使用Kmeans算法完成聚类任务
聚类任务
聚类任务是一种无监督学习任务,其目的是将一组数据点划分成若干个类别或簇,使得同一个簇内的数据点之间的相似度尽可能高,而不同簇之间的相似度尽可能低。聚类算法可以帮助我们发现数据中的内在结构和模式,发现异常点和离群值,简化数据表示,以及为进一步的分析提供基础。聚类任务在现实世界中有很多应用场景,以下是其中的一些例子:
-
市场细分:聚类可以帮助将市场分成不同的细分市场,以便更好地针对消费者需求制定营销策略。
-
图像分析:聚类可以用于图像分析,例如将相似的图像分组。
-
模式识别:聚类可以用于发现数据中的模式和关系,例如在医疗领域中,可以使用聚类来发现疾病之间的关系。
-
推荐系统:聚类可以用于推荐系统中,以将用户分组并向他们推荐相似的产品或服务。
K-Means算法
K-Means是一种基于聚类的无监督机器学习算法,其目的是将一组数据点分为k个不同的簇,使得每个数据点与其所属簇的中心点(也称质心)的距离最小化。以下是K-Means的工作原理:
-
初始化:随机选择k个数据点作为初始质心。
-
分配:对每个数据点,计算其与每个质心的距离,并将其分配给距离最近的质心所代表的簇。
-
重新计算质心:对于每个簇,重新计算其质心位置,即将该簇中所有数据点的坐标求平均。
-
重复执行第2,3步,直到所有数据点的簇分配不再改变或达到预设的最大迭代次数为止。
下面是用K-Means算法完成聚类的简单Demo,下面的demo中K设置为2.
from sklearn.cluster import KMeans
import numpy as np
# create some sample data
X = np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])
# create a KMeans object with 2 clusters
kmeans = KMeans(n_clusters=2, random_state=0)
# fit the KMeans object to the data
kmeans.fit(X)
# print the centroids of the two clusters
print(kmeans.cluster_centers_)
# predict the cluster labels for the data points
labels = kmeans.predict(X)
# print the predicted cluster labels for the data points
print(labels)执行结果:cluster_centers_:[[1. 2.][4. 2.]], labels:[0 0 0 1 1 1]
上面的Demo中使用到KMeans函数,KMeans函数是一种聚类分析算法,用于将数据集分成多个簇。其主要作用是将相似的数据点分到同一个簇中,同时将不同的数据点分到不同的簇中。KMeans算法通过迭代寻找最优的聚类结果,可以对数据进行分组、分类和聚类分析。该函数包含多个输入参数,各个参数含义如下:
-
n_clusters:聚类的数量(簇的个数),即K值。默认值为8。如果知道数据的实际类别数目,可以将其设置为该数目;否则,可以通过手动设置不同的聚类数量来寻找最佳解。 -
init:初始化质心的方法。默认为"k-means++",表示使用一种改进的贪心算法来选取初始质心。也可以设置为随机选择初始质心的"random"方法。 -
max_iter:最大迭代次数。默认值为300。当质心移动的距离小于阈值或达到最大迭代次数时,算法停止。 -
tol:质心移动的阈值。默认值为1e-4。当质心移动的距离小于该阈值时,算法停止。 -
n_init:随机初始化的次数。默认值为10。由于KMeans算法易受初始质心的影响,因此可以通过多次运行算法并选择最好的结果来减少随机性的影响。 -
algorithm:KMeans算法实现的方式。默认为"auto",表示由算法自动选择最佳的实现方式("full"表示使用标准的KMeans算法,"elkan"表示使用改进的Elkan算法)。对于大规模数据集,建议使用"elkan"实现方式。
上面的Demo例子是对List数据进行聚类,接下来看看如何使用K-means方法对足球队进行聚类,下面的例子中读取了csv文件中的原始数据,csv文件中存放了不同球队在三次比赛中的排名。
# coding: utf-8
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
import numpy as np
# 输入数据
data = pd.read_csv('./kmeans/data.csv', encoding='gbk')
train_x = data[["2019年国际排名", "2018世界杯", "2015亚洲杯"]]
kmeans = KMeans(n_clusters=3)
# 规范化到[0,1]空间
min_max_scaler = preprocessing.MinMaxScaler()
train_x = min_max_scaler.fit_transform(train_x)
# kmeans算法
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x)
# 合并聚类结果,插入到原数据中
result = pd.concat((data, pd.DataFrame(predict_y)), axis=1)
result.rename({0: u'聚类'}, axis=1, inplace=True)
print(result)采用K-means方法进行聚类,假设K=3,聚类后的结果如下所示,可以看到把球队分到了0,1,2三种不同类型中。

对图像进行聚类
上面的例子是对数据进行聚类,下面看看如何对图像进行聚类,下面的Demo例子中将weixin登陆的图标按不同像素下的颜色分成了2类。
# -*- coding: utf-8 -*-
# 使用K-means对图像进行聚类,显示分割标识的可视化
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import preprocessing# 加载图像,并对数据进行规范化
def load_data(filePath):# 读文件f = open(filePath, 'rb')data = []# 得到图像的像素值img = image.open(f)# 得到图像尺寸width, height = img.sizefor x in range(width):for y in range(height):# 得到点(x,y)的三个通道值c1, c2, c3 = img.getpixel((x, y))data.append([c1, c2, c3])f.close()# 采用Min-Max规范化mm = preprocessing.MinMaxScaler()data = mm.fit_transform(data)return np.asarray(data), width, height# 加载图像,得到规范化的结果img,以及图像尺寸
img, width, height = load_data('./kmeans/weixin.jpg')# 用K-Means对图像进行2聚类
kmeans = KMeans(n_clusters=3)
kmeans.fit(img)
label = kmeans.predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像pic_mark,用来保存图像聚类的结果,并设置不同的灰度值
pic_mark = image.new("L", (width, height))
for x in range(width):for y in range(height):# 根据类别设置图像灰度, 类别0 灰度值为255, 类别1 灰度值为127pic_mark.putpixel((x, y), int(256 / (label[x][y] + 1)) - 1)
pic_mark.save("./kmeans/weixin_mark1.jpg", "JPEG")下图中第一张图是原图,第二张图是分类K=2的结果。可以看到,因为只进行了2种类型区分,新生成的图片中,纯白色是原图中深蓝色的代表,黑灰色是原图中白亮色的代表。说明聚类正确。



图三是K=16的分类结果,当分类K=16时,和原图就很接近了,K=16的分类代码细节如下所示:
# -*- coding: utf-8 -*-
# 使用K-means对图像进行聚类,并显示聚类压缩后的图像
import numpy as np
import PIL.Image as image
from sklearn.cluster import KMeans
from sklearn import preprocessing
import matplotlib.image as mpimg# 加载图像,并对数据进行规范化
def load_data(filePath):# 读文件f = open(filePath, 'rb')data = []# 得到图像的像素值img = image.open(f)# 得到图像尺寸width, height = img.sizefor x in range(width):for y in range(height):# 得到点(x,y)的三个通道值c1, c2, c3 = img.getpixel((x, y))data.append([(c1 + 1) / 256.0, (c2 + 1) / 256.0, (c3 + 1) / 256.0])f.close()return np.asarray(data), width, height# 加载图像,得到规范化的结果imgData,以及图像尺寸
img, width, height = load_data('./kmeans/weixin.jpg')
# 用K-Means对图像进行16聚类
kmeans = KMeans(n_clusters=16)
label = kmeans.fit_predict(img)
# 将图像聚类结果,转化成图像尺寸的矩阵
label = label.reshape([width, height])
# 创建个新图像img,用来保存图像聚类压缩后的结果
img = image.new('RGB', (width, height))
for x in range(width):for y in range(height):c1 = kmeans.cluster_centers_[label[x, y], 0]c2 = kmeans.cluster_centers_[label[x, y], 1]c3 = kmeans.cluster_centers_[label[x, y], 2]img.putpixel((x, y),(int(c1 * 256) - 1, int(c2 * 256) - 1, int(c3 * 256) - 1))
img.save('./kmeans/weixin_new.jpg')上面介绍了如何使用K-Means算法完成文本类或者图片类聚类任务,在实际项目中,K-Means算法应用非常广泛,主要应用在如下的业务场景中。
-
市场营销:K-Means算法可以对市场消费者进行分类,以便公司更好地了解他们的需求和行为,制定更有效的营销策略。
-
图像处理:K-Means算法可以用于对图像像素进行聚类,以实现图像压缩和图像分割等功能。
-
自然语言处理:K-Means算法可以用于对文本数据进行聚类,以实现语义分析和文本分类等功能。
-
生物信息学:K-Means算法可以用于对生物数据进行聚类,以实现基因分类和蛋白质分类等功能。
-
金融领域:K-Means算法可以用于对金融数据进行聚类,以实现风险评估和资产管理等功能。
上面提到K-Means算法可以对图像像素进行聚类,以实现图像压缩的功能,下面的例子中就采用K-Means算法对图片像素进行聚类,从而实现压缩的效果。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from PIL import Image# 加载图片
img = Image.open('./kmeans/baby.jpg')
img_data = np.array(img)# 将三维的图片数组变成二维的像素点数组
pixels = img_data.reshape((img_data.shape[0] * img_data.shape[1], img_data.shape[2]))
# 使用K-Means聚类算法对像素点进行聚类
kmeans = KMeans(n_clusters=16, random_state=0)
labels = kmeans.fit_predict(pixels)# 将每个像素点替换为所属聚类的中心点
new_pixels = kmeans.cluster_centers_[labels]# 将一维的像素点数组还原为图片数组的形式
new_img_data = new_pixels.reshape((img_data.shape[0], img_data.shape[1], img_data.shape[2]))# 显示原始图片和压缩后的图片
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 6))
fig.suptitle('Image Compression using K-Means Clustering')ax1.set_title('Original Image')
ax1.imshow(img_data)ax2.set_title('Compressed Image')
ax2.imshow(new_img_data.astype('uint8'))plt.show()原图和压缩后的图片结果如下所示:
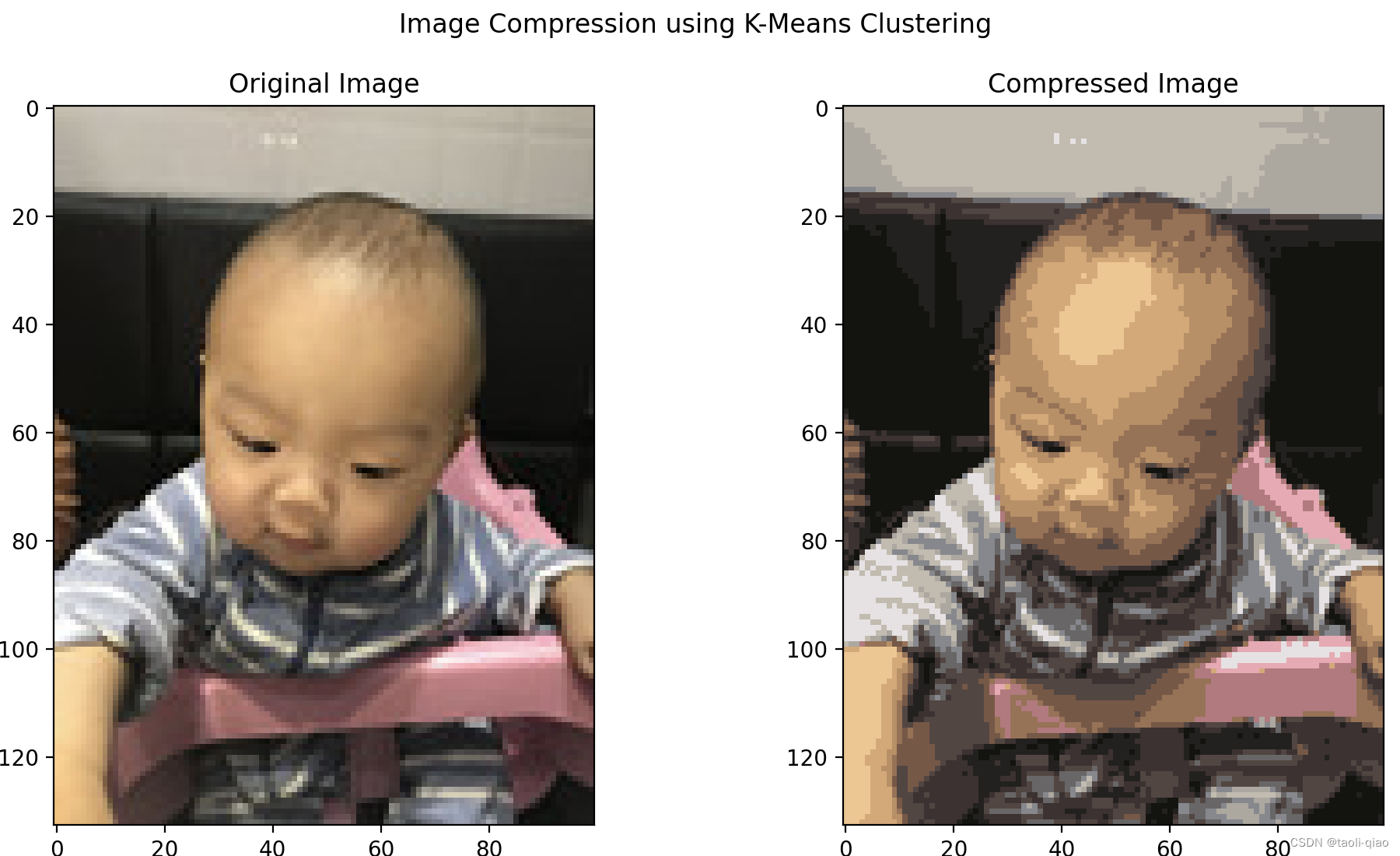
相关文章:
使用Kmeans算法完成聚类任务
聚类任务 聚类任务是一种无监督学习任务,其目的是将一组数据点划分成若干个类别或簇,使得同一个簇内的数据点之间的相似度尽可能高,而不同簇之间的相似度尽可能低。聚类算法可以帮助我们发现数据中的内在结构和模式,发现异常点和离…...
内网穿透技术 - 带你玩转NATAPP
前言 使用内网穿透工具,我们就可以在公网中直接访问在局域网内搭建的服务器网页,也可以直接远程连接到局域网内的机器。本文章主要介绍下NATAPP内网穿透工具的使用。 NATAPP使用教程 官网 在官网先注册,然后登录。登录后,会有一…...

SQL server 简介
SQL server 简介 学习目的 SQL Server 是由微软公司开发的一种关系型数据库管理系统(RDBMS),用于存储和检索数据。它提供了一个可扩展的、安全的和可靠的数据存储和管理解决方案。 SQL Server 主要用于构建企业级应用程序,支持…...

springboot 之以enable开头的注解
Spring 有很多 Enable 开头的注解,平时在使用的时候也没有注意过为什么会有这些注解 Enable 注解 首先我们先看一下有哪些常用的 Enable 开头的注解,以及都是干什么用的。 EnableRetry:开启Spring 的重试功能; EnableSch…...

#P1007. [NOIP2007提高组] 矩阵取数游戏
题目描述 帅帅经常跟同学玩一个矩阵取数游戏:对于一个给定的 n \times mnm 的矩阵,矩阵中的每个元素 a_{i,j}ai,j 均为非负整数。游戏规则如下: 每次取数时须从每行各取走一个元素,共 nn 个。经过 mm 次后取完矩阵内所有元素&…...
TypeScript基础篇 - TS模块
目录 模块的概念 Export 语法(default) Export 语法(non-default) import 别名 Type Export语法【TS】 模块相关配置项:module【tsconfig.json】 模块相关配置项:moduleResolution 小节总结 模块的…...

安卓:Picasso——加载网络图片的库
目录 一、Picasso介绍及其优势 二、Picasso的使用方法 1、添加依赖: 2、Picasso常用方法: 1、加载图像: 2、图像显示: 3、图像处理: 4、图像占位符和错误处理: 5、缓存控制: 6、清除缓…...

1468-PIPI的魔咒
题目描述: 大魔术师PIPI有N个转换魔咒,每个转换魔咒可以将一个字符串变成另一个字符串。 比如说: “PIPI”->“POPO” “boy”->“girl” “boy”->“u” “isau”->“OJ” 那么对于字符串"PIPIisaboy",大魔术师PIPI可…...
3d激光slam建图与定位(1)_基于ndt算法定位
一.代码实现流程 二.ndt算法原理 一.该算法定位有三个进程文件 1.map_loader.cpp用于点云地图的读取,从文件中读取点云后对这个点云地图进行旋转平移后发布点云地图到ros #include "map_loader.h"MapLoader::MapLoader(ros::NodeHandle &nh){std::st…...
云安全攻防(二)之 云原生安全
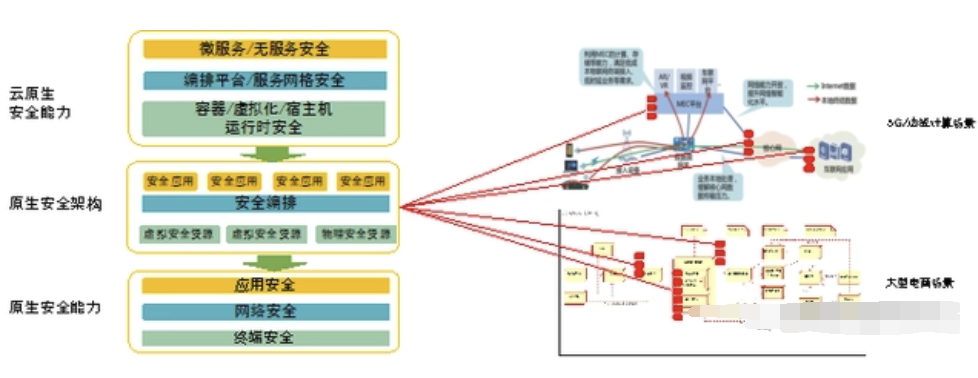
云原生安全 什么是云原生安全?云原生安全包含两层含义:面向云原生环境的安全和具有云原生特征的安全 面向云原生环境的安全 面向云原生环境的安全的目标是防护云原生环境中的基础设施、编排系统和微服务系统的安全。这类安全机制不一定会具有云原生的…...
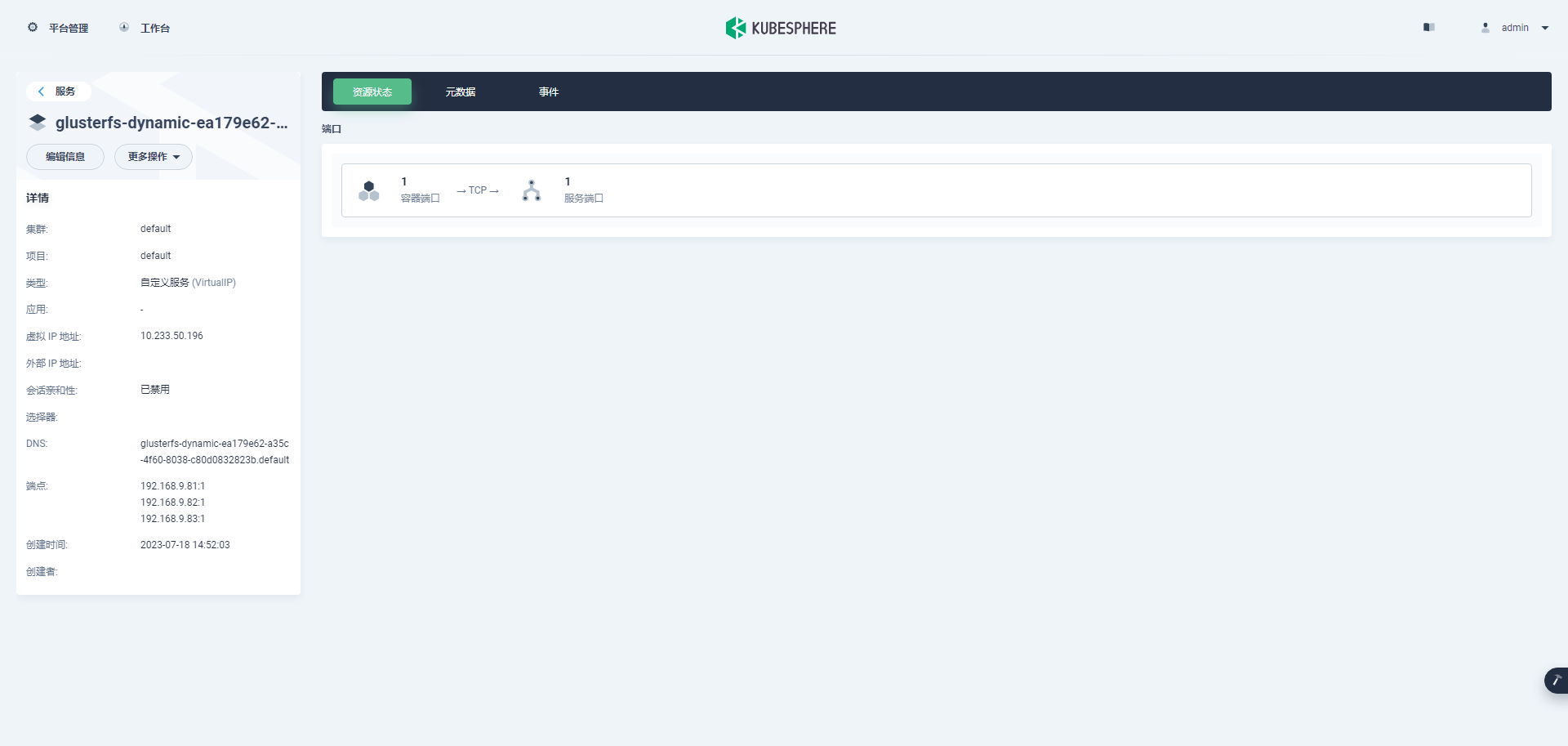
最后的组合:K8s 1.24 基于 Hekiti 实现 GlusterFS 动态存储管理实践
前言 知识点 定级:入门级GlusterFS 和 Heketi 简介GlusterFS 安装部署Heketi 安装部署Kubernetes 命令行对接 GlusterFS 实战服务器配置(架构 1:1 复刻小规模生产环境,配置略有不同) 主机名IPCPU内存系统盘数据盘用途ks-master-0192.168.9.912450100…...
)
笙默考试管理系统-MyExamTest(16)
笙默考试管理系统-MyExamTest(16) 目录 一、 笙默考试管理系统-MyExamTest 二、 笙默考试管理系统-MyExamTest 三、 笙默考试管理系统-MyExamTest 四、 笙默考试管理系统-MyExamTest 五、 笙默考试管理系统-MyExamTest 笙默考试管理系统-MyExa…...

初级算法-树
文章目录 二叉树的最大深度题意:解:代码: 验证二叉搜索树题意:解:代码: 对称二叉树题意:解:代码: 二叉树的层序遍历题意:解:代码: 将有…...

Harbor Failed to start docker.service: Unit docker.service not found.
有可能是修改配置文件导致了问题,最近肯定修改过某个配置文件 本文只针对配置Harbor过程中遇到该问题,很有是deamon.json的 insecure-registries和docker.service的 ExecStart/usr/bin/dockerd --insecure-registry冲突了,删掉一个就好 我使…...
网络安全/信息安全(黑客技术)自学笔记
一、网络安全基础知识 1.计算机基础知识 了解了计算机的硬件、软件、操作系统和网络结构等基础知识,可以帮助您更好地理解网络安全的概念和技术。 2.网络基础知识 了解了网络的结构、协议、服务和安全问题,可以帮助您更好地解决网络安全的原理和技术…...
ADB 命令结合 monkey 的简单使用,超详细
一:ADB简介 1,什么是adb: ADB 全称为 Android Debug Bridge,起到调试桥的作用,是一个客户端-服务器端程序。其中客户端是用来操作的电脑,服务端是 Android 设备。ADB 也是 Android SDK 中的一个工具&…...
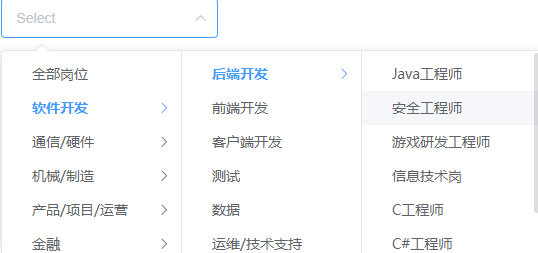
级联选择框
文章目录 实现级联选择框效果图实现前端工具版本添加依赖main.js导入依赖级联选择框样式 后端数据库设计 实现级联选择框 效果图 实现 前端 工具版本 node.js v16.6.0vue3 级联选择框使用 Element-Plus 实现 添加依赖 在 package.json 添加依赖,并 npm i 导入…...
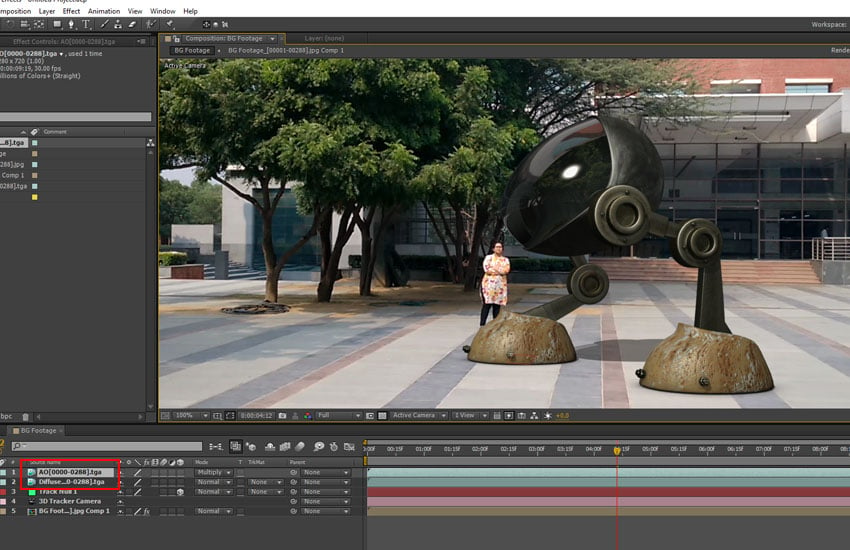
如何在3ds max中创建可用于真人场景的巨型机器人:第 5 部分
推荐: NSDT场景编辑器助你快速搭建可二次开发的3D应用场景 1. After Effects 中的项目设置 步骤 1 打开“后效”。 打开后效果 步骤 2 我有真人版 我在After Effects中导入的素材。这是将 用作与机器人动画合成的背景素材。 实景镜头 步骤 3 有背景 选定的素材…...
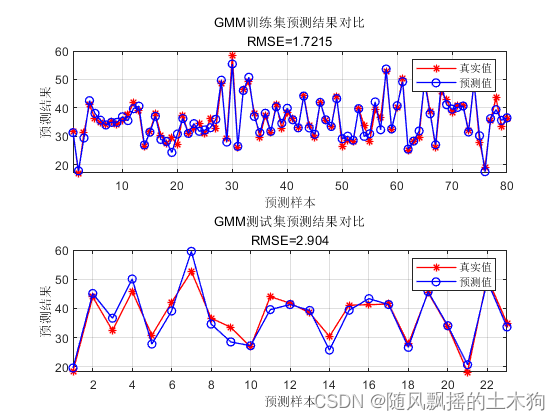
【MATLAB第61期】基于MATLAB的GMM高斯混合模型回归数据预测
【MATLAB第61期】基于MATLAB的GMM高斯混合模型回归数据预测 高斯混合模型GMM广泛应用于数据挖掘、模式识别、机器学习和统计分析。其中,它们的参数通常由最大似然和EM算法确定。关键思想是使用高斯混合模型对数据(包括输入和输出)的联合概率…...
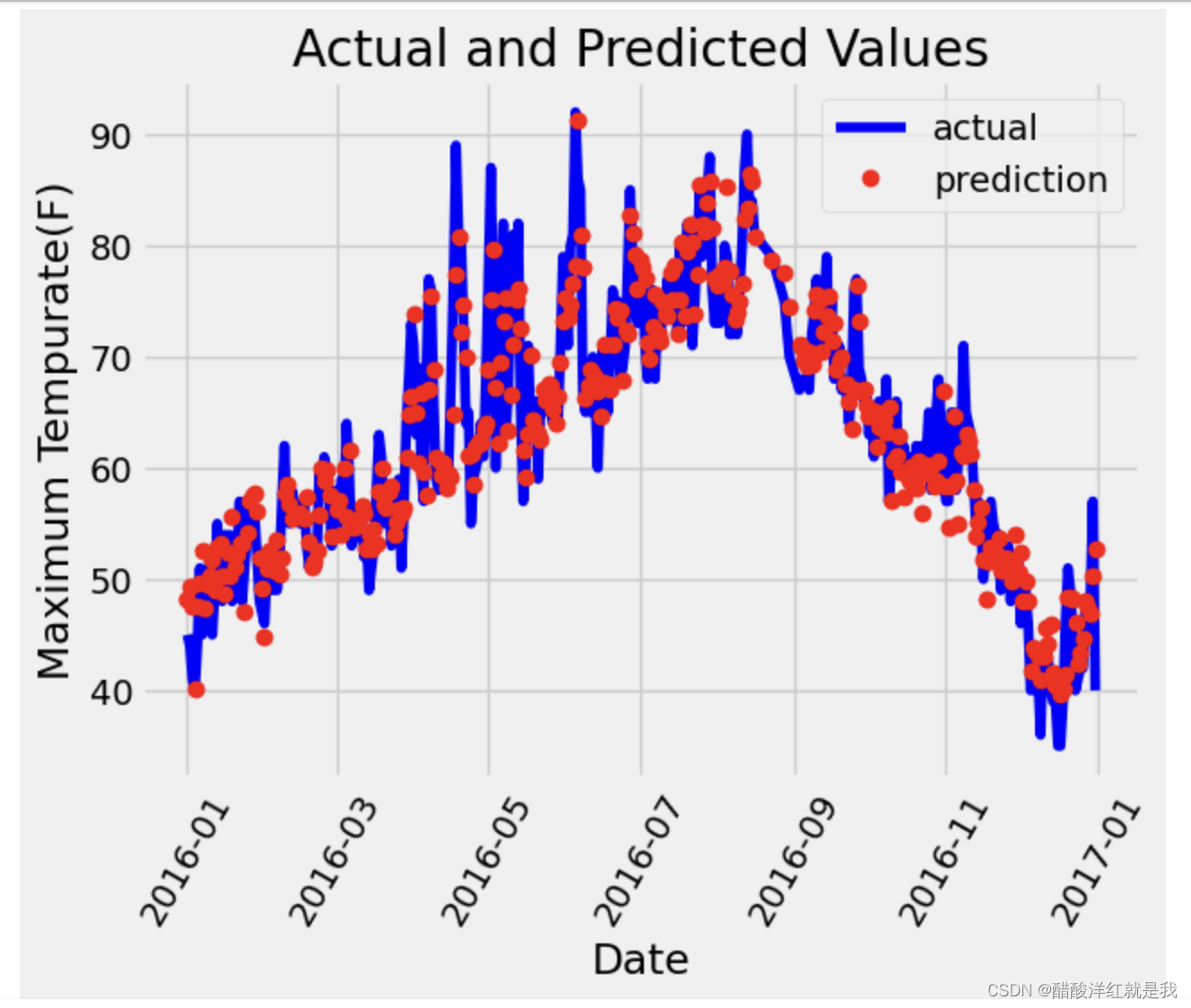
Mnist分类与气温预测任务
目录 传统机器学习与深度学习的特征工程特征向量pytorch实现minist代码解析归一化损失函数计算图Mnist分类获取Mnist数据集,预处理,输出一张图像面向工具包编程使用TensorDataset和DataLoader来简化数据预处理计算验证集准确率 气温预测回归构建神经网络…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

【2026最新】应对Turnitin查重:实测5大英文查降AI宝藏工具,一站式搞定初稿
现在的英文初稿,无论是期刊文章、SCI 还是普通的 Course Essay,基本都需要评估内容的原创度,进行文章 AI 率检测。很多伙伴以为纯手敲就能过,结果一查数据依然不尽如人意。 针对英文内容,咱们必须使用专门的英文检测和…...

苏州创新药20年,站上全球产业洗牌暴风眼
一个城市的创新药产业集群如何从无到有,又如何在全球化临界点寻找自己的位置。文|徐鑫编|任晓渔过去一年多,苏州是全球创新药产业版图中一个绕不过去的城市。大额海外授权交易频繁传出,在中国高端制造走出去的背景下&a…...

亚马逊 Rufus 关停,Alexa 正式上线:卖家必须读懂的6条新规则
2026年5月13日,亚马逊官方正式宣布,下线Rufus,推出全新AI购物助手:Alexa for Shopping。但是,这不是粗暴地直接下线 Rufus,而是一次购物AI底层架构的重组 —— 将 Rufus 的商品专长 与 Alexa的用户理解力&a…...

雪球网md5__1038参数逆向解析与Node.js复现
1. 这不是“破解”,而是对前端加密逻辑的常规逆向还原你打开雪球网任意一只股票详情页,F12 打开开发者工具,切到 Network 面板,刷新页面——很快就能在 XHR 请求里捕获到类似这样的接口:https://xueqiu.com/stock/cube…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

榨干Codex!OpenAI工程师亲授Codex真正用法
你可能把 Codex 当编程助手用,改改代码,跑跑测试。但它的能力远不止于此。OpenAI 的客户支持工程师 Jason(jxnlco)告诉你,Codex 其实是一套完整的电脑工作系统,从语音输入到自动化,从浏览器操控…...

百度深度学习研究院的“叛将“,带着一颗芯片改变了中国智能驾驶——地平线余凯,从ImageNet冠军到征程出货1000万
大家好,我是写代码的篮球球痴。这篇文章跟我自己有点关系——我开的是理想汽车。理想的智驾系统 AD Pro,搭载的就是地平线征程 5 芯片。2026 年 1 月理想 AD Pro 4.0 推送,基于单颗征程 6M 实现了城市 NOA——这是行业里第一个用单颗 128TOPS…...
)
用Python复现Nature论文:仅需100次循环数据,提前预测锂电池寿命(附完整代码与数据集)
用Python实战预测锂电池寿命:从数据特征到模型部署全解析锂电池作为现代能源存储的核心组件,其寿命预测一直是工业界和学术界关注的焦点。传统方法往往需要等待电池出现明显容量衰减才能进行判断,而最新研究表明,通过分析早期循环…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...