【性能优化】MySQL百万数据深度分页优化思路分析
业务场景
一般在项目开发中会有很多的统计数据需要进行上报分析,一般在分析过后会在后台展示出来给运营和产品进行分页查看,最常见的一种就是根据日期进行筛选。这种统计数据随着时间的推移数据量会慢慢的变大,达到百万、千万条数据只是时间问题。
一、数据准备(生成百万数据)
sql:将your_table_name 改成自己的表名,目前我的表中有id,name,password、create_time四个字段(这个是生成一百万数据的,会有点影响性能,插入比较耗时)
INSERT INTO `your_table_name ` (name, password, create_time, age)
SELECT SUBSTRING(MD5(RAND()), 1, 10),SUBSTRING(MD5(RAND()), 1, 10),NOW() - INTERVAL FLOOR(RAND() * 31536000) SECOND,FLOOR(RAND() * 100) + 1
FROM(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t1,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t2,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t3,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t4,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t5,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t6,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t7,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t8,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t9,(SELECT 1 UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5 UNION SELECT 6 UNION SELECT 7 UNION SELECT 8 UNION SELECT 9 UNION SELECT 10) t10;可以选择每次插入10万条数据,多次插入效果比一次插入效果更好。

建表SQL:
CREATE TABLE `user` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) DEFAULT NULL COMMENT '名字',`password` varchar(50) DEFAULT NULL COMMENT '密码',`age` int(3) DEFAULT NULL COMMENT '年龄',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;二、场景复现
创建了一张user表,给create_time字段添加了索引。并在该表中添加了100w条数据。
CREATE TABLE `user` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) DEFAULT NULL COMMENT '名字',`password` varchar(50) DEFAULT NULL COMMENT '密码',`age` int(3) DEFAULT NULL COMMENT '年龄',`create_time` datetime DEFAULT NULL COMMENT '创建时间',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;查询前10条基本上不消耗什么时间
SELECT SQL_NO_CACHE *
FROM `user`
WHERE create_time BETWEEN '2023-01-01' AND '2023-05-23'
LIMIT 1,10;
从第100w+开始取数据的时候,查询耗时1.5秒。
SELECT SQL_NO_CACHE *
FROM `user`
WHERE create_time BETWEEN '2023-01-01' AND '2023-05-23'
LIMIT 1000000,10;
SQL_NO_CACHE
这个关键词是为了不让SQL查询走缓存。
同样的SQL语句,不同的分页条件,两者的性能差距如此之大,那么随着数据量的增长,往后页的查询所耗时间按理会越来越大。
三、问题分析
1、回表
我们一般对于查询频率比较高的字段会建立索引。索引会提高我们的查询效率。我们上面的语句使用了SELECT * FROM user,但是我们并不是所有的字段都建立了索引。当从索引文件中查询到符合条件的数据后,还需要从数据文件中查询到没有建立索引的字段。那么这个过程称之为回表。
2、覆盖索引
如果查询的字段正好创建了索引了,比如 SELECT create_time FROM user,我们查询的字段是我们创建的索引,那么这个时候就不需要再去数据文件里面查询,也就不需要回表。这种情况我们称之为覆盖索引。
3、IO
回表操作通常是IO操作,因为需要根据索引查找到数据行后,再根据数据行的主键或唯一索引去聚簇索引中查找具体的数据行。聚簇索引一般是存储在磁盘上的数据文件,因此在执行回表操作时需要从磁盘读取数据,而磁盘IO是相对较慢的操作。
4、问题衍生
当我们查询 LIMIT 2000,10 会不会扫描1-2000行,你之前有没有跟我一样,觉得数据是直接从2000行开始取的,前面的根本没扫描或者不回表。其实这样的写法,一个完整的流程是查询数据,如果不能覆盖索引,那么也是要回表查询数据的。
所以越到后面大概率是会查询越慢!
四、问题总结
我们现在知道了LIMIT 遇到后面查询的性能越差,性能差的原因是因为要回表,既然已经找到了问题那么我们只需要减少回表的次数就可以提升查询性能了。
五、解决方案
既然覆盖索引可以防止数据回表,那么我们可以先查出来主键id(主键索引),然后将查出来的数据作为临时表然后 JOIN 原表就可以了,这样只需要对查询出来的5条结果进行数据回表,大幅减少了IO操作。
六、优化前后性能对比
我们看下执行效果:
-
优化前:1.5s
SELECT SQL_NO_CACHE *
FROM `user`
WHERE create_time BETWEEN '2003-01-01' AND '2003-05-23'
LIMIT 1000000,10;
-
优化后:0.6s
SELECT SQL_NO_CACHE *
FROM `user`
WHERE create_time BETWEEN '2003-01-01' AND '2023-05-23'
LIMIT 1000000,10;SELECT SQL_NO_CACHE *
FROM (SELECT SQL_NO_CACHE id
FROM `user`
WHERE create_time BETWEEN '2003-01-01' AND '2023-05-23'
LIMIT 1000000,10) AS temp
INNER JOIN `user` AS u ON u.id = temp.id; 
查询耗时性能大幅提升。这样如果分页数据很大的话,也不会像普通的limit查询那样慢。
总结:
其实实际业务场景数据达到百万了都会选择三方工具了,比如:ES,本文只是拿分页数据做例子,探讨一下SQL的查询效率。
相关文章:
【性能优化】MySQL百万数据深度分页优化思路分析
业务场景 一般在项目开发中会有很多的统计数据需要进行上报分析,一般在分析过后会在后台展示出来给运营和产品进行分页查看,最常见的一种就是根据日期进行筛选。这种统计数据随着时间的推移数据量会慢慢的变大,达到百万、千万条数据只是时间问…...
交叉编译工具链的安装、配置、使用
一、交叉编译的概念 交叉编译是在一个平台上生成另一个平台上的可执行代码。 编译:一个平台上生成在该平台上的可执行文件。 例如:我们的Windows上面编写的C51代码,并编译成可执行的代码,如xx.hex.在C51上面运行。 我们在Ubunt…...
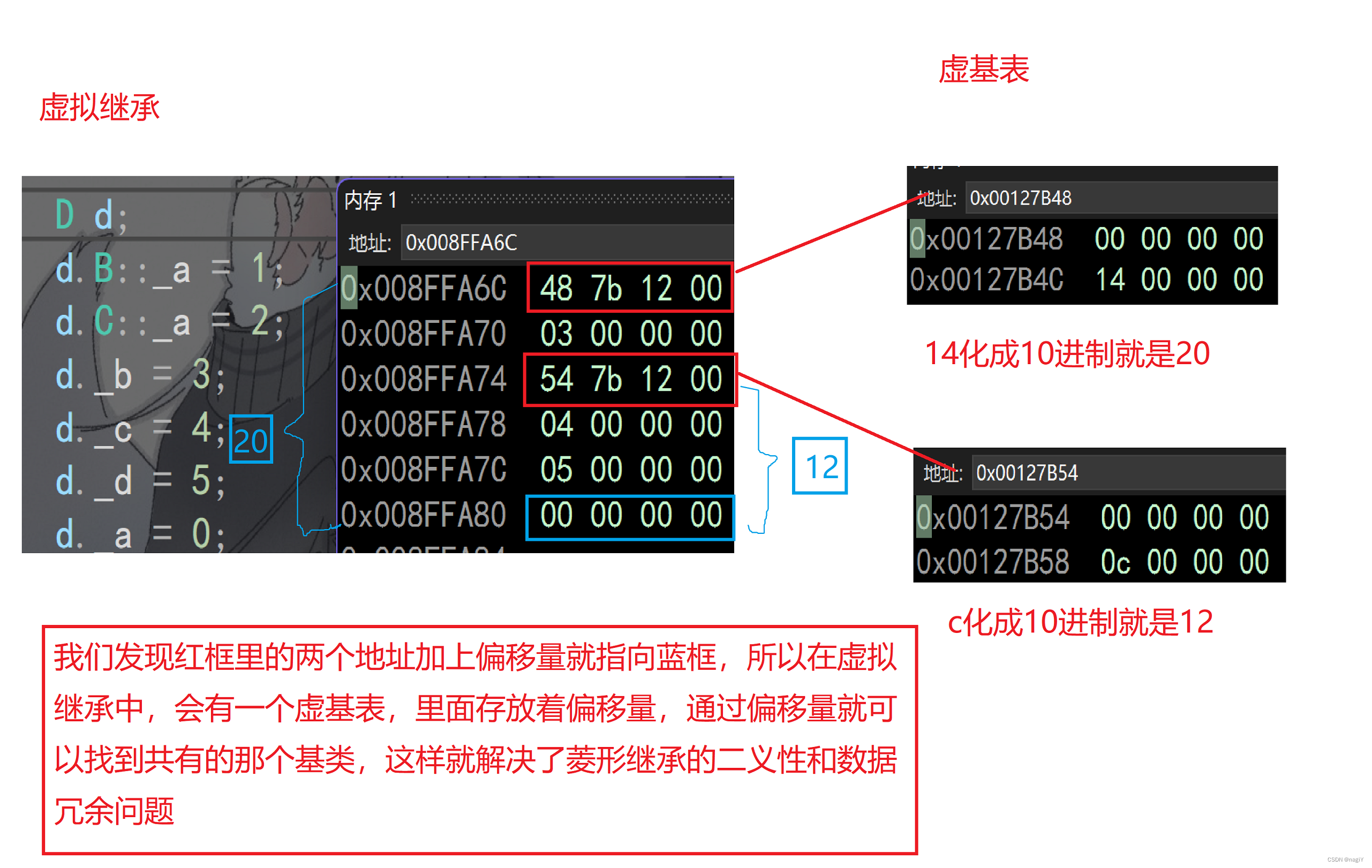
【C++ 进阶】继承
一.继承的定义格式 基类又叫父类,派生类又叫子类; 二.继承方式 继承方式分为三种: 1.public继承 2.protected继承 3.private继承 基类成员与继承方式的关系共有9种,见下表: 虽然说是有9种,但其实最常用的还…...
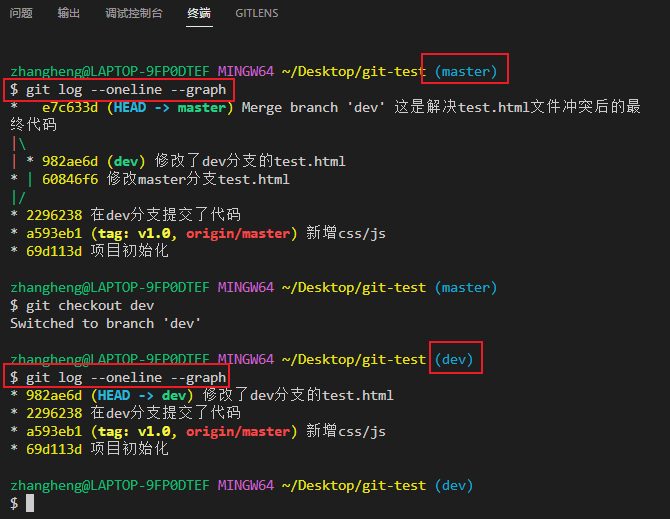
Git使用详细教程
1. cmd面板的常用命令 clear:清屏cd 文件夹名称----进入文件夹cd … 进入上一级目录(两个点)dir 查看当前目录下的文件和文件夹(全拼:directory)Is 查看当前目录下的文件和文件夹touch 文件名----创建文件echo 内容 > 创建文件名----创建文件并写入内容rm 文件名…...

小程序 表单验证
使用 WxValidate.js 插件来校验表单数据 常用实例方法 名称返回类型描述checkForm(e)boolean验证所有字段的规则,返回验证是否通过。valid()boolean返回验证是否通过。size()number返回错误信息的个数。validationErrors()array返回所有错误信息。addMethod(name…...
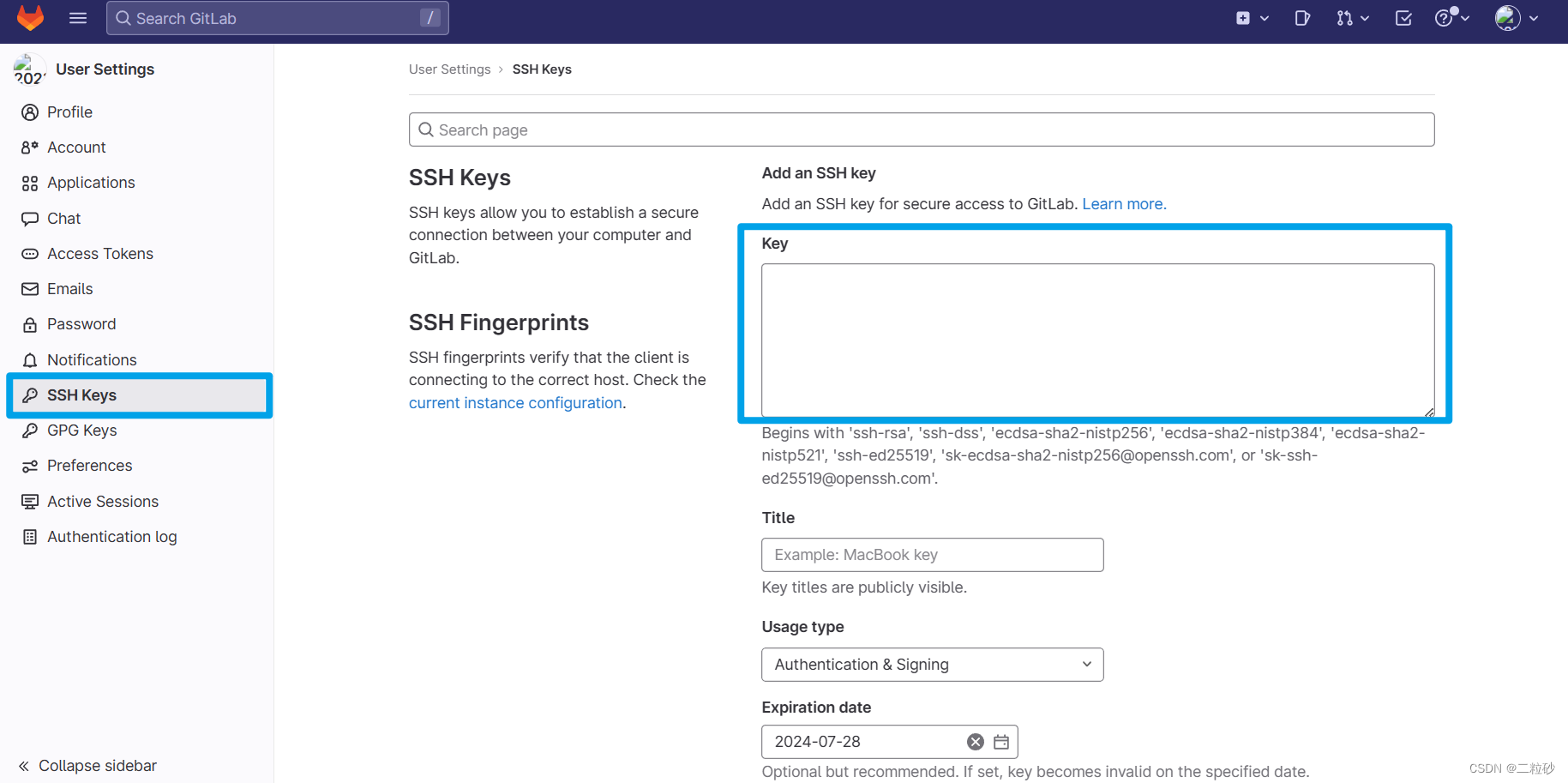
本地仓库推送至远程仓库
1. 本地生成ssh密钥对 ssh-keygen -t rsa -C 邮箱2. 添加公钥到gitlab/github/gitee上 打开C:\Users\用户名\.ssh目录下生成的密钥文件id_rsa.pub,把内容复制到如下文本框中 删除Expiration date显示的日期,公钥有效期变成永久,之后点Add K…...
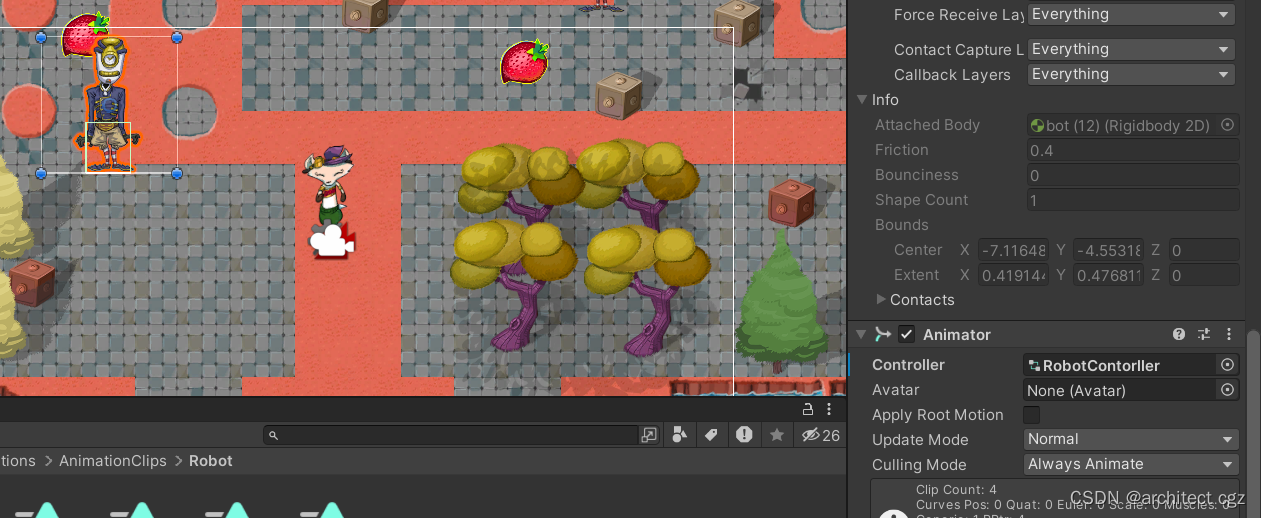
【Unity2D】角色动画的切换
动画状态转换 第一种方法是设置一个中间状态,从中间状态向其余各种状态切换,且各状态向其他状态需要设置参数 实现动作转移时右键点击Make Transition即可 实现动画转移需要设置条件 点击一种动画到另一种动画的线 ,然后点击加号添加Condi…...
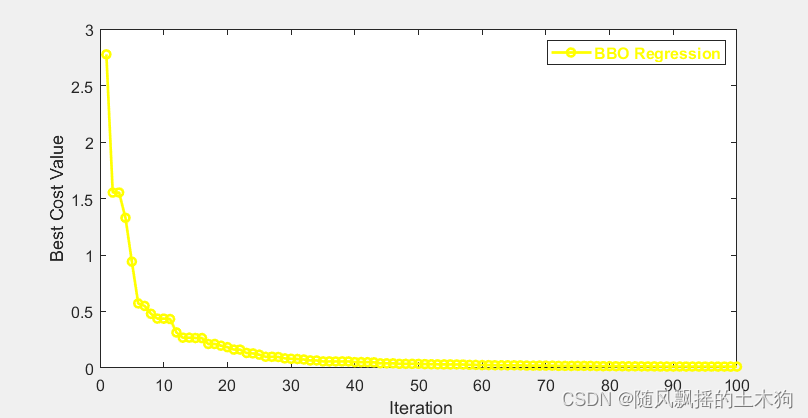
【MATLAB第62期】基于MATLAB的PSO-NN、BBO-NN、前馈神经网络NN回归预测对比
【MATLAB第62期】基于MATLAB的PSO-NN、BBO-NN、前馈神经网络NN回归预测对比 一、数据设置 1、7输入1输出 2、103行样本 3、80个训练样本,23个测试样本 二、效果展示 NN训练集数据的R2为:0.73013 NN测试集数据的R2为:0.23848 NN训练集数据的…...
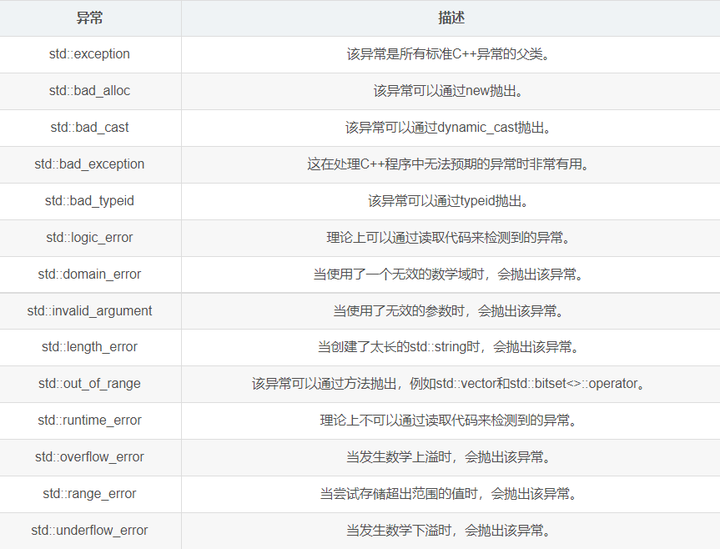
深度剖析C++ 异常机制
传统排错 我们早在 C 程序里面传统的错误处理手段有: 终止程序,如 assert;缺陷是用户难以接受,说白了就是一种及其粗暴的手法,比如发生内存错误,除0错误时就会终止程序。 返回错误码。缺陷是需要我们自己…...
)
adb no permissions (user *** is not in the plugdev group)
首次配置ubuntu下的adb 环境,执行了adb device命令会出现以下问题 lvilvi-PC:~/develop/android/sdk/platform-tools$ adb devices List of devices attached 123699aac6536d65 no permissions (user lvi is not in the plugdev group); see [http://develo…...
【外卖系统】分类管理业务
公共字段自动填充 需求分析 对于之前的开发中,有创建时间、创建人、修改时间、修改人等字段,在其他功能中也会有出现,属于公共字段,对于这些公共字段最好是在某个地方统一处理以简化开发,使用Mybatis Plus提供的公共…...
])
es报错[FORBIDDEN/12/index read-only / allow delete (api)]
报错 [FORBIDDEN/12/index read-only / allow delete (api)] es磁盘满了 postman请求 put 请求 http://loclahost:9200/_settings {"settings": {"index": {"blocks": {"read_only_allow_delete": "false"}}} }...
)
关于网络通信安全协议的一些知识(ssl,tls,CA,https)
首先了解一下http协议的变迁。 http1.0默认短连接,1.1默认长连接并且可以管道传输,但是存在队头阻塞问题; https就是在tcp和http之间加了SSL/TLS层。 http2也是安全的,改进是hpack二进制和编码压缩减小体积,stream没有…...

Generative Diffusion Prior for Unified Image Restoration and Enhancement 论文阅读笔记
这是CVPR2023的一篇用diffusion先验做图像修复和图像增强的论文 之前有一篇工作做了diffusion先验(Bahjat Kawar, Michael Elad, Stefano Ermon, and Jiaming Song, “Denoising diffusion restoration models,” arXiv preprint arXiv:2201.11793, 2022. 2, 4, 6,…...
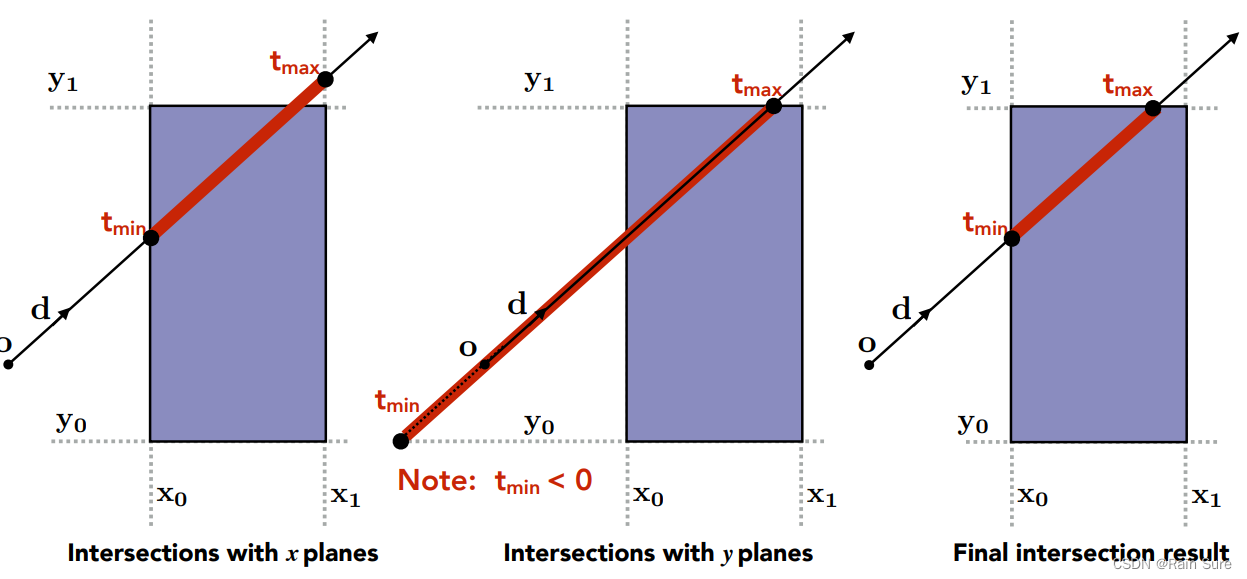
GAMES101 笔记 Lecture13 光线追踪1
目录 Why Ray Tracing?(为什么需要光线追踪?)Basic Ray Tracing Algorithm(基础的光线追踪算法)Ray Casting(光线的投射)Generating Eye Rays(生成Eye Rays) Recursive(Whitted-Styled) Ray Tracing Ray-Surface Intersection(光线和平面的交点)Ray Rquation(射线方…...

【多模态】21、BARON | 通过引入大量 regions 来提升模型开放词汇目标检测能力
文章目录 一、背景二、方法2.1 主要过程2.2 Forming Bag of Regions2.3 Representing Bag of Regions2.4 Aligning bag of regions 三、效果 论文:Aligning Bag of Regions for Open-Vocabulary Object Detection 代码:https://github.com/wusize/ovdet…...

2023“Java 基础 - 中级 - 高级”面试集结,已奉上我的膝盖
Java 基础(对象线程字符接口变量异常方法) 面向对象和面向过程的区别? Java 语言有哪些特点? 关于 JVM JDK 和 JRE 最详细通俗的解答 Oracle JDK 和 OpenJDK 的对比 Java 和 C的区别? 什么是 Java 程序的主类&…...
开源项目-erp企业资源管理系统(毕设)
哈喽,大家好,今天给大家带来一个开源项目-erp企业资源管理系统,项目通过ssh+oracle技术实现。 系统主要有基础数据,人事管理,采购管理,销售管理,库存管理,权限管理模块 登录 主页 基础数据 基础数据有商品类型,商品,供应商,客户,仓库管理功能...
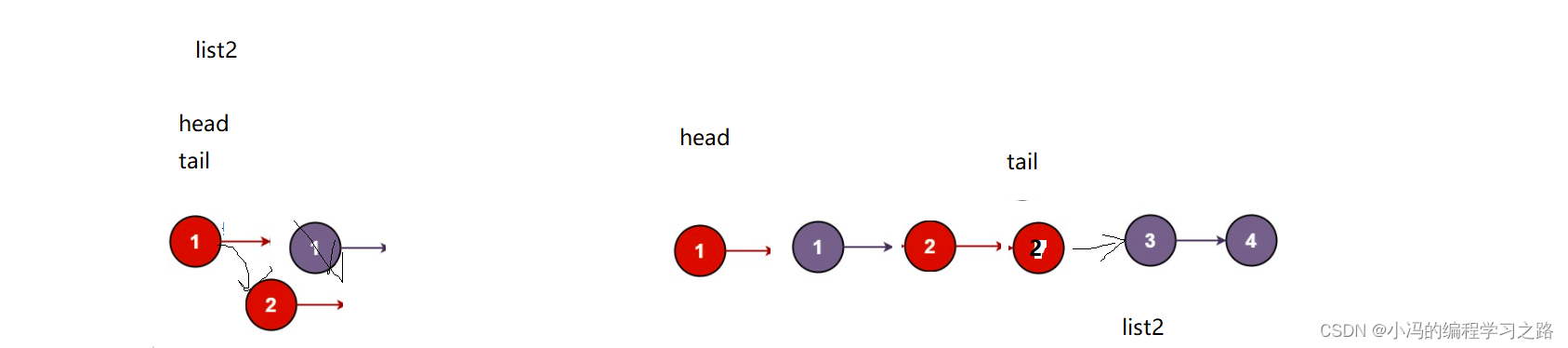
Leetcode刷题---C语言实现初阶数据结构---单链表
1 删除链表中等于给定值 val 的所有节点 删除链表中等于给定值 val 的所有节点 给你一个链表的头节点head和一个整数val,请你删除链表中所有满足Node.valval的节点,并返回新的头节点 输入:head [1,2,6,3,4,5,6], val 6 输出:[…...

opencv hand openpose
使用opencv c 来调用caffemodel 使用opencv 得dnn 模块调用 caffemodel得程序,图片自己输入就行,不做过多得解释,看代码清单。 定义手指关节点 const int POSE_PAIRS[20][2] { {0,1}, {1,2}, {2,3}, {3,4}, // thumb {0,5}, {5,6}, {6,7}…...

工业级房价预测实战:从数据清洗到可解释模型部署
1. 这不是“调个模型就完事”的房价预测——而是一次完整的工业级回归建模实战复盘你打开Kaggle,下载一个带“house price”字样的CSV文件,pandas读进来,train_test_split切两刀,RandomForestRegressor.fit()跑完,R显示…...

科研节奏管理法:4篇论文驱动的工程化落地实践
1. 项目概述:这不是一份文献综述,而是一份“科研呼吸节奏”训练手册“Month in 4 Papers (December 2024)”——这个标题乍看像一份学术月报,但如果你真把它当成四篇论文的摘要合集,就完全错过了它最核心的价值。我做了十年科研内…...

痛苦本身没有价值,从痛苦中提炼出的原则才有价值
如何打破"好了伤疤忘了疼"的人性循环 目录 如何打破"好了伤疤忘了疼"的人性循环 为什么我们天生就"好了伤疤忘了疼" 真正有效的解决方法:把"感性记忆"转化为"理性制度" 第一级:痛苦发生时——立刻"固化"教训,…...
)
【限时公开】我们压测了23个开源AI Agent框架,仅2个支持亚秒级SQL生成+自动schema纠错(测试报告PDF已备)
更多请点击: https://codechina.net 第一章:AI Agent数据分析应用 AI Agent 正在重塑数据分析的范式——它不再依赖人工编写 SQL 或手动配置 ETL 流程,而是通过自然语言理解任务意图、自主调用工具、迭代验证结果,并生成可解释的…...

FFXIV国际服中文汉化工具:5步实现终极中文游戏体验
FFXIV国际服中文汉化工具:5步实现终极中文游戏体验 【免费下载链接】FFXIVChnTextPatch 项目地址: https://gitcode.com/gh_mirrors/ff/FFXIVChnTextPatch 还在为《最终幻想14》国际服的英文界面而烦恼吗?想要体验国际服的最新内容,却…...

从代购源码到生产环境:反向海淘系统部署与运维实战指南
代码写完之后,真正的考验才刚刚开始。 这是做代购网站开发时经常会遇到的另一个问题——开发的时候感觉一切顺利,一上线就各种出状况。数据库连接数不够、海外用户访问慢、订单高峰期系统卡死……这些问题我在之前的反向海淘项目里都经历过。 这些问题的…...

2026年一键生成论文工具实测报告:5款神器从文献到降重一站式避坑指南
写论文的煎熬,是每个科研人和学生都无法回避的“必修课”。选题无从下手,文献检索耗时费力,格式排版让人抓狂,查重降重更是反复折腾。2026年的今天,AI工具早已不再只是“文字助手”,而是进化成了能全程陪伴…...

HermesAgent工具如何快速对接Taotoken的多模型服务提供商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 HermesAgent工具如何快速对接Taotoken的多模型服务提供商 基础教程类,本文将指导使用HermesAgent工具的开发者…...

DMXAPI:国产多模态大模型API聚合平台,让开发者一键调用通义千问等主流模型
在国产大模型百花齐放的今天,如何高效、稳定地接入各类模型能力,成为开发者和企业面临的核心痛点。DMXAPI 应运而生,作为中国多模态大模型API聚合平台,致力于打造"国产模型一站式调用中心",让开发者无需对接…...

抖音小店搜索排名规则及优化方法
一、抖音商城搜索排名规则1.商品相关性:商品标题、关键词与用户搜索词的匹配程度是重要因素。精准匹配的商品会在搜索结果中更靠前展示。例如,用户搜索"夏季连衣裙”,标题中明确包含该关键词且商品属性也相符的连衣裙,会优先被展示。商品…...