kafka:消费者从指定时间的偏移开始消费(二)
我的前一篇博客《kafka:AdminClient获取指定主题的所有消费者的消费偏移(一)》为了忽略忽略掉上线之前的所有消息,从获取指定主题的所有消费者的消费偏移并计算出最大偏移来解决此问题。
但这个方案需要使用不常用的AdminClient类,而且如果该主题如果是第一次被消费者拉取消息时,因为得不到消费者的消费偏移,最后的结果,就是从0偏移开始拉取所有消息。并不能真正实现忽略上线之前所有消息的目的。
所以我又优化了方案。基本的原理就是使用KafkaConsumer.offsetsForTimes方法获取消费者的所有主题分区的指定时间的偏移,并将这个偏移作为消费开始的偏移(KafkaConsumer.seek方法) 。
@Testpublic void test3SeekToTime() {// 配置Kafka消费者的属性Properties props = new Properties();props.put("bootstrap.servers", "localhost:9092");props.put("group.id", "my_consumer_group");props.put("key.deserializer", StringDeserializer.class.getName());props.put("value.deserializer", StringDeserializer.class.getName());// 创建Kafka消费者实例try(Consumer<String, String> consumer = new KafkaConsumer<>(props)){ boolean seek = false;/** * 循环开始的时间,* 忽略该时间之前的消息*/long startMills = System.currentTimeMillis();while (true) {try {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(4000));if(!seek) {if(!records.isEmpty()) {/** * 获取第一批消息时更新消息偏移到循环开始的时间*/consumer.offsetsForTimes(Maps.asMap(consumer.assignment(),t->startMills)).forEach((k,v)->{if(null != v) {System.out.println("seek %s to %s",k,v.offset());consumer.seek(k,v.offset());}});seek = true;}/** 跳过第一批获取到的消息,继续循环 */continue;}records.forEach(record -> {String value = record.value();System.out.println("Received message: " + value);});}catch (Exception e) {e.printStackTrace();}}}}
相关文章:
)
kafka:消费者从指定时间的偏移开始消费(二)
我的前一篇博客《kafka:AdminClient获取指定主题的所有消费者的消费偏移(一)》为了忽略忽略掉上线之前的所有消息,从获取指定主题的所有消费者的消费偏移并计算出最大偏移来解决此问题。 但这个方案需要使用不常用的AdminClient类,而且如果该主题如果是第…...
Spring的加载配置文件、容器和获取bean的方式
🐌个人主页: 🐌 叶落闲庭 💨我的专栏:💨 c语言 数据结构 javaweb 石可破也,而不可夺坚;丹可磨也,而不可夺赤。 Spring配置文件和容器相关 一、加载properties文件1.1加载…...

(二)利用Streamlit创建第一个app——单页面、多页面
1 单页面app Step1:创建一个新的Python脚本。我们称之为uber_pickups.py。 Step2:在您喜爱的IDE或文本编辑器中打开uber_pickups.py,然后添加以下行: import streamlit as st import pandas as pd import numpy as npStep3&…...

一条sql查询语句在mysql中的执行过程是什么
mysql的连接器 我们想要在mysql中执行一条sql查询语句,首先需要连接到mysql服务,那么客户端首先要向mysql服务端发起连接请求,我们可以在客户端用mysql -h [ip] -P [port] -u 用户名 -p 密码 命令向服务端发起连接请求,这个连接请…...

网络互联究竟是需要什么协议相同,什么协议不同?
混淆概念的几个说法: 说法1: “以太网交换机不可以实现采用不同网络层协议的互联” 原因:以太网交换机是数据链路层的设备,不懂网络层的知识 说法2: “网桥可互联不同的物理层、不同的MAC子层以及不同速率的以太网”…...
ajax axios json
目录 一、ajax概述 1. 概念 2. 实现方式 (1)原生的JS实现方式(了解) (2) JQeury实现方式 二、axios 介绍 三、axios使用 1. axios 发送get/post请求 2. axios验证用户名称是否存在 四、json 1. …...
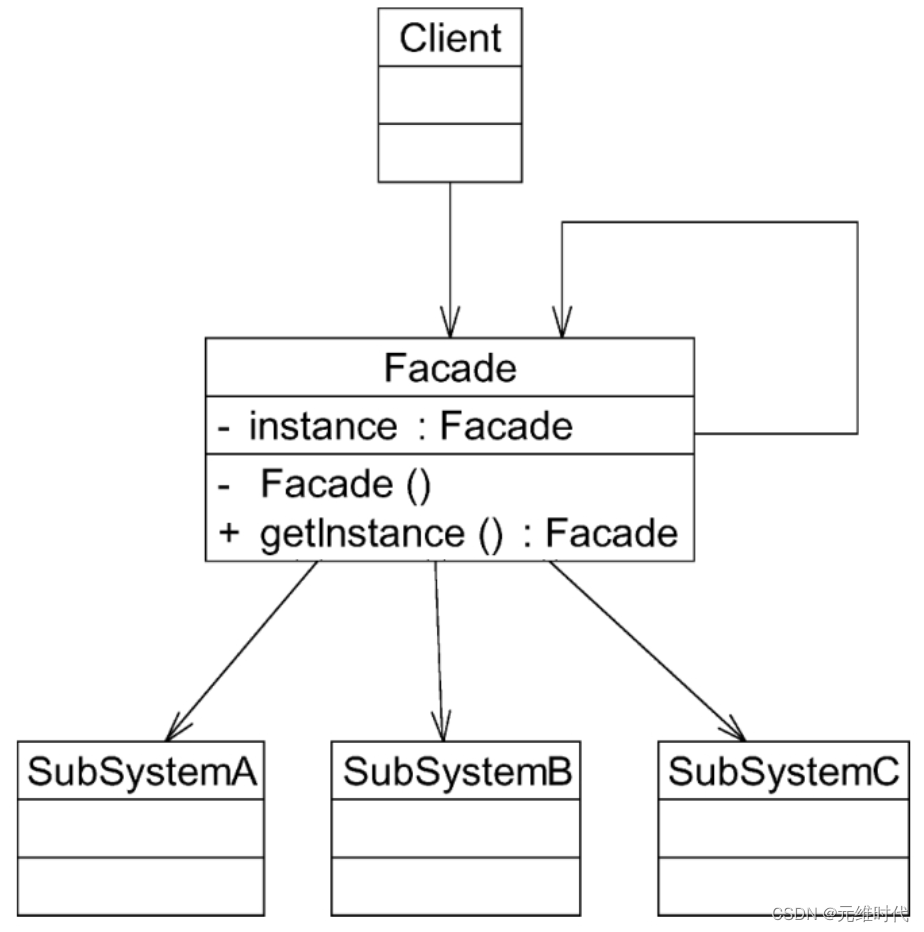
外观模式——提供统一入口
1、简介 1.1、概述 在软件开发中,有时候为了完成一项较为复杂的功能,一个类需要和多个其他业务类交互,而这些需要交互的业务类经常会作为一个完整的整体出现,由于涉及的类比较多,导致使用时代码较为复杂。此时&#…...
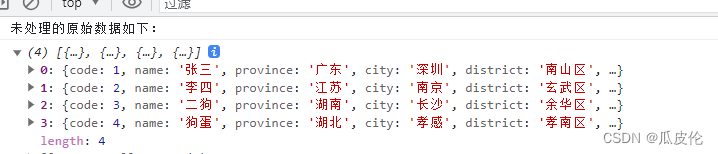
Vue中导入并读取Excel数据
在工作中遇到需要前端上传excel文件获取到相应数据处理之后传给后端并且展示上传文件的数据. 一、引入依赖 npm install -S file-saver xlsxnpm install -D script-loadernpm install xlsx二、在main.js中引入 import XLSX from xlsx三、创建vue文件 <div><el-uplo…...

CUDA常用函数
cudaDeviceSynchronize cudaDeviceSynchronize是一个CUDA函数,用于同步当前设备上的所有CUDA流。它会阻塞调用它的线程,直到所有设备上的CUDA流都执行完为止。这可以确保在进行后续的CUDA操作时,先前的操作已经完成。 在CUDA程序中࿰…...

72. ElasticSearch常用命令
索引管理 1新建索引 curl -XPUT http://10.42.172.35:9200/index012 读写权限 curl -XPUT -d {"blocks.read":false} http://10.42.172.35:9200/index01/_settings3 查看索引 单个 curl -XGET http://10.42.172.35:9200/index01/_settings多个 curl -XGET http…...
)
2023.7.26(同余方程的通解与特解)
Water(扩欧求特解与通解) 题意:给容量分别为A与B的水杯,问确切喝到C水的最小操作次数 有4种操作:选一杯全喝,选一杯全部倒掉,选一杯装满,将一杯的水尽量倒到另一杯中 思路:只有AxByC有解时才能确…...

Diffusion扩散模型学习3——Stable Diffusion结构解析-以图像生成图像(图生图,img2img)为例
Diffusion扩散模型学习3——Stable Diffusion结构解析-以图像生成图像(图生图,img2img)为例 学习前言源码下载地址网络构建一、什么是Stable Diffusion(SD)二、Stable Diffusion的组成三、img2img生成流程1、输入图片编…...

LangChain||什么是LangChain? LangChain有什么用?
从Auto-GPT说起: Auto-GPT可以调用本地电脑工具处理复杂信息;Auto-GPT可以围绕目标查阅资 料、“独立思考”、及时反馈、并 及时调整下一步操作…Auto-GPT的诞生,创造了大家 对“将LLM作为智慧大脑来高效 处理综合复杂任务”的想象;首次尝试串联大语言模…...

秋招算法备战第28天 | 93.复原IP地址、78.子集、90.子集II
93. 复原 IP 地址 - 力扣(LeetCode) 这个问题可以通过深度优先搜索(DFS)的方法来解决。我们要做的就是在字符串的每个可能位置插入点,然后检查生成的每一部分是否在 0-255 的范围内,以及是否没有前导零(除非这一部分本…...

Mongodb空间索引的使用以及与Django的对接
Mongodb的空间索引 Mongodb数据库大家都非常熟悉,是一个基于分布式文件存储的开源数据库系统,在高负载的情况下,添加更多的节点,可以保证服务器性能,数据结构由键值(key>value)对组成。MongoDB 文档类似于 JSON 对…...

Windows安装MySQL数据库
MySQL数据库安装 MySQL下载 下载地址:https://dev.mysql.com/downloads/mysql/ 可以选择下载msi或zip,以下为zip模式安装步骤 下载了mysql的zip安装包之后解压即可; Windows安装步骤 初始化MySQL,并记录生成的用户密码root的随机…...

聊聊函数式编程中的“式”
当谈到函数式编程的“式”时,通常指的是函数的组合、转换和应用,以及处理数据的方式和风格。在函数式编程中,式是用来构建程序逻辑的基本单元。 下面更详细解释函数式编程中的几个关键式: 函数的组合: 函数式编程中…...

ubuntu目录分析
在Ubuntu根目录下,以下是一些常见文件夹的含义: /bin:存放可执行文件,包含一些基本的命令和工具。 /boot:存放启动时所需的文件,如内核和引导加载程序。 /dev:包含设备文件,用于与硬…...

Python 进阶(三):正则表达式(re 模块)
❤️ 博客主页:水滴技术 🌸 订阅专栏:Python 入门核心技术 🚀 支持水滴:点赞👍 收藏⭐ 留言💬 文章目录 1. 导入re模块2. re模块中的常用函数2.1 re.search()2.2 re.findall()2.3 re.sub()2.4…...
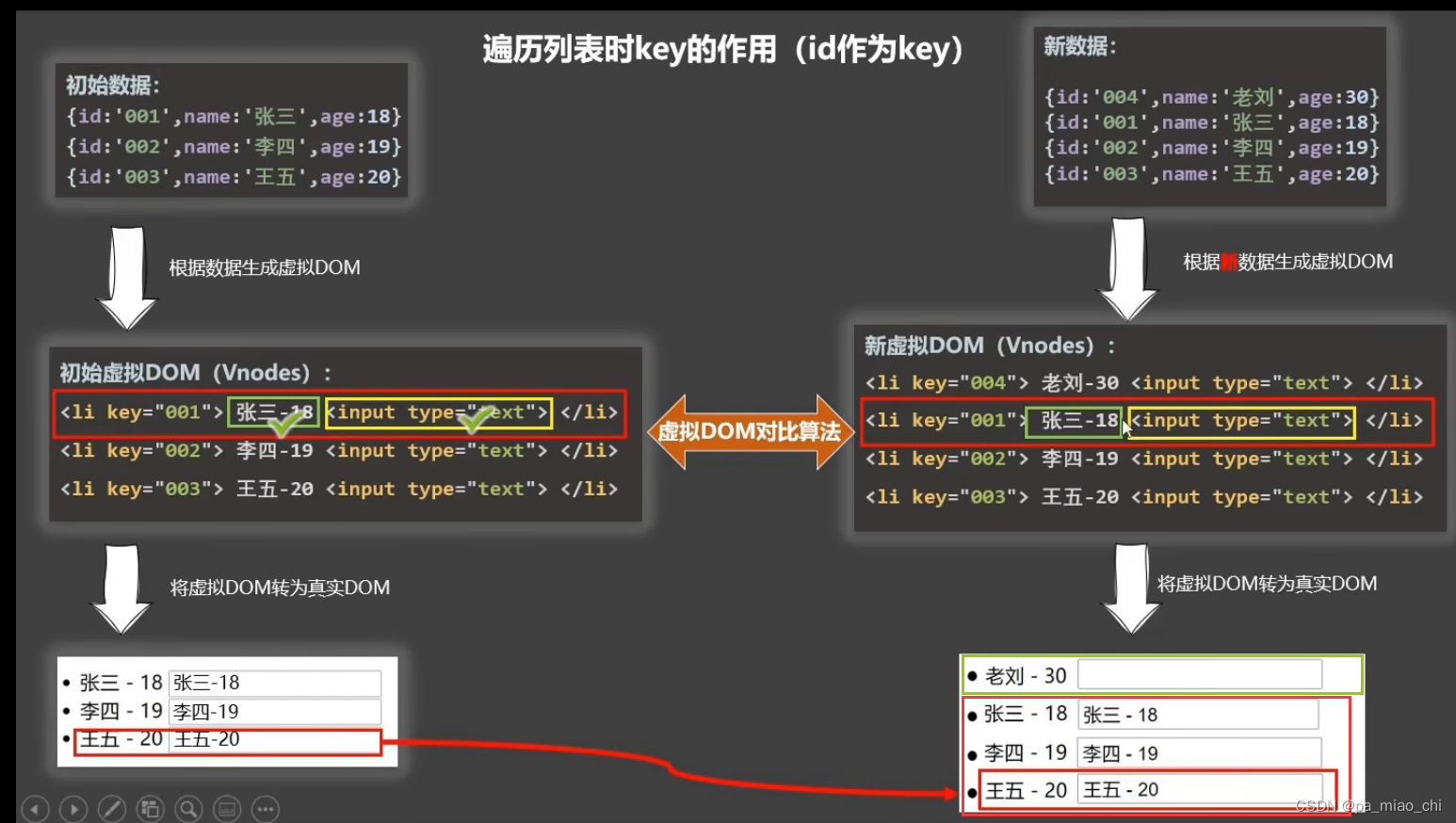
Vue2 第六节 key的作用与原理
(1)虚拟DOM (2)v-for中的key的作用 一.虚拟DOM 1.虚拟DOM就是内存中的数据 2.原生的JS没有虚拟DOM: 如果新的数据和原来的数据有重复数据,不会在原来的基础上新加数据,而是重新生成一份 3. Vue会有虚拟…...

ECB02蓝牙主机模式避坑实录:STM32F103C8T6连接失败、绑定不清除的5个常见问题解决
ECB02蓝牙主机模式实战避坑指南:STM32F103C8T6连接异常全解析 当你第一次尝试用STM32F103C8T6通过ECB02蓝牙模块建立主机连接时,大概率会遇到各种"灵异现象":模块毫无反应、AT指令石沉大海、设备死活连不上旧设备、数据乱码像天书……...

告别应用层延时!在迅为RK3568开发板上,将RS485收发切换彻底交给Linux内核驱动
告别应用层延时!在迅为RK3568开发板上将RS485收发切换彻底交给Linux内核驱动 工业自动化领域对通信实时性的要求近乎苛刻,当RS485总线上挂载的多个设备响应时间参差不齐时,应用层手动控制的收发切换就像用机械表校准原子钟——看似可行实则漏…...

如何高效解决多云存储兼容问题?Alibaba Cloud OSS SDK实战指南
如何高效解决多云存储兼容问题?Alibaba Cloud OSS SDK实战指南 【免费下载链接】alibabacloud-oss-sdk The OSS SDK. Powered by Darabonba. 项目地址: https://gitcode.com/gh_mirrors/al/alibabacloud-oss-sdk 面对日益复杂的多云存储环境,开发…...

同事悄悄告诉我,他月薪比我高1.8万,岗位一模一样。我去问HR,HR说,薪资保密。我才明白,保密的从来不是他的,是我的
最近看到一个帖子,有人说,他在公司干了三年,一直以为自己的薪资还算正常,直到有一天,关系不错的同事喝多了,把工资条拍给他看。两个人同一天入职,同一个岗位,同一个绩效评级。差了1.…...

ViGEmBus虚拟游戏控制器驱动:Windows游戏输入的革命性解决方案
ViGEmBus虚拟游戏控制器驱动:Windows游戏输入的革命性解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 在Windows游戏世界中,…...

FanControl:重新定义Windows风扇控制,告别恼人噪音与散热烦恼
FanControl:重新定义Windows风扇控制,告别恼人噪音与散热烦恼 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/…...

Playwright×CoPilot:用自然语言驱动UI自动化的新范式
1. 这不是“写代码”,而是让AI替你“看屏幕、点按钮、填表单”“Playwright CoPilot:UI自动化的超级加速器”——这个标题里藏着一个正在悄悄改变测试和RPA工作流的事实:我们正从“手写定位器硬编码断言”的时代,跨入“用自然语言…...

深入解析Linux内核sk_buff内存布局与核心操作原理
1. 项目概述:从数据包到sk_buff的旅程在网络编程和内核开发领域,sk_buff(socket buffer)是一个绕不开的核心数据结构。它就像网络数据包在内核世界里的“标准集装箱”,负责承载从网卡接收到应用层发送的每一份数据。无…...

NotebookLM落地失败真相:为什么83%团队卡在第2阶段?3个权威诊断指标立即自检
更多请点击: https://codechina.net 第一章:NotebookLM落地失败的核心归因诊断 NotebookLM 作为 Google 推出的面向文档理解的实验性 AI 工具,其本地化部署与企业级集成常遭遇系统性失效。深入分析表明,失败并非源于单一技术缺陷…...

碧蓝航线全皮肤解锁终极指南:Perseus补丁五分钟快速上手
碧蓝航线全皮肤解锁终极指南:Perseus补丁五分钟快速上手 【免费下载链接】Perseus Azur Lane scripts patcher. 项目地址: https://gitcode.com/gh_mirrors/pers/Perseus 还在为碧蓝航线中那些精美的舰娘皮肤需要付费解锁而烦恼吗?想要免费体验所…...