W2NER详解
论文:https://arxiv.org/pdf/2112.10070.pdf
代码:https://github.com/ljynlp/W2NER
文章目录
- W2NER
- 介绍
- 模型架构
- 解码
- 源码介绍
- 数据输入格式
- 模型代码
- 参考资料
W2NER
介绍
W2NER模型,将NER任务转化预测word-word(备注,中文是字-字),它能够统一处理扁平实体、重叠实体和非连续实体三种NER任务。
假定摄入的句子 X 由 N 个tokne或word组成, X = { x 1 , x 2 , . . . , x N } X = \{x_1,x_2,...,x_N\} X={x1,x2,...,xN},模型对每个word pair( x i , x j x_i,x_j xi,xj)中的两个word关系类别R进行预测,其中 R ∈ { N o n e , N N W , T H W − ∗ } R\in\{None,NNW,THW-^*\} R∈{None,NNW,THW−∗}
- None:两个word之间没有关系,不属于同一实体
- NNW:即Next-Neighboring-Word,表示这两个word在同一个实体中相邻的位置
- THW-*:即Tail-Head-Word-*,表示这两个word在同一个实体中,且分别是实体的结尾和开始。用来判断实体的类别和边界,其中*是实体类型
举一个具体的例子(蓝色箭头为NNW、红色箭头为THW-*):
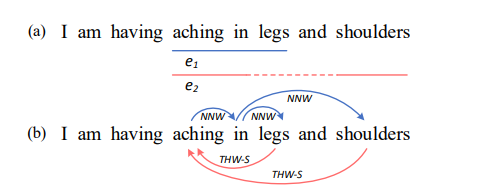
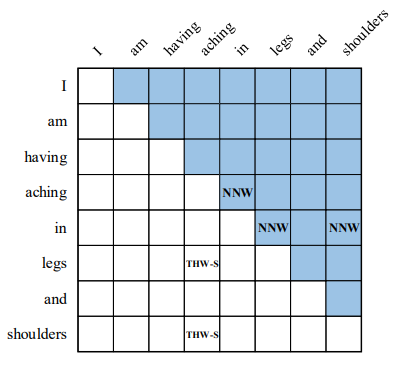
上面的句子中由两个症状(symptom)实体,“aching in legs” 和 “aching in shoulders”,分别记作 e 1 , e 2 e_1,e_2 e1,e2;针对这两个实体,可以得到(b)中的word-word之间的关系,将句子按word维度构建二维矩阵为:
模型架构
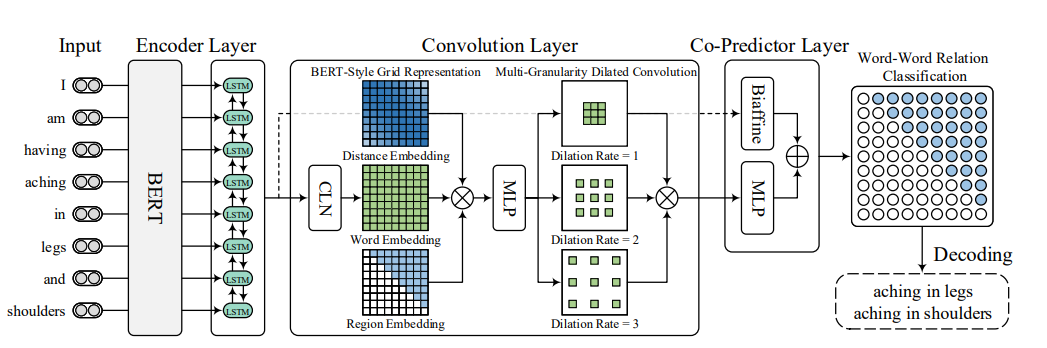
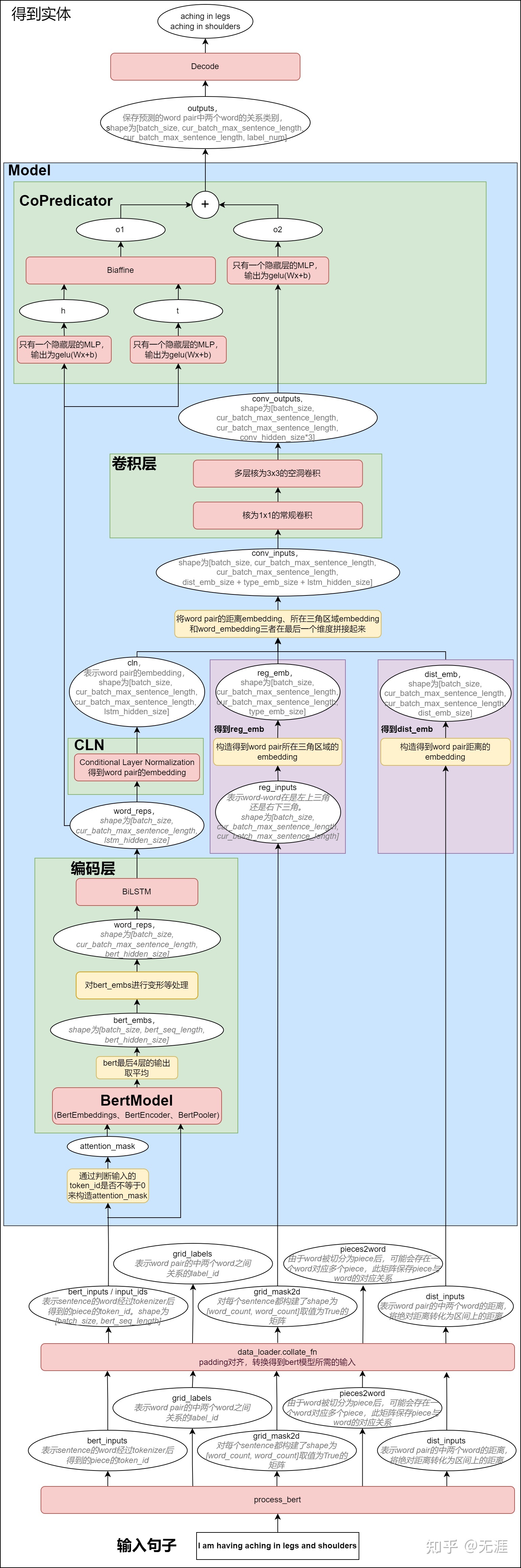
W2NER模型主要是用来预测word pair中两个word之间的关系,也就是最右边的这个图。
接下来,让我们来看下数据流转:
- 输入的sentence经过EncoderLayer(BERT + BiLSTM)得到word_reps
word_reps = {batch_size,cur_batch_max_sentence_length,lstm_hidden_size}
- 将word_reps经过CLN(Conditional Layer Normalization)层,得到cln
cln = {batch_size,cur_batch_max_sentence_length,cur_batch_max_sentence_length,lstm_hidden_size}
- 将word pair的distance_embedding和 三角区域的region_embedding 和 word_reps按最后一个维度拼接,得到conv_inputs
conv_inputs = {batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, dist_emb_size + type_emb_size + lstm_hidden_size}
- 将conv_inputs经过卷积层(核为1*1的常规二维卷积 + 核为3*3的多层空洞卷积),得到conv_outputs
conv_outputs = {batch_size, output_height = cur_batch_max_sentence_length, output_width = cur_batch_max_sentence_length, conv_hidden_size * 3}
- 将conv_outputs经过CoPredictor(由Biaffine + MLP组成),得到output
output = {batch_size, cur_batch_max_sentence_length, cur_batch_max_sentence_length, label_num}
此时对output对最后一个维度取softmax,可得到word-word pair,再进行关系解码
解码
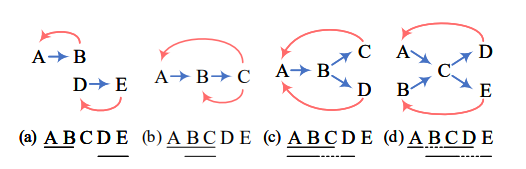
情况a(扁平实体)
(B,A)的关系为THW,则表示B是实体的结尾,A是实体的开始;又(A,B)的关系为NNW,表示A和B是在同一个实体中的相邻位置,所以得到扁平实体“AB”同理可得扁平实体“DE”
情况b(重叠实体)
(C,A)的关系为THW,则C是实体的结尾,A是实体的开始;又(A,B)和(B,C)的关系均为NNW,表示A和B是在同一个实体中的相邻位置,B和C是在同一个实体中的相邻位置,所以得到扁平实体“ABC”同理得到扁平实体“BC”
情况c(扁平实体 + 非连续实体)
得到扁平实体“ABC”、“ABD”
情况d(扁平实体 + 非连续实体)
得到非连续实体“ACD”、“BCE”
源码介绍
数据输入格式
B指batch_size,L指当前句子的长度
- bert_inputs:bert模型的输入token_ids,也就是input_ids包含[CLS]和[SEP] 维度[B,L + 2]
- grid_labels:标注数据实体构建的THW和NHW关系二维矩阵 维度[B,L,L]
- grid_mask2d:网格mask信息,有效信息True,padding为False,维度[B,L,L]
- dist_inputs:网格字符的相对位置信息,维度[B,L,L]
- pieces2word:维度[B,L,L+2]
- entity_text:用来标明实体信息,包括位置,类别。最后用来做评估使用
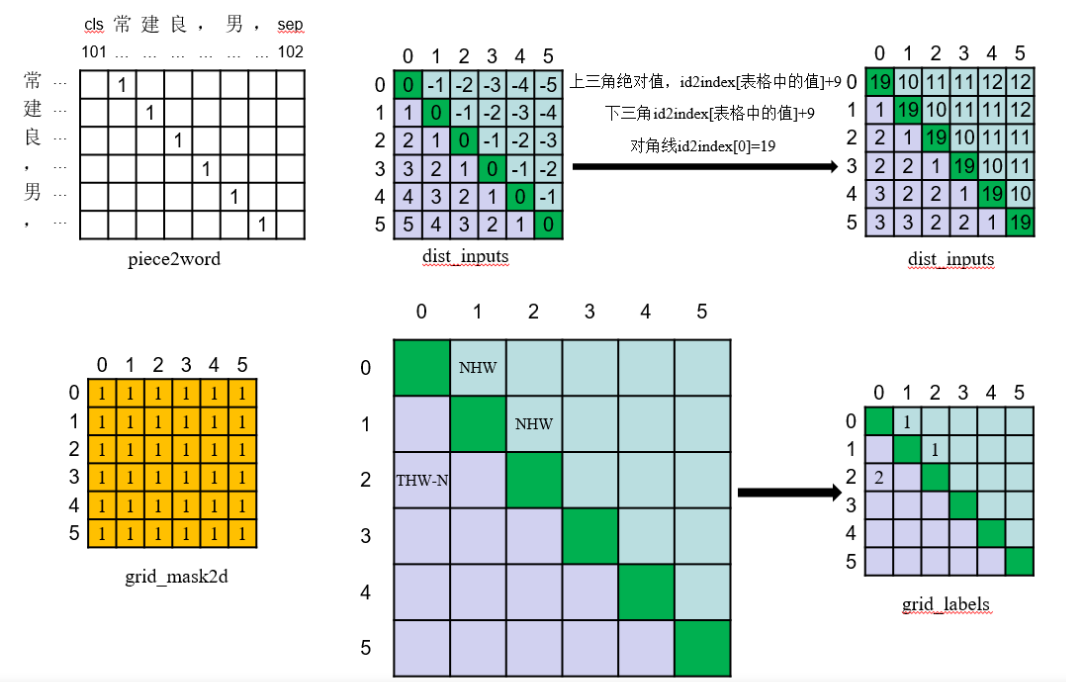
假设有句子:常建良,男
实体为:常建良(Name类型)
则pieces2word、pieces2word、grid_mask2d、grid_labels如下
id2index为
dis2idx = np.zeros((1000), dtype='int64')
dis2idx[1] = 1
dis2idx[2:] = 2
dis2idx[4:] = 3
dis2idx[8:] = 4
dis2idx[16:] = 5
dis2idx[32:] = 6
dis2idx[64:] = 7
dis2idx[128:] = 8
dis2idx[256:] = 9
模型代码
模型主类Model
class Model(BaseModel):def __init__(self, use_bert_last_4_layers=False):super().__init__()self.use_bert_last_4_layers = use_bert_last_4_layersself.bert = build_transformer_model(config_path=config_path, checkpoint_path=checkpoint_path, # segment_vocab_size=0, output_all_encoded_layers = True if use_bert_last_4_layers else False)lstm_input_size = self.bert.configs['hidden_size']self.dis_embs = nn.Embedding(20, dist_emb_size)self.reg_embs = nn.Embedding(3, type_emb_size)self.encoder = nn.LSTM(lstm_input_size, lstm_hid_size // 2, num_layers=1, batch_first=True,bidirectional=True)conv_input_size = lstm_hid_size + dist_emb_size + type_emb_sizeself.convLayer = ConvolutionLayer(conv_input_size, conv_hid_size, dilation, conv_dropout)self.dropout = nn.Dropout(emb_dropout)self.predictor = CoPredictor(label_num, lstm_hid_size, biaffine_size,conv_hid_size * len(dilation), ffnn_hid_size, out_dropout)self.cln = LayerNorm(lstm_hid_size, conditional_size=lstm_hid_size)def forward(self, token_ids, pieces2word, dist_inputs, sent_length, grid_mask2d):bert_embs = self.bert([token_ids, torch.zeros_like(token_ids)])if self.use_bert_last_4_layers:bert_embs = torch.stack(bert_embs[-4:], dim=-1).mean(-1) # 取最后四层的均值length = pieces2word.size(1)min_value = torch.min(bert_embs).item()# 最大池化_bert_embs = bert_embs.unsqueeze(1).expand(-1, length, -1, -1)_bert_embs = torch.masked_fill(_bert_embs, pieces2word.eq(0).unsqueeze(-1), min_value)word_reps, _ = torch.max(_bert_embs, dim=2)# LSTMword_reps = self.dropout(word_reps)packed_embs = pack_padded_sequence(word_reps, sent_length.cpu(), batch_first=True, enforce_sorted=False)packed_outs, (hidden, _) = self.encoder(packed_embs)word_reps, _ = pad_packed_sequence(packed_outs, batch_first=True, total_length=sent_length.max())# 条件LayerNormcln = self.cln(word_reps.unsqueeze(2), word_reps)# concatdis_emb = self.dis_embs(dist_inputs)tril_mask = torch.tril(grid_mask2d.clone().long())reg_inputs = tril_mask + grid_mask2d.clone().long()reg_emb = self.reg_embs(reg_inputs)conv_inputs = torch.cat([dis_emb, reg_emb, cln], dim=-1)# 卷积层conv_inputs = torch.masked_fill(conv_inputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)conv_outputs = self.convLayer(conv_inputs)conv_outputs = torch.masked_fill(conv_outputs, grid_mask2d.eq(0).unsqueeze(-1), 0.0)# 输出层outputs = self.predictor(word_reps, word_reps, conv_outputs)return outputs
ConvolutionLayer类
class ConvolutionLayer(nn.Module):'''卷积层'''def __init__(self, input_size, channels, dilation, dropout=0.1):super(ConvolutionLayer, self).__init__()self.base = nn.Sequential(nn.Dropout2d(dropout),nn.Conv2d(input_size, channels, kernel_size=1),nn.GELU(),)self.convs = nn.ModuleList([nn.Conv2d(channels, channels, kernel_size=3, groups=channels, dilation=d, padding=d) for d in dilation])def forward(self, x):x = x.permute(0, 3, 1, 2).contiguous()x = self.base(x)outputs = []for conv in self.convs:x = conv(x)x = F.gelu(x)outputs.append(x)outputs = torch.cat(outputs, dim=1)outputs = outputs.permute(0, 2, 3, 1).contiguous()return outputs
CoPredictor类
class CoPredictor(nn.Module):def __init__(self, cls_num, hid_size, biaffine_size, channels, ffnn_hid_size, dropout=0):super().__init__()self.mlp1 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)self.mlp2 = MLP(n_in=hid_size, n_out=biaffine_size, dropout=dropout)self.biaffine = Biaffine(n_in=biaffine_size, n_out=cls_num, bias_x=True, bias_y=True)self.mlp_rel = MLP(channels, ffnn_hid_size, dropout=dropout)self.linear = nn.Linear(ffnn_hid_size, cls_num)self.dropout = nn.Dropout(dropout)def forward(self, x, y, z):h = self.dropout(self.mlp1(x))t = self.dropout(self.mlp2(y))o1 = self.biaffine(h, t)z = self.dropout(self.mlp_rel(z))o2 = self.linear(z)return o1 + o2
MLP类
class MLP(nn.Module):'''MLP全连接'''def __init__(self, n_in, n_out, dropout=0):super().__init__()self.linear = nn.Linear(n_in, n_out)self.activation = nn.GELU()self.dropout = nn.Dropout(dropout)def forward(self, x):x = self.dropout(x)x = self.linear(x)x = self.activation(x)return x
Biaffine类
class Biaffine(nn.Module):'''仿射变换'''def __init__(self, n_in, n_out=1, bias_x=True, bias_y=True):super(Biaffine, self).__init__()self.n_in = n_inself.n_out = n_outself.bias_x = bias_xself.bias_y = bias_yweight = torch.zeros((n_out, n_in + int(bias_x), n_in + int(bias_y)))nn.init.xavier_normal_(weight)self.weight = nn.Parameter(weight, requires_grad=True)def extra_repr(self):s = f"n_in={self.n_in}, n_out={self.n_out}"if self.bias_x:s += f", bias_x={self.bias_x}"if self.bias_y:s += f", bias_y={self.bias_y}"return sdef forward(self, x, y):if self.bias_x:x = torch.cat((x, torch.ones_like(x[..., :1])), -1)if self.bias_y:y = torch.cat((y, torch.ones_like(y[..., :1])), -1)# [batch_size, n_out, seq_len, seq_len]s = torch.einsum('bxi,oij,byj->boxy', x, self.weight, y)# remove dim 1 if n_out == 1s = s.permute(0, 2, 3, 1)return s
参考资料
https://blog.csdn.net/HUSTHY/article/details/123870372
https://zhuanlan.zhihu.com/p/546602235
参照代码:
https://github.com/Tongjilibo/bert4torch/blob/master/examples/sequence_labeling/task_sequence_labeling_ner_W2NER.py
相关文章:
W2NER详解
论文:https://arxiv.org/pdf/2112.10070.pdf 代码:https://github.com/ljynlp/W2NER 文章目录 W2NER介绍模型架构解码 源码介绍数据输入格式模型代码 参考资料 W2NER 介绍 W2NER模型,将NER任务转化预测word-word(备注ÿ…...

ElementUI tabs标签页样式改造美化
今天针对ElementUI的Tabs标签页进行了样式修改,更改为如下图所属的样子。 在线运行地址:JSRUN项目-ElementUI tabs标签页样式改造 大家如果有需要可以拿来修改使用,下面我也简单的贴上代码,代码没有注释,很抱歉&#x…...
出海周报|Temu在美状告shein、ChatGPT安卓版上线、小红书回应闪退
工程机械产业“出海”成绩喜人,山东相关企业全国最多Temu在美状告shein,跨境电商战事升级TikTok将在美国推出电子商务计划,售卖中国商品高德即将上线国际图服务,初期即可覆盖全球超200个国家和地区ChatGPT安卓版正式上线ÿ…...

2023年7月26日 单例模式
单例模式 饿汉模式 package com.wz.cinema.platform.server.util;public class DataManager {/*** 单例模式:整个类在运行中只会有一个实例* 既然是在运行中只有一个实例,那么就必须* 考虑多线程环境** 单例模式分为懒汉模式和饿汉模式* 饿汉模式本身就是…...

[ 容器 ] Docker 安全及日志管理
目录 Docker 容器与虚拟机的区别Docker 存在的安全问题Docker 架构缺陷与安全机制Docker 安全基线标准容器相关的常用安全配置方法限制流量流向镜像安全避免Docker 容器中信息泄露DockerClient 端与 DockerDaemon 的通信安全 容器的安全性问题的根源在于容器和宿主机共享内核。…...
游游的排列构造
示例1 输入 5 2 输出 3 1 5 2 4 示例2 输入 5 3 输出 2 1 4 3 5 #include<bits/stdc.h> using namespace std; typedef long long ll; const int N1e55; int n,k; int main(){scanf("%d%d",&n,&k);int xn-k1;int yn-k;int f1;for(int i1;i&l…...
拯救者Y9000K无线Wi-Fi有时不稳定?该如何解决?
由于不同品牌路由器的性能差异,无法完美兼容最新的无线网卡技术,在连接网络时(特别是网络负载较大的情况下),可能会出现Wi-Fi信号断开、无法网络无法访问、延迟突然变大的情况;可尝试下面方法进行调整。 1…...
【业务功能篇59】Springboot + Spring Security 权限管理 【下篇】
UserDetails接口定义了以下方法: getAuthorities(): 返回用户被授予的权限集合。这个方法返回的是一个集合类型,其中每个元素都是一个GrantedAuthority对象,表示用户被授予的权限。getPassword(): 返回用户的密码。这个方法返回的是一个字符…...

性能优化 - 前端性能监控和性能指标计算方式
性能优化 - 前端性能监控和性能指标计算方式 前言一. 性能指标介绍1.1 单一指标介绍1.2 指标计算① Redirect(重定向耗时)② AppCache(应用程序缓存的DNS解析)③ DNS(DNS解析耗时)④ TCP(TCP连接耗时)⑤ TTFB(请求响应耗时)⑥ Trans(内容传输耗时)⑦ DOM(DOM解析耗时) 1.3 FP(f…...
git stash clear清空本地暂存代码
git stash clear清空本地暂存代码 git stash 或者 git stash list 查看本地暂存的代码。 清除本地暂存的代码修改: git stash clear git回退代码仓库版本_git回退到之前的版本会影响本地代码嘛_zhangphil的博客-CSDN博客git回退代码版本_git回退到之前的版本会影…...
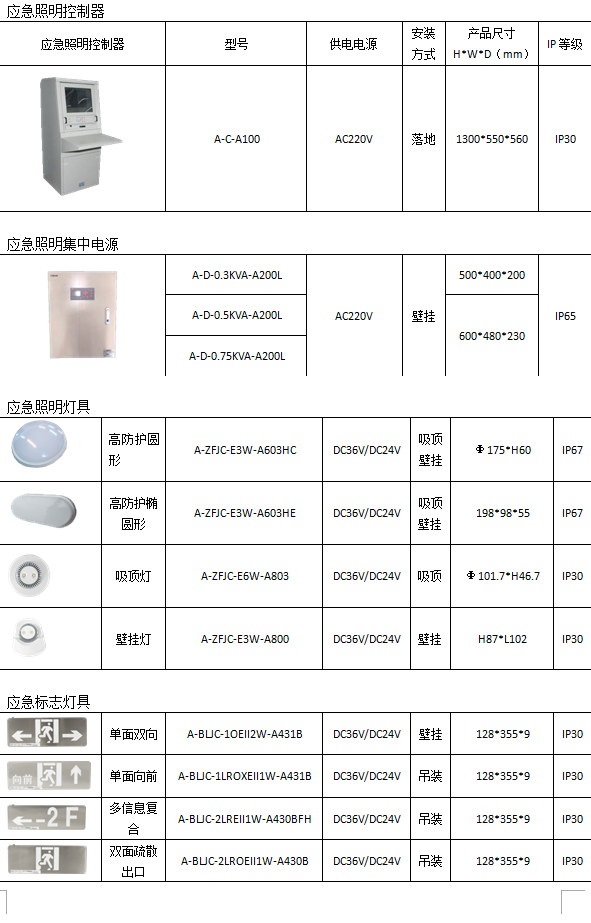
消防应急照明设置要求在炼钢车间电气室的应用
摘 要:文章以GB51309—2018《消防应急照明和疏散指示系统技术标准》为设计依据,结合某炼钢车间转炉项目的设计过程,在炼钢车间电气室的疏散照明和备用照明的设计思路、原则和方法等方面进行阐述。通过选择合理的消防应急疏散照明控制系统及灯具供配电方案…...

element 表单验证 深层验证绑定
直接上代码 :prop 和prop 都可以,vue2和vue3或者是element、elementplus都可以用 <template><div class"page page-table"><section class"page-query-form"><breadcrumb :hasLine"false" /></section&g…...

brew 换镜像网站
在国内,使用brew极慢. 因为它需要访问国外的一些服务器. 解决方法是使用国内的镜像站. 如果是首次安装: curl https://raw.githubusercontent.com/Homebrew/install/master/install.sh > install-brew.sh 然后,在下载的文件中, 修改BREW_REPO为: BREW_REPO"https…...
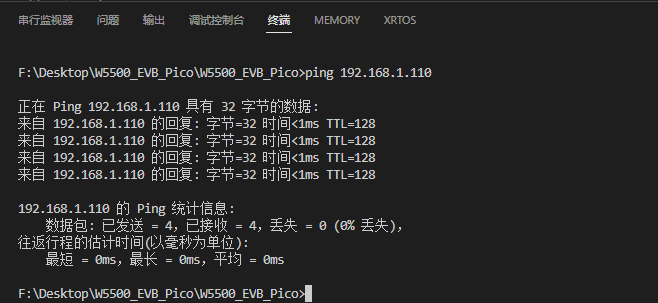
WIZnet W5500-EVB-Pico 静态IP配置教程(二)
W5500是一款高性价比的 以太网芯片,其全球独一无二的全硬件TCP、IP协议栈专利技术,解决了嵌入式以太网的接入问题,简单易用,安全稳定,是物联网设备的首选解决方案。WIZnet提供完善的配套资料以及实时周到的技术支持服务…...

R语言无法调用stats.dll的问题解决方案[补充]
写在前面 在去年10月份,出过一起关于R语言无法调用stats.dll的问题解决方案,今天(你看到后是昨天)不知道为什么,安装包,一直安装不了,真的是炸裂了。后面再次把R与Rstuido升级。说实话,我是真不…...

无线蓝牙耳机有什么推荐?怎么选择适合自己的耳机?七款蓝牙耳机分享
随着信息技术的不断发展,蓝牙耳机的不断发展也是必然的,可以说蓝牙耳机在大部分人们的生活中是不可缺少的一部分。那么我们该怎么去挑选出适合我们自己的需求的“蓝”朋友呢? 第一款:南卡小音舱lite2蓝牙耳机 推荐指数ÿ…...
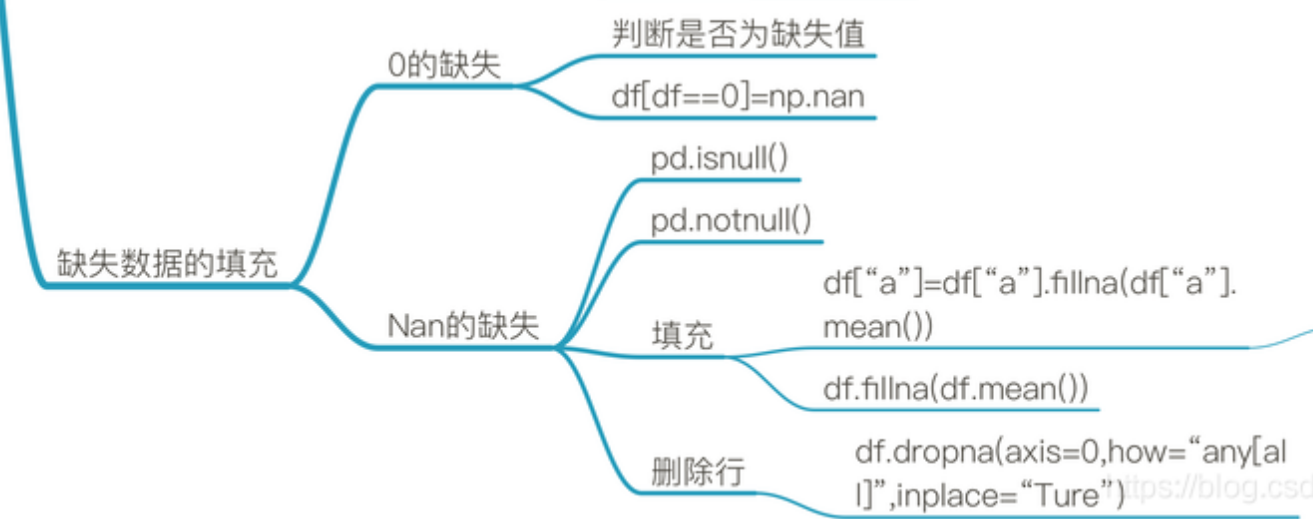
【数据分析专栏之Python篇】四、pandas介绍
前言 在上一篇中我们安装和使用了Numpy。本期我们来学习使用 核心数据分析支持库 Pandas。 一、pandas概述 1.1 pandas 简介 Pandas 是 Python 的 核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。 …...

《算法竞赛·快冲300题》每日一题:“最小生成树”
《算法竞赛快冲300题》将于2024年出版,是《算法竞赛》的辅助练习册。 所有题目放在自建的OJ New Online Judge。 用C/C、Java、Python三种语言给出代码,以中低档题为主,适合入门、进阶。 文章目录 题目描述题解C代码Java代码Python代码 “ 最…...

mysql的主键选择
一.没有定义主键有什么问题 如果定义了主键,那么InnoDB会使用主键作为聚簇索引如果没有定义主键,那么会使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作为聚簇索引如果既没有主键也找不到合适的非空索引,那么In…...

Eureka 学习笔记1:服务端实例缓存
版本 awsVersion ‘1.11.277’ 缓存类型registryConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>AbstractInstanceRegistry成员变量readWriteCacheMapLoadingCacheResponseCacheImpl成员变量readOnlyCacheMapConcurrentMap<Key, Value>…...

专业做绝对值编码器的服务商
在工业自动化领域,绝对值编码器是不可或缺的关键组件。它能够直接输出轴或直线运动的“绝对位置”,断电后位置信息不会丢失,每次上电都能立刻知道当前的精确坐标,这使得其在各种精密应用中具有无可替代的优势。本文将通过具体数据…...

Token聚合平台 vs 传统云 vs AI原生云,AI推理应用怎么选?
在大模型能力深度融入生产环境的当下,后端 AI 架构的选择往往决定了应用的生死。从早期的“调用一个接口”到如今复杂的智能体(Agent)工作流,开发团队在底座选型上面临着两条截然不同的演进路径:一条是追求便利与极致轻…...

Kirikiri游戏开发终极指南:开源工具集完整解决方案
Kirikiri游戏开发终极指南:开源工具集完整解决方案 【免费下载链接】KirikiriTools Tools for the Kirikiri visual novel engine 项目地址: https://gitcode.com/gh_mirrors/ki/KirikiriTools KirikiriTools是专为Kirikiri视觉小说游戏引擎设计的开源工具集…...

Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化
Bpmn Process Designer性能优化指南:大型流程图的渲染与交互优化 【免费下载链接】bpmn-process-designer bpmn-js 工具库 项目地址: https://gitcode.com/gh_mirrors/bp/bpmn-process-designer Bpmn Process Designer是一款基于bpmn-js的强大流程设计器工具…...

ARMv8-A架构VDISR_EL3与VSESR_EL2寄存器解析
1. AArch64系统寄存器概述在ARMv8-A架构中,系统寄存器是处理器状态和功能控制的核心组件。它们分布在不同的异常级别(EL0-EL3),每个级别都有特定的访问权限和功能定位。作为芯片级开发者,理解这些寄存器的细节对构建稳定可靠的系统至关重要。…...

网页端嵌入 Agent 对接前端方案
本文将深入探讨「网页端嵌入AI」的核心概念与实战技巧,帮助你快速掌握关键要点。让我们开始吧! 网页端嵌入 Agent 对接前端方案 1. 引言 当前前端项目正从被动展示走向主动交互,AI Agent 嵌入网页端可自动化 UI 操作、优化布局并辅助编码。…...

3个核心操作:让网络架构可视化变得如此简单
3个核心操作:让网络架构可视化变得如此简单 【免费下载链接】easy-topo vuesvgelement-ui 快捷画出网络拓扑图 项目地址: https://gitcode.com/gh_mirrors/ea/easy-topo 在数字时代的网络管理中,技术文档的可视化呈现已经成为专业沟通的关键。面对…...
)
收藏必备!小白程序员轻松上手大模型:RAG技术实战指南(含评测体系)
本文深入浅出地解析了RAG(检索增强生成)技术在大模型开发中的应用,覆盖了从文档加载、智能切分到索引构建、检索优化、生成调优的全链路实战指南,并介绍了进阶的Graph RAG和多跳推理。特别强调了“可测、可调、可信赖”的RAG工程化…...

2026年AI写作辅助网站测评:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都无法回避的“成长痛”。选题无从下手,文献检索耗时费力,写作过程卡顿不断,格式调整反复修改,查重降重更是让人抓耳挠腮。进入2026年,AI工具早已不只是“文字助手”&#…...

Pulover‘s Macro Creator:你的数字助手,让电脑学会“自己工作“
Pulovers Macro Creator:你的数字助手,让电脑学会"自己工作" 【免费下载链接】PuloversMacroCreator Automation Utility - Recorder & Script Generator 项目地址: https://gitcode.com/gh_mirrors/pu/PuloversMacroCreator 你是否…...