Spark SQL报错: Task failed while writing rows.
错误
今天运行 Spark 任务时报了一个错误,如下所示:
WARN scheduler.TaskSetManager: Lost task 9.0 in stage 3.0 (TID 69, xxx.xxx.xxx.com, executor 3): org.apache.spark.SparkException: Task failed while writing rows.at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:254)at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:169)at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$write$1.apply(FileFormatWriter.scala:168)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)at org.apache.spark.scheduler.Task.run(Task.scala:121)at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:402)at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1360)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:408)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NullPointerExceptionat java.lang.System.arraycopy(Native Method)at org.apache.hadoop.hive.ql.io.orc.DynamicByteArray.add(DynamicByteArray.java:115)at org.apache.hadoop.hive.ql.io.orc.StringRedBlackTree.addNewKey(StringRedBlackTree.java:48)at org.apache.hadoop.hive.ql.io.orc.StringRedBlackTree.add(StringRedBlackTree.java:55)at org.apache.hadoop.hive.ql.io.orc.WriterImpl$StringTreeWriter.write(WriterImpl.java:1211)at org.apache.hadoop.hive.ql.io.orc.WriterImpl$StructTreeWriter.write(WriterImpl.java:1734)at org.apache.hadoop.hive.ql.io.orc.WriterImpl.addRow(WriterImpl.java:2403)at org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat$OrcRecordWriter.write(OrcOutputFormat.java:86)at org.apache.spark.sql.hive.execution.HiveOutputWriter.write(HiveFileFormat.scala:149)at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.write(FileFormatDataWriter.scala:137)at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:242)at org.apache.spark.sql.execution.datasources.FileFormatWriter$$anonfun$org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask$3.apply(FileFormatWriter.scala:239)at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1394)at org.apache.spark.sql.execution.datasources.FileFormatWriter$.org$apache$spark$sql$execution$datasources$FileFormatWriter$$executeTask(FileFormatWriter.scala:245)...
ORC 仅在 HiveContext 中受支持,但这里使用 SQLContext。
解决办法
SQLContext 存在一些问题,尝试使用 HiveContext。 使用以下配置来解决:
spark.sql.orc.impl=native
native 和 hive 二选一,native 是基于 ORC1.4,表示使用 Spark SQL 提供的本地ORC实现方式。hive 是基于 Hive 的 ORC1.2.1
相关文章:

Spark SQL报错: Task failed while writing rows.
错误 今天运行 Spark 任务时报了一个错误,如下所示: WARN scheduler.TaskSetManager: Lost task 9.0 in stage 3.0 (TID 69, xxx.xxx.xxx.com, executor 3): org.apache.spark.SparkException: Task failed while writing rows.at org.apache.spark.sq…...
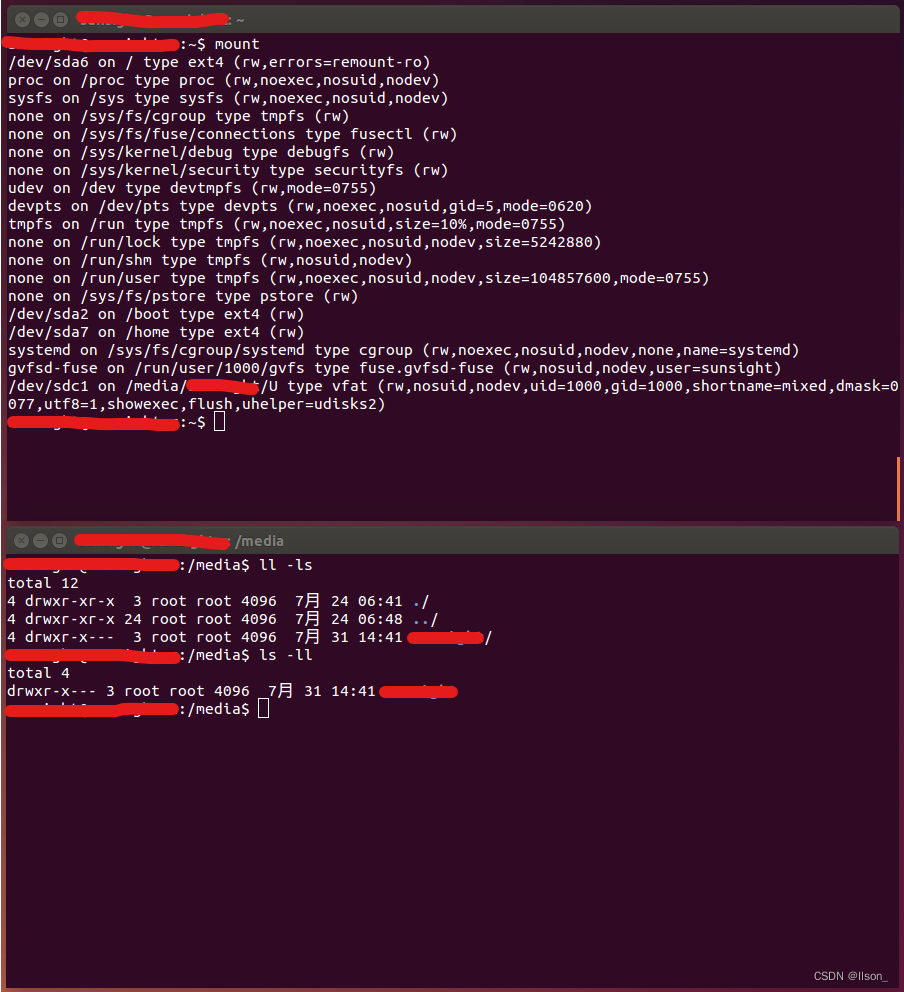
Linux系统下U盘打不开: No application is registered as handling this file
简述 系统是之前就安装好使用的Ubuntu14.04,不过由于某些原因只安装到了机械硬盘中;最近新买了一块固态硬盘,所以打算把Ubuntu系统迁移到新的固态硬盘上; 当成功的迁移了系统之后发现其引导有点问题,导致多个系统启动不…...

07 定时器处理非活动连接(上)
07 定时器处理非活动连接(上) 基础知识 非活跃,是指客户端(这里是浏览器)与服务器端建立连接后,长时间不交换数据,一直占用服务器端的文件描述符,导致连接资源的浪费。 定时事件&a…...
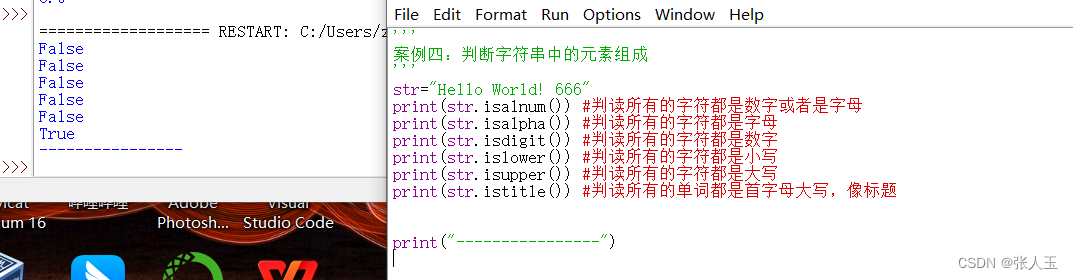
python——案例四:判断字符串中的元素组成
案例四:判断字符串中的元素组成str"Hello World! 666" print(str.isalnum()) #判读所有的字符都是数字或者是字母 print(str.isalpha()) #判读所有的字符都是字母 print(str.isdigit()) #判读所有的字符都是数字 print(str.islower()) #判读所有的字符都是…...
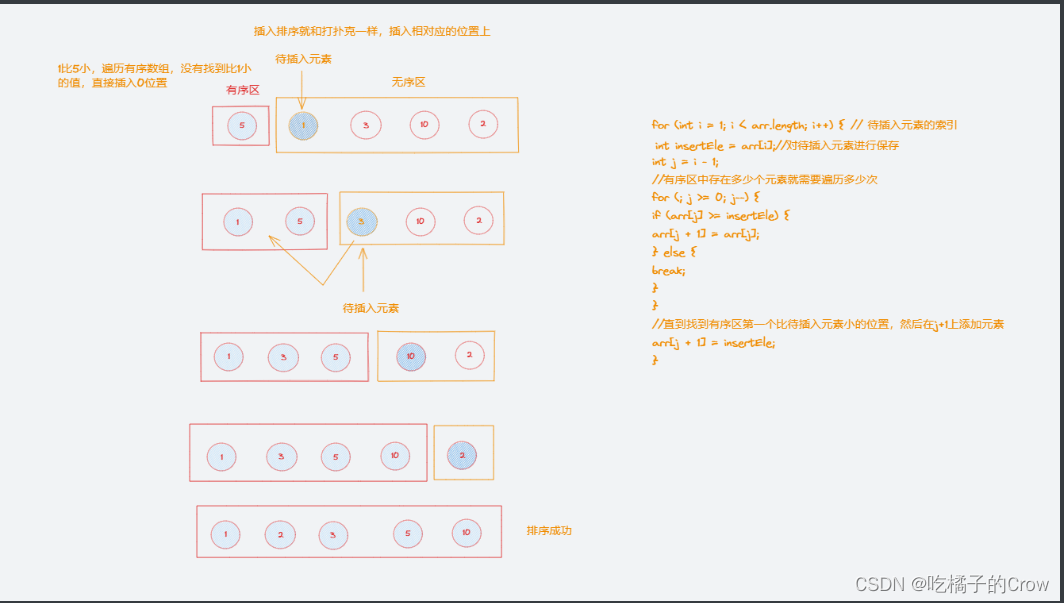
一起学算法(插入排序篇)
概念: 插入排序(inertion Sort)一般也被称为直接插入排序,是一种简单的直观的排序算法 工作原理:将待排列元素划分为(已排序)和(未排序)两部分,每次从&…...
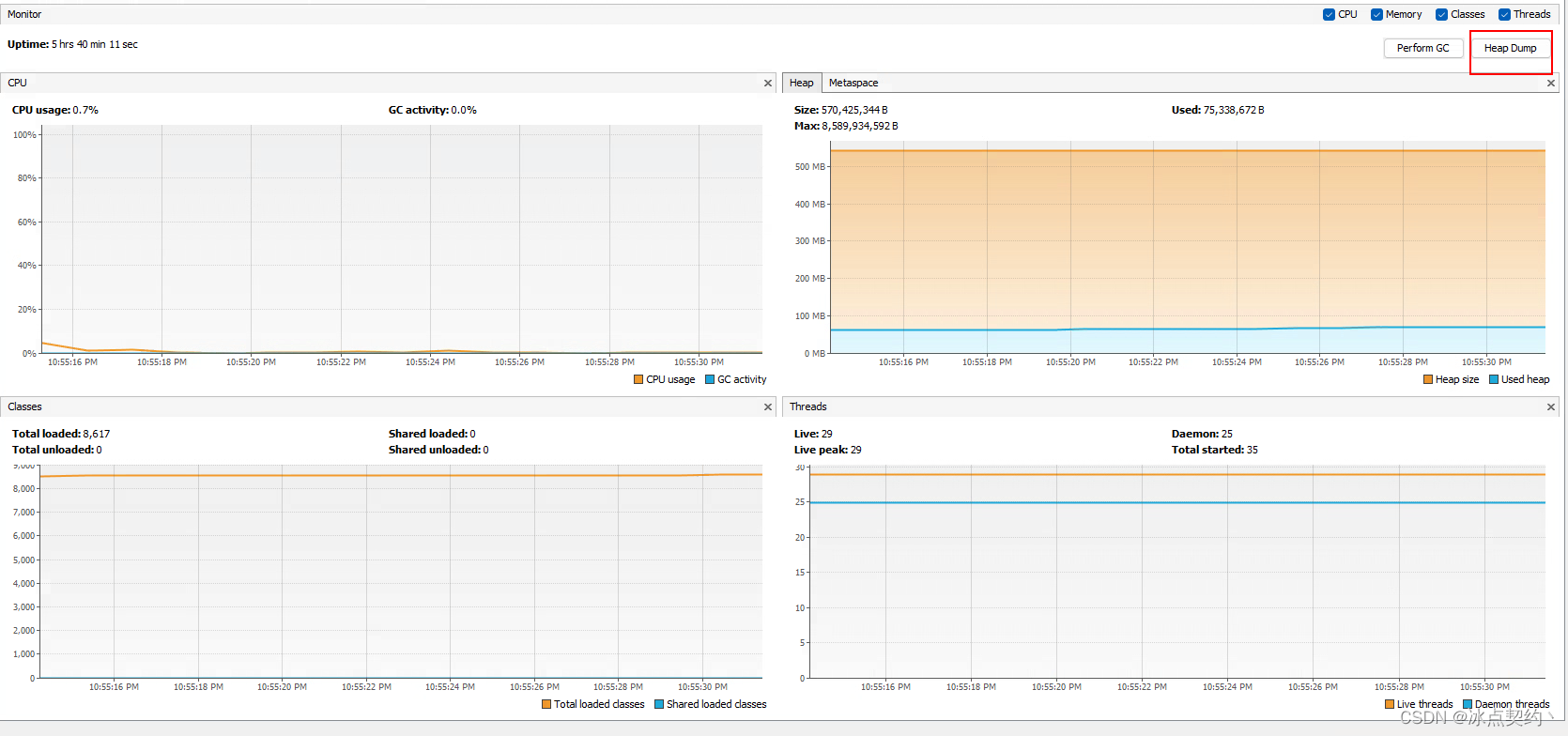
JVM基础篇-本地方法栈与堆
JVM基础篇-本地方法栈与堆 本地方法栈 什么是本地方法? 本地方法即那些不是由java层面实现的方法,而是由c/c实现交给java层面进行调用,这些方法在java中使用native关键字标识 public native int hashCode()本地方法栈的作用? 为本地方法提供内存空…...
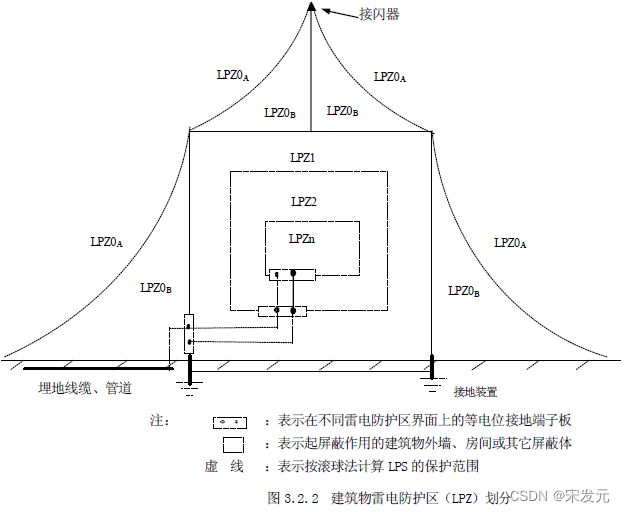
防雷保护区如何划分,防雷分区概念LPZ介绍
在防雷设计中,很重要的一点就是防雷分区的划分,只有先划分好防雷区域等级,才好做出比较好的防雷器设计方案。 因为标准对不同区安装的防雷浪涌保护器要求是不一样的。 那么,防雷保护区是如何划分的呢? 如上图所示&…...

随手笔记——3D−3D:ICP求解
随手笔记——3D−3D:ICP求解 使用 SVD 求解 ICP使用非线性优化来求解 ICP 原理参见 https://blog.csdn.net/jppdss/article/details/131919483 使用 SVD 求解 ICP 使用两幅 RGB-D 图像,通过特征匹配获取两组 3D 点,最后用 ICP 计算它们的位…...

Python调用各大机器翻译API大全
过去的二三年中,我一直关注的是机器翻译API在自动化翻译过程中的应用,包括采用CAT工具和Python编程语言来调用机器翻译API,然后再进行译后编辑,从而达到快速翻译的目的。 然而,我发现随着人工智能的发展,很…...

重生之我要学C++第六天
这篇文章的主要内容是const以及权限问题、static关键字、友元函数和友元类,希望对大家有所帮助,点赞收藏评论支持一下吧! 更多优质内容跳转: 专栏:重生之C启程(文章平均质量分93) 目录 const以及权限问题 1.const修饰…...

SpringBoot中ErrorPage(错误页面)的使用--【ErrorPage组件】
SpringBoot系列文章目录 SpringBoot知识范围-学习步骤–【思维导图知识范围】 文章目录 SpringBoot系列文章目录本系列校训 SpringBoot技术很多很多环境及工具:必要的知识深层一些的知识 上效果图在Spring Boot里使用ErrorPage还要注意的是 配套资源作业ÿ…...

【Android】APP网络优化学习笔记
网络优化原因 进行网络优化对于移动应用程序而言非常重要,原因如下: 用户体验: 网络连接是移动应用程序的核心功能之一。通过进行网络优化,可以提高应用的加载速度和响应速度,减少用户等待时间,提供更流…...
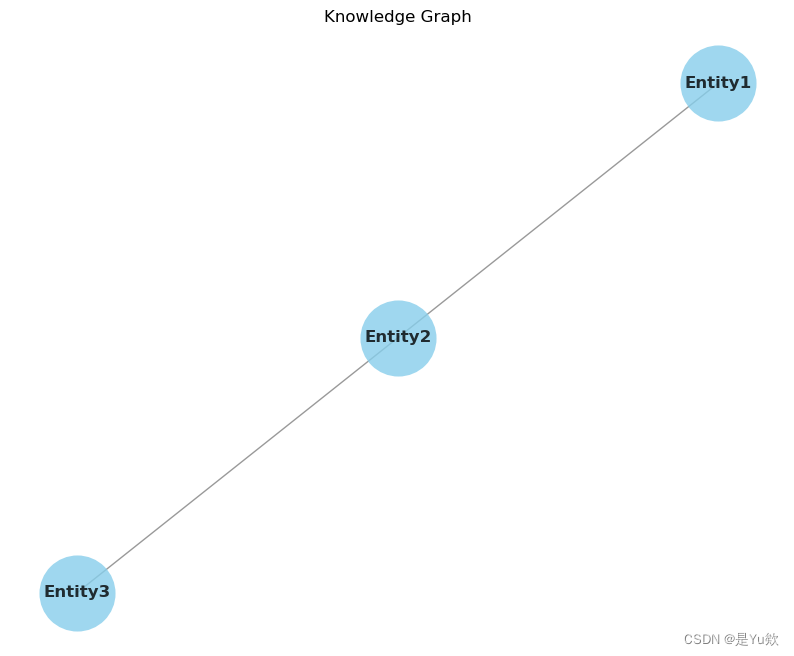
简单的知识图谱可视化+绘制nx.Graph()时报错TypeError: ‘_AxesStack‘ object is not callable
绘制nx.Graph时报错TypeError: _AxesStack object is not callable 写在最前面知识图谱可视化预期报错可能的原因 原代码原因确认解决后的代码解决! 写在最前面 实现一个简单的知识图谱的可视化功能。 使用了NetworkX库来构建知识图谱,并使用matplotlib…...
)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码5.1 fun.m5.2 main.m6.完整代码6.1 fun.m6.2 main.m7.运行结果1.模型原理 基于粒子群优化算法(Particle Swarm Optimization, PSO)优…...
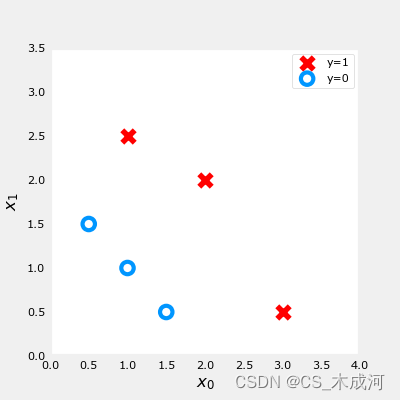
【机器学习】Cost Function for Logistic Regression
Cost Function for Logistic Regression 1. 平方差能否用于逻辑回归?2. 逻辑损失函数loss3. 损失函数cost附录 导入所需的库 import numpy as np %matplotlib widget import matplotlib.pyplot as plt from plt_logistic_loss import plt_logistic_cost, plt_two_…...

【EI/SCOPUS会议征稿】2023年第四届新能源与电气科技国际学术研讨会 (ISNEET 2023)
作为全球科技创新大趋势的引领者,中国一直在为科技创新创造越来越开放的环境,提高学术合作的深度和广度,构建惠及全民的创新共同体。这些努力为全球化和创建共享未来的共同体做出了新的贡献。 为交流近年来国内外在新能源和电气技术领域的最新…...
【计算机网络】10、ethtool
文章目录 一、ethtool1.1 常见操作1.1.1 展示设备属性1.1.2 改变网卡属性1.1.2.1 Auto-negotiation1.1.2.2 Speed 1.1.3 展示网卡驱动设置1.1.4 只展示 Auto-negotiation, RX and TX1.1.5 展示统计1.1.7 排除网络故障1.1.8 通过网口的 LED 区分网卡1.1.9 持久化配置(…...

什么是前端工程化?
工程化介绍 什么是前端工程化? 前端工程化是一种思想,而不是某种技术。主要目的是为了提高效率和降低成本,也就是说在开发的过程中可以提高开发效率,减少不必要的重复性工作等。 tip 现实生活举例 建房子谁不会呢?请…...

【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程
【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程 文章目录 【深度学习】【三维重建】windows11环境配置tiny-cuda-nn详细教程前言确定版本对应关系源码编译安装tiny-cuda-nn总结 前言 本人windows11下使用【Instant Neural Surface Reconstruction】算法时需要…...

Matlab 一种自适应搜索半径的特征提取方法
文章目录 一、简介二、实现代码参考资料一、简介 在之前的博客(C++ ID3决策树)中,提到过一种信息熵的概念,其中它表达的大致意思为:香农认为熵是指“当一件事情有多种可能情况时,这件事情发生某种情况的不确定性”,也就是指如果一个事情的不确定性越大,那么这个信息的熵…...

红队exe捆绑避坑指南:绕过EDR与邮件网关的可信交付实践
1. 这不是“打包器教学”,而是红队实战中反复摔打出来的交付逻辑在真实红队支撑或攻防演练中,我见过太多人把“exe捆绑”当成一个纯技术动作:msfvenom生成payload → 用Resource Hacker换图标 → 7-Zip加自解压 → 发给目标。结果呢ÿ…...

Tomcat DefaultServlet MIME类型处理缺陷导致信息泄露
1. 这个漏洞不是“能读文件”那么简单,而是Tomcat在特定配置下主动把不该暴露的内部状态当HTTP响应发出去了CVE-2024-21733这个编号刚出来时,我第一反应是又一个“目录遍历”或“文件读取”类的老套路。但真正花半天时间搭环境复现、抓包分析、翻Tomcat源…...

Python代码性能优化实战:从循环到并发的全方位加速技巧
1. 项目概述:为什么你的Python代码总是“慢半拍”?干了这么多年开发,我见过太多同事和学员写的Python代码,功能上没问题,逻辑也清晰,但就是跑起来“慢半拍”。尤其是在处理数据清洗、批量文件操作或者实现一…...

benchmark-ips源码剖析:理解Ruby性能测试的内部机制
benchmark-ips源码剖析:理解Ruby性能测试的内部机制 【免费下载链接】benchmark-ips Provides iteration per second benchmarking for Ruby 项目地址: https://gitcode.com/gh_mirrors/be/benchmark-ips 什么是benchmark-ips? benchmark-ips是一…...

6.解决 99% 刷机故障|GPT 分区修复 + SEP 兼容检测 + 全分区备份,工程师实战手册
摘要 本文面向具备基础Linux命令行操作能力的维修工程师与高级发烧友,系统阐述主流品牌手机刷机与维修的底层逻辑与标准化操作流程。内容覆盖高通、联发科、苹果A系列三大芯片平台的刷机协议差异,提供完整的刷机工具链搭建脚本、分区备份恢复脚本、以及底层驱动级故障诊断代…...

PHP - PHP 简易 Web 服务器、基础接口开发
一、PHP 简易 Web 服务器 1、基本介绍 PHP 自带一个简易的 Web 服务器,适合快速测试,启动方式如下 php -S 【监听地址】:【监听端口】# 例如php -S 127.0.0.1:80002、注意事项 通过以下方式启动,就需要通过 localhost 访问,而不能…...

DreamTalk多语言支持深度分析:从中文到德语的语音驱动生成
DreamTalk多语言支持深度分析:从中文到德语的语音驱动生成 【免费下载链接】dreamtalk Official implementations for paper: DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models 项目地址: https://gitcode.com/gh_mirro…...

“文章同步助手” Wechatsync 连接到WordPress独立站
“文章同步助手” Wechatsync 浏览器插件,可以将文章一键分发到包括WordPress在内的二十多个内容平台- 。这连接逻辑本质上都是调用WordPress的REST API来建立连接。 🔌 连接独立站 WordPress 的操作流程 要实现同步,你需要在浏览器插件中配置…...

ICode竞赛Python三级通关秘籍:用if else控制飞船和机器人走迷宫
ICode竞赛Python三级通关秘籍:用if else控制飞船和机器人走迷宫 在ICode国际青少年编程竞赛的Python三级训练场中,掌握if else条件判断是解锁迷宫挑战的关键。不同于枯燥的语法练习,我们将通过飞船(Spaceship)和机器人(Dev)的视角,…...

从零搭建 Geo 开源项目源码开发环境——以 GeoServer 为例
在地理信息(GIS)与空间数据服务开发中,Geo 系开源项目(如 GeoServer、GeoPandas、GeoDjango 等)非常常见。很多团队后期都会走到“读源码 / 改源码 / 二次开发”这一步,而第一步往往是:把源码跑…...