Python调用各大机器翻译API大全
过去的二三年中,我一直关注的是机器翻译API在自动化翻译过程中的应用,包括采用CAT工具和Python编程语言来调用机器翻译API,然后再进行译后编辑,从而达到快速翻译的目的。
然而,我发现随着人工智能的发展,很多机器翻译也做了相应的调整,调用机器翻译api的样例也发生了变化,今天我特意把主流机器翻译api调用的Python代码汇聚于此,总共有七种方法,供大家学习参考。
一、Python调用Google机器翻译API
目前官方网站的调用代码没有之前的好用,所以我们依然采用以前的代码,只用安装requests, 而不用安装额外的Python包,前提是只要知道Google翻译的API密匙和翻译的语对方向即可,代码如下:
import requests
def google_api(content):url = "https://translation.googleapis.com/language/translate/v2"data = {'key': "YOUR_API_KEY", #你自己的api密钥'source': "zh",'target': "en",'q': content,'format': 'text'}headers = {'X-HTTP-Method-Override': 'GET'}response = requests.post(url, data=data, headers=headers)res = response.json()text = res["data"]["translations"][0]["translatedText"]return text
print("谷歌翻译:"+google_api("好好学习,天天向上!"))二、Python调用百度机器翻译API
Python调用百度机器翻译API的代码有些变化,但前提是需要申请百度的api id和key,放到以下代码中:
import requests
import random
import json
from hashlib import md5# Set your own appid/appkey.
appid = 'YOUR APP ID'
appkey = 'YOU APP KEY'# For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21`
from_lang = 'en'
to_lang = 'zh'endpoint = 'http://api.fanyi.baidu.com'
path = '/api/trans/vip/translate'
url = endpoint + pathquery = 'Hello World!'# Generate salt and sign
def make_md5(s, encoding='utf-8'):return md5(s.encode(encoding)).hexdigest()def baidu_api(query,from_lang,to_lang):salt = random.randint(32768, 65536)sign = make_md5(appid + query + str(salt) + appkey)# Build requestheaders = {'Content-Type': 'application/x-www-form-urlencoded'}payload = {'appid': appid, 'q': query, 'from': from_lang, 'to': to_lang, 'salt': salt, 'sign': sign}# Send requestr = requests.post(url, params=payload, headers=headers)result = r.json()# Show response#print(json.dumps(result, indent=4, ensure_ascii=False))return result["trans_result"][0]['dst']print(baidu_api(query,from_lang, to_lang))三、Python调用小牛机器翻译API代码
以下代码是经过我改进后的代码,效率更高一些,供大家参考。小牛现在提供100万字符/月的额度,大家可以申请试用。
import json
import requests
apikey="YOUR_API_KEY"
def translate(sentence, src_lan, tgt_lan):url = 'http://api.niutrans.com/NiuTransServer/translation?'data = {"from": src_lan, "to": tgt_lan, "apikey": apikey, "src_text": sentence}res = requests.post(url, data = data)res_dict = json.loads(res.text)if "tgt_text" in res_dict:result = res_dict['tgt_text']else:result = resreturn result
if __name__ == "__main__":while True:line = input("请输入要翻译的文本:")try:trans = translate(line, 'auto', 'en')print(trans+"\n---------")except Exception as exc:print(exc)四、Python调用同花顺机器翻译api
之前我已经写出采用Python调用同花顺机器翻译api来翻译字幕的代码,详情如下:
import json,os,sys
import requests
import easygui as g
# appid = '你申请的id'
# appkey = '你申请的key'
# 解说打包报错问题
os.environ['REQUESTS_CA_BUNDLE'] = os.path.join(os.path.dirname(sys.argv[0]), 'cacert.pem')def get_key():
"""读取本地appid.txt,获取id和key并生成字典"""dic={}with open("appid.txt","r",encoding="utf-8") as f:lines=[line.strip() for line in f.readlines()]for line in lines:ls=line.split("=")dic[ls[0].strip()]=ls[1].strip()return dicdef getToken():
"因为用同花顺的API时要校验token,由于token只有24小时的有效期,因此每次都要调用一下,以防过期。本函数获取最新的token"tokenUrl = 'https://b2b-api.10jqka.com.cn/gateway/service-mana/app/login-appkey'param = {}param['appId'] = appidparam['appSecret'] = appkeyauthResult = requests.post(tokenUrl, data=param)authResult = authResult.contentres = json.loads(authResult)access_token = ''if 0 == res['flag']:access_token = res['data']['access_token']return access_tokendef translate(texts, token):
"调用同花顺机器翻译API函数,注意这里是英文翻译成中文,如果要中文翻译成英文要修改【param['from']】为zh,【param['to'] 】为en"ls=[]if '' == token:returnparam = {}param['app_id'] = appidparam['from'] = "en"param['to'] = 'zh'param['domain'] = 'default'param['text'] = json.dumps(texts)headers = {"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8", "open-authorization": "Bearer" + token}url = 'https://b2b-api.10jqka.com.cn/gateway/arsenal/machineTranslation/batch/get/result'response = requests.post(url, headers=headers, data=param)Ret = response.contentres = json.loads(Ret)if 0 == res['status_code']:res = res['data']for rst in res['trans_result']:ls.append(rst['dst'])return lsdef read_srt(file):
"读取字幕文件,生成字幕序号、时间和字幕内容的列表"with open(file, "r", encoding = "utf-8-sig") as f:lines=[line.strip() for line in f.readlines()]max_line=len(lines)if max_line<=600:texts=lines[2:max_line:4]times=lines[1:max_line:4]nums=lines[:max_line:4]else:g.msgbox("字幕文件超过150行!请更换文件。")return nums,times,textsdef add_to_srt(nums,times,texts,trans):
"生成新的字幕文件,把译文也添加上。"final_list=[]for (num,time,text,tran) in zip(nums,times,texts,trans):new_line = num + "\n"+ time + "\n" + text + "\n" + tran +"\n\n"final_list.append(new_line)with open(srt.replace(".srt", "_new.srt"), "wt", encoding= "utf-8-sig") as f:f.write("".join(final_list))print("done!")if __name__ == '__main__':d=get_key()appid=d["id"]appkey=d["key"]title='请打开字幕文件'srt=g.fileopenbox(default='*.srt')nums,times,texts=read_srt(srt)token = getToken() #token有效期为24小时,请在应用程序中做好定时获取操作,避免token失效trans=translate(texts, token)add_to_srt(nums,times,texts,trans)g.msgbox("字幕文件已经翻译成功,请在字幕所在目录查看。")五、Python调用彩云 小译机器翻译api
彩云这个小而美的机器翻译一直很低调,翻译的速度和质量都还不错。以下是相关的样例代码:
import requests
import jsonurl = "http://api.interpreter.caiyunai.com/v1/translator"
token = "你的令牌" #这里填写你自己的令牌payload = {#"source" : ["Where there is a will, there is a way.", #"ColorfulClouds Weather is the best weather service."],"source" : "Where there is a will, there is a way.","trans_type" : "en2zh","request_id" : "demo",}headers = {'content-type': "application/txt",'x-authorization': "token " + token,
}response = requests.request("POST", url, data=json.dumps(payload), headers=headers)#print(response.text)
resp = json.loads(response.text)['target']print(resp)六、Python调用阿里云机器翻译api
阿里云机器翻译api的调用比较繁琐,申请过程也较复杂,其翻译质量倒时一般,大家可以有选择地使用以下代码:
from alibabacloud_alimt20181012.client import Client as alimt20181012Client
from alibabacloud_tea_openapi import models as open_api_models
from alibabacloud_alimt20181012 import models as alimt_20181012_models
from alibabacloud_tea_util import models as util_modelsACCESS_KEY_ID = 【Access_key_id>】#这里把尖括号里的 Acess_key_id和Acess_key_secret分别修改为自己申请的通用翻译api
ACCESS_KEY_SECRET = 【Access_key_secret】def create_client(access_key_id: str,access_key_secret: str,
) -> alimt20181012Client:config = open_api_models.Config(access_key_id=access_key_id,access_key_secret=access_key_secret)config.endpoint = f'mt.cn-hangzhou.aliyuncs.com'return alimt20181012Client(config)
def translate(text):client = create_client(ACCESS_KEY_ID, ACCESS_KEY_SECRET)translate_general_request = alimt_20181012_models.TranslateGeneralRequest(format_type='text',source_language='en',target_language='zh',source_text=text,scene='general')runtime = util_models.RuntimeOptions()resp = client.translate_general_with_options(translate_general_request, runtime)return resp.body.data.__dict__['translated']
print(translate("Rome is not built in a day."))七、利用ChatGPT来翻译
ChatGPT也可以用于翻译,只要我们给它发出指令即可。代码如下:
import openaiopenai.api_base = "https://api.openai.com/v1"openai.api_key = "YOUR_API_KEY"model_engine_id = "text-davinci-003"while True:prompt = input("Q:")completions = openai.Completion.create(engine=model_engine_id,prompt="Translate the following sentences into Chinese:"+prompt,max_tokens=800,)message = completions.choices[0].text.strip()print("A:",message,end="\n")八、学后反思
1. 本文总结了六大机器翻译api的调用方法,供大家参考。英译汉,个人推荐的是Google翻译。汉译英推荐百度翻译、小牛翻译等。译文润色可以调用ChatGPT帮忙。
2. 下一步,我将努力整合一下更多的机器翻译api的调用方法,添加在一起,也可以写一个调用包,以方便大家使用。
相关文章:

Python调用各大机器翻译API大全
过去的二三年中,我一直关注的是机器翻译API在自动化翻译过程中的应用,包括采用CAT工具和Python编程语言来调用机器翻译API,然后再进行译后编辑,从而达到快速翻译的目的。 然而,我发现随着人工智能的发展,很…...

重生之我要学C++第六天
这篇文章的主要内容是const以及权限问题、static关键字、友元函数和友元类,希望对大家有所帮助,点赞收藏评论支持一下吧! 更多优质内容跳转: 专栏:重生之C启程(文章平均质量分93) 目录 const以及权限问题 1.const修饰…...

SpringBoot中ErrorPage(错误页面)的使用--【ErrorPage组件】
SpringBoot系列文章目录 SpringBoot知识范围-学习步骤–【思维导图知识范围】 文章目录 SpringBoot系列文章目录本系列校训 SpringBoot技术很多很多环境及工具:必要的知识深层一些的知识 上效果图在Spring Boot里使用ErrorPage还要注意的是 配套资源作业ÿ…...

【Android】APP网络优化学习笔记
网络优化原因 进行网络优化对于移动应用程序而言非常重要,原因如下: 用户体验: 网络连接是移动应用程序的核心功能之一。通过进行网络优化,可以提高应用的加载速度和响应速度,减少用户等待时间,提供更流…...
简单的知识图谱可视化+绘制nx.Graph()时报错TypeError: ‘_AxesStack‘ object is not callable
绘制nx.Graph时报错TypeError: _AxesStack object is not callable 写在最前面知识图谱可视化预期报错可能的原因 原代码原因确认解决后的代码解决! 写在最前面 实现一个简单的知识图谱的可视化功能。 使用了NetworkX库来构建知识图谱,并使用matplotlib…...
)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码5.1 fun.m5.2 main.m6.完整代码6.1 fun.m6.2 main.m7.运行结果1.模型原理 基于粒子群优化算法(Particle Swarm Optimization, PSO)优…...
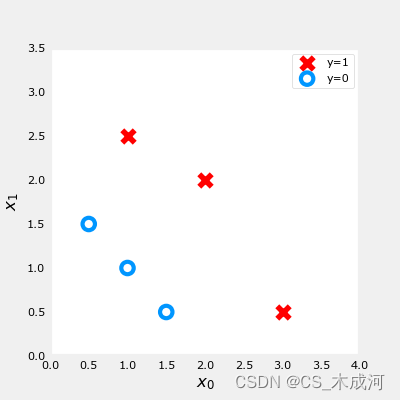
【机器学习】Cost Function for Logistic Regression
Cost Function for Logistic Regression 1. 平方差能否用于逻辑回归?2. 逻辑损失函数loss3. 损失函数cost附录 导入所需的库 import numpy as np %matplotlib widget import matplotlib.pyplot as plt from plt_logistic_loss import plt_logistic_cost, plt_two_…...

【EI/SCOPUS会议征稿】2023年第四届新能源与电气科技国际学术研讨会 (ISNEET 2023)
作为全球科技创新大趋势的引领者,中国一直在为科技创新创造越来越开放的环境,提高学术合作的深度和广度,构建惠及全民的创新共同体。这些努力为全球化和创建共享未来的共同体做出了新的贡献。 为交流近年来国内外在新能源和电气技术领域的最新…...
【计算机网络】10、ethtool
文章目录 一、ethtool1.1 常见操作1.1.1 展示设备属性1.1.2 改变网卡属性1.1.2.1 Auto-negotiation1.1.2.2 Speed 1.1.3 展示网卡驱动设置1.1.4 只展示 Auto-negotiation, RX and TX1.1.5 展示统计1.1.7 排除网络故障1.1.8 通过网口的 LED 区分网卡1.1.9 持久化配置(…...

什么是前端工程化?
工程化介绍 什么是前端工程化? 前端工程化是一种思想,而不是某种技术。主要目的是为了提高效率和降低成本,也就是说在开发的过程中可以提高开发效率,减少不必要的重复性工作等。 tip 现实生活举例 建房子谁不会呢?请…...

【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程
【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程 文章目录 【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程前言确定版本对应关系源码编译安装tiny-cuda-nn总结 前言 本人windows11下使用【Instant Neural Surface Reconstruction】算法时需要…...

Matlab 一种自适应搜索半径的特征提取方法
文章目录 一、简介二、实现代码参考资料一、简介 在之前的博客(C++ ID3决策树)中,提到过一种信息熵的概念,其中它表达的大致意思为:香农认为熵是指“当一件事情有多种可能情况时,这件事情发生某种情况的不确定性”,也就是指如果一个事情的不确定性越大,那么这个信息的熵…...
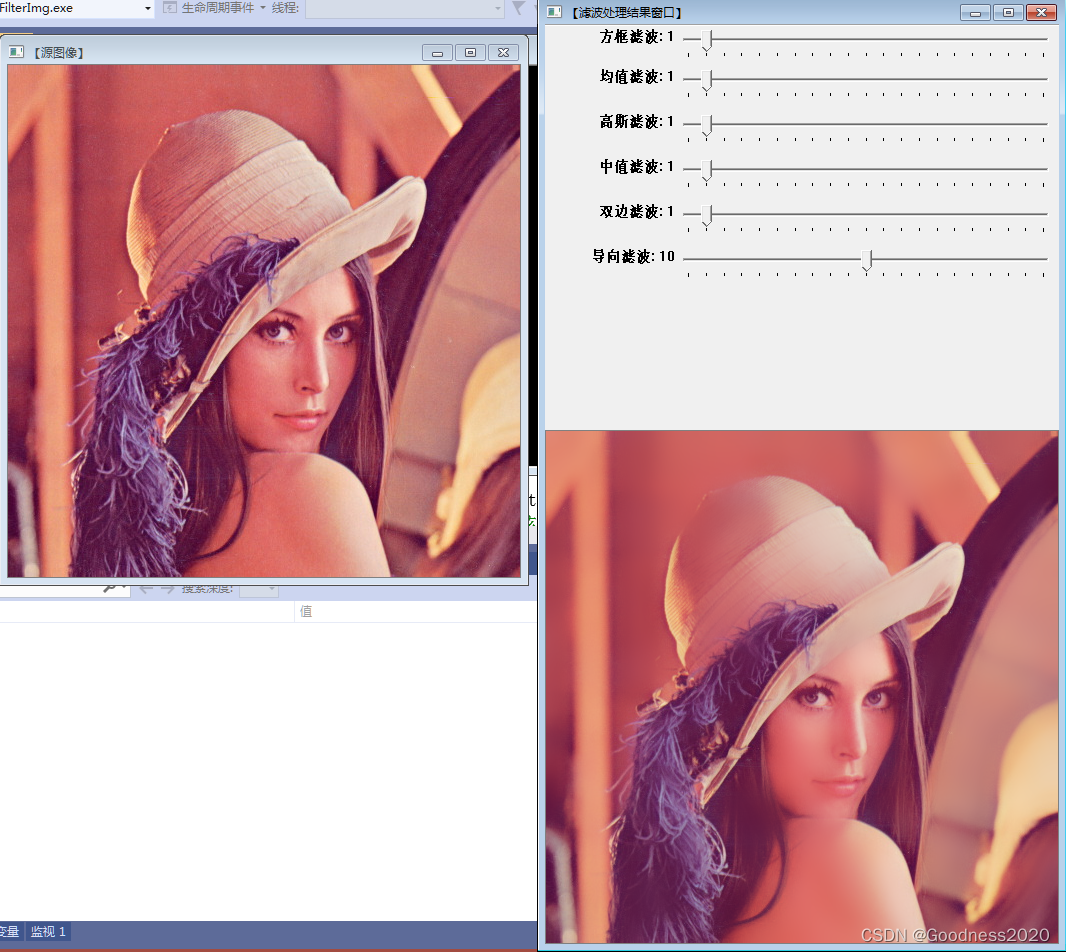
基于opencv的几种图像滤波
一、介绍 盒式滤波、均值滤波、高斯滤波、中值滤波、双边滤波、导向滤波。 boxFilter() blur() GaussianBlur() medianBlur() bilateralFilter() 二、代码 #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> …...
puppeteer代理的搭建和配置
puppeteer代理的搭建和配置 本文深入探讨了Puppeteer在网络爬虫和自动化测试中的重要角色,着重介绍了如何搭建和配置代理服务器,以优化Puppeteer的功能和性能。文章首先介绍了Puppeteer作为一个强大的Headless浏览器自动化工具的优势和应用场景…...
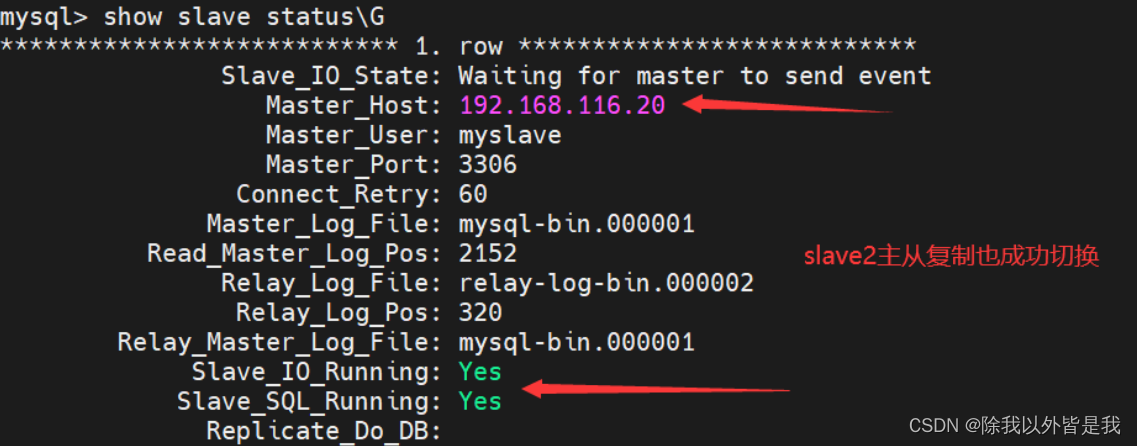
【简单认识MySQL的MHA高可用配置】
文章目录 一、简介1、概述2、MHA 的组成3.MHA 的特点4、MHA工作原理 二、搭建MHA高可用数据库群集1.主从复制2.MHA配置 三、故障模拟四、故障修复步骤: 一、简介 1、概述 MHA(Master High Availability)是一套优秀的MySQL高可用…...
【云原生】一文学会Docker存储所有特性
目录 1.Volumes 1.Volumes使用场景 2.持久将资源存放 3. 只读挂载 2.Bind mount Bind mounts使用场景 3.tmpfs mounts使用场景 4.Bind mounts和Volumes行为上的差异 5.docker file将存储内置到镜像中 6.volumes管理 1.查看存储卷 2.删除存储卷 3.查看存储卷的详细信息…...

Android Ble蓝牙App(一)扫描
Ble蓝牙App(一)扫描 前言正文一、基本配置二、扫描准备三、扫描页面① 增加UI布局② 点击监听③ 扫描处理④ 广播处理 四、权限处理五、扫描结果① 列表适配器② 扫描结果处理③ 接收结果 六、源码 前言 关于低功耗的蓝牙介绍我已经做过很多了࿰…...
mac pd安装ubuntu并配置远程连接
背景 一个安静的下午,我又想去折腾点什么了。准备学习一下k8s的,但是没有服务器。把我给折腾的,在抱怨了:为什么M系列芯片的资源怎么这么少。 好在伙伴说,你可以尝试一下ubantu。于是,我只好在我的mac上安…...
1.3 eureka+ribbon,完成服务注册与调用,负载均衡源码追踪
本篇继先前发布的1.2 eureka注册中心,完成服务注册的内容。 目录 环境搭建 采用eurekaribbon的方式,对多个user服务发送请求,并实现负载均衡 负载均衡原理 负载均衡源码追踪 负载均衡策略 如何选择负载均衡策略? 饥饿加载…...

mysql修改字段长度是否锁表
Varchar对于小于等于255字节以内的长度可以使用一个byte 存储。大于255个字节的长度则需要使用2个byte存储 1, 如果是255长度之内的扩展,或者255之外的扩展,则不锁表,采用in-place方式执行 2, 如果从varchar长度从(0,2…...
)
别再让日志拖慢你的服务器!深入对比C++同步与异步日志的性能差异(附TinyWebServer实测)
C服务器日志性能优化实战:同步与异步方案深度对比 当你的Web服务器开始承载真实流量时,那些看似无害的日志语句可能正在悄悄吞噬着系统性能。我曾在一个电商促销日亲眼目睹,由于同步日志的阻塞导致服务器响应时间从50ms飙升到800ms࿰…...

circumflex 语法高亮功能详解:让评论和文章更易读的终极指南
circumflex 语法高亮功能详解:让评论和文章更易读的终极指南 【免费下载链接】circumflex 🌿 Its Hacker News in your terminal 项目地址: https://gitcode.com/gh_mirrors/ci/circumflex circumflex 是一个强大的终端 Hacker News 浏览器&#…...

分布式团队的代码协作规范:从分支策略到提交信息格式
在分布式团队模式下,代码协作的地域分散、时区差异和沟通成本,给版本控制和质量保障带来了严峻挑战。作为软件测试从业者,我们不仅是代码质量的“守门员”,更需要深入理解并推动执行规范的代码协作流程,从分支管理到提…...

pytest Code Review skill.md
Skills 架构设计 本文深入探讨 Agent Skills 的技术架构和设计理念,帮助你理解 Skills 如何高效地扩展 Claude 的能力。 核心设计理念 Agent Skills 采用**渐进式披露(Progressive Disclosure)**架构,这是一种现代软件工程中的…...

什么样的落地灯对小孩看书好?家长首选落地灯推荐清单,优选品质
选护眼大路灯这事吧,我以前也踩过坑:有的灯亮是亮,但眩光明显,盯久了眼睛就发干;还有的调亮度很难掌控,忽明忽暗看着就累。所以我比较在意什么样的落地灯对小孩看书好?下面给大家挑了5款口碑不错…...

Diablo Edit2:5分钟掌握暗黑破坏神2终极角色编辑器
Diablo Edit2:5分钟掌握暗黑破坏神2终极角色编辑器 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否厌倦了在暗黑破坏神2中反复刷装备的无尽循环?是否因为技能点分配失…...

通过TaotokenCLI工具一键配置多开发环境提升团队协作效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置多开发环境提升团队协作效率 在团队协作开发中,一个常见的挑战是确保所有成员都能快速、…...

Servlet 容器与过滤器 超详细讲解
目录 一、Servlet 容器(Servlet Container) 1. 是什么? 2. 核心作用(必须掌握) 3. Servlet 生命周期(容器全权控制) 4. 工作流程(HTTP 请求完整链路) 5. 总结一句话 二、过滤器(Filter) 1. 是什么? 2. 核心特点 3. 过滤器能做什么?(高频场景) 4. 过滤…...

如何用Python快速接入Taotoken平台调用多款大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何用Python快速接入Taotoken平台调用多款大模型 对于希望便捷使用多种大语言模型的开发者而言,逐一对接不同厂商的AP…...

硬件工程师效率翻倍:我是如何让Cadence OrCAD导出的PDF自动生成清晰书签目录的
硬件工程师效率革命:用OrCAD打造智能PDF文档工作流 在硬件设计领域,一份结构清晰的原理图PDF文档往往能大幅提升团队协作效率。想象一下这样的场景:当你将精心设计的电路方案交付给客户或跨部门同事时,对方打开的是一个带有智能书…...