强化学习QLearning 进行迷宫游戏和代码
强化学习是机器学习里面的一个分支。它强调基于环境而探索行动、学习,以取得最大化的预期收益。其灵感来源于心理学中的行为主义理论,既有机体如何在环境给予的奖励或者惩罚的刺激下,逐步形成对刺激的预期,产生能够最大利益的习惯性行为。简而言之,强化学习就是让机器学着如何在环境中通过不断的试错、尝试,学习、累积经验拿到高分.
强化学习基本结构
强化学习致力于控制一个计算机智能体,使之在未知环境中完成任务目标。
下图中给出强化学习基本机构。在一个未知“迷宫”环境中,计算机算法软件(探索机器人控制大脑)基于自身的控制策略行动。基本结构包括:
(1)智能体(Agent):探索机器人大脑,智能体的结构可以是一个神经网络,也可以是一个简单的算法,智能体的输入通常是状态(State),输出通常是策略(Policy);
(2)动作(Actions):是指动作空间。对于机器人玩迷宫游戏,只有上下左右移动方向可行动,那Actions就是上、下、左、右;
(3)状态(State):就是智能体的输入,机器人在迷宫中的位置;
(4)奖励(Reward):机器人进入某个状态时,能给智能体带来正奖励或者负奖励;
(5)环境(Environment):就是指机器人所走的迷宫,能接收action,返回state和reward。

1、强化学习决策过程
马尔科夫决策过程(MDP)为求解强化学习问题提供了数学框架。几乎所有的强化学习问题都可以建模为MDP。
在强化学习中,agent与environment按顺序在互动。在时刻 t1 ,agent会接收到来自环境的一个observation(观察),获取状态s1,基于这个状态s1 ,agent会做出动作a1 ,然后这个动作作用在环境上,于是agent可以接收到一个奖赏rt+1,并且agent就会到达新的状态s2,以此方式持续下去。agent与environment之间的交互就是产生了一个序列,如下图所示。

强化学习迷宫Q-Learning算法决策实现过程,就是马尔科夫决策过程(MDP)过程的实现,实践过程如下图所示。
强化学习基本要素
基于上述迷宫的案例,我们可以整理出思路里面出现的强化学习要素:
2.4.1. 马尔可夫决策过程(MDP)模型要素
马尔可夫决策过程(MDP)包含5个模型要素,状态(state)、动作(action)、策略(policy)、奖励(reward)和回报(return):
(1)环境的状态s,状态是对环境的描述,正如机器人在迷宫中的位置,也就是t时刻环境的状态st,体现为环境状态集中的某一个状态,在智能体做出动作后,状态会发生变化;MDP所有状态的集合是状态空间,状态空间可以是离散或连续的。
S= s1,s2,s3,s4,……,sπ
(2)机器人的动作A,动作是对智能体行为的描述,是智能体决策的结果。t时刻机器人采取的动作At,是它的动作集中某一个动作;MDP所有可能动作的集合是动作空间,动作空间可以是离散或连续的。
A= a1,a2,a3,a4,……,aπ
(3)环境的奖励R,奖励是智能体给出动作后,环境对智能体的反馈。是当前时刻状态、动作和下个时刻状态的标量函数。
t时刻机器人在状态st ,采取的动作at对应的奖励rt+1 ,会在t+1时刻得到;
R = R(st, at,st+1)
(4)机器人的策略(policy)π,策略是指代表机器人采取动作的依据,即机器人会依据策略π来选择动作。最常见的策略表达方式是一个条件概率分布π(a|s), 即在状态s时采取动作a的概率。即π(a|s)=P(At = a| st=s),此时概率大的动作被机器人选择的概率较高。
(5)环境的状态转化模型,可以理解为一个概率状态机,它可以表示为一个概率模型,即在状态s下采取动作a ,转到下一个状态s’的概率,表示为Pass’ 。
2.4.2. 贝尔曼方程及其要素
贝尔曼方程(Bellman Equation)也被称作动态规划方程(Dynamic Programming Equation),用于求解马尔可夫决策过程(MDP)过程。
贝尔曼方程是动态规划(Dynamic Programming)这些数学最佳化方法能够达到最佳化的必要条件。此方程把“决策问题在特定时间怎么取值”以“来自初始选择的报酬比从初始选择衍生的决策问题的值”的形式表示。借此这个方式把动态最佳化问题变成简单的子问题,而这些子问题遵守从贝尔曼所提出来的“最优原理”。
几乎所有的可以用最优控制理论(Optimal Control Theory)解决的问题也可以通过分析合适的贝尔曼方程得到解决。然而,贝尔曼方程通常指离散时间(discrete-time)最佳化问题的动态规划方程。
贝尔曼方程的三个要素,策略函数、状态价值函数、状态——行为值函数(Q函数)(简称为动作价值函数)。
(1)回报(return),回报是奖励随时间步的积累,在引入轨迹的概念后,回报也是轨迹上所有奖励的总和。
(2)折扣因素,奖励衰减因子(γ),在[0,1]之间。如果为0,则是贪婪法,即价值只由当前延时奖励决定,如果是1,则所有的后续状态奖励和当前奖励一视同仁。大多数时候,我们会取一个0到1之间的数字,即当前延时奖励的权重比后续奖励的权重大。
折扣因素主要作用:
避免连续任务造成回报G无限大;
区分即时奖励和未来奖励的重要程度。
(3)状态值函数 机器人在策略π和状态s时,采取行动后的状态所处的最佳的(程度)价值(value),一般用 表示,是一个期望函数。
价值函数 一般可以表示为下式,不同的算法会有对应的一些价值函数变种,但思路相同:
(4)状态——行为值函数(Q函数)
机器人在策略π和状态s时,采取行动后的行为的所处的最佳的程度,一般用 表示,也是一个期望函数。
根据策略π从状态s 开始采取行动a所获得的期望回报,也就是贝尔曼方程,如下式所述:
(5)探索率ϵ,这个比率主要用在强化学习训练迭代过程中,由于我们一般会选择使当前轮迭代价值最大的动作,但是这会导致一些较好的但我们没有执行过的动作被错过。因此我们在训练选择最优动作时,会有一定的概率ϵ不选择使当前轮迭代价值最大的动作,而选择其他的动作。
Q-Learning算法
时序差分学习 (temporal-difference learning, TD learning):指从采样得到的不完整的状态序列学习,该方法通过合理的 bootstrapping,先估计某状态在该状态序列(episode)完整后可能得到的 return,并在此基础上利用累进更新平均值的方法得到该状态的价值,再通过不断的采样来持续更新这个价值。
时间差分(TD) 学习是蒙特卡罗(MC) 思想和动态规划(DP) 的结合。与MC方法 类似,TD方法 可以直接从经验中学习,而不需要知道环境模型。与 DP 类似,TD方法基于其他学习的估计值来更新估计值,而不用等待最终的结果。首先从预测(prediction)问题出发,建立给定策略 [公式] 对应的值函数 [公式] 的估计。对于控制(control)问题,DP、TD以及MC方法都使用了 广义策略迭代(GPI)的某种形式。这些方法中的不同点主要体现在解决预测问题方面。
Q-learning一种TD(Time Difference)方法,也是一种Value-based的方法。所谓Value-based方法,就是先评估每个action的Q值(Value),再根据Q值求最优策略 的方法。
在Q -值函数包含了两个可以操作的因素。
首先是一个学习率 learning rate(α),它定义了一个旧的Q值将从新的Q值哪里学到的新Q占自身的多少比重。值为0意味着代理不会学到任何东西(旧信息是重要的),值为1意味着新发现的信息是唯一重要的信息。
下一个因素被称为折扣因子discount factor(γ),它定义了未来奖励的重要性。值为0意味着只考虑短期奖励,其中1的值更重视长期奖励。
公式可以变换为:
因此:
是指旧Q值在newQ(s,a)之中所占得比重
是指为本次行动学习到的奖励(行动本身带来的奖励和未来潜在的奖励)。
3.3. Q-table
Q-Learning最终目标是获得回报G,这样需要保存训练过程中的轨迹上所有奖励的总和。因此设计了Q-table用于存储Q(s,a) ,创建一个二维表,可以存储每个state中每个action的未来预期的最大奖励值。这样我们可以知道每个state下的最佳action。
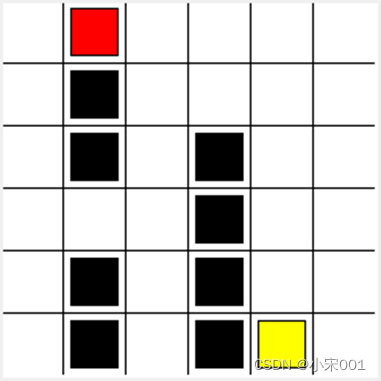
如下图迷宫,每个state(这里指的是方块)允许四种可能性的action,即上、下、左、右。
这个table就叫做Q-table(Q指的是这个action的预期奖励)。迷宫的Q-table中的列有四个action(上下左右行为),行代表state,每个单元格的值将是特定状态(state)和行动(action)下未来预期的最大奖励值
4. 迷宫游戏代码结构
迷宫游戏代码有三部分组成:
maze_env 是迷宫环境,基于Python标准GUI库Tkinter开发
RL_brain 是Q-Learning的核心实现
run_maze 是控制执行算法的代码
maze_env.py
import numpy as np
import time
import syssys.setrecursionlimit(10000)
if sys.version_info.major ==2:import Tkinter as tk
else:import tkinter as tk
UNIT = 40 #像素
MAZE_H = 6 #网格高度
MAZE_W = 6 #网格宽度class Maze(object):def __init__(self):self.action_space = ['u','d','l','r']self.n_actions = len(self.action_space)# self.title('迷宫')# self.geometry('{0}x{1}'.format(MAZE_H*UNIT,MAZE_W*UNIT))# 初始化窗口 画布self.window = tk.Tk()self.canvas = tk.Canvas(self.window,bg='white',height= MAZE_H*UNIT,width = MAZE_W*UNIT)self._build_maze()def _build_maze(self):h = MAZE_H * UNITw = MAZE_W * UNIT#创建画布,设计宽和高#创建栅格# 画线for c in range(0, w, UNIT):self.canvas.create_line(c, 0, c, h)for r in range(0, h, UNIT):self.canvas.create_line(0, r, w, r)# 陷阱self.hells = [self._draw_rect(3, 2, 'black'),self._draw_rect(3, 3, 'black'),self._draw_rect(3, 4, 'black'),self._draw_rect(3, 5, 'black'),self._draw_rect(4, 5, 'black'),self._draw_rect(1, 0, 'black'),self._draw_rect(1, 1, 'black'),self._draw_rect(1, 2, 'black'),self._draw_rect(1, 4, 'black'),self._draw_rect(1, 5, 'black')]self.hell_coords = []for hell in self.hells:self.hell_coords.append(self.canvas.coords(hell))# 奖励self.oval = self._draw_rect(4, 5, 'yellow')# 玩家对象self.rect = self._draw_rect(0, 0, 'red')self.canvas.pack()# color 颜色def _draw_rect(self, x, y, color):center = UNIT / 2w = center - 5x_ = UNIT * x + centery_ = UNIT * y + centerreturn self.canvas.create_rectangle(x_ - w,y_ - w,x_ + w,y_ + w,fill=color)def reset(self):self.canvas.update()time.sleep(0.5)self.canvas.delete(self.rect)self.rect = self._draw_rect(0, 0, 'red')self.old_s = Nonereturn self.canvas.coords(self.rect)# return self.window.coords(self.rect)# 走下一步def step(self,action):s = self.canvas.coords(self.rect)base_action = np.array([0,0])if action == 0: #upif s[1]>UNIT:base_action[1] -=UNITelif action == 1: #downif s[1] <(MAZE_H -1) * UNIT:base_action[1] += UNITelif action == 2: #rightif s[0] <(MAZE_W -1) * UNIT:base_action[0] += UNITelif action == 3: # leftif s[0] > UNIT:base_action[0] -= UNIT# 根据策略移动红块self.canvas.move(self.rect,base_action[0],base_action[1])s_ = self.canvas.coords(self.rect) #next state# 判断是否得到奖励或惩罚if s_ ==self.canvas.coords(self.oval):reward = 1done = Trues_ = 'terminal'elif s_ in self.hell_coords:reward = -1done = Trues_ = 'terminal'else:reward = 0done = Falseself.old_s = sreturn s_,reward,donedef rander(self):time.sleep(0.1)self.canvas.update()
def update():t=0for t in range(10):s = env.reset()print(s)while True:env.rander()a = 2s,r,done = env.step(a)t+=1# print(t)if done:break
if __name__ == '__main__':print(sys.getrecursionlimit())env = Maze()env.window.after(100,update)env.window.mainloop()RL_brain.py 是Q-Learning的核心实现
import numpy as np import pandas as pdclass QLearningTable:def __init__(self,actions,learning_rate=0.01,reward_decay=0.9,e_greedy=0.9):self.actions = actionsself.lr = learning_rateself.gamma = reward_decayself.epsilon = e_greedyself.q_table = pd.DataFrame(columns=self.actions,dtype=np.float64)print(self.q_table)def choose_action(self,observation):self.check_state_exist(observation)if np.random.uniform()<self.epsilon:state_action = self.q_table.loc[observation,:]# 防止相同列值时取第一个列,所以打乱列的顺序action = np.random.choice(state_action[state_action==np.max(state_action)].index)else:action = np.random.choice(self.actions)return actiondef learn(self,s,a,r,s_):self.check_state_exist(s_)q_predict = self.q_table.loc[s,a] # q估计if s_ !='terminal':q_target = r + self.gamma*self.q_table.loc[s_,:].max() # q现实else:q_target = rself.q_table.loc[s,a] += self.lr *(q_target - q_predict)# 检查状态是否存在def check_state_exist(self,state):if (state not in self.q_table.index):self.q_table = self.q_table.append(pd.Series([0]*len(self.actions),index= self.q_table.columns,name = state,))
run_maze.py 是控制执行算法的代码
from maze_env import Maze
from QLearn.RL_brain import QLearningTable
import numpy as np
def update1():for episode in range(100):#获取初始坐标observation = env.reset()# print(type(observation))print(observation)while True:# 刷新环境env.rander()# Rl基于观测选择下一个动作action = RL.choose_action(str(observation))print(action)# 执行这个动作得到反馈(下一个状态observation_ 奖励reward 是否结束done)observation_,reward, done = env.step(action)# RL更新状态表Q-tableRL.learn(str(observation),action,reward,str(observation_))observation = observation_if done:breakif __name__ == '__main__':env = Maze()RL = QLearningTable(actions=list(range(env.n_actions)))env.window.after(10,update1) # 设置10ms的延迟env.window.mainloop()运行之后的效果图:

相关文章:
强化学习QLearning 进行迷宫游戏和代码
强化学习是机器学习里面的一个分支。它强调基于环境而探索行动、学习,以取得最大化的预期收益。其灵感来源于心理学中的行为主义理论,既有机体如何在环境给予的奖励或者惩罚的刺激下,逐步形成对刺激的预期,产生能够最大利益的习惯…...
Vue2 第九节 过滤器
(1)定义:对要显示的数据进行特定格式化后再显示 (2)语法: ① 注册过滤器 1)Vue.filter(name, callback) 全局过滤器 2) new Vue({filters:{}}) 局部过滤器 ② 使用过滤器 1&…...

Swift 对象数组去重
使用 reduce 方法去重 使用 reduce 方法结合 contains 方法可以实现去重。reduce 方法用于将数组的元素进行累积计算,而 contains 方法用于检查元素是否已经存在于结果数组中。 struct SearchRecord: Equatable {let id: Intlet name: String }let records [Sear…...

代码随想录算法训练营day52 300.递增子序列 674.最长连续递增子序列 718.最长重复子数组
题目链接300.递增子序列 class Solution {public int lengthOfLIS(int[] nums) {int[] dp new int[nums.length];Arrays.fill(dp, 1);for(int i 0; i < nums.length; i){for(int j 0; j < i; j){if(nums[i] > nums[j]){dp[i] Math.max(dp[i], dp[j] 1);}}}int r…...

Android 面试题 虚拟机、进程、线程 七
🔥 安卓虚拟机 🔥 虽然Android程序是使用Java语言开发的,当然,现在也可以使用kotlin语言。但是实际上我们开发出来的Android程序并不能运行在JVM上,而是只能运行在一个类似JVM的Android虚拟机上。Android虚拟机有两种&…...
Flutter 状态组件 InheritedWidget
Flutter 状态组件 InheritedWidget 视频 前言 今天会讲下 inheritedWidget 组件,InheritedWidget 是 Flutter 中非常重要和强大的一种 Widget,它可以使 Widget 树中的祖先 Widget 共享数据给它们的后代 Widget,从而简化了状态管理和数据传递…...
<C++> 入门
在学习完C语言的基础上,继续开始C的学习。 C是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式等。熟悉C语言之后,对C学习有一定的帮助。 1. 补充C语言语法的不足,以及C是如…...

政策加持智能家居市场,涂鸦赋能客户打造“以人为本”智能生活新方式
7月18日,商务部等13部门联合发布了《关于促进家居消费若干措施的通知》(以下简称《通知》),《通知》指出,创新培育智能消费,支持企业运用物联网、云计算、人工智能等技术,着重加快智能家电、智能…...

安全渗透初级知识总结-2
CIA三原则:保密性,完整性,可用性 https:解决了安全传输问题 核心技术:用非对称加密传输对称加密的秘钥,然后用对称秘钥通信 抓包:Wireshark、tshark、tcpdump valueof方法是一个所有对象都拥有的方法&am…...

数学建模的32种常规方法及案例代码
比赛期间整理的数学建模的32种常规方法及案例代码友情分享: 链接:https://pan.baidu.com/s/18uDr1113a0jhd2No8O1Nog 提取码:xae5 在数学建模中,常规算法是指那些被广泛应用于各种问题求解的经典算法。这些算法覆盖了不同的数学…...
【Django+Vue】英文成绩管理平台--20230727
能够满足大部分核心需求(标绿):报表部分应该比较难。 项目地址 前端编译 https://gitlab.com/m7840/toeic_vue_dist Vue源码 https://gitlab.com/m7840/toeic_vue Django源码 https://gitlab.com/m7840/toeic_python 项目架构 流程 …...

栈-模拟栈
实现一个栈,栈初始为空,支持四种操作: push x – 向栈顶插入一个数 x; pop – 从栈顶弹出一个数; empty – 判断栈是否为空; query – 查询栈顶元素。 现在要对栈进行 M 个操作,其中的每个…...

图观| 从王宝强、费翔、阿汤哥等新上映的电影聊聊图的智能推荐场景
从技术的视角来看,推荐系统本质上是在用户需求不明确的情况下,从海量的信息中为用户过滤出他可能感兴趣的信息的一种技术手段。 我们日常接触到的智能推荐有: 电商网站:如淘宝、天猫、京东、Amazon…… 生活服务:如美…...
Redis系列一:介绍
介绍 The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker. 相关资源 Redis 官网:https://redis.io/ 源码地址:https://github.com/redis/redis Redis 在线测试&#…...

Java 设计模式 - 单例模式 - 保证类只有一个实例
单例模式 - 保证类只有一个实例 为什么使用单例模式?单例模式的实现方式1. 饿汉式(Eager Initialization)2. 懒汉式(Lazy Initialization)3. 双重检查锁(Double-Checked Locking)4. 静态内部类&…...

第2章 JavaScript语法
准备工作 编写js需要准备一个编译器和游览器,js必须通过HTML/XHTML文档编写 js的编写位置 <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Docume…...

【Golang】Golang进阶系列教程--为什么 Go for-range 的 value 值地址每次都一样?
文章目录 前言现象无限循环相同地址 原因推荐阅读 前言 循环语句是一种常用的控制结构,在 Go 语言中,除了 for 关键字以外,还有一个 range 关键字,可以使用 for-range 循环迭代数组、切片、字符串、map 和 channel 这些数据类型。…...
)
小研究 - JVM 垃圾回收方式性能研究(三)
本文从几种JVM垃圾回收方式及原理出发,研究了在 SPEC jbb2015基准测试中不同垃圾回收方式对于JVM 性能的影响,并通过最终测试数据对比,给出了不同应用场景下如何选择垃圾回收策略的方法。 目录 4 垃圾回收器性能比较 4.1 测试结果 5 结语 …...

java根据poi解析excel内容
一.HSSFWorkbook、XSSFWorkbook、SXSSFWorkbook Apache POI包中的HSSFWorkbook、XSSFWorkbook、SXSSFWorkbook的区别如下: HSSFWorkbook:一般用于操作Excel2003以前(包括2003)的版本,扩展名是.xls。 XSSFWorkbook:一…...

实验报告-Sublime配置默认语法,以配置Verilog语法为例
实验报告-Sublime配置默认语法,以配置Verilog语法为例 1,下载Verilog语法环境2,Sublime配置语法工作环境,以Verilog语法环境为例。3,打开一个新的Sublime,验证编辑器配置Verilog为默认语法成功!4,Sublime汉化1,下载Verilog语法环境 参考文献: 1,Sublime Text 4加载…...

全域流量矩阵系统的运筹学解法:用线性规划模型,算出你100个账号的最优流量分配
手里有100个账号,抖音30个、小红书25个、视频号20个、B站15个、快手10个——然后呢?大多数人的做法是:每个平台平均发,每个账号随便发,发完看天吃饭。这不叫矩阵运营,这叫资源浪费。今天换个完全不同的视角…...
)
告别Keil4编译报错!手把手教你为STC89C52RC单片机配置头文件路径(保姆级教程)
从零解决Keil4头文件报错:STC89C52RC开发环境配置全指南 当你第一次打开Keil4准备为STC89C52RC单片机编写程序时,满心期待地点下编译按钮,却看到屏幕上跳出"Cannot open source file REG52.H"的红色错误提示——这种挫败感我太熟悉…...

RTX251实时系统中NMI中断支持问题解析
1. RTX251调试中的NMI中断问题解析在嵌入式系统开发中,非屏蔽中断(NMI)作为一种高优先级的中断机制,通常用于处理系统关键错误和调试场景。然而,当使用Keil的RTX251实时操作系统与Temic 251系列芯片配合时,开发者可能会遇到NMI支持…...

G-Helper:释放华硕笔记本性能的免费开源轻量控制神器
G-Helper:释放华硕笔记本性能的免费开源轻量控制神器 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zenbook, Exp…...

第1章:AI Agent 架构与核心组件
第1章:AI Agent 架构与核心组件 1.1 从 LLM 到 AI Agent:范式转变 大型语言模型(LLM)本身只是被动响应的工具——用户输入提示,模型输出回答。而 AI Agent(人工智能代理)则赋予了模型主动思考、规划和使用工具的能力,使其能够: 自主规划:将复杂任务分解为可执行的步…...

注意力的几何本质:一个空间与两个算子的统一框架
1. 项目概述:这不是又一篇讲Attention机制的“科普文”如果你最近翻过几篇顶会论文,或者在GitHub上扫过几个热门Transformer库的源码,大概率会在某个角落撞见“The Geometry of Attention: One Space, Two Operators”这个标题。它不像“Atte…...

AI博士退出潮背后的科研适配性诊断
1. 这不是一篇“劝退”文,而是一份AI研究者的真实离职手记“Why I Quit My PhD in AI”——这个标题在2023—2024年反复出现在Substack、Medium和国内少数深度技术社区的首页。它不像“我如何用3个月拿下大厂offer”那样带着明确功利导向,也不像“AI博士…...

2026 年一人公司创业热潮:政策与 AI 驱动,机遇背后暗藏风险
一人公司创业热潮来袭:政策与 AI 双驱动,机遇背后暗藏风险从苏州到深圳,从成都到上海,一种名为 OPC(One Person Company,一人公司)的创业范式正以前所未有的速度席卷全国。数据为证:…...
安装 NVIDIA 显卡驱动)
麒麟系统(桌面版)安装 NVIDIA 显卡驱动
麒麟系统(桌面版)安装 NVIDIA 显卡驱动 一、确认系统和显卡信息 # 查看系统版本 cat /etc/kylin-release# 查看内核版本 uname -r# 查看显卡型号 lspci | grep -i nvidia二、更新系统并安装编译依赖 sudo apt update && sudo apt upgrade -y sud…...

什么,锐捷极简以太彩光一张网竟然有两幅面孔?
在园区网络的建设中,我们常常面临一个两难选择:教学或办公楼需要大带宽,宿舍或病房楼需要弹性带宽。如果分别建两张网,成本翻倍、运维复杂。 锐捷极简以太彩光方案给出的答案是:一张物理网络,同时融合两种…...