mysql的主键选择
一.没有定义主键有什么问题
- 如果定义了主键,那么InnoDB会使用主键作为聚簇索引
- 如果没有定义主键,那么会使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作为聚簇索引
- 如果既没有主键也找不到合适的非空索引,那么InnoDB会自动生成一个不可见的名为row_id的列名为GEN_CLUST_INDEX的聚簇索引,该列是一个6字节的自增数值,随着插入而自增--补充:该全局row_id在代码实现上使用的是bigint unsigned类型,但实际上只给row_id留了6字节,这种设计就会存在一个问题:如果全局row_id一直涨,一直涨,直到2的48幂次-1时,这个时候再+1,row_id的低48位都为0,结果在插入新一行数据时,拿到的row_id就为0,存在主键冲突的可能性。
自动生成的名为row_id主键有什么问题
- 使用不了主键索引,查询会进行全表扫描
- 影响数据插入性能,插入数据需要生成ROW_ID,而生成的ROW_ID是全局共享的(InnoDB 维护了一个全局的 dictsys.row_id,所有未定义主键的表都共享该row_id),并发会导致锁竞争,影响性能
二.有主键,但是主键达到最大值有什么问题
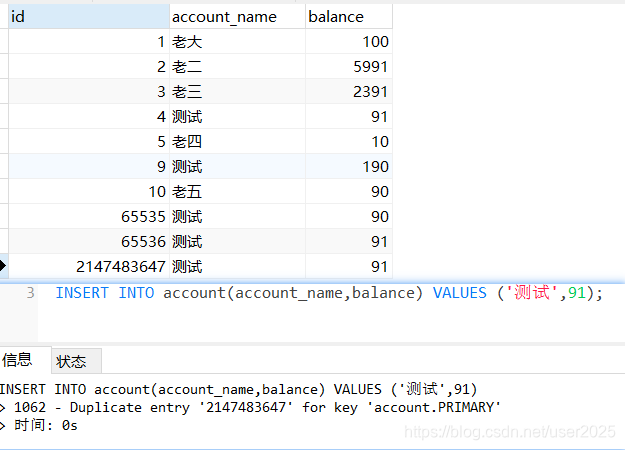
如果申明了用int类型的数据库自增的主键,当主键达到最大值,再插入则主键不会再增长,而是报主键重复错误。
MySQL主键当达到最大值(如果为int类型,最大值为21亿多),此时再插入数据,会提示主键重复错误。
三.主键的选择
1.规范
1)规范推荐使用int,bigint 无符号做自增键
在《阿里巴巴 Java 开发手册》第五章 MySQL 规定第九条中,强制规定了单表的主键 id 必须为无符号的 bigint 类型,且是自增的。

MySQL开发规范中经常可以看到:
- 推荐使用int,bigint 无符号做自增键
- 禁止使用uuid做主键
关于主键的类型选择上最常见的争论是用整型还是字符型的问题,关于这个问题《高性能MySQL》一书中有明确论断:
整数通常是标识列的最好选择,因为它很快且可以使用AUTO_INCREAMENT,如果可能,应该避免使用字符串类型作为标识列,因为很消耗空间,且通常比数字类型慢。
如果是使用MyISAM,则就更不能用字符型,因为MyISAM默认会对字符型采用压缩引擎,从而导致查询变得非常慢。
2)规范背后的原因
通常主键 id 的数据类型有两种选择:字符串或者整数,主键通常要求是唯一的,如果使用字符串类型,我们可以选择 UUID 或者具有业务含义的字符串来作为主键。
对于 UUID 而言,它由 32 个字符+4 个'-'组成,长度为 36,虽然 UUID 能保证唯一性,但是它有两个致命的缺点:
- 不是递增的。MySQL 中索引的数据结构是 B+Tree,这种数据结构的特点是索引树上的节点的数据是有序的,而如果使用 UUID 作为主键,那么每次插入数据时,因为无法保证每次产生的 UUID 有序,所以就会出现新的 UUID 需要插入到索引树的中间去,这样可能会频繁地导致页分裂,使性能下降。
- 太占用内存。每个 UUID 由 36 个字符组成,在字符串进行比较时,需要从前往后比较,字符串越长,性能越差。另外字符串越长,占用的内存越大,由于页的大小是固定的,这样一个页上能存放的关键字数量就会越少,这样最终就会导致索引树的高度越大,在索引搜索的时候,发生的磁盘 IO 次数越多,性能越差。
对于整数的数字类型,MySQL 中主要有 int 和 bigint 类型。其中 int 占用 4 个字节,bigint 占用 8 个字节,这和 Java 中的 int 和 long 对应。如果使用无符号的 int 类型作为主键,那么主键的最大值为 2^32-1,即 4294967295,这个值不到 43 亿,似乎有点太小了。虽然一张表的数据,我们不可能让其达到 43 亿条(太大会影响性能),但是对于频繁进行插入、删除的表来说,43 亿这个值是可以达到的。而如果使用无符号的 bigint 类型的话,主键的最大值可以达到 2^64-1,这个数足够大了,如果以每秒插入 100 万条数据计算的,58 万年以后才能达到最大值。所以 bigint 作为主键的数据类型,完全不用担心超过最大值的问题。
而强制要求主键 id 是自增的,则是为了在数据插入的过程中,尽可能的避免索引树上页分裂的问题。
2.介绍下long和雪花id和uuid
1)主键id:

tinyint、smallint、mediumint,这三个不常用就不说了。无符号是设置了 unsigned 属性,表示不允许负值,这大致可以使正数的上限提高一倍。
以无符号int类型为例,42亿虽然看起来是个很大的数字,但是对于一些插入删除很频繁的业务来说,并非无法触达这个上限。特别是有的业务表设置的步长比较大,会导致id自增的速度更快。如果你的业务预期会产生很多数据,那么建议你在创建表时,直接使用bigint。
因为MySQL的主键策略:id自增值达到上限以后,再申请下一个 id 时,仍然是最大值,就会报主键重复错误。
如果bigint真的还不够使用的话,我们可以使用雪花算法生成的id做主键,由于其也是大致递增的,对性能也不会产生影响,只需要由bigint改成更大范围的decimal就行。
2)雪花id:
我之前文章已有介绍
3)UUID:
我之前文章已有介绍
3.实战:
在mysql新建3张结构一模一样的表
1)效率测试结果
每个表新增10w,30w,100w数据
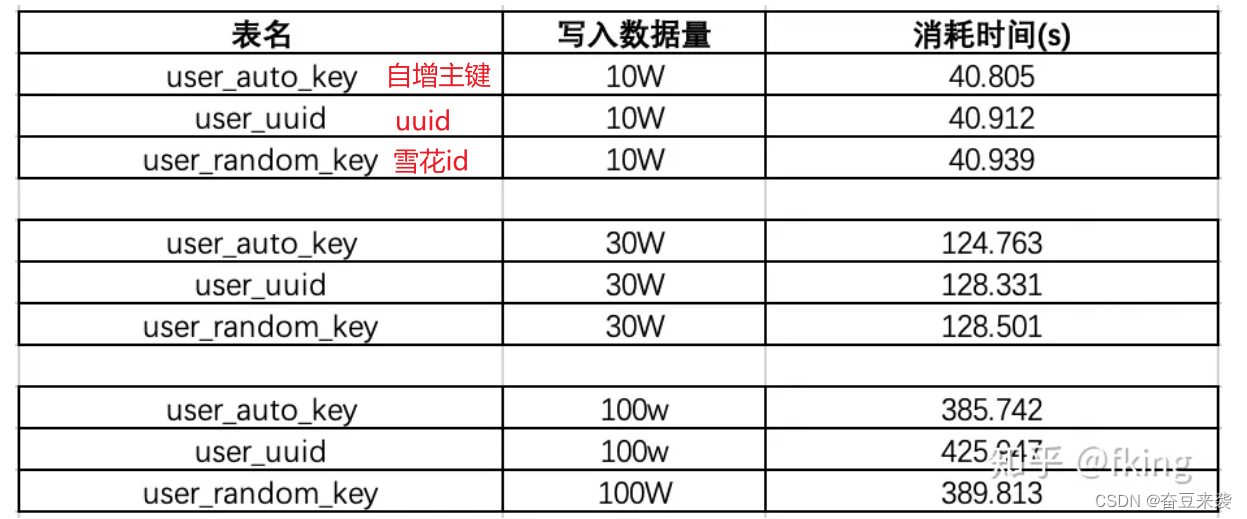
在已有数据量为130W的时候:我们再来测试一下插入10w数据,看看会有什么结果:

可以看出在数据量100W左右的时候,uuid的插入效率垫底,并且在后序增加了130W的数据,uudi的时间又直线下降。时间占用量总体可以打出的效率排名为:auto_key>random_key>uuid,uuid的效率最低,在数据量较大的情况下,效率直线下滑。
4.使用自增id的缺点
那么使用自增的id就完全没有坏处了吗?并不是,自增id也会存在以下几点问题:
①:别人一旦爬取你的数据库,就可以根据数据库的自增id获取到你的业务增长信息,很容易分析出你的经营情况
②:对于高并发的负载,innodb在按主键进行插入的时候会造成明显的锁争用,主键的上界会成为争抢的热点,因为所有的插入都发生在这里,并发插入会导致间隙锁竞争
③:Auto_Increment锁机制会造成自增锁的抢夺,有一定的性能损失
5.总结
总结:总体来看,效率简单排名为:auto_key>random_key>uuid,
但是,根据自己项目的需求,权衡利弊,选择三个中的一个就行了.
----------------------------------------------------------------------------------------------------
为什么?mysql不推荐使用uuid或者雪花id作为主键? - 知乎 (zhihu.com)
链接:https://juejin.cn/post/7206197077909782588
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
相关文章:
mysql的主键选择
一.没有定义主键有什么问题 如果定义了主键,那么InnoDB会使用主键作为聚簇索引如果没有定义主键,那么会使用第一非空的唯一索引(NOT NULL and UNIQUE INDEX)作为聚簇索引如果既没有主键也找不到合适的非空索引,那么In…...

Eureka 学习笔记1:服务端实例缓存
版本 awsVersion ‘1.11.277’ 缓存类型registryConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>AbstractInstanceRegistry成员变量readWriteCacheMapLoadingCacheResponseCacheImpl成员变量readOnlyCacheMapConcurrentMap<Key, Value>…...

vue : 无法加载文件 C:\Users\86182\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。
windows11: PS E:\VueProjects> vue vue : 无法加载文件 C:\Users\86182\AppData\Roaming\npm\vue.ps1,因为在此系统上禁止运行脚本。有关详细信息,请参阅 https:/ go.microsoft.com/fwlink/?LinkID135170 中的 about_Execution_Policie…...
FLinkCDC读取MySQl时间戳时区相关问题解决汇总
FlinkCDC时间问题timestamp等https://blog.csdn.net/qq_30529079/article/details/127809317 FLinkCDC读取MySQl中的日期问题https://blog.csdn.net/YPeiQi/article/details/130265653 关于flink1.11 flink sql使用cdc时区差8小时问题https://blog.csdn.net/weixin_44762298/…...

第三篇-Tesla P40+CentOS7+CUDA 11.7 部署实践
硬件环境 系统:CentOS-7 CPU: 14C28T 显卡:Tesla P40 24G 准备安装 驱动: 515 CUDA: 11.7 cuDNN: 8.9.2.26 安装依赖 yum clean all yum update yum install -y gcc gcc-c pciutils kernel-devel-$(uname -r) kernel-headers-$(uname -r)查看GPU信息…...
AC+FIT(瘦AP)配置浅谈
FIT ensp实验材料 :pc、路由器、三层交换机、二层交换机、ac、ap 保证连通性: 根据ac与ap设计好的ip配置,使之可以通讯 ac与ap可以实现跨网段管理 1、设置三层交换机的vlan 与vlanif信息 dhcp enable //开启dhcp ip pool forap //…...
【Python】PySpark 数据计算 ② ( RDD#flatMap 方法 | RDD#flatMap 语法 | 代码示例 )
文章目录 一、RDD#flatMap 方法1、RDD#flatMap 方法引入2、解除嵌套3、RDD#flatMap 语法说明 二、代码示例 - RDD#flatMap 方法 一、RDD#flatMap 方法 1、RDD#flatMap 方法引入 RDD#map 方法 可以 将 RDD 中的数据元素 逐个进行处理 , 处理的逻辑 需要用外部 通过 参数传入 map…...
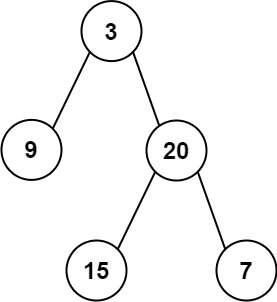
二叉树题目:左叶子之和
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:左叶子之和 出处:404. 左叶子之和 难度 3 级 题目描述 要求 给你二叉树的根结点 root \texttt{ro…...

Spark SQL报错: Task failed while writing rows.
错误 今天运行 Spark 任务时报了一个错误,如下所示: WARN scheduler.TaskSetManager: Lost task 9.0 in stage 3.0 (TID 69, xxx.xxx.xxx.com, executor 3): org.apache.spark.SparkException: Task failed while writing rows.at org.apache.spark.sq…...
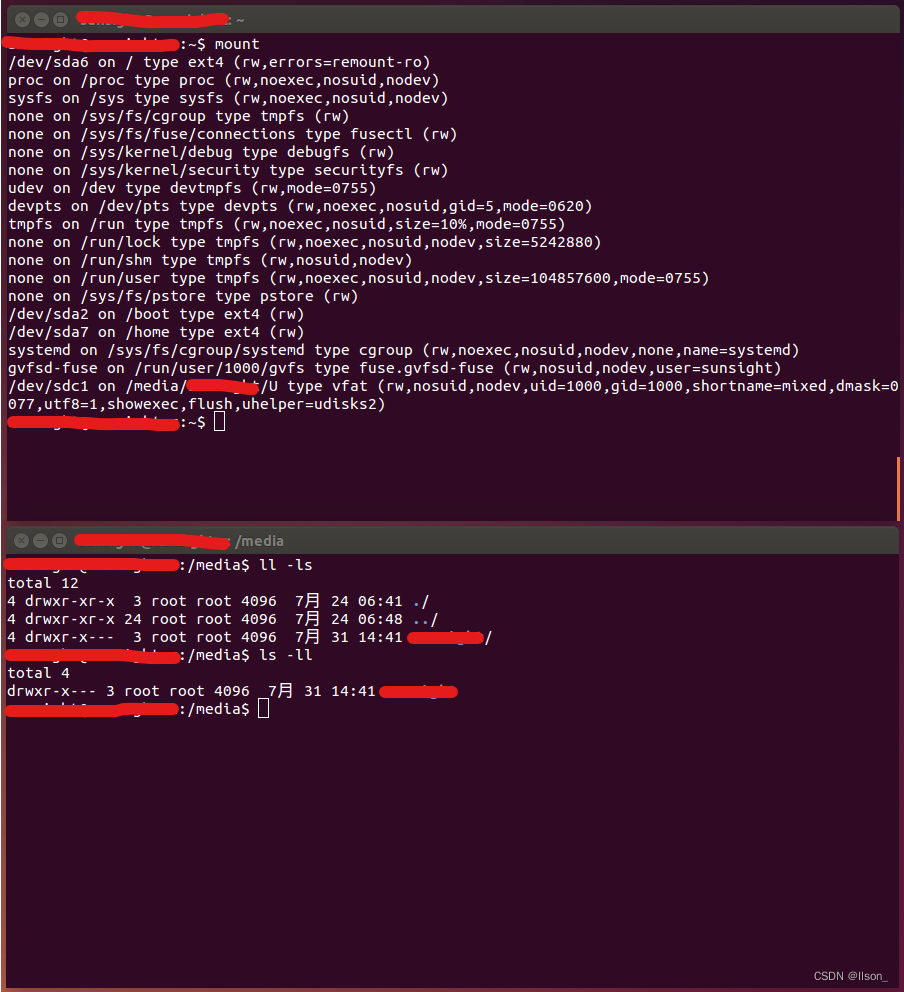
Linux系统下U盘打不开: No application is registered as handling this file
简述 系统是之前就安装好使用的Ubuntu14.04,不过由于某些原因只安装到了机械硬盘中;最近新买了一块固态硬盘,所以打算把Ubuntu系统迁移到新的固态硬盘上; 当成功的迁移了系统之后发现其引导有点问题,导致多个系统启动不…...

07 定时器处理非活动连接(上)
07 定时器处理非活动连接(上) 基础知识 非活跃,是指客户端(这里是浏览器)与服务器端建立连接后,长时间不交换数据,一直占用服务器端的文件描述符,导致连接资源的浪费。 定时事件&a…...
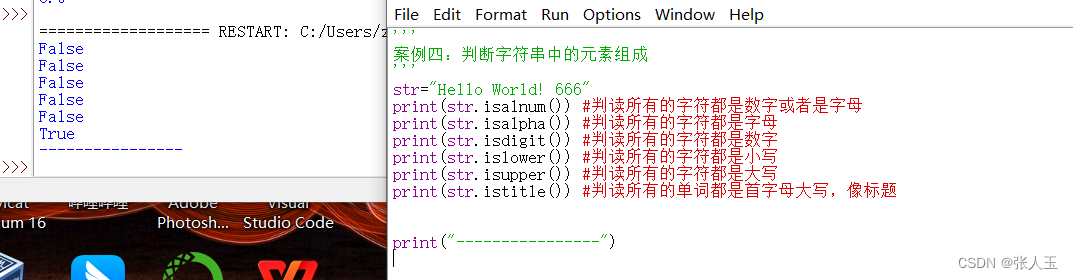
python——案例四:判断字符串中的元素组成
案例四:判断字符串中的元素组成str"Hello World! 666" print(str.isalnum()) #判读所有的字符都是数字或者是字母 print(str.isalpha()) #判读所有的字符都是字母 print(str.isdigit()) #判读所有的字符都是数字 print(str.islower()) #判读所有的字符都是…...
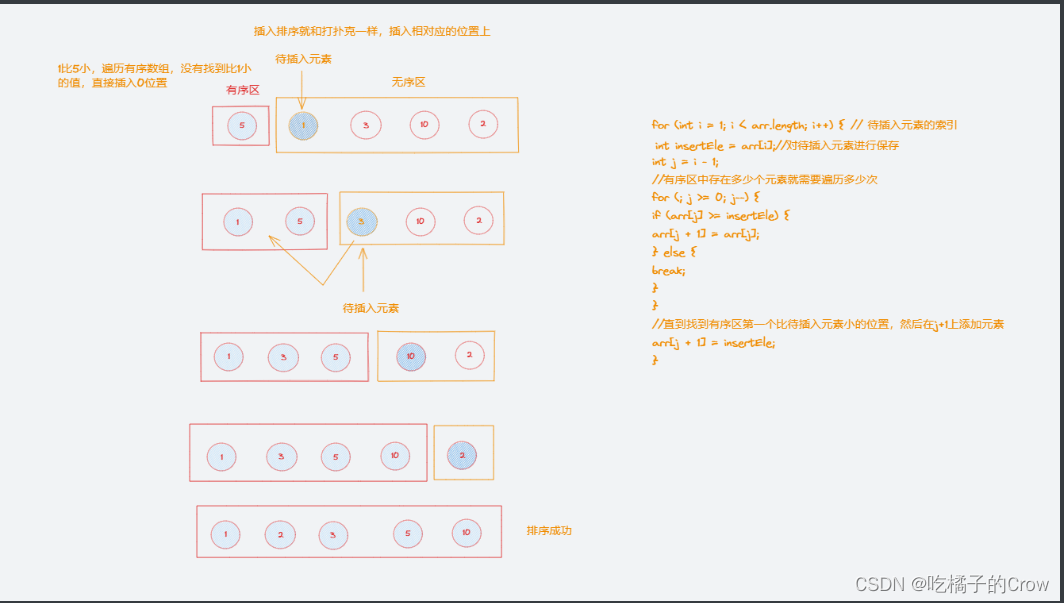
一起学算法(插入排序篇)
概念: 插入排序(inertion Sort)一般也被称为直接插入排序,是一种简单的直观的排序算法 工作原理:将待排列元素划分为(已排序)和(未排序)两部分,每次从&…...
JVM基础篇-本地方法栈与堆
JVM基础篇-本地方法栈与堆 本地方法栈 什么是本地方法? 本地方法即那些不是由java层面实现的方法,而是由c/c实现交给java层面进行调用,这些方法在java中使用native关键字标识 public native int hashCode()本地方法栈的作用? 为本地方法提供内存空…...
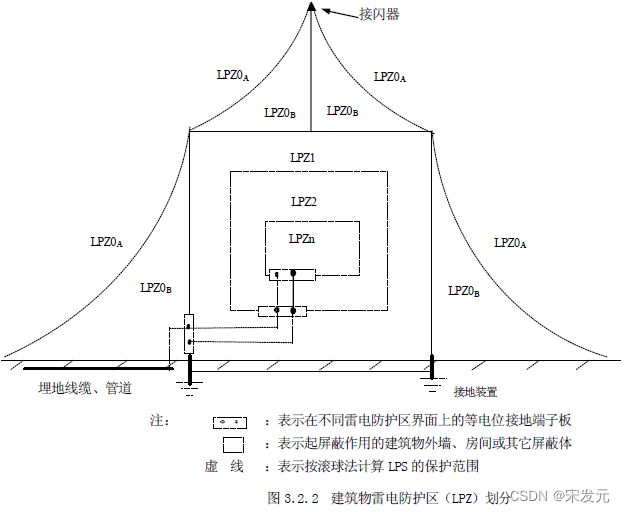
防雷保护区如何划分,防雷分区概念LPZ介绍
在防雷设计中,很重要的一点就是防雷分区的划分,只有先划分好防雷区域等级,才好做出比较好的防雷器设计方案。 因为标准对不同区安装的防雷浪涌保护器要求是不一样的。 那么,防雷保护区是如何划分的呢? 如上图所示&…...

随手笔记——3D−3D:ICP求解
随手笔记——3D−3D:ICP求解 使用 SVD 求解 ICP使用非线性优化来求解 ICP 原理参见 https://blog.csdn.net/jppdss/article/details/131919483 使用 SVD 求解 ICP 使用两幅 RGB-D 图像,通过特征匹配获取两组 3D 点,最后用 ICP 计算它们的位…...

Python调用各大机器翻译API大全
过去的二三年中,我一直关注的是机器翻译API在自动化翻译过程中的应用,包括采用CAT工具和Python编程语言来调用机器翻译API,然后再进行译后编辑,从而达到快速翻译的目的。 然而,我发现随着人工智能的发展,很…...

重生之我要学C++第六天
这篇文章的主要内容是const以及权限问题、static关键字、友元函数和友元类,希望对大家有所帮助,点赞收藏评论支持一下吧! 更多优质内容跳转: 专栏:重生之C启程(文章平均质量分93) 目录 const以及权限问题 1.const修饰…...

SpringBoot中ErrorPage(错误页面)的使用--【ErrorPage组件】
SpringBoot系列文章目录 SpringBoot知识范围-学习步骤–【思维导图知识范围】 文章目录 SpringBoot系列文章目录本系列校训 SpringBoot技术很多很多环境及工具:必要的知识深层一些的知识 上效果图在Spring Boot里使用ErrorPage还要注意的是 配套资源作业ÿ…...

【Android】APP网络优化学习笔记
网络优化原因 进行网络优化对于移动应用程序而言非常重要,原因如下: 用户体验: 网络连接是移动应用程序的核心功能之一。通过进行网络优化,可以提高应用的加载速度和响应速度,减少用户等待时间,提供更流…...

AI驱动数字孪生:从静态镜像到自主决策的工业智能体
1. 项目概述:当物理世界有了“数字分身”,它就开始自己思考了我第一次在德国一家汽车厂的控制中心看到那个画面时,手里的咖啡差点洒出来——大屏幕上,整条总装线正以毫秒级延迟同步运转:机械臂的关节扭矩、焊点温度曲线…...

昇腾CANN pto-isa:虚拟指令集如何把 Ascend C 翻译成硬件指令
一个 Ascend C kernel 写好后,要在昇腾 NPU 上执行,需要经过两道编译:第一道,昇腾编译器把 Ascend C 翻译成 PTO(Parallel Tensor Orchestration)虚拟指令;第二道,NPU 固件在运行时把…...

RT-Trace升级:集成GDB Server与一键烧录,打造嵌入式开发调试平台
1. 项目概述:嵌入式开发的“瑞士军刀”再进化如果你是一名嵌入式开发者,最近可能被一个词刷屏了——RT-Trace。这已经不是它第一次带来惊喜了。最初,它以非侵入式的实时追踪和性能分析能力,在RT-Thread社区里掀起了一阵热潮&#…...

3步实现百度网盘高速下载:Python解析工具实战指南
3步实现百度网盘高速下载:Python解析工具实战指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse baidu-wangpan-parse是一款高效的Python工具,专门用于…...

从文件上传到 RAG 检索:真正看懂了一个 AI 项目的知识库链路
一、前言:今天不是单独学一个知识点,而是串起了一条完整链路 今天继续分析 AI 项目中的 RAG 模块时,我发现自己之前对“文件上传”“文件切片”“向量化”“召回”“大模型回答”这些概念,虽然都单独听过,但真正放到项…...

3分钟完成Excel批量查询:智能多文件搜索工具完整指南
3分钟完成Excel批量查询:智能多文件搜索工具完整指南 【免费下载链接】QueryExcel 多Excel文件内容查询工具。 项目地址: https://gitcode.com/gh_mirrors/qu/QueryExcel 还在为处理海量Excel文件而烦恼吗?面对成百上千个表格文件,传统…...
与少样本(Few-shot)提示在用例生成中的对比)
【Prompt实战】零样本(Zero-shot)与少样本(Few-shot)提示在用例生成中的对比
目录 一、开篇:一个测试工程师的真实困境 二、基础概念:零样本与少样本的本质区别 三、学术界怎么说:最新实证研究深度解读...

终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量
终极AI评估指南:用DeepEval开源框架轻松保障你的大语言模型质量 【免费下载链接】deepeval The LLM Evaluation Framework 项目地址: https://gitcode.com/GitHub_Trending/de/deepeval 你是否曾担心AI助手给出错误的医疗建议?是否焦虑金融AI客服…...

【ElevenLabs老挝文语音实战指南】:2024年唯一经实测验证的8步本地化语音合成落地方案
更多请点击: https://kaifayun.com 第一章:ElevenLabs老挝文语音合成的技术背景与本地化价值 ElevenLabs 作为全球领先的AI语音生成平台,长期聚焦于高保真、情感化多语言语音合成技术。尽管其支持语言列表持续扩展,老挝文&#x…...

【技术干货】微小间距、热敏感区域焊接难?激光锡球焊接在芯片封装中的高精零飞溅解决方案
随着智能穿戴设备、5G通信、电子娱乐影音等产品的普及,智能电子产品已深度融入现代人生活的方方面面,从衣食住行到尖端科技领域,无处不在。人们在享受便利的同时,不禁好奇:这些设备究竟如何实现“智能化”?…...