<C++> 入门
在学习完C语言的基础上,继续开始C++的学习。
C++是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式等。熟悉C语言之后,对C++学习有一定的帮助。
1. 补充C语言语法的不足,以及C++是如何对C语言设计不合理的地方进行优化的,比如:作用域方面、IO方面、函数方面、指针方面、宏方面等。
2. 为后续类和对象学习打基础。
C++兼容C语言语法
C++是向后兼容C语言的,这意味着几乎所有合法的C代码也可以在C++中编译和运行。C++最初是作为C的一个超集而设计的,因此C++保留了C语言的大部分特性和语法,同时引入了一些新的特性。
示例:
#include <iostream>
using namespace std;
int main(){cout << "hello world" << endl; //hello worldprintf("hello world\n"); //hello worldreturn 0;
}
但是并非百分百兼容。这意味着,许多合法的C代码在C++中也是有效的,并且可以在C++中编译和运行,但也有一些情况下C和C++之间存在不同之处,可能需要进行一些修改才能正常工作。
1.C++关键字
// C++ 关键字列表// 基本类型关键字
bool char int float double void
short long signed unsigned// 控制流关键字
if else switch case default
while do for break continue
return goto// 函数相关关键字
typedef constexpr static_cast dynamic_cast reinterpret_cast
const_cast sizeof typeid noexcept operator
new delete this virtual override
final template typename using try
catch// 类、对象和访问控制关键字
class struct union enum private protected
public friend virtual explicit mutable constexpr// 命名空间关键字
namespace using// 异常处理关键字
throw try catch// 杂项关键字
asm auto register volatile// C++11及以后新增关键字
nullptr enum class static_assert alignas alignof
decltype noexcept constexpr thread_local// C++11以后引入的一些预处理器命令
static_assert alignof alignas __has_include __has_cpp_attribute// C++17及以后新增关键字
inline if constexpr namespace// C++20及以后新增关键字
concept requires// C++20引入的模块化关键字
import module export// C++23中引入的预处理器关键字
__VA_OPT__
2.命名空间
C++中的命名空间是一种用于组织代码的机制,可以将全局作用域内的标识符(例如变量、函数、类等)封装在一个逻辑组中,从而防止名称冲突和提供更好的代码组织结构。
为什么设计命名空间?
命名空间的设计是为了解决代码组织和名称冲突问题。在大型软件项目中,可能有数以千计的函数、变量和类等。如果没有命名空间,所有这些标识符都将位于全局作用域中,很容易导致名称冲突和混乱的代码结构。
示例:
#include <stdio.h>
#include <stdlib.h>
int rand = 10; // C语言没办法解决类似这样的命名冲突问题,所以C++提出了namespace来解决
int main(){printf("%d\n", rand);return 0;
}
// 编译后后报错:error C2365: “rand”: 重定义;以前的定义是“函数”
上述代码的rand变量为C语言stdlib里面的函数名,不能定义。C语言没办法解决类似这样的命名冲突问题,所以C++提出了命名空间来解决

2.1 域作用符::
域:全局域和局部域
int a = 2;void f1(){int a = 0;printf("%d\n", a); //0printf("%d\n",::a); // 2 ::域作用限定符,表示全局域
}int main(){printf("%d\n", a); //2f1();return 0;
}
域作用符::还可以用于访问命名空间、类、结构体、枚举和全局变量等作用域内的成员。
2.2 命名空间的定义
namespace MyNamespace {// 声明或定义一些变量、函数、类等
}
示例:
// phw是命名空间的名字,一般开发中是用项目名字做命名空间名。
//1. 正常的命名空间定义
namespace phw{// 命名空间中可以定义变量/函数/类型int rand = 10;int Add(int left, int right){return left + right;}struct Node{struct Node* next;int val;};
}//2. 命名空间可以嵌套
// test.cpp
namespace N1{int a;int b;int Add(int left, int right){return left + right;}namespace N2{int c;int d;int Sub(int left, int right){return left - right;}}
}//3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
//ps:一个工程中的test.h和上面test.cpp中两个N1会被合并成一个
// test.h
namespace N1{int Mul(int left, int right){return left * right;}
}
注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
2.3 命名空间的使用
#include<iostream>
namespace phw {// 命名空间中可以定义变量/函数/类型int a = 0;int b = 1;int Add(int left, int right) {return left + right;}struct Node {struct Node *next;int val;};
}// namespace phwint main() {printf("%d\n", a);return 0;
}
编译报错:error C2065: “a”: 未声明的标识符,没有引入命名空间
命名空间的使用有三种方式:
-
加命名空间名称及作用域限定符
int main(){printf("%d\n", phw::a);return 0; } -
使用using将命名空间中某个成员引入
using phw::b; int main(){printf("%d\n", phw::a);printf("%d\n", b);return 0; } -
使用using namespace 命名空间名称引入
using namespce phw;
int main(){printf("%d\n", N::a);printf("%d\n", b);Add(10, 20);return 0;
}
using namespace全局展开,一般情况,不建议全局展开。
实际开发的项目工厂,我们将常用部分展开即可,小的程序,日常练习,不太会发现冲突,就可以使用全局展开。
例如:
#include <iostream>
//using namespace std;
//常用展开
using std::cout;
using std::endl;int main() {cout << "1111" << endl;cout << "1111" << endl;cout << "1111" << endl;cout << "1111" << endl;int i = 0;std::cin >> i;return 0;
}
3.C++输入&输出
在C++中,输入和输出是通过标准库提供的输入输出流(iostream)来完成的。标准库中定义了两个主要的流对象:cin用于输入(console input),cout用于输出(console output)。它们分别对应于标准输入和标准输出。
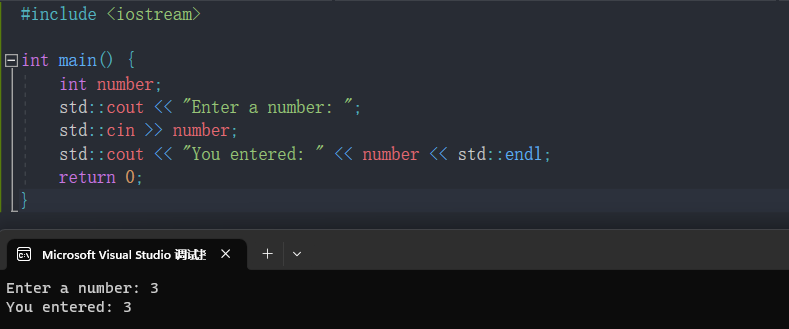
示例:
#include <iostream>int main() {int number;std::cout << "Enter a number: ";std::cin >> number;std::cout << "You entered: " << number << std::endl;return 0;
}
在上面的例子中,std::cin >> number;语句将用户输入的数据读取到number变量中。
cout和cin都是可以自动识别变量类型的
例如:
#include <iostream>
using namespace std;int main() {char name[10] = "张三";int age = 18;//...cout << "姓名:" << name << endl;cout << "年龄:" << age << endl;printf("姓名:%s\n年龄:%d\n", name, age);return 0;
}
输出结果:
姓名:张三
年龄:18
姓名:张三
年龄:18
endl和"\n"的区别:
std::endl是一个特殊的操纵符,用于插入一个换行符并刷新输出缓冲区。"\n"是换行符的转义序列,但它不会刷新输出缓冲区。
#include <iostream>int main() {std::cout << "Hello" << std::endl; // 输出 "Hello" 并换行std::cout << "World\n"; // 输出 "World" 并换行(但不刷新输出缓冲区)return 0;
}
除了cin和cout,标准库还提供了其他输入输出流,如cerr(用于输出错误消息)和clog(用于输出程序运行时的日志信息)。它们的用法与cin和cout类似,但有一些细微的差异。
#include <iostream>int main() {std::cerr << "This is an error message." << std::endl;std::clog << "This is a log message." << std::endl;return 0;
}
注意:
关于cout和cin还有很多更复杂的用法,比如控制浮点数输出精度,控制整形输出进制格式等等。但是C++兼容C语言语法,控制浮点数输出精度,控制整形输出进制格式使用cout比较麻烦,推荐使用C语言的printf函数和scanf函数。
4.缺省参数
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实 参则采用该形参的缺省值,否则使用指定的实参。
示例:
#include <iostream>
using namespace std;//形参a是一个缺省值
void Func(int a = 0) {cout << a << endl;
}int main() {Func(1); Func(); return 0;
}
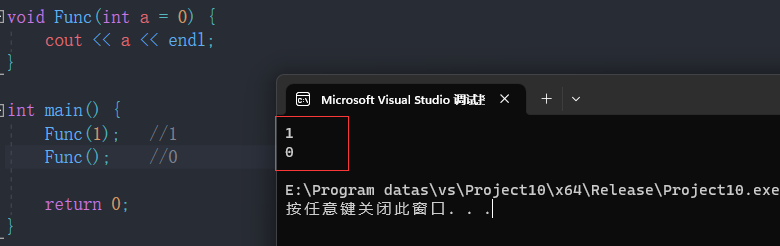
当Func函数没有传参时,使用参数的默认值0,而传参时,使用指定的实参
4.1 缺省参数的分类
分为全缺省和半缺省
- 全缺省参数
示例:
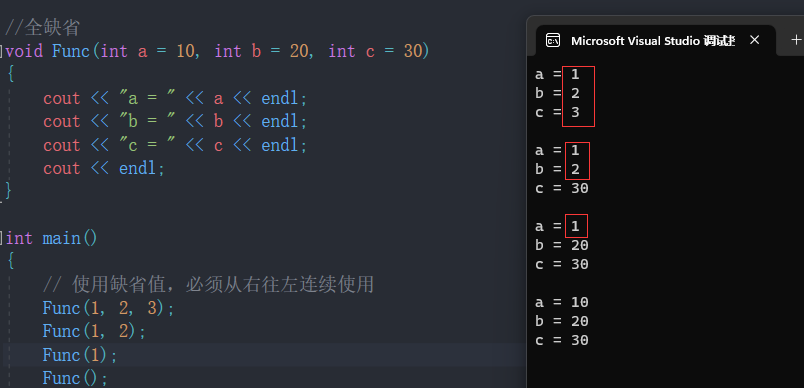
#include <iostream>
using namespace std;//全缺省
void Func(int a = 10, int b = 20, int c = 30)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;cout << endl;
}int main()
{// 使用缺省值,必须从右往左连续使用Func(1, 2, 3);Func(1, 2);Func(1);Func();return 0;
}
- 半缺省参数
示例1:
#include <iostream>
using namespace std;// 半缺省
// 必须从右往左连续缺省
void Func(int a, int b = 10, int c = 20)
{cout << "a = " << a << endl;cout << "b = " << b << endl;cout << "c = " << c << endl;cout << endl;
}int main()
{// 使用缺省值,必须从右往左连续使用Func(1, 2, 3);Func(1, 2);Func(1);return 0;
}
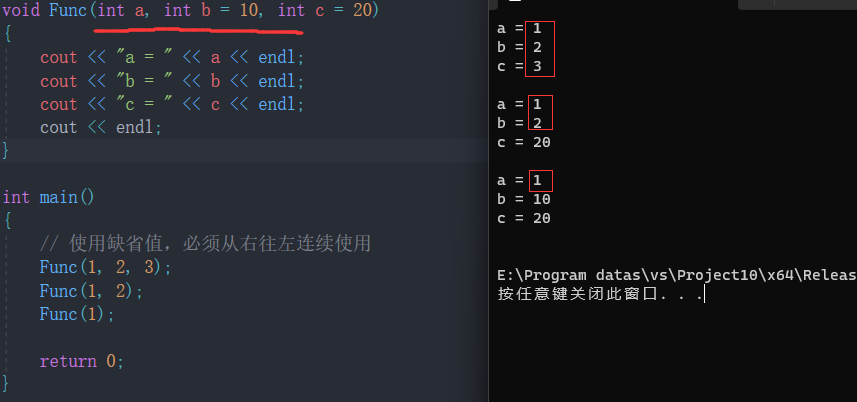
示例2:
#include <iostream>
using namespace std;struct Stack {int *a;int top;int capacity;
};
//defaultCapacity缺省参数
void StackInit(struct Stack *ps, int defaultCapacity = 4) {ps->a = (int *) malloc(sizeof(int) * defaultCapacity);if (ps->a == NULL) {perror("malloc fail");exit(-1);}ps->top = 0;ps->capacity = defaultCapacity;
}int main() {Stack st1;// 最多要存100个数StackInit(&st1, 100);Stack st2;// 不知道多少数据,不传size,默认就是缺省参数的值4StackInit(&st2);return 0;
}
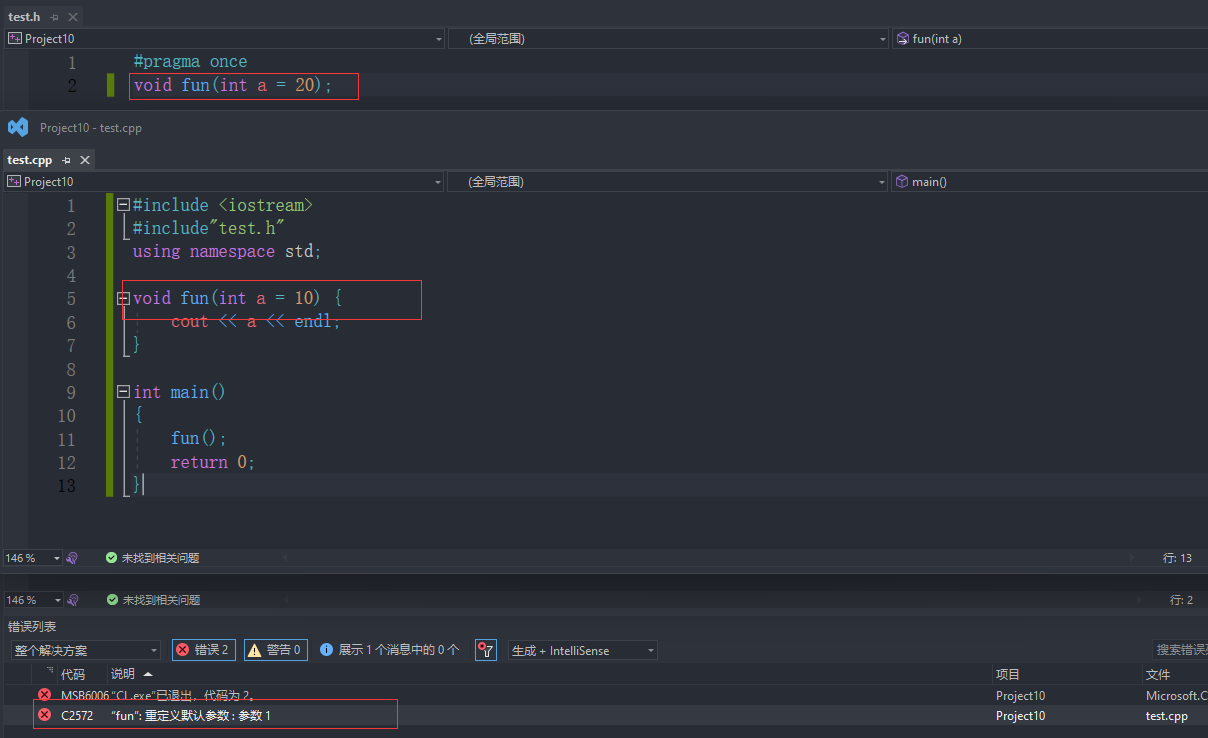
注意:
半缺省参数必须从右往左依次来给出,不能间隔着给
缺省参数不能在函数声明和定义中同时出现
例如:
- 缺省值必须是常量或者全局变量
5.函数重载
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这 些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
函数重载的条件:
为了成功重载一个函数,函数重载必须满足以下条件:
- 函数名称相同。
- 函数位于同一作用域内。
- 参数列表不同,包括参数的类型、数量或顺序不同。
示例1:
#include <iostream>
using namespace std;
// 1、参数类型不同
int Add(int left, int right) {cout << "int Add(int left, int right)" << endl;return left + right;
}double Add(double left, double right) {cout << "double Add(double left, double right)" << endl;return left + right;
}void f() {cout << "f()" << endl;
}void f(int a) {cout << "f(int a)" << endl;
}// 3、参数类型顺序不同
void f(int a, char b) {cout << "f(int a,char b)" << endl;
}void f(char b, int a) {cout << "f(char b, int a)" << endl;
}int main() {Add(10, 20); //int Add(int left, int right)Add(10.1, 20.2);//double Add(double left, double right)f(); //f()f(10); //f(int a)f(10, 'a'); //f(int a,char b)f('a', 10); //f(char b, int a)return 0;
}
5.1 C++支持函数重载的原理name mangling
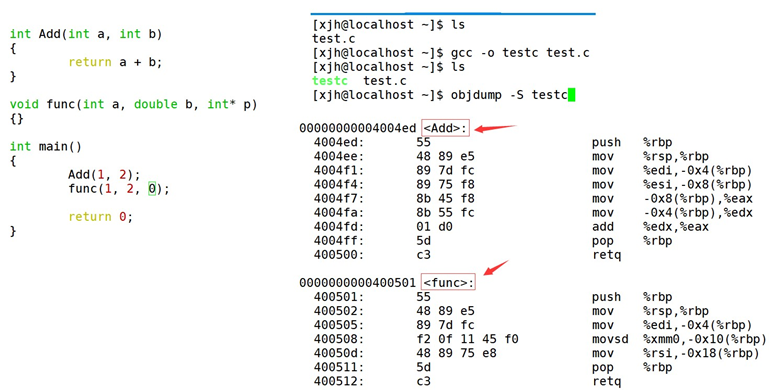
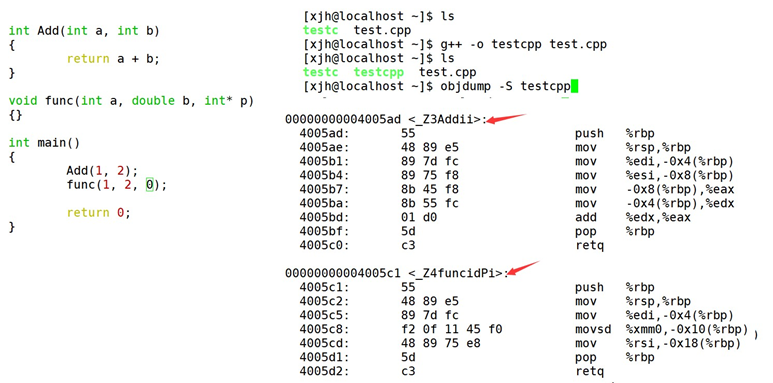
C++支持函数重载的原理是基于编译器的 name mangling 技术,这是一种将函数名和其参数类型组合起来生成唯一标识符的方法,用来区分不同的同名函数。例如,如果有两个函数都叫func ,但是一个参数是int ,另一个参数是double ,那么编译器会将它们的名字改为类似 _Z4funci 和 _Z4funcd 的形式,这样就可以在链接时正确地找到对应的函数。不同的编译器可能有不同的 name mangling 规则,但是原理都是一样的。
通过下面我们可以看出gcc的函数修饰后名字不变。而g++的函数修饰后变成【_Z+函数长度 +函数名+类型首字母】。
采用gcc编译器的结果:
采用g++编译的结果:
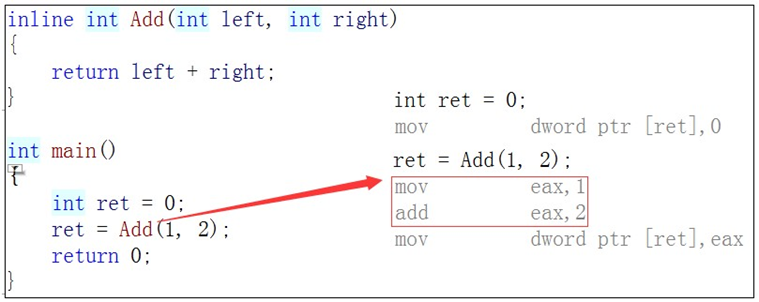
6.内联函数
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
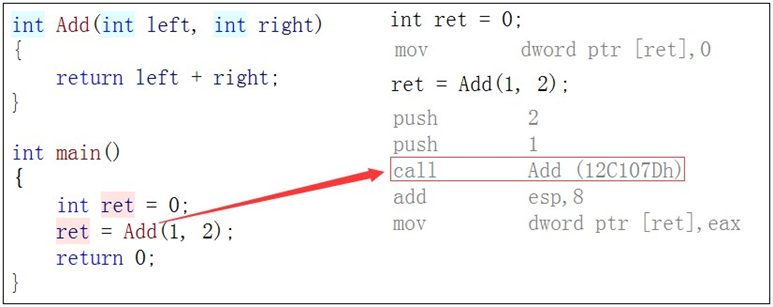
如果在上述函数前增加inline关键字将其改成内联函数,在编译期间编译器会用函数体替换函数的调用。
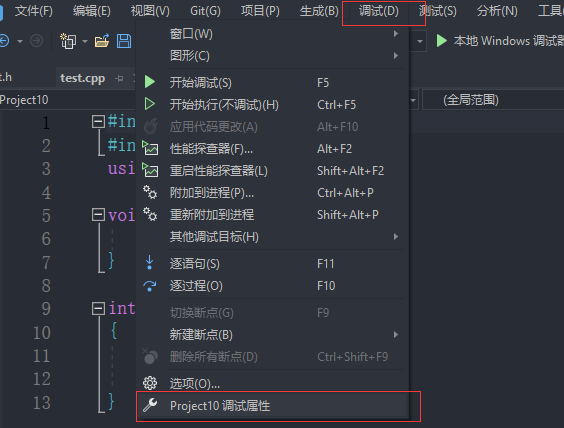
查看方式:
1.在release模式下,查看编译器生成的汇编代码中是否存在call Add
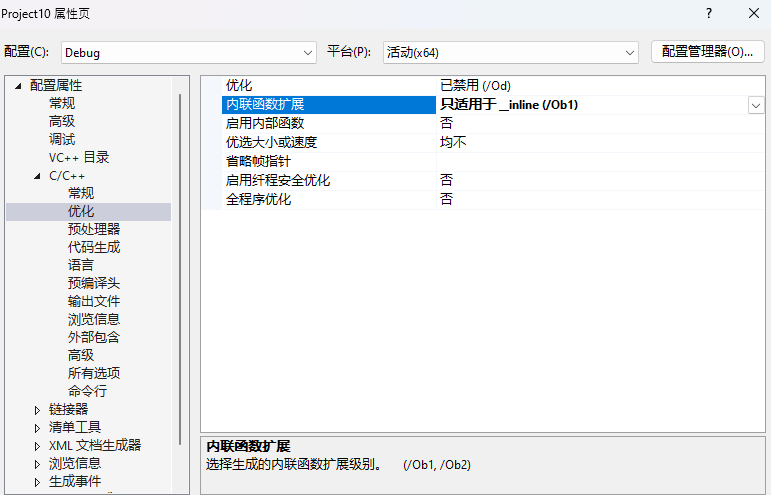
2.在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,以下给出vs2022的设置方式)
6.1 内联函数的特性
-
inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。 -
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。 -
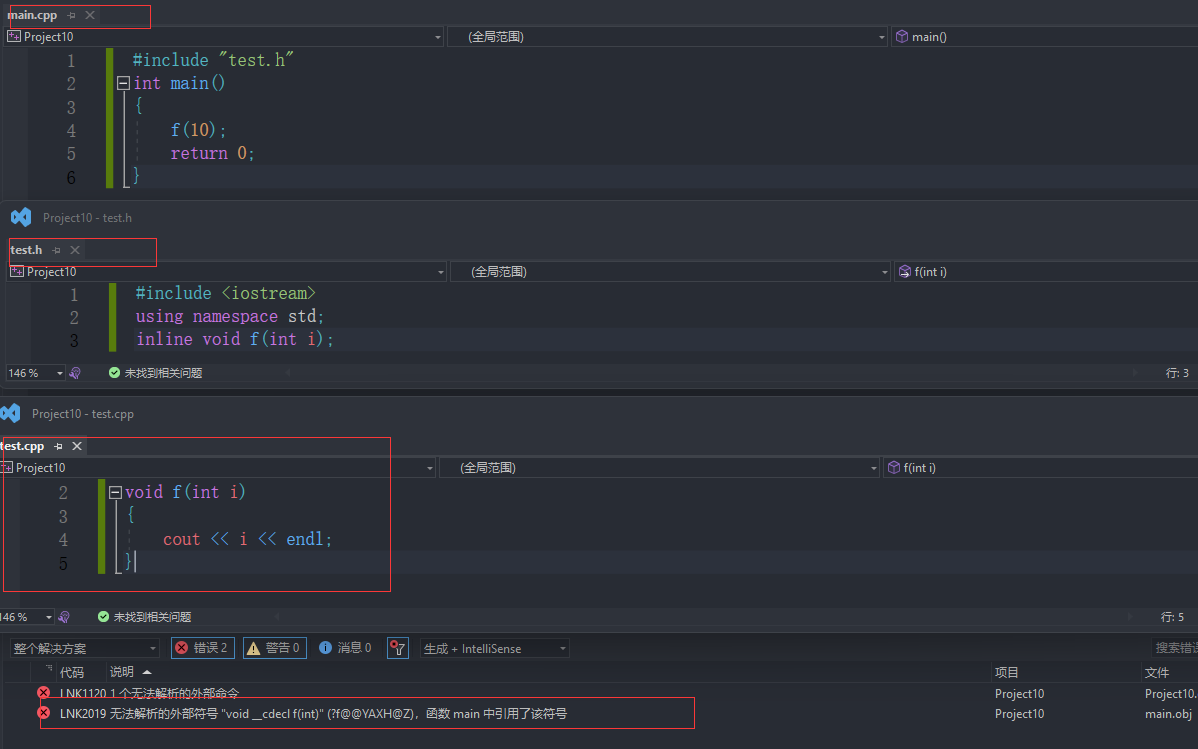
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到 -
内联函数的定义通常放在头文件中。这是因为当函数被调用时,编译器需要能够在调用处内联展开函数的代码,而函数定义必须对编译器可见。如果函数定义放在源文件中,其他文件调用时将无法内联展开。
6.2 C语言宏的缺点
优点:
1.增强代码的复用性。
2.提高性能。
缺点:
1.不方便调试宏。(因为预编译阶段进行了替换)
2.导致代码可读性差,可维护性差,容易误用。
3.没有类型安全的检查 。
C++有哪些技术替代宏?
const和enum替代宏常量inline去替代宏函数
使用宏:
#define ADD(x, y) x + y;
#define ADD(x, y) (x + y)
#define ADD(x, y) (x) + (y)
#define ADD(x, y) ((x) + (y));#define ADD(x, y) ((x) + (y))
#define ADD(x, y) (x + y)
#define ADD(x, y) (x) + (y)
#define ADD(x, y) x + yint main() {ADD(1, 2) * 3;// ((1)+(2))*3;int a = 1, b = 2;ADD(a | b, a & b);// ((a | b) + (a & b));;return 0;
}
使用inline代替
inline int Add(int x, int y) {int z = x + y;z = x + y;z += x + y;//z = x + y;//z = x + y;//z = x * y;//z = x + y;//z += x + y;//z -= x + y;//z += x + y;//z += x * y;//z -= x / y;//z += x + y;//z += x + y;return z;
}int main() {int ret = Add(1, 2);cout << ret << endl;return 0;
}
相关文章:
<C++> 入门
在学习完C语言的基础上,继续开始C的学习。 C是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式等。熟悉C语言之后,对C学习有一定的帮助。 1. 补充C语言语法的不足,以及C是如…...

政策加持智能家居市场,涂鸦赋能客户打造“以人为本”智能生活新方式
7月18日,商务部等13部门联合发布了《关于促进家居消费若干措施的通知》(以下简称《通知》),《通知》指出,创新培育智能消费,支持企业运用物联网、云计算、人工智能等技术,着重加快智能家电、智能…...

安全渗透初级知识总结-2
CIA三原则:保密性,完整性,可用性 https:解决了安全传输问题 核心技术:用非对称加密传输对称加密的秘钥,然后用对称秘钥通信 抓包:Wireshark、tshark、tcpdump valueof方法是一个所有对象都拥有的方法&am…...

数学建模的32种常规方法及案例代码
比赛期间整理的数学建模的32种常规方法及案例代码友情分享: 链接:https://pan.baidu.com/s/18uDr1113a0jhd2No8O1Nog 提取码:xae5 在数学建模中,常规算法是指那些被广泛应用于各种问题求解的经典算法。这些算法覆盖了不同的数学…...
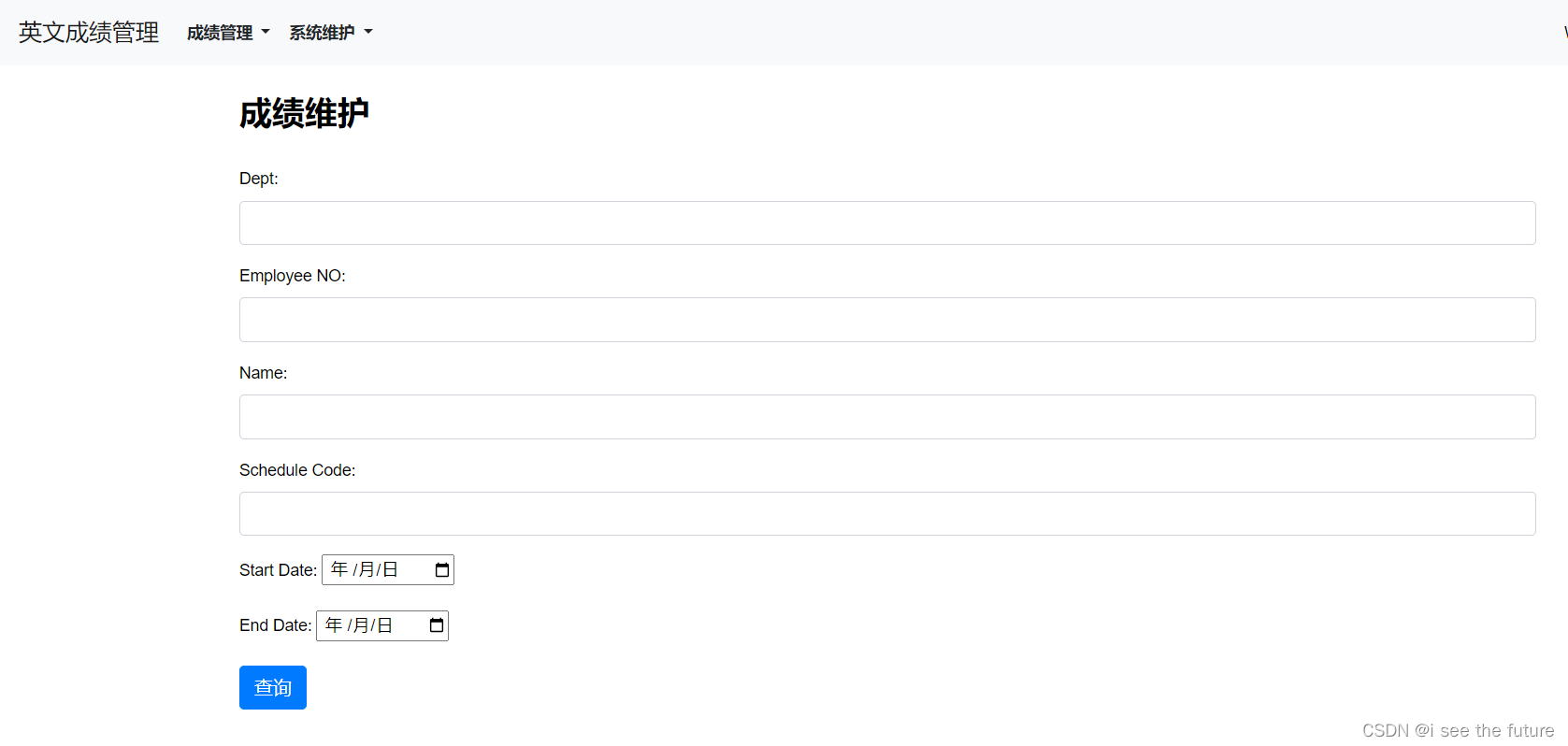
【Django+Vue】英文成绩管理平台--20230727
能够满足大部分核心需求(标绿):报表部分应该比较难。 项目地址 前端编译 https://gitlab.com/m7840/toeic_vue_dist Vue源码 https://gitlab.com/m7840/toeic_vue Django源码 https://gitlab.com/m7840/toeic_python 项目架构 流程 …...

栈-模拟栈
实现一个栈,栈初始为空,支持四种操作: push x – 向栈顶插入一个数 x; pop – 从栈顶弹出一个数; empty – 判断栈是否为空; query – 查询栈顶元素。 现在要对栈进行 M 个操作,其中的每个…...

图观| 从王宝强、费翔、阿汤哥等新上映的电影聊聊图的智能推荐场景
从技术的视角来看,推荐系统本质上是在用户需求不明确的情况下,从海量的信息中为用户过滤出他可能感兴趣的信息的一种技术手段。 我们日常接触到的智能推荐有: 电商网站:如淘宝、天猫、京东、Amazon…… 生活服务:如美…...
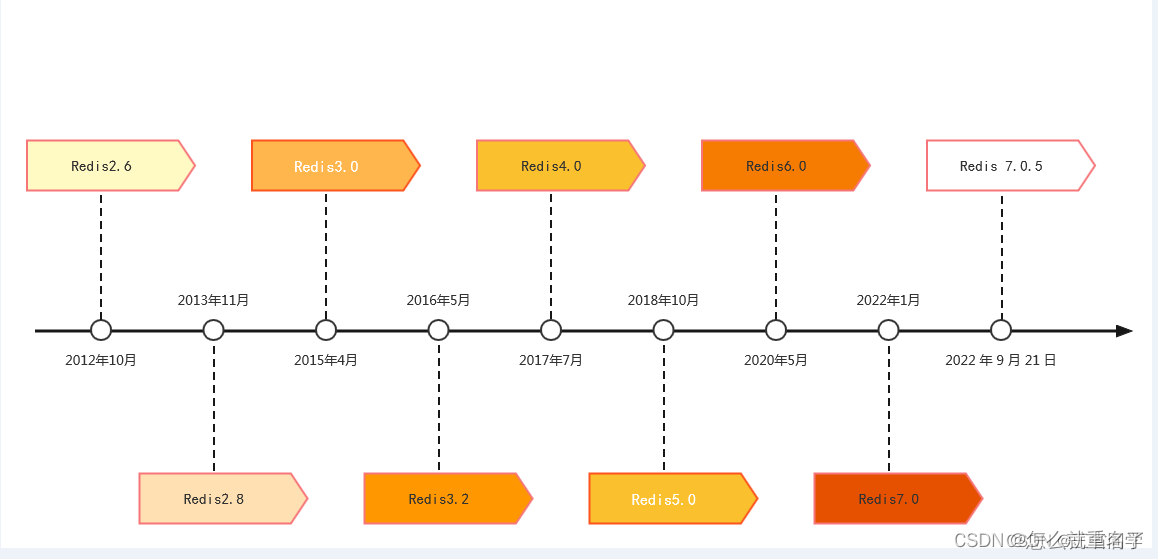
Redis系列一:介绍
介绍 The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker. 相关资源 Redis 官网:https://redis.io/ 源码地址:https://github.com/redis/redis Redis 在线测试&#…...

Java 设计模式 - 单例模式 - 保证类只有一个实例
单例模式 - 保证类只有一个实例 为什么使用单例模式?单例模式的实现方式1. 饿汉式(Eager Initialization)2. 懒汉式(Lazy Initialization)3. 双重检查锁(Double-Checked Locking)4. 静态内部类&…...

第2章 JavaScript语法
准备工作 编写js需要准备一个编译器和游览器,js必须通过HTML/XHTML文档编写 js的编写位置 <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Docume…...

【Golang】Golang进阶系列教程--为什么 Go for-range 的 value 值地址每次都一样?
文章目录 前言现象无限循环相同地址 原因推荐阅读 前言 循环语句是一种常用的控制结构,在 Go 语言中,除了 for 关键字以外,还有一个 range 关键字,可以使用 for-range 循环迭代数组、切片、字符串、map 和 channel 这些数据类型。…...
)
小研究 - JVM 垃圾回收方式性能研究(三)
本文从几种JVM垃圾回收方式及原理出发,研究了在 SPEC jbb2015基准测试中不同垃圾回收方式对于JVM 性能的影响,并通过最终测试数据对比,给出了不同应用场景下如何选择垃圾回收策略的方法。 目录 4 垃圾回收器性能比较 4.1 测试结果 5 结语 …...

java根据poi解析excel内容
一.HSSFWorkbook、XSSFWorkbook、SXSSFWorkbook Apache POI包中的HSSFWorkbook、XSSFWorkbook、SXSSFWorkbook的区别如下: HSSFWorkbook:一般用于操作Excel2003以前(包括2003)的版本,扩展名是.xls。 XSSFWorkbook:一…...

实验报告-Sublime配置默认语法,以配置Verilog语法为例
实验报告-Sublime配置默认语法,以配置Verilog语法为例 1,下载Verilog语法环境2,Sublime配置语法工作环境,以Verilog语法环境为例。3,打开一个新的Sublime,验证编辑器配置Verilog为默认语法成功!4,Sublime汉化1,下载Verilog语法环境 参考文献: 1,Sublime Text 4加载…...
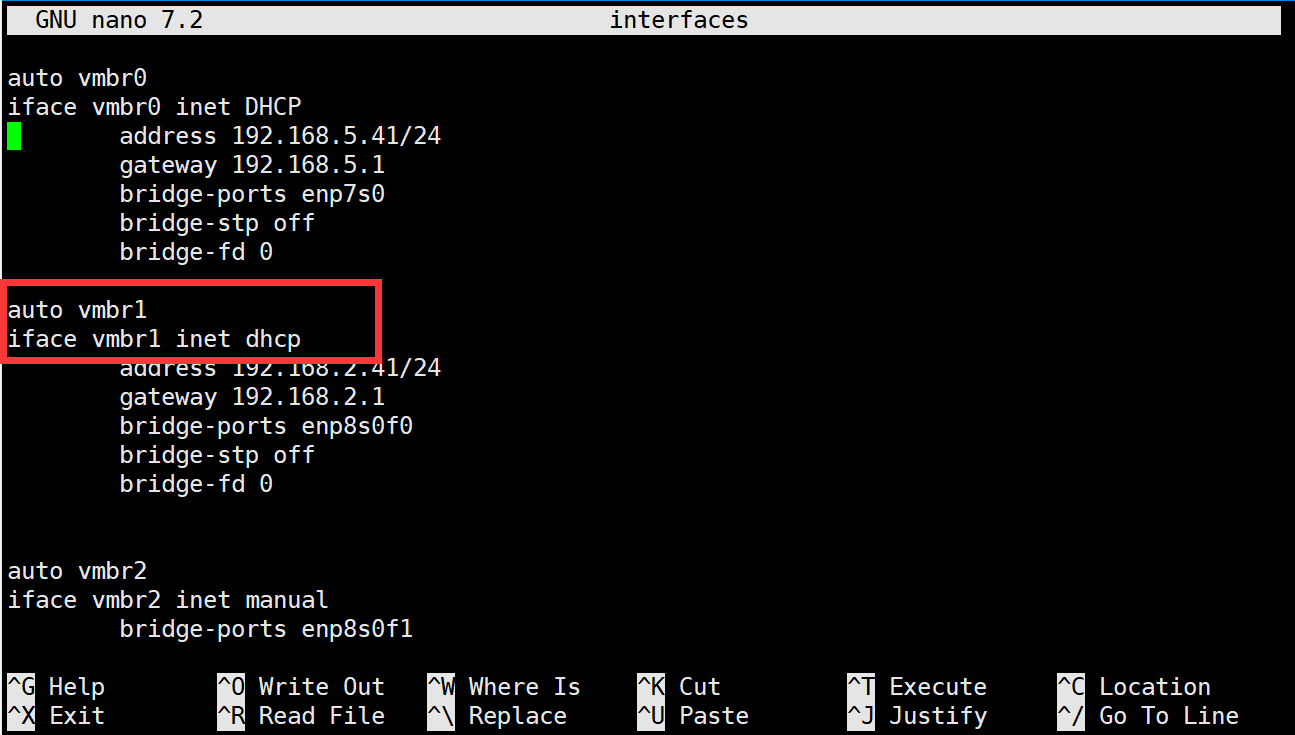
pve安装ikuai并设置,同时把pve的网络连接到ikuai虚拟机
目录 前因 前置条件 安装ikuai 进入ikuai的后台 配置lan口,以及wan口 配置lan口桥接 按实际情况来设置了 单拨(PPOE拨号) 多拨(内外网设置点击基于物理网卡的混合模式) 后续步骤 pve连接虚拟机ikuai的网络以及其他虚拟机连接ikuai的网…...
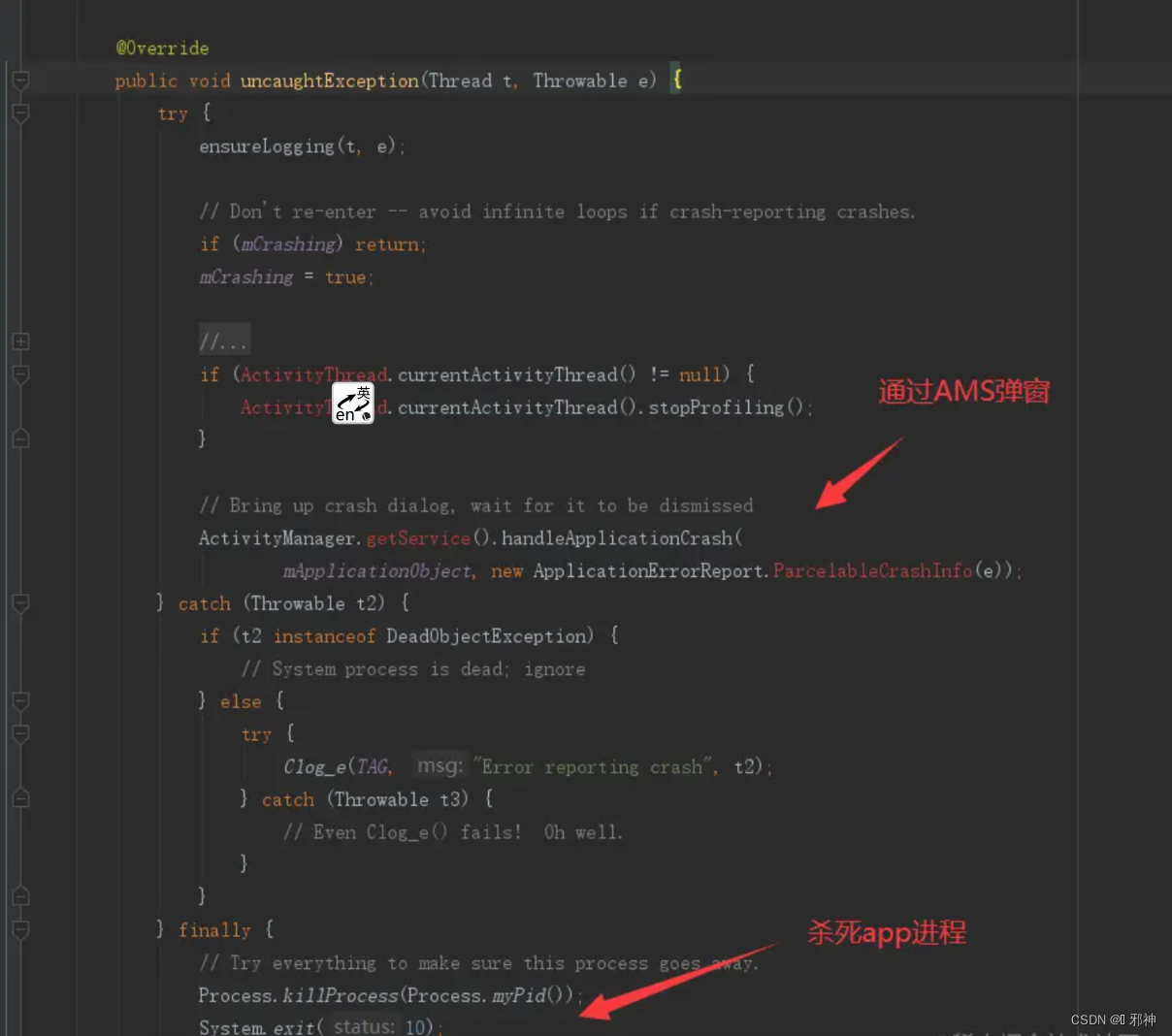
Android 面试题 ANR 五
🔥 什么是 ANR 🔥 ANR(Application Not Responding )应用无响应的简称,是为了在 APP卡死时,用户 可以强制退出APP的选择,从而避免卡机无响应问题,这是Android系统的一种自我保护机制。 在Android中…...

实训笔记7.28
实训笔记7.28 7.28笔记一、Hive的基本使用1.1 Hive的命令行客户端的使用1.2 Hive的JDBC客户端的使用1.2.1 使用前提1.2.2 启动hiveserver21.2.3 使用方式 1.3 Hive的客户端中也支持操作HDFS和Linux本地文件 二、Hive中DDL语法2.1 数据库的管理2.1.1 创建语法2.1.2 修改语法2.1.…...

C 游游的二进制树
题目描述 游游拿到了一棵树,共有nnn个节点,每个节点都有一个权值:0或者1。这样,每条路径就代表了一个二进制数。 游游想知道,有多少条路径代表的二进制数在[l,r][l,r][l,r]区间范围内? (请注意…...
收发存和进销存有什么区别?
一、什么是收发存和进销存 1、收发存 收发存是供应链管理中的关键概念,用于描述企业在供应链中的物流和库存管理过程。 收发存代表了企业在采购、生产和销售过程中的物流活动和库存水平。 收(Receiving) 企业接收供应商送达的物料或产品…...

小程序 账号的体验版正式版的账号信息及相关配置
siteinfo.js // 正式环境 const releaseConfig {appID: "",apiUrl: "",imgUrl: "" }; // 测试环境(包含开发环境和体验环境) const developConfig {appID: "",apiUrl: "",imgUrl: "" }…...
)
别再硬编码IP了!用LabVIEW类+队列实现仪器参数动态管理(附网口类实战代码)
告别硬编码:LabVIEW面向对象编程在仪器参数管理中的实战应用 在工业自动化和测试测量领域,工程师们经常面临一个共同的挑战:如何高效管理各类仪器的配置参数。传统开发方式中,IP地址、端口号等关键参数往往直接硬编码在程序里&…...

Proxifier+Charles实现Windows桌面程序HTTPS抓包
1. 为什么单靠Charles抓不到某些exe的HTTPS流量?你有没有遇到过这种情况:装好Charles、配好系统代理、证书也信任了,浏览器和大部分App的HTTPS请求都能清清楚楚看到明文,可偏偏某个本地运行的.exe程序——比如某款桌面版网盘客户端…...

ARM嵌入式开发中DS-5内存优化与JVM调优实战
1. 问题现象与背景分析最近在调试基于ARM架构的嵌入式系统时,遇到了一个棘手的问题:DS-5开发环境中的Eclipse频繁崩溃,控制台反复弹出"JVM terminated"错误提示,有时还会显示"Java was started but exited with re…...

边缘计算与持续学习在机器人导航中的应用与优化
1. 边缘计算与持续学习在机器人导航中的核心价值 机器人导航系统正面临两大核心挑战:实时性要求和环境动态变化。传统云端处理模式由于网络延迟难以满足毫秒级响应需求,而静态训练模型无法适应不断变化的物理环境。边缘计算与持续学习技术的结合为这些问…...

飞书多维表格还能这么玩?我用它搭了个超好用的 AI 批量生图工具
大家好!上一篇文章我分享了一个飞书多维表格自动化插件的核心功能,很多朋友都在问:这个插件到底能解决什么实际问题?今天就用我最近刚搭好的一个实战案例,给大家好好拆解一下。我用飞书多维表格,从零搭建了…...

Keil MDK C166工具链Watch窗口数组显示异常解决方案
1. 问题现象与影响范围解析在Keil MDK开发环境中使用C166工具链时,开发者可能会遇到一个棘手的调试器显示问题:Watch窗口中的数组和指针数值显示异常。具体表现为数组地址计算错误,进而导致所有数组成员的数值显示都不正确。这个问题不仅影响…...

2026 年招聘效率升级:高匹配候选人推荐的 AI 实践路径
招聘的核心目标是快速找到适配岗位的人才,而简历筛选与候选人推荐是决定招聘效率的关键环节。传统招聘模式下,HR 需手动比对简历与岗位要求,不仅耗时久,还易因主观判断遗漏高匹配候选人。随着 AI 技术在人力资源领域的深度应用&am…...

【能力边界】大模型到底不能做什么?盘点AI在软件测试中的7个致命缺陷
开篇:为什么“会用大模型”≠“会用大模型做测试”? 2026年5月,AI编程工具的渗透速度超乎想象——GitHub Copilot推出永久免费个人版,Cursor的Composer 2让Agent模式成为日常开发标配,Claude Code用终端交互重新定义人与AI的协作方式。据实测对比,Cursor在一次跨模块任务…...

B站直播神器:神奇弹幕全方位操作指南
B站直播神器:神奇弹幕全方位操作指南 【免费下载链接】MagicalDanmaku 本仓库及所有相关项目已永久停止开发、维护和任何形式的分发。 项目地址: https://gitcode.com/gh_mirrors/bi/MagicalDanmaku 直播难题:为什么你需要智能弹幕助手 每个B站主…...

Ender-3固件配置终极指南:5步简单快速性能优化
Ender-3固件配置终极指南:5步简单快速性能优化 【免费下载链接】Ender-3 The Creality3D Ender-3, a fully Open Source 3D printer perfect for new users on a budget. 项目地址: https://gitcode.com/gh_mirrors/en/Ender-3 Ender-3固件配置是解锁3D打印机…...