机器学习深度学习——Dropout
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——权重衰减
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
Dropout
- 重新审视过拟合
- 扰动的稳健性
- 实践中的Dropout
- 从零开始实现
- 定义模型参数
- 定义模型
- 训练和测试
- 简洁实现
- 小结
重新审视过拟合
当面对更多特征而样本不足时,线性模型常会过拟合。而如果给出更多的样本而不是特征,通常线性模型不会过拟合。但线性模型泛化的可靠性是有代价的:线性模型没有考虑到特征之间的交互作用。对每个特征,线性模型必须指定正的或负的权重,而忽略了其他的特征。这也是之前提出隐藏层的缘由。
泛化性和灵活性之间的这种基本权衡称为偏差-方差权衡。线性模型有很高的偏差:它们只能表示一小类函数。然而,这些模型的方差很低:它们在不同的随机数据样本上可以得出相似的结果。
深度神经网络就与线性模型不同,它处在偏差-方差谱的另一端,它不能查单独查看每个特征,而是学习特征之间的交互。但当我们有比特征多得多的样本时,深度神经网络也有可能会过拟合。
扰动的稳健性
我们期望的好的预测模型能在未知的数据上有很好的表现,为缩小训练与测试性能之间的差距,应该以简单模型为目标。简单性就是以较小维度的形式展现,之前验证过线性模型的单项式函数时就探讨过这一点了,此外,上一节的L2正则化-权重衰减时也看到了,参数的范数也代表了一种有用的简单性度量。
简单的另一个角度是平滑性,即函数不应该对其输入的微小变化敏感。例如,当我们对图像进行分类时,我们预计像像素添加一些随机噪声应该是基本无影响的。克里斯托弗·毕晓普证明了具有噪声的训练等价于Tikhonov正则化,不必管具体原理,咱只要知道正则化的作用就是为了权重衰减的,这证实了“要求函数光滑”和“要求函数对输入的随机噪声具有适应性”之间的联系。
因此提出了一个想法:在训练过程中,在计算后续层之前向网络的每一层注入噪声。因为当训练一个有多层的深层网络时,注入噪声只会在输入-输出映射上增强平滑性。
这个方法就称为dropout,dropout在前向传播过程中,计算每一内部层的同时注入噪声,已经成为训练神经网络的常用技术。这种方法在表面上看起来像是在训练过程中丢弃(drop out)一些神经元。标准暂退法就包括在计算下一层之前将当前层的一些结点置0。
关键在于,如何注入这些噪声。一种想法是以一种无偏向的方式注入噪声。这样在固定住其他层时,每一层的期望值都等于没有噪声时的值。
在标准暂退法正则化中,通过按保留(未丢弃)的节点的分数进行规范化来消除每一层的偏差。如下所示:
h ′ = { 0 ,概率为 p h 1 − p ,其他情况 h^{'}= \begin{cases} \begin{aligned} 0,概率为p\\ \frac{h}{1-p},其他情况 \end{aligned} \end{cases} h′=⎩ ⎨ ⎧0,概率为p1−ph,其他情况
显然,E[h’]=0*p+(1-p)*h/(1-p)=h
实践中的Dropout
对于一个带有1个隐藏层和5个隐藏单元的多层感知机:
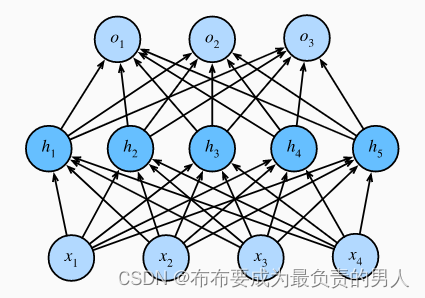
当我们将dropout应用到隐藏层,以p的概率将隐藏单元置0时,结果可以看作一个只包含神经元子集的网络,如:
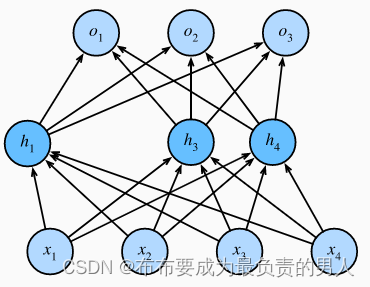
因此输出的计算不再依赖h2和h5,且它们各自的梯度在反向传播时也会消失。
我们在测试时会丢弃任何节点,不用dropout。
从零开始实现
要实现单层的dropout函数,我们从均匀分布U[0,1]中抽取样本,样本数与这层神经网络的维度一致。 然后我们保留那些对应样本大于p的节点,把剩下的丢弃。
在下面的代码中,我们实现 dropout_layer 函数, 该函数以dropout的概率丢弃张量输入X中的元素, 如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout。
import torch
from torch import nn
from d2l import torch as d2ldef dropout_layer(X, dropout):assert 0 <= dropout <= 1# 在本情况中,所有元素都被丢弃if dropout == 1:return torch.zeros_like(X)# 在本情况中,所有元素都被保留if dropout == 0:return Xmask = (torch.rand(X.shape) > dropout).float()return mask * X / (1.0 - dropout)
我们可以通过下面几个例子来测试dropout_layer函数。 我们将输入X通过暂退法操作,暂退概率分别为0、0.5和1。
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.))
运行结果:
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 1., 2., 3., 4., 5., 6., 7.],
[ 8., 9., 10., 11., 12., 13., 14., 15.]])
tensor([[ 0., 2., 0., 6., 0., 0., 0., 14.],
[16., 18., 20., 0., 0., 26., 28., 0.]])
tensor([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])
定义模型参数
同样,我们使用Fashion-MNIST数据集。我们定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元。
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
定义模型
我们可以将dropout应用于每个隐藏层的输出(在激活函数之后),并且可以为每一层分别设置dropout概率(常见的技巧是在靠近输入层的地方设置较低的暂退概率)。下面的模型将第一个和第二个隐藏层的暂退概率分别设置为0.2和0.5,并且dropout只在训练期间有效。
dropout1, dropout2 = 0.2, 0.5class Net(nn.Module):def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training=True):super(Net, self).__init__()self.num_inputs = num_inputsself.training = is_trainingself.lin1 = nn.Linear(num_inputs, num_hiddens1)self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)self.lin3 = nn.Linear(num_hiddens2, num_outputs)self.relu = nn.ReLU()def forward(self, X):H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))# 只有在训练模型时才使用dropoutif self.training == True:# 在第一个全连接层之后添加一个dropout层H1 = dropout_layer(H1, dropout1)H2 = self.relu(self.lin2(H1))if self.training == True:# 在第二个全连接层之后添加一个dropout层H2 = dropout_layer(H2, dropout2)out = self.lin3(H2)return outnet = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
训练和测试
这类似于前面描述的多层感知机训练和测试。
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
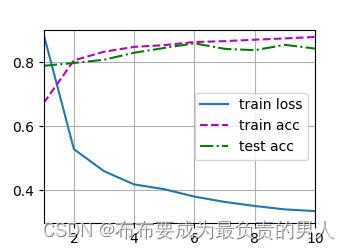
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
运行结果:
简洁实现
对于深度学习框架的高级API,我们只需在每个全连接层之后添加一个Dropout层,将暂退概率作为唯一的参数传递给它的构造函数。在训练时,Dropout层将根据指定的暂退概率随机丢弃上一层的输出。在测试时,Dropout层仅传递数据。
import torch
from torch import nn
from d2l import torch as d2lnum_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256dropout1, dropout2 = 0.2, 0.5net = nn.Sequential(nn.Flatten(),nn.Linear(784, 256),nn.ReLU(),# 在第一个全连接层之后添加一个dropout层nn.Dropout(dropout1),nn.Linear(256, 256),nn.ReLU(),# 在第二个全连接层之后添加一个dropout层nn.Dropout(dropout2),nn.Linear(256, 10))def init_weights(m):if type(m) == nn.Linear:nn.init.normal_(m.weight, std=0.01)net.apply(init_weights)num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
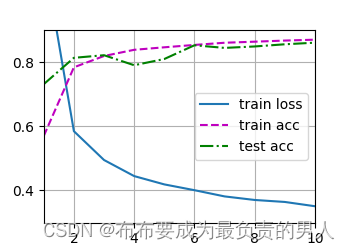
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
d2l.plt.show()
运行结果:
小结
1、dropout在前向传播过程中,计算每一内部层的同时丢弃一些神经元。
2、dropout可以避免过拟合,它通常与控制权重向量的维数和大小结合使用的。
3、dropout将活性值h替换为具有期望值h的随机变量。
4、dropout仅在训练期间使用。
相关文章:
机器学习深度学习——Dropout
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——权重衰减 📚订阅专栏:机器学习&&深度学习 希望文章对你们有所帮助 Drop…...

Intel和AMD 与 x86,ARM,MIPS有什么区别?
先说amd和intel amd和Intel这俩公司的渊源很深,早期时Intel先是自己搞了个x86架构,然后amd拿到了x86的授权也可以自己做x86了。接着intel向64位过渡的时候自己搞了个ia64(x64架构)但是因为和x86架构不兼容市场反应极差࿰…...

QT编写的串口助手
QT编写的串口助手 提前的知识 创建UI界面工程 找帮助文档 添加串口的宏...

C语言字符串的处理
用惯了Java C#这些语言,C语言中处理字符串还是有些不习惯的,所以这里写一下学习笔记。 C中字符串就是字符数组,是指向字符的指针,并且以空字符 \0 结尾,字符串作为函数的参数传递时一般使用指针类型,使用数…...
Docker 阿里云容器镜像服务
阿里云-容器镜像服务ACR 将本地/服务器docker image(镜像)推送到 阿里云容器镜像服务仓库 1. 在容器镜像服务ACR中创建个人实例 2. 进入个人实例 > 命名空间 创建命名空间 3. 进入个人实例 > 镜像仓库 创建镜像仓库 4. 进入镜像仓库 > 基本信…...


【雕爷学编程】MicroPython动手做(20)——掌控板之三轴加速度6
知识点:什么是掌控板? 掌控板是一块普及STEAM创客教育、人工智能教育、机器人编程教育的开源智能硬件。它集成ESP-32高性能双核芯片,支持WiFi和蓝牙双模通信,可作为物联网节点,实现物联网应用。同时掌控板上集成了OLED…...
链路 聚合
静态链路聚合:多数内网使用 。非物理直连建议与BFD联动 动态链路聚合LACP:是公有协议、内网、二层专线接口都能使用,现网多数使用此方式链路 聚合 PAGP:思科私有协议,只支持思科设备使,现网多数不用...
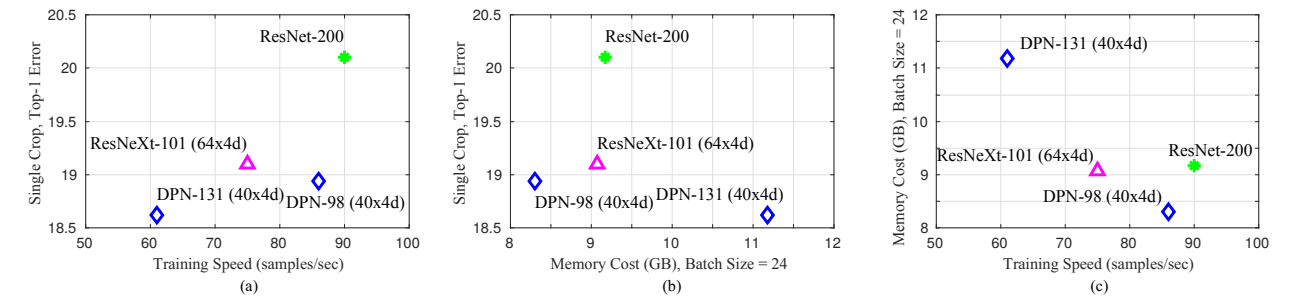
DPN(Dual Path Network)网络结构详解
论文:Dual Path Networks 论文链接:https://arxiv.org/abs/1707.01629 代码:https://github.com/cypw/DPNs MXNet框架下可训练模型的DPN代码:https://github.com/miraclewkf/DPN 我们知道ResNet,ResNeXt,D…...

【转载】Gin框架优雅退出
转载自: https://juejin.cn/post/7212786062224146487 Gin是一个非常流行的Web框架,经常被用于构建高性能、易于维护的Web应用。在领域驱动设计(DDD)和微服务等方面也有广泛应用。但是,像其他应用程序一样,…...
【数字IC设计】VCS仿真DesignWare IP
DesignWare介绍 DesignWare是SoC/ASIC设计者最钟爱的设计IP库和验证IP库。它包括一个独立于工艺的、经验证的、可综合的虚拟微架构的元件集合,包括逻辑、算术、存储和专用元件系列,超过140个模块。DesignWare和 Design Compiler的结合可以极大地改进综合…...

【*1900 图论+枚举思想】CF1328 E
Problem - E - Codeforces 题意: 思路: 注意到题目的性质:满足条件的路径个数是极少的,因为每个点离路径的距离<1 先考虑一条链,那么直接就选最深那个点作为端点即可 为什么,因为我们需要遍历所有点…...
10.5-通信管理模块)
AutoSAR系列讲解(实践篇)10.5-通信管理模块
目录 一、ComM 1、内部唤醒 2、外部唤醒 二、CanSM 三、状态关联 之前讲解了BswM和EcuM,详细讲解了BswM的配置,而大部分的配置都在BswM中做了,EcuM的配置就很简单了,基本上勾一勾就ok了。下面我们 来讲解模式管理还可能用到的通信模块 一、ComM ComM就像一个通信的总…...
)
2023.7.30(epoll实现并发服务器)
服务器 #include <arpa/inet.h> #include <netinet/in.h> #include <netinet/ip.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <sys/epoll.h> #include <sys/socket.h> #include <sys/types.…...
)
小研究 - 基于解析树的 Java Web 灰盒模糊测试(一)
由于 Java Web 应用业务场景复杂, 且对输入数据的结构有效性要求较高, 现有的测试方法和工具在测试Java Web 时存在测试用例的有效率较低的问题. 为了解决上述问题, 本文提出了基于解析树的 Java Web 应用灰盒模糊测试方法. 首先为 Java Web 应用程序的输入数据包进行语法建模创…...
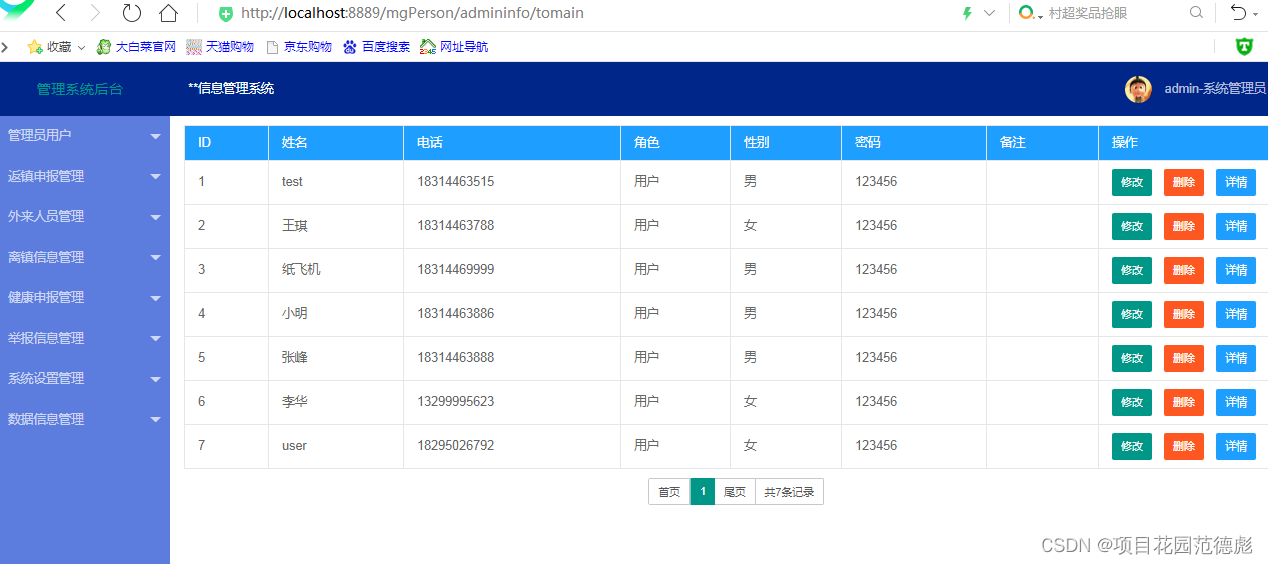
SpringBoot接手JSP项目--【JSB项目实战】
SpringBoot系列文章目录 SpringBoot知识范围-学习步骤【JSB系列之000】 文章目录 SpringBoot系列文章目录[TOC](文章目录) SpringBoot技术很多很多工作之初,面临JSP的老项目我要怎么办环境及工具:项目里可能要用到的技术JSPjstl其它的必要知识 上代码WE…...
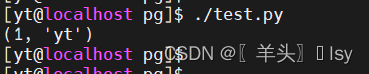
Python模块psycopg2连接postgresql
目录 1. 基础语法 2. 基础用法 3. 多条SQL 4. 事务SQL 1. 基础语法 语法 psycopg2.connect(dsn #指定连接参数。可以使用参数形式或 DSN 形式指定。host #指定连接数据库的主机名。dbname #指定数据库名。user #指定连接数据库使用的用户名。…...

Kotlin基础(八):泛型
前言 本文主要讲解kotlin泛型,主要包括泛型基础,类型变异,类型投射,星号投射,泛型函数,泛型约束,泛型在Android中的使用。 Kotlin文章列表 Kotlin文章列表: 点击此处跳转查看 目录 1.1 泛型基…...
环境变量path配置及其作用)
Java学习笔记——(10)环境变量path配置及其作用
环境变量的作用为了在 Dos 的任务目录,可以去使用 javac 和 java开发工具命令 先配置 JAVA_HOME 指向 jdk 安装的主目录(避免开发中出现问题) 编辑 path 环境变量(开发环境),增加 %JAVA_HOME%\bin 编辑 path 环境变量(运行环境…...
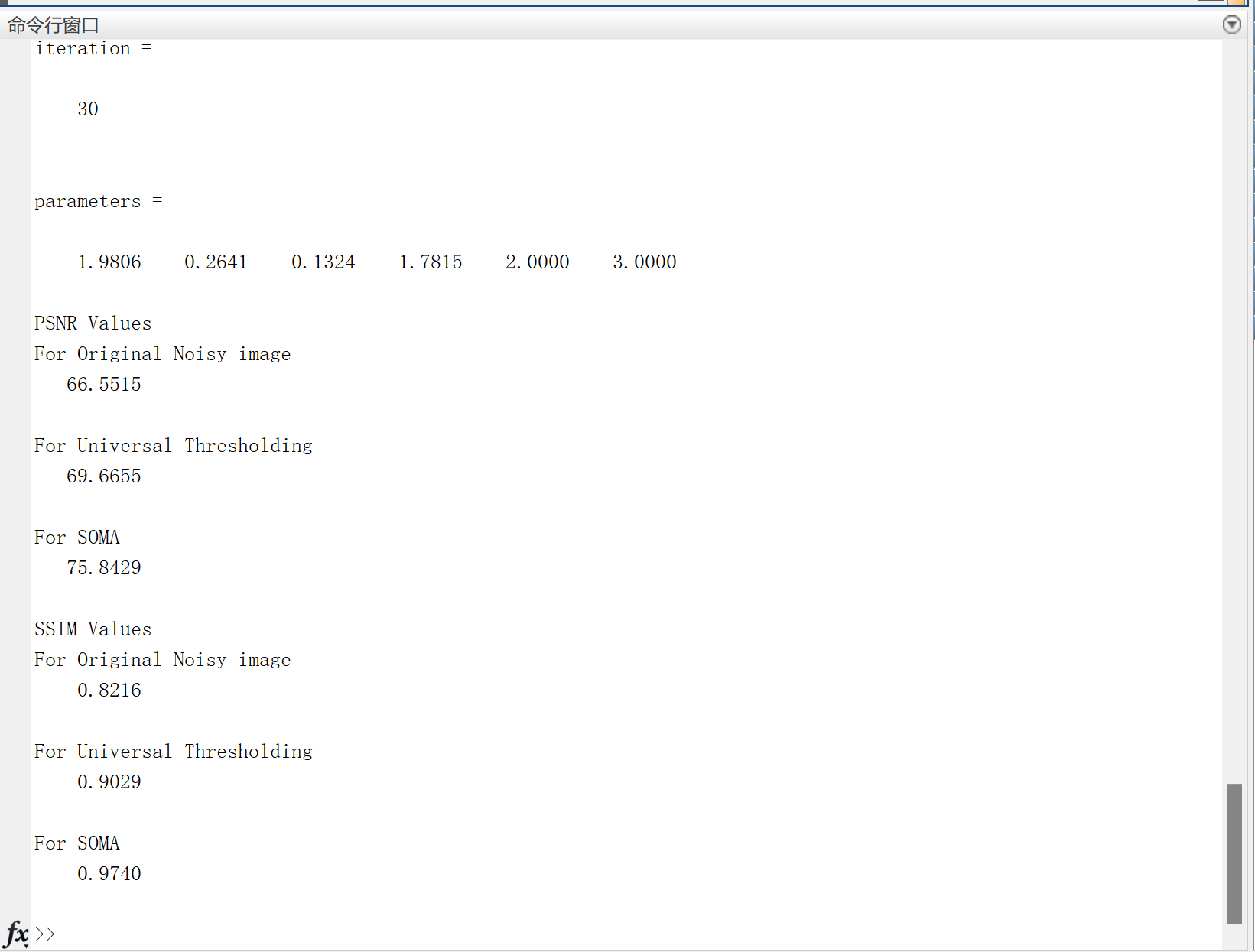
【图像去噪】基于进化算法——自组织迁移算法(SOMA)的图像去噪研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

生成式AI技术债:五大高发区与系统级防御实战
1. 项目概述:当生成式AI跑得比工程实践快时,技术债就不是“欠着”,而是“滚着”我带过三支不同行业的AI落地团队,从金融风控到智能客服再到工业质检,最近两年最常听到的不是“模型效果怎么样”,而是“这周又…...

129、运动控制中的软件架构:分层设计
运动控制中的软件架构:分层设计 从一次半夜的电机啸叫说起 凌晨两点,车间里只剩示波器的荧光。我盯着那根诡异的电流波形——电机在低速运行时发出刺耳的啸叫,像指甲划过黑板。PID参数调了无数遍,滤波器换了好几种,问题依旧。直到我打开同事留下的代码,发现他把电流环、…...

茉莉花插件:Zotero中文文献管理的终极解决方案,5分钟打造高效科研工作流
茉莉花插件:Zotero中文文献管理的终极解决方案,5分钟打造高效科研工作流 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/…...

Wireshark抓包提取NTLMv2 Hash实战指南
1. 这不是“黑客演示”,而是一次内网安全加固前的必做体检你有没有遇到过这样的情况:某天突然收到告警,说域控日志里出现了大量异常的NTLM认证失败记录;或者渗透测试报告里赫然写着“存在明文凭据泄露风险”,但你翻遍所…...

如何做好费用率数据分析?巧用费用率研判企业盈利现状
企业经营发展过程中,盈利水平高低直接决定长远发展实力,而费用率数据是看透企业真实盈利水平最直观、最核心的指标。很多经营者在日常管理中,往往只看重账面营收的增长,却忽略了费用率数据的深层分析与解读,最终出现营…...

数据结构——带懒标记的线段树
一、什么是线段树?线段树是一种二叉树数据结构,用于高效地处理区间查询和区间更新操作。核心思想:将数组分成若干个区间(线段),每个节点代表一个区间,通过合并子节点的信息来得到父节点的信息。…...
 1. Q-learning的遗憾界分析-高效的Q-learning算法)
(二) 1. Q-learning的遗憾界分析-高效的Q-learning算法
高效的Q-learning算法 1.1. 无模型算法 1.2. UCB算法 1.3. 文献回顾 无模型(Model-free)强化学习算法(如 Q-learning)无需显式地对环境进行建模,而是直接对价值函数或策略进行参数化和更新。与基于模型(Model-based)的方法相比,这类算法通常更简单、更灵活,因此在现代…...

从官方demo到真实项目:手把手教你定制uniapp uni-card卡片的样式与交互
从官方demo到真实项目:手把手教你定制uniapp uni-card卡片的样式与交互 在移动应用开发中,卡片式设计已经成为展示内容的黄金标准。uni-app的uni-card组件为开发者提供了一个快速构建卡片式界面的基础工具,但实际项目中,我们往往需…...

Go语言DDD实战:领域驱动设计
Go语言DDD实战:领域驱动设计 1. DDD分层 type UserService struct {repo UserRepository }func (s *UserService) CreateUser(cmd *CreateUserCommand) error {// 领域逻辑 }2. 总结 DDD通过统一语言和限界上下文实现复杂业务系统的有效建模。...

影刀RPA 企业级专题篇:多租户自动化平台与账号环境隔离设计
影刀RPA 企业级专题篇:多租户自动化平台与账号环境隔离设计 作者:林焱 很多自动化系统前期。 其实都默认只有一个“使用方”。 几个流程。 几台执行机。 统一浏览器环境。 前期问题不大。 但真正进入企业级阶段以后。 系统会逐渐出现࿱…...