降龙十八掌
目录
大数据:
1 HIVE:
1.1 HIVE QL
1.1.1 创建表
1.1.2 更新表
1.1.3 常用语句
1.2 hive参数配置
大数据:
1 HIVE:
1.1 HIVE QL
DDL中常用的命令有:create,drop,alter,truncate和rename等等。而,DML中常用的命令有:insert,update,delete和select等等
1.1.1 创建表
- 创建一张内部分区表
CREATE TABLE ads_ql_jg_jhxm_1day (xzqhdm string comment '行政区划代码' ,sscsdm string comment '所属城市代码' ,yskzjbm string comment '原始库主键编码' ,xmmc string comment '项目名称' ,xmlx string comment '项目类型' ,zgdw string comment '主管单位' ,xmnr string comment '项目内容' ,jhnd int comment '计划年度' ,xmjszq int comment '项目建设周期' ,xmtze decimal(13,3) comment '项目投资额' ,bz string comment '备注' ,sjtbzt string comment '数据同步状态' ,sjtbsj timestamp comment '数据同步时间' ,kjxx string comment '空间信息'
)
COMMENT '桥梁计划项目属性结构表'
partitioned by (partition_time string)
ROW FORMAT DELIMITED FIELDS
TERMINATED BY ',' stored as orc;- 创建外部表
CREATE EXTERNAL TABLE page_view
(
viewTime INT,
userid BIGINT,
page_url STRING,
referrer_url STRING,
ip STRING COMMENT 'IP Address of the User',
country STRING COMMENT 'country of origination'
)
COMMENT 'page_view'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\054' --指定字段分隔符,这里我们使用逗号分隔符
--FIELDS TERMINATED BY '\t':制表符(\t)作为字段分隔符。
STORED AS TEXTFILE
LOCATION '<hdfs_location>'; -
创建分桶表
CREATE TABLE par_table
(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User'
)
COMMENT 'par_table'
PARTITIONED BY(date STRING, pos STRING) --2级分区
CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS --根据 userid 列进行分桶,并在每个桶内按照 viewTime 列进行排序
ROW FORMAT DELIMITED '\t'
FIELDS TERMINATED BY '\n'
STORED AS ORC;
1.1.2 更新表
--删除表
DROP TABLE table_name;--删除多个分区
ALTER TABLE table_name DROP PARTITION (statis_date='20230701'), PARTITION (statis_date='20230702');
--删除一个分区范围
--删除 2023-07-01 到 2023-07-10 的日分区
ALTER TABLE table_name DROP PARTITION (statis_date BETWEEN '20230701' AND '20230710');--重命名表
ALTER TABLE table_name RENAME TO new_table_name;--修改列的名字、类型、位置、注释
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
--这个命令可以允许改变列名、数据类型、注释、列位置或者它们的任意组合,例子如下
--将dwd_test_d 表中的orderid 字段修改为order_id,并把字段类型和注释更新成新的
ALTER TABLE dwd_test_d CHANGE COLUMN orderid order_id string comment '订单号';1.1.3 常用语句
--新增字段
ALTER TABLE employee ADD COLUMNS (salary double COMMENT '员工薪水');--复制一个空表
CREATE TABLE empty_key_value_store LIKE key_value_store;--插入数据的语句
INSERT INTO table VALUES (value1, value2, ...),(value1, value2, ...), ...--往分区表写入的语句
insert overwrite table dwd_test_d partition (partition_time='20230524')
select
...from
table_name--快速创建备份表
create table ads_ql_jg_wqzzjl_full_20230711 stored as orc as
select
*
from
ads_ql_jg_wqzzjl_full--hive取昨天日期
regexp_replace(substr(date_sub(FROM_UNIXTIME(UNIX_TIMESTAMP()),1),1,10),'-','')
--hive取明天日期
regexp_replace(substr(date_add(FROM_UNIXTIME(UNIX_TIMESTAMP()),1),1,10),'-','')
--时间戳
from_unixtime(unix_timestamp(),'yyyy-MM-dd HH:mm:ss') as etl_time
--hive取当前日期
DATE_FORMAT(CURRENT_DATE(), 'yyyyMMdd')--开窗函数
row_number() over( partition by a.id, a.create_date order by etl_time desc) as rn
--行转列
select 分类字段,concut_ws('',collet_set (合并字段)) as 别名
from table_name
group by
分类字段--列转行
select 字段,字段别名
from table_name
lateral view explode (split(拆分字段,分隔符)) 表别名 as 字段别名1.1.4 DWD表做更新插入语句
每天把分区表中新增和修改的数据插入到DWD表中
insert overwrite table dwd_ps_jg_xqrb_full
selectsscsbm,sscs,xzqhdm,xzqhmc,.........from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss') as etl_time --etl处理时间
from(selecta.*,row_number() over(partition by a.jyjlbm,a.jyxxbm order by etl_time desc) as rnfrom(selectsscsbm,sscs,xzqhdm,xzqhmc,.........etl_time --etl处理时间fromdwd_ps_jg_xqrb_fullunion allselectsscsbm,sscs,xzqhdm,xzqhmc,.........from_unixtime(unix_timestamp(), 'yyyy-MM-dd HH:mm:ss') as etl_time --etl处理时间frommid_dwd_ps_jg_xqrb_incwherepartition_time = '${lastDay}') a) b
wherern = 1-
1.2 hive参数配置
set mapred.job.name=任务名称;--设置MR任务名称--2个分桶表JOIN设置参数--start
--执行Join操作时,基于排序后的数据进行高效的连接。
set hive.auto.convert.sortmerge.join=true;
--基于分桶的Map Join通过将数据按照相应的分桶策略分配到不同的桶中,然后在执行 Join 操作时,只处理涉及到的特定桶的数据,避免了全表扫描的开销,提高了查询效率。
set hive.optimize.bucketmapjoin = true;
--Sort-Merge Join 通过对参与 Join 操作的表按照 Join 键进行排序,从而实现高效的连接操作。它可以避免传统的 Hash Join 算法所带来的内存开销和数据倾斜的问题。
set hive.optimize.bucketmapjoin.sortedmerge = true;
--2个分桶表JOIN设置参数--endset hive.map.aggr=true; --启用 hive.map.aggr 参数后,Hive 将在 Map 阶段进行部分聚合操作,减少数据传输的数量。具体来说,Map 端会对局部数据进行聚合,将相同键的数据合并在一起,然后再传输给 Reduce 端进行最终的聚合操作。这样做的好处是减少了数据传输量,减轻了网络负载,从而提高了查询性能。尤其在处理大规模数据集时,启用 Map 端聚合功能可以有效减少整体作业的执行时间。但可能会增加 Map 阶段的内存消耗。2 Doris
--建表语句
CREATE TABLE ods_ps_jc_ssjc
(`bsm` varchar(32) NOT NULL comment "标识码"
,`dwbsm` varchar(32) NOT NULL comment "点位标识码"
,`jczb` varchar(32) NOT NULL comment "监测指标"
,`jcz` decimal(20,2) NOT NULL comment "监测值"
,`jccjsj` DATETIME NOT NULL comment "监测采集时间"
,`jcsbsj` DATETIME NOT NULL comment "监测上报时间"
,`bz` varchar(255) comment "备注"
)
DUPLICATE KEY(`bsm`,`dwbsm`,`jczb`)
DISTRIBUTED BY HASH(`bsm`) BUCKETS 1
PROPERTIES(
"replication_allocation" = "tag.location.default: 1"
);--创建动态分区表
CREATE TABLE doris_d.ods_ql_jc_ssjc_inc (
BSM VARCHAR(32) comment '标识码'
,DWBSM VARCHAR(32) comment '点位标识码'
,JCZB VARCHAR(32) comment '监测指标'
,JCZ decimal(20,2) comment '监测值'
,JCCJSJ DATETIME comment '监测采集时间'
,JCSBSJ DATETIME comment '监测上报时间'
,BZ VARCHAR(255) comment '备注'
,YSKZJBZ VARCHAR(64) comment '原始库主键标志'
,SJTBZT VARCHAR(16) comment '数据同步状态'
,SJTBSJ DATETIME comment '数据同步时间'
,SSCSDM VARCHAR(6) comment '所属城市代码'
,EXTRACT_TIME DATETIME comment '抽取时间'
)
DUPLICATE KEY(`BSM`)
COMMENT '桥梁实时监测属性结构表'
PARTITION BY RANGE(SJTBSJ) ()
DISTRIBUTED BY HASH(`SJTBSJ`) BUCKETS 1
PROPERTIES("dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "2","replication_allocation" = "tag.location.default: 1"
);--查询表中分区
SHOW PARTITIONS FROM doris_d.ods_ql_jc_ssjc_inc;
--查询建表语句
SHOW CREATE TABLE doris_d.ods_ql_jc_ssjc_inc
--查询表中某个分区
select * from doris_d.ods_ql_jc_ssjc_inc PARTITION p20230722相关文章:

降龙十八掌
目录 大数据: 1 HIVE: 1.1 HIVE QL 1.1.1 创建表 1.1.2 更新表 1.1.3 常用语句 1.2 hive参数配置 大数据: 1 HIVE: 1.1 HIVE QL DDL中常用的命令有:create,drop,alter,trunc…...

【项目设计】MySQL 连接池的设计
目录 👉关键技术点👈👉项目背景👈👉连接池功能点介绍👈👉MySQL Server 参数介绍👈👉功能实现设计👈👉开发平台选型👈👉MyS…...

Ubuntu系统adb开发调试问题记录
Ubuntu系统adb开发调试问题记录 一、adb devices no permissions二、自定义adb server端口三、动态库目录四、USB抓包 一、adb devices no permissions lsusb -t 设备树直观地查看设备的Bus ID和Device Num,lsusb找到对应的PID和VID编辑udev规则 sudo vim /etc/ud…...

【宏定义】——检验条件是否成立,并返回指定的值
文章目录 功能说明实现示例解析扩展 功能说明 宏检验条件是否成立,并返回指定的值 #define TU_VERIFY(...) _GET_3RD_ARG(__VA_ARGS__, TU_VERIFY_2ARGS, TU_VERIFY_1ARGS, UNUSED)(__VA_ARGS__)TU_VERIFY(1) 检验为真,啥也不干TU_VERIFY(0) 校验为假&…...

UE5引擎源码小记 —反射信息注册过程
序 最近看了看反射相关的知识,用不说一点人话的方式来说,反射是程序在运行中能够动态获取修改或调用自身属性的东西。 一开始我是觉得反射用处好像不大,后续查了下一些反射的使用环境,发现我格局小了,我觉得用处不大的…...
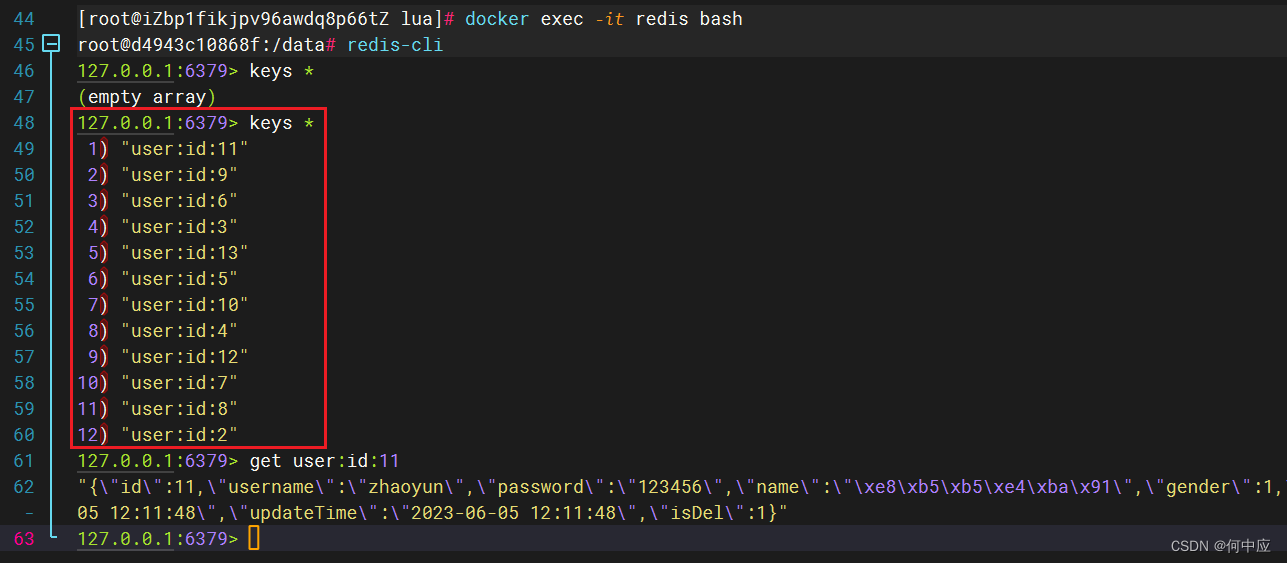
Redis缓存预热
说明:项目中使用到Redis,正常情况,我们会在用户首次查询数据的同时把该数据按照一定命名规则,存储到Redis中,称为冷启动(如下图),这种方式在一些情况下可能会给数据库带来较大的压力…...
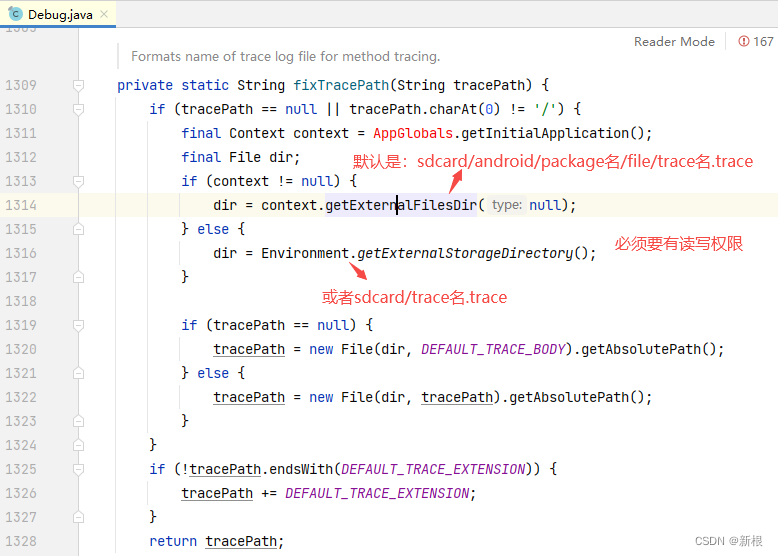
Android 耗时分析(adb shell/Studio CPU Profiler/插桩Trace API)
1.adb logcat 查看冷启动时间和Activity显示时间: 过滤Displayed关键字,可看到Activity的显示时间 那上面display后面的是时间是指包含哪些过程的时间呢? 模拟在Application中沉睡1秒操作,冷启动情况下: 从上可知&…...

保护隐私与安全的防关联、多开浏览器
随着互联网的不断发展,我们越来越离不开浏览器这个工具,它为我们提供了便捷的网络浏览体验。然而,随着我们在互联网上的活动越来越多,我们的个人信息和隐私也日益暴露在网络风险之下。在这种背景下,为了保护个人隐私和…...

CloudStudio搭建Next框架博客_抛开电脑性能在云端编程(沉浸式体验)
文章目录 ⭐前言⭐进入cloud studio工作区指引💖 注册coding账号💖 选择cloud studio💖 cloud studio选择next.js💖 安装react的ui框架(tDesign)💖 安装axios💖 代理请求跨域&#x…...

【FPGA IP系列】FIFO深度计算详解
FIFO(First In First Out)是一种先进先出的存储结构,经常被用来在FPGA设计中进行数据缓存或者匹配传输速率。 FIFO的一个关键参数是其深度,也就是FIFO能够存储的数据条数,深度设计的合理,可以防止数据溢出,也可以节省…...

JavaScript中语句和表达式
在JavaScript编程中,Statements和Expressions都是代码的构建块,但它们有不同的特点和用途。 ● Statements(语句)是执行某些操作的完整命令;每个语句通常以分号结束。例如,if语句、for语句、switch语句、函…...

打卡力扣题目十
#左耳听风 ARST 打卡活动重启# 目录 一、题目 二、解决方法一 三、解决方法二 关于 ARTS 的释义 —— 每周完成一个 ARTS: ● Algorithm: 每周至少做一个 LeetCode 的算法题 ● Review: 阅读并点评至少一篇英文技术文章 ● Tips: 学习至少一个技术技巧 ● Shar…...

UniApp实现API接口封装与请求方法的设计与开发方法
UniApp实现API接口封装与请求方法的设计与开发方法 导语:UniApp是一个基于Vue.js的跨平台开发框架,可以同时开发iOS、Android和H5应用。在UniApp中,实现API接口封装与请求方法的设计与开发是一个十分重要的部分。本文将介绍如何使用UniApp实…...
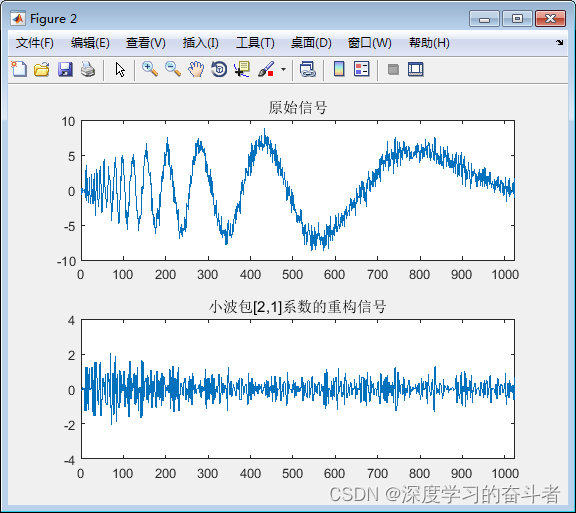
利用小波分解信号,再重构
function [ output_args ] example4_5( input_args ) %EXAMPLE4_5 Summary of this function goes here % Detailed explanation goes here clc; clear; load leleccum; s leleccum(1:3920); % 进行3层小波分解,小波基函数为db2 [c,l] wavedec(s,3,db2); %进行…...
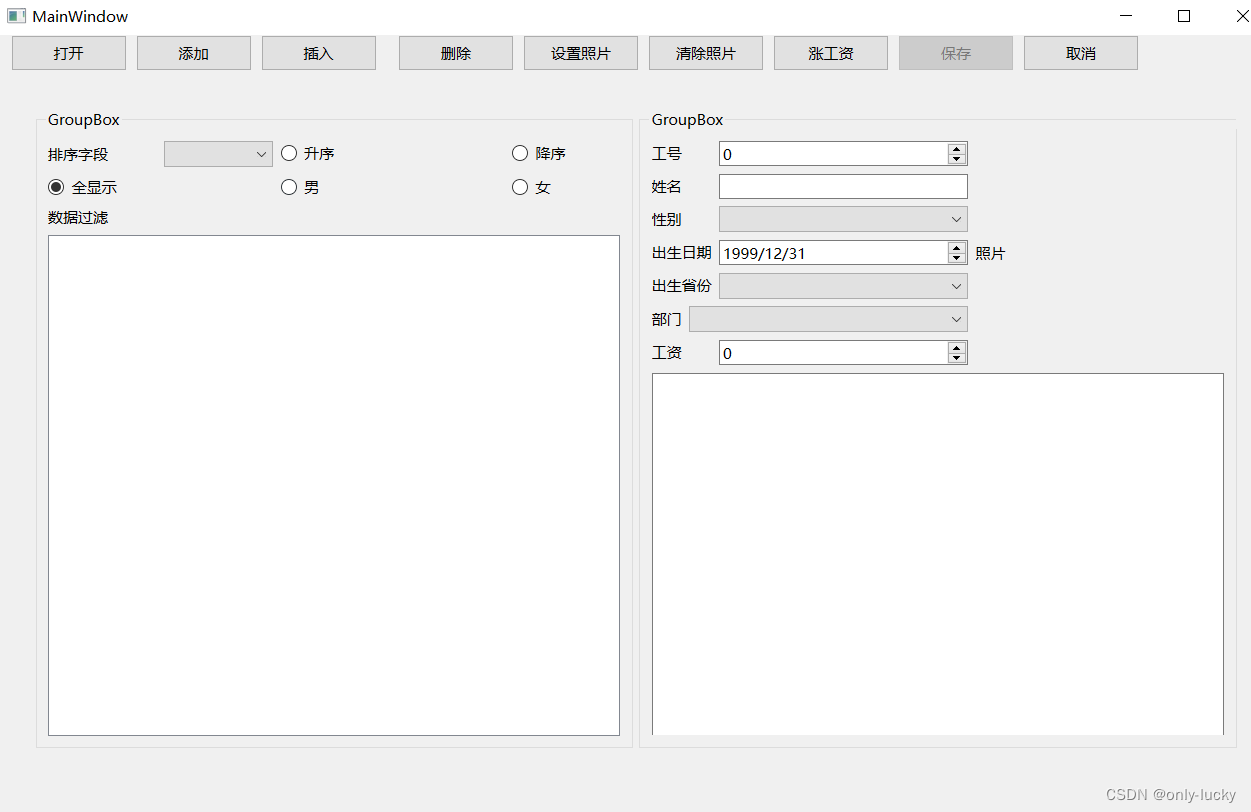
QT数据库编程
ui界面 mainwindow.cpp #include "mainwindow.h" #include "ui_mainwindow.h" #include <QButtonGroup> #include <QFileDialog> #include <QMessageBox> MainWindow::MainWindow(QWidget* parent): QMainWindow(parent), ui(new Ui::M…...

基于stm32单片机的直流电机速度控制——LZW
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 一、实验目的二、实验方法三、实验设计1.实验器材2.电路连接3.软件设计(1)实验变量(2)功能模块a)电机接收信号…...

实际项目中使用mockjs模拟数据
项目中的痛点 自己模拟的数据对代码的侵入程度太高,接口完成后要删掉对应的代码,导致接口开发完后端同事开发完,前端自己得加班;接口联调的时间有可能会延期,接口完成的质量参差不齐;对于数据量过大的模拟…...
【家庭公网IPv6】
家庭公网IPv6 这里有两个网站: 1、 IPV6版、多地Tcping、禁Ping版、tcp协议、tcping、端口延迟测试,在本机搭建好服务器后,可以用这个测试外网是否可以访问本机; 2、 IP查询ipw.cn,这个可以查询本机的网络是否IPv6访问…...

【iOS】Frame与Bounds的区别详解
iOS的坐标系 iOS特有的坐标是,是在iOS坐标系的左上角为坐标原点,往右为X正方向,向下为Y正方向。 bounds和frame都是属于CGRect类型的结构体,系统的定义如下,包含一个CGPoint(起点)和一个CGSiz…...
SpringBoot百货超市商城系统 附带详细运行指导视频
文章目录 一、项目演示二、项目介绍三、运行截图四、主要代码 一、项目演示 项目演示地址: 视频地址 二、项目介绍 项目描述:这是一个基于SpringBoot框架开发的百货超市系统。首先,这是一个很适合SpringBoot初学者学习的项目,代…...

企业级实时数据采集方案:构建高性能直播弹幕监控系统
企业级实时数据采集方案:构建高性能直播弹幕监控系统 【免费下载链接】BarrageGrab 抖音快手bilibili直播弹幕wss直连,非系统代理方式,无需多开浏览器窗口 项目地址: https://gitcode.com/gh_mirrors/ba/BarrageGrab 在直播电商、游戏…...

从状态机视角理解程序:形式化方法如何保证复杂系统正确性
1. 从数学视角审视程序:为什么我们需要形式化思维在软件开发的日常里,我们常常埋头于代码的细节:这个循环边界对不对?那个指针会不会为空?这个API调用返回错误该怎么处理?我们依赖编译器、静态分析工具、单…...

GitHub中文界面插件架构解析与实战指南
GitHub中文界面插件架构解析与实战指南 【免费下载链接】github-chinese GitHub 汉化插件,GitHub 中文化界面。 (GitHub Translation To Chinese) 项目地址: https://gitcode.com/gh_mirrors/gi/github-chinese 核心问题:开发者面临的GitHub语言障…...

Unity PC端微信扫码登录:不拉起浏览器的原生UI集成方案
1. 这不是“微信扫码登录”的常规玩法,而是PC端Unity游戏的UI原生集成方案你有没有遇到过这样的场景:在Unity开发的PC单机游戏或局域网对战工具里,想让用户用微信账号快速登录,但一接入微信开放平台的标准OAuth2流程,点…...

宇树go2机械狗远程操控联网问题
用手机“Unitree Go”app的wifi模式,让狗和电脑连接同一个wifi,使其处于同一个局域网下。要求wifi名和密码无中文。然后在本地电脑powershell输入ipconfig查询本机局域网网段,确认机械狗同一网段 IP 地址。终端执行命令:ssh unitr…...

VMware虚拟机安装及配置
密码 # 设置 root 用户密码 sudo passwd root修改国内镜像源 在 Ubuntu 24.04 之前,Ubuntu 的软件源配置文件路径为 /etc/apt/sources.list;从 Ubuntu 24.04 开始,Ubuntu 的软件源配置文件变更为 DEB822 格式,路径为 /etc/apt/so…...

RK3588嵌入式主板如何以ARM架构重塑智能医疗设备设计
1. 项目概述:当医疗设备遇上“能效比”难题在医疗设备这个对稳定性和可靠性要求近乎苛刻的领域,硬件平台的每一次选择都像是一场精密的外科手术,需要权衡性能、功耗、尺寸、成本与长期供应。过去很长一段时间,当设备需要更强的算力…...
)
香橙派Zero3无屏幕配网新玩法:用ESP32-C3蓝牙模块搞定WiFi连接(附完整代码)
香橙派Zero3无屏幕配网新玩法:用ESP32-C3蓝牙模块搞定WiFi连接(附完整代码) 在物联网和边缘计算项目中,无头设备(Headless Device)的网络配置一直是个棘手问题。想象一下:你刚拿到一块香橙派Zer…...

【K8s】解惑:K8s 与 Docker 的关系
目录 引言:一个绕不开的问题 一句话说清K8s与Docker的关系 澄清三个误解 从命令的角度,直观对比 引言:一个绕不开的问题 在学习云原生技术的路上,几乎每个人都会遇到这样一个困惑: “有了 Kubernetes(…...

2026年想找口碑好的长沙瓷砖美缝?哪家专业这里给你答案!
装修是一件充满期待却又布满挑战的事情,而美缝作为装修收尾的关键一步,其重要性不言而喻。然而,许多业主在美缝过程中遭遇了各种困扰,究竟怎样才能找到一家专业靠谱的美缝团队呢?在长沙,长沙匠心徐师傅美缝…...