使用 Logstash 及 enrich processor 实现数据丰富自动化
在我之前的文章:
-
Elasticsearch:enrich processor (7.5发行版新功能)
-
Elasticsearch:使用 Elasticsearch ingest pipeline 丰富数据
通过上面的两篇文章的介绍,我们应该充分掌握了如何使用 enrich processor 来丰富数据了。特别是在上面的第二篇文章中,我们需要使用手动来一个一个地通过 Kibana 的界面来写入数据。我们感觉还是比较麻烦。如果我们能够实现自动化来完成整个的操作,那将是非常好的。在今天的文章中,我们将结合 enrich processor 和 Logstash 来实现数据的丰富自动化。我们可以利用 Linux 所提供的脚本来完成数据摄入的自动化。
在一下的展示中,我将使用如下的架构来进行展示:

数据描述
在进行我们的练习之前,我们下载所需要的数据及相关文档:
git clone https://github.com/evermight/elasticsearch-ingestarallels@ubuntu2004:~/data/elasticsearch-ingest/part-3$ pwd
/home/parallels/data/elasticsearch-ingest/part-3
parallels@ubuntu2004:~/data/elasticsearch-ingest/part-3$ tree -L 3
.
├── 01-zip_geo.sh
├── 02-customer.sh
├── 03-product.sh
├── 04-order_item.sh
├── 05-order.sh
├── data
│ ├── customer
│ │ ├── data.csv
│ │ └── readme.txt
│ ├── mysql
│ │ ├── load.sql
│ │ └── readme.md
│ ├── order
│ │ ├── data.csv
│ │ └── data.xlsx
│ ├── order_item
│ │ ├── data.csv
│ │ └── data.xlsx
│ ├── product
│ │ └── data.csv
│ └── zip_geo
│ ├── data.csv
│ └── data.xlsx
├── env.sample
├── logstash
│ ├── customer.conf
│ ├── order.conf
│ ├── order_item.conf
│ ├── product.conf
│ └── zip_geo.conf
├── mapping
│ ├── customer.json
│ ├── order.json
│ └── zip_geo.json
├── part-3.pdf
├── part-3.pptx
├── pipeline
│ ├── customer.json
│ ├── order_item.json
│ └── order.json
├── policy
│ ├── customer.json
│ ├── order_item.json
│ ├── product.json
│ └── zip_geo.json
├── readme.md
├── run.sh
└── teardown.sh如上所示,我们的文档结构如上所示。我们的数据结构如下:
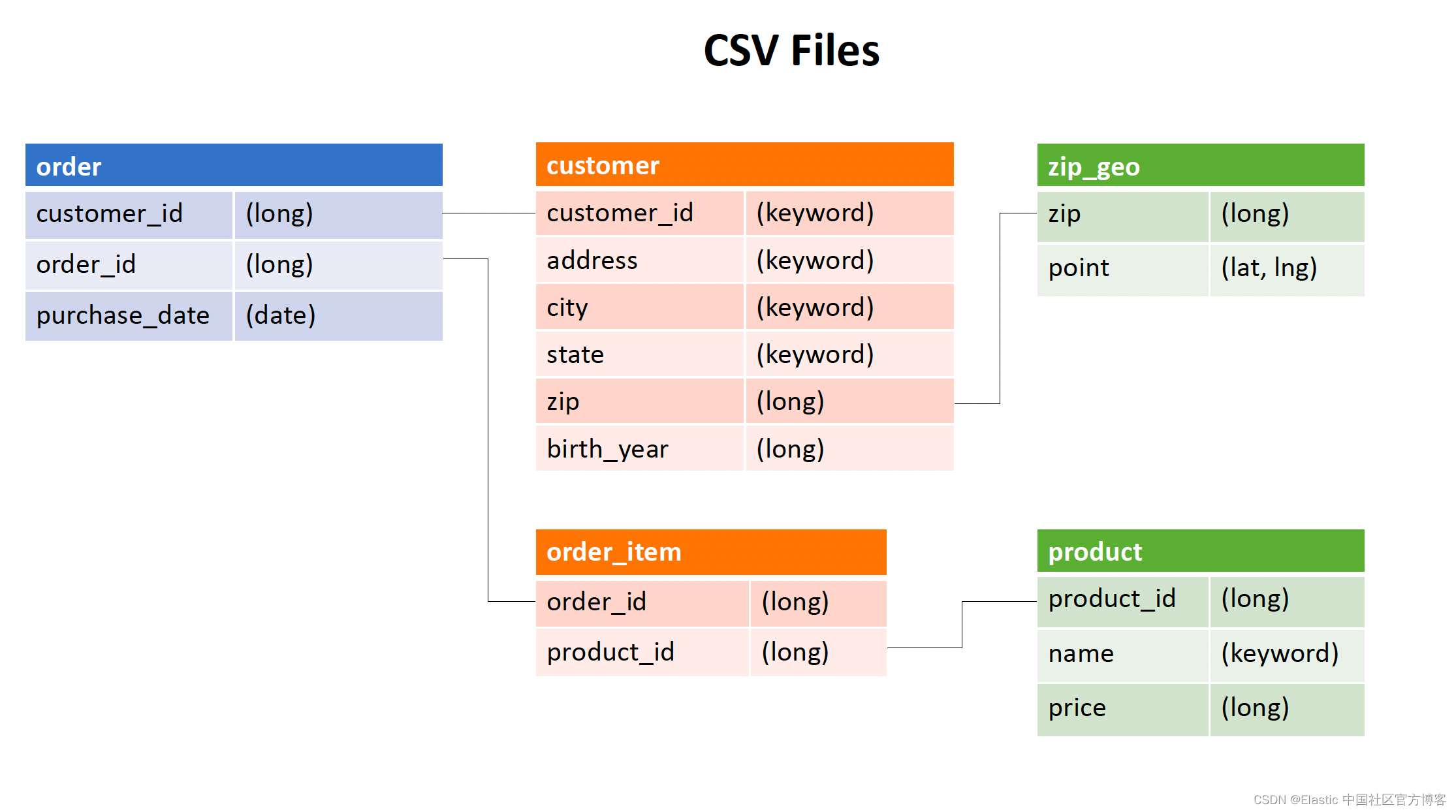
我们有如上的几个表格。它们之间的数据是相互关联的。我们知道在 Elasticsearch 中的数据,它不像传统的关系数据库,在查询的时候,我们可以通过 join 来丰富数据,而且为了能够提高数据的查询速度,我们最好把数据实现扁平化,这也就是的数据的非规范化(denormalization)。我们可以详细阅读文章 “Elasticsearch:Elasticsearch 中索引映射的非规范化”。在摄入数据的时候,我们希望把相关的内容最终能丰富到最后的文档中。我们希望实现如下的内容:

从上面的最终结果,我们可以看出来,我们需要的数据来自不同的表格。这个需要我们使用 enrich processor 来帮我们完成。
文件目录描述
在项目的目录(part-3)下面,我们可以看到如下的几个子目录:
- data:在这个目录里它含有我们需要的各个数据以及它们的来源
- mapping:在这个目录中,它含有各个表格数据的 mapping。通常我们并不需要预先定义数据的类型。我们可以让 Elasticsearch 帮我们自动识别数据的类型,但这往往不是最佳的。通过定义相应数据的 mapping,一方面它可以帮忙明确地定义数据字段的类型,比如 geo_point 数据类型,另一方面,通过设置 mapping,也可以提高数据的摄入速度
- policy:在这个目录中,它定义了使用 enrich processor 时所需要的 policies。
- pipeline:在这个目录里,它定义了在 enrich 时,我们需要使用到的 enrich processor
- logstash:在这个目录里,它定义了 Logstash 需要使用到的配置文件
写入文档的顺序
由于我们的数据是一个关系数据表格,在我们写入数据的时候,我们先从上面图中的右边开始写入数据,这是因为左边的表格依赖于右边的表格。只有它们的数据是准备好的状态,那么我们才可以利用它们来丰富左边的表格。这也就是我们看到的如下的脚本:

如上图所示,我们可以看到
01-zip_geo.sh
02-customer.sh
03-product.sh
04-order_item.sh
05-order.sh 这个其实就是我们执行脚本的顺序。我们需要按照上面的顺序从上到下来进行执行。
摄入数据
我们知道在我们摄入数据的时候,我们可以使用 Logstash 来写入 CSV 文档。Logstash 的好处是,它含有丰富的 filters 来供我们对数据进行处理。

针对 Elastic Stack 8.x 的安装来说,在默认的情况下,Elasticsearch 是带有安全的。针对自签名的集群来说,它通常还含有证书。针对带有安全的集群,我们可以参考文章 “Logstash:如何连接到带有 HTTPS 访问的集群”。下面,我们以摄入 zip_geo 为例来进行展示。在摄入数据的时候,我们需要使用到 fingerprint。我们可以参考文章 “Beats:使用 fingerprint 来连接 Beats/Logstash 和 Elasticsearch”。
在 logstash 目录下,我们可以看到如下的 zip_geo.conf 文档:
zip_geo.conf
input {file {path => "##PROJECTPATH##/data/zip_geo/data.csv"start_position => "beginning"sincedb_path => "/dev/null" mode => "read"exit_after_read => truefile_completed_action => "log"file_completed_log_path => "##PROJECTPATH##/.logstash-status"}
}filter {csv {autodetect_column_names => true}mutate {convert => {"zip" => "integer""point" => "string"}}
}output {elasticsearch {hosts => ["##ELASTICHOST##"]ssl => ##ELASTICSSL##user => "##ELASTICUSER##"password => "##ELASTICPASS##"index => "zip_geo"ssl => trueca_trusted_fingerprint => "##FINGERPRINT##"}
}这是一个标准的 Logstash 配置文件。在上面,我们可以看到一下奇奇怪怪的的像 ##PROJECTPATH## 这样的占位符号。这个需要在哪里配置呢?
我们回到项目的根目录下(part-3),我们可以看到一个叫做 env.sample 的文档。我们通过如下的命令来来创建一个叫做 .env 的文件:
cp env.sample .env我们可以使用我们喜欢的编辑器来编辑这个 .env 文件:
vi .envPROJECTPATH="/home/parallels/data/elasticsearch-ingest/part-3"
ELASTICHOST="192.168.0.3:9200"
ELASTICSSL="true"
ELASTICUSER="elastic"
ELASTICPASS="h6y=vgnen2vkbm6D+z6-"
FINGERPRINT="bd0a26dc646ef1cb3cb5e132e77d6113e1b46d56ee390dd3c6f0b2d2b16962c4"
LOGSTASHPATH="/home/parallels/elastic/logstash-8.8.2"我们根据自己的配置填入上面的信息。其中 FINGERPRINT 最为简单的办法就是通过 Kibana 的配置文件 config/kibana.yml 文件来获得。我们保存好上面的文件。这里其实就是定义的环境变量。我们接下来查看 1-zip_geo.sh 文件:
1-zip_geo.sh
#!/bin/bashsource ./.envhostprotocol="http"
if [ "$ELASTICSSL" = "true" ]; thenhostprotocol="https"
ficurl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/zip_geo"
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/zip_geo/_mapping" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/mapping/zip_geo.jsonlogstashconf=`cat ${PROJECTPATH}/logstash/zip_geo.conf`
logstashconf="${logstashconf//\#\#PROJECTPATH\#\#/"$PROJECTPATH"}"
logstashconf="${logstashconf//\#\#ELASTICHOST\#\#/"$ELASTICHOST"}"
logstashconf="${logstashconf//\#\#ELASTICSSL\#\#/"$ELASTICSSL"}"
logstashconf="${logstashconf//\#\#ELASTICUSER\#\#/"$ELASTICUSER"}"
logstashconf="${logstashconf//\#\#ELASTICPASS\#\#/"$ELASTICPASS"}"
logstashconf="${logstashconf//\#\#FINGERPRINT\#\#/"$FINGERPRINT"}"
$LOGSTASHPATH/bin/logstash -e "$logstashconf"curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/policy/zip_geo.jsonsleep 30
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy/_execute"上面的代码看起来很负责,一下子看不太明白。在开始的部分,我们从环境变量里得到 ELASTICSSL 的值。如果 Elasticsearch 集群的访问是 https 访问的,那么这个值应该设置为 true。这个在接下来的 curl 指令中需要用到。值得注意的是:由于我们的集群是自签名的,我们使用 -k 选项来绕开证书的配置,尽管我们也可以通过设置来配置证书的访问。
记下来,我们使用 curl 指令来创建 zip_geo 索引。它的指令的格式有点类似:
curl -k -u elastic:h6y=vgnen2vkbm6D+z6- https://localhost:9200/zip_geo如果是在 Kibana 中的 Dev Tools 中进行操作,它相当于:
PUT zip_geo上述指令创建一个叫做 zip_geo 的指令。
接下来的指令,它相当于:
curl -k -X PUT -u elastic:h6y=vgnen2vkbm6D+z6- ”https://localhost:9200/zip_geo/_mapping" \
-H "Content-Type: application/json" \
-d /Users/liuxg/data/elasticsearch-ingest/part-3/mapping/zip_geo.json上述命令相当于在 Kibana 中打入如下的命令:
PUT zip_geo/_mapping
{"properties": {"zip": {"type": "long"},"point": {"type": "geo_point"}}
}下面的代码:
logstashconf=`cat ${PROJECTPATH}/logstash/zip_geo.conf`
logstashconf="${logstashconf//\#\#PROJECTPATH\#\#/"$PROJECTPATH"}"
logstashconf="${logstashconf//\#\#ELASTICHOST\#\#/"$ELASTICHOST"}"
logstashconf="${logstashconf///\#\#ELASTICSSL\#\#/"$ELASTICSSL"}"
logstashconf="${logstashconf//\#\#ELASTICUSER\#\#/"$ELASTICUSER"}"
logstashconf="${logstashconf//\#\#ELASTICPASS\#\#/"$ELASTICPASS"}"
logstashconf="${logstashconf//\#\#FINGERPRINT\#\#/"$FINGERPRINT"}"
./bin/logstash -e "$logstashconf"这部分代码的真正意思是替换 zip_geo,conf 里含有 “## ... ##" 部分的字符串进行替换。如果你对这个不是很熟悉的话,请参阅网上的链接。在上面的最后部分,我们使用 Logstash 来运行在 logstashconf 变量里的管道。
下面的代码:
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/policy/zip_geo.json它用来运行 zip_geo_policy 以生成相应的 .enrich_zip_geo_policy,,,,, 索引。它想到于如下的命令:
curl -k -X PUT -u elastic:h6y=vgnen2vkbm6D+z6- "https://localhost:9200/_enrich/policy/zip_geo_policy" \
-H "Content-Type: application/json" \
-d @$PROJECTPATH/policy/zip_geo.json在 Kibana 中,我们可以打入如下的命令来实现同样的功能:
PUT /_enrich/policy/zip_geo_policy
{"match": {"indices": "zip_geo","match_field": "zip","enrich_fields": ["point"]}
}由于生成丰富索引需要一定的时间,在脚本的部分,我们挂起 30 秒的时间,当然这个依赖于数据量的多少。
在最后的部分,我们执行:
curl -k -X PUT -u $ELASTICUSER:$ELASTICPASS "$hostprotocol://$ELASTICHOST/_enrich/policy/zip_geo_policy/_execute"它相当于执行:
curl -k -X PUT -u elastic:h6y=vgnen2vkbm6D+z6- "https://localhost:9200/_enrich/policy/zip_geo_policy/_execute"在 Kibana 中,我们可以通过如下的命令来完成相应的功能:
PUT /_enrich/policy/zip_geo_policy/_execute好了,让我们来执行第一个脚本:


运行完,我们的第一个脚本后,我们可以在 Kibana 中进行查看:


我们按照同样的套路依次执行如下的脚本:
02-customer.sh
03-product.sh
04-order_item.sh
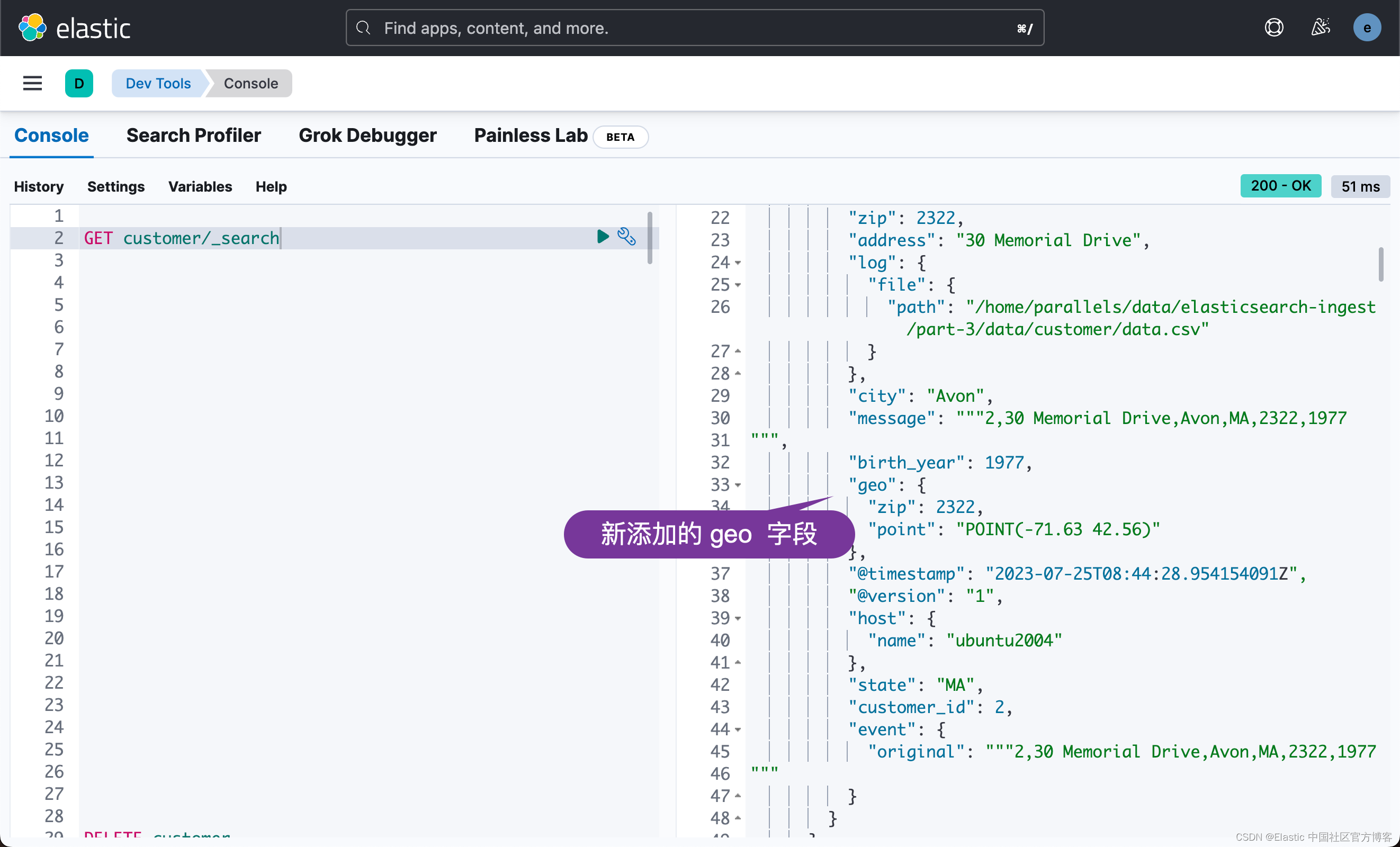
05-order.sh 在运行完 02-customer.sh 后,我们可以看到:
我们接着运行 02-product.sh 脚本。我们可以查看到 product 索引的文档:

我们再接着运行 04-order_item.sh 脚本:

我们接下来运行 05-order.sh:
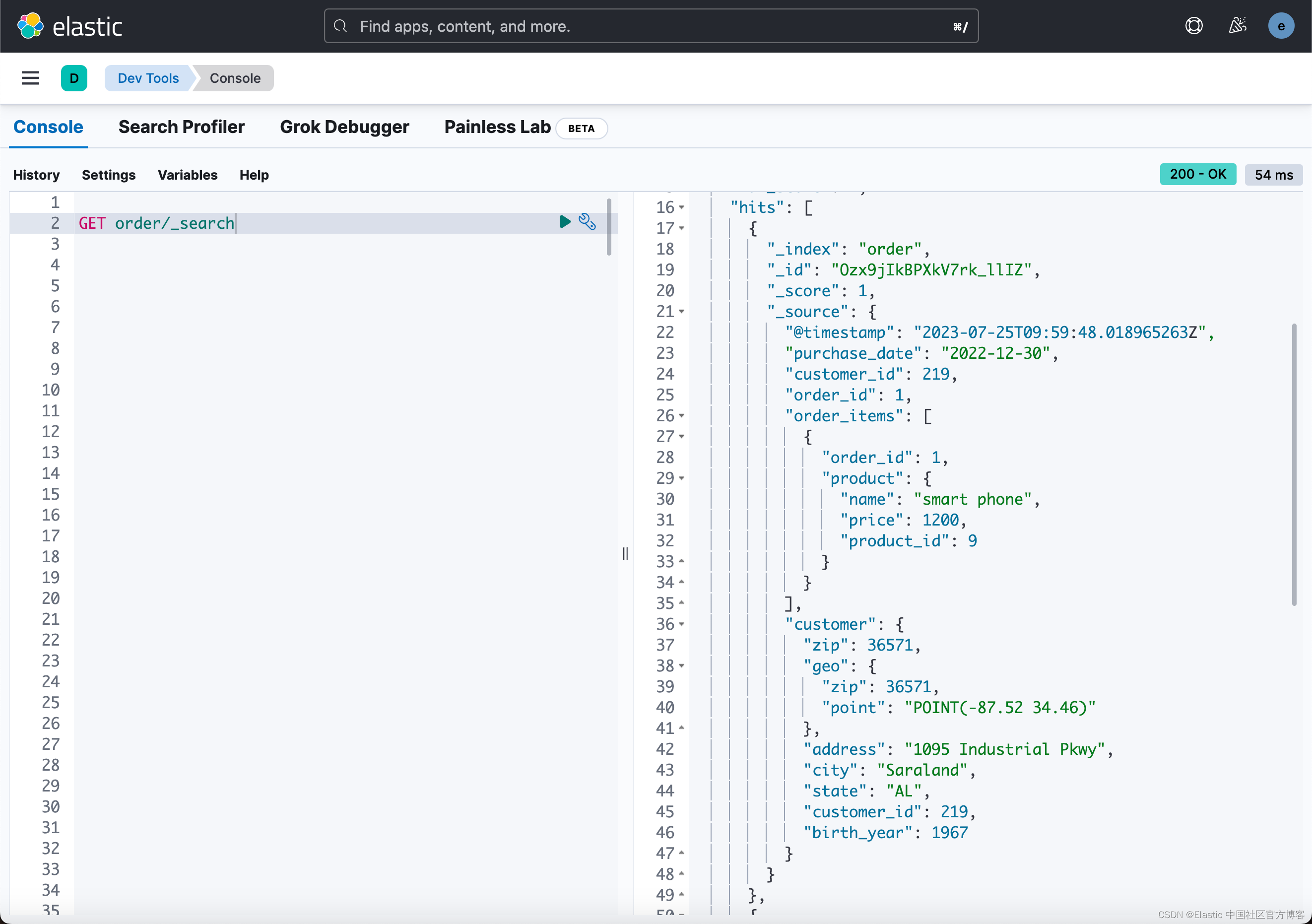
从上面,我们可以看到我们最终想要的结果。
为了能删除所有之前创建的资源,我们可以一键删除:
./teardown.sh然后,我们可以再使用一个命令来完成所有的运行:
parallels@ubuntu2004:~/data/elasticsearch-ingest/part-3$ cat run.sh
./01-zip_geo.sh
./02-customer.sh
./03-product.sh
./04-order_item.sh
./05-order.sh./run.sh特别注意的一点是,我们的 enrich processor 是在 ingest pipeline 里被调用的,比如:
output {elasticsearch {hosts => ["##ELASTICHOST##"]ssl => ##ELASTICSSL##user => "##ELASTICUSER##"password => "##ELASTICPASS##"index => "customer"pipeline => "customer_pipeline"ca_trusted_fingerprint => "##FINGERPRINT##" }
}你可以在地址下载所有的代码:GitHub - evermight/elasticsearch-ingest
相关文章:
使用 Logstash 及 enrich processor 实现数据丰富自动化
在我之前的文章: Elasticsearch:enrich processor (7.5发行版新功能) Elasticsearch:使用 Elasticsearch ingest pipeline 丰富数据 通过上面的两篇文章的介绍,我们应该充分掌握了如何使用 enrich proce…...
Django模板语法和请求
1、在django关于模板文件加载顺序 创建的django项目下会有一个seeetings.py的文件 如果在seeetings.py 中加了 os.path.join(BASE_DIR,‘templates’),如果是pycharm创建的django项目会加上,就会默认先去根目录找templates目录下的html文件,…...

Android跨进程传大图思考及实现——附上原理分析
1.抛一个问题 这一天,法海想锻炼小青的定力,由于Bitmap也是一个Parcelable类型的数据,法海想通过Intent给小青传个特别大的图片 intent.putExtra("myBitmap",fhBitmap)如果“法海”(Activity)使用Intent去传递一个大的Bitmap给“…...

【动态规划part13】| 300.最长递增子序列、674.最长连续递增序列、718.最长重复数组
目录 🎈LeetCode 300.最长递增子序列 🎈LeetCode 674. 最长连续递增序列 🎈LeetCode 718. 最长重复子数组 🎈LeetCode 300.最长递增子序列 链接:300.最长递增子序列 给你一个整数数组 nums ,找到其…...

QMainWindow
文章目录 QMainWindow基本元素QMainWindow函数介绍简单的示例效果图 QMainWindow QMainWindow是一个为用户提供主窗口程序 的类,包含一个菜单栏(menu bar)、多个工具栏 (tool bars)、多个锚接部件(dock widgets)、―个 状态栏(status bar )及一个中心部件(central …...
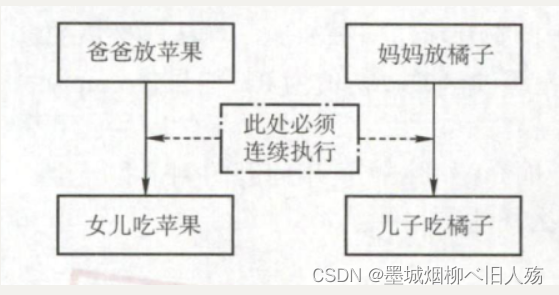
PV操作解决经典进程同步问题
一.经典同步问题 在学习《操作系统》时,会接触到进程的概念,其中不可避免的接触到进程同步问题,今天我们用熟悉的PV操作解决一些经典的进程同步问题。 二.生产者-消费者问题 1.问题描述 问题描述:一组生产者进程和一组消费者进…...

一文3000字从0到1使用Selenium进行自动化测试
对于很多刚入门的测试新手来说,大家都将自动化测试作为自己职业发展的一个主要阶段。可是,在成为一名合格的自动化测试工程师之前,我们不仅要掌握相应的理论知识,还要进行大量的实践,积累足够的经验,以便快…...
基于开源IM即时通讯框架MobileIMSDK:RainbowChat v9.0版已发布
关于MobileIMSDK MobileIMSDK 是一套专门为移动端开发的开源IM即时通讯框架,超轻量级、高度提炼,一套API优雅支持UDP 、TCP 、WebSocket 三种协议,支持iOS、Android、H5、标准Java平台,服务端基于Netty编写。 工程开源地址是&am…...

交叉编译----宿主机x86 ubuntu 64位-目标机ARMv8 aarch64
1.交叉编译是什么,为什么要交叉编译 编译:在一个平台上生成在该平台上的可执行代码交叉编译:在一个平台上生成在另一个平台上的可执行代码交叉编译的例子:如51单片机的可执行代码(hex文件)是在集成环境kei…...
安防监控视频汇聚平台EasyCVR修改录像计划等待时间较长是什么原因?
安防监控视频EasyCVR视频融合汇聚平台基于云边端智能协同,支持海量视频的轻量化接入与汇聚、转码与处理、全网智能分发等。音视频流媒体视频平台EasyCVR拓展性强,视频能力丰富,具体可实现视频监控直播、视频轮播、视频录像、云存储、回放与检…...

深度学习调参指南
1. 选择合适的模型架构 模型的结构(层数和宽度),参数配置,尽量用已经有效的模型 2. 选择优化器 针对具体的问题,从选择常用的优化器开始,进行比较 3. 选择BatchSize 1). Batch Size决定训练速度,但是不影响验证集…...

MYSQL 优化常用方法
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可…...
isp调试工具环境搭建及其介绍!
一、isp调试环境搭建: 后期调试isp,是在rv1126提供的RKISP2.x Tuner工具上进行调试,所以我们大前提必须要把这个环境和一些操作先搞熟悉来,后面有一些专用术语,我们遇到了再去看,现在专门看一些专用术语&am…...
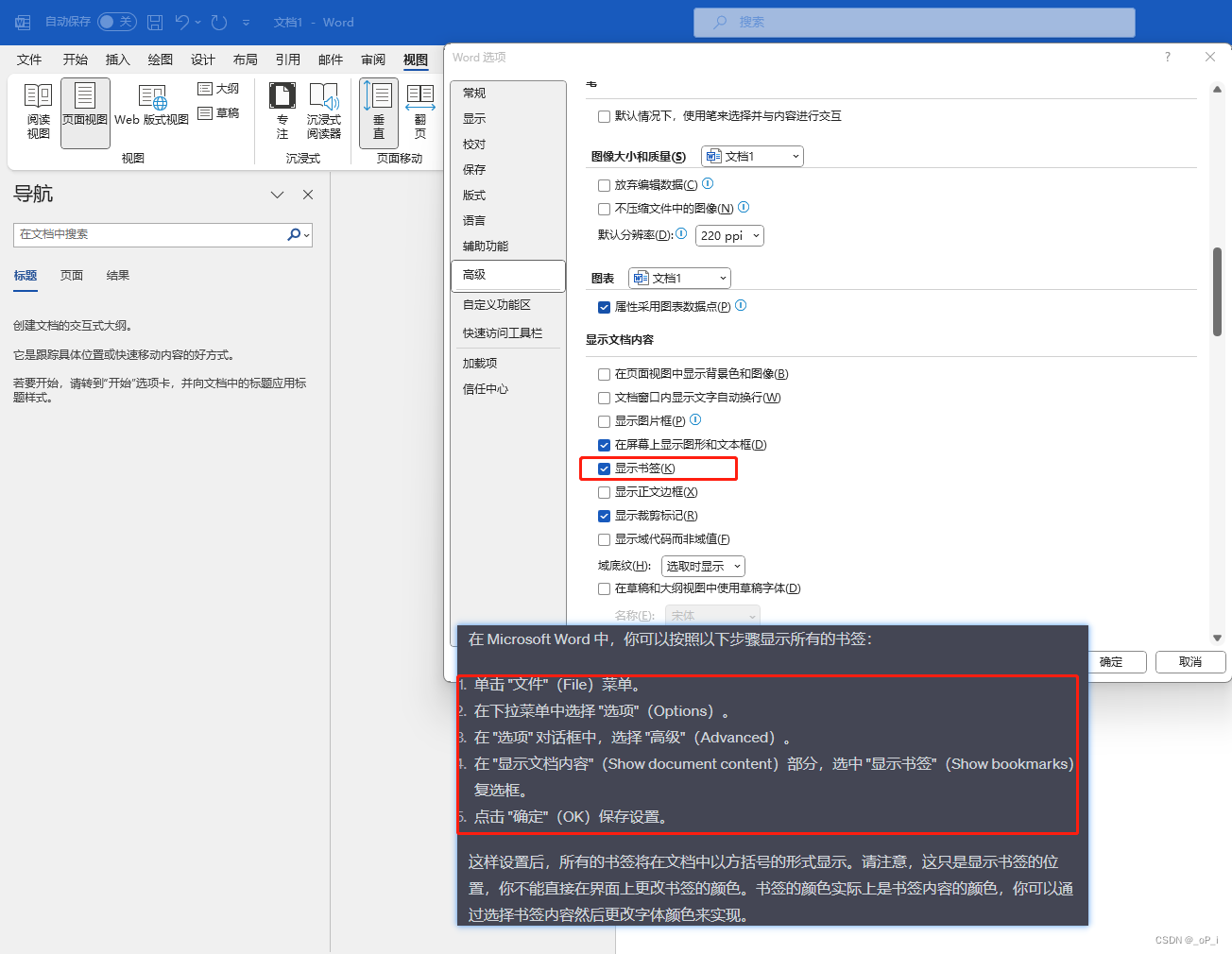
word显示书签并给书签添加颜色
CTRg 定位书签 在 Word 的用户界面中,没有直接的选项可以批量为所有书签设置颜色。但你可以使用 VBA 宏或者编写自定义的功能来实现这个需求。这里给出一个简单的 VBA 宏,它可以设置当前文档中所有书签内文本的颜色:vba Sub ColorAllBookmark…...
 trait备忘录(持续更新))
Rust系列(四) trait备忘录(持续更新)
上一篇:Rust系列(三) 类型系统与trait 基于官方文档进行简单学习记录,保证所有示例是可运行的基本单元。测试rust程序除了使用官方的playground之外,还可以通过定义[[example]]来运行程序。 文章目录 1. Deref2. DerefMut 1. Deref 用于不可…...

贪心算法总结及其leetcode题目N道
1 我为什么要写这个总结 1.1 字节笔试题 小明在玩一场通关游戏,初始血量为1,关卡有怪兽或者有血包(正数就是血包可回血数,负数说明是怪兽的伤害值),当捡到血包时会加血量,碰到怪兽时会掉血&am…...

k8s的namespace一直处于terminating的解法
先试了强制替换,无法替换掉,强制删除,也删除不掉namespace [rootmaster k8s-study]# vi ns-demo.yaml [rootmaster k8s-study]# kubectl create -f ns-demo.yaml namespace/demo created [rootmaster k8s-study]# kubectl get -f ns-demo.ya…...

JAVA面试总结-Redis篇章(六)——数据过期策略
Java面试总结-Redis篇章(六)——数据过期策略 Redis数据删除策略——惰性删除Redis数据删除策略——定期删除 Redis数据删除策略——惰性删除 Redis数据删除策略——定期删除...
【LLM】大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model
大语言模型学习之LLAMA 2:Open Foundation and Fine-Tuned Chat Model 快速了解预训练预训练模型评估微调有监督微调(SFT)人类反馈的强化学习(RLHF)RLHF结果局限性安全性预训练的安全性安全微调上手就干使用登记代码下载获取模型转换模型搭建Text-Generation-WebUI分发模型…...

Android是如何识别USB信号的
Android设备通过USB接口与外部设备通信时,会通过USB控制器(USB Controller)与USB设备进行通信。USB控制器是Android设备的一个硬件组件,它负责管理USB总线并控制所有USB设备的连接和通信。 当一个USB设备被插入Android设备的USB接…...

告别格式修改熬夜战!okbiye 一键搞定毕业论文格式规范
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT智能排版 - Okbiye智能写作https://www.okbiye.com/typesetting 一、毕业季的格式噩梦:多少论文栽在 “排版” 这一步 临近毕业,不少同学的论文修改稿都卡在了格式环节…...

魔兽争霸3闪退修复终极指南:5步让你的经典游戏重获新生
魔兽争霸3闪退修复终极指南:5步让你的经典游戏重获新生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3闪退而烦恼吗&…...

BetterGI原神自动化工具:5分钟快速上手指南,解放你的游戏时间
BetterGI原神自动化工具:5分钟快速上手指南,解放你的游戏时间 【免费下载链接】better-genshin-impact 📦BetterGI 更好的原神 - 自动拾取 | 自动剧情 | 全自动钓鱼(AI) | 全自动七圣召唤 | 自动伐木 | 自动刷本 | 自动采集/挖矿/锄地 | 一条…...

Warcraft Helper终极指南:5分钟让你的魔兽争霸3在现代系统流畅运行
Warcraft Helper终极指南:5分钟让你的魔兽争霸3在现代系统流畅运行 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在Wind…...

强化学习入门ⅡCS188 Note10 学习笔记
更好的阅读体验 Approximate Q-learning Q-learning虽然很有优势,但是缺乏了泛化能力。当pacman学习了figure1中的困境后,智能体是不会意识到figure2,figure3中的情景和figure1中的困境基本一样 所以说Q-Learning很有局限性,这时候该算法…...

去偏机器学习在左截断右删失数据因果生存分析中的应用
1. 项目概述:当生存分析遇上复杂数据与因果推断在生物医学、流行病学乃至社会科学研究中,我们常常关心一个关键事件发生的时间:从接受某种治疗到疾病复发,从开始暴露于某种风险因素到出现特定结局,或者从产品发布到用户…...

DriverStore Explorer终极指南:Windows驱动管理的完整实用方案
DriverStore Explorer终极指南:Windows驱动管理的完整实用方案 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统盘空间不断减少而烦恼?是否…...

告别ibus!Ubuntu 22.04 LTS下Fcitx5+搜狗输入法保姆级配置指南
Ubuntu 22.04 LTS 现代化输入方案:Fcitx5与搜狗输入法深度整合指南在Linux桌面环境中,输入法配置一直是中文用户面临的经典难题。Ubuntu 22.04 LTS作为长期支持版本,其默认的IBus框架对中文输入的支持始终差强人意。本文将带你探索更先进的解…...
和Windows上彻底卸载AWS CLI v2)
告别混乱:如何在不同Linux发行版(openEuler/Ubuntu)和Windows上彻底卸载AWS CLI v2
彻底卸载AWS CLI v2:跨平台深度清理指南当AWS CLI v2出现版本冲突、配置混乱或需要重新安装时,简单的删除操作往往无法彻底清除所有痕迹。本文将深入探讨如何在Windows、Ubuntu和openEuler系统上执行外科手术式卸载,确保不留任何残留文件。1.…...

机器学习势函数与元动力学模拟:揭示电催化水分解的原子尺度反应机理
1. 项目概述:当机器学习势函数遇上电催化水分解 在电催化水分解这个充满前景的清洁能源技术领域,析氧反应(OER)一直是个“老大难”问题。它发生在电解池的阳极,需要将水分子高效地拆解成氧气、质子和电子。这个过程的效…...