【Python】PySpark 数据计算 ② ( RDD#flatMap 方法 | RDD#flatMap 语法 | 代码示例 )
文章目录
- 一、RDD#flatMap 方法
- 1、RDD#flatMap 方法引入
- 2、解除嵌套
- 3、RDD#flatMap 语法说明
- 二、代码示例 - RDD#flatMap 方法
一、RDD#flatMap 方法
1、RDD#flatMap 方法引入
RDD#map 方法 可以 将 RDD 中的数据元素 逐个进行处理 , 处理的逻辑 需要用外部 通过 参数传入 map 函数 ;
RDD#flatMap 方法 是 在 RDD#map 方法 的基础上 , 增加了 " 解除嵌套 " 的作用 ;
RDD#flatMap 方法 也是 接收一个 函数 作为参数 , 该函数被应用于 RDD 中的每个元素及元素嵌套的子元素 , 并返回一个 新的 RDD 对象 ;
2、解除嵌套
解除嵌套 含义 : 下面的的 列表 中 , 每个元素 都是一个列表 ;
lst = [[1, 2], [3, 4, 5], [6, 7, 8]]
如果将上述 列表 解除嵌套 , 则新的 列表 如下 :
lst = [1, 2, 3, 4, 5, 6, 7, 8]
RDD#flatMap 方法 先对 RDD 中的 每个元素 进行处理 , 然后再 将 计算结果展平放到一个新的 RDD 对象中 , 也就是 解除嵌套 ;
这样 原始 RDD 对象 中的 每个元素 , 都对应 新 RDD 对象中的若干元素 ;
3、RDD#flatMap 语法说明
RDD#flatMap 语法说明 :
newRDD = oldRDD.flatMap(lambda x: [element1, element2, ...])
旧的 RDD 对象 oldRDD 中 , 每个元素应用一个 lambda 函数 , 该函数返回多个元素 , 返回的多个元素就会被展平放入新的 RDD 对象 newRDD 中 ;
代码示例 :
# 将 字符串列表 转为 RDD 对象
rdd = sparkContext.parallelize(["Tom 18", "Jerry 12", "Jack 21"])# 应用 map 操作,将每个元素 按照空格 拆分
rdd2 = rdd.flatMap(lambda element: element.split(" "))
二、代码示例 - RDD#flatMap 方法
代码示例 :
"""
PySpark 数据处理
"""# 导入 PySpark 相关包
from pyspark import SparkConf, SparkContext
# 为 PySpark 配置 Python 解释器
import os
os.environ['PYSPARK_PYTHON'] = "Y:/002_WorkSpace/PycharmProjects/pythonProject/venv/Scripts/python.exe"# 创建 SparkConf 实例对象 , 该对象用于配置 Spark 任务
# setMaster("local[*]") 表示在单机模式下 本机运行
# setAppName("hello_spark") 是给 Spark 程序起一个名字
sparkConf = SparkConf() \.setMaster("local[*]") \.setAppName("hello_spark")# 创建 PySpark 执行环境 入口对象
sparkContext = SparkContext(conf=sparkConf)# 打印 PySpark 版本号
print("PySpark 版本号 : ", sparkContext.version)# 将 字符串列表 转为 RDD 对象
rdd = sparkContext.parallelize(["Tom 18", "Jerry 12", "Jack 21"])# 应用 map 操作,将每个元素 按照空格 拆分
rdd2 = rdd.flatMap(lambda element: element.split(" "))# 打印新的 RDD 中的内容
print(rdd2.collect())# 停止 PySpark 程序
sparkContext.stop()执行结果 :
Y:\002_WorkSpace\PycharmProjects\pythonProject\venv\Scripts\python.exe Y:/002_WorkSpace/PycharmProjects/HelloPython/hello.py
23/07/31 23:02:58 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/07/31 23:02:59 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark 版本号 : 3.4.1
['Tom', '18', 'Jerry', '12', 'Jack', '21']Process finished with exit code 0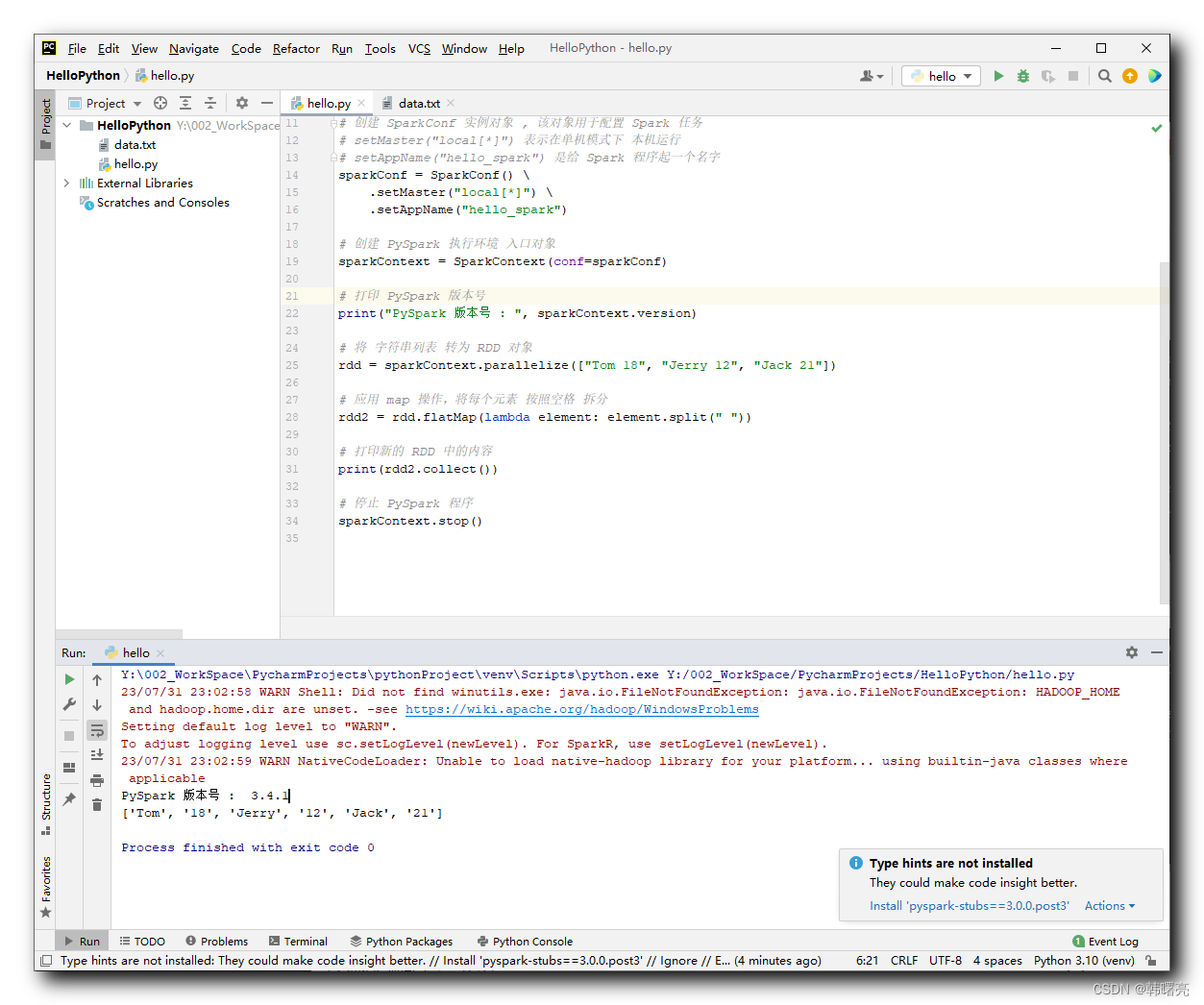
相关文章:
【Python】PySpark 数据计算 ② ( RDD#flatMap 方法 | RDD#flatMap 语法 | 代码示例 )
文章目录 一、RDD#flatMap 方法1、RDD#flatMap 方法引入2、解除嵌套3、RDD#flatMap 语法说明 二、代码示例 - RDD#flatMap 方法 一、RDD#flatMap 方法 1、RDD#flatMap 方法引入 RDD#map 方法 可以 将 RDD 中的数据元素 逐个进行处理 , 处理的逻辑 需要用外部 通过 参数传入 map…...
二叉树题目:左叶子之和
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:左叶子之和 出处:404. 左叶子之和 难度 3 级 题目描述 要求 给你二叉树的根结点 root \texttt{ro…...

Spark SQL报错: Task failed while writing rows.
错误 今天运行 Spark 任务时报了一个错误,如下所示: WARN scheduler.TaskSetManager: Lost task 9.0 in stage 3.0 (TID 69, xxx.xxx.xxx.com, executor 3): org.apache.spark.SparkException: Task failed while writing rows.at org.apache.spark.sq…...
Linux系统下U盘打不开: No application is registered as handling this file
简述 系统是之前就安装好使用的Ubuntu14.04,不过由于某些原因只安装到了机械硬盘中;最近新买了一块固态硬盘,所以打算把Ubuntu系统迁移到新的固态硬盘上; 当成功的迁移了系统之后发现其引导有点问题,导致多个系统启动不…...

07 定时器处理非活动连接(上)
07 定时器处理非活动连接(上) 基础知识 非活跃,是指客户端(这里是浏览器)与服务器端建立连接后,长时间不交换数据,一直占用服务器端的文件描述符,导致连接资源的浪费。 定时事件&a…...
python——案例四:判断字符串中的元素组成
案例四:判断字符串中的元素组成str"Hello World! 666" print(str.isalnum()) #判读所有的字符都是数字或者是字母 print(str.isalpha()) #判读所有的字符都是字母 print(str.isdigit()) #判读所有的字符都是数字 print(str.islower()) #判读所有的字符都是…...
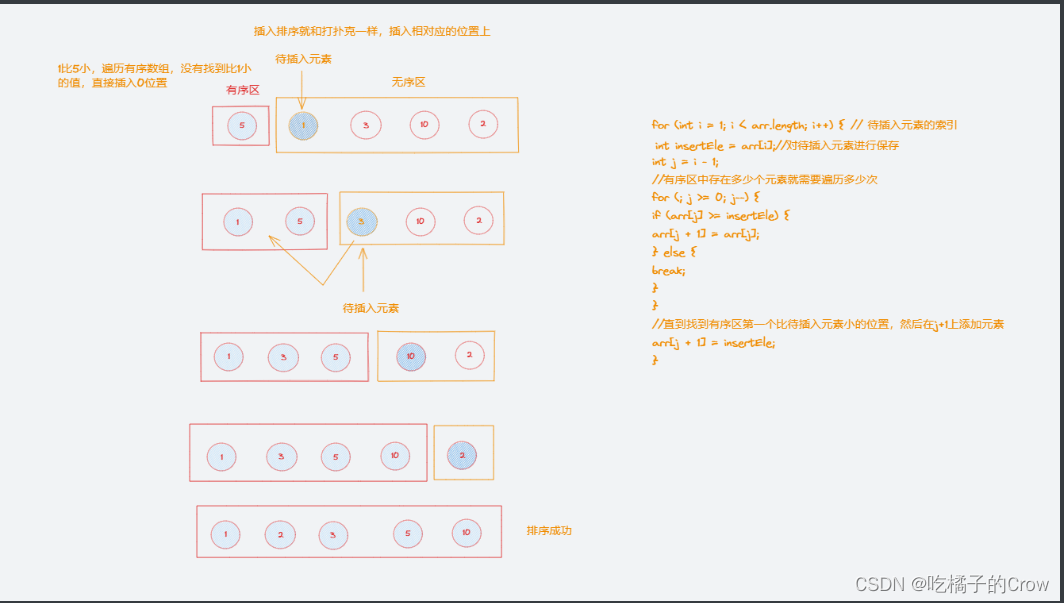
一起学算法(插入排序篇)
概念: 插入排序(inertion Sort)一般也被称为直接插入排序,是一种简单的直观的排序算法 工作原理:将待排列元素划分为(已排序)和(未排序)两部分,每次从&…...
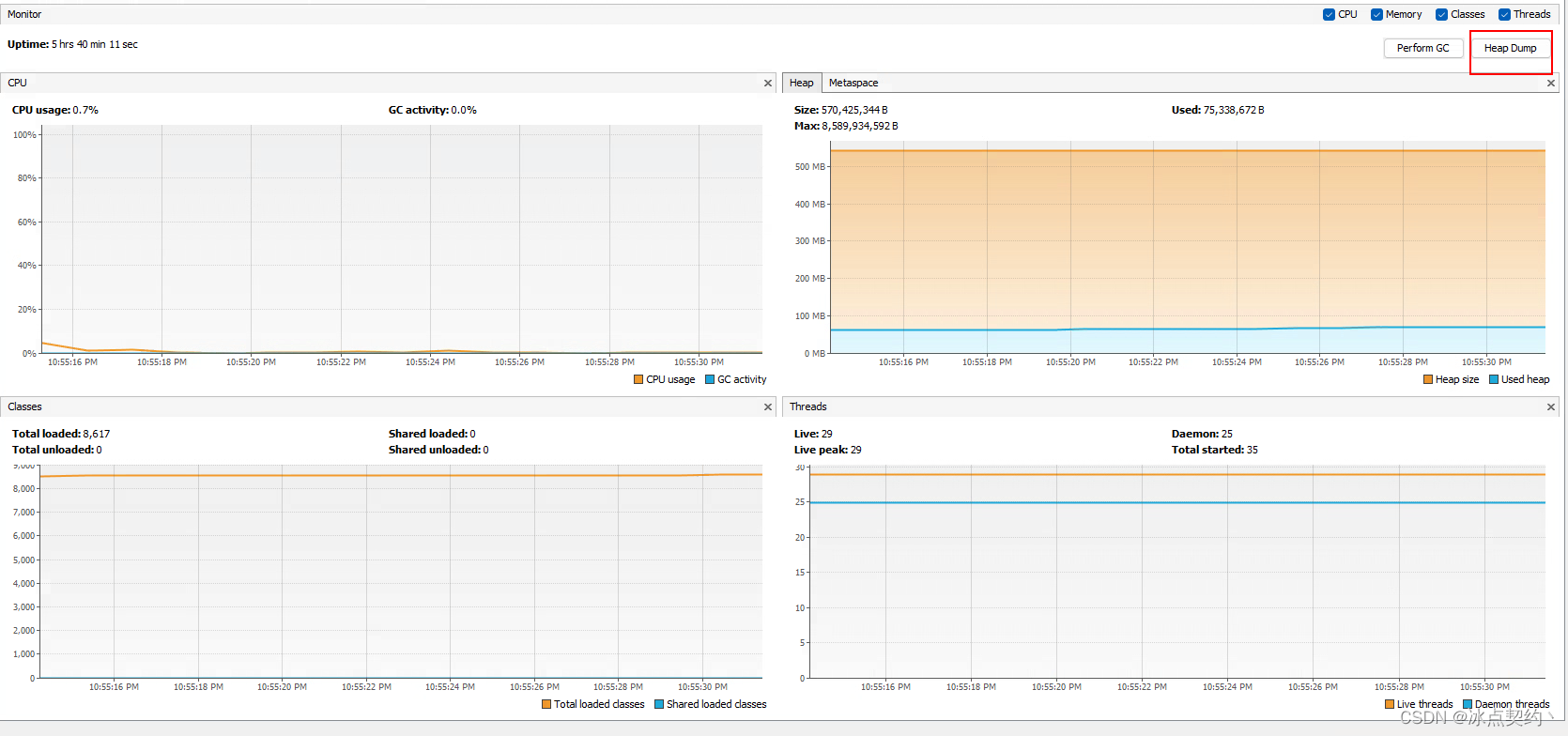
JVM基础篇-本地方法栈与堆
JVM基础篇-本地方法栈与堆 本地方法栈 什么是本地方法? 本地方法即那些不是由java层面实现的方法,而是由c/c实现交给java层面进行调用,这些方法在java中使用native关键字标识 public native int hashCode()本地方法栈的作用? 为本地方法提供内存空…...
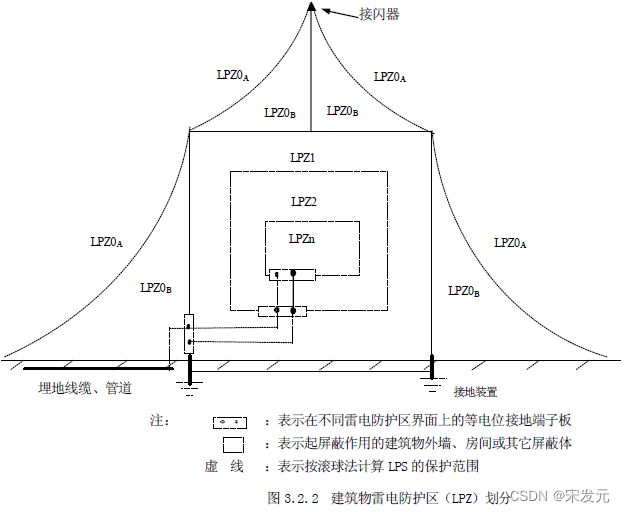
防雷保护区如何划分,防雷分区概念LPZ介绍
在防雷设计中,很重要的一点就是防雷分区的划分,只有先划分好防雷区域等级,才好做出比较好的防雷器设计方案。 因为标准对不同区安装的防雷浪涌保护器要求是不一样的。 那么,防雷保护区是如何划分的呢? 如上图所示&…...

随手笔记——3D−3D:ICP求解
随手笔记——3D−3D:ICP求解 使用 SVD 求解 ICP使用非线性优化来求解 ICP 原理参见 https://blog.csdn.net/jppdss/article/details/131919483 使用 SVD 求解 ICP 使用两幅 RGB-D 图像,通过特征匹配获取两组 3D 点,最后用 ICP 计算它们的位…...

Python调用各大机器翻译API大全
过去的二三年中,我一直关注的是机器翻译API在自动化翻译过程中的应用,包括采用CAT工具和Python编程语言来调用机器翻译API,然后再进行译后编辑,从而达到快速翻译的目的。 然而,我发现随着人工智能的发展,很…...

重生之我要学C++第六天
这篇文章的主要内容是const以及权限问题、static关键字、友元函数和友元类,希望对大家有所帮助,点赞收藏评论支持一下吧! 更多优质内容跳转: 专栏:重生之C启程(文章平均质量分93) 目录 const以及权限问题 1.const修饰…...

SpringBoot中ErrorPage(错误页面)的使用--【ErrorPage组件】
SpringBoot系列文章目录 SpringBoot知识范围-学习步骤–【思维导图知识范围】 文章目录 SpringBoot系列文章目录本系列校训 SpringBoot技术很多很多环境及工具:必要的知识深层一些的知识 上效果图在Spring Boot里使用ErrorPage还要注意的是 配套资源作业ÿ…...

【Android】APP网络优化学习笔记
网络优化原因 进行网络优化对于移动应用程序而言非常重要,原因如下: 用户体验: 网络连接是移动应用程序的核心功能之一。通过进行网络优化,可以提高应用的加载速度和响应速度,减少用户等待时间,提供更流…...
简单的知识图谱可视化+绘制nx.Graph()时报错TypeError: ‘_AxesStack‘ object is not callable
绘制nx.Graph时报错TypeError: _AxesStack object is not callable 写在最前面知识图谱可视化预期报错可能的原因 原代码原因确认解决后的代码解决! 写在最前面 实现一个简单的知识图谱的可视化功能。 使用了NetworkX库来构建知识图谱,并使用matplotlib…...
)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于粒子群优化算法优化BP神经网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码5.1 fun.m5.2 main.m6.完整代码6.1 fun.m6.2 main.m7.运行结果1.模型原理 基于粒子群优化算法(Particle Swarm Optimization, PSO)优…...
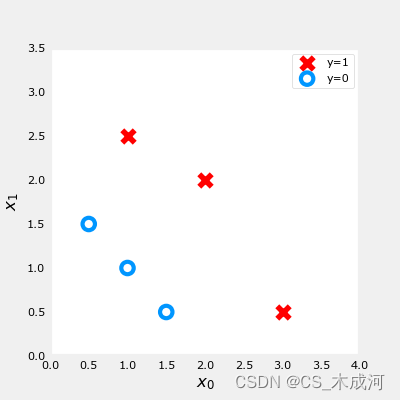
【机器学习】Cost Function for Logistic Regression
Cost Function for Logistic Regression 1. 平方差能否用于逻辑回归?2. 逻辑损失函数loss3. 损失函数cost附录 导入所需的库 import numpy as np %matplotlib widget import matplotlib.pyplot as plt from plt_logistic_loss import plt_logistic_cost, plt_two_…...

【EI/SCOPUS会议征稿】2023年第四届新能源与电气科技国际学术研讨会 (ISNEET 2023)
作为全球科技创新大趋势的引领者,中国一直在为科技创新创造越来越开放的环境,提高学术合作的深度和广度,构建惠及全民的创新共同体。这些努力为全球化和创建共享未来的共同体做出了新的贡献。 为交流近年来国内外在新能源和电气技术领域的最新…...
【计算机网络】10、ethtool
文章目录 一、ethtool1.1 常见操作1.1.1 展示设备属性1.1.2 改变网卡属性1.1.2.1 Auto-negotiation1.1.2.2 Speed 1.1.3 展示网卡驱动设置1.1.4 只展示 Auto-negotiation, RX and TX1.1.5 展示统计1.1.7 排除网络故障1.1.8 通过网口的 LED 区分网卡1.1.9 持久化配置(…...

什么是前端工程化?
工程化介绍 什么是前端工程化? 前端工程化是一种思想,而不是某种技术。主要目的是为了提高效率和降低成本,也就是说在开发的过程中可以提高开发效率,减少不必要的重复性工作等。 tip 现实生活举例 建房子谁不会呢?请…...

GEO优化的两大误区:你是在“交学费”还是在“抢红利”?
当AI搜索成为用户的新入口,一批先行者已经吃到了红利。但更多人,还在两个极端之间摇摆。 你有没有遇到过这样的情况? 刷到某个同行,因为上了DeepSeek或豆包的推荐,咨询量翻了几倍。你也心动,开始研究GEO&a…...

【基于项目代码实测:XCP/CCP 模块“标定差异”全流程深度操作指南无标题】
在实际项目的 XCP/CCP 标定业务中,核对与同步底层内存参数是一项极其高频的操作。本指南将完全基于最新版“标定差异(Calibration Difference)”界面的真实功能逻辑,为你提供一份严谨、详细、且立即可用的三倍容量操作手册。无论你…...

大二学完 MyBatis 再学 MyBatis-Plus,我踩过的 10 个坑
作者:逆境不可逃 技术永无止境 希望我的内容可以帮助到你!!!!! 本节目属于专栏《后端新手谈》:https://blog.csdn.net/2401_87662859/category_13141790.html 大家吼 ! 我是 逆境不可逃 今天给…...
》读书笔记:异常检测方法梳理与实践理解)
《数据挖掘(主编:吕欣 王梦宁)》读书笔记:异常检测方法梳理与实践理解
《数据挖掘(主编:吕欣 王梦宁)》读书笔记:异常检测方法梳理与实践理解本文是学习《数据挖掘(主编:吕欣 王梦宁)》中“异常检测”相关内容后的整理笔记。文章不追求逐条复述教材,而是…...
)
别再让日志拖慢你的服务器!深入对比C++同步与异步日志的性能差异(附TinyWebServer实测)
C服务器日志性能优化实战:同步与异步方案深度对比 当你的Web服务器开始承载真实流量时,那些看似无害的日志语句可能正在悄悄吞噬着系统性能。我曾在一个电商促销日亲眼目睹,由于同步日志的阻塞导致服务器响应时间从50ms飙升到800ms࿰…...

嵌入式与复杂系统安全开发实战:从威胁建模到安全编码的十大核心实践
1. 项目概述:为什么安全开发不再是“可选项”?干了十几年软件开发,从早期的桌面应用到后来的Web服务,再到近几年深度参与的嵌入式系统,我最大的感触就是:安全这件事,已经从“锦上添花”变成了“…...

无监督聚类挖掘声音语义:从音乐描述文本发现认知规律
1. 这不是传统聚类,而是一场对“声音语言”的考古式挖掘你有没有试过听一首歌,然后被某段音色击中——那种“像融化的玻璃糖纸裹着雨滴坠落”的感觉?或者在音乐评论区刷到“低频像沉入深海的青铜钟”“人声有未拆封的羊皮纸质感”这类描述&am…...

从云台控制理解双环PID:手把手调试大疆GM6020电机的角度与速度环
从云台控制理解双环PID:手把手调试大疆GM6020电机的角度与速度环 在机器人控制领域,精准的位置控制是实现高性能运动的基础。无论是工业机械臂的重复定位,还是竞技机器人云台的快速响应,都离不开对电机运动的精确控制。而在这其中…...
)
微波遥感杂谈五(微波辐射计)
前言微波辐射计是通过被动的接收各个高度传来的温度辐射的微波信号来判断温度、 湿度曲线,能定量测量目标(如地物和大气各成分)的低电平微波辐射的高灵敏度接收装置。目前机载微波辐射计实测温度分辨率达0.02K,星载微波辐射计温度分辨率达 0.2࿵…...

【K8s】解惑:K8s 与 Docker 的关系
目录 引言:一个绕不开的问题 一句话说清K8s与Docker的关系 澄清三个误解 从命令的角度,直观对比 引言:一个绕不开的问题 在学习云原生技术的路上,几乎每个人都会遇到这样一个困惑: “有了 Kubernetes(…...