简单的知识图谱可视化+绘制nx.Graph()时报错TypeError: ‘_AxesStack‘ object is not callable
绘制nx.Graph时报错TypeError: '_AxesStack' object is not callable
- 写在最前面
- 知识图谱可视化
- 预期
- 报错
- 可能的原因
- 原代码
- 原因确认
- 解决后的代码
- 解决!
写在最前面
实现一个简单的知识图谱的可视化功能。
使用了NetworkX库来构建知识图谱,并使用matplotlib库来绘制图形。
过几天将发布关于#通过noe4j可视化知识图谱#的文章
细节上还在优化
题外话,构建知识图谱真的好慢啊,尤其是自动构建实体之间的关系,代码要跑好久好久
而且不算论文中的创新点,感觉有点鸡肋
知识图谱可视化
知识图谱可视化是将知识图谱的数据以图形化的方式展示出来,以便更加直观地理解、分析和探索知识图谱中的关系与信息。
可以通过交互式的图形界面,对知识图谱中的关系和概念进行探索和分析,并且能够自由地从宏观到微观地进行导航和浏览。
可以应用于搜索引擎、推荐系统、医学研究、商业智能、社交网络、金融分析等领域。
预期
绘制nx.Graph()的graph
报错
TypeError: ‘_AxesStack’ object is not callable
nx.draw(graph, pos, with_labels=True, node_size=3000, font_size=12, node_color='skyblue', font_weight='bold', alpha=0.8, linewidths=0, edge_color='gray')9 plt.title("Knowledge Graph")10 plt.show()File D:\Program\Anaconda\lib\site-packages\networkx\drawing\nx_pylab.py:113, in draw(G, pos, ax, **kwds)111 cf.set_facecolor("w")112 if ax is None:
--> 113 if cf._axstack() is None:114 ax = cf.add_axes((0, 0, 1, 1))115 else:TypeError: '_AxesStack' object is not callable<Figure size 1000x800 with 0 Axes>
可能的原因
这个错误是由于在绘制图形时调用了一个不可调用的对象 _AxesStack,通常这与与变量或函数名冲突有关。检查你的代码是否有其他地方使用了名为 plt 或 ax 的变量或函数,导致了该错误。
以下是可能导致问题的一些常见原因和解决方法:
-
确保
plt是 Matplotlib 的 pyplot 对象,并且没有在其他地方被重新定义。在使用plt之前,可以尝试在代码的开头添加import matplotlib.pyplot as plt。 -
确保没有将变量名
ax分配为 Axes 对象。Axes 对象是由plt.subplots()或plt.add_axes()等函数返回的,因此如果使用ax作为一个普通变量,可能会导致冲突。 -
可能是代码中的其他部分修改了 Matplotlib 的默认行为,导致
AxesStack不可调用。请检查在绘制图形之前是否有任何涉及 Matplotlib 的自定义设置或修改。
在确认以上问题之后,可以尝试修改代码,并确保绘图部分没有与之前提到的问题冲突,从而避免该错误的出现。
原代码
定义了一个名为draw_graph的函数,该函数接受一个图形对象作为参数,并在绘图中显示该图形。main函数创建了一个空的图形对象,并添加了一些节点和边。
import networkx as nx
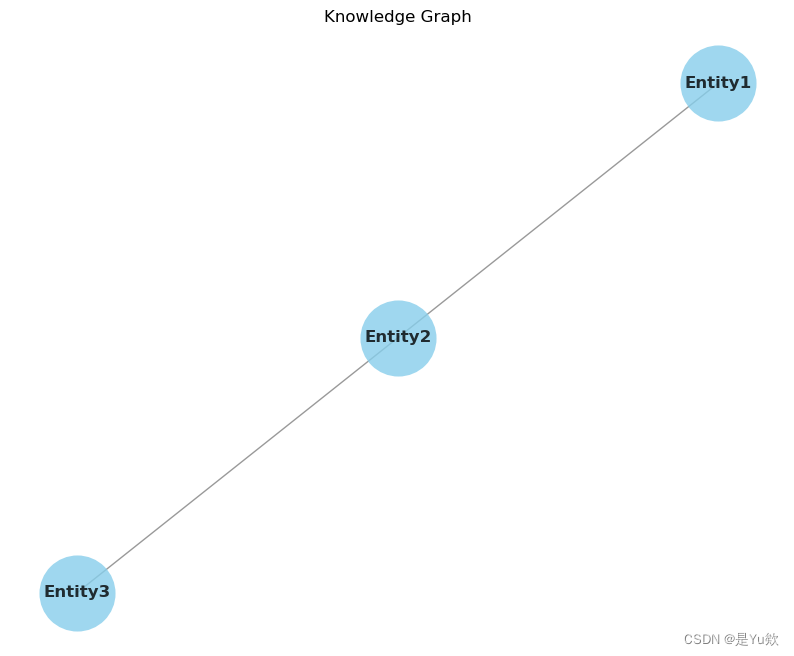
import matplotlib.pyplot as pltdef draw_graph(graph):pos = nx.spring_layout(graph, seed=42)# 下面这行代码有问题,已修改为# fig, ax = plt.subplots(figsize=(10, 8))plt.figure(figsize=(10, 8))nx.draw(graph, pos, with_labels=True, node_size=3000, font_size=12, node_color='skyblue', font_weight='bold', alpha=0.8, linewidths=0, edge_color='gray')plt.title("Knowledge Graph")plt.show()def main():# 假设已构建好知识图谱graph = nx.Graph()graph.add_nodes_from(["Entity1", "Entity2", "Entity3"])graph.add_edges_from([("Entity1", "Entity2"), ("Entity2", "Entity3")])draw_graph(graph)if __name__ == "__main__":main()原因确认
我遇到的是第二个原因:因为与 Matplotlib 的 Axes 对象(ax)冲突。
为了解决这个问题,尝试在绘制图形时明确指定 Axes 对象。在 plt.subplots() 中创建一个新的 Axes 对象,然后将其传递给 nx.draw() 函数。
解决后的代码
import networkx as nx
import matplotlib.pyplot as pltdef draw_graph(graph):pos = nx.spring_layout(graph, seed=42) # You can use different layout algorithmsfig, ax = plt.subplots(figsize=(10, 8))nx.draw(graph, pos, with_labels=True, node_size=3000, font_size=12, node_color='skyblue', font_weight='bold', alpha=0.8, linewidths=0, edge_color='gray', ax=ax)ax.set_title("Knowledge Graph")plt.show()def main():# 假设已构建好知识图谱graph = nx.Graph()graph.add_nodes_from(["Entity1", "Entity2", "Entity3"])graph.add_edges_from([("Entity1", "Entity2"), ("Entity2", "Entity3")])draw_graph(graph)if __name__ == "__main__":main()解决!
相关文章:
简单的知识图谱可视化+绘制nx.Graph()时报错TypeError: ‘_AxesStack‘ object is not callable
绘制nx.Graph时报错TypeError: _AxesStack object is not callable 写在最前面知识图谱可视化预期报错可能的原因 原代码原因确认解决后的代码解决! 写在最前面 实现一个简单的知识图谱的可视化功能。 使用了NetworkX库来构建知识图谱,并使用matplotlib…...
)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码5.1 fun.m5.2 main.m6.完整代码6.1 fun.m6.2 main.m7.运行结果1.模型原理 基于粒子群优化算法(Particle Swarm Optimization, PSO)优…...
【机器学习】Cost Function for Logistic Regression
Cost Function for Logistic Regression 1. 平方差能否用于逻辑回归?2. 逻辑损失函数loss3. 损失函数cost附录 导入所需的库 import numpy as np %matplotlib widget import matplotlib.pyplot as plt from plt_logistic_loss import plt_logistic_cost, plt_two_…...

【EI/SCOPUS会议征稿】2023年第四届新能源与电气科技国际学术研讨会 (ISNEET 2023)
作为全球科技创新大趋势的引领者,中国一直在为科技创新创造越来越开放的环境,提高学术合作的深度和广度,构建惠及全民的创新共同体。这些努力为全球化和创建共享未来的共同体做出了新的贡献。 为交流近年来国内外在新能源和电气技术领域的最新…...
【计算机网络】10、ethtool
文章目录 一、ethtool1.1 常见操作1.1.1 展示设备属性1.1.2 改变网卡属性1.1.2.1 Auto-negotiation1.1.2.2 Speed 1.1.3 展示网卡驱动设置1.1.4 只展示 Auto-negotiation, RX and TX1.1.5 展示统计1.1.7 排除网络故障1.1.8 通过网口的 LED 区分网卡1.1.9 持久化配置(…...

什么是前端工程化?
工程化介绍 什么是前端工程化? 前端工程化是一种思想,而不是某种技术。主要目的是为了提高效率和降低成本,也就是说在开发的过程中可以提高开发效率,减少不必要的重复性工作等。 tip 现实生活举例 建房子谁不会呢?请…...

【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程
【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程 文章目录 【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程前言确定版本对应关系源码编译安装tiny-cuda-nn总结 前言 本人windows11下使用【Instant Neural Surface Reconstruction】算法时需要…...

Matlab 一种自适应搜索半径的特征提取方法
文章目录 一、简介二、实现代码参考资料一、简介 在之前的博客(C++ ID3决策树)中,提到过一种信息熵的概念,其中它表达的大致意思为:香农认为熵是指“当一件事情有多种可能情况时,这件事情发生某种情况的不确定性”,也就是指如果一个事情的不确定性越大,那么这个信息的熵…...
基于opencv的几种图像滤波
一、介绍 盒式滤波、均值滤波、高斯滤波、中值滤波、双边滤波、导向滤波。 boxFilter() blur() GaussianBlur() medianBlur() bilateralFilter() 二、代码 #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> …...
puppeteer代理的搭建和配置
puppeteer代理的搭建和配置 本文深入探讨了Puppeteer在网络爬虫和自动化测试中的重要角色,着重介绍了如何搭建和配置代理服务器,以优化Puppeteer的功能和性能。文章首先介绍了Puppeteer作为一个强大的Headless浏览器自动化工具的优势和应用场景…...
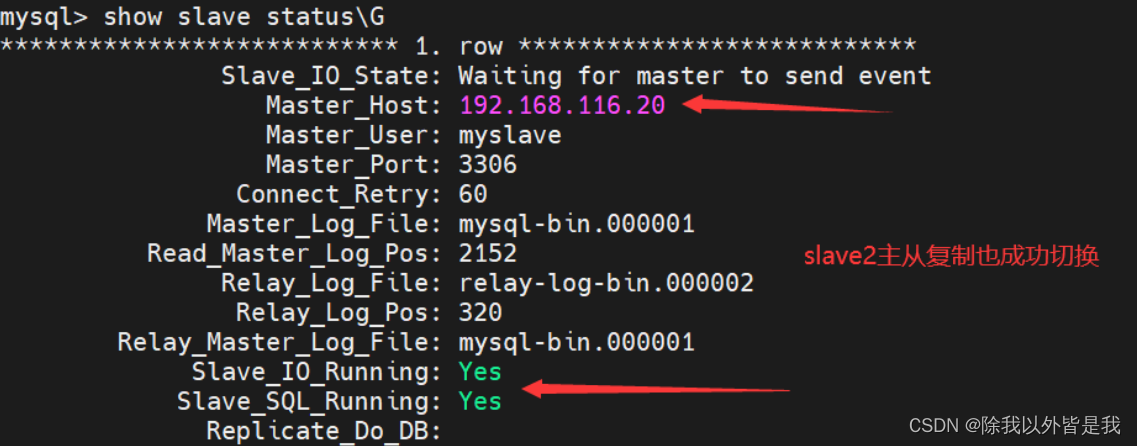
【简单认识MySQL的MHA高可用配置】
文章目录 一、简介1、概述2、MHA 的组成3.MHA 的特点4、MHA工作原理 二、搭建MHA高可用数据库群集1.主从复制2.MHA配置 三、故障模拟四、故障修复步骤: 一、简介 1、概述 MHA(Master High Availability)是一套优秀的MySQL高可用…...
【云原生】一文学会Docker存储所有特性
目录 1.Volumes 1.Volumes使用场景 2.持久将资源存放 3. 只读挂载 2.Bind mount Bind mounts使用场景 3.tmpfs mounts使用场景 4.Bind mounts和Volumes行为上的差异 5.docker file将存储内置到镜像中 6.volumes管理 1.查看存储卷 2.删除存储卷 3.查看存储卷的详细信息…...

Android Ble蓝牙App(一)扫描
Ble蓝牙App(一)扫描 前言正文一、基本配置二、扫描准备三、扫描页面① 增加UI布局② 点击监听③ 扫描处理④ 广播处理 四、权限处理五、扫描结果① 列表适配器② 扫描结果处理③ 接收结果 六、源码 前言 关于低功耗的蓝牙介绍我已经做过很多了࿰…...
mac pd安装ubuntu并配置远程连接
背景 一个安静的下午,我又想去折腾点什么了。准备学习一下k8s的,但是没有服务器。把我给折腾的,在抱怨了:为什么M系列芯片的资源怎么这么少。 好在伙伴说,你可以尝试一下ubantu。于是,我只好在我的mac上安…...
1.3 eureka+ribbon,完成服务注册与调用,负载均衡源码追踪
本篇继先前发布的1.2 eureka注册中心,完成服务注册的内容。 目录 环境搭建 采用eurekaribbon的方式,对多个user服务发送请求,并实现负载均衡 负载均衡原理 负载均衡源码追踪 负载均衡策略 如何选择负载均衡策略? 饥饿加载…...

mysql修改字段长度是否锁表
Varchar对于小于等于255字节以内的长度可以使用一个byte 存储。大于255个字节的长度则需要使用2个byte存储 1, 如果是255长度之内的扩展,或者255之外的扩展,则不锁表,采用in-place方式执行 2, 如果从varchar长度从(0,2…...
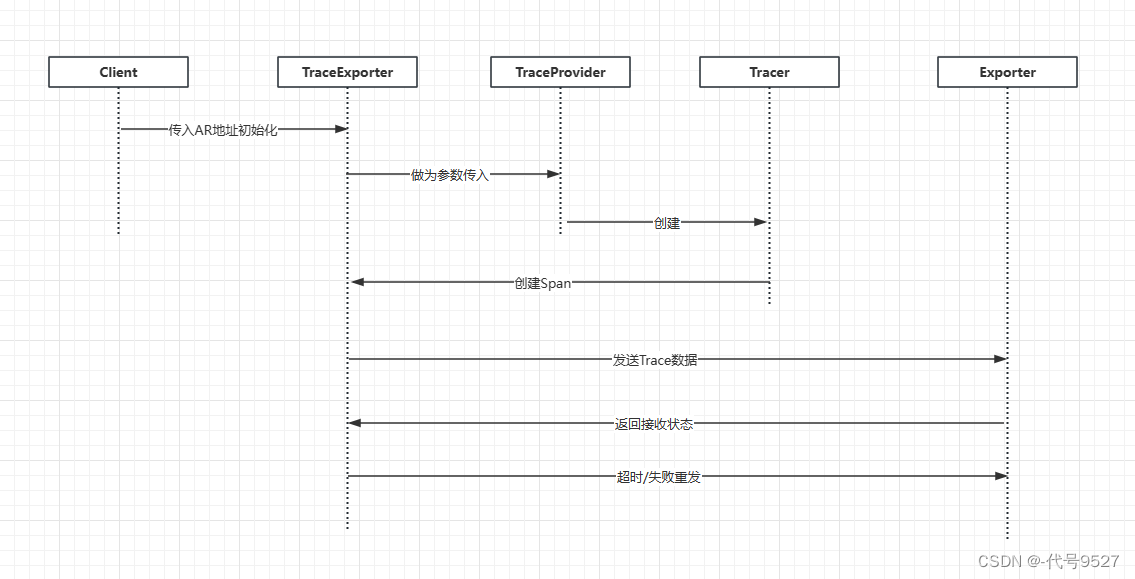
SpringCloud集成OpenTelemetry的实现
SpringCloud项目做链路追踪,比较常见的会集成SleuthZipKin来完成,但这次的需求要集成开源框架OpenTelemetry,这里整理下实现过程。相关文章: 【SpringCloud集成SleuthZipkin进行链路追踪】 【OpenTelemetry框架Trace部分整理】 …...
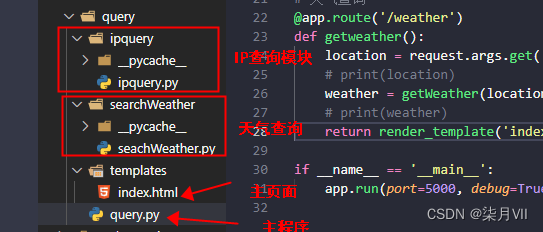
Python爬取IP归属地信息及各个地区天气信息
一、实现样式 二、核心点 1、语言:Python、HTML,CSS 2、python web框架 Flask 3、三方库:requests、xpath 4、爬取网站:https://ip138.com/ 5、文档结构 三、代码 ipquery.py import requests from lxml import etree # 请求…...
RedLock + Redisson
目录 2.9 RedLock2.9.1 上述实现的分布式锁在集群状态下失效的原因2.9.2 解决方式-RedLock 2.10 redisson中的分布式锁2.10.0 redisson简介以及简单使用简单使用redisson中的锁Redisson常用配置 2.10.1 Redisson可重入锁实现原理2.10.2 公平锁(Fair Lock)…...
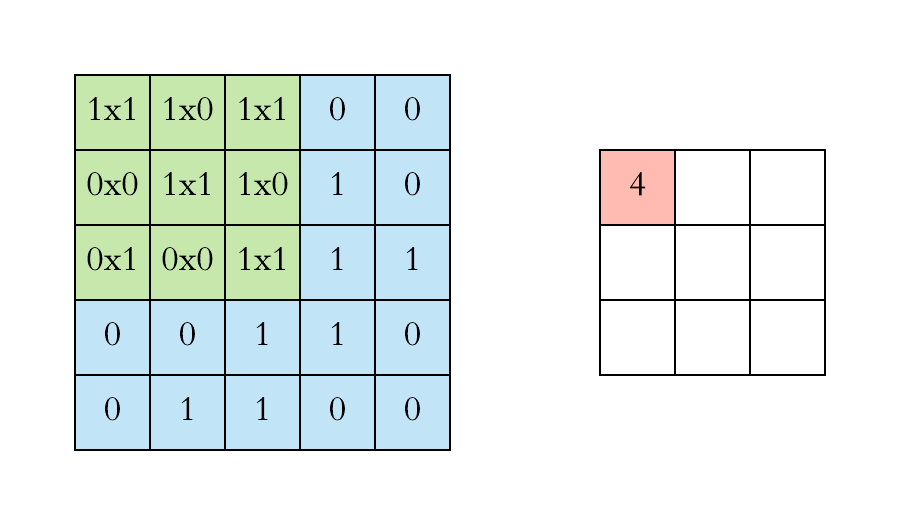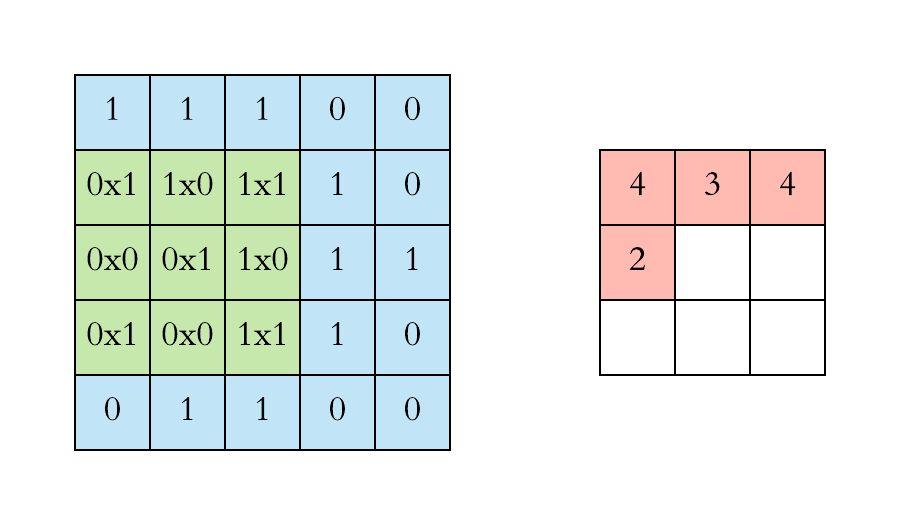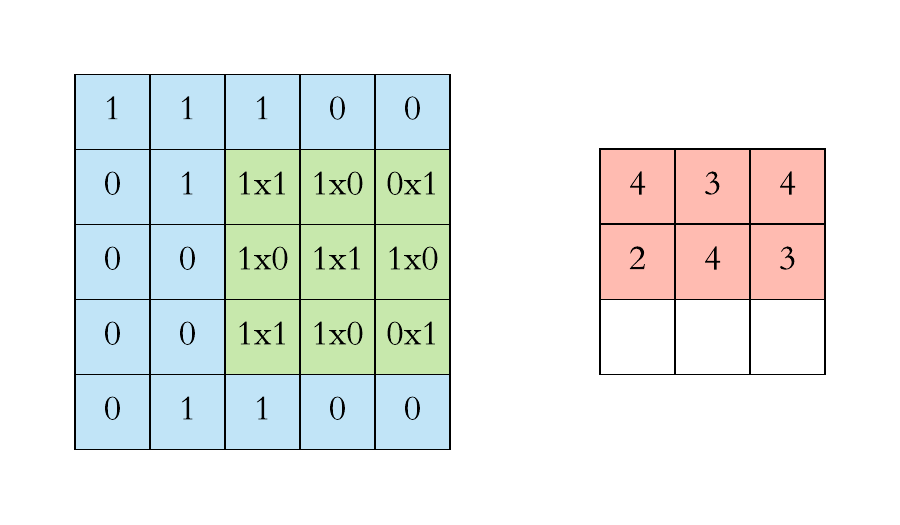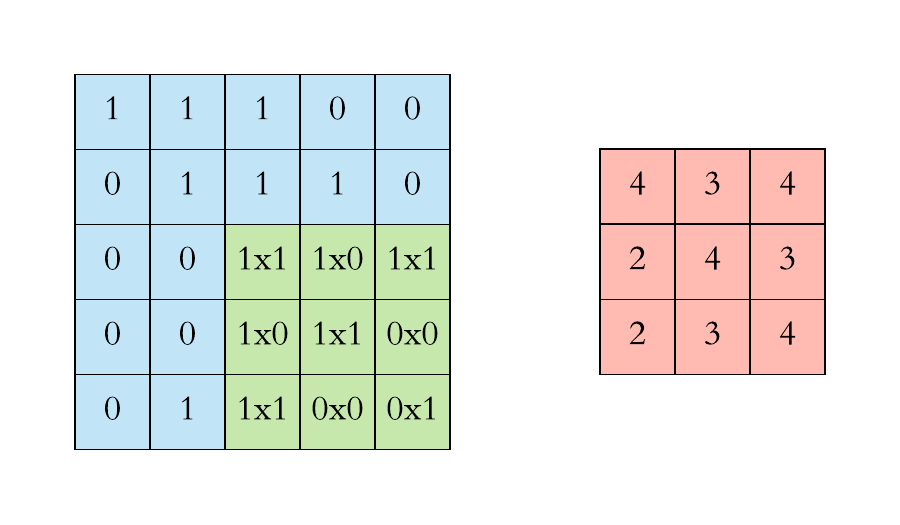
计算机视觉:卷积层的参数量是多少?
本文重点 卷积核的参数量是卷积神经网络中一个重要的概念,它决定了网络的复杂度和计算量。在深度学习中,卷积操作是一种常用的操作,用于提取图像、语音等数据中的特征。卷积神经网络的优势点在于稀疏连接和权值共享,这使得卷积核的参数相较于传统的神经网络要少很多。 举例…...

3分钟解锁:让魔兽争霸3在现代Windows系统上完美运行的完整指南
3分钟解锁:让魔兽争霸3在现代Windows系统上完美运行的完整指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Wind…...

作业5:案例挑战
文章目录1、密码锁设计 P110,2、基于PWM的可调光台灯设计 P131,3、动态密码获取系统设计 P210,效果(1) 密码模式说明(2) 测试密码输入(3) 测试修改密码(4) 测试修改密码模式4、数码管时钟系统设计 P228,7.5.2 数码管时钟系统设计&…...

线粒体氧化磷酸化的新靶点:S-Gboxin的发现与研究进展
在肿瘤治疗的探索历程中,科学家们始终在寻找能够精准打击癌细胞而又最大限度保护正常组织的新型药物。2019年,一项发表在Nature杂志上的研究引起了学界广泛关注——施宇峰团队首次报道了Gboxin这一化合物的发现与独特的作用机制[1]。作为Gboxin的代谢稳定…...

Unity 2D开发第一课:建立空间直觉与项目根基
1. 为什么“Unity 2D 游戏开发教程(一)”不是从“新建项目”开始讲起 很多人点开标题叫“Unity 2D 游戏开发教程(一)”的视频或文章,第一帧就看到编辑器界面、鼠标点“New Project”、输入项目名、选模板——然后心里一…...

虚幻5细节面板消失的真相与四步唤醒方案
1. 这不是Bug,是虚幻5蓝图编辑器的“细节面板隐身术”在作祟2025年用虚幻引擎5做项目,突然发现蓝图编辑器右侧的细节面板(Details Panel)怎么点都不出来——节点选中了没反应,右键菜单里找不到“显示细节”,…...

如何快速突破百度网盘限速:高效下载工具终极指南
如何快速突破百度网盘限速:高效下载工具终极指南 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 百度网盘作为国内最流行的云存储平台,其下载速度限制一…...

Stata小白也能搞定的空间面板回归:从莫兰检验到效应分解保姆级教程
Stata空间面板回归实战:从数据准备到结果解读的全流程指南 空间计量经济学正在成为区域经济、环境科学等领域研究的热点方法。但对于许多初学者来说,面对复杂的空间权重矩阵构建和各种检验步骤时,常常感到无从下手。本文将用最直观的方式&…...

2026年局域网考试系统选型对比:优考试助力政企信创与内网安全
在数字政府与信创产业全面推进的当下,政企、事业单位及涉密单位的考试场景,正面临国产化适配、数据安全、灵活部署三重核心要求。既要满足内网环境下的数据安全与物理隔离,又要兼顾部分场景下外网访问的灵活性,传统单一架构考试系…...
的介绍说明)
关于国内SDR(成都振芯)的介绍说明
概述 软件无线电(SDR)是一种无线电通信技术,其关键功能(如调制解调、滤波、变频等)通过软件在可编程硬件(如FPGA、DSP)上实现,而非依赖固定的硬件电路。这使得无线电设备具有高度的灵…...

巴别鸟vs坚果云:企业云盘同步机制踩坑与实战配置
干企业网盘这行,最怕听到用户说"同步慢"。我们2019年上线第一版云盘时,同步1GB的CAD图纸包要40分钟,用户骂完就跑。踩了三年坑才知道,"能同步"和"同步好用"根本是两回事。 本文从踩坑实录加配置实战…...