Python 进阶(三):正则表达式(re 模块)

❤️ 博客主页:水滴技术
🌸 订阅专栏:Python 入门核心技术
🚀 支持水滴:点赞👍 + 收藏⭐ + 留言💬
文章目录
- 1. 导入re模块
- 2. re模块中的常用函数
- 2.1 re.search()
- 2.2 re.findall()
- 2.3 re.sub()
- 2.4 re.compile()
- 2.5 re.split()
- 3. 正则表达式的语法
- 4. 匹配对象的属性和方法
- 4.1 group()
- 4.2 start()
- 4.3 end()
- 4.4 span()
- 5. 常用示例
- 5.1 匹配数字
- 5.2 匹配邮箱
- 5.3 匹配URL
- 5.4 匹配日期
- 5.5 匹配IP地址
- 5.6 匹配HTML标签
- 5.7 匹配手机号码
- 5.8 匹配身份证号码
- 5.9 匹配QQ号码
- 5.10 匹配微信号
- 5.11 匹配邮政编码
- 5.12 匹配中文字符
- 5.13 匹配空白字符
- 5.14 匹配非空白字符
- 5.15 匹配多行文本
- 5.16 匹配特定字符集
- 5.17 匹配特定字符集的补集
- 5.18 匹配重复字符
- 6. 总结
- 系列文章
- 热门专栏
大家好,我是水滴~~
Python标准库中的re模块是用于处理正则表达式的模块。正则表达式是一种用于匹配字符串的强大工具,可以方便地从文本中提取和处理数据。在本教程中,我们将介绍re模块的基本用法和示例。
1. 导入re模块
在使用re模块之前,需要先导入它。可以使用以下代码导入re模块:
import re
2. re模块中的常用函数
Python的re模块提供了众多用于处理正则表达式的函数。下面是一些常用的函数:
2.1 re.search()
re.search()函数用于在字符串中搜索正则表达式的第一个匹配项。如果匹配成功,返回匹配对象;否则返回None。
import restring = "The quick brown fox jumps over the lazy dog."
match = re.search("fox", string)if match:print("Found:", match.group())
else:print("Not found")
输出:
Found: fox
2.2 re.findall()
re.findall()函数用于在字符串中查找所有匹配的子串,并以列表形式返回。如果没有找到匹配,返回空列表。
import restring = "The quick brown fox jumps over the lazy dog."
matches = re.findall("o", string)if matches:print("Found:", matches)
else:print("Not found")
输出:
Found: ['o', 'o', 'o', 'o']
2.3 re.sub()
re.sub()函数用于在字符串中用指定的字符串替换所有匹配的子串,并返回新的字符串。可以使用正则表达式来指定要替换的模式。
import restring = "The quick brown fox jumps over the lazy dog."
new_string = re.sub("fox", "cat", string)print("Old string:", string)
print("New string:", new_string)
输出:
Old string: The quick brown fox jumps over the lazy dog.
New string: The quick brown cat jumps over the lazy dog.
2.4 re.compile()
re.compile()函数用于将正则表达式编译成一个正则表达式对象,以便在后续的匹配中重复使用。
import repattern = re.compile("fox")
string = "The quick brown fox jumps over the lazy dog."
match = pattern.search(string)if match:print("Found:", match.group())
else:print("Not found")
输出:
Found: fox
2.5 re.split()
re.split()函数用于根据正则表达式来分割字符串,并返回分割后的列表。
import restring = "The quick brown fox jumps over the lazy dog."
words = re.split("\W+", string)print(words)
输出:
['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '']
3. 正则表达式的语法
在使用Python的re模块时,需要使用正则表达式来指定要匹配的模式。正则表达式由一系列字符和特殊字符组成。下面是一些常用的特殊字符:
| 字符 | 描述 |
|---|---|
| . | 匹配除了换行符外的任意单个字符 |
| * | 匹配前面的字符0次或多次 |
| + | 匹配前面的字符1次或多次 |
| ? | 匹配前面的字符0次或1次 |
| {n} | 匹配前面的字符n次 |
| {n,} | 匹配前面的字符至少n次 |
| {n,m} | 匹配前面的字符至少n次,但不超过m次 |
| [] | 匹配方括号中的任意单个字符 |
| [^] | 匹配不在方括号中的任意单个字符 |
| () | 分组,可以在匹配中引用 |
下面是一些示例:
| 正则表达式 | 描述 |
|---|---|
| abc | 匹配字符串"abc" |
| . | 匹配任意单个字符 |
| a* | 匹配零个或多个字符"a" |
| a+ | 匹配一个或多个字符"a" |
| a? | 匹配零个或一个字符"a" |
| a{3} | 匹配三个字符"a" |
| a{3,} | 匹配至少三个字符"a" |
| a{3,6} | 匹配三到六个字符"a" |
| [abc] | 匹配单个字符"a"、“b"或"c” |
| [^abc] | 匹配除了字符"a"、"b"和"c"以外的任意单个字符 |
| (ab)+ | 匹配一个或多个"ab"字符串 |
4. 匹配对象的属性和方法
当使用re模块的函数对字符串进行匹配时,将返回一个匹配对象。匹配对象具有以下常用属性和方法:
4.1 group()
group()方法返回匹配的子串。
import restring = "The quick brown fox jumps over the lazy dog."
match = re.search("fox", string)if match:print("Found:", match.group())
else:print("Not found")
输出:
Found: fox
4.2 start()
start()方法返回匹配的子串在原始字符串中的开始位置的索引。
import restring = "The quick brown fox jumps over the lazy dog."
match = re.search("fox", string)if match:print("Start index:", match.start())
else:print("Not found")
输出:
Start index: 16
4.3 end()
end()方法返回匹配的子串在原始字符串中的结束位置的索引。
import restring = "The quick brown fox jumps over the lazy dog."
match = re.search("fox", string)if match:print("End index:", match.end())
else:print("Not found")
输出:
End index: 19
4.4 span()
span()方法返回匹配的子串在原始字符串中的开始和结束位置的索引。
import restring = "The quick brown fox jumps over the lazy dog."
match = re.search("fox", string)if match:print("Span:", match.span())
else:print("Not found")
输出:
Span: (16, 19)
5. 常用示例
正则表达式是一种强大的文本匹配工具,可以用于处理字符串中的数据和信息。在Python中,可以使用re模块来处理正则表达式。下面是一些常见的正则表达式示例,用于展示如何使用Python中的正则表达式。
5.1 匹配数字
匹配数字非常常见,可以使用\d元字符来匹配任意数字。例如,下面的正则表达式将匹配任意数字:
import restring = "There are 123 apples in the basket."
matches = re.findall("\d+", string)print(matches)
输出:
['123']
5.2 匹配邮箱
匹配邮箱也是一种常见的需求,可以使用正则表达式来实现。下面的正则表达式将匹配有效的邮箱地址:
import reemail = "example@domain.com"
pattern = r"^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$"
matches = re.findall(pattern, email)print(matches)
输出:
['example@domain.com']
5.3 匹配URL
匹配URL也是一种常见的需求,可以使用正则表达式来实现。下面的正则表达式将匹配有效的URL地址:
import reurl = "https://www.google.com/search?q=python"
pattern = r"https?://(?:[-\w.]|(?:%[\da-fA-F]{2}))+"
matches = re.findall(pattern, url)print(matches)
输出:
['https://www.google.com']
5.4 匹配日期
匹配日期也是一种常见的需求,可以使用正则表达式来实现。下面的正则表达式将匹配格式为YYYY-MM-DD的日期:
import redate = "Today is 2023-07-29."
pattern = r"\d{4}-\d{2}-\d{2}"
matches = re.findall(pattern, date)print(matches)
输出:
['2023-07-29']
5.5 匹配IP地址
匹配IP地址也是一种常见的需求,可以使用正则表达式来实现。下面的正则表达式将匹配有效的IP地址:
import reip = "192.168.1.1"
pattern = r"\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\b"
matches = re.findall(pattern, ip)print(matches)
输出:
['192.168.1.1']
5.6 匹配HTML标签
匹配HTML标签也是一种常见的需求,可以使用正则表达式来实现。下面的正则表达式将匹配HTML标签:
import rehtml = "<p>This is a paragraph.</p>"
pattern = r"<.*?>"
matches = re.findall(pattern, html)print(matches)
输出:
['<p>', '</p>']
5.7 匹配手机号码
匹配手机号码也是一种常见的需求,可以使用正则表达式来实现。下面的正则表达式将匹配有效的手机号码:
import rephone = "13812345678"
pattern = r"1[3-9]\d{9}"
matches = re.findall(pattern, phone)print(matches)
输出:
['13812345678']
5.8 匹配身份证号码
import re
idcard = "310101198001010001"
pattern = r"\d{6}(?:19|20)\d{2}(?:0[1-9]|1[0-2])(?:0[1-9]|[1-2]\d|3[0-1])\d{3}[0-9Xx]"
matches = re.findall(pattern, idcard)
print(matches)
输出:
['310101198001010001']
5.9 匹配QQ号码
import re
qq = "123456"
pattern = r"^[1-9]\d{4,10}$"
matches = re.findall(pattern, qq)
print(matches)
输出:
['123456']
5.10 匹配微信号
import re
wechat = "wx123456"
pattern = r"^[a-zA-Z][-_a-zA-Z0-9]{5,19}$"
matches = re.findall(pattern, wechat)
print(matches)
输出:
['wx123456']
5.11 匹配邮政编码
import re
zipcode = "12345-6789"
pattern = r"\d{5}(?:-\d{4})?"
matches = re.findall(pattern, zipcode)
print(matches)
输出:
['12345-6789']
5.12 匹配中文字符
import re
text = "这是一段中文文本。"
pattern = r"[\u4e00-\u9fa5]+"
matches = re.findall(pattern, text)
print(matches)
输出:
['这是一段中文文本']
5.13 匹配空白字符
import re
text = "This is a sentence with spaces."
matches = re.findall("\s+", text)
print(matches)
输出:
[' ', ' ', ' ', ' ', ' ']
5.14 匹配非空白字符
import re
text = "This is a sentence with spaces."
matches = re.findall("\S+", text)
print(matches)
输出:
['This', 'is', 'a', 'sentence', 'with', 'spaces.']
5.15 匹配多行文本
import re
text = "Line 1\nLine 2\nLine 3"
matches = re.findall(r"^.*$", text, re.MULTILINE)
print(matches)
输出:
['Line 1', 'Line 2', 'Line 3']
5.16 匹配特定字符集
import re
text = "The quick brown fox jumps over the lazy dog."
matches = re.findall("[aeiou]", text)
print(matches)
输出:
['u', 'i', 'o', 'o', 'u', 'o', 'e', 'a', 'o']
5.17 匹配特定字符集的补集
import re
text = "The quick brown fox jumps over the lazy dog."
matches = re.findall("[^aeiou]", text)
print(matches)
输出:
['T', 'h', ' ', 'q', 'c', 'k', ' ', 'b', 'r', 'w', 'n', ' ', 'f', 'x', ' ', 'j', 'm', 'p', 's', ' ', 'v', 'r', ' ', 't', 'h', ' ', 'l', 'z', 'y', ' ', 'd', 'g', '.']
5.18 匹配重复字符
import re
text = "The quick brown fox jumps over the lazy dog."
matches = re.findall("o+", text)
print(matches)
输出:
['o', 'oo', 'o', 'o', 'o']
这些示例展示了如何使用Python中的正则表达式进行文本匹配。正则表达式是一种非常强大的文本处理工具,可以用于处理各种文本数据和信息。在处理和清洗大量文本数据时,正则表达式可以提高工作效率和准确性。
6. 总结
re模块是Python标准库中用于处理正则表达式的模块。它提供了一系列函数和方法,用于在字符串中搜索、替换和分割子串。要使用re模块,需要熟悉正则表达式的语法和常用特殊字符。在匹配成功后,将返回一个匹配对象,可以使用其属性和方法来获取匹配的子串和位置等信息。
系列文章
🔥 Python 进阶(一):PyCharm 下载、安装和使用
🔥 Python 进阶(二):操作字符串的常用方法
热门专栏
👍 《Python入门核心技术》
👍 《IDEA 教程:从入门到精通》
👍 《Java 教程:从入门到精通》
👍 《MySQL 教程:从入门到精通》
👍 《大数据核心技术从入门到精通》
相关文章:
Python 进阶(三):正则表达式(re 模块)
❤️ 博客主页:水滴技术 🌸 订阅专栏:Python 入门核心技术 🚀 支持水滴:点赞👍 收藏⭐ 留言💬 文章目录 1. 导入re模块2. re模块中的常用函数2.1 re.search()2.2 re.findall()2.3 re.sub()2.4…...
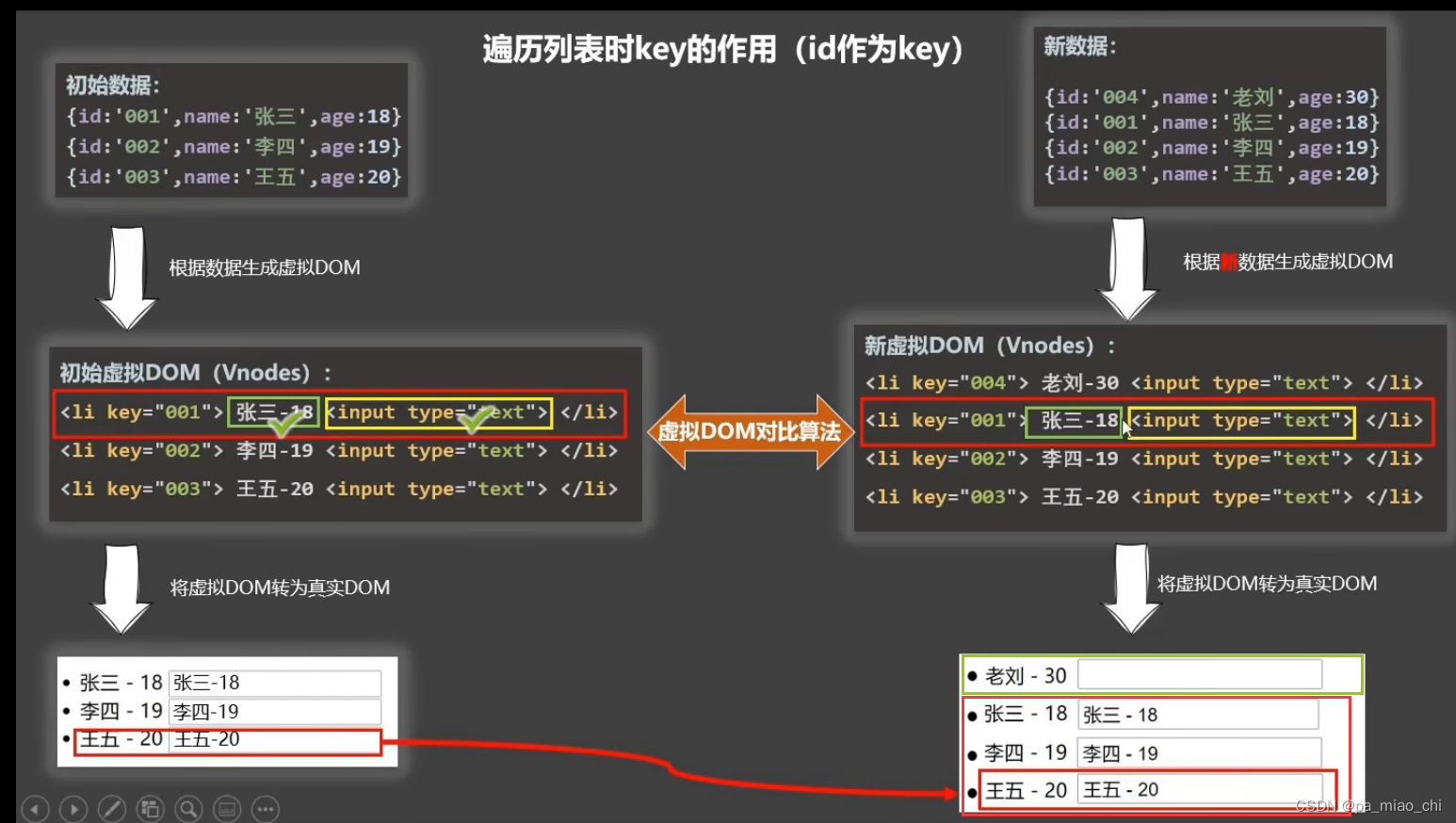
Vue2 第六节 key的作用与原理
(1)虚拟DOM (2)v-for中的key的作用 一.虚拟DOM 1.虚拟DOM就是内存中的数据 2.原生的JS没有虚拟DOM: 如果新的数据和原来的数据有重复数据,不会在原来的基础上新加数据,而是重新生成一份 3. Vue会有虚拟…...

React之组件的生命周期
React之组件的生命周期 一、概述二、整体说明三、挂载阶段四、更新阶段五、卸载阶段 一、概述 生命周期:一个事务从创建到最后消亡经历的整个过程组件的生命周期:组件从被创建到挂载到页面中运行,再到组件不用时卸载的过程意义:理解组件的生…...

linux -网络编程-多线程并发服务器
目录 1.三次握手和四次挥手 2 滑动窗口 3 函数封装思想 4 高并发服务器 学习目标: 掌握三次握手建立连接过程掌握四次握手关闭连接的过程掌握滑动窗口的概念掌握错误处理函数封装实现多进程并发服务器实现多线程并发服务器 1.三次握手和四次挥手 思考: 为什么…...

Golang之路---02 基础语法——字典
字典 字典(Map 类型),是由若干个 key:value 这样的键值对映射组合在一起的数据结构。 key 不能是切片,不能是字典,不能是函数。 字典初始化 方式:map[KEY_TYPE]VALUE_TYPE //1.var map1 map[string]int…...
)
Pytorch(三)
一、经典网络架构图像分类模型 数据预处理部分: 数据增强数据预处理DataLoader模块直接读取batch数据 网络模块设置: 加载预训练模型,torchvision中有很多经典网络架构,可以直接调用注意别人训练好的任务跟咱们的并不完全一样,需要把最后…...
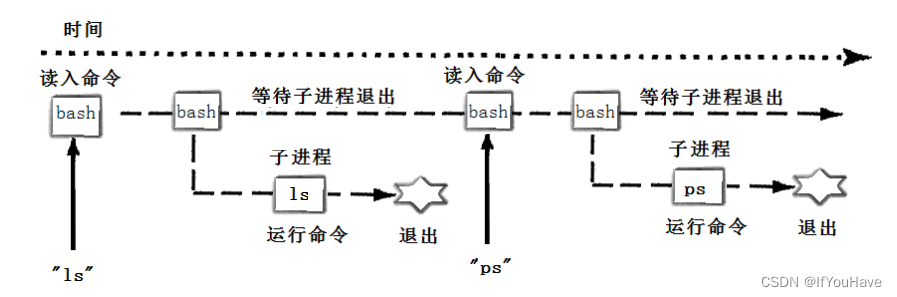
Linux——进程控制
目录 1. 进程创建 1.1 fork函数 1.2 fork系统调用内部宏观流程 1.3 fork后子进程执行位置分析 1.4 fork后共享代码分析 1.5 fork返回值 1.6 写时拷贝 1.7 fork常规用法 1.8 fork调用失败的原因 2.进程终止 2.1 进程退出场景 2.2 strerror函数—返回描述错误号的字符…...
)
剑指 Offer 59 - I. 滑动窗口的最大值 / LeetCode 239. 滑动窗口最大值(优先队列 / 单调队列)
题目: 链接:剑指 Offer 59 - I. 滑动窗口的最大值;LeetCode 239. 滑动窗口最大值 难度:困难 下一篇:剑指 Offer 59 - II. 队列的最大值(单调队列) 给你一个整数数组 nums,有一个大…...
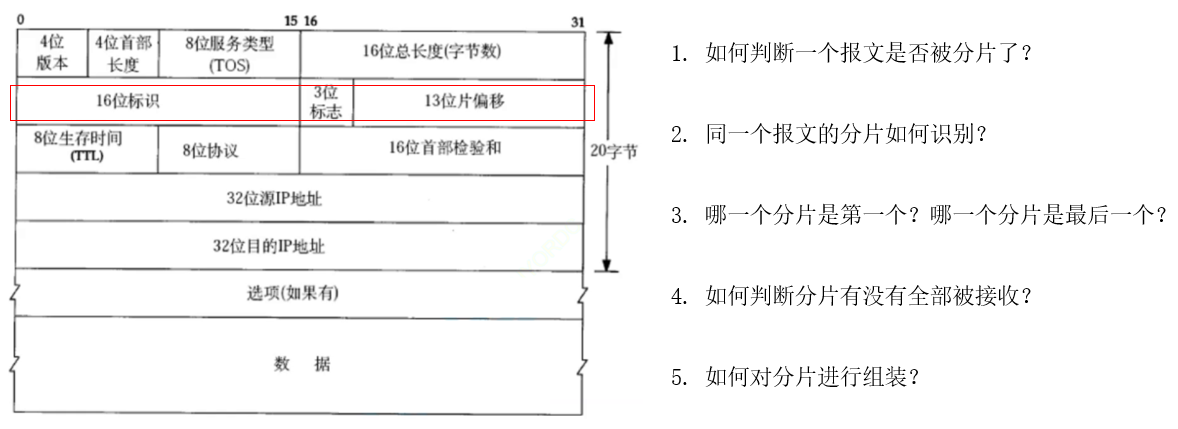
【Linux后端服务器开发】IP协议
目录 一、IP协议概述 二、协议头格式 三、网段划分 四、IP地址的数量限制 五、路由 六、分片和组装 一、IP协议概述 主机:配有IP地址,但是不进行路由控制的设备 路由器:即配有IP地址,又能进行路由控制 节点:主…...

React组件进阶之children属性,props校验与默认值以及静态属性static
React组件进阶之children属性,props校验与默认值以及静态属性static 一、children属性二、props校验2.1 props说明2.2 prop-types的安装2.3 props校验规则2.4 props默认值 三、静态属性static 一、children属性 children 属性:表示该组件的子节点,只要组…...
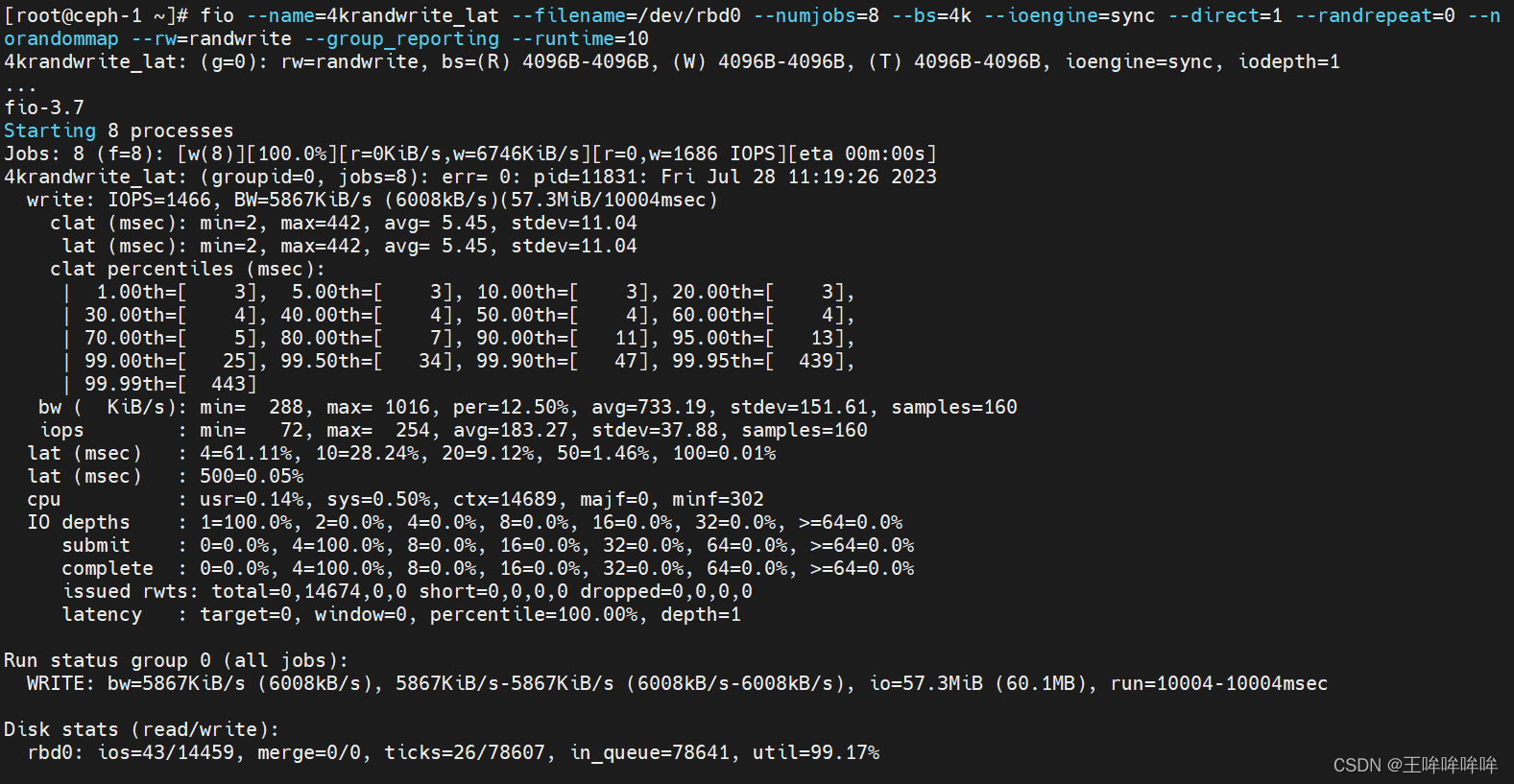
ceph集群中RBD的性能测试、性能调优
文章目录 rados benchrbd bench-write测试工具Fio测试ceph rbd块设备的iops性能测试ceph rbd块设备的带宽测试ceph rbd块设备的延迟 性能调优 rados bench 参考:https://blog.csdn.net/Micha_Lu/article/details/126490260 rados bench为ceph自带的基准测试工具&am…...

texshop mac中文版-TeXShop for Mac(Latex编辑预览工具)
texshop for mac是一款可以在苹果电脑MAC OS平台上使用的非常不错的Mac应用软件,texshop for mac是一个非常有用的工具,广泛使用在数学,计算机科学,物理学,经济学等领域的合作,这些程序的标准tetex分布特产…...
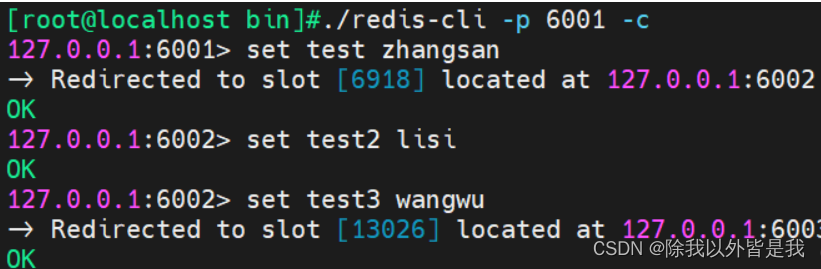
简单认识redis高可用实现方法
文章目录 一、redis群集三种模式二、 Redis 主从复制1、简介2、作用:3、流程:4.配置主从复制 三、Redis 哨兵模式1、简介2、原理:3、作用:4、哨兵结构由两部分组成,哨兵节点和数据节点:5、故障转移机制:6、…...

搭建git服务器
1.创建linux账户,创建文件 adduser git passwd gitpsw su git pwd cd ~/ mkdir .ssh cd ~/.ssh touch authorized_keys 2.特别重要(单独起一行),给文件设权限 chmod 700 /home/git/.ssh chmod 600 /home/git/.ssh/authorized_keys 3.本地生产密钥并把…...

线程中断机制
如何中断一个线程? 首先一个线程不应该由其他线程来强制中断或者停止,而是应该由线程自己自行停止。所以我们看到线程的stop()、resume()、suspend()等方法已经被标记为过时了。 其次在java中没有办法立即停止一个线程,然而停止线程显得尤为重…...

CollectionUtils工具类的使用
来自:小小程序员。 本文仅作记录 org.apache.commons.collections包下的CollectionUtils工具类,下面说说它的用法: 一、集合判空 通过CollectionUtils工具类的isEmpty方法可以轻松判断集合是否为空,isNotEmpty方法判断集合不为…...

基于Nonconvex规划的配电网重构研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
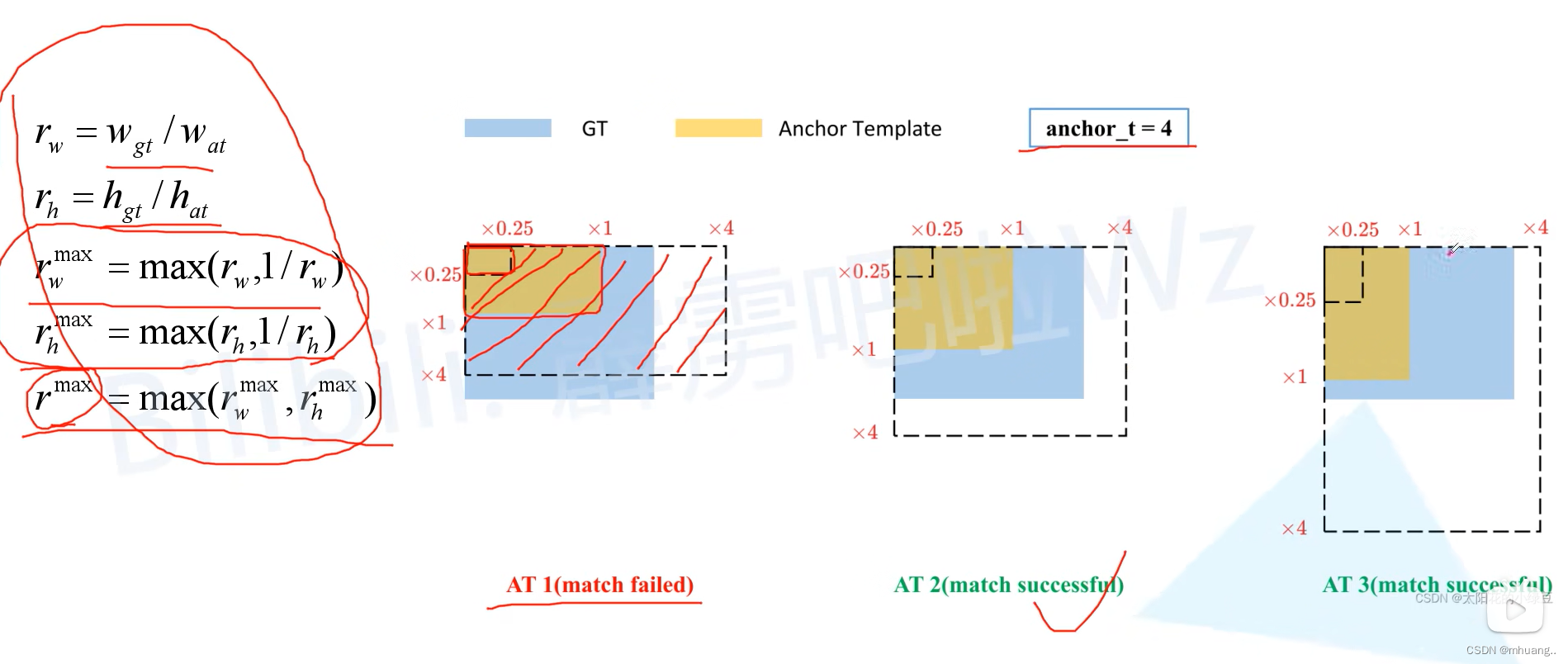
yolo系列笔记(v4-v5)
YOLOv4 YOLOv4网络详解_哔哩哔哩_bilibili 网络结构,在Yolov3的Darknet的基础上增加了CSP结构。 CSP的优点: 加强CNN的学习能力 去除计算瓶颈。 减少显存的消耗。 结构为: 、 其实还是类似与残差网络的结构,保留下采样之前…...

小白如何高效刷题Leetcode?
文章目录 为什么会有这样的现象?研究与学习人生而有别 如何解决困境?1. 要补的:化抽象为具体,列举找规律2. 要补的:前人总结的套路3. 与人交流探讨4. 多写总结文章 总结 明明自觉学会了不少知识,可真正开始…...
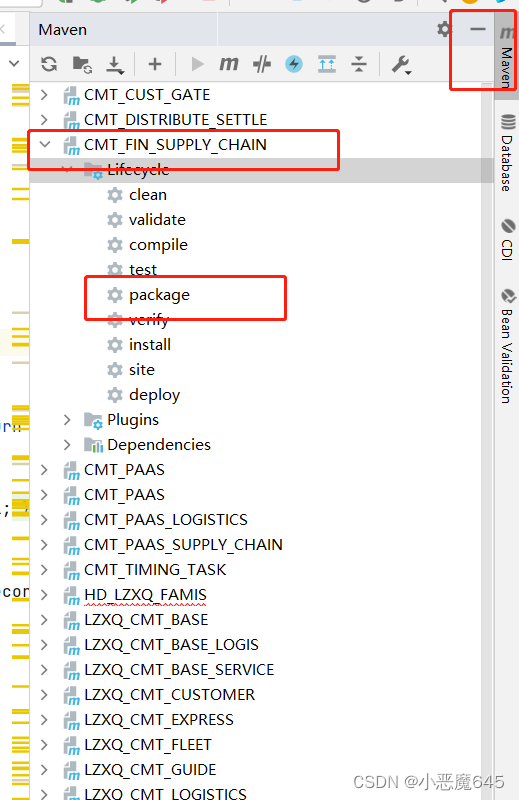
使用IDEA打jar包的详细图文教程
1. 点击intellij idea左上角的“File”菜单 -> Project Structure 2. 点击"Artifacts" -> 绿色的"" -> “JAR” -> Empty 3. Name栏填入自定义的名字,Output ditectory 选择 jar 包目标目录,Available Elements 里右击…...
)
DeepSeek高并发场景下的云原生弹性架构设计(千万QPS容灾实测数据首次公开)
更多请点击: https://codechina.net 第一章:DeepSeek高并发场景下的云原生弹性架构设计(千万QPS容灾实测数据首次公开) 在支撑DeepSeek大模型推理服务的生产环境中,我们构建了一套面向千万级QPS的云原生弹性架构。该架…...

别再一页页改了!用OrCAD Capture CIS高效管理原理图文档与BOM
用OrCAD CIS实现原理图文档与BOM的智能化协同管理 在硬件工程团队协作中,原理图文档与物料清单(BOM)的一致性管理常成为效率瓶颈。传统手工维护方式不仅耗时费力,更可能因人为疏忽导致版本混乱。OrCAD Capture CIS的元件信息系统为…...

AI-auth-toolkit社区贡献指南:从入门到核心开发者
AI-auth-toolkit社区贡献指南:从入门到核心开发者 【免费下载链接】genai-compliance-bench GenAI compliance benchmark is a evaluation benchmarks for generative AI in regulated industries. 项目地址: https://gitcode.com/gh_mirrors/ai/genai-compliance…...

同事悄悄告诉我,他月薪比我高1.8万,岗位一模一样。我去问HR,HR说,薪资保密。我才明白,保密的从来不是他的,是我的
最近看到一个帖子,有人说,他在公司干了三年,一直以为自己的薪资还算正常,直到有一天,关系不错的同事喝多了,把工资条拍给他看。两个人同一天入职,同一个岗位,同一个绩效评级。差了1.…...

轻量级本地OCR工具SmolDocling实战指南
1. 项目概述:为什么需要一个本地运行的轻量级OCR应用?SmolDocling这个名字本身就带着点工程师式的幽默感——“smol”是“small”的网络变体,强调体积小、依赖少;“Docling”则暗指文档(document)处理的小精…...

Layerdivider:AI智能分层工具完整指南 - 快速将单张图片转为分层PSD
Layerdivider:AI智能分层工具完整指南 - 快速将单张图片转为分层PSD 【免费下载链接】layerdivider A tool to divide a single illustration into a layered structure. 项目地址: https://gitcode.com/gh_mirrors/la/layerdivider Layerdivider是一个革命性…...

10分钟快速上手:使用html-to-docx实现HTML到Word文档的无缝转换
10分钟快速上手:使用html-to-docx实现HTML到Word文档的无缝转换 【免费下载链接】html-to-docx HTML to DOCX converter 项目地址: https://gitcode.com/gh_mirrors/ht/html-to-docx 还在为网页内容无法完美转换为Word文档而烦恼吗?每次复制粘贴H…...

Upscayl Windows编译深度解析:从Vulkan初始化失败到成功构建的专业指南
Upscayl Windows编译深度解析:从Vulkan初始化失败到成功构建的专业指南 【免费下载链接】upscayl 🆙 Upscayl - #1 Free and Open Source AI Image Upscaler for Linux, MacOS and Windows. 项目地址: https://gitcode.com/GitHub_Trending/up/upscayl…...

Makefile中FORCE伪目标的原理与应用:实现强制构建与版本信息生成
1. 项目概述与FORCE的引入在嵌入式开发,尤其是像RT-Thread这类复杂操作系统的构建过程中,Makefile是绕不开的核心工具。它不仅仅是编译指令的集合,更是整个项目构建逻辑的蓝图。很多工程师,特别是从IDE环境转过来的朋友࿰…...

KubeVirt虚拟化实践:在Kubernetes上运行虚拟机
KubeVirt虚拟化实践:在Kubernetes上运行虚拟机 一、KubeVirt概述 KubeVirt是一个开源项目,允许在Kubernetes集群上运行和管理虚拟机(VM)。它将Kubernetes的编排能力与传统虚拟化技术相结合,实现了容器与虚拟机的统一管理。 KubeVirt的核心…...