Redis如何实现排行榜?
今天给大家简单聊聊 Redis Sorted Set 数据类型底层的实现原理和游戏排行榜实战。特别简单,一点也不深入,也就 7 张图,粉丝可放心食用,哈哈哈哈哈~~~~。
1. 是什么
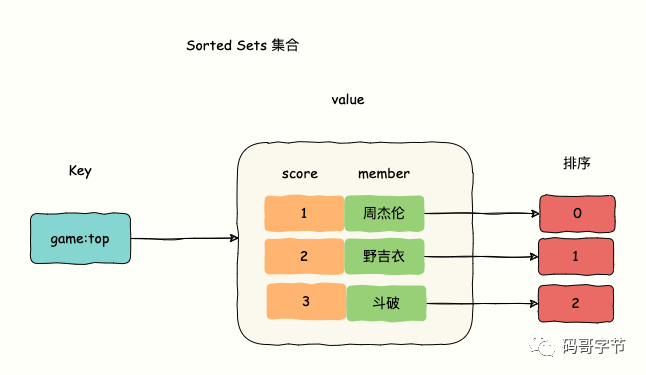
Sorted Sets 与 Sets 类似,是一种集合类型,集合中不会出现重复的数据(member)。区别在于 Sorted Sets 元素由两部分组成,分别是 member 和 score。
member 会关联一个 double 类型的分数(score),sorted sets 默认会根据这个 score 对 member 进行从小到大的排序,如果 member 关联的分数 score 相同,则按照字符串的字典顺序排序。
这是规则,得记下来。
2-24
常见的使用场景:
-
排行榜,比如维护大型在线游戏中根据分数排名的 Top 10 有序列表。
-
速率限流器,根据排序集合构建滑动窗口速率限制器。
-
延迟队列,score 存储过期时间,从小到大排序,最靠前的就是最先到期的数据。
2. 修炼心法
Sorted Sets 底层有两种方式来存储数据。
-
在 7.0 版本之前是 ziplist,之后被 listpack 代替,使用 listpack 存储的条件是集合元素个数小于等于
zset-max-listpack-entries配置值(默认 128),且 member 占用字节大小小于zset-max-listpack-value配置值(默认 64)时使用 listpack 存储,member 和 score 紧凑排列作为 listpack 的一个元素进行存储。 -
不满足上述条件,使用 skiplist + dict(散列表) 组合方式存储,数据会插入 skiplist 的同时也会向 dict(散列表)中插入数据 ,是一种用空间换时间的思路。散列表的 key 存放的是元素的 member,value 存储的是 member 关联的 score。
❝MySQL:“也就是说 listpack 适用于元素个数不多且元素内容不大的场景。”
对,使用 listpack 存储的目的就是节省内存。
Sorted Sets 能支持高效的范围查询,正是因为采用了 skiplist 跳表,比如 ZRANGE 命令时时间复杂度为 O(log(n)) + m, n 是 member 个数,m 是返回结果数。需要注意的是,你应该避免命令会返回大量结果。
而使用 dict 的原因是实现 O(1) 时间复杂度查询单个元素。比如 ZSCORE key member 指令。
总结来说,Sorted Sets 在插入或者更新的时候,会同时往 skiplist 和 散列表中插入或者更新对应的数据。保证 skiplist 和散列表的数据一致。
❝MySQL:“这个方式很巧妙呀,skiplist 用来根据 score 进行范范围查询或者单个查询,dict 散列表则用于实现 O(1) 时间复杂度查根据数据查询对应 score,满足高效范围查询和单元素查询。“
sorted sets 实现源码主要在以下两个文件中。
-
结构定义在
server.h。 -
功能实现在
t_zset.c。
先看 skiplist(跳表) + dict(散列表)数据结构如何存储数据。
skiplist + dict
❝MySQL:“说说什么是跳表吧”
实质就是一种可以进行二分查找的有序链表。跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
不仅能提高搜索性能,还可以提高插入和删除操作的性能。它在性能上和红黑树、AVL 树不相上下,但是跳表的原理和实现比红黑树简单。
回顾链表,它的痛点就是查询很慢,O(n) 时间复杂度,作为唯快不破的 Redis 是不能忍的。

图2-25
如果在有序链表的每相邻两个节点增加一个“跳跃”指向下下个节点的指针,那么查找的时间复杂度就可以降低为原来的一半,如下图所示。

图 2-26
这样 level 0 和 level 1 分别形成两个链表,level 1 层的链表节点个数只有 2 个(6、26)。
跳表节点查找
查找数据总是从最高层开始比较,如果节点保存的值比待查数据小,跳表就继续访问该层的下一个节点;
如果碰到比待查数据值大的节点时,那就跳到当前节点的下一层的链表继续查找。
比如现在想查找 17,查找的路径如下图红色指向的方向进行。

-
从 level 1 开始,17 与 6 比较,值大于节点,继续与下一个节点比较。
-
与 26 比较,17 < 26,回到原节点,跳到当前节点的 level 0 层链表,与下一个节点比较,找到目标 17。
skiplist 正是受这种多层链表的想法启发设计出来的。按照上面的生成链表方式,每次往上增加一层链表的节点个数是下面一层的一半,这样的查找过程就类似于一个二分查找,时间复杂度为 O(log n)。
但是,这种方式在插入数据的时候有很大的问题,每次新增一个节点,就会打乱相邻的两层链表节点个数 2:1 的关系,如果要维持这个关系,就需要对链表调整,事件复杂度是 O(n)。
为了避免这个问题,它不要求上下相邻的两层链表节点个数有严格的比例关系,而是为每个节点随机出一个层数,这样插入节点只需要修改前后指针。
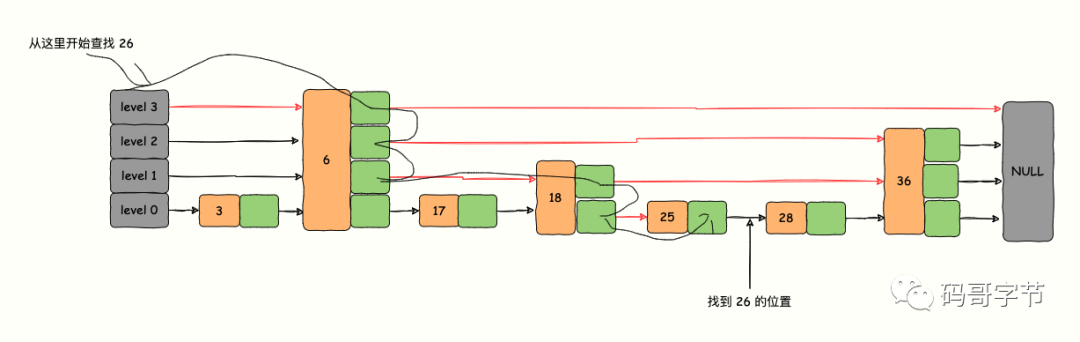
如下图是一个有 4 层链表的 skiplist,假设我们要查找 26,下图给出了查找经历过的路径。
对经典跳表有个直观的映像后,来看看 Redis 中 skiplist 的实现细节,Sorted Sets 数据结构定义如下。
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
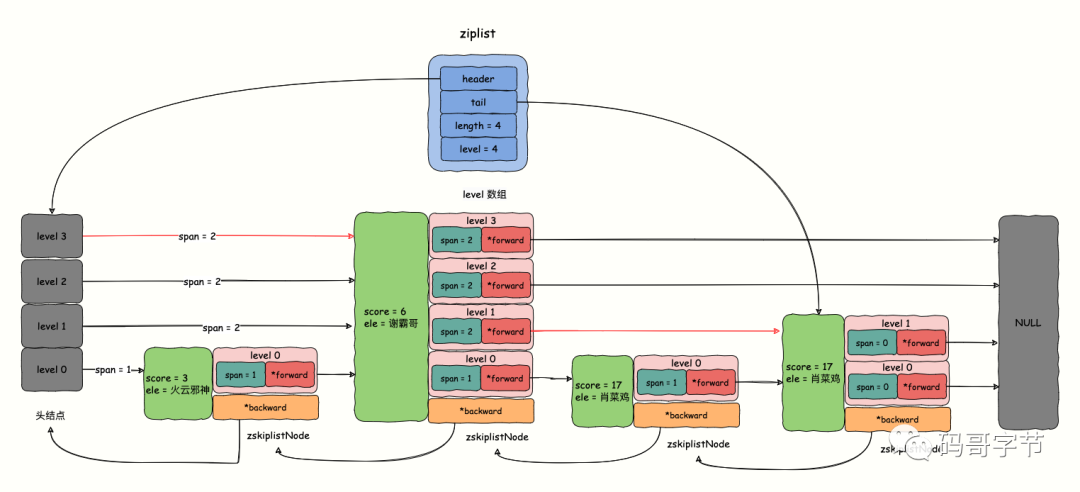
zset 结构体中有两个变量,分别是散列表 dict 和跳表 zskiplist。dict 在前文已经讲过, 重点看 zskiplist 。
typedef struct zskiplist {// 头、尾指针便于双向遍历struct zskiplistNode *header, *tail;// 当前跳表包含元素个数unsigned long length;// 表内节点的最大层级数int level;
} zskiplist;
-
zskiplistNode *header, *tail,两个头、尾指针,用于实现双向遍历。 -
length,链表包含的节点总数。需要注意的是,新创建的zskiplist会生成一个空的头指针,它不包含在 length 计数中。 -
level,表示skiplist中,所有节点层数的最大值。
接着继续看 skiplist 中每个节点的定义 zskiplistNode 结构体。
typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span;} level[];} zskiplistNode;
-
Sorted Set 既要保存元素,又要保存元素的权重。所以对应了 sds 类型的 ele 存储实际内容, double 类型 score 用于保存权重。
-
*backward,后退指针,指向该节点的上一个节点,便于从尾节点实现倒序查找。注意,每个节点只有一个后向指针,只有 level 0 层链表是一个双向链表。 -
level[],是一个zskiplistLevel结构体类型的柔性数组。跳表是一个多层的有序链表,每一层的节点也是由指针链接起来的,所以数组中每个元素代表着 skiplist 的一层。-
*forward,该层的前进指针。 -
span,跨度,用来记录节点在该层的*forward指针到指针指向的下一个节点之间跨越了 level0 层的节点数。span 用于计算元素排名(rank),例如查找 ele = 肖菜鸡、score = 17 的排名,只需要把查找路径经过的节点的 span 相加即可,如下图的红色路径的 span 累加,rank = (2 + 2) - 1 = 3(减 1 是因为 rank 从 0 开始)。如果要计算从大到小的排名,只需要用 skiplist 长度减去查找路径上的 span 累加值,即4 - (2 + 2) = 0。
-
下图展示了 Redis 中一个 skiplsit 的可能结构。
listpack
❝MySQL:“根据
zset结构体定义可知,分别使用了 dict、zskiplist 两种数据结构,listpack 影子都见不着呀。“
这个问题问得好,使用 listpack 存储的细节在源码文件t_zset.c 中的zaddGenericCommand函数中体现,部分代码如下,内部会判断是否使用 listpack 来存储。·
void zaddGenericCommand(client *c, int flags) {// 省略部分代码// key 不存在则创建 sorted setzobj = lookupKeyWrite(c->db,key);if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;if (zobj == NULL) {if (xx) goto reply_to_client;// 当 zset_max_listpack_entries == 0 或者// 元素字节大小大于 zset_max_listpack_value 配置// 则使用 skiplist + dict 存储,否则使用 listpack。if (server.zset_max_listpack_entries == 0 ||server.zset_max_listpack_value < sdslen(c->argv[scoreidx+1]->ptr)){zobj = createZsetObject();} else {zobj = createZsetListpackObject();}dbAdd(c->db,key,zobj);}// 省略部分代码
}
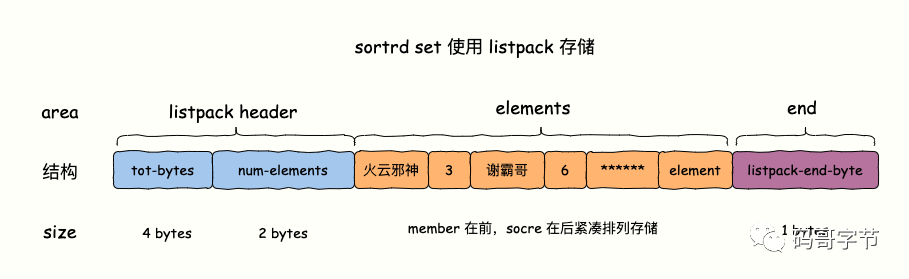
我们知道,listpack 是一块由多个数据项组成的连续内存。而 sorted set 每一项元素是由 member 和 score 两部分组成。
采用 listpack 存储插入一个(member、score)数据对的时候,每个 member/score 数据对紧凑排列存储。
listpack 最大的优势就是节省内存,查找元素的话只能按顺序查找,时间复杂度是 O(n)。正是如此,在少量数据的情况下,才能做到既能节省内存,又不会影响性能。每一步查找前进两个数据项,也就是跨越一个 member/score 数据对。
3. 出招实战:排行榜
很多地方都会用到排行榜功能,比如微博热榜、知乎热榜、电影排行榜、游戏战力排行等。
以游戏排行榜为例,我教你使用 Sorted Set 实现一个实时游戏高分排行榜。
玩家的得分越高,排行越靠前,如果分数相同则先达到该分数的玩家排在前面,游戏排行榜的提供的功能如下。
-
按照分数从大到小排名,查询前 N 位玩家信息。
-
新注册玩家,需要把新玩家信息添加到排行榜中。
-
能查看某个玩家的排名和分数。
Sorted Set 每个元素有两部分组成(member + score),可利用 score 进行排序,正好满足我们的场景。用 score 保存玩家的游戏得分,member 保存玩家 ID。
❝王架构:“分数相同,先达到该分数的排在前面,也就是说,游戏分数相同的情况下,时间戳越小,排名越靠前,咋实现?”
这个问题问得好,既然时间也会影响排名,那就把时间戳考虑到 score 中。
❝王架构:“有问题,分数越大,排名越靠前;而时间戳越小,排名越靠前。两个规则相反的,怎么结合在一起。”
好问题,这时候你可以指定一个非常大的时间作为基准时间,比如这个时间就是你当年信誓旦旦的对那个女孩说:“如果非要在我们的爱上加一个期限,我是希望……一万年”,也就是 2023 + 10000 年。
执行时间排序值 =(基准时间 - 玩家达到分数时间)/ 基准时间公式计算,得到的结果值一定小于 1,正好可作为 score 小数部分。越早达到,这个值就越大,满足排序。
最后score = 玩家游戏分 + ((基准时间 - 玩家获得某分数时间) / 基准时间),就实现了分数相同,先达到该分数的排在前面的功能。
代码逻辑如下所示。
private double calcScore(int playerScore, long playerScoreTime) {return playerScore + (BASE_TIME - playerScoreTime) * 1.0 / BASE_TIME;
}
-
playerScore,玩家游戏分。
-
playerScoreTime,玩家获得分数的时间秒数。
-
BASE_TIME,基准时间的时间秒数。
想要获取真正玩家游戏分数的时候,取整数位即可。接下来我来演示一下如何使用 zset 的指令实现排行榜。
假设 BASE_TIME 为 12023 年 1 月 1 日 0 时 0 分 0 秒时间戳秒数 = 317242022400。
更新排行榜
使用指令 ZADD key score member [score member...] 用于新增或者更新玩家排行榜。如下指令表示新增了 4 个玩家信息到排行榜。leaderboard:339 作为 key,表示区服 339 战力排行榜,玩家 2 和玩家 3 的战力都是 500 分,玩家 3 比玩家 2 先到达 500 战力。
redis> ZADD leaderboard:339 2500.994707057989 player:1
(integer) 1
redis> ZADD leaderboard:339 500.99470705798905 player:2
(integer) 1
redis> ZADD leaderboard:339 500.9947097814618 player:3
(integer) 1
redis> ZADD leaderboard:339 987770.994707058 player:4
(integer) 1
假设某天玩家 4 的女朋友不在家,他就天天玩游戏,战力提升到 1987770。执行如下指令,player:4 的 score 机会更新为 1987770.994707055。
ZADD leaderboard:339 1987770.994707055 player:4
获取 Top 3 玩家排行信息
ZRANGE 命令可以按照排名、score、字典排序进行范围查询。语法使用规则
ZRANGE key start stop [BYSCORE | BYLEX] [REV] [LIMIT offset count] [WITHSCORES]
默认排序是按照 score 由低到高,分数相同则根据 member 字典排序。
-
REV,可选参数,按照 score 由高到低逆序排序。
-
LIMIT offset count 可选参数,类似于 MySQL 的使用,需要注意的是, count 为负数则返回所有符合数据。
-
WITHSCORES 可选参数,返回 score 和 member,返回的格式是 member 1,score 1,…memberN,scoreN。
你可以使用 REV 来实现逆序,WITHSCORES返回 member 和 score。如下指令的一是是从 key 为 leaderboard:339 的 Sorted Set 中按照 score 逆序排序获取 3 个元素。
> ZRANGE leaderboard:339 0 2 REV WITHSCORES
player:4
1987770.9947070549
player:1
2500.9947070579892
player:3
500.99470978146178
获取指定玩家排名
我提供了 ZREVRANK指令,用于返回指定 member 的排名,需要注意的是,排名从 0 开始。如下指令查找 player:4 的排名,0 表示第一。
> ZREVRANK leaderboard:339 player:4
0
相关文章:
Redis如何实现排行榜?
今天给大家简单聊聊 Redis Sorted Set 数据类型底层的实现原理和游戏排行榜实战。特别简单,一点也不深入,也就 7 张图,粉丝可放心食用,哈哈哈哈哈~~~~。 1. 是什么 Sorted Sets 与 Sets 类似,是一种集合类型ÿ…...

Pycharm debug程序,跳转至指定循环条件/循环次数
在断点出右键,然后设置条件 示例 for i in range(1,100):a i 1b i 2print(a, b, i) 注意: 1、你应该debug断点在循环后的位置而不是循环上的位置,然后你就可以设置你的条件进入到指定的循环上了 2、设置条件,要使用等于符号…...

react实现markdown
参考:https://blog.csdn.net/Jack_lzx/article/details/118495763 参考:https://blog.csdn.net/m0_48474585/article/details/119742984 0. 示例 用react实现markdown编辑器 1.基本布局及样式 <><div classNametf_editor_header>头部&…...
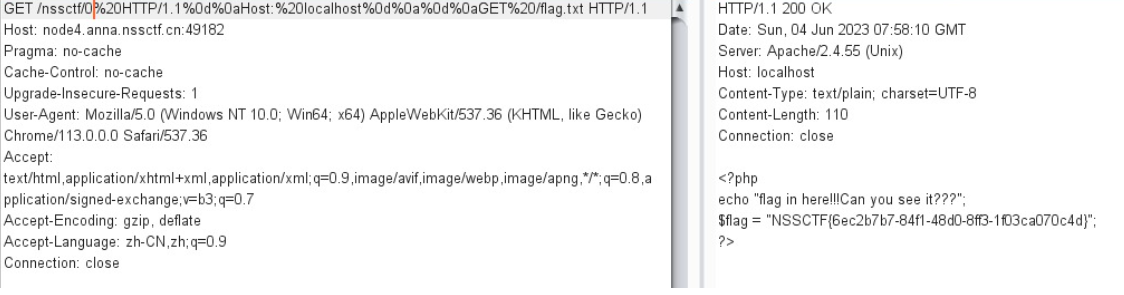
HTTP请求走私漏洞简单分析
文章目录 HTTP请求走私漏洞的产生HTTP请求走私漏洞的分类HTTP请求走私攻击的危害确认HTTP请求走私漏洞通过时间延迟技术确认CL漏洞通过时间延迟技术寻找TE.CL漏洞 使用差异响应内容确认漏洞通过差异响应确认CL.TE漏洞通过差异响应确认TE.CL漏洞 请求走私漏洞的利用通过请求漏洞…...
BI-SQL丨两表差异比较
BOSS:哎,白茶,我们最近新上了一个系统,后续有一些数据要进行源切换,这个能整么? 白茶:没问题,可以整! BOSS:哦,对了,差点忘记告诉你了…...

ZooKeeper 选举的过半机制防止脑裂
结论: Zookeeper采用过半选举机制,防止了脑裂。 原因: 如果有5台节点,leader联系不上了,其他4个节点由于超过半数,所以又选出了一个leader,当失联的leader恢复网络时,发现集群中已…...
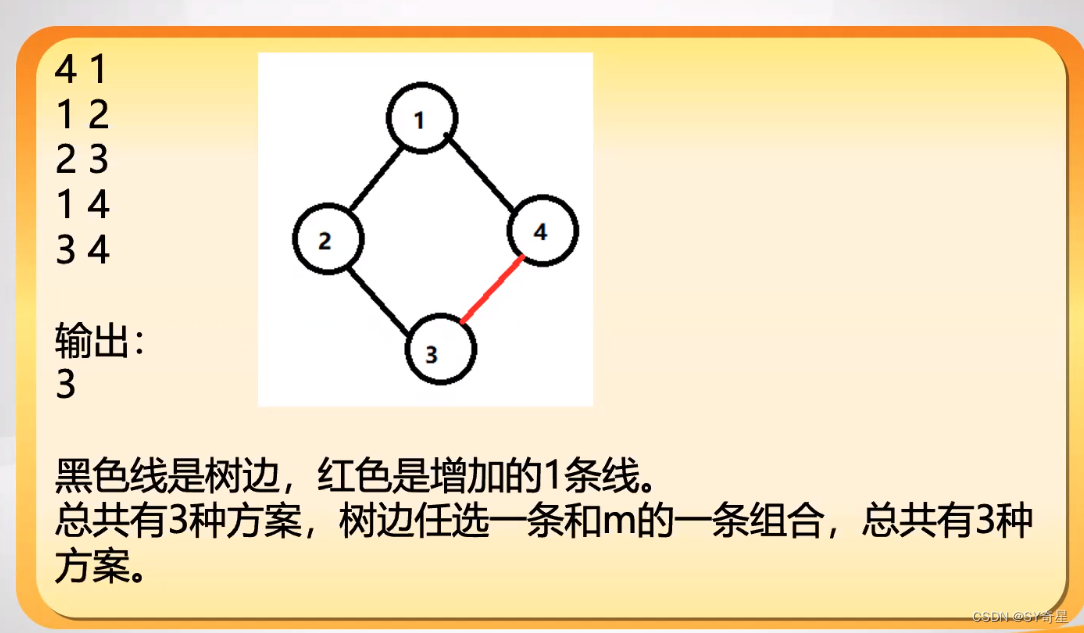
【图论】树上差分(边差分)
一.简介 其实点差分和边差分区别不大。 点差分中,d数组存储的是树上的节点 边差分中,d数组存储的是当前节点到父节点的那条边的差分值。 指定注意的是:边差分中因为根连的父节点是虚点,所以遍历结果时应当忽略! 二…...
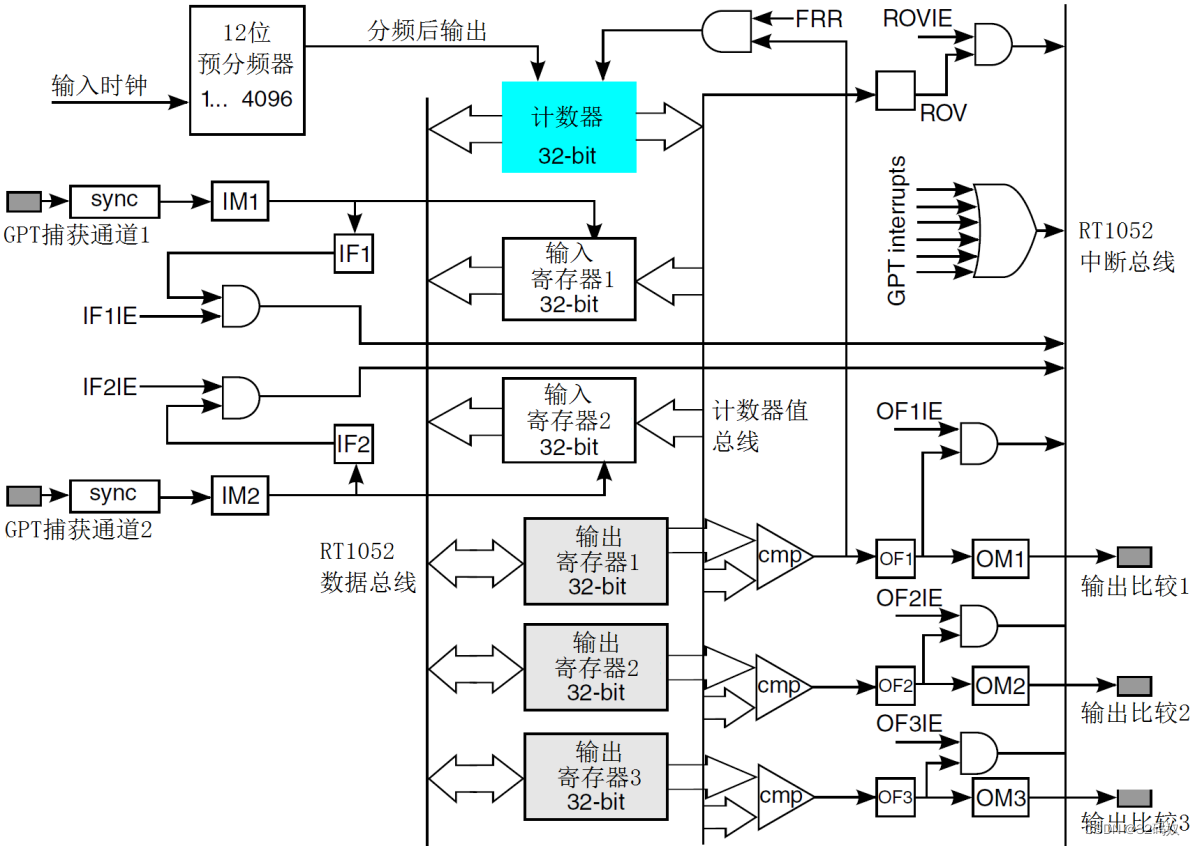
RT1052的定时器
文章目录 1 通用定时器1.1 定时器框图1.2 实现周期性中断 2 相关寄存器3 定时器配置3.1 时钟使能3.2 初始化GPT1定时器3.2.1 base3.2.2 initConfig3.2.2.1 clockSorce3.2.2.2 divider3.2.2.3 enablexxxxx 3.3 设置 GPT1 比较值3.3.1 base3.3.2 channel3.3.3 value 3.4 设置 GPT…...
opencv python 训练自己的分类器
源码下载 一、分类器制作 1.样本准备 收集好你所需的正样本,和负样本,分别保存在不同文件夹 在pycharm新建项目,项目结构如下:has_mask文件夹放置正样本,no_mask文件夹放置负样本 安装opencv,把opencv包…...
详解Mybatis之分页插件【PageHelper】
编译软件:IntelliJ IDEA 2019.2.4 x64 操作系统:win10 x64 位 家庭版 Maven版本:apache-maven-3.6.3 Mybatis版本:3.5.6 文章目录 一. 什么是分页?二. 为什么使用分页?三. 如何设计一个Page类(分…...
【基于矢量射线的衍射积分 (VRBDI)】基于矢量射线的衍射积分 (VRBDI) 和仿真工具(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

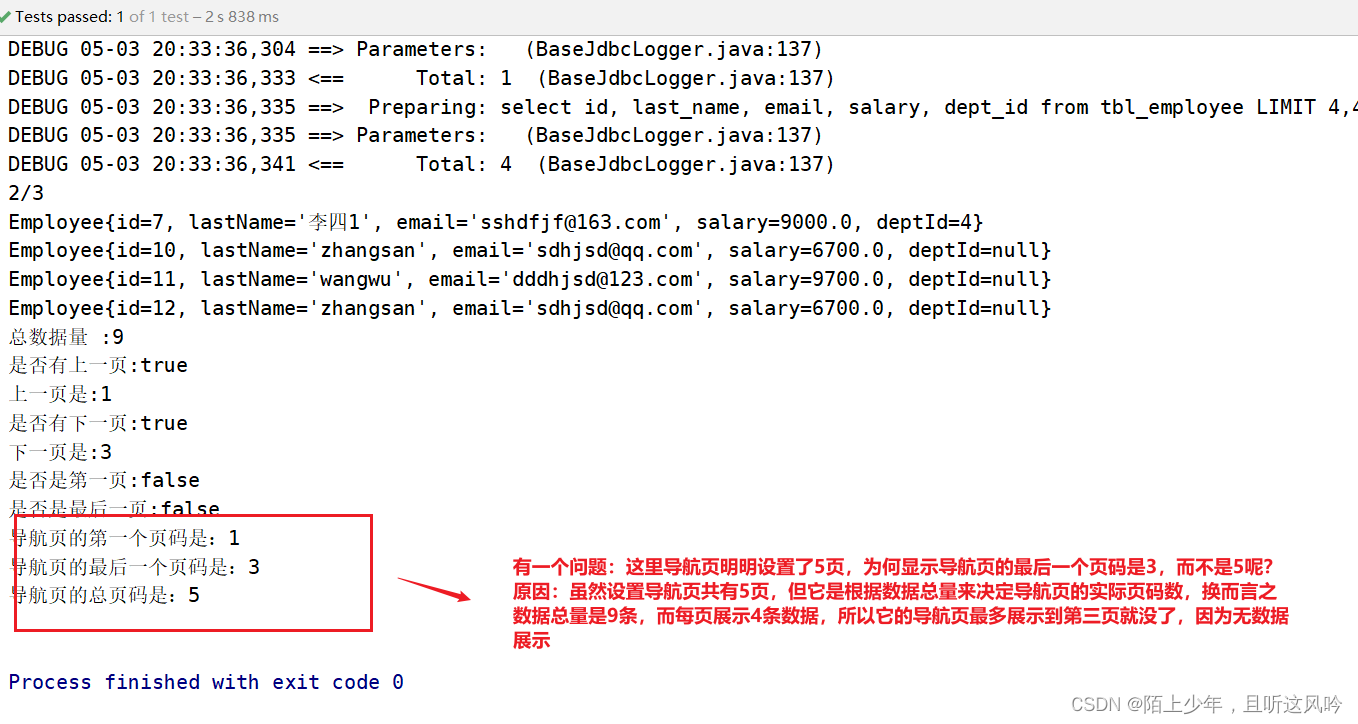
基于jackson对bean的序列号和反序列化
通过观察控制台输出的SQL发现页面传递过来的员工id的值和数据库中的id值不一致,这是怎么回事呢? 分页查询时服务端响应给页面的数据中id的值为19位数字,类型为long 页面中js处理long型数字只能精确到前16位,所以最终通过ajax请求提交给服务…...

排队理论简介
排队理论简介 1. 理论背景2. 研究的数学方法3. 拒绝型排队系统与等候型排队系统4. 拒绝型排队系统 本文参考文献为Вентцель Е. С.的《Исследование операций》。 1. 理论背景 排队理论又称大众服务理论,顾名思义指的是在有限的服务条…...
-算法分析)
极速查找(3)-算法分析
篇前小言 本篇文章是对查找(2)的续讲二叉排序树 二叉排序树(Binary Search Tree,BST),又称为二叉查找树,是一种特殊的二叉树。性质: 左子树的节点值小于根节点的值,右…...

http 常见的响应状态码 ?
100——客户必须继续发出请求101——客户要求服务器根据请求转换HTTP协议版本200——交易成功201——提示知道新文件的URL202——接受和处理、但处理未完成203——返回信息不确定或不完整204——请求收到,但返回信息为空205——服务器完成了请求,用户代理…...
机器学习笔记之优化算法(四)线搜索方法(步长角度;非精确搜索)
机器学习笔记之优化算法——线搜索方法[步长角度,非精确搜索] 引言回顾:精确搜索步长及其弊端非精确搜索近似求解最优步长的条件反例论述 引言 上一节介绍了从精确搜索的步长角度观察了线搜索方法,本节将从非精确搜索的步长角度重新观察线搜…...
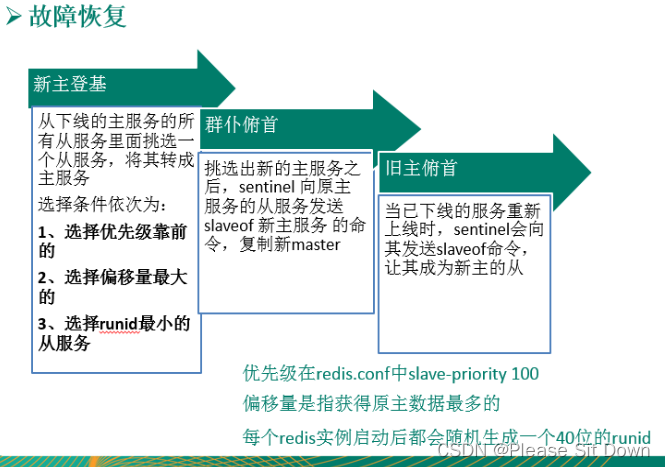
Redis 哨兵 (sentinel)
是什么 官网理论:https://redis.io/docs/management/sentinel/ 吹哨人巡查监控后台 master 主机是否故障,如果故障了根据投票数自动将某一个从库转换为新主库,继续对外服务。 作用:无人值守运维 哨兵的作用: 1…...

统计2021年10月每个退货率不大于0.5的商品各项指标
统计2021年10月每个退货率不大于0.5的商品各项指标_牛客题霸_牛客网s mysql(ifnull): select product_id, format(ifnull(sum(if_click)/nullif(count(*),0),0),3) as ctr, format(ifnull(sum(if_cart)/nullif(sum(if_click),0),0),3) as c…...
【小波尺度谱】从分段离散小波变换计算小波尺度谱研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
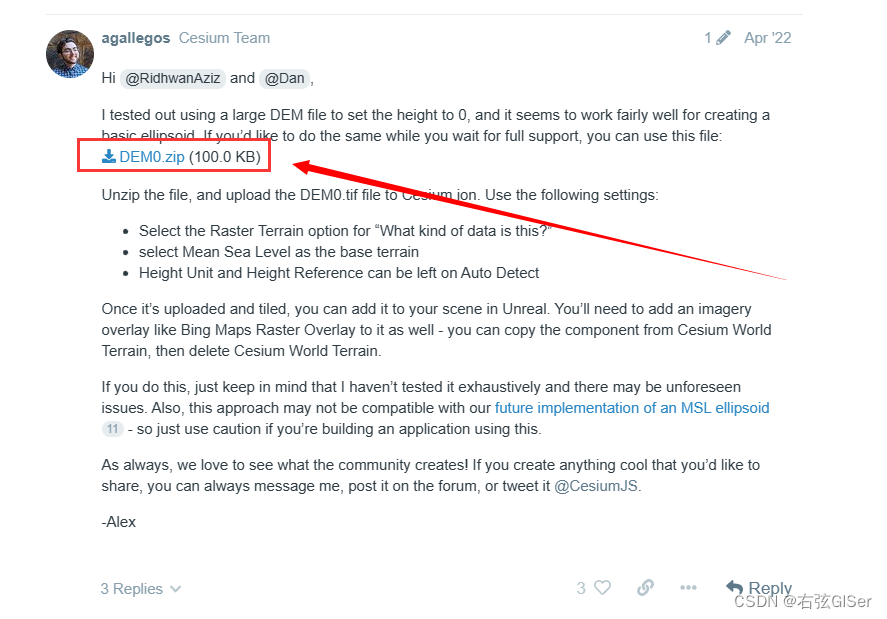
UE5、CesiumForUnreal加载无高度地形
文章目录 1.实现目标2.实现过程3.参考资料1.实现目标 在UE5中,CesiumForUnreal插件默认的地形都是带高度的,这里加载没有高度的地形,即大地高程为0,GIF动图如下: 2.实现过程 参考官方的教程,下载无高度的DEM,再切片加载到UE中。 (1)下载无高度地形DEM0。 在官方帖子…...

OFDM同步避坑指南:STO和CFO估计,选ML还是Classen算法?看这篇就够了
OFDM同步算法实战指南:如何在高干扰环境中选择最优STO/CFO估计方案无线通信工程师在设计OFDM系统时,往往会在同步环节遇到一个关键抉择:面对复杂的信道环境和严苛的性能要求,究竟该选择哪种同步算法组合?这个问题没有标…...

统信UOS 20.1060专业版美化全攻略:从桌面到GRUB再到锁屏,一次搞定个性化设置
统信UOS 20.1060专业版深度美化指南:打造高效统一的视觉工作流第一次打开统信UOS专业版时,默认的蓝色渐变桌面确实给人一种专业稳重的印象。但连续使用几周后,我发现自己开始对着千篇一律的界面走神——这就像每天穿着同样的西装上班…...

告别重装!用Systemback在Ubuntu 20.04上打造你的专属系统‘时光机’
用Systemback为Ubuntu打造专属系统时光机每次系统崩溃都要重装?开发环境配置浪费半天时间?实验室电脑和个人笔记本环境不一致?这些问题对于频繁折腾系统的开发者来说简直是噩梦。Systemback就像给Ubuntu系统装上了"时光机"…...
)
别再让WSL2吃光你的C盘!手把手教你迁移到D盘并优化内存配置(Windows10/11通用)
WSL2系统迁移与性能调优全指南:释放C盘空间与提升运行效率 每次打开资源管理器看到C盘剩余空间不足10%的红色警告,作为开发者的你是否感到一阵窒息?WSL2虽然为Windows带来了原生的Linux体验,但默认安装配置却可能成为系统资源的&q…...

Unity实现CS级FPS手感的四大底层契约与枪械物理精调
1. 这不是又一个“FPS入门教程”,而是一份被反复验证过的实战路线图很多人点开“Unity FPS教程”时,心里想的是:抄几段代码、拖几个预制体、跑通一个能走能跳的场景,就算交差了。我试过不下二十个标着“完整”“从零开始”的FPS项…...

揭秘AI Agent如何3天筛选10万简历:头部猎企正在用的5个私有化部署方案
更多请点击: https://intelliparadigm.com 第一章:AI Agent招聘行业应用全景图 AI Agent正以前所未有的深度与广度重塑招聘行业的技术范式。它不再局限于简历关键词匹配或简单流程自动化,而是以多角色协同、上下文感知、自主决策为特征&…...

用Python复现论文里的CDSM融合:从NuScenes数据预处理到3D检测模型训练全流程
用Python复现论文里的CDSM融合:从NuScenes数据预处理到3D检测模型训练全流程自动驾驶感知系统的核心挑战在于如何有效融合多模态传感器数据。本文将手把手带你实现论文《CDSM: Cross-Domain Spatial Matching for Camera-Radar Fusion in 3D Object Detection》的核…...
专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢)
项目介绍 基于Python的大学生竞赛组队系统设计与实现(含模型描述及部分示例代码)专栏近期有大量优惠 还请多多点一下关注 加油 谢谢 你的鼓励是我前行的动力 谢谢支持 加油 谢谢
基于Python的大学生竞赛组队系统设计与实现的详细项目实例 请注意此篇内容只是一个项目介绍 更多详细内容可直接联系博主本人 或者访问对应标题的完整博客或者文档下载页面(含完整的程序,GUI设计和代码详解) 大学生竞赛已成为高校人才培养…...

抖音无水印下载器:5分钟掌握高效批量下载的完整指南
抖音无水印下载器:5分钟掌握高效批量下载的完整指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support…...

对比直连与通过Taotoken调用大模型API的延迟体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直连与通过Taotoken调用大模型API的延迟体感差异 在集成大模型API到应用时,开发者通常会关注请求的响应速度&#…...