【多模态】21、BARON | 通过引入大量 regions 来提升模型开放词汇目标检测能力

文章目录
- 一、背景
- 二、方法
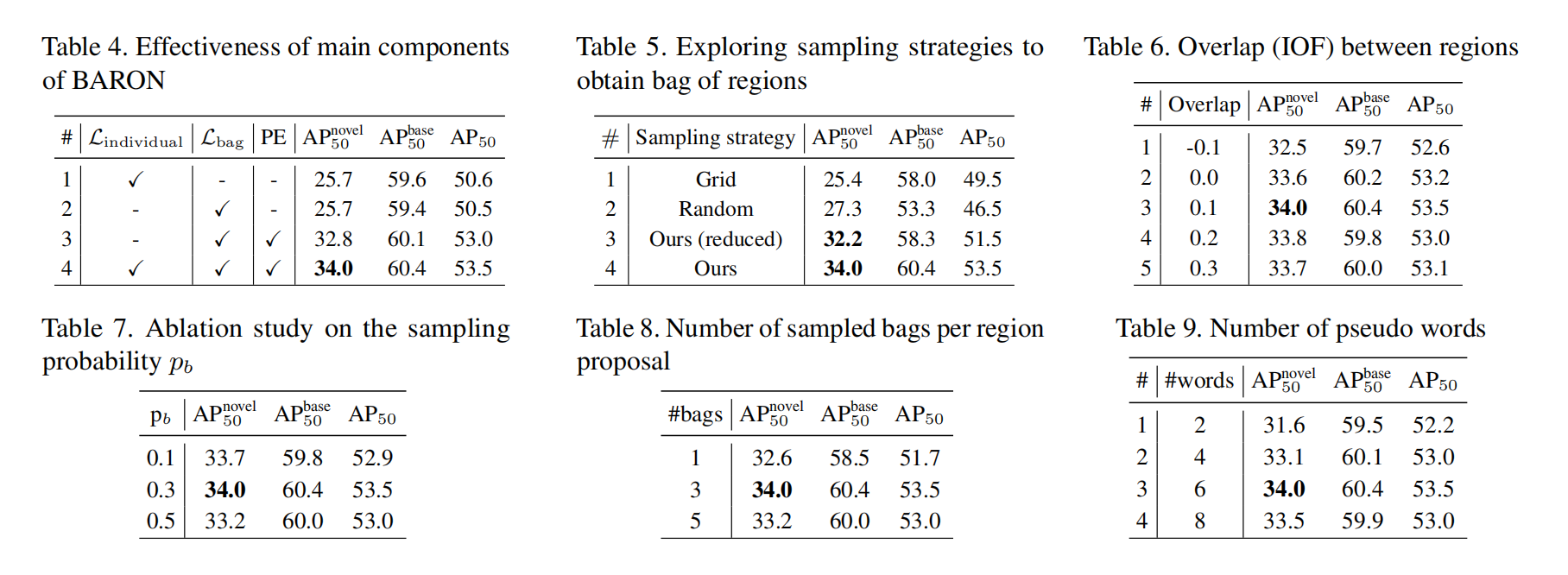
- 2.1 主要过程
- 2.2 Forming Bag of Regions
- 2.3 Representing Bag of Regions
- 2.4 Aligning bag of regions
- 三、效果
论文:Aligning Bag of Regions for Open-Vocabulary Object Detection
代码:https://github.com/wusize/ovdet
出处:CVPR2023
一、背景
传统目标检测器只能识别特定的类别,开放词汇目标检测由于不受预训练类别的限制,能够检测任意类别的目标,而受到了很多关注
针对 OVD 问题的一个典型解决方案就是基于蒸馏的方法,也就是从预训练的 vision-language 模型中蒸馏出丰富的特征来识别丰富的类别
VLM 是通过大量的 image-text pairs 来学习将两者对齐,如图 1a 所示
之前也有很多蒸馏的方法通过将每个 region embedding 和对应的从 VLM 中输出的特征进行对齐
本文作者提出【align the embedding of BAg of RegiONs】,来让模型不仅仅理解单个的目标,而是理解场景
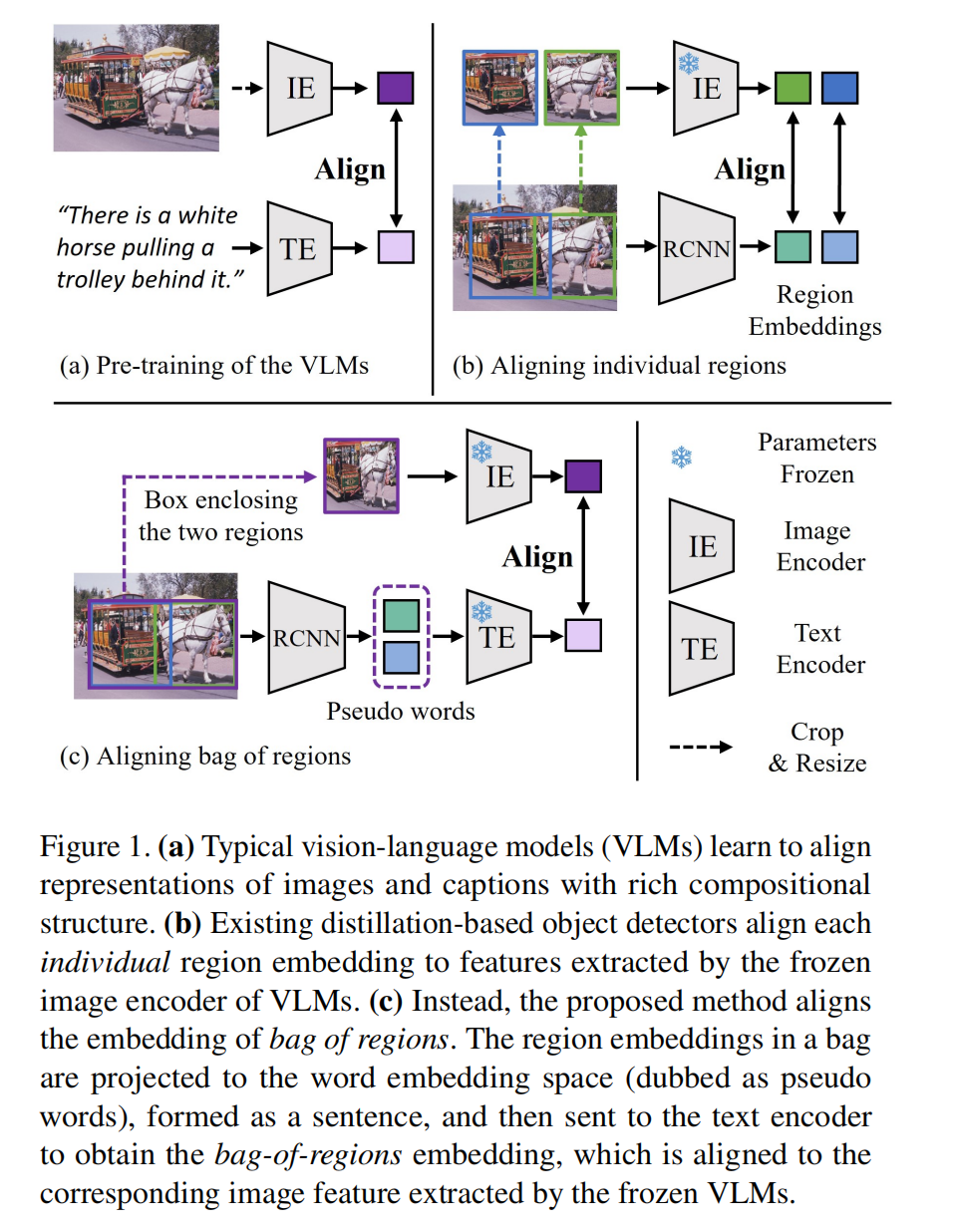
BARON 结构如图 1c 所示:
- 首先,从 bag 中抽取出和上下文相关的 region,由于 RPN 是需要能够提取出潜在的新类的,所以作者提出了 “neighborhood sampling strategy” 来抽取 region proposal 周围的框来帮助建模出共现的语义 concept
- 接着,BARON 通过将 region feature 投影到 word embedding space 得到 pseudo words,并且使用预训练好的 text encoder 来对这些 pseudo words 进行编码,得到一系列的 region embedding
- 投影到 word 空间的 pseudo words,就能够让 Text encoder 很好的抽取出共现的语义概念,并且理解整个场景
- 在送入 Text encoder 之前,为了保留 region box 的空间信息,会将 box shape 和 box center position 也投影到 embedding 中,驾到 pseudo word 上,然后再将 pseudo word 送入 Text encoder
- 训练 BARON 时,目标是将 bag-of-regions 的 embedding 和从教师 image encoder (IE)那里获得的 image crop 的 embedding 对齐,作者使用对比学习机制来学习 pseudo words 和 bag-of-regions embeddings,对比学习 loss 能够拉近成对儿的 pairs 的 student(detector)和 teacher(IE)embedding ,推远不成对儿的 pairs
二、方法
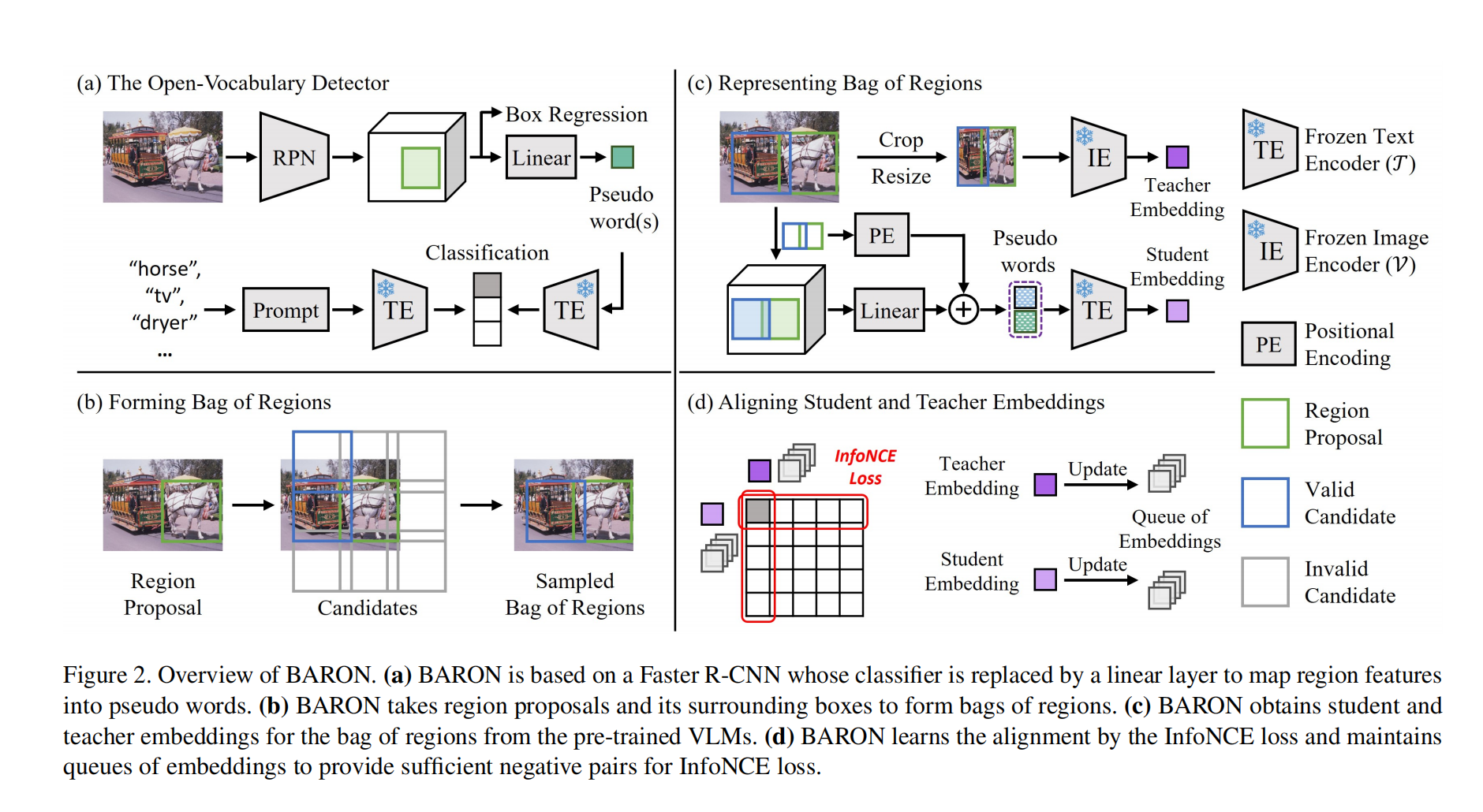
本文方法首次提出了对齐 bag of regions 的 embedding,之前的方法都是对齐单个 region 的 embedding
2.1 主要过程
本文方法主要基于 Faster R-CNN,为了让 Faster RNN 能够检测出任意词汇概念的目标,作者使用了一个线下映射层将原本的分类器代替了
线性映射层能够将 region features 映射到 word embedding space(即 pseudo words,如图 2a),这些 pseudo words 包含了每个目标更丰富的语义信息,类似于每个类别的名字包含了更多的单词(如 horse-driven trolley)
之后,将这些 pseudo words 输入 text encoder,计算和每个类别编码的相似性,然后得到类别结果
如图 2a 所示,给定 C 个目标类别,通过将类别名称转变为 prompt 模版 ‘a photo of {} in the scene’,并输入到 text encoder T 中来获得 embedding f c f_c fc
假设有 region 和其对应的 pseudo words w w w,该 region 是类别 c 的概率如下, < , > <,> <,> 表示 cosine 相似度, τ \tau τ 是温度系数
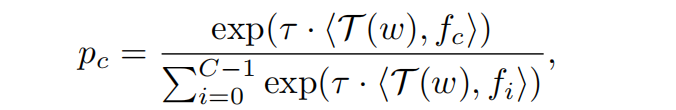
训练期间,只标注了基础类别,且也是使用基础类别来训练 Faster R-CNN 的回归和分类 loss 的
为了学习检测新类别(且没有 box 标注信息),之前的蒸馏方法都是只对齐单个的 region embedding 和其对应的从 VLMs 得到的特征
本文的方法为了捕捉更多的信息,将单个的 region 扩展到了 bag of regions
2.2 Forming Bag of Regions
本文中,也和其他方法一样使用 VLM 中的 image encoder 作者 teacher,来指导检测器的学习
不同的是,作者希望检测器能学习多个 concepts 的共现管辖,尤其是新目标的潜在出现的概率
为了效果和效率共存,作者将有如下两个属性的 regions 归到一个 bag 中去:
- 不同的 region 需要彼此距离接近
- 不同的 region 大小要相同
基于上面两个条件,作者使用 simple neighborhood sampling strategy,基于 RPN 预测得到的 region proposal,来构建 bag of regions
对每个 region proposal,作者都选取了其周围的 8 个相邻的 box 来作为候选,如图 2b 所示,此外,作者也会允许这些候选框之间有重叠,即 specific Intersection over Foreground (IOF) 来提高区域表达的连续性
为了平衡 bag 中 region 的 size,作者让着 8 个候选框的形状完全相同,且和该 region proposal 的大小也相同
2.3 Representing Bag of Regions
收集到 bag of regions 后, BARON 会从 student 和 teacher 中分别得到 bag-of-regions embeddings
假设第 i 个 groups 的第 j 个 region 为 b j i b_j^i bji,且 pseudo words 为 w j i w_j^i wji,用 T 表示预训练 VLM 的 文本编码器,V 表示图像编码器
1、student bag-of-regions embedding
由于region features 被投影到 word embedding space 且要和 text embedding 对齐,一个很直接的方法就是将这一系列的 pseudo words 进行 concat,然后输入 text encoder T 中,但是这样的话 region 的空间信息就会丢失,所以,作者将 bag 中的 regions 的中心位置、形状 都被编码了
位置编码会被夹到 pseudo word 上,然后再 concat
最终表达如下:
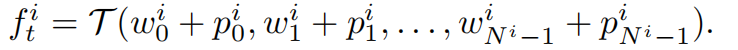
2、Teacher bag-of-regions embedding
使用 image encoder V 可以得到教师网络的编码,image feature 如下:
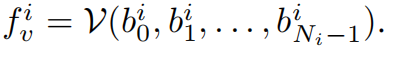
2.4 Aligning bag of regions
BARON 会将 teacher 的预测和 student 的学习结果进行对齐
给定 G 个 bag-of-regions,alignment InfoNCE loss 如下:
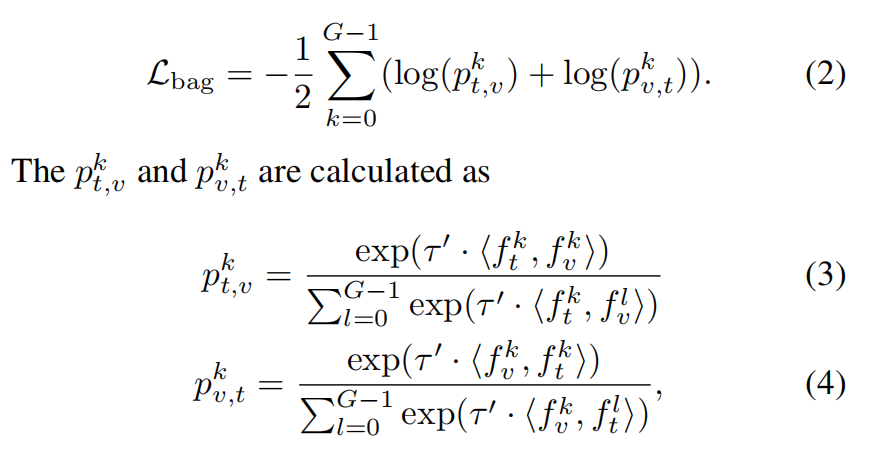
对齐单个 region:
单个 region 的 student 和 teacher embedding 的对齐对整个 bag-of-regions 的对齐很重要
所以,作者使用 individual-level distillation:
- teacher embedding:从 image encoder 的最后一个 attention 层使用 RoIAlign 获得
- 从 text encoder 的最后一个 attention layer 获得,对同一个 region 的所有 pseudo-word embedding 进行平均
- loss:使用 InfoNCE loss
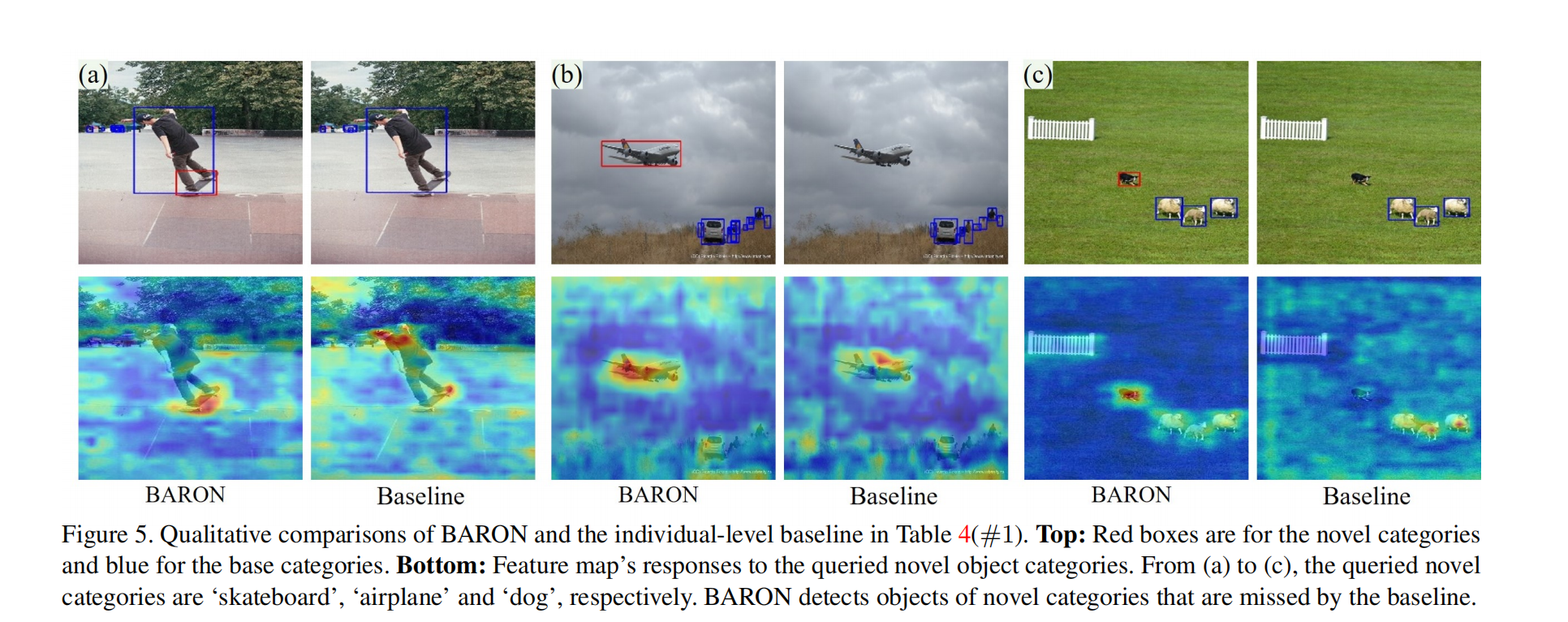
三、效果
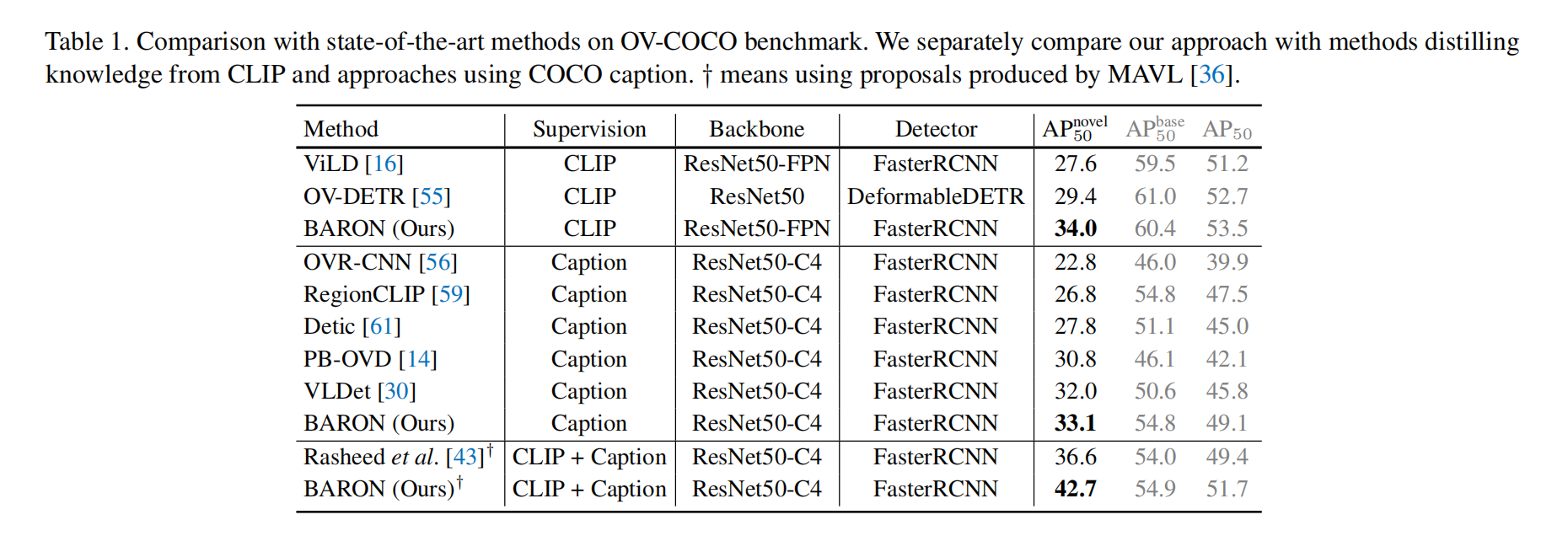
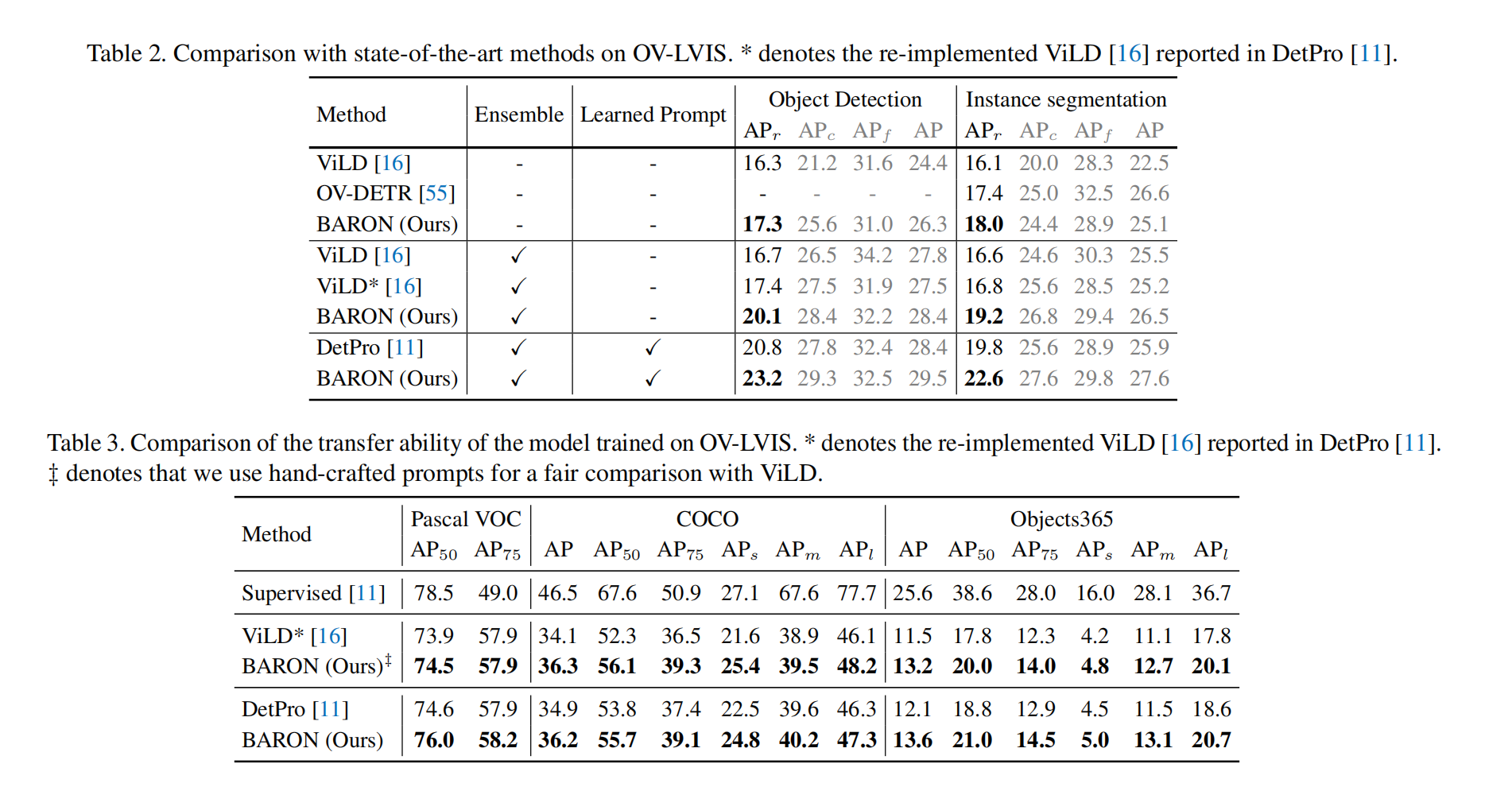





相关文章:
【多模态】21、BARON | 通过引入大量 regions 来提升模型开放词汇目标检测能力
文章目录 一、背景二、方法2.1 主要过程2.2 Forming Bag of Regions2.3 Representing Bag of Regions2.4 Aligning bag of regions 三、效果 论文:Aligning Bag of Regions for Open-Vocabulary Object Detection 代码:https://github.com/wusize/ovdet…...

2023“Java 基础 - 中级 - 高级”面试集结,已奉上我的膝盖
Java 基础(对象线程字符接口变量异常方法) 面向对象和面向过程的区别? Java 语言有哪些特点? 关于 JVM JDK 和 JRE 最详细通俗的解答 Oracle JDK 和 OpenJDK 的对比 Java 和 C的区别? 什么是 Java 程序的主类&…...
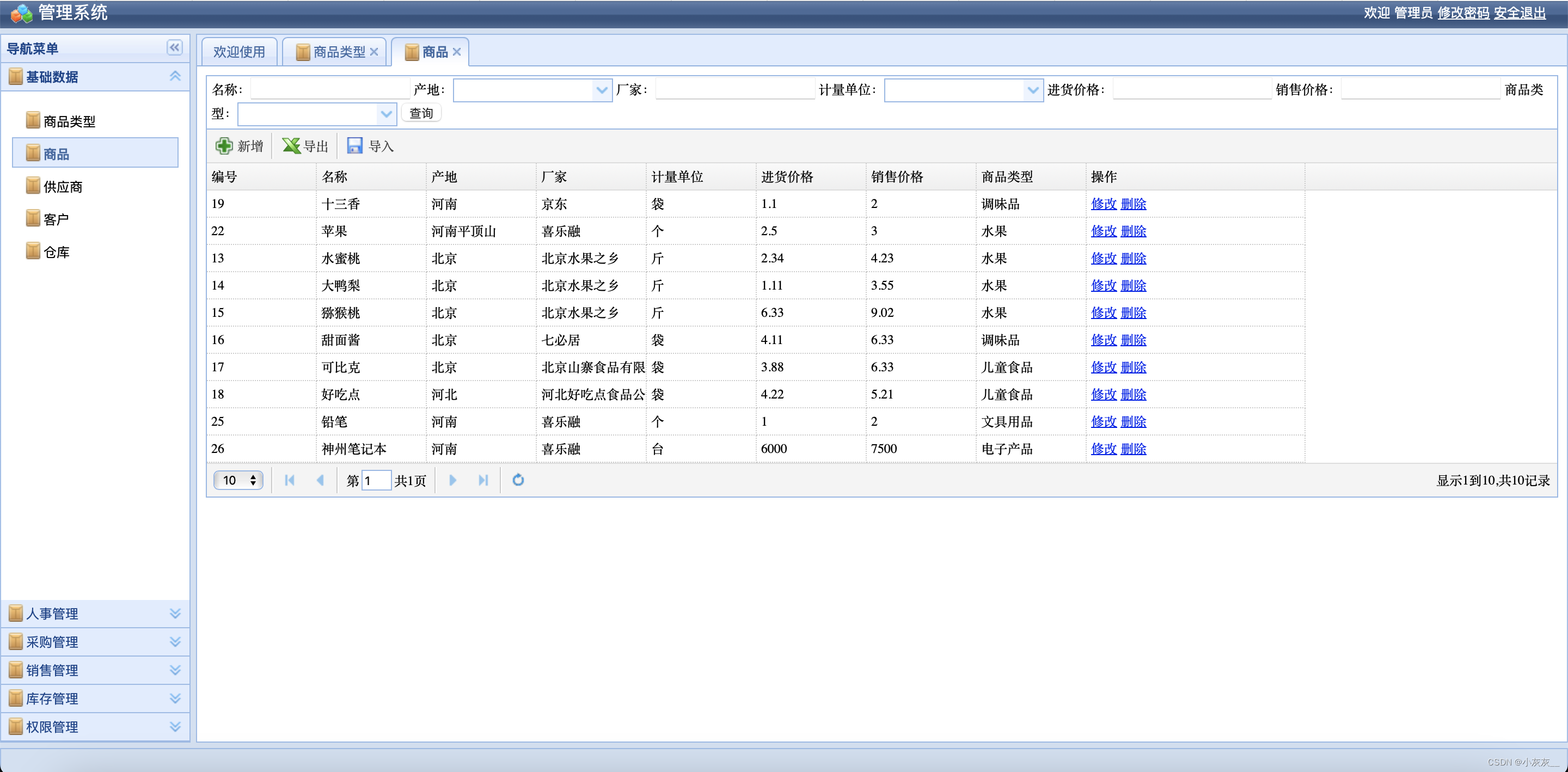
开源项目-erp企业资源管理系统(毕设)
哈喽,大家好,今天给大家带来一个开源项目-erp企业资源管理系统,项目通过ssh+oracle技术实现。 系统主要有基础数据,人事管理,采购管理,销售管理,库存管理,权限管理模块 登录 主页 基础数据 基础数据有商品类型,商品,供应商,客户,仓库管理功能...
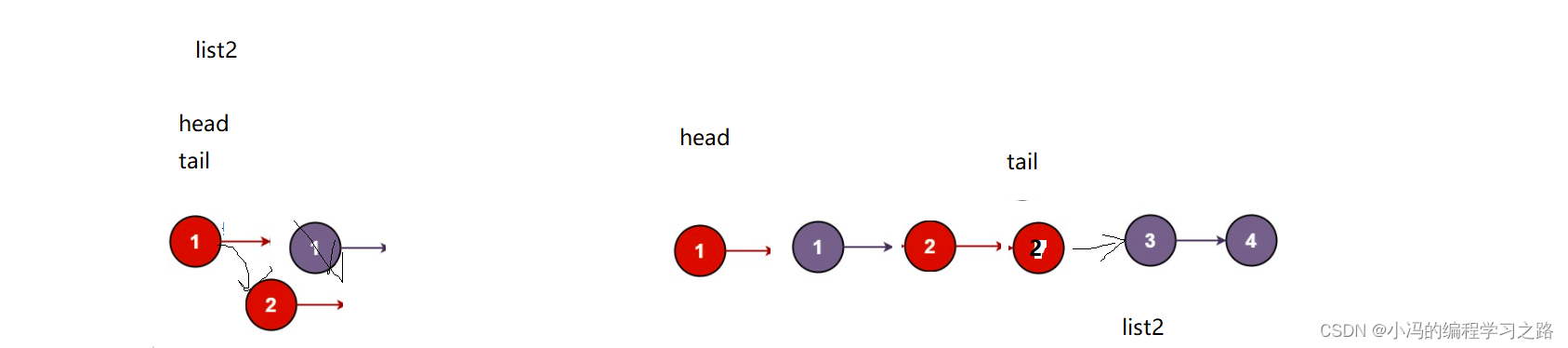
Leetcode刷题---C语言实现初阶数据结构---单链表
1 删除链表中等于给定值 val 的所有节点 删除链表中等于给定值 val 的所有节点 给你一个链表的头节点head和一个整数val,请你删除链表中所有满足Node.valval的节点,并返回新的头节点 输入:head [1,2,6,3,4,5,6], val 6 输出:[…...

opencv hand openpose
使用opencv c 来调用caffemodel 使用opencv 得dnn 模块调用 caffemodel得程序,图片自己输入就行,不做过多得解释,看代码清单。 定义手指关节点 const int POSE_PAIRS[20][2] { {0,1}, {1,2}, {2,3}, {3,4}, // thumb {0,5}, {5,6}, {6,7}…...

flutter fl_chart 柱状图 柱条数量较多 实现左右滑动 固定y轴
一、引入插件 pub.dev:fl_chart package - All Versions 根据项目版本,安装可适配的 fl_chart 版本 二、官网柱状图示例 github参数配置:(x轴、y轴、边框、柱条数据、tooltip等) https://github.com/imaNNeo/fl_c…...

CAN学习笔记1:计算机网络
计算机网络 1 概述 计算机网络就是把多种形式的计算机用通信线路连接起来,并使其能够互相进行交换的系统。实际上,计算机网络包括了计算机、各种硬件、各种软件、组成网络的体系结构、网络传输介质和网络通信计数。因此,计算机网络是计算机…...

NAND flash的坏块
NAND flash的坏块 1.为什么会出现坏块 由于NAND Flash的工艺不能保证NAND的Memory Array(由NAND cell组成的阵列)在其生命周期中保持性能的可靠(电荷可能由于其他异常原因没有被锁起来。因此,在NAND的生产中及使用过程中会产生坏…...

代码随想录算法训练营第二十五天 | 读PDF复习环节3
读PDF复习环节3 本博客的内容只是做一个大概的记录,整个PDF看下来,内容上是不如代码随想录网站上的文章全面的,并且PDF中有些地方的描述,是很让我疑惑的,在困扰我很久后,无意间发现,其网站上的讲…...
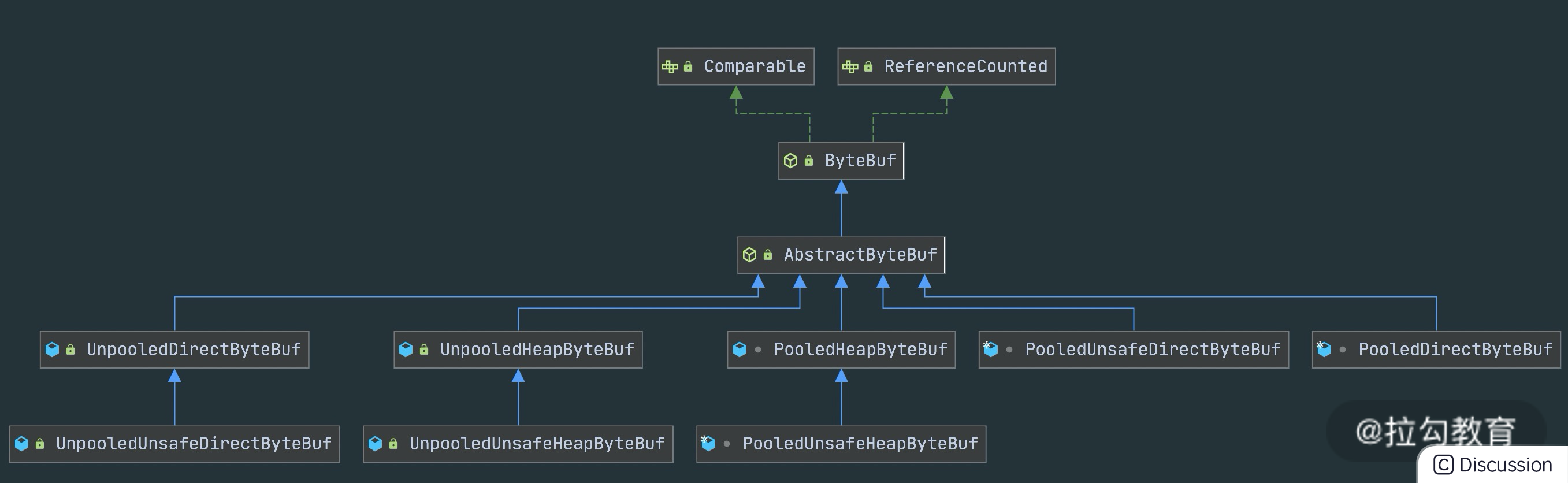
18.Netty源码之ByteBuf 详解
highlight: arduino-light ByteBuf 是 Netty 的数据容器,所有网络通信中字节流的传输都是通过 ByteBuf 完成的。 然而 JDK NIO 包中已经提供了类似的 ByteBuffer 类,为什么 Netty 还要去重复造轮子呢?本节课我会详细地讲解 ByteBuf。 JDK NIO…...
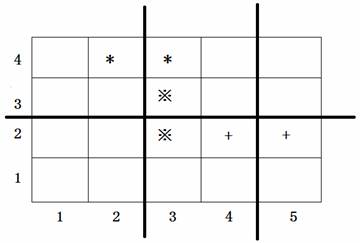
#P0999. [NOIP2008普及组] 排座椅
题目描述 上课的时候总会有一些同学和前后左右的人交头接耳,这是令小学班主任十分头疼的一件事情。不过,班主任小雪发现了一些有趣的现象,当同学们的座次确定下来之后,只有有限的 DD 对同学上课时会交头接耳。 同学们在教室中坐…...

Sentinel 容灾中心的使用
Sentinel 容灾中心的使用 往期文章 Nacos环境搭建Nacos注册中心的使用Nacos配置中心的使用 熔断/限流结果 Jar 生产者 spring-cloud-alibaba:2021.0.4.0 spring-boot:2.6.8 spring-cloud-loadbalancer:3.1.3 sentinel:2021.0…...

深度学习中简易FC和CNN搭建
TensorFlow是由谷歌开发的PyTorch是由Facebook人工智能研究院(Facebook AI Research)开发的 Torch和cuda版本的对应,手动安装较好 全连接FC(Batch*Num) 搭建建议网络: from torch import nnclass Mnist_NN(nn.Module):def __i…...

【多模态】20、OVR-CNN | 使用 caption 来实现开放词汇目标检测
文章目录 一、背景二、方法2.1 学习 视觉-语义 空间2.2 学习开放词汇目标检测 三、效果 论文:Open-Vocabulary Object Detection Using Captions 代码:https://github.com/alirezazareian/ovr-cnn 出处:CVPR2021 Oral 一、背景 目标检测数…...
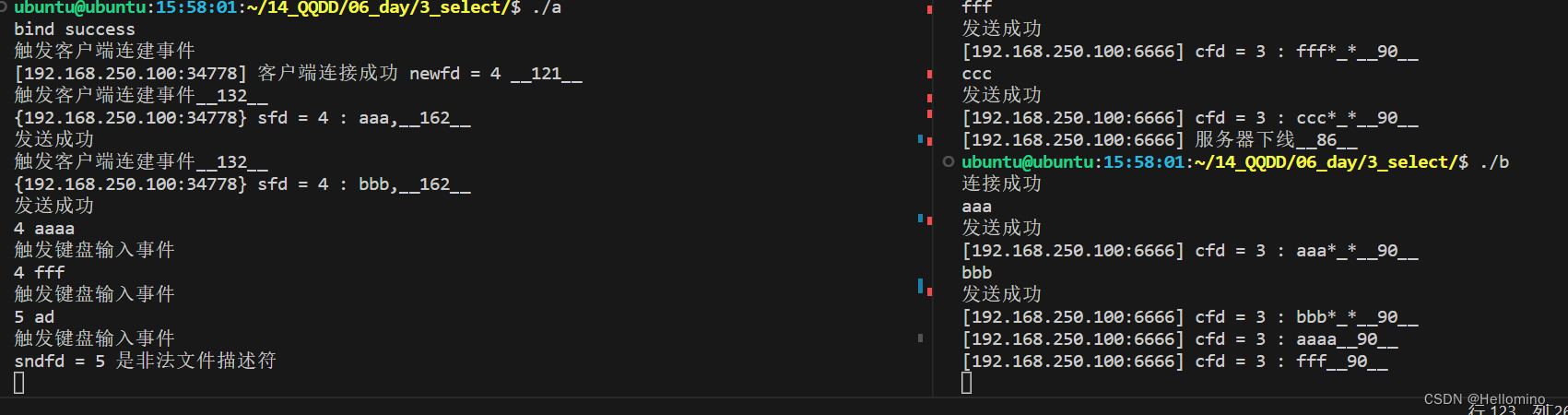
网络编程 IO多路复用 [select版] (TCP网络聊天室)
//head.h 头文件 //TcpGrpSer.c 服务器端 //TcpGrpUsr.c 客户端 select函数 功能:阻塞函数,让内核去监测集合中的文件描述符是否准备就绪,若准备就绪则解除阻塞。 原型: #include <sys/select.…...

数学建模学习(7):单目标和多目标规划
优化问题描述 优化 优化算法是指在满足一定条件下,在众多方案中或者参数中最优方案,或者参数值,以使得某个或者多个功能指标达到最优,或使得系统的某些性能指标达到最大值或者最小值 线性规划 线性规划是指目标函数和约束都是线性的情况 [x,fval]linprog(f,A,b,Aeq,Beq,LB,U…...

Element UI如何自定义样式
简介 Element UI是一套非常完善的前端组件库,但是如何个性化定制其中的组件样式呢?今天我们就来聊一聊这个 举例 就拿最常见的按钮el-button来举例,一般来说默认是蓝底白字。效果图如下 可是我们想个性化定制,让他成为粉底红字应…...

protobuf入门实践2
如何在proto中定义一个rpc服务? syntax "proto3"; //声明protobuf的版本package fixbug; //声明了代码所在的包 (对于C来说就是namespace)//下面的选项,表示生成service服务类和rpc方法描述, 默认是不生成的 option cc_generi…...

adb shell使用总结
文章目录 日志记录系统概览adb 使用方式 adb命令日志过滤按照告警等级进行过滤按照tag进行过滤根据告警等级和tag进行联合过滤屏蔽系统和其他App干扰,仅仅关注App自身日志 查看“当前页面”Activity文件传输截屏和录屏安装、卸载App启动activity其他 日志记录系统概…...
-Tag的含义、Tag类型与其他的转换)
UG NX二次开发(C++)-Tag的含义、Tag类型与其他的转换
文章目录 1、前言2、Tag号的含义3、tag_t转换为int3、TaggedObject与Tag转换3.1 TaggedObject定义3.2 TaggedObject获取Tag3.3 根据Tag获取TaggedObject4.Tag与double类型的转换1、前言 在UG NX中,每个对象对应一个tag号,C++中,其类型是tag_t,一般是5位或者6位的int数字,…...

瑞数6代JSVMP对抗实战:Node.js环境补全与412绕过
1. 这不是“绕过验证码”,而是一场Web前端对抗的深度解剖瑞数6代,业内常被称作“JSVMP黑盒”的典型代表——它不靠传统混淆堆砌代码体积,也不依赖简单的时间戳或行为采集做判断,而是把整个校验逻辑编译进一套自定义的、高度定制化…...

微信抓包全链路实战:Proxifier+Fiddler+Burp协同排障指南
1. 为什么微信抓包成了“玄学”,而你总在重装系统? 微信抓包这件事,我干了七年,从2017年用Charles配iOS证书开始,到今天手头常备三套环境:Mac上跑Fiddler EverywhereProxifier组合应对企业微信定制版&…...

忆往游戏平台官网:正版怀旧手游官方下载与资讯中心
忆往游戏平台(又称 “忆往怀旧手游”)是安徽游昕网络科技有限公司官方认证的正版怀旧手游聚合平台,专注经典端游 IP 正版复刻与发行,主打 “零魔改、纯复古、散人友好”,为 80、90 后玩家提供安全、纯净、高还原的怀旧…...
)
AI Agent重构餐饮服务链:从排队超15分钟到响应<1.2秒的9大技术跃迁(行业首份效能白皮书)
更多请点击: https://kaifayun.com 第一章:AI Agent重构餐饮服务链:从排队超15分钟到响应<1.2秒的9大技术跃迁(行业首份效能白皮书) 传统餐饮服务链中,用户进店、点餐、支付、出餐、反馈等环节高度依赖…...

Linux服务器TCP连接数远超65535:从协议原理到高并发调优
1. 项目概述:一个流传甚广的“常识”误区“Linux服务器的TCP连接数上限是65535。” 这句话,我相信很多运维工程师、后端开发,甚至是一些面试官都曾说过或听过。它像一条技术领域的“都市传说”,在无数技术讨论、博客文章甚至面试题…...

3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命
3大远程管理痛点解决方案:MobaXterm中文版实现一站式终端效率革命 【免费下载链接】Mobaxterm-Chinese Mobaxterm simplified Chinese version. Mobaxterm 的简体中文版. 项目地址: https://gitcode.com/gh_mirrors/mo/Mobaxterm-Chinese 远程服务器管理面临…...

麻雀AI助手Akagi:免费实时分析工具,5分钟提升雀魂游戏水平 [特殊字符]️
麻雀AI助手Akagi:免费实时分析工具,5分钟提升雀魂游戏水平 🀄️ 【免费下载链接】Akagi 支持雀魂、天鳳、麻雀一番街、天月麻將,能夠使用自定義的AI模型實時分析對局並給出建議,內建Mortal AI作為示例。 Supports Majs…...

为什么感觉苹果11的手机放歌音效比华为mate80好,大家觉得呢?什么原因?配置有何差别?——有没有音效好的手机推荐?——有带hifi效果的吗?
公开信息中没有直接对比两款机型音效的权威测试,结合硬件和系统规律来看,这种听感差异主要是调校风格不同导致的,并非绝对的音质好坏。 核心原因分析 系统与音频链路调校差异 苹果iOS是封闭式系统,对音频链路的优化更统一,没有第三方厂商的碎片化干扰,驱动调校成熟…...

企业级SECS/GEM协议实现:secsgem库的深度解析与实战指南
企业级SECS/GEM协议实现:secsgem库的深度解析与实战指南 【免费下载链接】secsgem Simple Python SECS/GEM implementation 项目地址: https://gitcode.com/gh_mirrors/se/secsgem 在半导体制造和工业自动化领域,设备通信的标准化和可靠性至关重要…...

Excel MCP Server:革命性的无Excel数据处理引擎
Excel MCP Server:革命性的无Excel数据处理引擎 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 在数据处理领域,传统Excel依赖…...