupt() {// 处理传输完成的中断信号// ...
}
Part 4: DMA中断处理和性能优化
DMA中断处理:
在DMA传输完成时,DMA控制器可以触发一个中断,通知CPU传输已完成。CPU可以相应地执行中断处理程序,进行必要的操作。
-
中断使能设置:
在配置DMA参数时,通过设置相应的控制信息,可以选择是否使能DMA传输完成中断。如果使能了中断,DMA传输完成时会产生中断请求信号。否则,传输完成后不会触发中断。 -
中断处理程序:
在CPU侧,需要编写中断处理程序来处理DMA传输完成中断。中断处理程序负责执行相应的操作,如处理传输完成的数据、清除中断标志等。
DMA性能优化:
为了提高DMA传输的效率和性能,可以采取以下优化技术:
-
数据对齐(Data Alignment):
尽可能地对齐数据可以提高DMA的传输效率。许多硬件平台在DMA传输时对数据对齐有限制,所以确保数据在传输过程中的对齐是重要的。 -
数据块传输(Block Transfer):
DMA支持以块为单位的数据传输,逐次传输多个数据块,并在传输完成后给出一个中断通知。这种方式比每次传输一个数据更高效,减少了中断的开销和系统总线访问的次数。 -
通道优先级(Channel Priority):
在具有多个DMA通道的系统中,可以通过设置不同的通道优先级,来决定DMA通道之间的数据传输优先级。这样可以在多个外设设备同时请求传输时,对优先级较高的设备进行优先处理。 -
多重缓冲区(Double Buffering):
使用多个缓冲区来存储数据可以提高DMA传输效率。当DMA从一个缓冲区传输数据时,CPU可以同时向另一个缓冲区写入新的数据,从而实现并行操作。
Part 5: STM32实现DMA
基于标准库
示例代码:
#include "stm32f10x.h"#define BUFFER_SIZE 100uint32_t sourceBuffer[BUFFER_SIZE];
uint32_t destinationBuffer[BUFFER_SIZE];void DMA_Configuration(void) {DMA_InitTypeDef DMA_InitStructure;RCC_AHBPeriphClockCmd(RCC_AHBPeriph_DMA1, ENABLE);DMA_DeInit(DMA1_Channel1);DMA_InitStructure.DMA_PeripheralBaseAddr = (uint32_t)&(ADC1->DR);DMA_InitStructure.DMA_MemoryBaseAddr = (uint32_t)destinationBuffer;DMA_InitStructure.DMA_DIR = DMA_DIR_PeripheralSRC;DMA_InitStructure.DMA_BufferSize = BUFFER_SIZE;DMA_InitStructure.DMA_PeripheralInc = DMA_PeripheralInc_Disable;DMA_InitStructure.DMA_MemoryInc = DMA_MemoryInc_Enable;DMA_InitStructure.DMA_PeripheralDataSize = DMA_PeripheralDataSize_HalfWord;DMA_InitStructure.DMA_MemoryDataSize = DMA_MemoryDataSize_HalfWord;DMA_InitStructure.DMA_Mode = DMA_Mode_Circular;DMA_InitStructure.DMA_Priority = DMA_Priority_High;DMA_InitStructure.DMA_M2M = DMA_M2M_Disable;DMA_Init(DMA1_Channel1, &DMA_InitStructure);DMA_Cmd(DMA1_Channel1, ENABLE);
}int main() {// 初始化源缓冲区for (int i = 0; i < BUFFER_SIZE; i++) {sourceBuffer[i] = i;}// 配置DMADMA_Configuration();while (1) {// 等待DMA传输完成while (!DMA_GetFlagStatus(DMA1_FLAG_TC1));// 处理传输完成的数据for (int i = 0; i < BUFFER_SIZE; i++) {// 处理destinationBuffer中的数据// ...}// 清除DMA传输完成标志位DMA_ClearFlag(DMA1_FLAG_TC1);}
}
在这个示例代码中,首先通过DMA_Configuration函数进行DMA的配置。然后在主循环中等待DMA传输完成的标志位,处理传输完成的数据,并清除传输完成标志位。
基于HAL库
示例代码:
#include "stm32f1xx_hal.h"#define BUFFER_SIZE 100DMA_HandleTypeDef hdma_adc1;uint32_t sourceBuffer[BUFFER_SIZE];
uint32_t destinationBuffer[BUFFER_SIZE];void DMA_Configuration(void) {__HAL_RCC_DMA1_CLK_ENABLE();hdma_adc1.Instance = DMA1_Channel1;hdma_adc1.Init.Direction = DMA_PERIPH_TO_MEMORY;hdma_adc1.Init.PeriphInc = DMA_PINC_DISABLE;hdma_adc1.Init.MemInc = DMA_MINC_ENABLE;hdma_adc1.Init.PeriphDataAlignment = DMA_PDATAALIGN_HALFWORD;hdma_adc1.Init.MemDataAlignment = DMA_MDATAALIGN_HALFWORD;hdma_adc1.Init.Mode = DMA_CIRCULAR;hdma_adc1.Init.Priority = DMA_PRIORITY_HIGH;HAL_DMA_Init(&hdma_adc1);__HAL_LINKDMA(&hadc1, DMA_Handle, hdma_adc1);HAL_DMA_Start(&hdma_adc1, (uint32_t)&(ADC1->DR), (uint32_t)destinationBuffer, BUFFER_SIZE);
}void HAL_ADC_ConvCpltCallback(ADC_HandleTypeDef* hadc) {// 处理传输完成的数据for (int i = 0; i < BUFFER_SIZE; i++) {// 处理destinationBuffer中的数据// ...}
}int main() {// 初始化源缓冲区for (int i = 0; i < BUFFER_SIZE; i++) {sourceBuffer[i] = i;}// 配置DMADMA_Configuration();// 启动ADC转换HAL_ADC_Start_DMA(&hadc1, (uint32_t*)sourceBuffer, BUFFER_SIZE);while (1) {// 主循环中不需要额外的处理// 在需要使用CPU的其他任务中加入适当的延时或等待DMA传输完成的标志位// ...}
}
这个示例使用了STM32Cube HAL库提供的HAL库函数进行DMA的配置和控制。在DMA_Configuration函数中,使用HAL_DMA_Init函数进行DMA的初始化,并且通过__HAL_LINKDMA宏将DMA与ADC关联起来。在HAL_ADC_ConvCpltCallback函数中,处理传输完成的数据。
相关文章:
DMA传输原理与实现详解(超详细)
DMA(Direct Memory Access,直接内存访问)是一种计算机数据传输方式,允许外围设备直接访问系统内存,而无需CPU的干预。 文章目录 Part 1: DMA的工作原理配置阶段:数据传输阶段: Part 2: DMA数据…...
【《React Hooks实战》——指导你使用hook开发性能优秀可复用性高的React组件】
使用React Hooks后,你很快就会发现,代码变得更具有组织性且更易于维护。React Hooks是旨在为用户提供跨组件的重用功能和共享功能的JavaScript函数。利用React Hooks, 可以将组件分成多个函数、管理状态和副作用,并且不必声明类即…...

Ajax详细讲解
Ajax(Asynchronous JavaScript And XML)即异步 JavaScript 和 XML,是一组用于在网页上进行异步数据交换的 Web 开发技术,可以在不刷新整个页面的情况下向服务器发起请求并获取数据,然后将数据插入到网页中的某个位置。…...
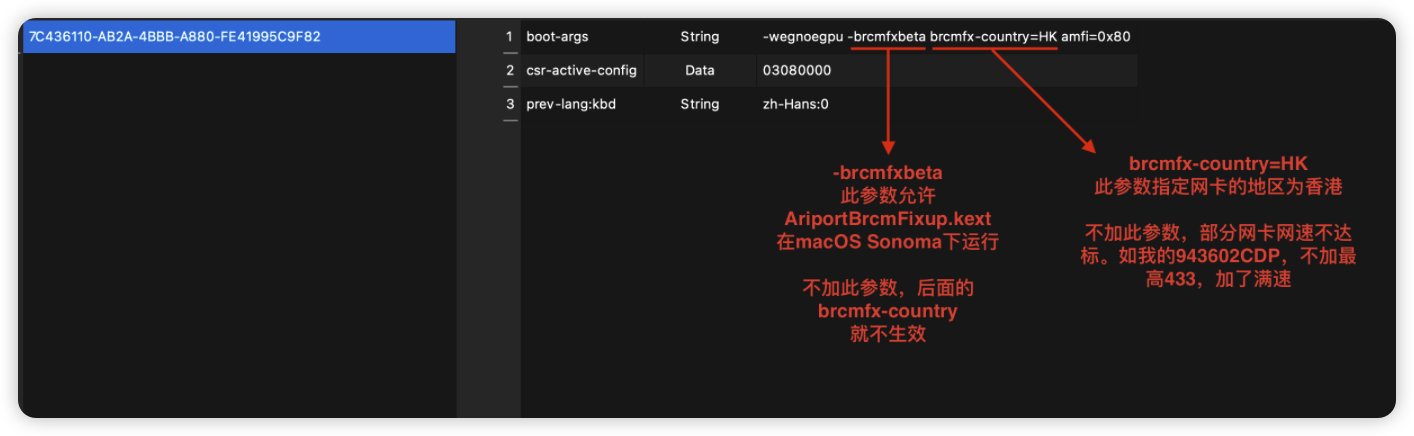
黑苹果如何在macOS Sonoma中驱动博通网卡
准备资源(百度:黑果魏叔 下载) 资源包中包含:AirportBrcmFixup.kext/IOSkywalkFamily.kext/IO80211FamilyLegacy.kext/OpenCore-Patcher 使用方法: 1.将 csr-active-config 设置为 03080000 全选代码 复制 2.在 …...

JVM-Cpu飙升排查及解决
https://blog.csdn.net/m0_37542440/article/details/123679011 1. 问题情况 在服务器上执行某个任务时,系统突然运行缓慢,top 发现cpu飙升,一度接近100%,最终导致服务假死。 2. 问题排查 1. 执行 “top” 命令:查看所…...

exoplayer3 ffmpeg 扩展库编译 aar,导入集成
exoplayer3 ffmpeg 扩展库编译 aar,导入集成。 已经编译完成的aar:https://download.csdn.net/download/mhhyoucom/88086822 编译项目方法: github下载项目:https://github.com/google/ExoPlayer FFmpeg 模块提供 ,…...
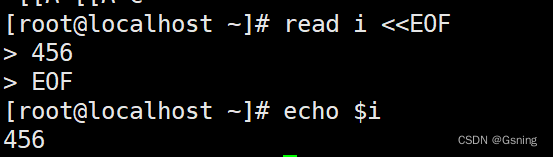
Shell免交互
免交互 免交互就是:不需要人为控制就可以完成的自动化操作,自动化运维 Shell脚本和免交互是一个概念,是有两种写法。 Here Document 免交互 使用I/O(输入/输出)重定向的方式将命令的列表提供给交互式的程序或者命令cat read 是一种标准输入…...
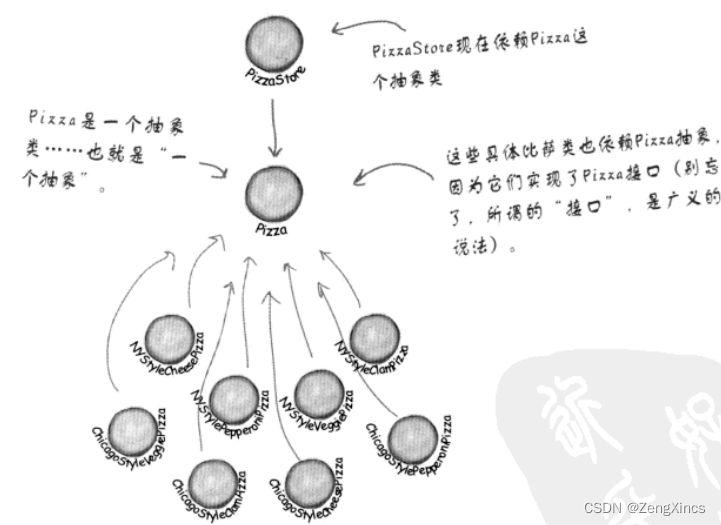
设计模式之四:工厂模式
引言:除了使用new操作符之外,还有更多制造对象的方法。同时,实例化这个活动不应该总是公开地进行。 1.简单工厂模式 这里有一些相关的具体类,要在运行时有一些具体条件来决定究竟实例化哪个类。这样的代码(if..elseif…...
斩获CVPR 2023竞赛2项冠军|美团街景理解中视觉分割技术的探索与应用
总第569篇 2023年 第021篇 视觉分割技术在街景理解中具有重要地位,同时也面临诸多挑战。美团街景理解团队经过长期探索,构建了一套兼顾精度与效率的分割技术体系,在应用中取得了显著效果。同时,相关技术斩获了CVPR 2023竞赛2项冠军…...
)
UE4/5C++多线程插件制作(十五、将模板统一,修改统一后的其他类,修改继承,修改返回类型等)
目录 MTPManageBase.h MTPAbandonable.h MTPAbandonableManage.h MTPThreadInterface.h MTPThreadAgendyManage.h MTPThreadTaskManage.h MTPManage.cpp MTPThreadTaskManage.h...
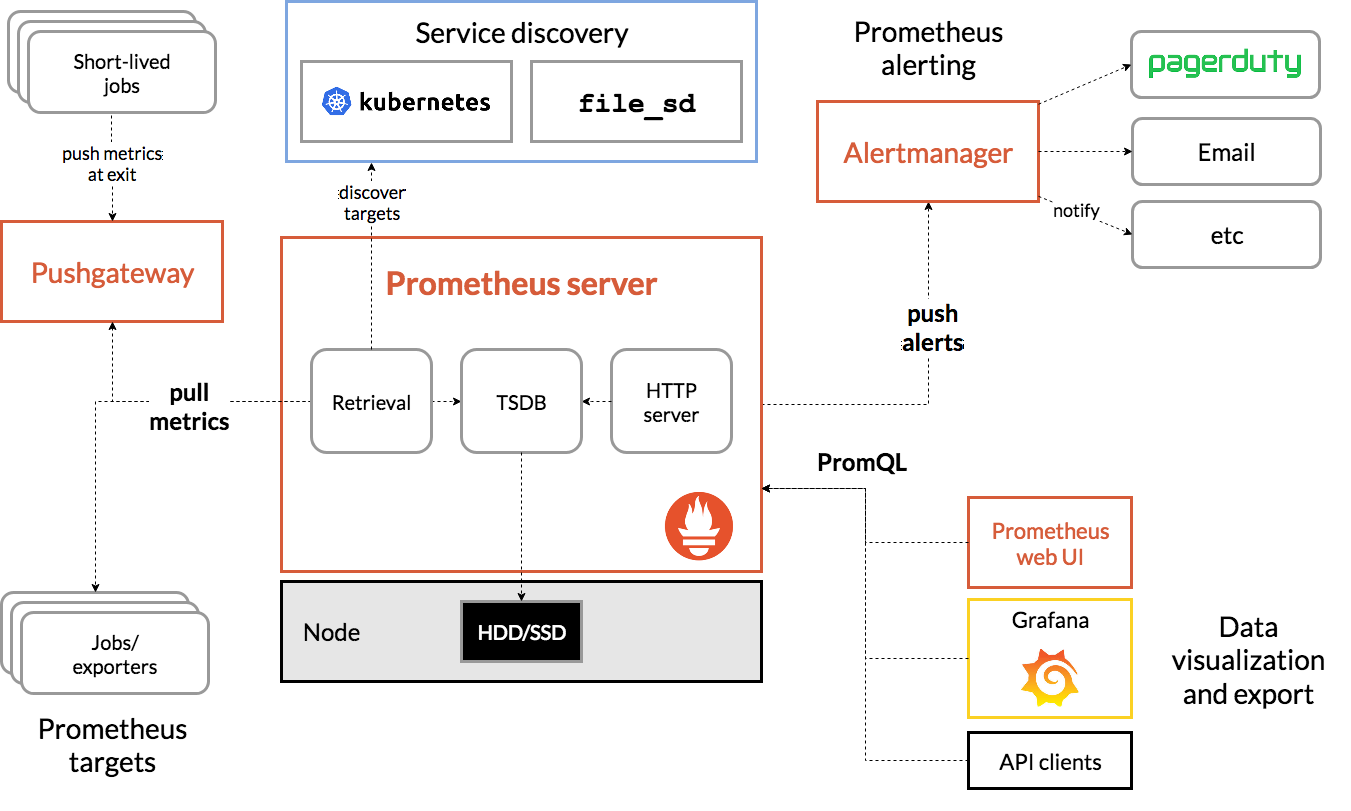
K8S系统监控:使用Metrics Server和Prometheus
Kubernetes 也提供了类似的linux top的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装一个插件 Metrics Server 才可以。 Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的…...

数据结构基础之排序算法
在数据结构中,常见的排序算法有以下几种: 冒泡排序(Bubble Sort):通过比较相邻元素并交换它们的位置,每轮将最大(或最小)的元素冒泡到末尾,重复执行直到排序完成。 fun…...
Spark(37):Streaming DataFrame 和 Streaming DataSet 创建
目录 0. 相关文章链接 1. 概述 2. socket source 3. file source 3.1. 读取普通文件夹内的文件 3.2. 读取自动分区的文件夹内的文件 4. kafka source 4.1. 导入依赖 4.2. 以 Streaming 模式创建 Kafka 工作流 4.3. 通过 Batch 模式创建 Kafka 工作流 5. Rate Source…...

SpringBoot集成Thymeleaf
Spring Boot 集成 Thymeleaf 模板引擎 1、Thymeleaf 介绍 Thymeleaf 是适用于 Web 和独立环境的现代服务器端 Java 模板引擎。 Thymeleaf 的主要目标是为开发工作流程带来优雅的自然模板,既可以在浏览器中正确显示的 HTML,也可以用作静态原型…...
:牛客在线编程03 二叉树)
算法练习(2):牛客在线编程03 二叉树
package jz.bm;import jz.TreeNode;import java.util.*;public class bm3 {/*** BM23 二叉树的前序遍历*/public int[] preorderTraversal (TreeNode root) {ArrayList<Integer> list new ArrayList<>();preOrder(root, list);int[] res new int[list.size()];fo…...

回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测
回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测 目录 回归预测 | MATLAB实现TCN-BiLSTM时间卷积双向长短期记忆神经网络多输入单输出回归预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 1.MATLAB实现TCN-BiLSTM时间卷积…...
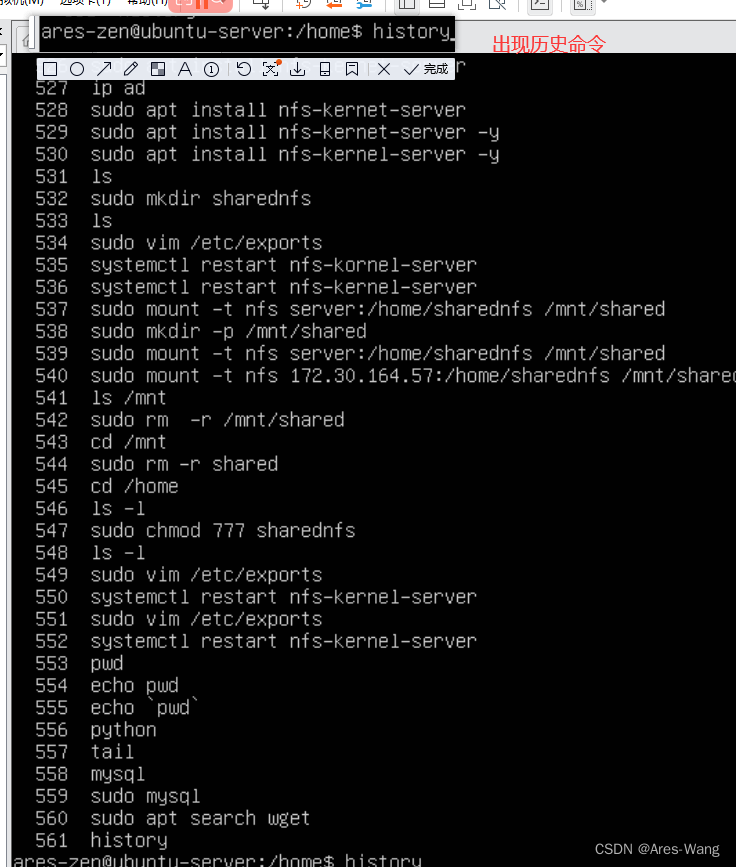
Linux 系列 常见 快捷键总结
强制停止 Ctrl C 退出程序、退出登录 Ctrl D 等价 exit 查看历史命令 history !命令前缀,自动匹配上一个命令 (历史命令中:从最新——》最老 搜索) ctrl r 输入内去历史命令中检索 # 回车键可以直接执行 ctrl a 跳到命令开头 …...
OA系统构建排座
目录 一.排座的介绍,作用 1.排座介绍 A.前端实现 B.数据库实现 C.后端实现 2.排座作用 A.座位预订 B.座位安排 C. 实时座位状态显示 二.利用Layui实现排座 1.基础版(通过htmlcssjs实现) A.基础版源码(html): 2.进阶版 …...

微信小程序 居中、居右、居底和横向、纵向布局,文字在图片中间,网格布局
微信小程序居中、居右、横纵布局 1、水平垂直居中(相对父类控件)方式一:水平垂直居中 父类控件: display: flex;align-items: center;//子控件垂直居中justify-content: center;//子控件水平居中width: 100%;height: 400px //注意…...

【C++】总结2
文章目录 1.final和override关键字2.extern "C"的用法3.野指针和垂悬指针(悬空指针)4.指针指向的内存被释放是什么意思5.C和C的类型安全6.C中的重载、重写(覆盖)和隐藏的区别 1.final和override关键字 final和override是C11引入的关键字&…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

Kerberos身份认证原理与实战排错指南
1. 为什么今天还要花时间搞懂 Kerberos?——一个被低估的“老协议”正在悄悄支撑着你的日常你每天登录公司内网查邮件、访问财务系统提交报销、用 Jenkins 构建代码、甚至在 Windows 域环境中打开一台同事的共享文件夹……这些看似顺滑的操作背后,大概率…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

自制射频功率计:基于AD8317芯片,成本43欧元实现1MHz-10GHz测量
1. 项目概述:为什么我要亲手打造一台射频功率计在无人机和模型飞行器的圈子里,尤其是在我们荷兰FMS Spaarnwoude俱乐部,合规飞行是头等大事。我给我的八轴飞行器加装了云台相机和图传系统,工作在5.8GHz频段。根据本地法规…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

【深度解析】AI Coding 模型竞速:从 Claude Mythos 安全编码到 GPT-5.6 传闻,如何落地代码审查智能体
摘要 AI 编码模型正在从“代码补全”进入“复杂代码库理解、漏洞发现与自动修复”阶段。本文结合 Claude Mythos、Claude Opus 4.8 与 GPT-5.6 相关信息,解析新一代 Coding Agent 的技术趋势,并给出基于大模型 API 的代码安全审查实战方案。背景介绍&…...

FairyGUI Unity鼠标悬停与点击对象获取原理与实战
1. 这不是“加个OnMouseEnter就能用”的事:FairyGUI在Unity中处理鼠标交互的真实困境很多人第一次在Unity里集成FairyGUI,想实现“鼠标悬停显示提示”或“点击高亮当前按钮”,下意识就去翻Unity的MonoBehaviour文档,找OnMouseEnte…...